
作者:小目標青年 來源:https://blog.csdn.net/qq_35387940/article/details/125921218 前言 不建議使用 select * 這幾個字眼,做開發的都不陌生吧。 阿裡的開發手冊上面也是有提到: 這個完整版可以關註公眾號Java核心技術,然後在公眾號 ...
作者:小目標青年
來源:https://blog.csdn.net/qq_35387940/article/details/125921218
前言
不建議使用 select *
這幾個字眼,做開發的都不陌生吧。
阿裡的開發手冊上面也是有提到:

這個完整版可以關註公眾號Java核心技術,然後在公眾號後臺回覆手冊獲取。
昨晚收到一個小兄弟的反饋:
隨後也問了下學習群里的兄弟們,
不敢吱聲的:

好像派:

離譜的:

那麼,我作為一個出手俠, 我必然要出手了。
出手俠:
習慣用語,等到xxxxx的時候,我就會出手。
正文

這個完整版可以關註公眾號Java核心技術,然後在公眾號後臺回覆手冊獲取。其實阿裡巴巴手冊上說明的三點了:
1) 增加查詢分析器解析成本
什麼是分析器成本,什麼東西,我隨手畫個簡圖,大家知道一下:
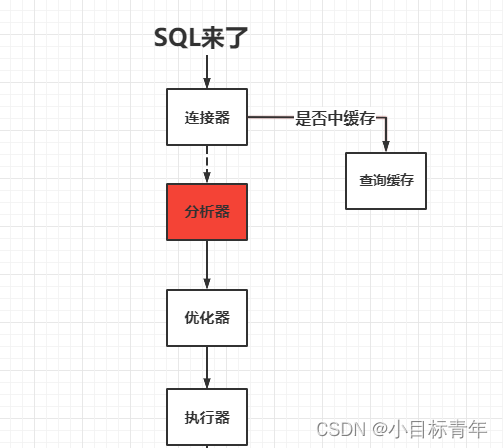
就是這個分析器,這裡會去解析你的sql的語法,詞法。
舉例,如果是select * from user , 看到 * ,就會去看看是哪個表 user,然後 Query Table Metadata For Columns,把所有列值給你支楞出來,填充成類似 select id ,name ,age,phone form user 這樣子。(當然還有其他分析了,例如如語法的判斷, 欄位的判斷, 表名等等)
說實話。這個分析器的成本....你要是說增加瞭解析成本,我確實能理解。
但是我感覺成本也不是很大.... 除非是個大表,大到查詢完所有列值?
so,我能接受,但是接受得不多。
2) 增減欄位,容易與resultMap 配置不一致
這一點我不想說。說實在的,有時候寫select *(需要查表所有列值的時候), 我實體加了欄位,我改了resultMap ,我sql還不用動。
這一點屬於是平時使用規範上的規避點了,不多言。
3)無用欄位增加網路消耗、磁碟IO開銷
這一點有講究。
可以看到我第一點裡面畫的簡圖, 如果說
不考慮緩存 存在的時候:
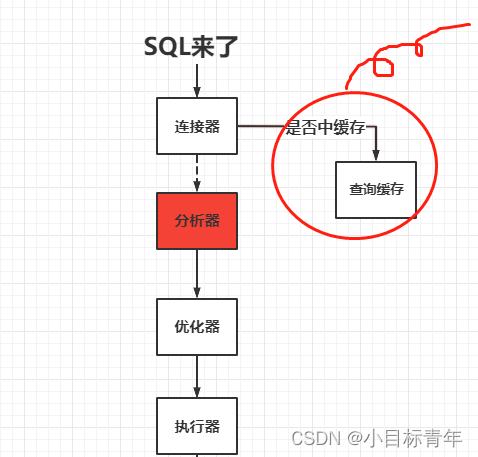
最終會走到執行器,然後執行器後面其實是引擎層

引擎層這裡我就不展開了,引擎層裡面其實包括了各種日誌(undo、redo、binlog等)的記錄,還有就是在記憶體里找數據。
簡單點歸納,其實這種查詢操作就是刷盤操作,從磁碟刷入記憶體,涉及到的 磁碟IO開銷。
那麼在刷盤操作的時候,是不是真的selec * 就真的會 增加 磁碟IO開銷呢?
答案,肯定是的。但是 增大的影響程度,我必須說一下:
如果你說 ,表裡面就三欄位 , id ,name ,age ,本來查 id ,name ;因為 select * ,變成查多了一個 age , 增大磁碟IO開銷 ?
我覺得是增大了,但是幾乎不用理。因為這些都是正常的數據類型,開銷增大不了多少。
所以,真正隱藏的雷是什麼?
有大欄位
例如
tinytext、text、mediumtext、longtext
tinybob、blob、mediumblob、longblob
這些家伙,在mysql上,就是當做一個獨立的對象處理。
這時候就真的要謹慎了。
如果你是個比較多欄位的表,例如什麼意見反饋表,留言不確定長度,用了text ,還有回覆留言欄位也用了text ;
又例如博客文本表,為了存content,用了這些大欄位。
本來想查詢一下 意見的反饋人名 ,或者是 查詢博客的標題,結果因為懶或者不註意,寫了select *., 查詢的時候帶出來這些 大欄位。
那麼顯然,這時候讀取的內容數據就是真的比原先初衷要大很多(沒準業主小丹投訴保全,意見反饋的留言給你寫了篇小論文), 這時候因為讀取的內容多,磁碟IO開銷多,然後返回數據包給客戶端量也多, 這樣 就真的是有影響了。
4) 補充,其實也是我首當其衝想說的一點
無法使用索引覆蓋
ps:今天學習成語了嗎?不要亂用成語。
select * 基本告別索引覆蓋了
什麼是索引覆蓋?
舉例 :
給name欄位 建索引, 查詢的時候,只用到了 索引的欄位,這就是索引覆蓋 。
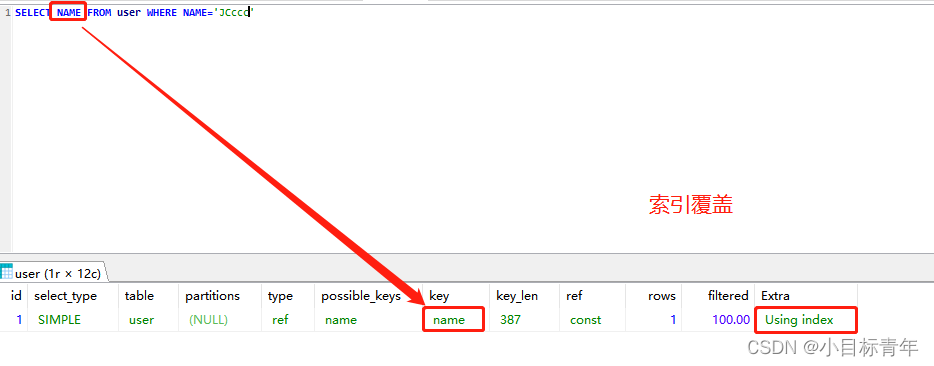
也就是直接通過查詢索引,拿出來的數據就已經滿足了查詢返回的欄位數據。無需額外其他查詢操作了,也就是索引覆蓋了。這樣肯定快。
如果初衷是查 name, 結果寫成了 select * , 變成查多了其他欄位, 那其他欄位不是索引,肯定無法觸發索引覆蓋使用場景了,也就是需要額外的回表查詢操作了,那這樣就慢了。
回歸正題,因為寫成select * ,變成查多了其他欄位, 其他欄位不是索引,導致回表,慢。
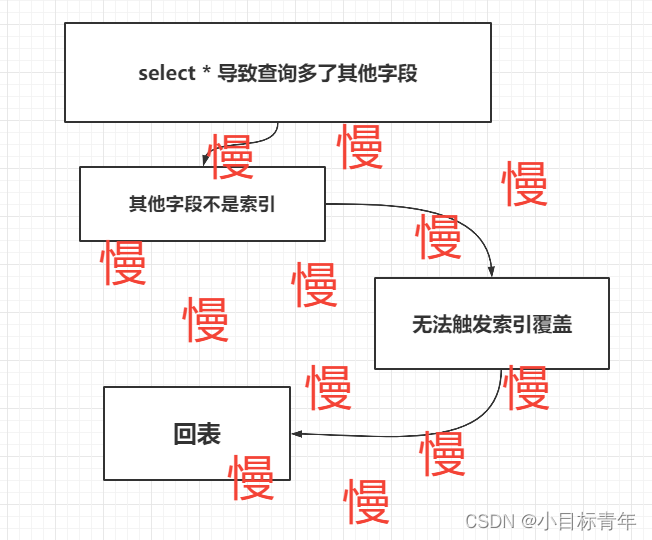
問題出在哪裡? 出在其他欄位不是索引?
那麼給其他欄位都建索引唄,完事了兄弟們。
你們千萬不要這麼亂搞,索引的維護成本一定是不能忽視的。
涉及到修改新增刪除數據時索引的維護成本,索引頁的分裂合併等等。索引也是需要存起來的,也是需要占用磁碟空間的。而且如果N個欄位都是索引, 隨便改動一行數據,需要維護N個索引。
什麼概念,就像咱們平時寫word文檔,搞了個目錄,然後底下的2級標題,3級標題,正文啥的,什麼分頁啥的,亂七八糟操作的編輯,都需要去刷新一下目錄。
那麼這個索引覆蓋影響真的非常大嗎?
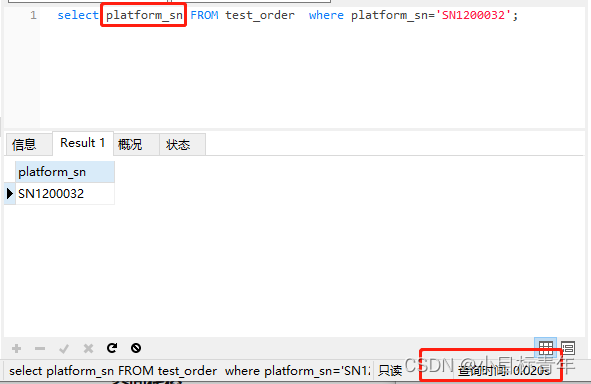
拿出200W數據的表,刪除全部索引,給 platform_sn 單獨加索引 :

然後先試試索引覆蓋的查詢,看看用時,0.02秒 :

接著換成select * :
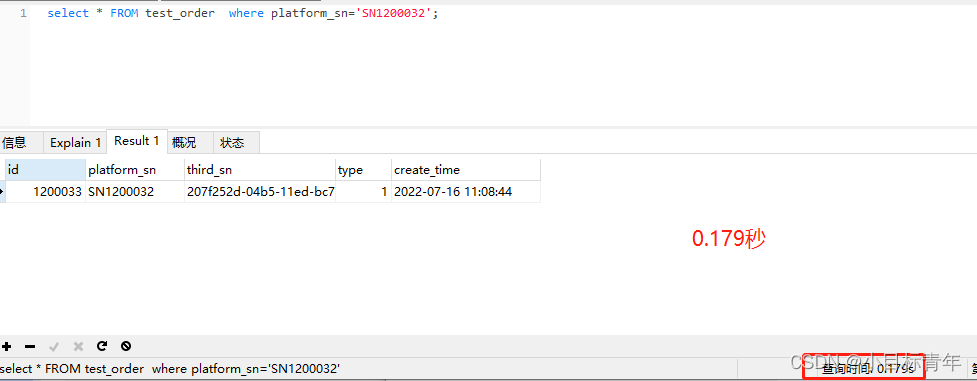
當然這是 200W 數據的場景下, 不過可以看出,時間差距還是很明顯。
0.02 到 0.179 ....
如果我們再加幾個大欄位?Text ... 那估計就真的離譜了 。
客觀總結:
- 如果表裡有大欄位,TEXT 、BLOB系列類型欄位, 使用
SELECT *需要註意 - 如果本來只查詢某1,2個比較常用的欄位的,可以給這些欄位建單個索引或者組合索引 ,這時候查詢就避免 使用
SELECT *,儘量能觸發索引覆蓋是最好的了 - 如果表欄位不多,也沒啥特殊欄位類型, 而且肯定是查多列的,無法觸發索引覆蓋的情況下,
我覺得 使用 SELECT * 也無妨,或者寫個<select cloum> 裡面列出所有欄位,這樣copy代碼也方便(因為會存在一種情況就是,資料庫裡面有這個欄位,但是不能查出來,這種情況select * 就是不如寫成select <select cloum>這種方式方便了,只需要在<select cloum> 提除某個欄位就 可以)。
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!


