
摘要:GaussDB(DWS)提供了資源管理功能,用戶可以根據自身業務情況對資源進行劃分,將資源按需劃分成不同的資源池,不同資源池之間資源互相隔離。 本文分享自華為雲社區《GaussDB(DWS)資源管理排隊原理與問題定位》,作者: 門前一棵葡萄樹 。 一、記憶體管控原理 GaussDB(DWS)提供 ...
摘要:GaussDB(DWS)提供了資源管理功能,用戶可以根據自身業務情況對資源進行劃分,將資源按需劃分成不同的資源池,不同資源池之間資源互相隔離。
本文分享自華為雲社區《GaussDB(DWS)資源管理排隊原理與問題定位》,作者: 門前一棵葡萄樹 。
一、記憶體管控原理
GaussDB(DWS)提供了資源管理功能,用戶可以根據自身業務情況對資源進行劃分,將資源按需劃分成不同的資源池,不同資源池之間資源互相隔離。再通過用戶關聯資源池的方式將資料庫用戶關聯至不同的資源池,用戶查詢依據“用戶-資源池”的關聯關係將查詢路由至對應資源池執行,以此實現對查詢併發、記憶體及CPU資源的管控。從而實現對不同業務之間的資源限制和隔離,滿足資料庫混合負載需求,保證查詢執行時資源調度的有序可控,防止爛SQL影響整個集群。
1.1 自適應記憶體
傳統記憶體管理場景下,使用work_mem限制運算元可以使用的記憶體上限,通常複雜查詢的執行計劃中包含多個運算元,每個運算元可能需要使用的記憶體並不相同,但是每個運算元可用的記憶體上限均為work_mem,很難找到一個最優的work_mem取值,一方面保證查詢性能滿足預期,一方面還需要保證不會導致記憶體報錯。在查詢併發場景下,靜態記憶體管理的work_mem及併發上限就更難設置了。單查詢運算元數量從0~N不等,設置work_mem後無法實現語句級記憶體資源使用的控制,多併發場景下可能會導致記憶體資源不受控,進而導致OOM。
針對傳統記憶體管理的弊端,GaussDB(DWS)設計實現了記憶體自適應技術:
- 解除對work_mem的依賴,優化器依據統計信息對查詢使用記憶體進行估算;
- 執行器執行SQL過程中,如果使用記憶體超過估算記憶體即觸發下盤;
- 資源管理依據優化器估算的查詢記憶體,對查詢進行調度和管控。
另外,為保證多CN場景下的記憶體可控,設計實現CCN用於查詢的統一調度,以此保證所有CN上運行的查詢使用記憶體之和不會超過記憶體上限,進而導致記憶體不足,引發報錯。CM在第一次集群啟動時,通過集群部署形式,選擇編號最小的CN作為CCN,CCN故障之後,由CM選擇新的CCN進行替換。
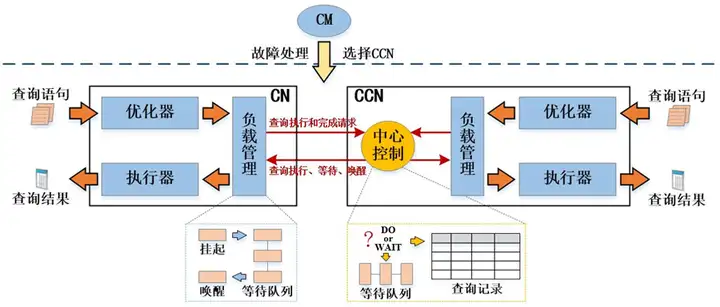
CCN管控與CN管控間差異及優劣:
- CN管控查詢由各CN單獨調度,各CN間互相不感知負載情況,無法準確感知和控制整個集群併發,記憶體管控效果有限,有可能出現記憶體報錯;
- CCN管控查詢由CCN統一調度,結合DN記憶體負反饋機制,CCN可以感知集群整體負載,記憶體管控更加精準,可以消除記憶體不足報錯;
- CCN管控涉及CN與CCN之間的通信,通信延遲可能帶來查詢性能的不穩定;通信延遲與網路環境及查詢併發度有關,大概10ms~ 1s不等;
- CCN管控相對CN管控邏輯更加複雜,除涉及資源池記憶體/併發管控外,還包含CCN全局記憶體管控,在作業管控和喚醒時都需要進行兩層邏輯判斷;
- CCN管控因為所有查詢都需要由CCN統一調度,因此管控時發生所衝突的可能性就更大。
綜上所述,CN管控對查詢性能影響較小,但是記憶體管控效果有限,CCN管控對查詢性能影響可能較大,但是可以實現記憶體精準管控,消除記憶體不足報錯。
為實現更為精細的管控,我們根據查詢預期執行時間和資源消耗,將查詢劃分為執行時間長、資源消耗多的複雜查詢和執行時間短、資源消耗少的簡單查詢。簡單查詢和複雜查詢的劃分與資源消耗密切相關,同時因為查詢執行前就需要劃分簡單/複雜查詢,因此根據估算記憶體(代價)對查詢進行劃分:
- 簡單查詢:估算記憶體小於32MB;
- 複雜查詢:估算記憶體大於等於32MB。
混合負載場景下,雖然簡單查詢本身執行時間短、消耗資源少,但是因為複雜查詢可能會長時間大量占用資源,進而導致資源耗盡,使得簡單查詢不得不在隊列中等待複雜查詢執行完成。為提升執行效率、提高資料庫整體吞吐量, 設計實現“短查詢加速”功能,實現對簡單查詢的單獨管控。
- 開啟短查詢加速後,簡單查詢與複雜查詢分別進行管控。
- 關閉短查詢加速後,簡單查詢與複雜查詢一起進行管控。
雖然單個簡單查詢資源消耗少,但是大量簡單查詢併發運行還是可能占用大量資源,另外對簡單查詢進行CCN管控可能會影響查詢性能,降低吞吐量。因此為降低對查詢的性能影響,同時實現記憶體管控目的,我們僅對複雜查詢進行CCN併發和記憶體管控,簡單查詢由各自CN單獨進行併發控制。
1.2 記憶體管控能力
GaussDB(DWS) 記憶體管控分為三級,分別是:
- 實例級記憶體管控:通過max_process_memory限制CN、DN可以使用的記憶體上限;
- 資源池記憶體管控:通過資源池參數mem_percent限制資源池記憶體使用,結合優化器估算的查詢記憶體,實現資源池之間的記憶體隔離;
- 作業記憶體管控:查詢優化器根據統計信息估算查詢執行時使用記憶體的最大值,查詢以估算記憶體為準向資源管理申請記憶體資源,查詢執行過程中使用記憶體超過估算記憶體即觸發下盤。
基於優化器給出的查詢估算記憶體,資源管理提供了兩種記憶體管控方式:
- 靜態記憶體管控(單CN管控):各CN互不感知,分別進行管控,多CN同時下發作業可能導致記憶體不可控;
- 動態記憶體管控(CCN管控):估算記憶體大於32MB的查詢統一由CCN調度,結合DN記憶體負反饋機制,CCN感知集群整體負載,實現記憶體的精準管控。
特例:
- 靜態記憶體管控關閉(資源池mem_percent=0)或查詢估算記憶體為0情況下,查詢執行過程中使用work_mem控制每個運算元可以使用的記憶體上限,多運算元並行可能導致記憶體不受控;
- 預設資源池支持DN上記憶體擴展,DN記憶體資源充足情況下查詢可以使用更多記憶體,提升查詢執行性能。
通過以上描述,其實不難看出記憶體管控的基礎是優化器的記憶體估算,記憶體估算準確可以實現記憶體的精準管控,記憶體估算不准可能引起一系列的問題:
- 記憶體估算小使用大(DN記憶體擴展),可能導致記憶體報錯;
- 記憶體估算大使用小,可能導致記憶體利用率低,吞吐量上不去;
- 記憶體估算過大,可能導致CCN/CN異常排隊。
基於以上問題,資源管理做了以下功能降低估算不准帶來的影響:
- 資源池增加參數memory_limit,用於配置單查詢估算記憶體上限,預設情況下查詢估算記憶體上限為資源池記憶體*0.4,實際場景下可按需設置該值大小,理論上查詢估算記憶體不應超過該值;
- 記憶體負反饋:正在執行的作業查詢估算記憶體之和超過總記憶體40%,實際使用記憶體低於估算記憶體60%時觸發記憶體負反饋,按照一定比例逐步降低查詢估算記憶體記賬值,以此下發更多查詢,提升記憶體使用率;
查詢估算記憶體兜底機制(820-1230):在查詢估算記憶體超過單查詢估算記憶體上限時,對查詢估算記憶體進行修正,按照單查詢估算記憶體上限進行管控。
二、排隊原理與問題排查
2.1 排隊原理
GaussDB(DWS)可能在以下情況下發生排隊:
- 單CN併發控制:單個CN上查詢併發超過max_active_statements引發排隊;
- 資源池快車道併發控制:資源池上簡單查詢併發超過資源池參數max_dop引發排隊;
- 資源池慢車道併發控制:資源池上複雜查詢併發超過資源池參數active_statements引發排隊;
- 資源池慢車道記憶體管控:資源池上運行的複雜查詢估算記憶體之和超過資源池參數mem_percent配置的資源池記憶體上限引發排隊;
- CCN全局記憶體管控:所有CN上運行的查詢記憶體估算記憶體/使用記憶體超過DN記憶體上限(max_dynamic_memory)引發排隊。
特例:初始用戶及白名單語句不受控。
2.2 常見視圖
GaussDB(DWS)對外提供諸多系統視圖,可以用來輔助資源管理及資源使用相關問題的分析定位,常用視圖及用法說明如下表所示。(☆代表常用程度)
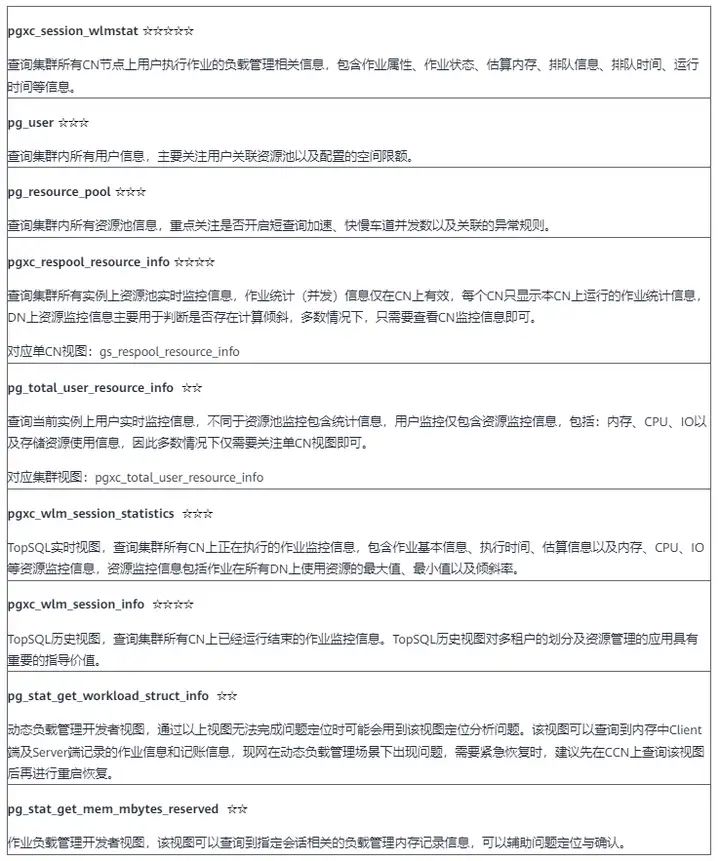
除過上述常用視圖,資源管理問題定位過程需要根據實際場景,結合實例日誌、集群狀態等共同分析定位。
2.3 自定義視圖
為方便迅速定位問題,根據現網實踐經驗對以上常見視圖進行組合,整合了三個問題定位過程中的常用視圖:資源池監控視圖、用戶監控視圖以及作業監控視圖。與上面內置視圖相比,這幾個視圖依據現網定位經驗與分散式資料庫特點,對查詢結果做了針對性優化,同時優化了欄位顯示,用戶更易理解,可以作為常規監控視圖使用。具體視圖定義可參考附件。

2.4 排隊問題排查
出現業務阻塞、性能下降、查詢無響應等類似現網問題時,通過以下方法可以排查是否排隊問題並定位排隊原因,同時根據排隊原因給出相應規避措施。
Step1 確認是否排隊
首先確認是否排隊問題,其次排查排隊原因,確認是否屬於正常排隊:
- 813及以上版本可以查詢資源池監控視圖
SELECT * FROM pgxc_respool_runtime_info ORDER BY 1,2,3;
- 811及以上版本可以作業運行監控視圖
SELECT s.resource_pool AS rpname, s.node_group, count(1) AS session_cnt, SUM(CASE WHEN a.enqueue = 'waiting in global queue' THEN 1 ELSE 0 END) AS global_wait, SUM(CASE WHEN s.lane= 'fast' AND a.state = 'active' AND (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') THEN 1 ELSE 0 END) AS fast_run, SUM(CASE WHEN s.lane= 'fast' AND a.enqueue = 'waiting in respool queue' THEN 1 ELSE 0 END) AS fast_wait, SUM(CASE WHEN s.lane= 'slow' AND a.state = 'active' AND (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') THEN 1 ELSE 0 END) AS slow_run, SUM(CASE WHEN s.lane= 'slow' AND (a.enqueue = 'waiting in ccn queue' OR a.enqueue = 'waiting in respool queue') THEN 1 ELSE 0 END) AS slow_wait, SUM(CASE WHEN (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') AND a.state = 'active' THEN statement_mem ELSE 0 END) AS est_mem FROM pgxc_session_wlmstat s,pgxc_stat_activity a WHERE s.threadid=a.pid(+) AND s.attribute != 'Internal' GROUP BY 1,2
- 800版本查詢作業運行監控視圖
SELECT s.resource_pool AS rpname, s.node_group, count(1) AS session_cnt, SUM(CASE WHEN a.enqueue = 'waiting in global queue' THEN 1 ELSE 0 END) AS global_wait, SUM(CASE WHEN s.attribute= 'Simple' AND a.state = 'active' AND (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') THEN 1 ELSE 0 END) AS fast_run, SUM(CASE WHEN s.attribute= 'Simple' AND a.enqueue = 'waiting in respool queue' THEN 1 ELSE 0 END) AS fast_wait, SUM(CASE WHEN s.attribute= 'Complicated' AND a.state = 'active' AND (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') THEN 1 ELSE 0 END) AS slow_run, SUM(CASE WHEN s.attribute= 'Complicated' AND (a.enqueue = 'waiting in ccn queue' OR a.enqueue = 'waiting in respool queue') THEN 1 ELSE 0 END) AS slow_wait, SUM(CASE WHEN (a.enqueue IS NULL OR a.enqueue = 'no waiting queue') AND a.state = 'active' THEN statement_mem ELSE 0 END) AS est_mem FROM pgxc_session_wlmstat s,pgxc_stat_activity a WHERE s.threadid=a.pid(+) AND s.attribute != 'Internal' GROUP BY 1,2;
某些老版本不存在pgxc_session_wlmstat視圖,可以參考附件創建類似函數/視圖。
- 直接查詢自定義視圖
通過查詢自定義視圖可以獲取到各資源池快慢車道作業運行信息以及作業排隊信息,據此可以直接判斷是否排隊問題。
Step2 排查排隊原因
常見排隊原因及解決措施
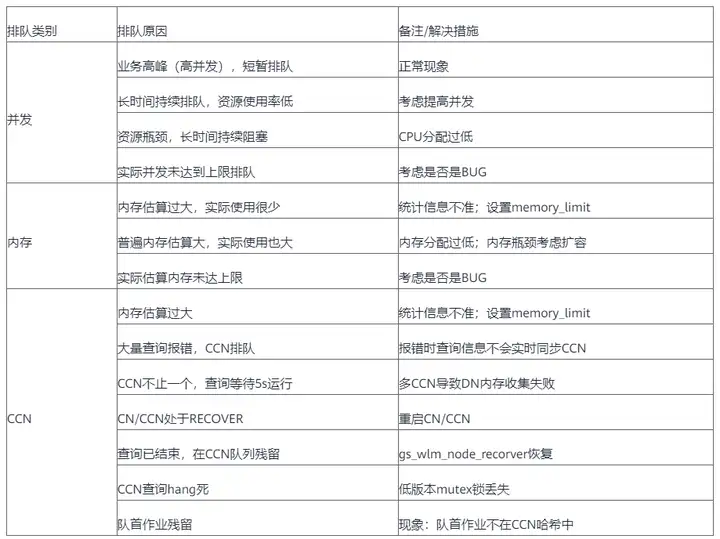
1.全局併發排隊
- 單CN實際運行作業數≥全局併發上限,則全局併發排隊正常;
- 單CN實際運行作業數長時間小於全局併發上限,則可能存在計數泄露。
2.快車道排隊
- 快車道實際運行作業數≥快車道併發上限,則快車道併發排隊正常;
- 快車道實際運行作業數長時間小於快車道併發上限,則可能存在計數泄露。
3.靜態慢車道排隊
- 慢車道實際運行作業數≥慢車道併發上限,則慢車道併發排隊正常;
- 慢車道實際運行作業累計估算記憶體≥慢車道記憶體上限,則慢車道記憶體占用達到上限導致排隊,關註是否有查詢估算記憶體過大;
- 如果慢車道併發和記憶體占用長時間達不到上限,則可能存在計數泄露。
4.動態CCN排隊
如果查詢在CCN排隊,可使用附件中自定義資源池監控視圖和作業監控視圖確認排隊原因,或查詢CCN開發者視圖確認排隊原因(不推薦):
SELECT * FROM pg_stat_get_workload_struct_info();
CCN上可能的排隊原因:
- CCN全局可用記憶體不足導致排隊,此時需特別關註是否有查詢估算記憶體過大;
- 資源池實際運行作業數≥慢車道車道併發上限,資源池併發上限,正常排隊;
- 資源池實際運行作業累計估算記憶體≥慢車道記憶體上限,則慢車道記憶體占用達到上限導致排隊,此時需特別關註是否有查詢估算記憶體過大;
- 資源池實際運行作業數或占用記憶體與記賬值不符,則可能存在計數泄露BUG;
- 隊首作業在CCN哈希中不存在,說明隊首作業殘留導致查詢不能正常下發;
- CN/CCN處於recover狀態或收集DN記憶體信息失敗(多CCN)導致所有查詢等待5s下發,現象為所有查詢排隊時間均為5~6s。
附件:自定義監控視圖.rar18.11KB

