
1、Stream 與 Channel stream 不會自動緩衝數據,channel 會利用系統提供的發送緩衝區、接收緩衝區(更為底層) stream 僅支持阻塞 API,channel 同時支持阻塞、非阻塞 API,網路 channel 可配合 selector 實現多路復用 二者均為全雙工,即讀 ...
1、Stream 與 Channel
- stream 不會自動緩衝數據,channel 會利用系統提供的發送緩衝區、接收緩衝區(更為底層)
- stream 僅支持阻塞 API,channel 同時支持阻塞、非阻塞 API,網路 channel 可配合 selector 實現多路復用
- 二者均為全雙工,即讀寫可以同時進行
- 雖然 Stream 是單向流動的,但是它也是全雙工的
2、IO 模型
- 同步:線程自己去獲取結果(一個線程)
- 例如:線程調用一個方法後,需要等待方法返回結果
- 非同步:線程自己不去獲取結果,而是由其它線程返回結果(至少兩個線程)
- 例如:線程 A 調用一個方法後,繼續向下運行,運行結果由線程 B 返回
當調用一次 channel.read 或 stream.read 後,會由用戶態切換至操作系統內核態來完成真正數據讀取,而讀取又分為兩個階段,分別為:
- 等待數據階段
- 複製數據階段
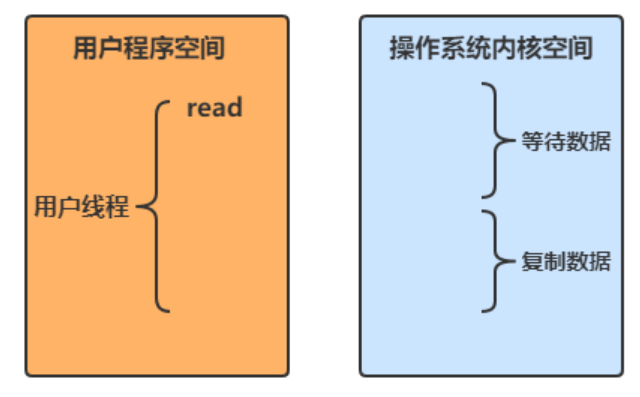
根據 UNIX 網路編程 - 捲 I,IO 模型主要有以下幾種
阻塞 IO
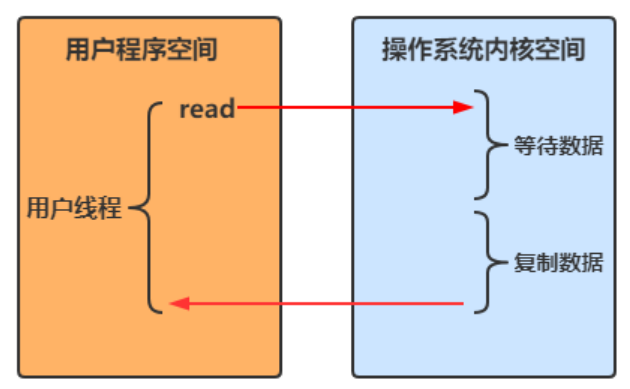
- 用戶線程進行 read 操作時,需要等待操作系統執行實際的 read 操作,此期間用戶線程是被阻塞的,無法執行其他操作
非阻塞IO
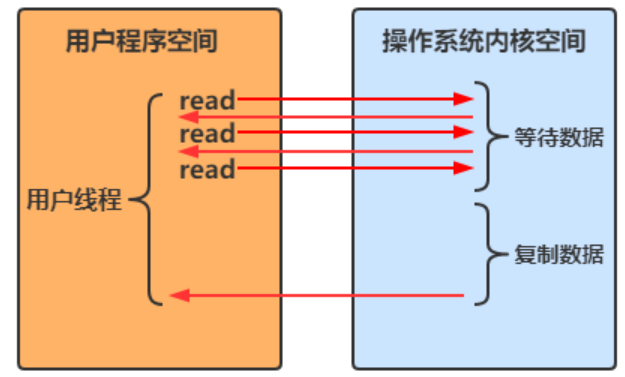
-
用戶線程
在一個迴圈中一直調用 read 方法,若內核空間中還沒有數據可讀,立即返回
- 只是在等待階段非阻塞
-
用戶線程發現內核空間中有數據後,等待內核空間執行複製數據,待複製結束後返回結果
多路復用
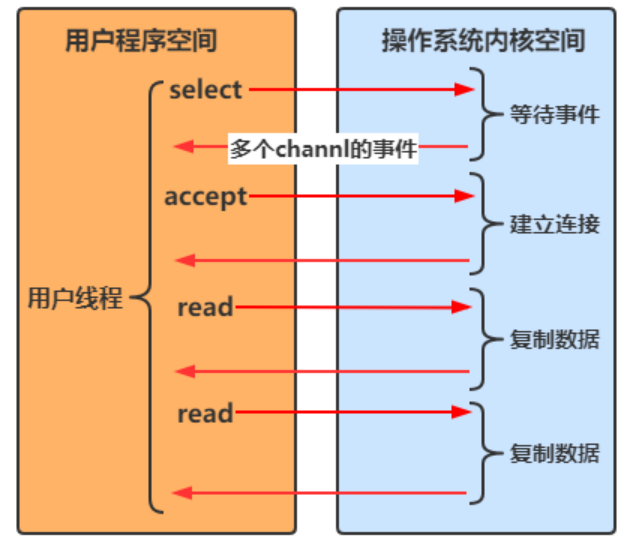
Java 中通過 Selector 實現多路復用
- 當沒有事件是,調用 select 方法會被阻塞住
- 一旦有一個或多個事件發生後,就會處理對應的事件,從而實現多路復用
多路復用與阻塞IO的區別
- 阻塞 IO 模式下,若線程因 accept 事件被阻塞,發生 read 事件後,仍需等待 accept 事件執行完成後,才能去處理 read 事件
- 多路復用模式下,一個事件發生後,若另一個事件處於阻塞狀態,不會影響該事件的執行
非同步IO
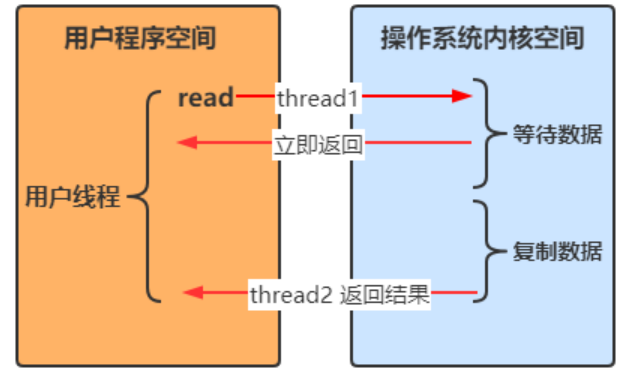
- 線程 1 調用方法後理解返回,不會被阻塞也不需要立即獲取結果
- 當方法的運行結果出來以後,由線程 2 將結果返回給線程 1
3、零拷貝
零拷貝指的是數據無需拷貝到 JVM 記憶體中,同時具有以下三個優點
- 更少的用戶態與內核態的切換
- 不利用 cpu 計算,減少 cpu 緩存偽共用
- 零拷貝適合小文件傳輸
傳統 IO 問題
傳統的 IO 將一個文件通過 socket 寫出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);
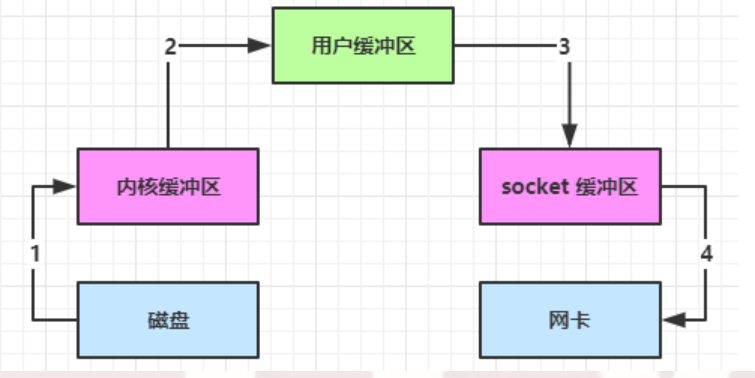
內部工作流如下
-
Java 本身並不具備 IO 讀寫能力,因此 read 方法調用後,要從 Java 程式的用戶態切換至內核態,去調用操作系統(Kernel)的讀能力,將數據讀入內核緩衝區。這期間用戶線程阻塞,操作系統使用 DMA(Direct Memory Access)來實現文件讀,其間也不會使用 CPU
DMA 也可以理解為硬體單元,用來解放 cpu 完成文件 IO
-
從內核態切換回用戶態,將數據從內核緩衝區讀入用戶緩衝區(即 byte [] buf),這期間 CPU 會參與拷貝,無法利用 DMA
-
調用 write 方法,這時將數據從用戶緩衝區(byte [] buf)寫入 socket 緩衝區,CPU 會參與拷貝
-
接下來要向網卡寫數據,這項能力 Java 又不具備,因此又得從用戶態切換至內核態,調用操作系統的寫能力,使用 DMA 將 socket 緩衝區的數據寫入網卡,不會使用 CPU
可以看到中間環節較多,java 的 IO 實際不是物理設備級別的讀寫,而是緩存的複製,底層的真正讀寫是操作系統來完成的
- 用戶態與內核態的切換髮生了 3 次,這個操作比較重量級
- 數據拷貝了共 4 次
NIO優化
通過 DirectByteBuf
- ByteBuffer.allocate(10)
- 底層對應 HeapByteBuffer,使用的還是 Java 記憶體
- ByteBuffer.allocateDirect(10)
- 底層對應 DirectByteBuffer,使用的是操作系統記憶體
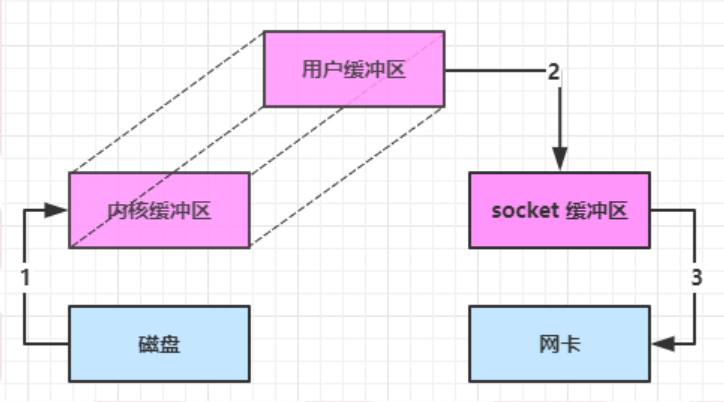
大部分步驟與優化前相同,唯有一點:Java 可以使用 DirectByteBuffer 將堆外記憶體映射到 JVM 記憶體中來直接訪問使用
- 這塊記憶體不受 JVM 垃圾回收的影響,因此記憶體地址固定,有助於 IO 讀寫
- Java 中的 DirectByteBuf 對象僅維護了此記憶體的虛引用,記憶體回收分成兩步
- DirectByteBuffer 對象被垃圾回收,將虛引用加入引用隊列
- 當引用的對象 ByteBuffer 被垃圾回收以後,虛引用對象 Cleaner 就會被放入引用隊列中,然後調用 Cleaner 的 clean 方法來釋放直接記憶體
- DirectByteBuffer 的釋放底層調用的是 Unsafe 的 freeMemory 方法
- 通過專門線程訪問引用隊列,根據虛引用釋放堆外記憶體
- DirectByteBuffer 對象被垃圾回收,將虛引用加入引用隊列
- 減少了一次數據拷貝,用戶態與內核態的切換次數沒有減少
進一步優化 1
以下兩種方式都是零拷貝,即無需將數據拷貝到用戶緩衝區中(JVM 記憶體中)
底層採用了 linux 2.1 後提供的 sendFile 方法,Java 中對應著兩個 channel 調用 transferTo/transferFrom 方法拷貝數據
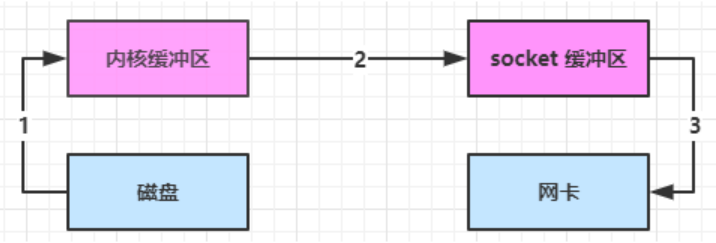
- Java 調用 transferTo 方法後,要從 Java 程式的用戶態切換至內核態,使用 DMA 將數據讀入內核緩衝區,不會使用 CPU
- 數據從內核緩衝區傳輸到 socket 緩衝區,CPU 會參與拷貝
- 最後使用 DMA 將 socket 緩衝區的數據寫入網卡,不會使用 CPU
這種方法下
- 只發生了 1 次用戶態與內核態的切換
- 數據拷貝了 3 次
進一步優化 2
linux 2.4 對上述方法再次進行了優化
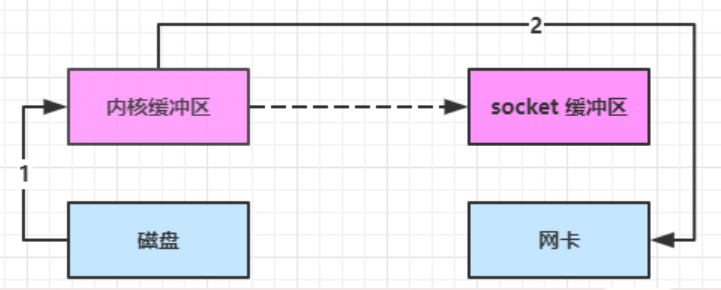
- Java 調用 transferTo 方法後,要從 Java 程式的用戶態切換至內核態,使用 DMA 將數據讀入內核緩衝區,不會使用 CPU
- 只會將一些 offset 和 length 信息拷入 socket 緩衝區,幾乎無消耗
- 使用 DMA 將 內核緩衝區的數據寫入網卡,不會使用 CPU
整個過程僅只發生了 1 次用戶態與內核態的切換,數據拷貝了 2 次
4、AIO
AIO 用來解決數據複製階段的阻塞問題
- 同步意味著,在進行讀寫操作時,線程需要等待結果,還是相當於閑置
- 非同步意味著,在進行讀寫操作時,線程不必等待結果,而是將來由操作系統來通過回調方式由另外的線程來獲得結果
非同步模型需要底層操作系統(Kernel)提供支持
- Windows 系統通過 IOCP 實現了真正的非同步 IO
- Linux 系統非同步 IO 在 2.6 版本引入,但其底層實現還是用多路復用模擬了非同步 IO,性能沒有優勢
本文由
傳智教育博學谷教研團隊發佈。如果本文對您有幫助,歡迎
關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力。轉載請註明出處!


