
ChunJun(原FlinkX)是一個基於 Flink 提供易用、穩定、高效的批流統一的數據集成工具。2018年4月,秉承著開源共用的理念,數棧技術團隊在github上開源了FlinkX,承蒙各位開發者的合作共建,FlinkX得到了快速發展。 兩年後的2022年4月,技術團隊決定對FlinkX進行整 ...
ChunJun(原FlinkX)是一個基於 Flink 提供易用、穩定、高效的批流統一的數據集成工具。2018年4月,秉承著開源共用的理念,數棧技術團隊在github上開源了FlinkX,承蒙各位開發者的合作共建,FlinkX得到了快速發展。
兩年後的2022年4月,技術團隊決定對FlinkX進行整體升級,並更名為ChunJun,希望繼續和各位優秀開發者合作,進一步推動數據集成/同步的技術發展。
因該文創作於於FlinkX更名為ChunJun之前,因此文中仍用FlinkX來進行分享,重要的事情說三遍:
FlinkX即是ChunJun
FlinkX即是ChunJun
FlinkX即是ChunJun
進入正文分享⬇️⬇️⬇️

分享嘉賓:馮江濤 中國移動雲能力中心
編輯整理:陳凱翔 亞廈股份
出品平臺:DataFunTalk
導讀:
隨著本地數據遷移上雲、雲上數據交換等多源異構數據源數據同步需求日益增多,傳統通過編寫腳本進行數據同步的方式投入高、效率低、運維管理困難;在公司內部,多款移動雲資料庫和大數據類產品根據客戶需求迫切希望集成數據同步能力,但缺少易用的框架,從0開始研發投入研發成本高。
針對上述問題,基於FlinkX多源異構數據同步框架,實現了用戶自建和移動雲上消息中間件、資料庫、對象存儲等多種異構數據源雙向讀寫,基於社區版實現了On k8s改造,需簡單配置即可滿足用戶數據快速上雲及雲上數據高效交換需求,降低開發運維投入,該成果已在移動雲至少3款產品中應用。
本文的主要內容包括:
FlinkX簡介
功能及原理
雲上入湖改造
展望
一、FlinkX簡介
1. 背景介紹

現在市面上有很多種資料庫產品,包括傳統的RDB和大數據相關的NoSQL,一般企業稍微大一點規模都會同時有各種各樣的資料庫。為什麼會有這麼多數據源?是因為不同的數據源適應不同的場景,但這麼多數據源會給開髮帶來困難。
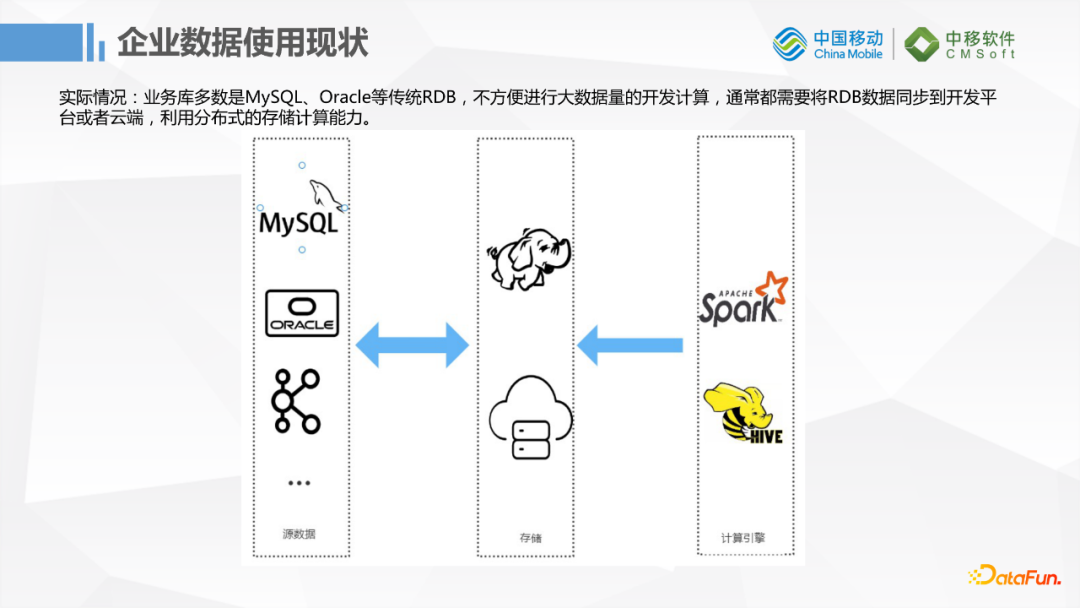
傳統的企業業務庫多數還是MySQL,Oracle這種傳統RDB,如果進行簡單的增刪改查是沒有問題的,但遇到大批量的數據計算這些RDB就無法支持了,所以就需要大數據的存儲。但是業務數據又在傳統資料庫中,所以傳統資料庫和大數據之間需要一個同步遷移的工具。
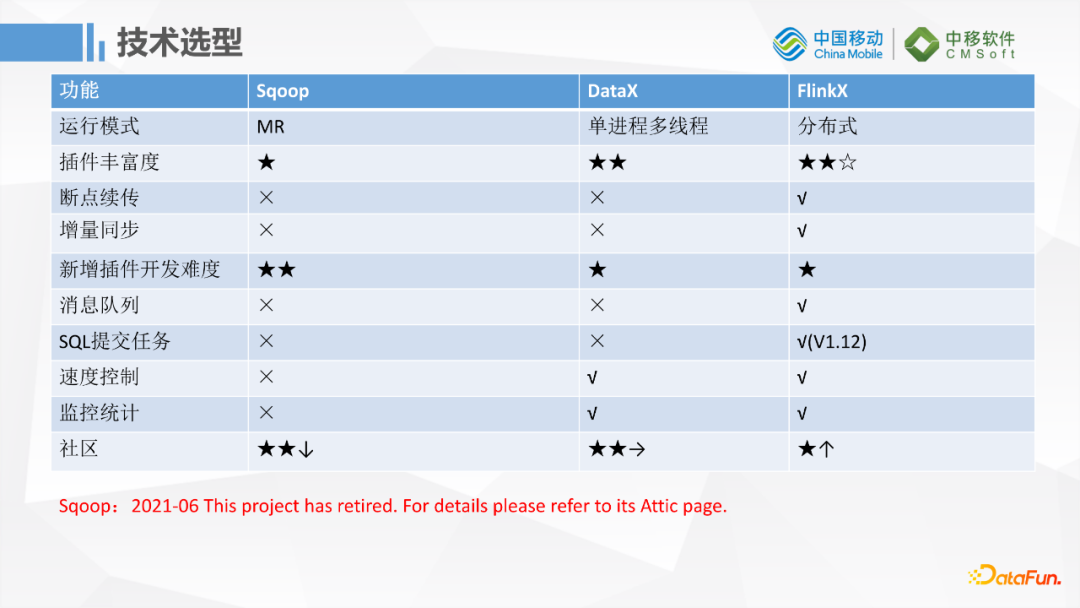
FlinkX這個工具相對比較小眾,是袋鼠雲開源的項目。更熟悉的工具可能是Sqoop和阿裡開源的DataX,上圖是一個簡單的對比,我們開始選型的時候也做過調研,包括它的運行模式,插件豐富度,是否支持斷點續傳等功能,特別是我們是做數據湖的,需要對數據湖插件的支持,還有考慮新增插件開發的難度。綜合調研下來,我們最終選擇了FlinkX。多數傳統的企業使用Sqoop比較多,因為他們只會在RDB和大數據之間做遷移,但是Sqoop已經在今年6月份被移除了Apache 頂級項目,上一次更新是在2019年1月份,已經2年多沒有任何的開發更新了,所以這個項目已經沒有新功能開發,這也不滿足我們的需求。之前我們也在移動雲上基於Sqoop做了一個插件,但是發現Sqoop在開發、運行上不太符合我們的場景。最終我們選定了FlinkX這個工具。
2. Flink簡介
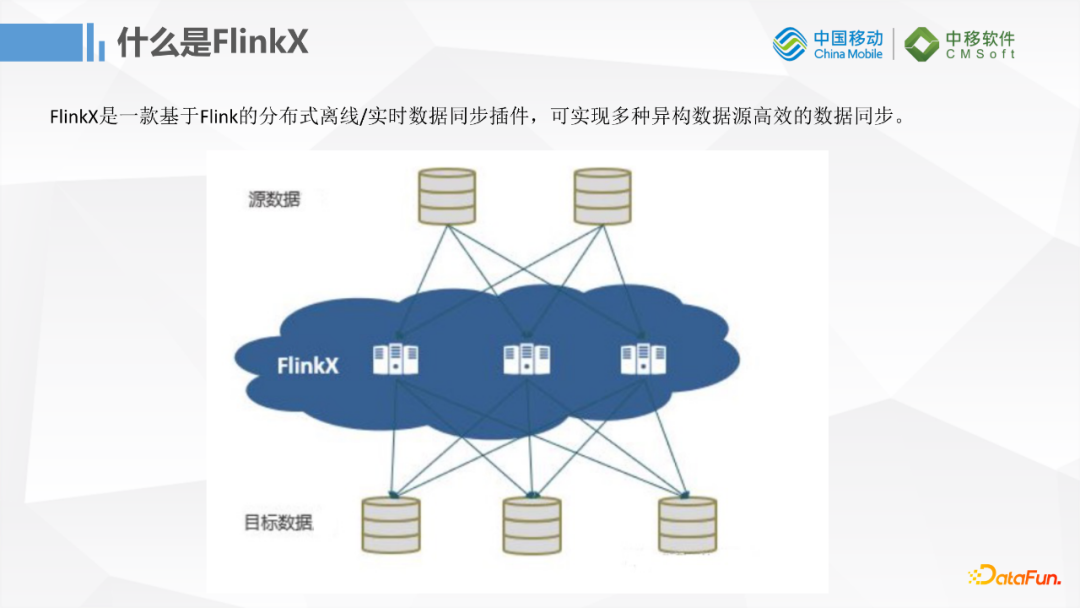
什麼是FlinkX呢?FlinkX是一個基於Flink流計算框架實現的數據同步插件,它可以實現多種數據源高效的數據同步,基本功能和DataX和Sqoop差不多。
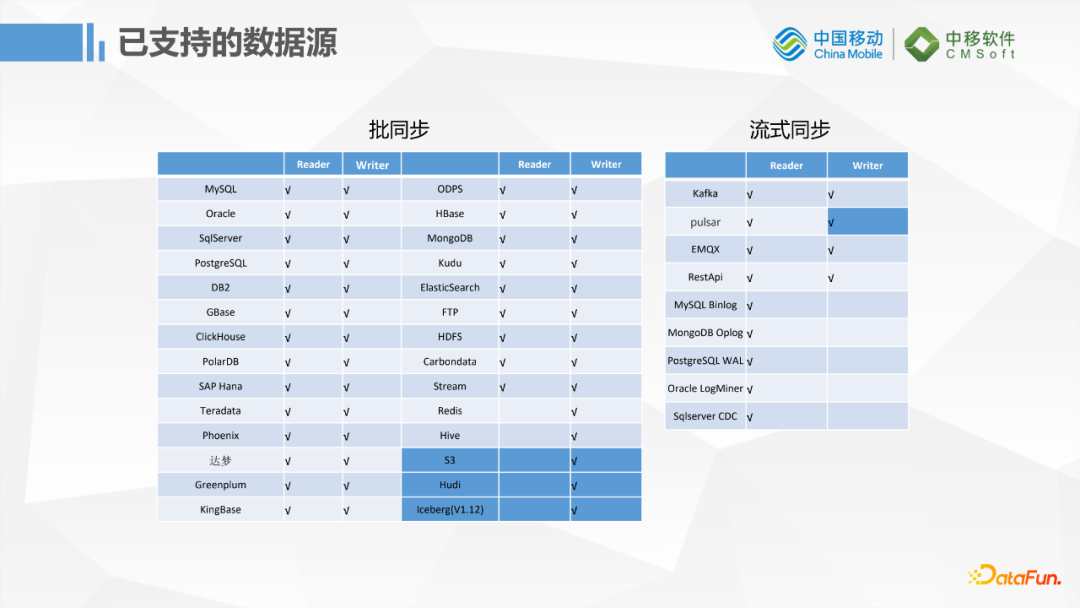
批同步方面支持的數據源跟DataX相當,但是在流式同步方面比較有優勢,因為它是基於Flink開發的,所以在流式數據方面支持的數據源比較全,比如Kafka,Pulsar這種消息隊列,還有資料庫的Binlog這種增量更新的數據同步,功能非常強大。基於開源社區1.11版本我們自己又開發了一些插件:對S3的寫入、Hudi數據湖的寫入、對Pulsar的寫入。Pulsar部門已經開源提交到社區了,S3和Hudi暫時還沒有提交。
二、功能及原理
接下來看一下FlinkX的功能和簡單的原理。
1. 斷點續傳
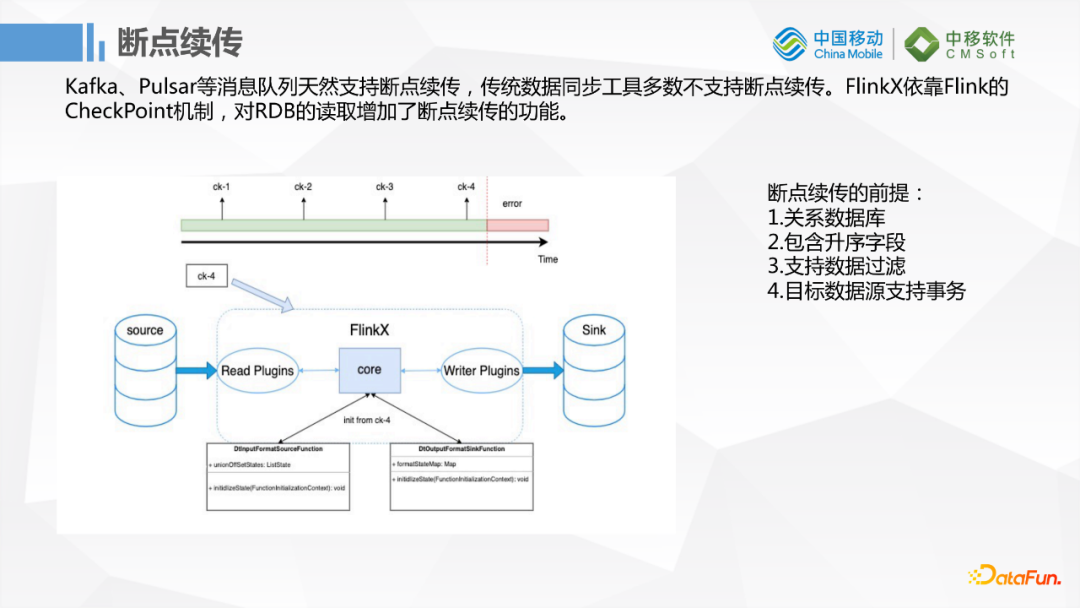
首先一個很棒的功能是斷點續傳,當然這個斷點續傳不是針對消息隊列來說的,因為消息隊列天然支持斷點續傳。FlinkX依賴Flink的checkpoint機制,對RDB擴展了斷點續傳的功能。但是它有一個前提,首先是關係型資料庫需要包含升序的欄位,然後是需要支持數據的過濾,最後是需要支持事務。比如使用MySQL時如果需要斷點續傳,配置了這個功能後它會根據欄位做一個取模,然後在數據搬運的過程中當前節點的數據會在checkpoint裡面保存,當需要重新運行任務的時候它會取上一次失敗的節點開始的那個點,因為它還需要根據保存失敗的id的數據做一下過濾,最後再從那個節點重新開始運行任務,這樣數據量比較大的時候會稍微節約一點時間。
2. 指標監控
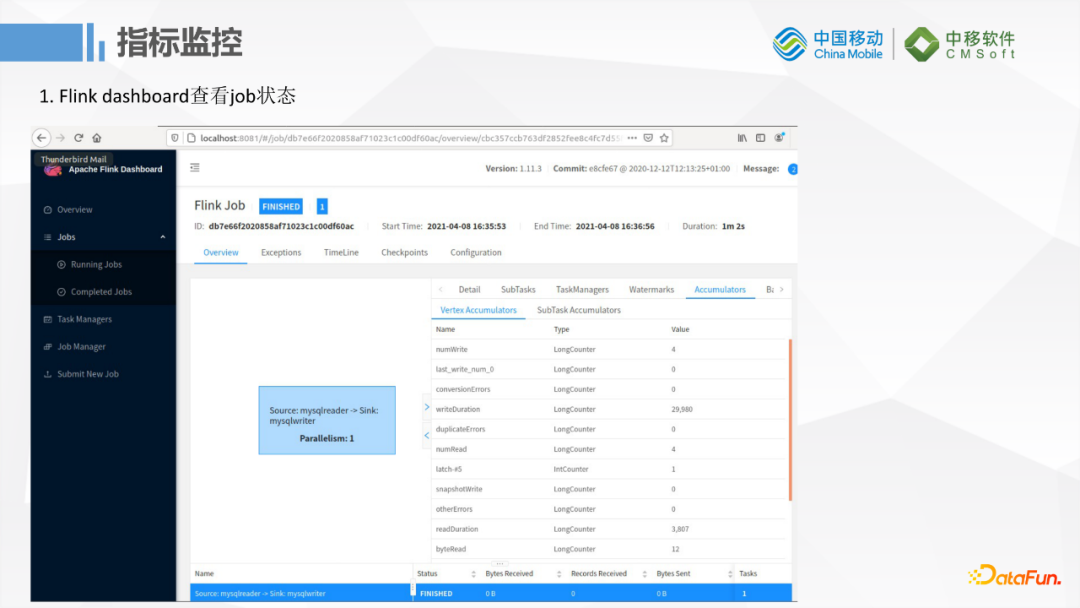
監控方面它會依賴Flink本身的監控功能,Flink內部有一些Accumulators和metric統計指標,如果把它運行在Flink上的話就可以通過Flink的DashBoard來查看Job的狀態。
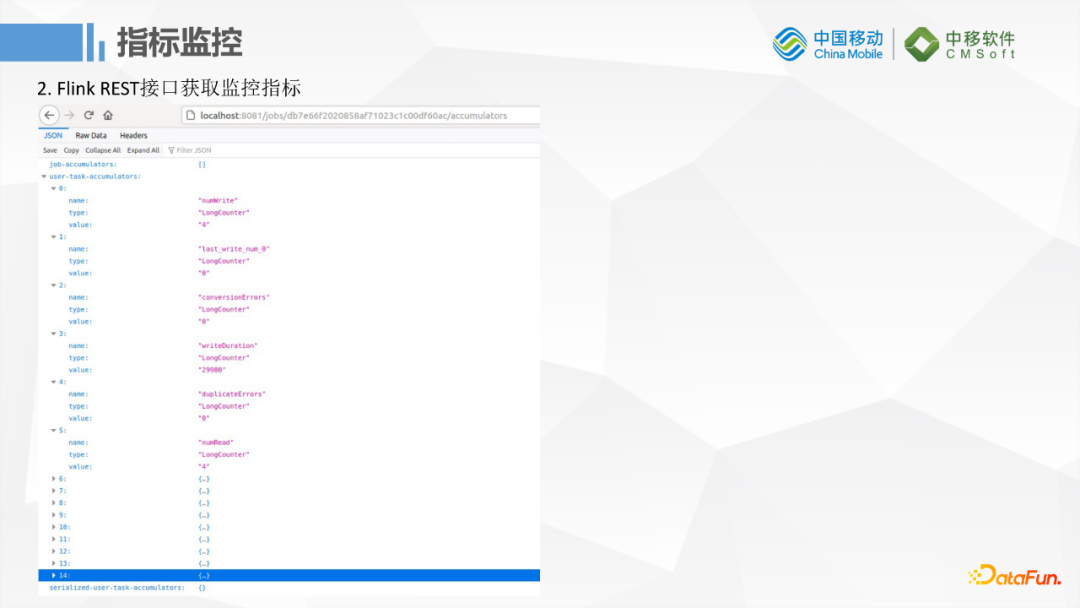
或者是把一些指標數據收集到Prometheus裡面,例如基本的條數,統計的數據量和錯誤的數據量都可以通過Prometheus收集之後再通過Grafana這樣的一些工具做展示。目前線上的這個功能還在開發中。
3. 錯誤統計和數據限制
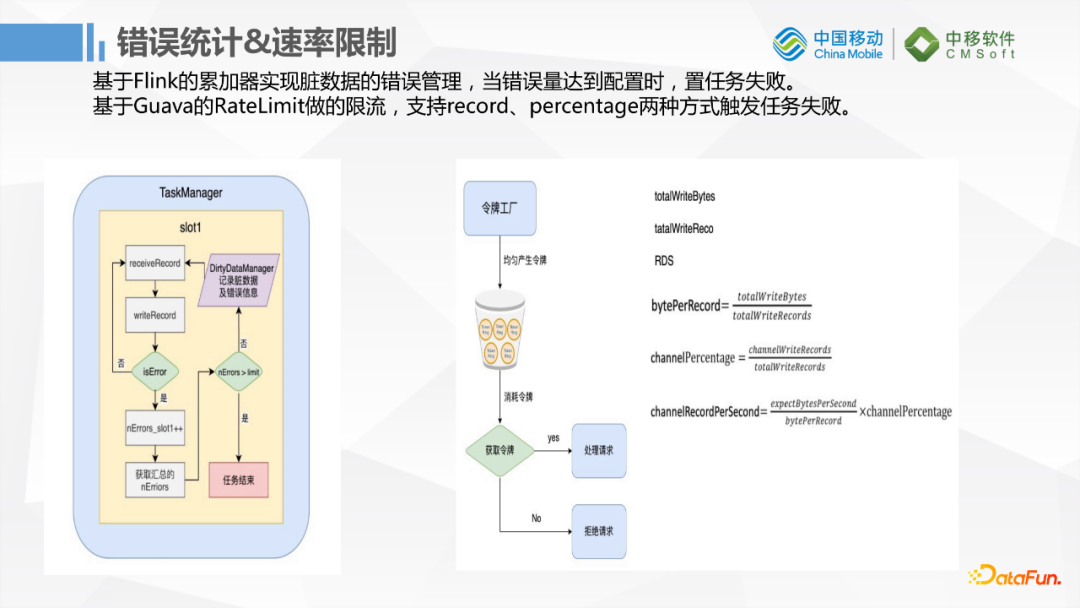
它還有一個比較好的功能是速率限制。當我們讀取數據寫入的時候,很多用戶首先擔心的問題是它會影響到生產庫,因為多數企業的庫可能沒有主從策略,生產庫是單實例運行的。如果這種搬運數據的任務影響到生產庫的話用戶基本上是不能接受的。所以做速率限制的功能對傳統用戶就非常友好。它的速率限制是基於Guava的RateLimit,根據令牌工廠生產令牌的方式做的速率限制,跟另外的漏斗演算法稍微有一點差別。缺點是峰值還是會很高,因為它保證的是平均速率限制在某一個範圍之內。
4. 插件式開發
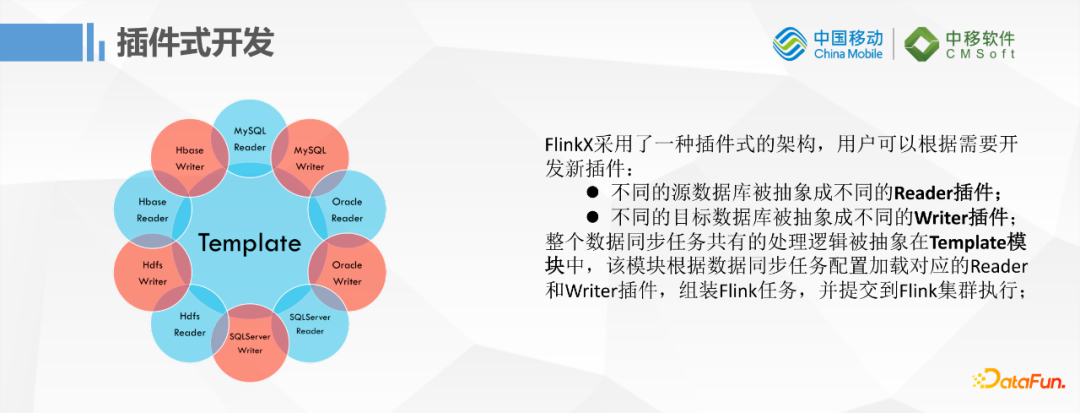
FlinkX的插件式開發模式,與Sqoop和DataX類似,不同的數據源都抽象成一個Reader插件和一個Writer插件,然後整個數據同步的任務和公有的邏輯就被抽象在一個統一的模塊中。一個模塊再根據同步任務的配置載入相應的Reader,Writer最後組裝成Flink任務,並提交到Flink集群去執行。

我們可以簡單看一下任務配置,都是基於JSON的方式配置基礎的Reader,Writer,然後是一些綜合的錯誤條數限制和速率限制,這邊的代碼就會根據配置文件通過Reader生成一個Flink Source,再通過Writer生成Sink,熟悉Flink代碼的小伙伴對這塊應該比較熟悉,其實就是Flink從Source端讀數據然後往Sink端寫數據,相對來說比較簡單。
三、雲上入湖改造
雲上入湖這裡我們做了一些改造。
1. K8s

首先是K8S的改造,因為社區的1.11版本支持的是Local,Standalone,YARN Session,YARN Perjob的模式,對雲原生方式的開發不是太友好。並且Flink原生的1.12版本已經支持K8S調度運行了,所以我們把基於FlinkX的1.11版本Flink升級到了1.12,讓它原生就可以支持K8S運行,這樣的話對我們任務的彈性擴縮容就更加友好,對入湖的任務資源隔離也比較友好,相互之間沒有影響。這裡也是基於Flink 1.12把裡面的ApplicationClusterDeployer這部分代碼做了一些簡單的改造,來適配我們的一些系統。基本上是把K8S的一些配置組裝一下,然後把FlinkX的一些Jar包的路徑寫進去,最後提交任務到我們的K8S集群。
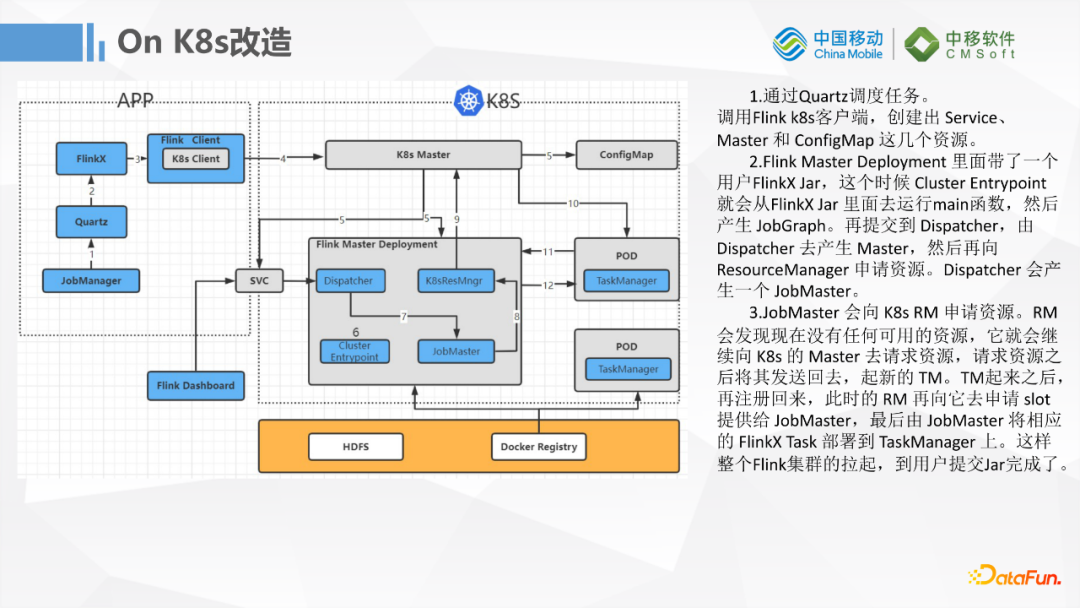
我們的JobManager會通過Quartz來做FlinkX任務的調度,然後通過Flink的客戶端調用K8S的客戶端,最終把任務提交到K8S上去執行。
2. Hudi寫入
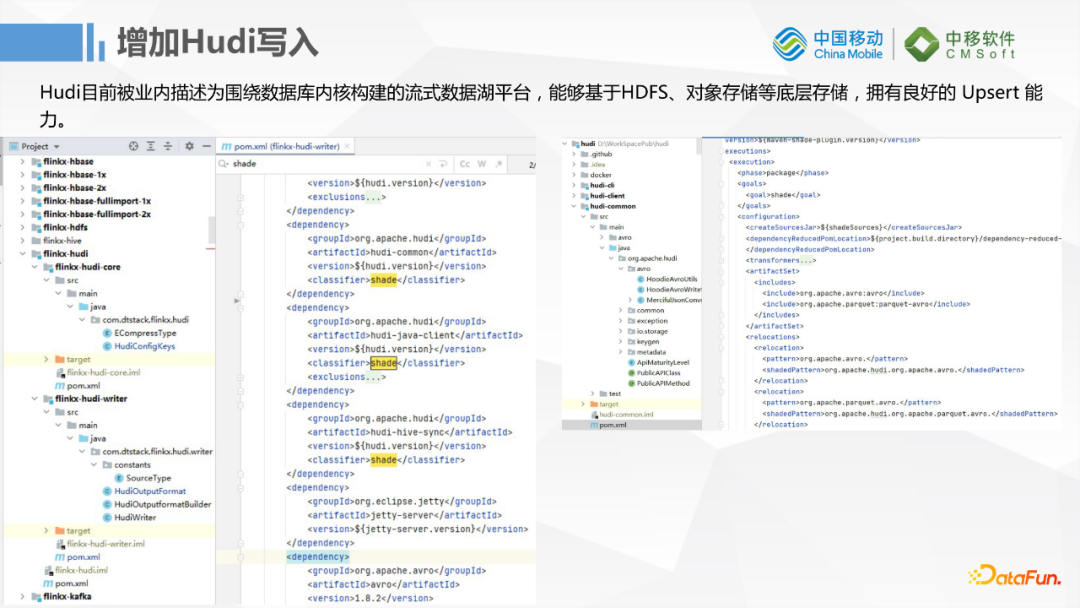
我們擴展了一個Hudi的插件,因為FlinkX裡面插件非常多,我們這邊會考慮到寫HBase和寫Hive之類的情況,開發過程中遇到了很多Jar包衝突的問題,所以我們給Hudi社區版0.09版本打了非常多的shade Jar,保證我們的線上運行沒有衝突,主要是avro的版本依賴問題。我們這邊HBase和Hive依賴的avro版本跟Hudi的版本會不一致,版本相容性之間有一些問題。
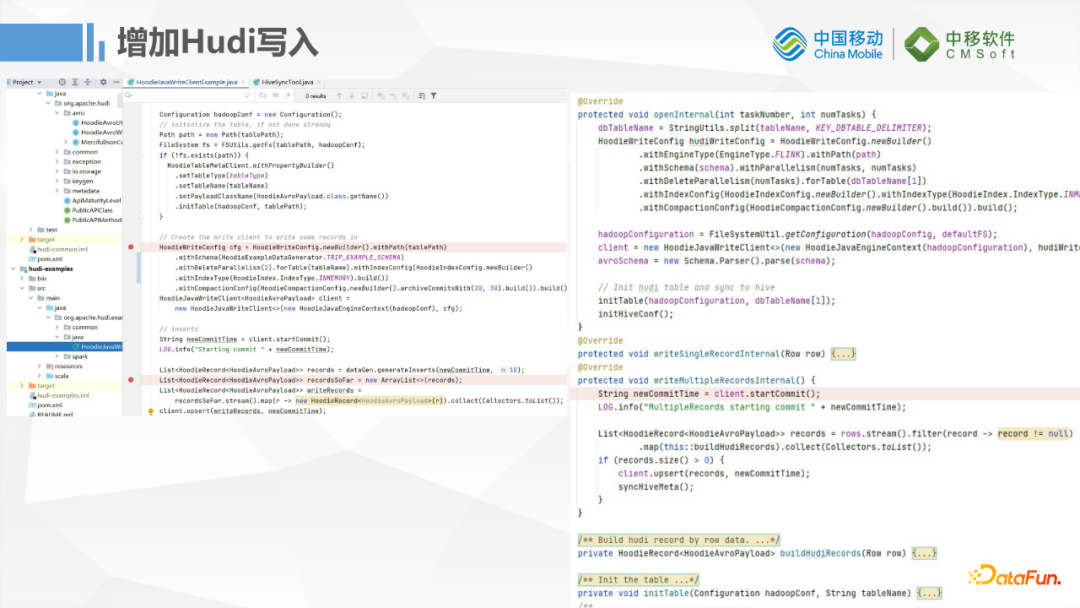
這裡看一下Hudi插件預覽的樣子,參考了Hudi源碼裡面加了Client的Example,也就是先載入Hudi配置,初始化表和Hive的配置,最後通過Kafka做實時數據寫入。目前只提供Upsert的支持,後期考慮MySQL Binlog支持的話會增加Delete功能的支持。
3. 日誌

還有一個改造可能不屬於FlinkX,就是我們的日誌功能,基於K8S Fluentd的一個小工具,EFK這套系統去收集日誌。整個過程對我們的業務是沒有入侵,沒有感知的,最終我們的日誌解析收集到ES中。Fluentd跟K8S結合的比較好的地方就是它可以採集到NameSpace,PodName, NodeSelector等數據,為後面查詢錯誤日誌提供了方便。

上圖就是使用Fluentd收集到的一些Pod的日誌,左側這邊看到有很多K8S的元數據信息,例如ContainerName,鏡像,NodeSelector,PodId等等這些數據。當然這個Kibana是我們留給後端開發用來排錯的,目前給前端用戶展示的還是把原始日誌數據做了彙總之後,通過頁面對應到任務上去查看。
四、展望
最後一部分是我們對於FlinkX的一些展望,先來看一下FlinkX V1.12的一些新特性:
與FlinkStreamSQL融合;
增加了transformer運算元,支持SQL的轉換;
插件向Flink社區看齊,不再區分Reader、Writer,統一命名成Connector,遵循Flink社區的規範,這樣統一以後FlinkX就可以和社區保持相容。理論上在使用FlinkX時可以使用Flink的原生Connector。Flink也可以調用FlinkX的Connector,這樣的話FlinkX就可以做成插件放到Flink的集群裡面,後面對於做湖倉一體或者Server開發就會非常的方便。
數據結構優化
支持二階段提交、數據湖Iceberg和提交kubernetes
對於數據入湖來說,目前的FlinkX有一個缺點,就是只支持結構化數據的傳輸,還不能原生支持二進位文件的同步。如果數據要入湖,會有很多媒體文件,Excel、Word、圖片、視頻等等,這一塊後期可能會自己去開發一些插件支持。
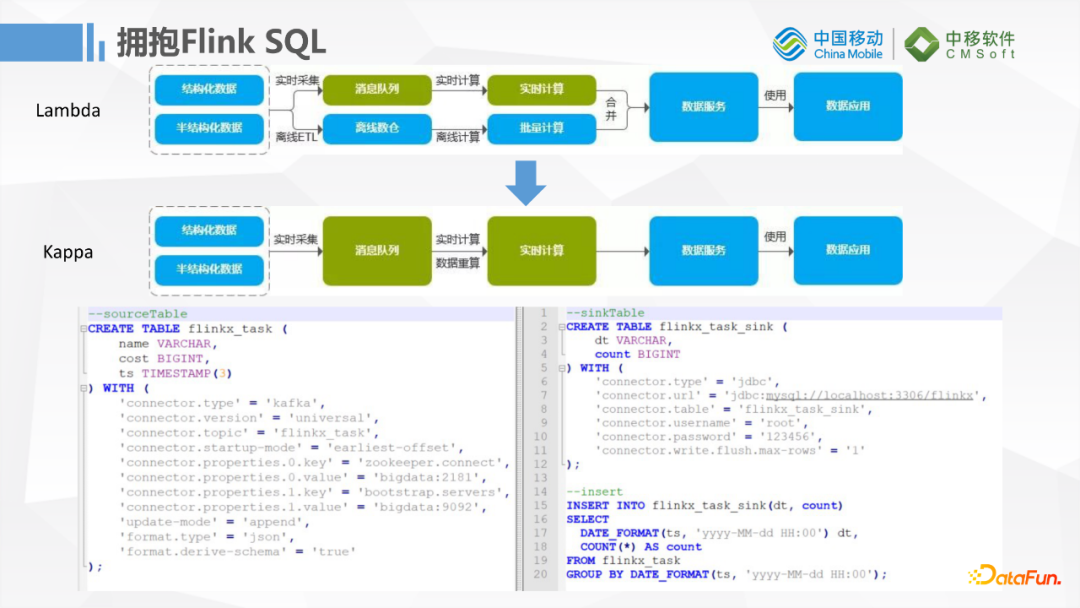
升級到1.12後對FlinkSQL的支持會更加友好,這樣傳統的Lambda升級到Kappa架構,對於習慣寫SQL做數據抽取轉換的用戶就非常友好,基本上可以靠一條SQL去實現流批一體化的任務,進一步降低開發維護的難度。我們可以從Kafka讀取一條數據,中間做一些簡單的轉換後寫到MySQL。我們後面資料庫肯定要支持越來越多的實時數據寫入,所以後期用SQL的方式開發這些任務就會更加便捷。
五、問答環節
Q:一般情況下FlinkX作業分配多少CPU和記憶體資源?
A:我們這邊一般定義一個Slot是一核2g,普通的一個MySQL到MySQL這樣的一個任務預設三個併發,用戶更多的是擔心我們的速度太快影響生產庫,目前自定義還沒有開放,後面具體的併發度會開放可以讓用戶自定義,目前Slot是固定的一核2g。
Q:現在流批一體的應用範圍廣嗎?
A:我認為是挺廣的,對於移動集團的一些項目,其實我們在適配他們的一些場景,主要還是基於消息隊列和MySQL的Binlog。我們之前遇到的用戶他在阿裡雲上訂購了結構化數據,現在他想上移動雲,但是他的生產庫又不能斷,他想做這樣的一個遷移,這就是需要流批一體的場景。他需要先做一個批的任務,把他歷史的數據搬運過來,再基於他的Binlog增量訂閱,實時同步更新他的增量數據,這就是一個很典型的傳統用戶的場景。再一個就是有一些大批量數據走Kafka,原始數據還是需要落一份到HDFS,但是需要實時的做一些彙總,這也算是一個比較典型的場景,會做流批一體的任務,我目前主要是針對這兩種場景做一些開發。
Q:FlinkX相較於FlinkCDC優勢在哪裡?
A:單說FlinkCDC他只是支持結構化數據增量更新,FlinkX如果是1.12版本它跟FlinkCDC之間的插件一些是共用的,然後他相較於原生的FlinkCDC做了一些擴展,特別是它會支持很多國產的資料庫,比如達夢,FlinkCDC目前還不支持。任務配置方式的話,FlinkX是基於JSON的,對於寫Flink代碼的的普通用戶更加友好。總結一句話就是擴展了更多插件。
Q:流批一體真的會減少機器的預算嗎?計算資源減少了還是存儲資源減少了?
A:存儲會減少一點,計算可能不會減少,因為流批一體的話,是在用同一套代碼維護批任務和流任務,中間的數據如果沒有必要的話是不用落地的,這塊肯定是節省存儲資源的。計算資源跟原來分開跑的話可能是相當的,不會有明顯的減少,主要是節省了存儲資源。
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack/Taier


