
查找 假設有如下這樣一個有序鏈表: 想要查找 24、43、59,按照順序遍歷,分別需要比較的次數為 2、4、6 目前查找的時間複雜度是 O(N),如何提高查找效率? 很容易想到二分查找,將查找的時間複雜度降到 O(LogN) 具體來說,我們把鏈表中的一些節點提取出來,作為索引,類似於二叉搜索樹,得到 ...
查找
假設有如下這樣一個有序鏈表:

想要查找 24、43、59,按照順序遍歷,分別需要比較的次數為 2、4、6
目前查找的時間複雜度是 O(N),如何提高查找效率?
很容易想到二分查找,將查找的時間複雜度降到 O(LogN)
具體來說,我們把鏈表中的一些節點提取出來,作為索引,類似於二叉搜索樹,得到如下結構:
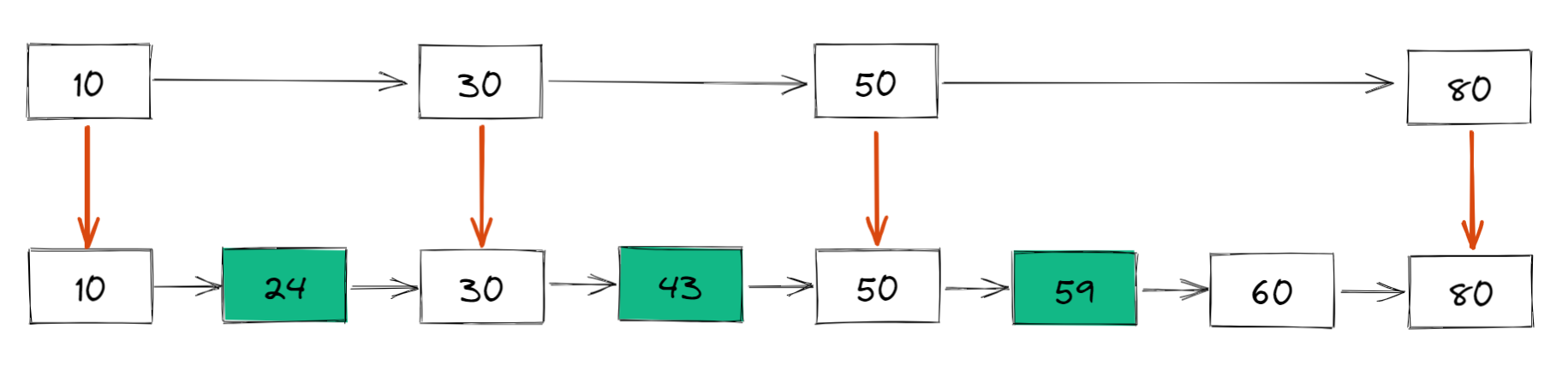
這裡我們把 10、30、50、80 提取出來作為一級索引,這樣搜索的時候就可以使用二分查找來減少比較次數了。
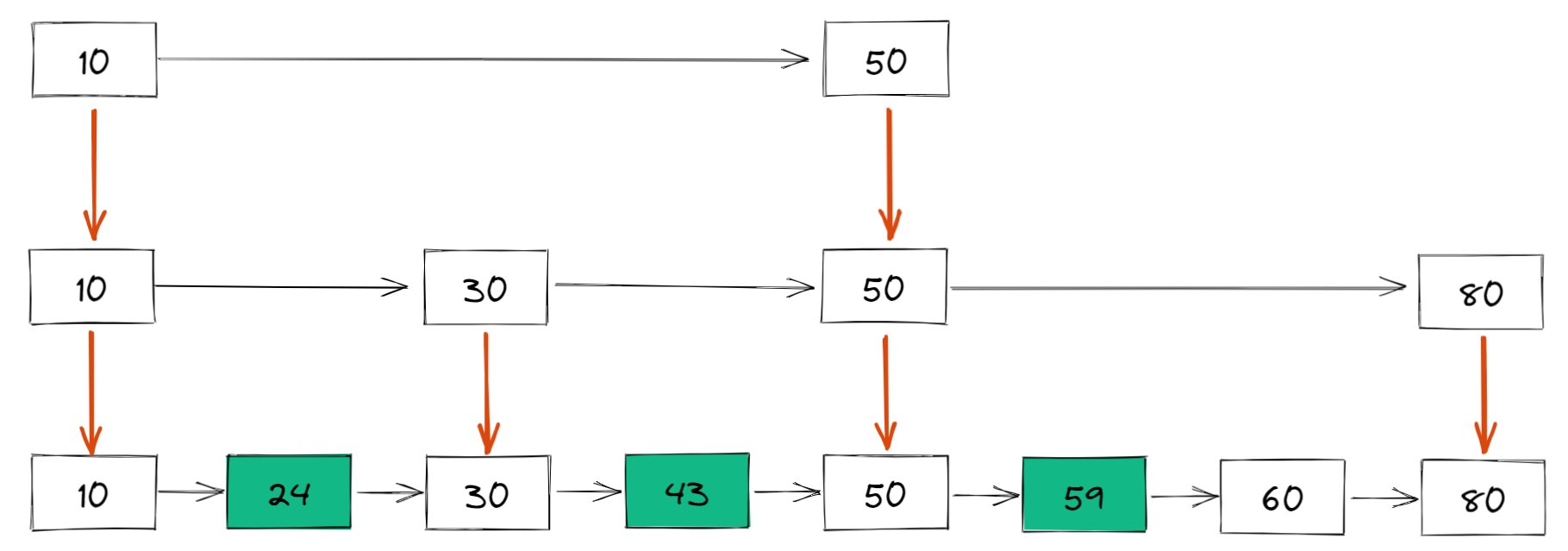
我們還可以再從一級索引提取一些元素出來,作為二級索引,變成如下結構:
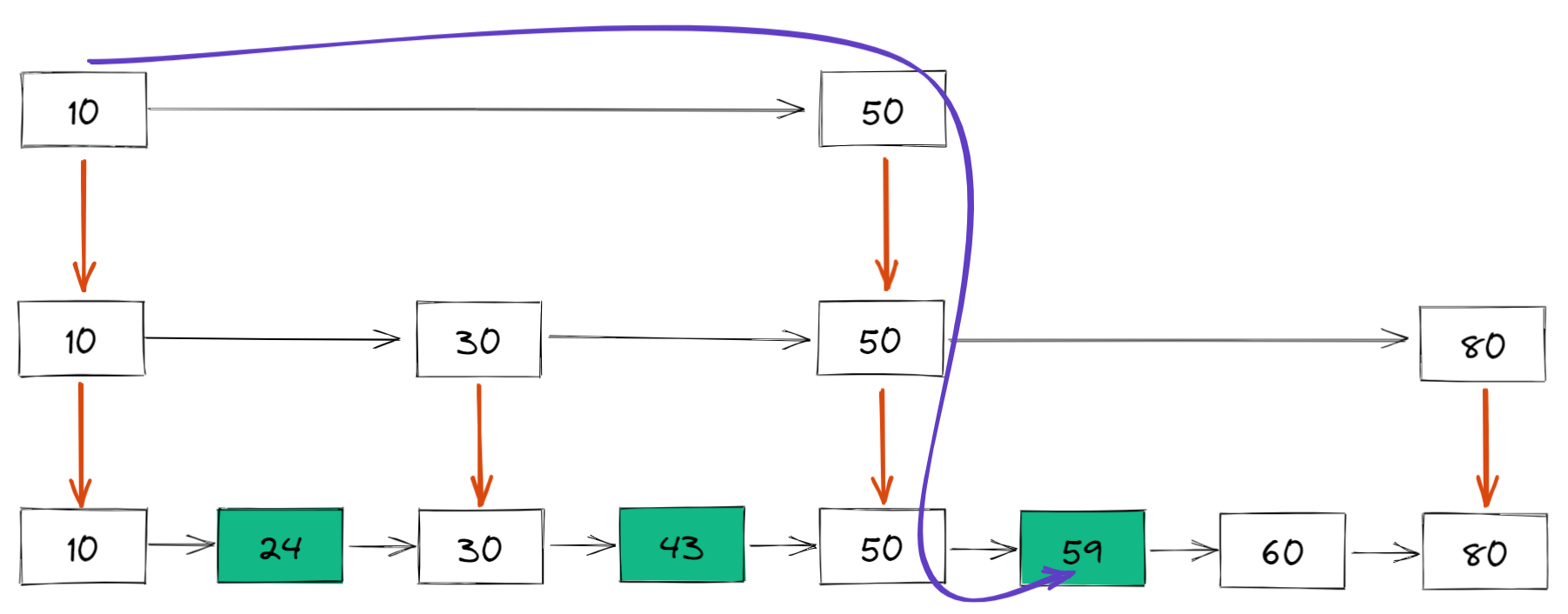
比如如果想要查找 59,那麼搜索路徑就是下麵這樣的:
回顧下鏈表的定義:
class ListNode {
private int val;
private ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
我們在每一個節點的基礎上添加一個 down 指針,用來指向下一層的節點
class Node {
private int val;
private ListNode next;
private ListNode down;
public ListNode(int val) {
this.val = val;
this.next = null;
this.down = null;
}
}
這樣,一個最簡單的跳錶節點就定義出來了。
我們這裡說的只是最簡單的實現,像比如 Redis 的跳錶實現和我們說的還是有所不同的,當然了,思想都是一致的
所以跳錶是什麼?簡單來說,跳錶就是支持二分查找的有序鏈表
具體的搜索演算法如下:
/* 如果存在 x, 返回 x 所在的節點, 否則返回 x 的後繼節點 */
private Node find(x) {
p = top;
while (true) {
while (p.next.val < x){
p = p.next;
}
if (p.down == null){
return p.next;
}
p = p.down;
}
return null;
}
插入
關於插入,大家可能很容易想到往最下麵一層的有序鏈表中添加數據,但是索引該咋辦?索引要不要更新呢?
如果不更新索引,就可能出現兩個索引節點之間數據非常多的情況,極端情況下跳錶就會退化為單鏈表,從而使得查找效率從 O(LogN) 退化為 O(N)。
所以,我們在插入數據的時候,索引節點也需要相應的改變來避免查找效率的退化
比較容易想到的做法就是完全重建索引,我們每次插入數據後,都把這個跳錶的索引刪掉全部重建。因為索引的空間複雜度是 O(N),即:索引節點的個數是 O(N) 級別,每次完全重新建一個 O(N) 級別的索引,時間複雜度也是 O(N) 。造成的後果是:為了維護索引,導致每次插入數據的時間複雜度變成了 O(N)。
那有沒有其他效率比較高的方式來維護索引呢?
最理想的索引就是在原始鏈表中每隔一個元素抽取一個元素做為一級索引。換種說法,我們在原始鏈表中【隨機】的選 n/2 個元素做為一級索引是不是也能通過索引提高查找的效率呢?
當然可以,因為一般隨機選的元素相對來說都是比較均勻的。如下圖所示,隨機選擇了 n/2 個元素做為一級索引,雖然不是每隔一個元素抽取一個,但是對於查找效率來講,影響不大,比如我們想找元素 16,仍然可以通過一級索引,使得遍歷路徑較少了將近一半。

當然了,如果抽取的一級索引的元素恰好是前一半的元素 1、3、4、5、7、8,那麼查找效率確實沒有提升,但是這樣的概率太小了。所以我們可以認為:當原始鏈表中元素數量足夠大,且抽取足夠隨機的話,我們得到的索引是均勻的。所以,我們可以維護一個這樣的索引:隨機選 n/2 個元素做為一級索引、隨機選 n/4 個元素做為二級索引、隨機選 n/8 個元素做為三級索引,依次類推,一直到最頂層索引。這裡每層索引的元素個數已經確定,且每層索引元素選取的足夠隨機,所以可以通過索引來提升跳錶的查找效率。
那代碼具體該如何實現,使得在每次新插入元素的時候,儘量讓該元素有 1/2 的幾率建立一級索引、1/4 的幾率建立二級索引、1/8 的幾率建立三級索引....呢?
其實很簡單啦,搞一個概率演算法就行了(具體是怎麼個概率法這裡就不詳細解釋了),當每次有數據要插入時,先通過概率演算法告訴我們這個元素需要插入到幾級索引中,然後開始維護索引並把數據插入到原始鏈表中。
如下所示,插入新元素 12,假設概率演算法返回的結果是 4,表示新元素需要插入到 4 級索引中,同時,我們還需要建立 3 級索引、2 級索引和 1 級索引(也就是原始有序鏈表)
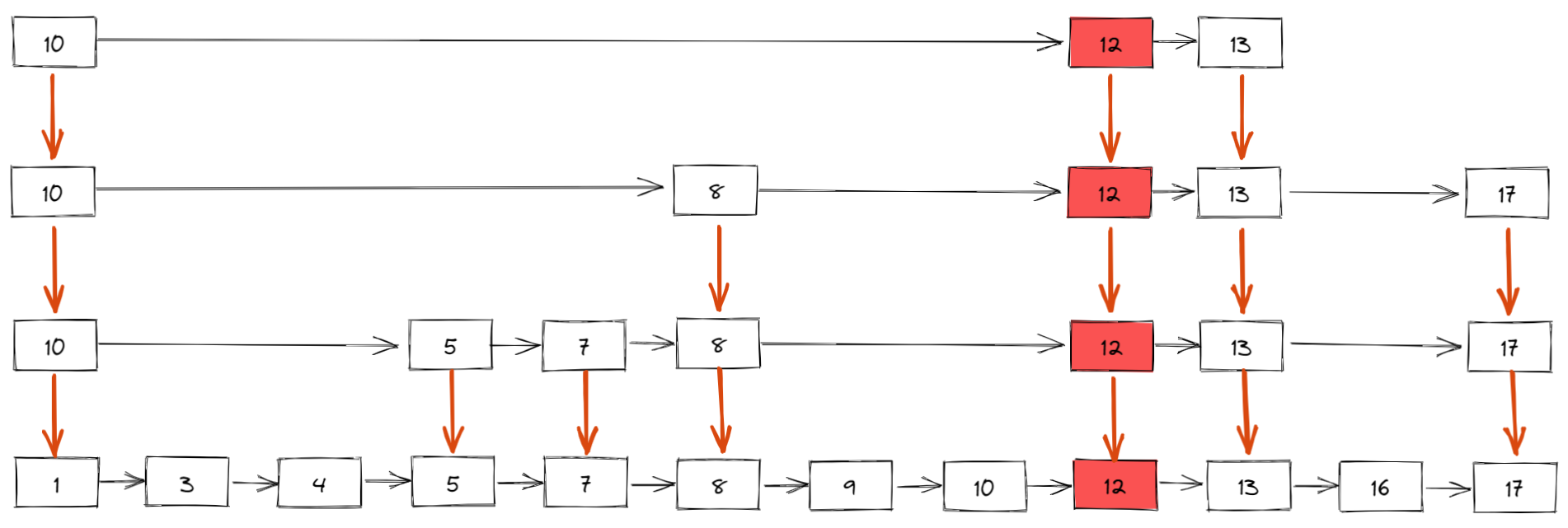
那插入數據時維護索引的時間複雜度是多少呢?
跳錶中,每一層索引都是一個有序的單鏈表,元素插入到單鏈表的時間複雜度為 O(1),我們索引的高度最多為 LogN,當插入一個元素 x 時,最壞的情況就是元素 x 需要插入到每層索引中,所以插入數據的最壞時間複雜度是 O(LogN),最好的時間複雜度是 O(1)。
刪除
跳錶刪除數據時,要把索引中對應節點也要刪掉。如下圖所示,如果要刪除元素 8,需要把原始鏈表中的 8 和第 2、3 級索引的 8 都刪除掉。
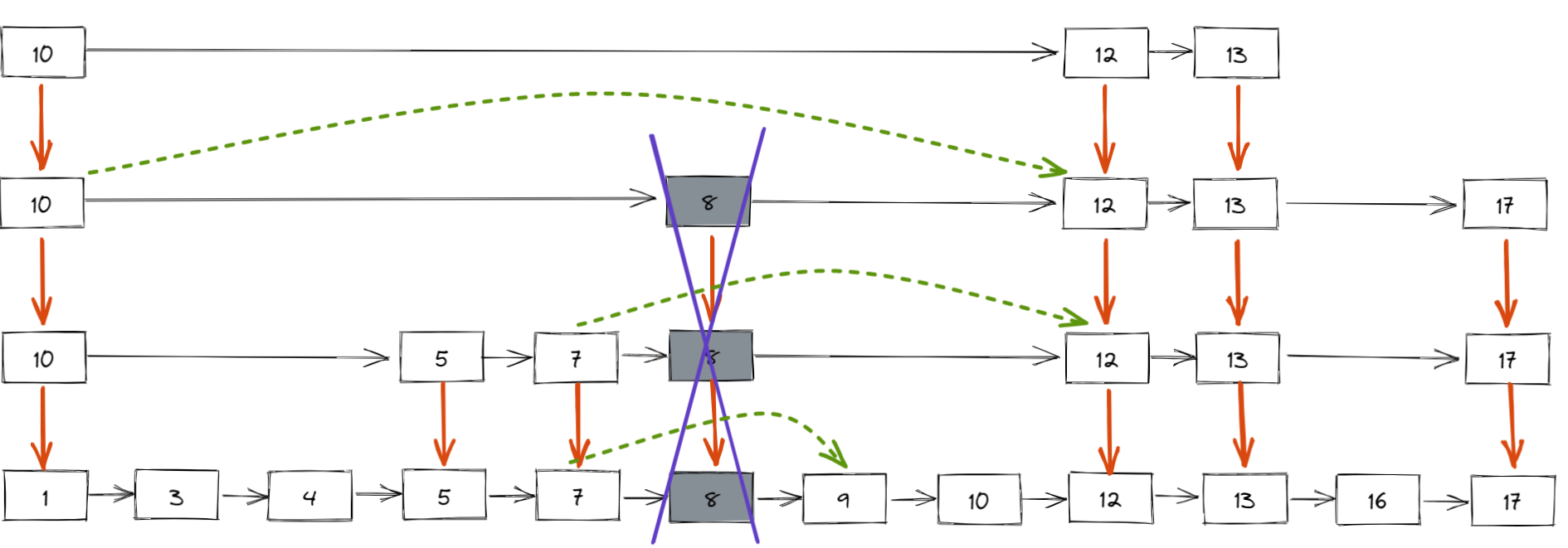
刪除元素的過程跟查找元素的過程類似,只不過在查找的路徑上如果發現了要刪除的元素 x,則執行刪除操作。
跳錶中,每一層索引都是一個有序的單鏈表,單鏈表刪除元素的時間複雜度為 O(1),最多需要刪除 LogN 個元素(索引層數為 LogN),所以刪除元素的總時間包 = 查找元素的時間 + 刪除 LogN 個元素的時間 = O(LogN ) + O(LogN ) = 2O(LogN ),忽略常數部分,刪除元素的時間複雜度為 O(LogN)。
小伙伴們大家好呀,本文首發於公眾號@飛天小牛肉,阿裡雲 & InfoQ 簽約作者,分享大廠面試原創高質量題解、原創技術幹活和成長經驗~)


