
DWM 建表,需要看 DWS 需求。 DWS 來自維度(訪客、商品、地區、關鍵詞),為了出最終的指標 ADS 需求指標 DWT 為什麼實時數倉沒有DWT,因為它是歷史的聚集,累積結果,實時數倉中不需要 DWD 不需要加工 DWM 需要加工的數據 統計主題 需求指標【ADS】輸出方式計算來源來源層級 ...
DWM 建表,需要看 DWS 需求。
DWS 來自維度(訪客、商品、地區、關鍵詞),為了出最終的指標
ADS 需求指標
DWT 為什麼實時數倉沒有DWT,因為它是歷史的聚集,累積結果,實時數倉中不需要
DWD 不需要加工
DWM 需要加工的數據
| 統計主題 | 需求指標【ADS】 | 輸出方式 | 計算來源 | 來源層級 |
|---|---|---|---|---|
| 訪客【DWS】 | pv | 可視化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 可視化大屏 | 需要用 page_log 過濾去重 | dwm | |
| 跳出率 | 可視化大屏 | 需要通過 page_log 行為判斷 | dwm | |
| 進入頁面數 | 可視化大屏 | 需要識別開始訪問標識 | dwd | |
| 連續訪問時長 | 可視化大屏 | page_log 直接可求 | dwd | |
| 商品 | 點擊 | 多維分析 | page_log 直接可求 | dwd |
| 收藏 | 多維分析 | 收藏表 | dwd | |
| 加入購物車 | 多維分析 | 購物車表 | dwd | |
| 下單 | 可視化大屏 | 訂單寬表 | dwm | |
| 支付 | 多維分析 | 支付寬表 | dwm | |
| 退款 | 多維分析 | 退款表 | dwd | |
| 評論 | 多維分析 | 評論表 | dwd | |
| 地區 | PV | 多維分析 | page_log 直接可求 | dwd |
| UV | 多維分析 | 需要用 page_log 過濾去重 | dwm | |
| 下單 | 可視化大屏 | 訂單寬表 | dwm | |
| 關鍵詞 | 搜索關鍵詞 | 可視化大屏 | 頁面訪問日誌 直接可求 | dwd |
| 點擊商品關鍵詞 | 可視化大屏 | 商品主題下單再次聚合 | dws | |
| 下單商品關鍵詞 | 可視化大屏 | 商品主題下單再次聚合 | dws |
獨立訪客UV
UV,全稱是 Unique Visitor,即獨立訪客,對於實時計算中,也可以稱為 DAU(Daily Active User),即每日活躍用戶,因為實時計算中的 UV 通常是指當日的訪客數。
那麼如何從用戶行為日誌中識別出當日的訪客,那麼有兩點:
- 是識別出該訪客打開的第一個頁面,表示這個訪客開始進入我們的應用
- 由於訪客可以在一天中多次進入應用,所以我們要在一天的範圍內進行去重(狀態去重)
KeyState min -> state (存日期)
- 獲取執行環境
- 讀取Kafka dwd_page_log 主題的數據
- 將每行數據轉換為JSON對象
- 過濾數據,狀態編程 只保留每個 mid 每天第一次登錄的數據
- 將數據寫入kafka
- 啟動任務
過濾思路
- 首先用 keyby 按照 mid 進行分組,每組表示當前設備的訪問情況
- 分組後使用 keystate 狀態,記錄用戶進入時間,實現 RichFilterFunction 完成過濾
- 重寫 open 方法用來初始化狀態
- 重寫 filter 方法進行過濾
◼ 可以直接篩掉 last_page_id 不為空的欄位,因為只要有上一頁,說明這條不是這個用戶進入的首個頁面。
◼ 狀態用來記錄用戶的進入時間,只要這個 lastVisitDate 是今天,就說明用戶今天已經訪問過了所以篩除掉。如果為空或者不是今天,說明今天還沒訪問過,則保留。
◼ 因為狀態值主要用於篩選是否今天來過,所以這個記錄過了今天基本上沒有用了,這裡 enableTimeToLive 設定了 1 天的過期時間,避免狀態過大。
跳出明細
跳出就是用戶成功訪問了網站的一個頁面後就退出,不在繼續訪問網站的其它頁面。
跳出率就是用跳出次數除以訪問次數。
關註跳出率,可以看出引流過來的訪客是否能很快的被吸引,渠道引流過來的用戶之間的質量對比,對於應用優化前後跳出率的對比也能看出優化改進的成果。
跳出率高不是好事、留存率高是好事
計算跳出行為的思路
首先要識別哪些是跳出行為,要把這些跳出的訪客最後一個訪問的頁面識別出來。那麼要抓住幾個特征:
- 該頁面是用戶近期訪問的第一個頁面
這個可以通過該頁面是否有上一個頁面(last_page_id)來判斷,如果這個表示為空,就說明這是這個訪客這次訪問的第一個頁面。 - 首次訪問之後很長一段時間(自己設定),用戶沒繼續再有其他頁面的訪問。
這第一個特征的識別很簡單,保留 last_page_id 為空的就可以了。但是第二個訪問的判斷,其實有點麻煩,首先這不是用一條數據就能得出結論的,需要組合判斷,要用一條存在的數據和不存在的數據進行組合判斷。而且要通過一個不存在的數據求得一條存在的數據。更麻煩的他並不是永遠不存在,而是在一定時間範圍內不存在。那麼如何識別有一定失效的組合行為呢?
最簡單的辦法就是 Flink 自帶的 CEP 技術。這個 CEP 非常適合通過多條數據組合來識別某個事件。
用戶跳出事件,本質上就是一個條件事件加一個超時事件的組合。
- 獲取執行環境
- 讀取 Kafka dwd_page_log 主題的數據
- 將每行數據轉換為JSON對象,並提取時間戳生成 Watermark
- 定義模式序列
- 將模式序列作用到流上 CEP
- 提取匹配上的和超時事件
- UNION 兩種事件
- 將數據寫入kafka
- 啟動任務
訂單寬表
需求分析與思路
訂單是統計分析的重要的對象,圍繞訂單有很多的維度統計需求,比如用戶、地區、商品、品類、品牌等等。
為了之後統計計算更加方便,減少大表之間的關聯,所以在實時計算過程中將圍繞訂單的相關數據整合成為一張訂單的寬表。
那究竟哪些數據需要和訂單整合在一起?
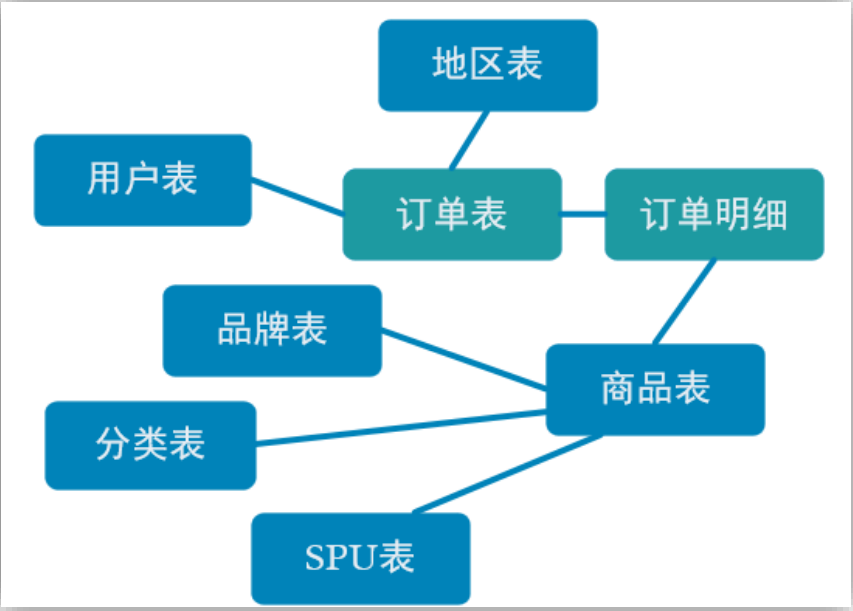
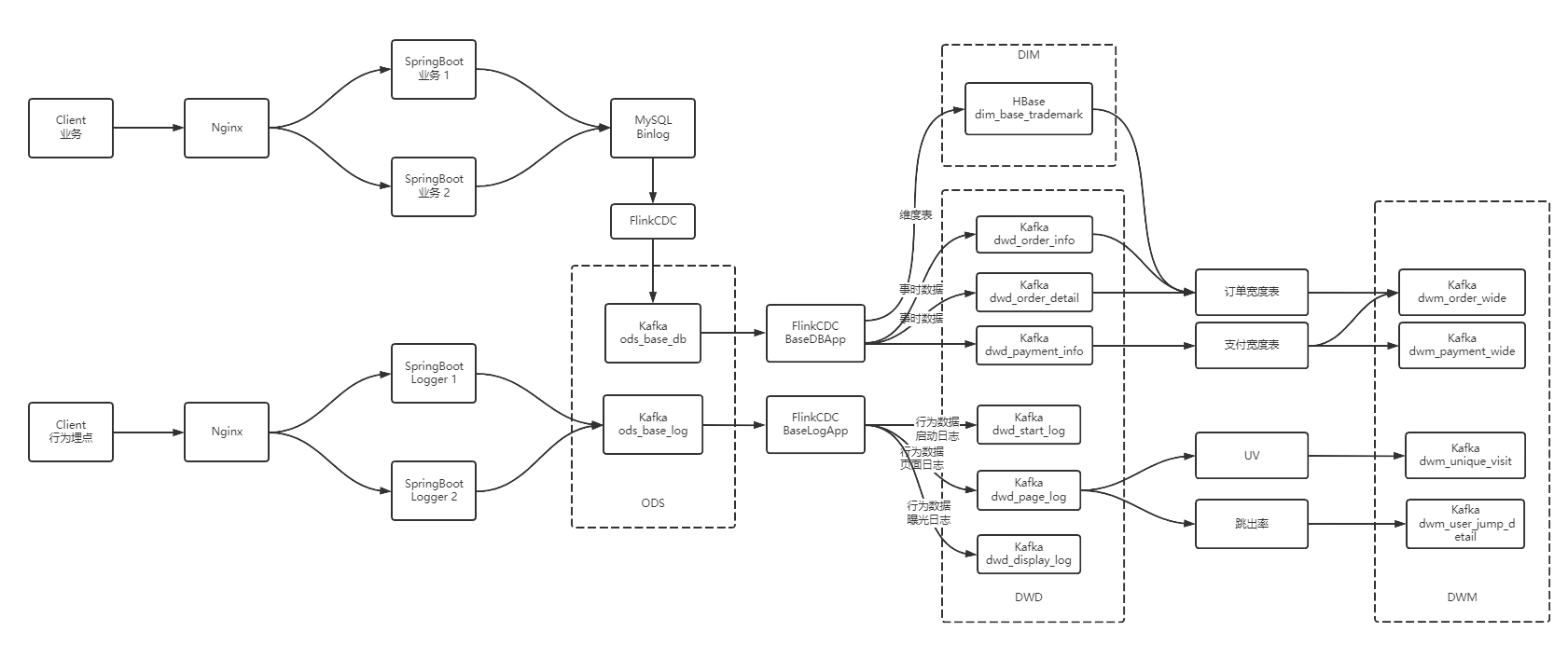
如上圖,由於在之前的操作我們已經把數據分拆成了事實數據和維度數據,事實數據(綠色)進入 kafka 數據流(DWD 層)中,維度數據(藍色)進入 hbase 中長期保存。那麼我們在 DWM 層中要把實時和維度數據進行整合關聯在一起,形成寬表。那麼這裡就要處理有兩種關聯,事實數據和事實數據關聯、事實數據和維度數據關聯。
- 事實數據和事實數據關聯,其實就是流與流之間的關聯。
- 事實數據與維度數據關聯,其實就是流計算中查詢外部數據源。
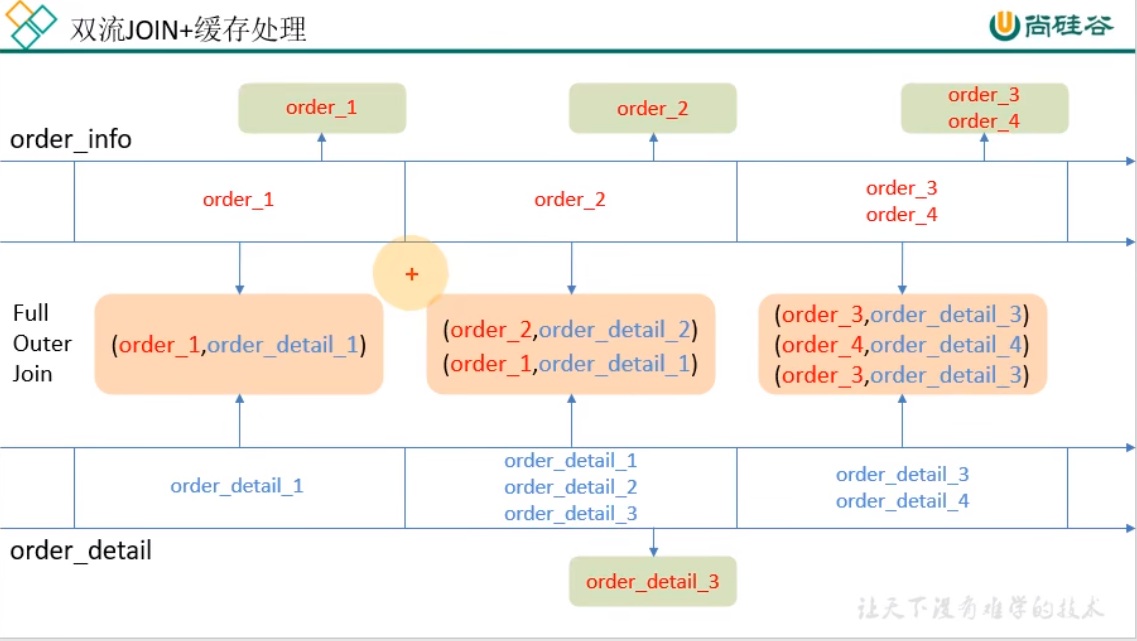
訂單和訂單明細關聯(雙流 join)
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/joining.html
在 flink 中的流 join 大體分為兩種,一種是基於時間視窗的 join(Time Windowed Join),比如 join、coGroup 等。另一種是基於狀態緩存的 join(Temporal Table Join),比如 Interval Join。
這裡選用 Interval Join,因為相比較視窗 join,Interval Join 使用更簡單,而且避免了應匹配的數據處於不同視窗的問題。Interval Join 目前只有一個問題,就是還不支持 left join。
但是我們這裡是訂單主表與訂單從表之間的關聯不需要 left join,所以 intervalJoin 是較好的選擇。
- 設定事件時間水位線
- 創建合併後的寬表實體類
- 訂單和訂單明細關聯 intervalJoin
- 獲取執行環境
- 讀取兩個埠數據創建流,並提取時間戳生成 Watermark
- 雙流join
- 列印
- 啟動任務
維表關聯代碼實現
維度關聯實際上就是在流中查詢存儲在 HBase 中的數據表。但是即使通過主鍵的方式查詢,HBase 速度的查詢也是不及流之間的 join。外部數據源的查詢常常是流式計算的性能瓶頸,所以咱們再這個基礎上還有進行一定的優化。
- 獲取執行環境
- 讀取 Kafka dwd_page_log 主題的數據
- 將每行數據轉換為JavaBean對象,並提取時間戳生成 Watermark
- 雙流join
- 關聯維度信息
- 將數據寫入kafka
- 啟動任務
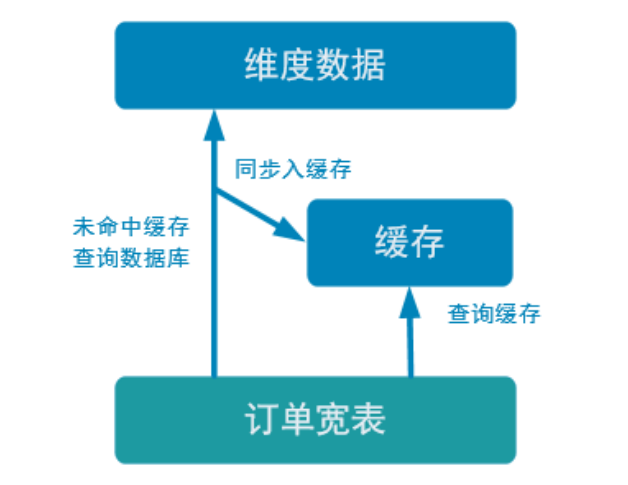
優化-加入旁路緩存模式 (cache-aside-pattern)
我們在上面實現的功能中,直接查詢的 HBase。外部數據源的查詢常常是流式計算的性能瓶頸,所以我們需要在上面實現的基礎上進行一定的優化。我們這裡使用旁路緩存。
旁路緩存模式是一種非常常見的按需分配緩存的模式。如下圖,任何請求優先訪問緩存,緩存命中,直接獲得數據返回請求。如果未命中則,查詢資料庫,同時把結果寫入緩存以備後續請求使用。
這種緩存策略有幾個註意點
緩存要設過期時間,不然冷數據會常駐緩存浪費資源。
要考慮維度數據是否會發生變化,如果發生變化要主動清除緩存。
緩存的選型
一般兩種:堆緩存或者獨立緩存服務(redis,memcache),
堆緩存,從性能角度看更好,畢竟訪問數據路徑更短,減少過程消耗。但是管理性差,其他進程無法維護緩存中的數據。
獨立緩存服務(redis,memcache)本事性能也不錯,不過會有創建連接、網路 IO 等消耗。但是考慮到數據如果會發生變化,那還是獨立緩存服務管理性更強,而且如果數據量特別大,獨立緩存更容易擴展。
因為咱們的維度數據都是可變數據,所以這裡還是採用 Redis 管理緩存。
優化-非同步查詢
在 Flink 流處理過程中,經常需要和外部系統進行交互,用維度表補全事實表中的欄位。例如:在電商場景中,需要一個商品的 skuid 去關聯商品的一些屬性,例如商品所屬行業、商品的生產廠家、生產廠家的一些情況;在物流場景中,知道包裹 id,需要去關聯包裹的行業屬性、發貨信息、收貨信息等等。
預設情況下,在 Flink 的 MapFunction 中,單個並行只能用同步方式去交互: 將請求發送到外部存儲,IO 阻塞,等待請求返回,然後繼續發送下一個請求。這種同步交互的方式往往在網路等待上就耗費了大量時間。為了提高處理效率,可以增加 MapFunction 的並行度,但增加並行度就意味著更多的資源,並不是一種非常好的解決方式。
Flink 在 1.2 中引入了 Async I/O,在非同步模式下,將 IO 操作非同步化,單個並行可以連續發送多個請求,哪個請求先返回就先處理,從而在連續的請求間不需要阻塞式等待,大大提高了流處理效率。
Async I/O 是阿裡巴巴貢獻給社區的一個呼聲非常高的特性,解決與外部系統交互時網路延遲成為了系統瓶頸的問題。
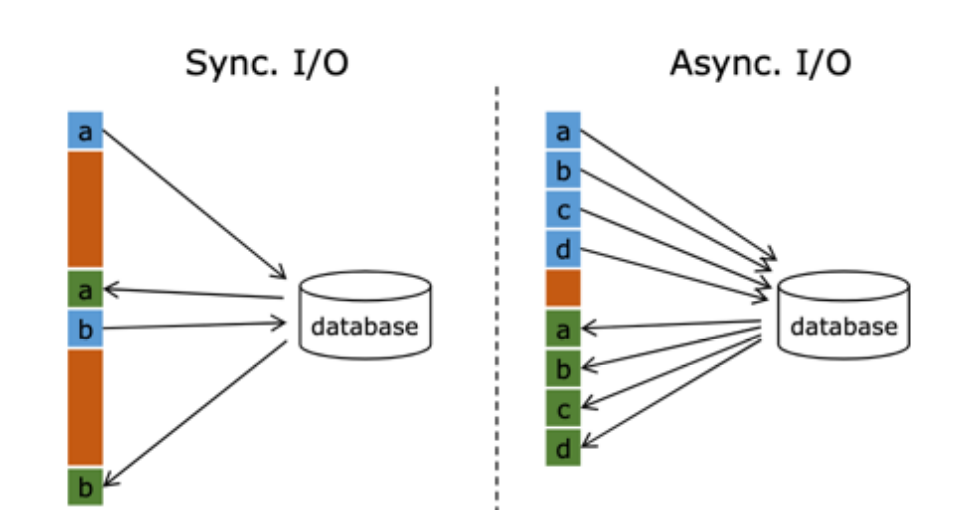
非同步查詢實際上是把維表的查詢操作托管給單獨的線程池完成,這樣不會因為某一個查詢造成阻塞,單個並行可以連續發送多個請求,提高併發效率。
這種方式特別針對涉及網路 IO 的操作,減少因為請求等待帶來的消耗。
支付寬表
支付寬表的目的,最主要的原因是支付表沒有到訂單明細,支付金額沒有細分到商品上,沒有辦法統計商品級的支付狀況。
所以本次寬表的核心就是要把支付表的信息與訂單寬表關聯上。
解決方案有兩個
- 一個是把訂單寬表輸出到 HBase 上,在支付寬表計算時查詢 HBase,這相當於把訂單寬表作為一種維度進行管理。
- 一個是用流的方式接收訂單寬表,然後用雙流 join 方式進行合併。因為訂單與支付產生有一定的時差。所以必須用 Interval Join 來管理流的狀態時間,保證當支付到達時訂單寬表還保存在狀態中。
訂單寬表不需要永久保存,數據本身要寫Kafka所以沒必要再寫一份到 HBase,還要從裡面查,綜合考慮,採用第2種方案。
https://www.bilibili.com/video/BV1Ju411o7f8/?p=73
大數據 - 數據倉庫-實時數倉架構分析
大數據 - 業務數據採集-FlinkCDC
大數據 - DWD&DIM 行為數據
大數據 - DWD&DIM 業務數據
大數據 - DWM層 業務實現
大數據 - DWS層 業務實現
大數據 - ADS 數據可視化實現

