
在今年的第七屆中國開源年會上,StoneDB 團隊在大數據分論壇發表了《HTAP 的下一步?SoTP 初探》主題演講,在本次演講中,我們首次正式對外闡釋了“SoTP 資料庫”的技術理念,本系列是演講實錄+小編補充版,權當拋磚引玉,供大家批評指正。由於內容比較多,本文為第一章節,主要講講我們提 SoT ...
在今年的第七屆中國開源年會上,StoneDB 團隊在大數據分論壇發表了《HTAP 的下一步?SoTP 初探》主題演講,在本次演講中,我們首次正式對外闡釋了“SoTP 資料庫”的技術理念,本系列是演講實錄+小編補充版,權當拋磚引玉,供大家批評指正。由於內容比較多,本文為第一章節,主要講講我們提 SoTP 的背景:From Big to Small and Wide Data。
一、HTAP 的起源、流派和迷思
HTAP 起源
我們首先從起源講起,不過由於是公開演講,考慮到一些聽眾是小白,所以這裡主要是從一個比較巨集觀的關係型資料庫行業發展歷史視角來看的,關於 HTAP 更具體的技術和商業的起源背景,可以看看 StoneDB 首席架構師李浩老師寫的這篇文章:HTAP 的背景。
眾所周知,圖靈獎(Turing Award)算是電腦領域里最高的一個獎項,截至今日,因為在資料庫領域有傑出貢獻而獲得圖靈獎的只有四位,分別是:
- 查爾斯·巴赫曼(CharlesW. Bachman),1973 年獲獎,設計並開發了網狀資料庫管理系統 IDS,推動了資料庫標準的制定,包括網狀資料庫模型、數據定義和數據操縱語言的規範說明(通俗來講,是他第一次提出了資料庫這麼個東西,可以說是咱們的祖師爺);
- 埃德加·弗蘭克·科德(Edgar Frank Codd),1981 年獲獎,提出了關係資料庫模型(關係型資料庫經久不衰,目前依然占據市場最多的份額);
- 詹姆斯·古瑞(James Gray),1998 年獲獎,主要是在大型資料庫和事務處理技術上的突破(重點研究如何保障數據的完整性、安全性、並行性,以及故障恢復,曾擔任 VLDB 期刊的主編);
- 邁克爾·斯通佈雷克(Michael Stonebraker),2014 年獲獎,現代資料庫系統的概念和實踐方面的基礎性貢獻(領導了影響力巨大的奠基性資料庫 Ingres 的開發,也是最早提倡發展列存資料庫的大佬之一)。

除了這四位資料庫界公認的大佬外,也有其他大牛,比如:
- 1988 年,為解決數據集成問題,IBM 的 2 位研究員 Barry Devlin 和 Paul Murphy,創造性地提出了數據倉庫(Data Warehouse)的概念;
- 1992 年,比爾·恩門(Bill Inmon)給出了數據倉庫的定義。數據倉庫是一個面向主題的、集成的、相對穩定的、反映歷史變化的數據集合,用於支持管理中的決策制定;
- 1993 年,E.F.Codd 提出 OLAP,以及 OLAP 12 條準則。
- ......
能看到,早些年的資料庫界名人們,並沒有太多中國人士,和操作系統一樣,中國在這類基礎軟體上的起步和投入都不算太早,這也是資料庫領域目前成為我國 35 個“卡脖子”技術之一的原因吧。
我這裡要指出的是——相信那些在資料庫界深耕數十年的朋友們應該早就感受到了——仿佛,自從上述這些大佬奠定了關係型資料庫發展的總基調後,後續的幾十年裡,就再沒看到什麼轟動一時的創新了,或者說,影響力能達到以上這些人士的資料庫專家學者也沒那麼多了。那段時間,關係型資料庫的熱點話題好像從百家爭鳴陷入了一個相對沉寂的時期,當然,後面也斷斷續續有一些新的技術熱點,不過,能像上面這些大佬一樣直接奠定一個學科或者理論的,就比較少了。
萬籟“俱寂”時,一家知名 IT 研究與顧問咨詢機構的發聲,給關係型資料庫這個平靜的池塘丟了顆巨石:2014 年,Gartner 正式提出了 HTAP 這個概念。
Gartner’s definition in 2014: utilizes in-memory computing technologies to enable concurrent analytical and transaction processing on the same in-memory data store.
Gartner’s new definition in 2018: supports weaving analytical and transaction processing techniques together as needed to accomplish the business task.
可以看到,Gartner 重點強調了使用記憶體技術實現 HTAP 的可行性,並表示 HTAP 將為巨大的業務創新創造機會,增量市場空間巨大。

一石捲起千層浪,陷入半沉寂的關係型資料庫技術,好像迎來了春天。那個時候,商業智能(BI)已經開始廣泛滲入到眾多企業的營銷業務體系裡了,處理數據的業務分析部門對實時處理和運維最簡化的需求越來越重要,HTAP 方案的提出自然迅速地引起了行業的強勢關註,因為這玩意兒光是聽起來就省心省力,誘惑很大。
我們正在做的 StoneDB,就是對標 Oracle MySQL HeatWave 的一款開源版實時一體化 HTAP 資料庫。
HTAP 流派

上圖是清華大學李國良教授團隊梳理的 HTAP 資料庫的發展時間線。我們這裡再舉幾個大家耳熟能詳的企業:像資料庫巨頭 Oracle 去年就推出了 MySQL HeatWave,沒錯,Oracle 官方已經明確表示了,做 HeatWave 的目的就是為了支持 HTAP,在最近的 Oracle CloudWorld 大會上還官宣了 MySQL HeatWave Lakehouse;Google 在 HTAP 上也動作頻頻,除了搞 F1 Lightning 以外,在今年 5 月 12 日的 Google I/O 2022 開發者大會還宣佈了雲原生 HTAP 資料庫 AlloyDB for PostgreSQL;緊接著,所有雲數倉都想打的知名廠商 SnowFlake 也在 6 月 14 日的用戶大會 Snowflake Summit 2022 上官宣正式推出 HTAP 存儲引擎 Unistore;資料庫獨角獸SingleStore(前身為 MemSQL) 也早就在 HTAP 領域上頻頻發聲,頂會論文都發了。國際上的這些大廠和獨角獸都在搞 HTAP,國內的更不用說了,阿裡、百度、騰訊、華為、位元組和眾多新興創業公司(包括咱們 StoneDB),以及老牌資料庫廠商都開始宣傳自己的一些產品可以實現或者主攻 HTAP。Gartner 之前在報告里預測說,到 2024 年,HTAP 資料庫會被廣泛用到各行各業中,現在看來,真的是有這種勢頭了。
顯而易見,HTAP 這倆馬車的車輪已經壓在了資料庫行業的歷史軌跡上,正在滾滾向前,勢不可擋。但是,隨著越來越多的廠商正式加入賽道,對於 HTAP 架構的技術實現,自然產生了一些分化。
我們之前在文章《深度乾貨!一篇 Paper 帶您讀懂 HTAP》中有做介紹,這篇報告里提到,至少有四種不同的架構方式可以實現 HTAP。

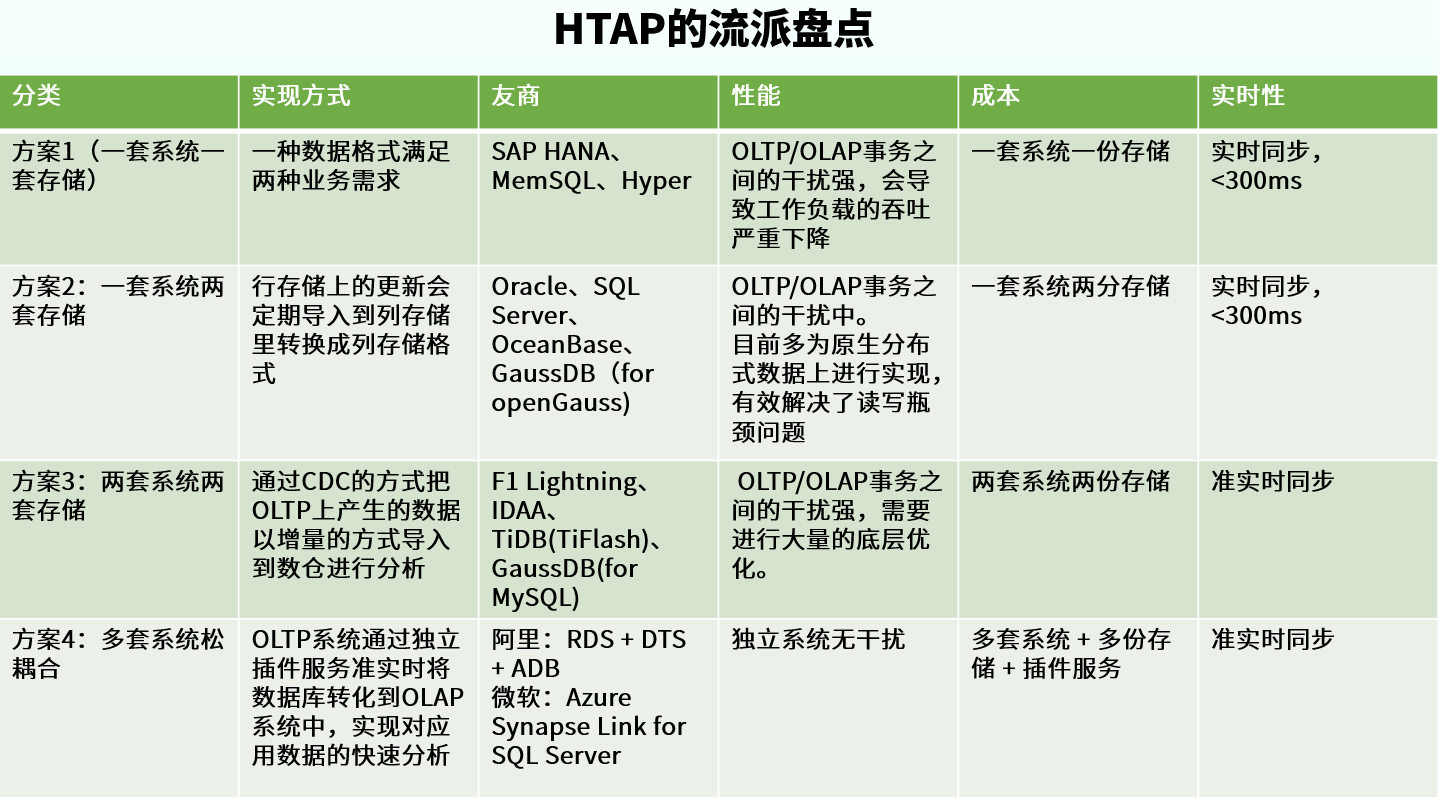
目前 HTAP 大致有四種實現方式:
-
方案 1(一套系統一套存儲):在一個系統里用一種數據格式滿足兩種業務需求;
-
方案 2(一套系統兩套存儲):一個系統里同時存在行存儲和列存儲,行存儲上的更新會定期導入到列存儲里轉換成列存儲格式;
-
方案 3(兩套系統兩套存儲):系統里同時存在 OLTP 與 OLAP 兩套引擎,分別寫入和讀取行存儲和列存儲;
-
方案 4(多套系統松耦合):不同的異構系統之間,通過獨立的插件服務對數據進行準實時同步,對外呈現 HTAP 能力。
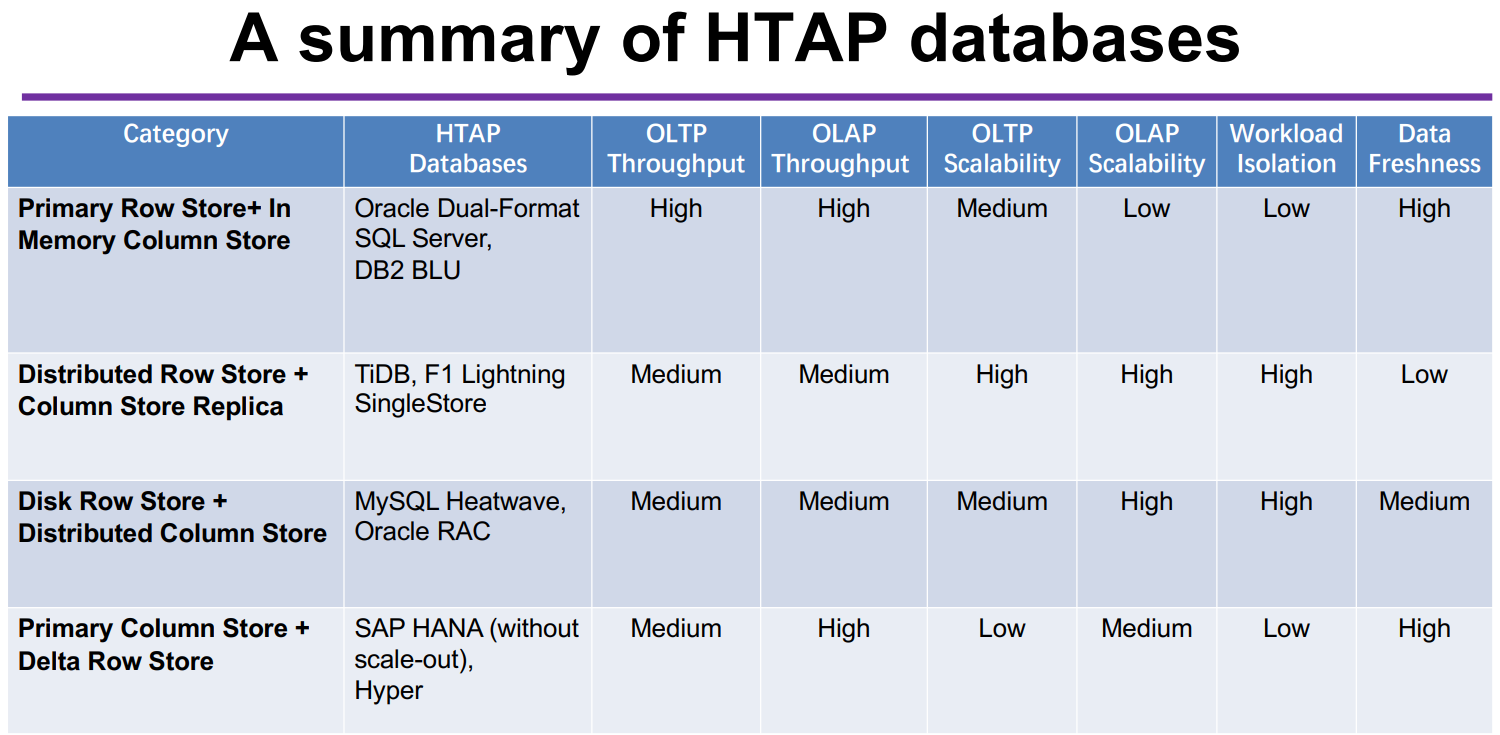
下麵這張表圖是我們對這四種架構方案的一個簡單的綜合盤點。
HTAP 迷思
隨著一些 HTAP 產品功能能夠實現落地了,在 HTAP 架構的選擇上引起了不少爭議(我們講叫技術口水戰),這很正常,大家都想說 HTAP 是自己做得比較好嘛。比如 StoneDB 這邊就比較支持完全一體化的混合負載架構(我們稱之為真正的 HTAP 面臨的挑戰);也有的團隊比較想搞那種兩套系統疊加的架構;還有更猛的,直接說要基於 GPU/CPU 搞 HTAP,就是 RateupDB,據說是全球唯一一個基於 GPU/CPU 和並行的 HTAP 資料庫,還發了一篇 VLDB,不過好像現在銷聲匿跡了,創始人目前應該是投身一家勢頭較猛的雲數倉創業公司去了。
由此可見,HTAP 雖然引起了一陣狂歡,但是,對 HTAP 資料庫架構選擇目前業界還是沒有一套特別稱得上成熟的方案,大家也都是在打磨產品中。有的走的稍微早了一些;有的還在孵化打磨;有的已經倒在半路上了,但是一個不可否認的事實是,大家都開始說自己能或者即將能支持 HTAP 了,就和資料庫領域另外一個爆火的“雲原生”關鍵字一樣,這真可謂是“二四八月亂穿衣”了,這也算是現在 HTAP 領域上存在的迷思吧。
新的趨勢:From Big to Small and Wide data
所以,在這個時候,作為率先提出要做 MySQL 開源 HTAP 資料庫的 StoneDB,想要稍微冷靜一下。
不是說我們不做 HTAP 了,而是有了一個新的思路。這個思路,也同樣來自於咱們的老朋友、好伙伴,大家都巴不得上他們報告的權威機構——Gartner。
Gartner 在去年發佈的《Gartner 2021 十大數據和分析趨勢》報告里,特別提到了一個重要的趨勢:。From Big to Small and Wide data

據 Gartner 預測,到 2025 年 70% 的組織會把重點從“大”數據轉向“小”數據和“寬”數據,為分析提供更多的場景,使人工智慧(AI)減少對數據量的需求(原文是 making artificial intelligence (AI) less data hungry)。

當然,這個趨勢的調研結論是有背景的,那就是突如其來的新冠疫情。面對新冠,很多數據幾乎是一夜式爆髮式變化增長,導致了基於大量歷史數據的機器學習和人工智慧模型變得不那麼可靠,隨著智能決策變得更加複雜和嚴格,數據和分析領導者應選擇能夠更加有效利用現有數據的分析技術。
如何更加有效利用數據分析?那就是我們講的用“小”而“寬”的數據取代“大”數據來解決問題。小數據——顧名思義,指的是能夠使用所需數據量較少,但仍能提供實用洞見的數據模型。寬數據——可以理解為多模數據,即使用寬數據分析各種小而多樣化的非結構化和結構化數據源併發揮它們的協同效果,從而增強情景態勢感知(contextual awareness,情境感知)和決策。
下麵就來詳細講解一下 Small Data 和 Wide Data 的定義。
Small data 概念
小數據的方法是指使用相對較少的數據,但仍能提供有見解的分析技術。其中包括了有針對性地使用數據要求比較低的模型,比如一些時間序列分析的技術,而不是用一刀切的方式去使用數據量要求較高的深度學習技術。
通俗地來講,使用 AI 或者 ML 技術,往往需要大量的數據源作為分析的訓練模型,但並不是數據量越多越好,特別是那些過時的歷史數據,對分析毫無意義,如果可以及時地找到一些比較精準的小數據進行分析,往往能獲得更有價值的效果。總之,小數據側重於應用分析技術,在小量的、單獨的數據集中尋找有用的信息。
Wide data 概念
寬數據允許分析師檢查和組合各種大小、非結構化和結構化數據。具體來說,寬而廣泛的數據就是將各種來源的不同數據源捆綁在一起,以進行有意義的分析。
基於寬數據的數據分析技術圍繞著結構化和非結構化數據的分析和協同,而不管數據集是否直接相關。寬數據最大的特征是可以提取或識別異構數據集之間的聯繫。
Small and Wide data 結合的作用
Gartner 知名研究副總裁 Rita Sallam 表示:“使用‘小’而‘寬’的數據能夠提供強大的分析和 AI,同時降低企業機構對大型數據集的依賴性。企業機構可以使用‘寬’數據獲得更豐富、更完整的態勢感知或 360 度視圖,這將使企業機構能夠使用分析技術做出更好的決策。”
Gartner 高級研究總監孫鑫表示:“隨著企業逐漸認識到大數據作為分析和人工智慧關鍵推動者的局限性,被稱為小數據和寬數據的方法正在慢慢涌現,小數據的方法拋開了對於大型單體數據的依賴,實現了對於小型、大型、結構化、非結構化的數據源的分析和協同。”
同時,據 Gartner 預測,到 2025 年,超過 85% 的技術供應商,將在人工智慧解決方案當中加入讓數據變得更豐富的方法和模型訓練技術,以提高模型的彈性和敏捷性,而在 2020 年,這樣做的供應商只有不到 5%。 由此可見,小數據和寬數據的市場增量巨大。
Small and Wide data 核心場景
說了這麼多“小”數據和“寬”數據,這兩個到一塊兒究竟能落地到什麼應用場景上?
從一個具體的場景為例,現在電商以及社交媒體都在做一個實時推薦的業務場景,而實時推薦的標準流程是首先通過大數據系統對客戶的購買歷史進行分析,要關註客戶購買產品的生命周期,客戶與企業之間的交互歷史;同時要去通過各種渠道去瞭解,目前客戶正在什麼環境,聽到了什麼? 正在瀏覽什麼信息?結合各種數據進行分析,最後產生 Top10 的產品推薦,然後通過 App 或者其他手段推送給客戶。
在這個過程中,需要收集的數據非常龐大,包括各種結構化數據,例如歷史訂單,客戶個人信息等,另外客戶的上網日誌,網頁瀏覽歷史,客戶的位置信息, 行動軌跡,這些數據的體量都非常大,而一旦涉及到千萬乃至上億的用戶,同時上萬種產品的場景下,這個數據量就是天文數字,而等待所有這些數據都收集完整併進行 AI 建模預測,則很可能是 1-2 天之後的事情了。
所以,為了儘可能快地對客戶當前狀況進行反饋,並推出相應的推薦方案,必須把數據鏈條縮短:首先通過在生產系統端,貼合用戶的購買歷史和行為,對整個場景進行約束,從海量數據分析,變成小數據量的分析,把推薦產品從幾萬,縮小到幾十的範圍,這個時候,就是從大數據到“小”數據的過程。然後在此基礎之上,通過補足其他渠道的信息,包括圖像、聲音、瀏覽日誌等等,對幾十的範圍進行進一步的精準化定位。這個時候,則體現了“寬”數據的價值。
預計小數據和寬數據技術將產生積極的結果,即:
- 零售需求預測(Retail demand forecasting)
- 實時行為智能( Real time behavioral intelligence)
- 超個性化和整體客戶體驗的改善( Hyper personalization and improvement of the overall customer experience)
- 人生安全
- 欺詐檢測
- 自適應自動系統(比如自適應 AI)等等
雖然“小”數據和“寬”數據技術的確切結果還沒有出現,但這個概念肯定是未來可期的,因為這些技術能夠在過去或歷史趨勢不再相關的領域提供卓有成效的洞察分析能力。
對於從“大”數據到“小”數據的過程,一個趨勢就是,數據分析不必一定從數倉開始, 而是從前端業務系統,結合一定的場景,首先發起快捷的數據分析, 解決場景定位,方案範圍初篩等數據的初步處理,讓後繼的分析儘可能地聚焦在指定的領域,一方面減少計算量,同時加速後繼決策的速度。
所以業務系統在承擔業務交易的時候,必須增加一定的數據分析和篩選的能力, 這個和傳統的業務系統是純粹 OLTP 系統的定義不一樣, 將來業務系統的能力將會從 OLTP 向 HTAP 逐步變遷。
這一塊還有很多東西可以講,後續我們繼續探討,今天就先點一下。作為在數據分析領域耕耘多年的資料庫團隊,我們對這個觀點是非常認可的。因為,經常做數據分析的人都知道,隨著使用數據的場景越來越多,數據支撐運營的場景也越來越多,很多情況下,數據驅動運營需要的是近期的熱數據,而不是長時間的數據。而這個“熱數據”,再更精確一些講,就應該是“熱”的“小”而“寬”數據。
這恰恰和 StoneDB 提倡的基於 MySQL 的 HTAP 資料庫要能夠支持實時與中小數據量場景不謀而合(正常 10T 左右,最高不超過 100T,當然了,要是擴展成 LakeHouse,支持的數據量會更多)。也和 SingleStore 講的觀點很類似:沒有 HTAP,機器學習和人工智慧都是不切實際的。
基於此,我們提出一個 idea,即 StoneDB 這種強調對熱數據實時分析的 HTAP 資料庫,也可以叫做 SoTP 資料庫。
SoTP 初探
SoTP,即 Serving over TP。
Serving 是什麼?SoTP 的定義和驅動又是什麼?這個留給我們下一篇文章繼續解讀,歡迎關註 StoneDB 公眾號。
StoneDB 2.0 雲原生分散式實時 HTAP 架構詳細設計以 RFC 形式持續進行,歡迎大家關註我們最新進展,更歡迎給我們開源協作的模式和方法提出改進意見,一起通過開源的方式共建 StoneDB ~
https://github.com/stoneatom/stonedb/issues/436
- StoneDB 代碼已完全在 Github 開源:
https://github.com/stoneatom/stonedb
- StoneDB 官網:


