
1. 前文回顧 在上篇文章 《深入理解 Linux 虛擬記憶體管理》 中,筆者分別從進程用戶態和內核態的角度詳細深入地為大家介紹了 Linux 內核如何對進程虛擬記憶體空間進行佈局以及管理的相關實現。在我們深入理解了虛擬記憶體之後,那麼何不順帶著也探秘一下物理記憶體的管理呢? 所以本文的目的是在深入理解虛擬 ...
1. 前文回顧
在上篇文章 《深入理解 Linux 虛擬記憶體管理》 中,筆者分別從進程用戶態和內核態的角度詳細深入地為大家介紹了 Linux 內核如何對進程虛擬記憶體空間進行佈局以及管理的相關實現。在我們深入理解了虛擬記憶體之後,那麼何不順帶著也探秘一下物理記憶體的管理呢?
所以本文的目的是在深入理解虛擬記憶體管理的基礎之上繼續帶大家向前奮進,一舉擊破物理記憶體管理的知識盲區,使大家能夠俯瞰整個 Linux 記憶體管理子系統的整體全貌。
而在正式開始物理記憶體管理的主題之前,筆者覺得有必須在帶大家回顧下上篇文章中介紹的虛擬記憶體管理的相關知識,方便大家來回對比虛擬記憶體和物理記憶體,從而可以全面整體地掌握 Linux 記憶體管理子系統。
在上篇文章的一開始,筆者首先為大家展現了我們應用程式頻繁接觸到的虛擬記憶體地址,清晰地為大家介紹了到底什麼是虛擬記憶體地址,以及虛擬記憶體地址分別在 32 位系統和 64 位系統中的具體表現形式:
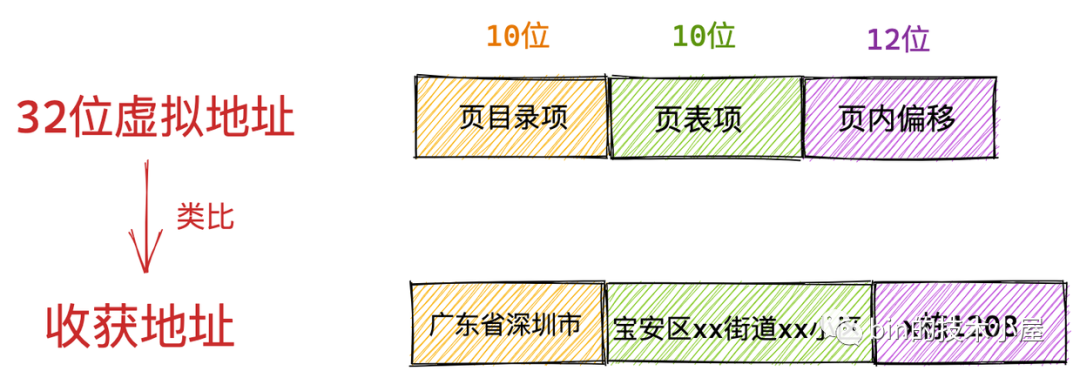
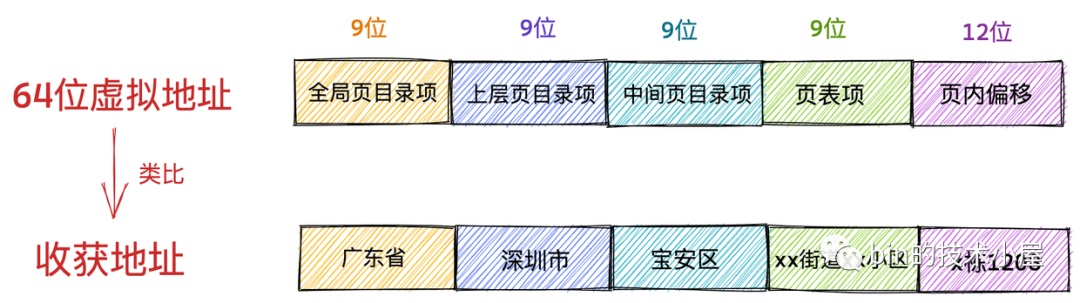
在我們清楚了虛擬記憶體地址這個基本概念之後,隨後筆者又拋出了一個問題:為什麼我們要通過虛擬記憶體地址訪問記憶體而不是直接通過物理地址訪問?
原來是在多進程系統中直接操作物理記憶體地址的話,我們需要精確地知道每一個變數的位置都被安排在了哪裡,而且還要註意當前進程在和多個進程同時運行的時候,不能共用同一個地址,否則就會造成地址衝突。
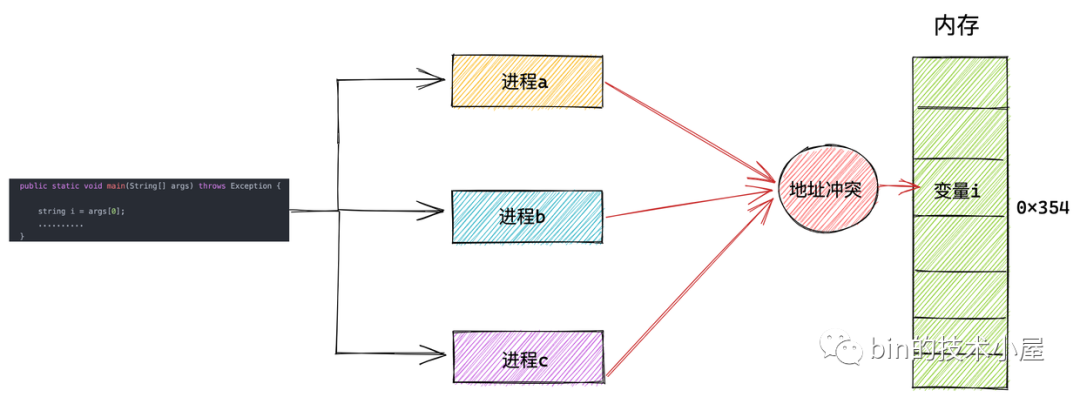
而虛擬記憶體空間的引入正是為瞭解決多進程地址衝突的問題,使得進程與進程之間的虛擬記憶體地址空間相互隔離,互不幹擾。每個進程都認為自己獨占所有記憶體空間,將多進程之間的協同相關細節統統交給內核中的記憶體管理模塊來處理,極大地解放了程式員的心智負擔。這一切都是因為虛擬記憶體能夠為進程提供記憶體地址空間隔離的功勞。
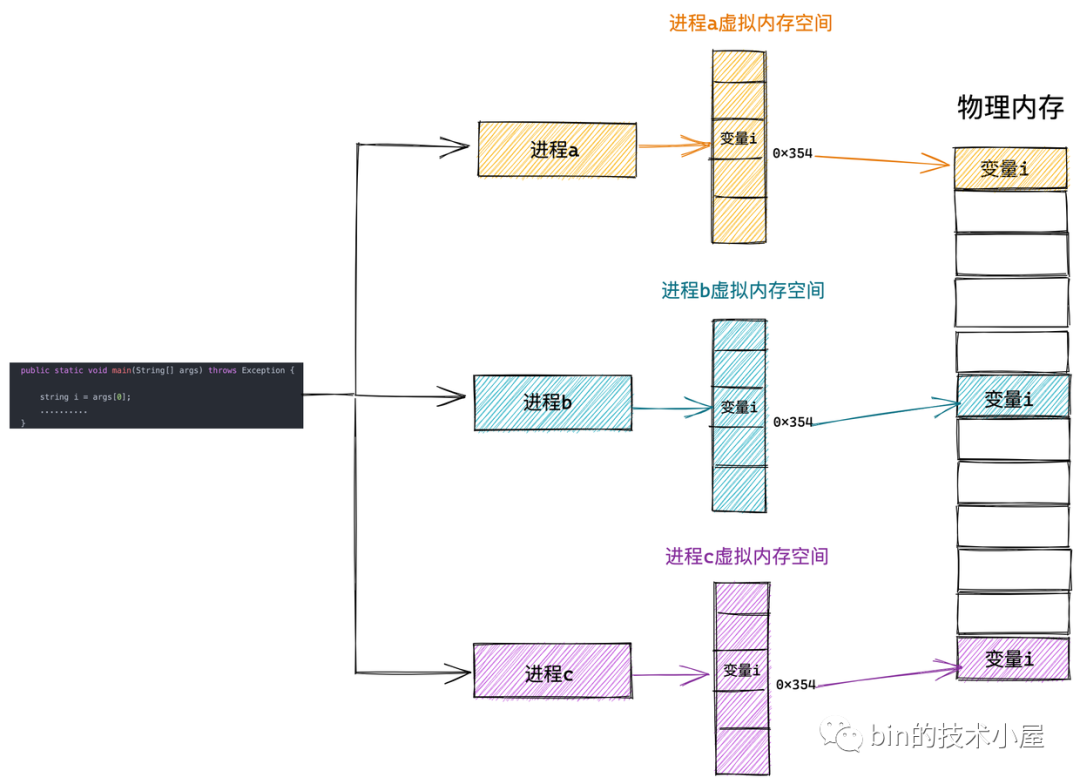
在我們清楚了虛擬記憶體空間引入的意義之後,筆者緊接著為大家介紹了進程用戶態虛擬記憶體空間分別在 32 位機器和 64 位機器上的佈局情況:
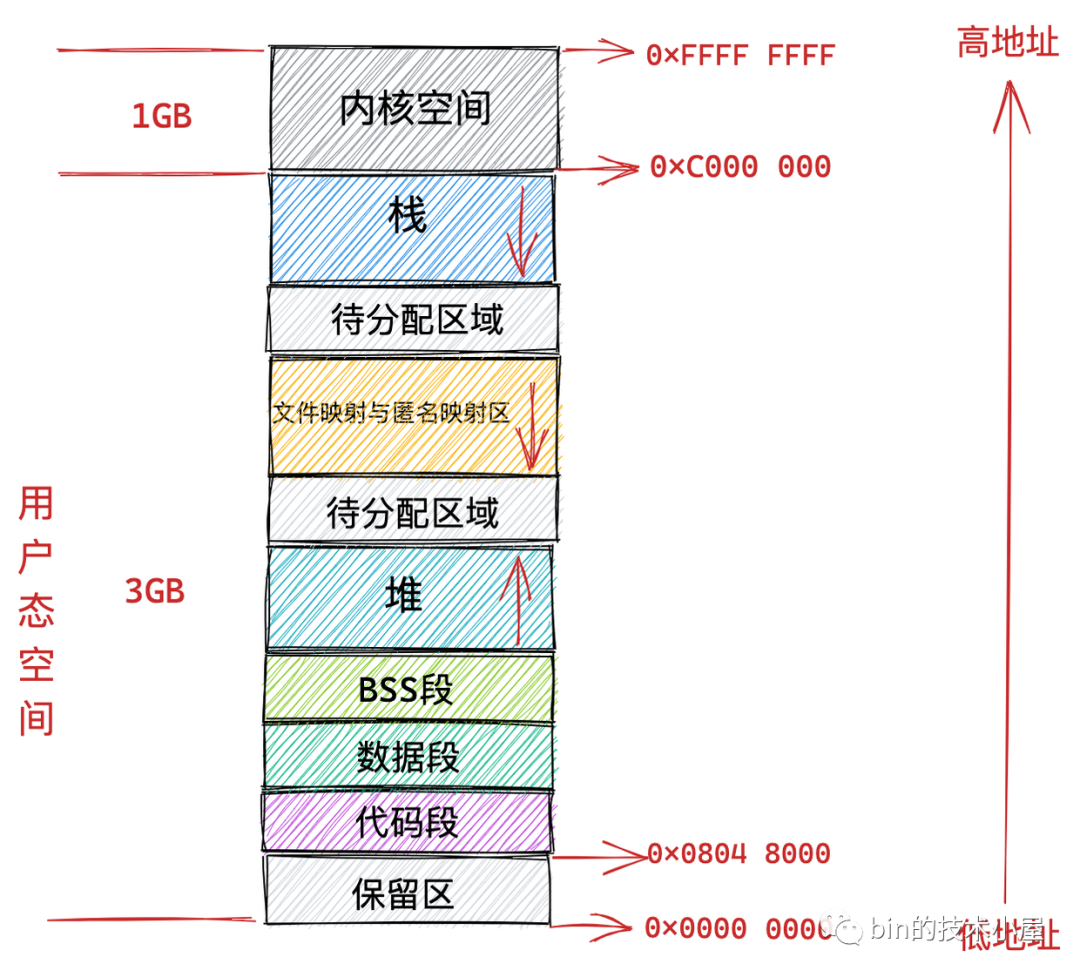
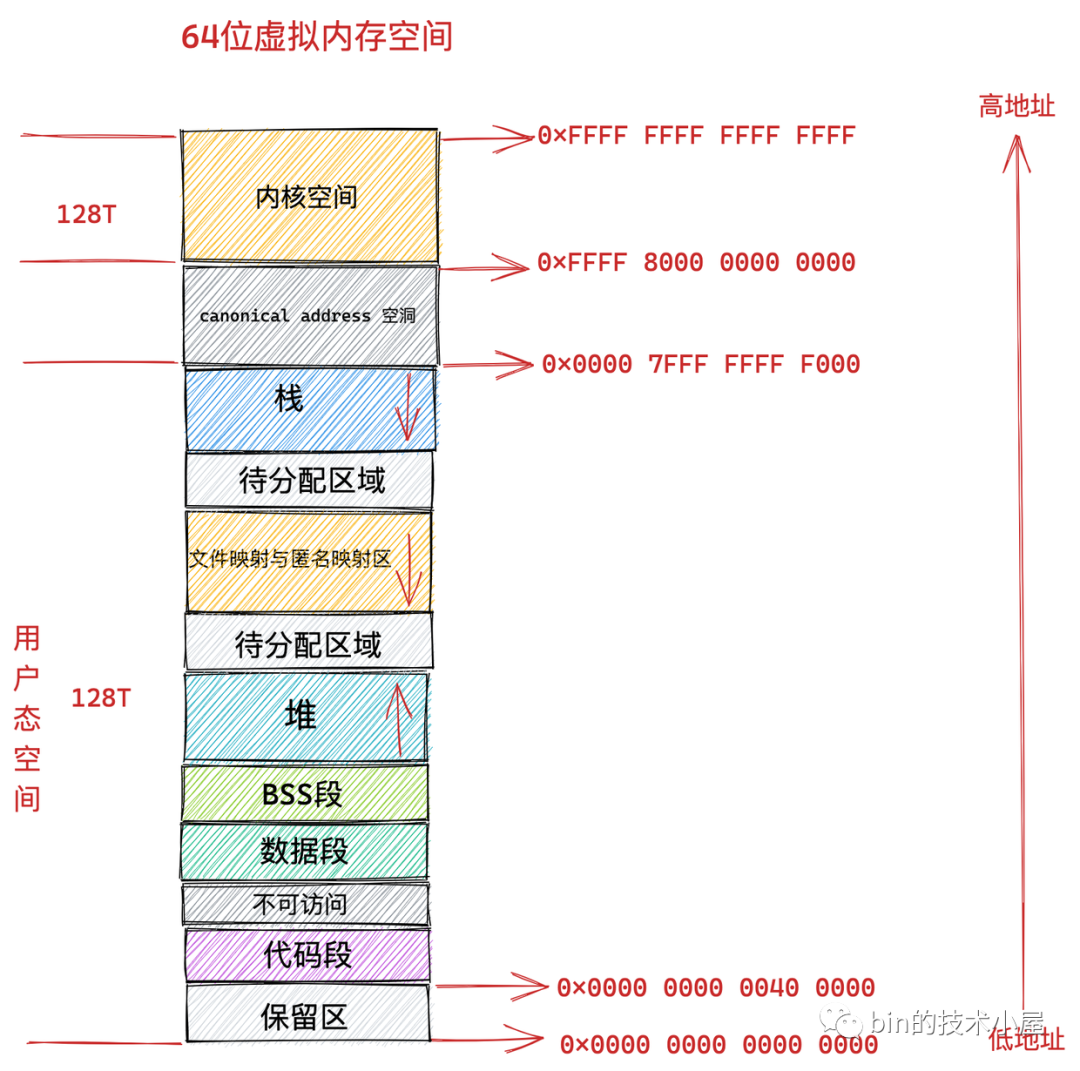
在瞭解了用戶態虛擬記憶體空間的佈局之後,緊接著我們又介紹了 Linux 內核如何對用戶態虛擬記憶體空間進行管理以及相應的管理數據結構:
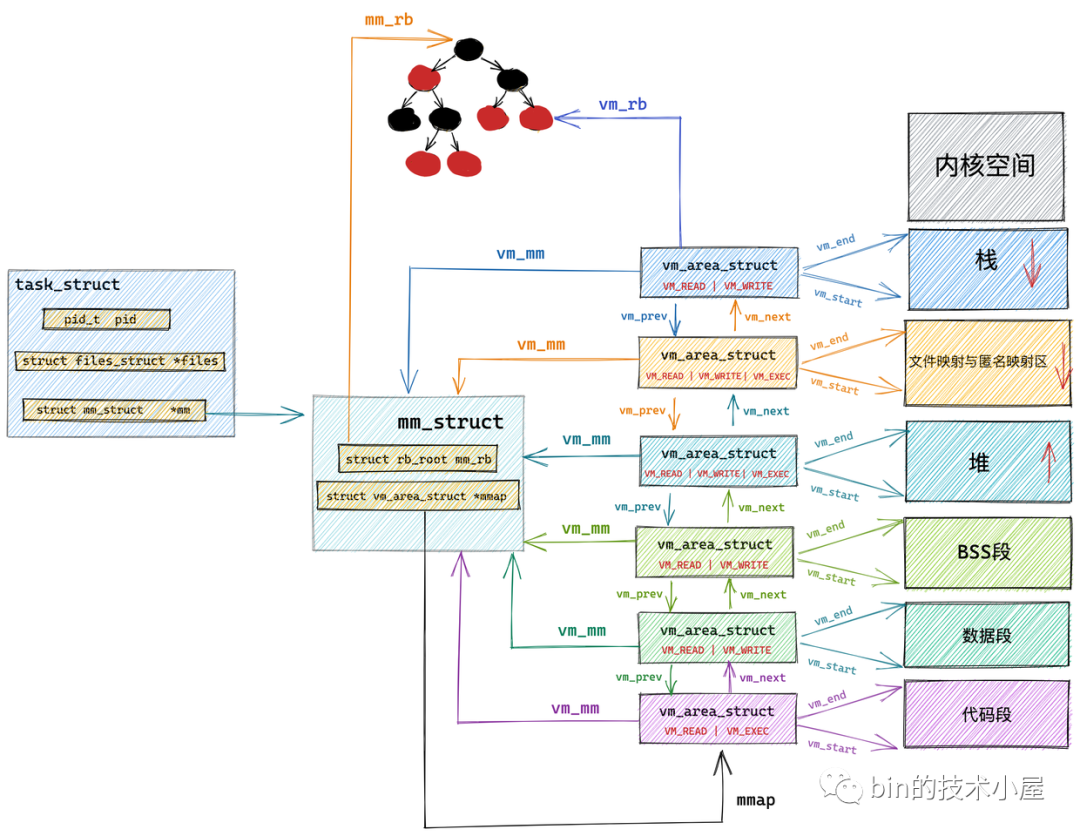
在介紹完用戶態虛擬記憶體空間的佈局以及管理之後,我們隨後又介紹了內核態虛擬記憶體空間的佈局情況,並結合之前介紹的用戶態虛擬記憶體空間,得到了 Linux 虛擬記憶體空間分別在 32 位和 64 位系統中的整體佈局情況:
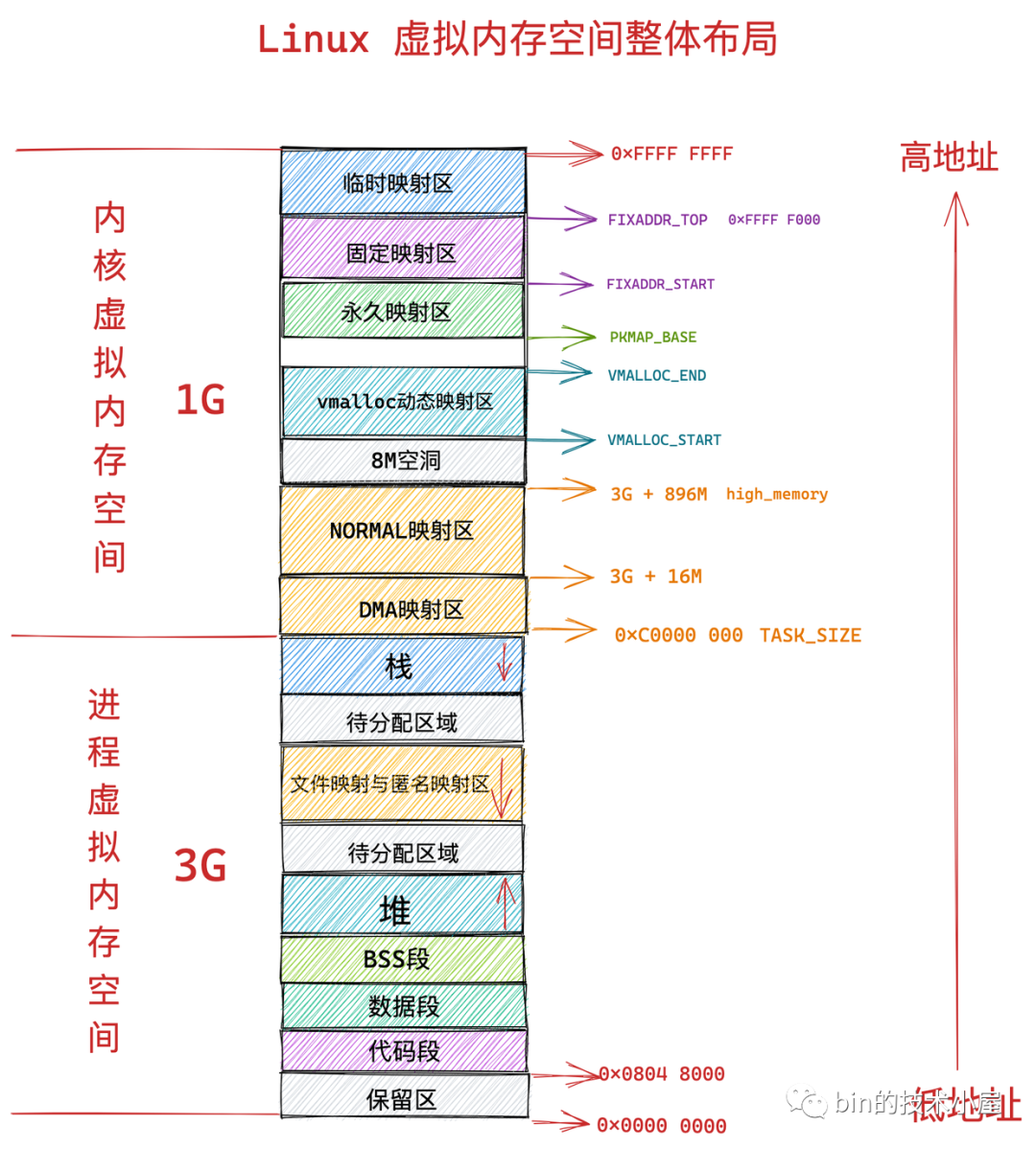

在虛擬記憶體全部介紹完畢之後,為了能夠承上啟下,於是筆者繼續在上篇文章的最後一個小節從電腦組成原理的角度介紹了物理記憶體的物理組織結構,方便讓大家理解到底什麼是真正的物理記憶體 ?物理記憶體地址到底是什麼 ?由此為本文的主題 —— 物理記憶體的管理 ,埋下伏筆~~~
最後筆者介紹了 CPU 如何通過物理記憶體地址向物理記憶體讀寫數據的完整過程:

在我們回顧完上篇文章介紹的用戶態和內核態虛擬記憶體空間的管理,以及物理記憶體在電腦中的真實組成結構之後,下麵筆者就來正式地為大家介紹本文的主題 —— Linux 內核如何對物理記憶體進行管理
2. 從 CPU 角度看物理記憶體模型
在前邊的文章中,筆者曾多次提到內核是以頁為基本單位對物理記憶體進行管理的,通過將物理記憶體劃分為一頁一頁的記憶體塊,每頁大小為 4K。一頁大小的記憶體塊在內核中用 struct page 結構體來進行管理,struct page 中封裝了每頁記憶體塊的狀態信息,比如:組織結構,使用信息,統計信息,以及與其他結構的關聯映射信息等。
而為了快速索引到具體的物理記憶體頁,內核為每個物理頁 struct page 結構體定義了一個索引編號:PFN(Page Frame Number)。PFN 與 struct page 是一一對應的關係。
內核提供了兩個巨集來完成 PFN 與 物理頁結構體 struct page 之間的相互轉換。它們分別是 page_to_pfn 與 pfn_to_page。
內核中如何組織管理這些物理記憶體頁 struct page 的方式我們稱之為做物理記憶體模型,不同的物理記憶體模型,應對的場景以及 page_to_pfn 與 pfn_to_page 的計算邏輯都是不一樣的。
2.1 FLATMEM 平坦記憶體模型
我們先把物理記憶體想象成一片地址連續的存儲空間,在這一大片地址連續的記憶體空間中,內核將這塊記憶體空間分為一頁一頁的記憶體塊 struct page 。
由於這塊物理記憶體是連續的,物理地址也是連續的,劃分出來的這一頁一頁的物理頁必然也是連續的,並且每頁的大小都是固定的,所以我們很容易想到用一個數組來組織這些連續的物理記憶體頁 struct page 結構,其在數組中對應的下標即為 PFN 。這種記憶體模型就叫做平坦記憶體模型 FLATMEM 。
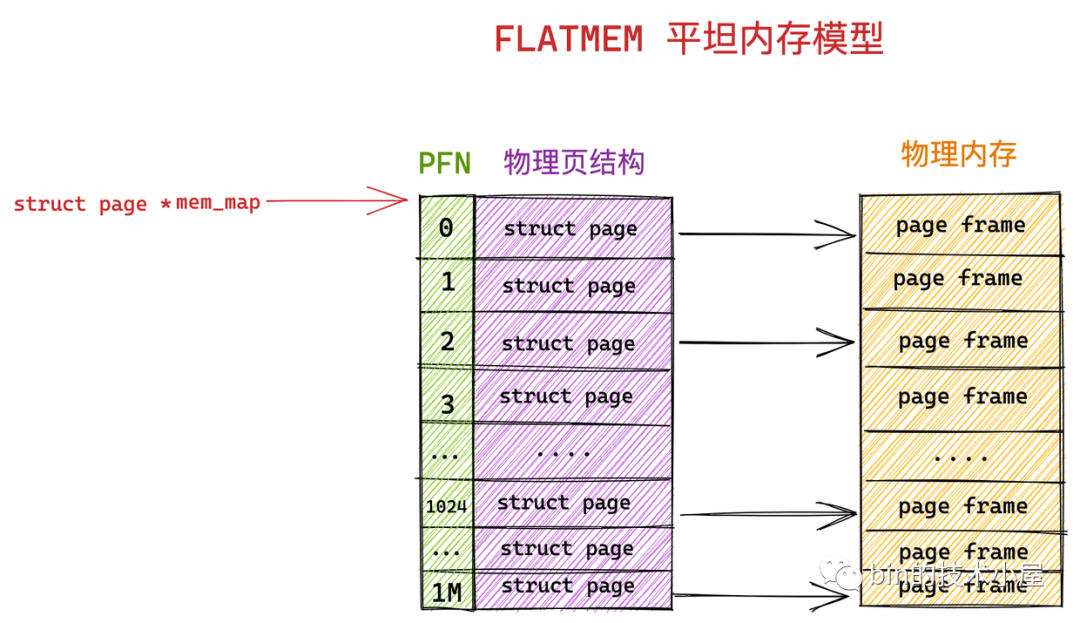
內核中使用了一個 mem_map 的全局數組用來組織所有劃分出來的物理記憶體頁。mem_map 全局數組的下標就是相應物理頁對應的 PFN 。
在平坦記憶體模型下 ,page_to_pfn 與 pfn_to_page 的計算邏輯就非常簡單,本質就是基於 mem_map 數組進行偏移操作。
#if defined(CONFIG_FLATMEM)
#define __pfn_to_page(pfn) (mem_map + ((pfn)-ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page)-mem_map) + ARCH_PFN_OFFSET)
#endif
ARCH_PFN_OFFSET 是 PFN 的起始偏移量。
Linux 早期使用的就是這種記憶體模型,因為在 Linux 發展的早期所需要管理的物理記憶體通常不大(比如幾十 MB),那時的 Linux 使用平坦記憶體模型 FLATMEM 來管理物理記憶體就足夠高效了。
內核中的預設配置是使用 FLATMEM 平坦記憶體模型。
2.2 DISCONTIGMEM 非連續記憶體模型
FLATMEM 平坦記憶體模型只適合管理一整塊連續的物理記憶體,而對於多塊非連續的物理記憶體來說使用 FLATMEM 平坦記憶體模型進行管理則會造成很大的記憶體空間浪費。
因為 FLATMEM 平坦記憶體模型是利用 mem_map 這樣一個全局數組來組織這些被劃分出來的物理頁 page 的,而對於物理記憶體存在大量不連續的記憶體地址區間這種情況時,這些不連續的記憶體地址區間就形成了記憶體空洞。
由於用於組織物理頁的底層數據結構是 mem_map 數組,數組的特性又要求這些物理頁是連續的,所以只能為這些記憶體地址空洞也分配 struct page 結構用來填充數組使其連續。
而每個 struct page 結構大部分情況下需要占用 40 位元組(struct page 結構在不同場景下記憶體占用會有所不同,這一點我們後面再說),如果物理記憶體中存在的大塊的地址空洞,那麼為這些空洞而分配的 struct page 將會占用大量的記憶體空間,導致巨大的浪費。
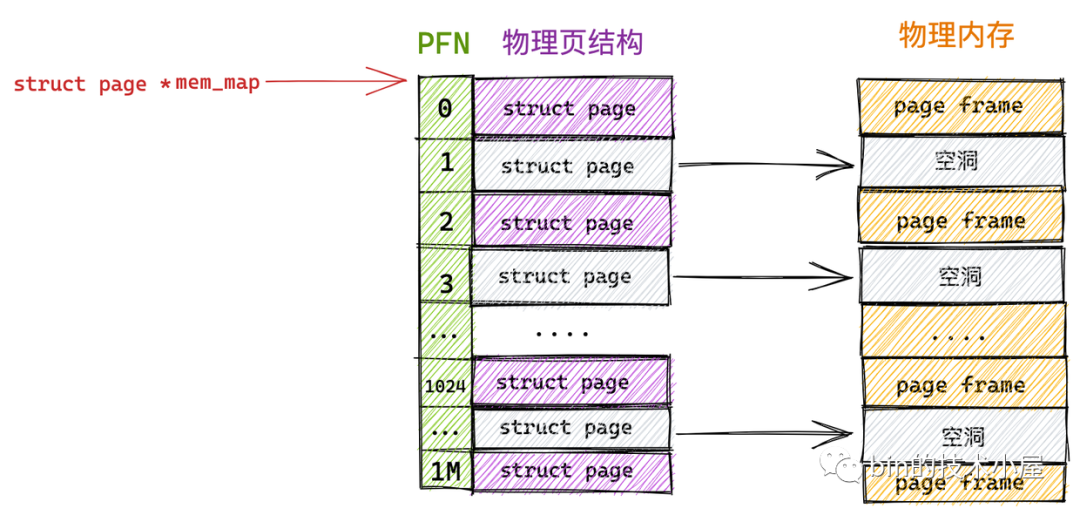
為了組織和管理這些不連續的物理記憶體,內核於是引入了 DISCONTIGMEM 非連續記憶體模型,用來消除這些不連續的記憶體地址空洞對 mem_map 的空間浪費。
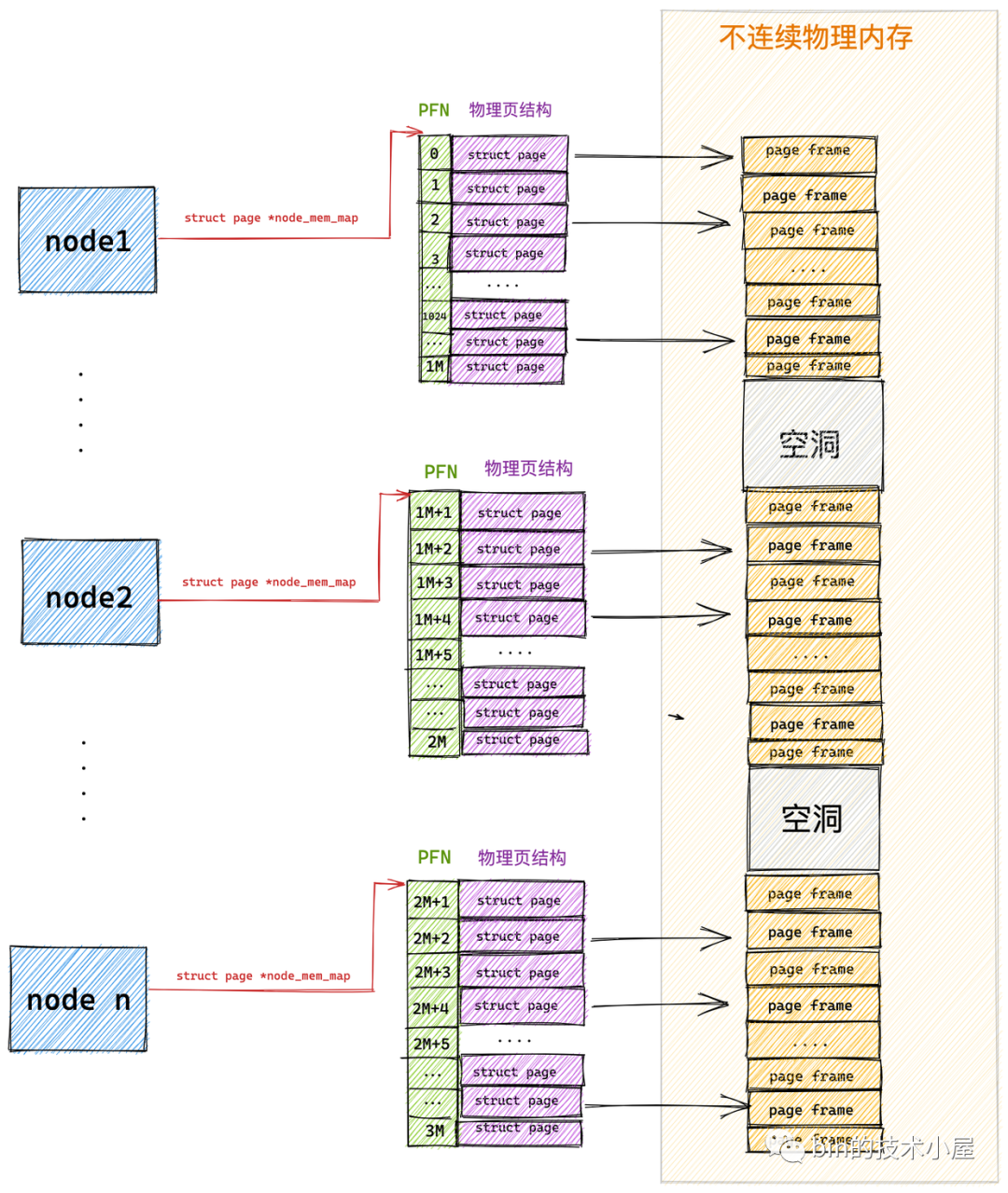
在 DISCONTIGMEM 非連續記憶體模型中,內核將物理記憶體從巨集觀上劃分成了一個一個的節點 node (微觀上還是一頁一頁的物理頁),每個 node 節點管理一塊連續的物理記憶體。這樣一來這些連續的物理記憶體頁均被劃歸到了對應的 node 節點中管理,就避免了記憶體空洞造成的空間浪費。
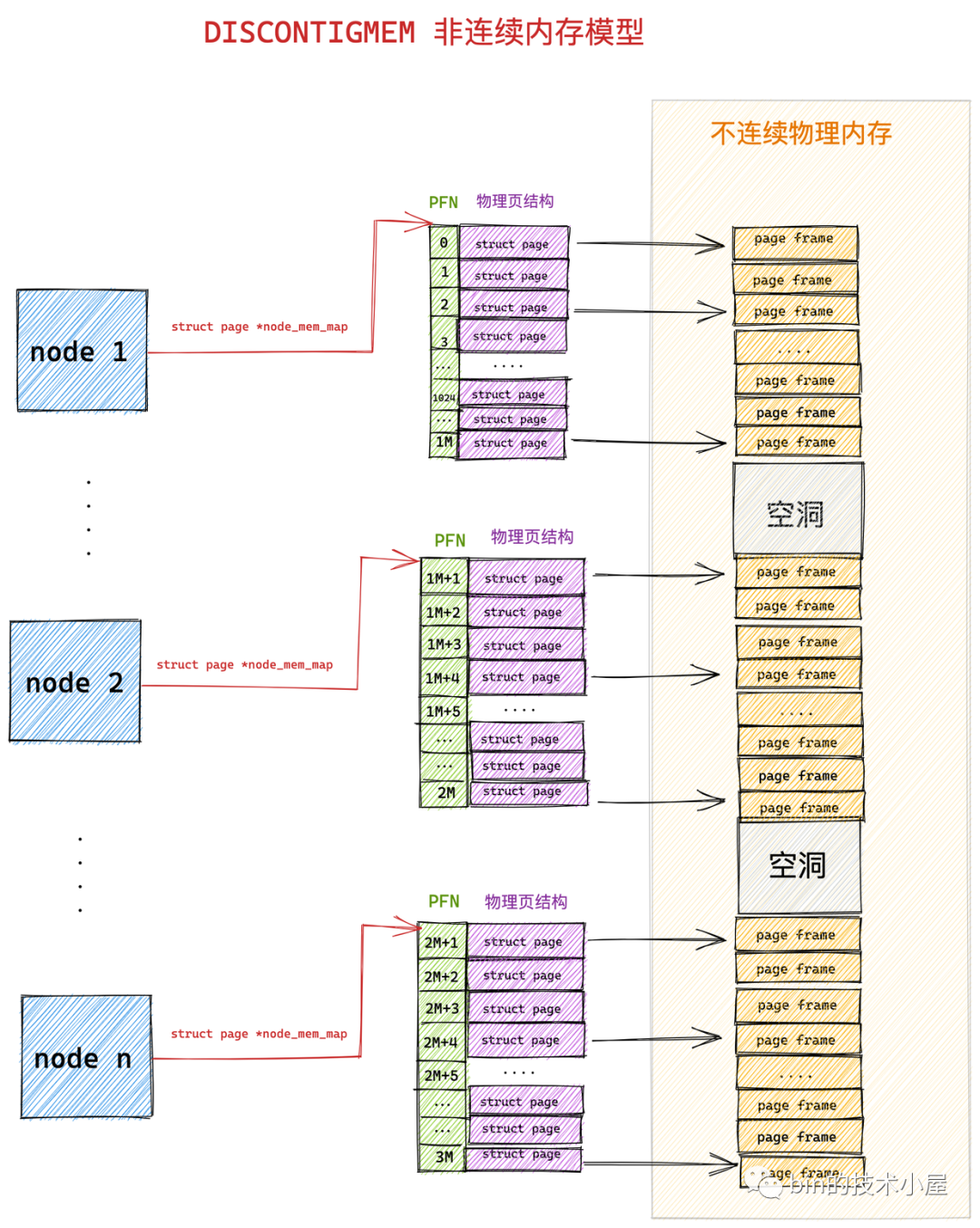
內核中使用 struct pglist_data 表示用於管理連續物理記憶體的 node 節點(內核假設 node 中的物理記憶體是連續的),既然每個 node 節點中的物理記憶體是連續的,於是在每個 node 節點中還是採用 FLATMEM 平坦記憶體模型的方式來組織管理物理記憶體頁。每個 node 節點中包含一個 struct page *node_mem_map 數組,用來組織管理 node 中的連續物理記憶體頁。
typedef struct pglist_data {
#ifdef CONFIG_FLATMEM
struct page *node_mem_map;
#endif
}
我們可以看出 DISCONTIGMEM 非連續記憶體模型其實就是 FLATMEM 平坦記憶體模型的一種擴展,在面對大塊不連續的物理記憶體管理時,通過將每段連續的物理記憶體區間劃歸到 node 節點中進行管理,避免了為記憶體地址空洞分配 struct page 結構,從而節省了記憶體資源的開銷。
由於引入了 node 節點這個概念,所以在 DISCONTIGMEM 非連續記憶體模型下 page_to_pfn 與 pfn_to_page 的計算邏輯就比 FLATMEM 記憶體模型下的計算邏輯多了一步定位 page 所在 node 的操作。
-
通過 arch_pfn_to_nid 可以根據物理頁的 PFN 定位到物理頁所在 node。
-
通過 page_to_nid 可以根據物理頁結構 struct page 定義到 page 所在 node。
當定位到物理頁 struct page 所在 node 之後,剩下的邏輯就和 FLATMEM 記憶體模型一模一樣了。
#if defined(CONFIG_DISCONTIGMEM)
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
unsigned long __nid = arch_pfn_to_nid(__pfn); \
NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
})
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
(unsigned long)(__pg - __pgdat->node_mem_map) + \
__pgdat->node_start_pfn; \
})
2.3 SPARSEMEM 稀疏記憶體模型
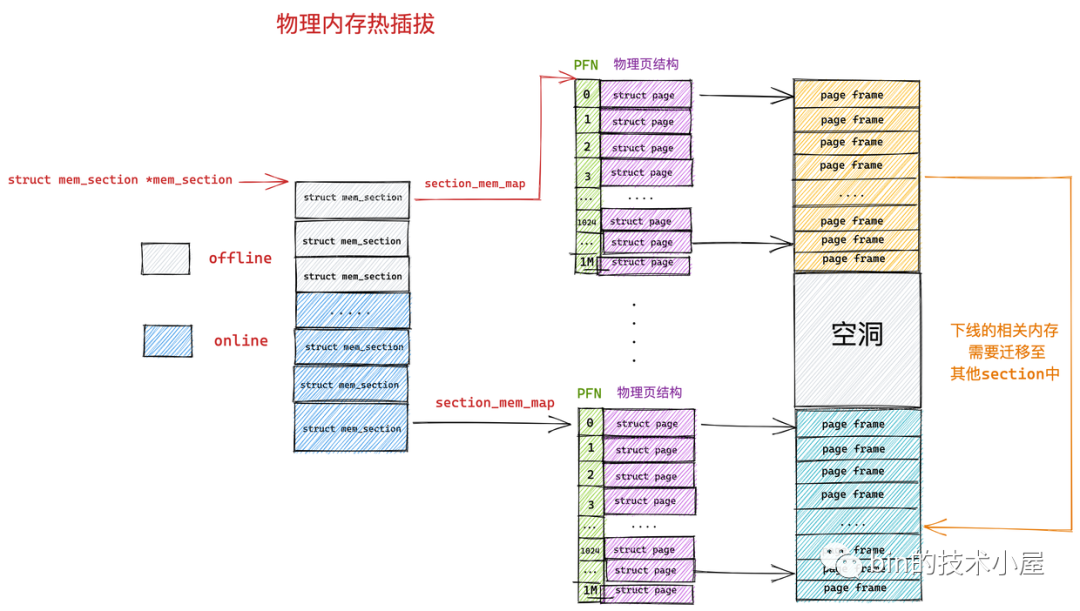
隨著記憶體技術的發展,內核可以支持物理記憶體的熱插拔了(後面筆者會介紹),這樣一來物理記憶體的不連續就變為常態了,在上小節介紹的 DISCONTIGMEM 記憶體模型中,其實每個 node 中的物理記憶體也不一定都是連續的。
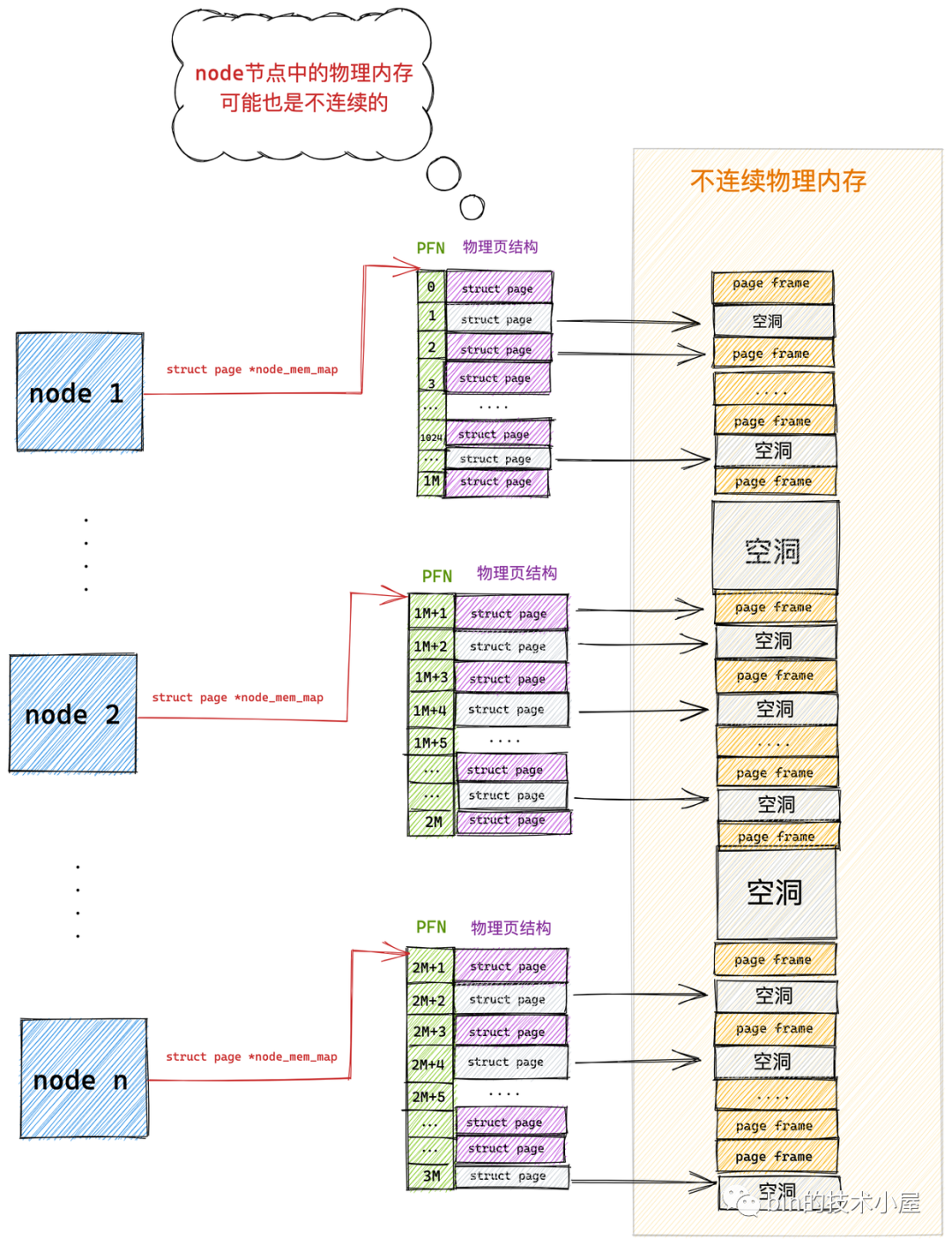
而且每個 node 中都有一套完整的記憶體管理系統,如果 node 數目多的話,那這個開銷就大了,於是就有了對連續物理記憶體更細粒度的管理需求,為了能夠更靈活地管理粒度更小的連續物理記憶體,SPARSEMEM 稀疏記憶體模型就此登場了。
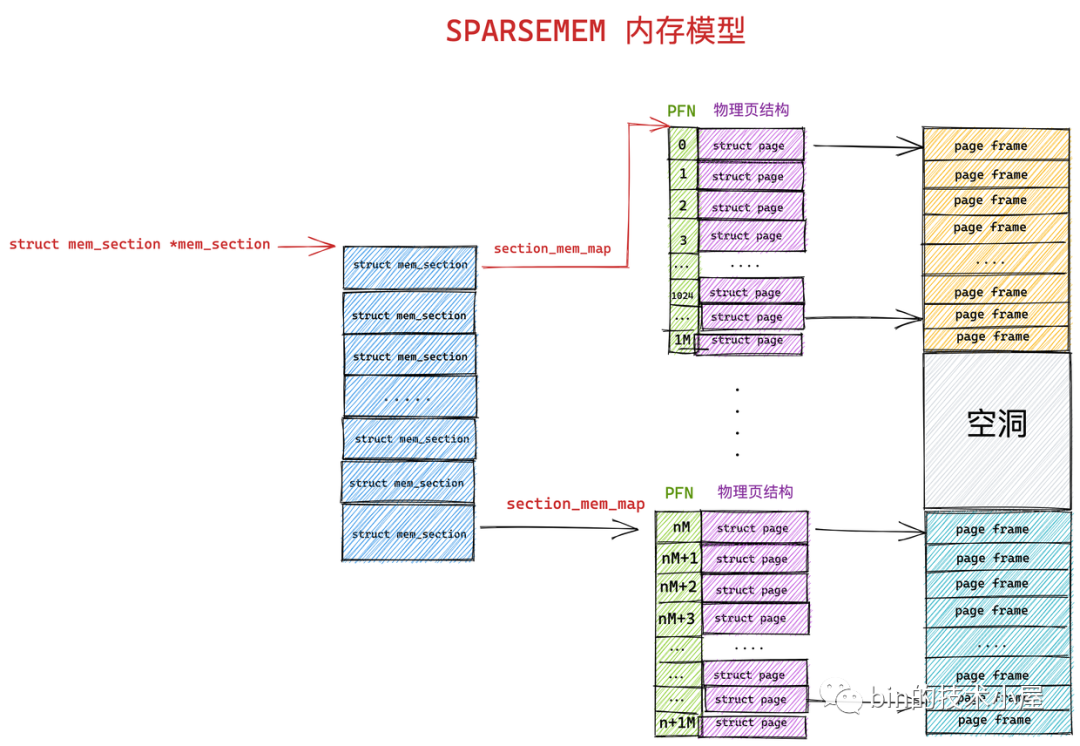
SPARSEMEM 稀疏記憶體模型的核心思想就是對粒度更小的連續記憶體塊進行精細的管理,用於管理連續記憶體塊的單元被稱作 section 。物理頁大小為 4k 的情況下, section 的大小為 128M ,物理頁大小為 16k 的情況下, section 的大小為 512M。
在內核中用 struct mem_section 結構體表示 SPARSEMEM 模型中的 section。
struct mem_section {
unsigned long section_mem_map;
...
}
由於 section 被用作管理小粒度的連續記憶體塊,這些小的連續物理記憶體在 section 中也是通過數組的方式被組織管理,每個 struct mem_section 結構體中有一個 section_mem_map 指針用於指向 section 中管理連續記憶體的 page 數組。
SPARSEMEM 記憶體模型中的這些所有的 mem_section 會被存放在一個全局的數組中,並且每個 mem_section 都可以在系統運行時改變 offline / online (下線 / 上線)狀態,以便支持記憶體的熱插拔(hotplug)功能。
#ifdef CONFIG_SPARSEMEM_EXTREME
extern struct mem_section *mem_section[NR_SECTION_ROOTS];
在 SPARSEMEM 稀疏記憶體模型下 page_to_pfn 與 pfn_to_page 的計算邏輯又發生了變化。
- 在 page_to_pfn 的轉換中,首先需要通過 page_to_section 根據 struct page 結構定位到 mem_section 數組中具體的 section 結構。然後在通過 section_mem_map 定位到具體的 PFN。
在 struct page 結構中有一個
unsigned long flags屬性,在 flag 的高位 bit 中存儲著 page 所在 mem_section 數組中的索引,從而可以定位到所屬 section。
- 在 pfn_to_page 的轉換中,首先需要通過 __pfn_to_section 根據 PFN 定位到 mem_section 數組中具體的 section 結構。然後在通過 PFN 在 section_mem_map 數組中定位到具體的物理頁 Page 。
PFN 的高位 bit 存儲的是全局數組 mem_section 中的 section 索引,PFN 的低位 bit 存儲的是 section_mem_map 數組中具體物理頁 page 的索引。
#if defined(CONFIG_SPARSEMEM)
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
#endif
從以上的內容介紹中,我們可以看出 SPARSEMEM 稀疏記憶體模型已經完全覆蓋了前兩個記憶體模型的所有功能,因此稀疏記憶體模型可被用於所有記憶體佈局的情況。
2.3.1 物理記憶體熱插拔
前面提到隨著記憶體技術的發展,物理記憶體的熱插拔 hotplug 在內核中得到了支持,由於物理記憶體可以動態的從主板中插入以及拔出,所以導致了物理記憶體的不連續已經成為常態,因此內核引入了 SPARSEMEM 稀疏記憶體模型以便應對這種情況,提供對更小粒度的連續物理記憶體的靈活管理能力。
本小節筆者就為大家介紹一下物理記憶體熱插拔 hotplug 功能在內核中的實現原理,作為 SPARSEMEM 稀疏記憶體模型的擴展內容補充。
在大規模的集群中,尤其是現在我們處於雲原生的時代,為了實現集群資源的動態均衡,可以通過物理記憶體熱插拔的功能實現集群機器物理記憶體容量的動態增減。
集群的規模一大,那麼物理記憶體出故障的幾率也會大大增加,物理記憶體的熱插拔對提供集群高可用性也是至關重要的。
從總體上來講,記憶體的熱插拔分為兩個階段:
-
物理熱插拔階段:這個階段主要是從物理上將記憶體硬體插入(hot-add),拔出(hot-remove)主板的過程,其中涉及到硬體和內核的支持。
-
邏輯熱插拔階段:這一階段主要是由內核中的記憶體管理子系統來負責,涉及到的主要工作為:如何動態的上線啟用(online)剛剛 hot-add 的記憶體,如何動態下線(offline)剛剛 hot-remove 的記憶體。
物理記憶體拔出的過程需要關註的事情比插入的過程要多的多,實現起來也更加的困難, 這就好比在《Java 技術棧中間件優雅停機方案設計與實現全景圖》 一文中我們討論服務優雅啟動,停機時提到的:優雅停機永遠比優雅啟動要考慮的場景要複雜的多,因為停機的時候,線上的服務正在承載著生產的流量需要確保做到業務無損。
同樣的道理,物理記憶體插入比較好說,困難的是物理記憶體的動態拔出,因為此時即將要被拔出的物理記憶體中可能已經為進程分配了物理頁,如何妥善安置這些已經被分配的物理頁是一個棘手的問題。
前邊我們介紹 SPARSEMEM 記憶體模型的時候提到,每個 mem_section 都可以在系統運行時改變 offline ,online 狀態,以便支持記憶體的熱插拔(hotplug)功能。 當 mem_section offline 時, 內核會把這部分記憶體隔離開, 使得該部分記憶體不可再被使用, 然後再把 mem_section 中已經分配的記憶體頁遷移到其他 mem_section 的記憶體上. 。
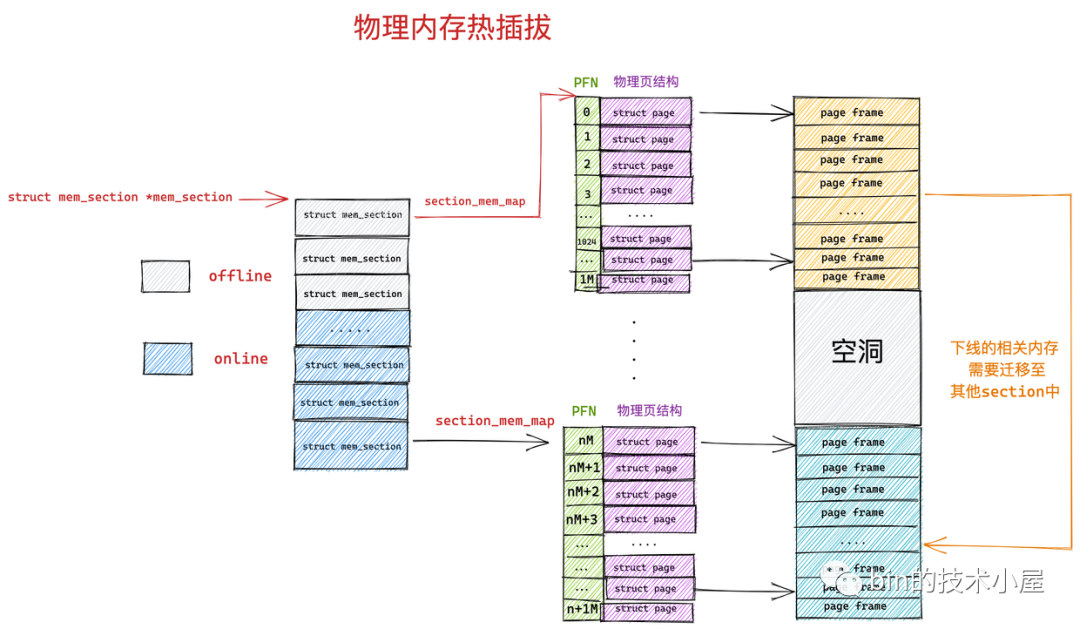
但是這裡會有一個問題,就是並非所有的物理頁都可以遷移,因為遷移意味著物理記憶體地址的變化,而記憶體的熱插拔應該對進程來說是透明的,所以這些遷移後的物理頁映射的虛擬記憶體地址是不能變化的。
這一點在進程的用戶空間是沒有問題的,因為進程在用戶空間訪問記憶體都是根據虛擬記憶體地址通過頁表找到對應的物理記憶體地址,這些遷移之後的物理頁,雖然物理記憶體地址發生變化,但是內核通過修改相應頁表中虛擬記憶體地址與物理記憶體地址之間的映射關係,可以保證虛擬記憶體地址不會改變。
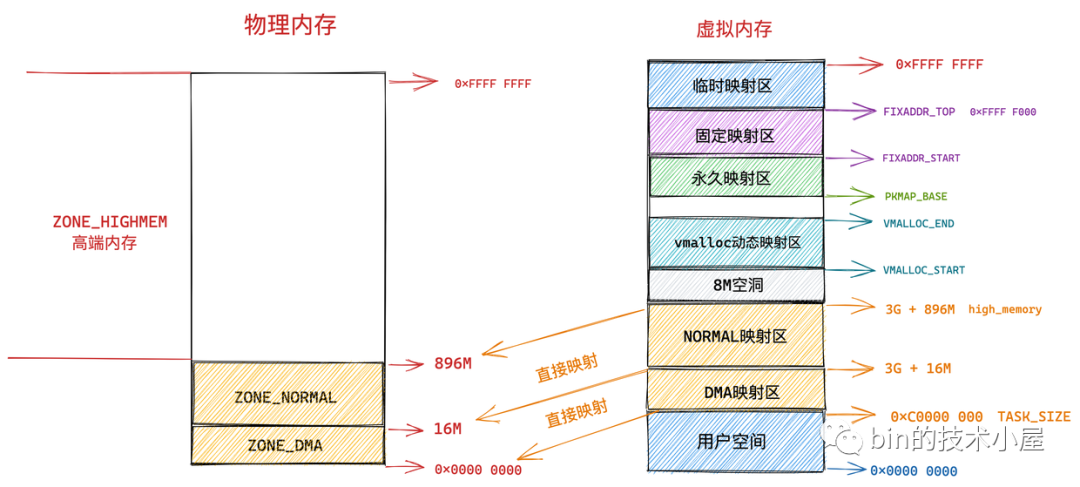
但是在內核態的虛擬地址空間中,有一段直接映射區,在這段虛擬記憶體區域中虛擬地址與物理地址是直接映射的關係,虛擬記憶體地址直接減去一個固定的偏移量(0xC000 0000 ) 就得到了物理記憶體地址。
直接映射區中的物理頁的虛擬地址會隨著物理記憶體地址變動而變動, 因此這部分物理頁是無法輕易遷移的,然而不可遷移的頁會導致記憶體無法被拔除,因為無法妥善安置被拔出記憶體中已經為進程分配的物理頁。那麼內核是如何解決這個頭疼的問題呢?
既然是這些不可遷移的物理頁導致記憶體無法拔出,那麼我們可以把記憶體分一下類,將記憶體按照物理頁是否可遷移,劃分為不可遷移頁,可回收頁,可遷移頁。
大家這裡需要記住一點,內核會將物理記憶體按照頁面是否可遷移的特性進行分類,筆者後面在介紹內核如何避免記憶體碎片的時候還會在提到
然後在這些可能會被拔出的記憶體中只分配那些可遷移的記憶體頁,這些信息會在記憶體初始化的時候被設置,這樣一來那些不可遷移的頁就不會包含在可能會拔出的記憶體中,當我們需要將這塊記憶體熱拔出時, 因為裡邊的記憶體頁全部是可遷移的, 從而使記憶體可以被拔除。
3. 從 CPU 角度看物理記憶體架構
在上小節中筆者為大家介紹了三種物理記憶體模型,這三種物理記憶體模型是從 CPU 的視角來看待物理記憶體內部是如何佈局,組織以及管理的,主角是物理記憶體。
在本小節中筆者為大家提供一個新的視角,這一次我們把物理記憶體看成一個整體,從 CPU 訪問物理記憶體的角度來看一下物理記憶體的架構,並從 CPU 與物理記憶體的相對位置變化來看一下不同物理記憶體架構下對性能的影響。
3.1 一致性記憶體訪問 UMA 架構
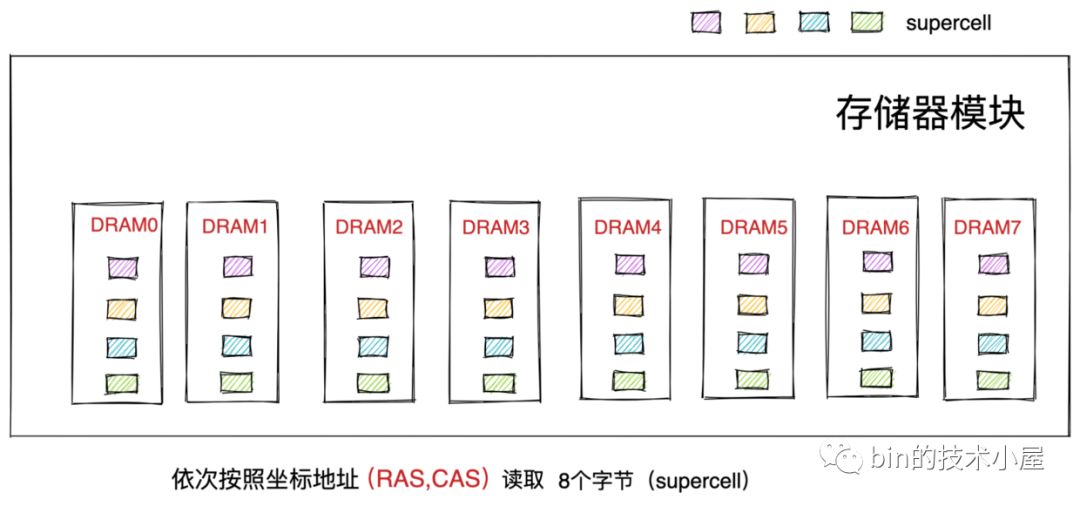
我們在上篇文章 《深入理解 Linux 虛擬記憶體管理》的 “ 8.2 CPU 如何讀寫主存” 小節中提到 CPU 與記憶體之間的交互是通過匯流排完成的。
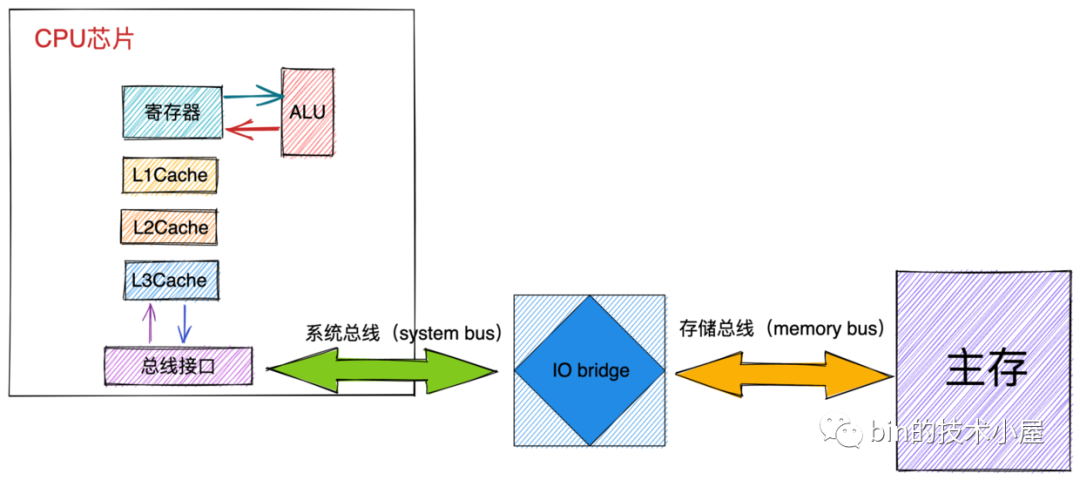
-
首先 CPU 將物理記憶體地址作為地址信號放到系統匯流排上傳輸。隨後 IO bridge 將系統匯流排上的地址信號轉換為存儲匯流排上的電子信號。
-
主存感受到存儲匯流排上的地址信號並通過存儲控制器將存儲匯流排上的物理記憶體地址 A 讀取出來。
-
存儲控制器通過物理記憶體地址定位到具體的存儲器模塊,從 DRAM 晶元中取出物理記憶體地址對應的數據。
-
存儲控制器將讀取到的數據放到存儲匯流排上,隨後 IO bridge 將存儲匯流排上的數據信號轉換為系統匯流排上的數據信號,然後繼續沿著系統匯流排傳遞。
-
CPU 晶元感受到系統匯流排上的數據信號,將數據從系統匯流排上讀取出來並拷貝到寄存器中。
上圖展示的是單核 CPU 訪問記憶體的架構圖,那麼在多核伺服器中多個 CPU 與記憶體之間的架構關係又是什麼樣子的呢?
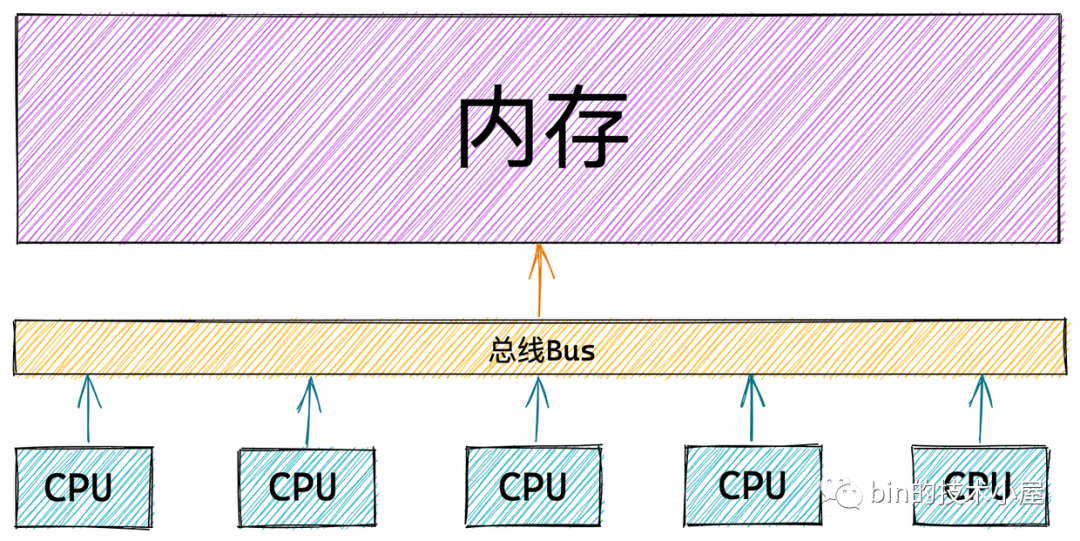
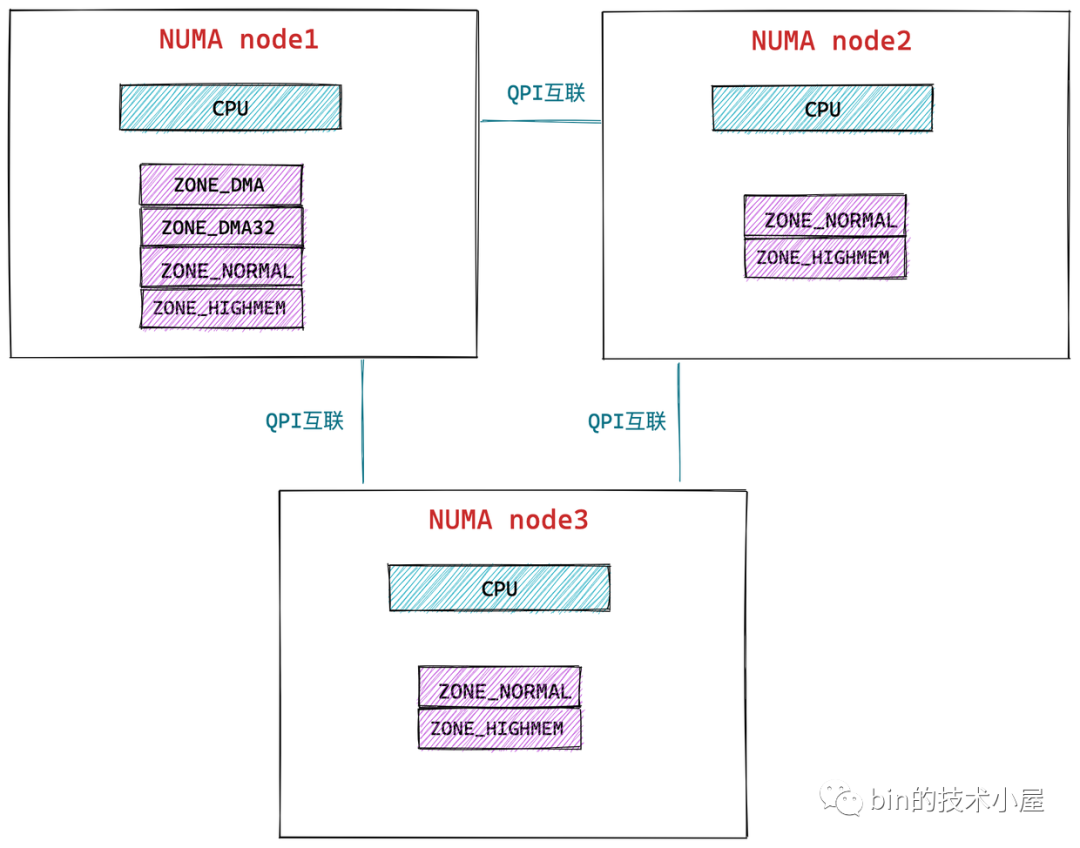
在 UMA 架構下,多核伺服器中的多個 CPU 位於匯流排的一側,所有的記憶體條組成一大片記憶體位於匯流排的另一側,所有的 CPU 訪問記憶體都要過匯流排,而且距離都是一樣的,由於所有 CPU 對記憶體的訪問距離都是一樣的,所以在 UMA 架構下所有 CPU 訪問記憶體的速度都是一樣的。這種訪問模式稱為 SMP(Symmetric multiprocessing),即對稱多處理器。
這裡的一致性是指同一個 CPU 對所有記憶體的訪問的速度是一樣的。即一致性記憶體訪問 UMA(Uniform Memory Access)。
但是隨著多核技術的發展,伺服器上的 CPU 個數會越來越多,而 UMA 架構下所有 CPU 都是需要通過匯流排來訪問記憶體的,這樣匯流排很快就會成為性能瓶頸,主要體現在以下兩個方面:
-
匯流排的帶寬壓力會越來越大,隨著 CPU 個數的增多導致每個 CPU 可用帶寬會減少
-
匯流排的長度也會因此而增加,進而增加訪問延遲
UMA 架構的優點很明顯就是結構簡單,所有的 CPU 訪問記憶體速度都是一致的,都必須經過匯流排。然而它的缺點筆者剛剛也提到了,就是隨著處理器核數的增多,匯流排的帶寬壓力會越來越大。解決辦法就只能擴寬匯流排,然而成本十分高昂,未來可能仍然面臨帶寬壓力。
為瞭解決以上問題,提高 CPU 訪問記憶體的性能和擴展性,於是引入了一種新的架構:非一致性記憶體訪問 NUMA(Non-uniform memory access)。
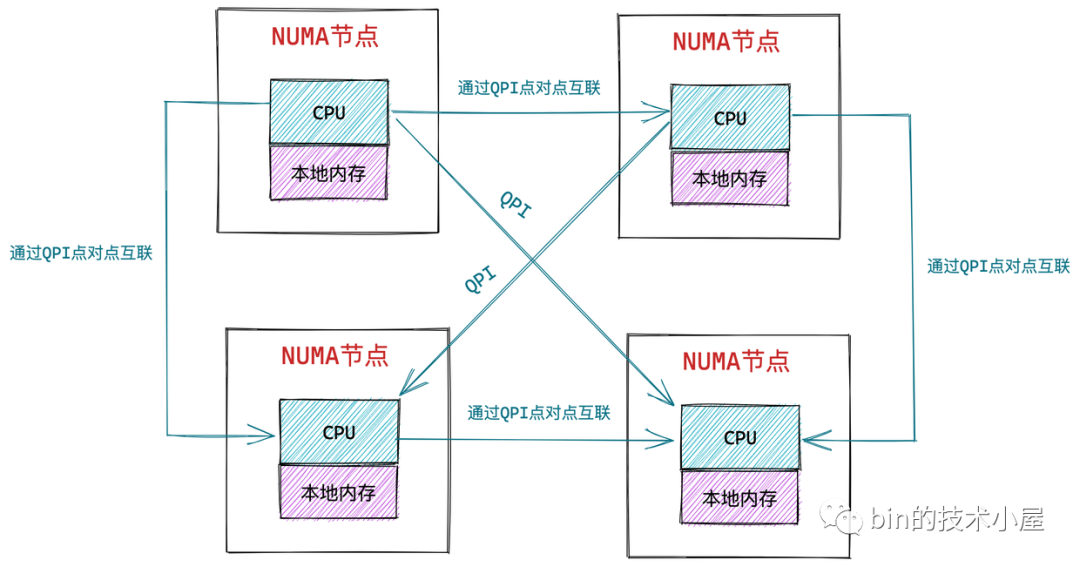
3.2 非一致性記憶體訪問 NUMA 架構
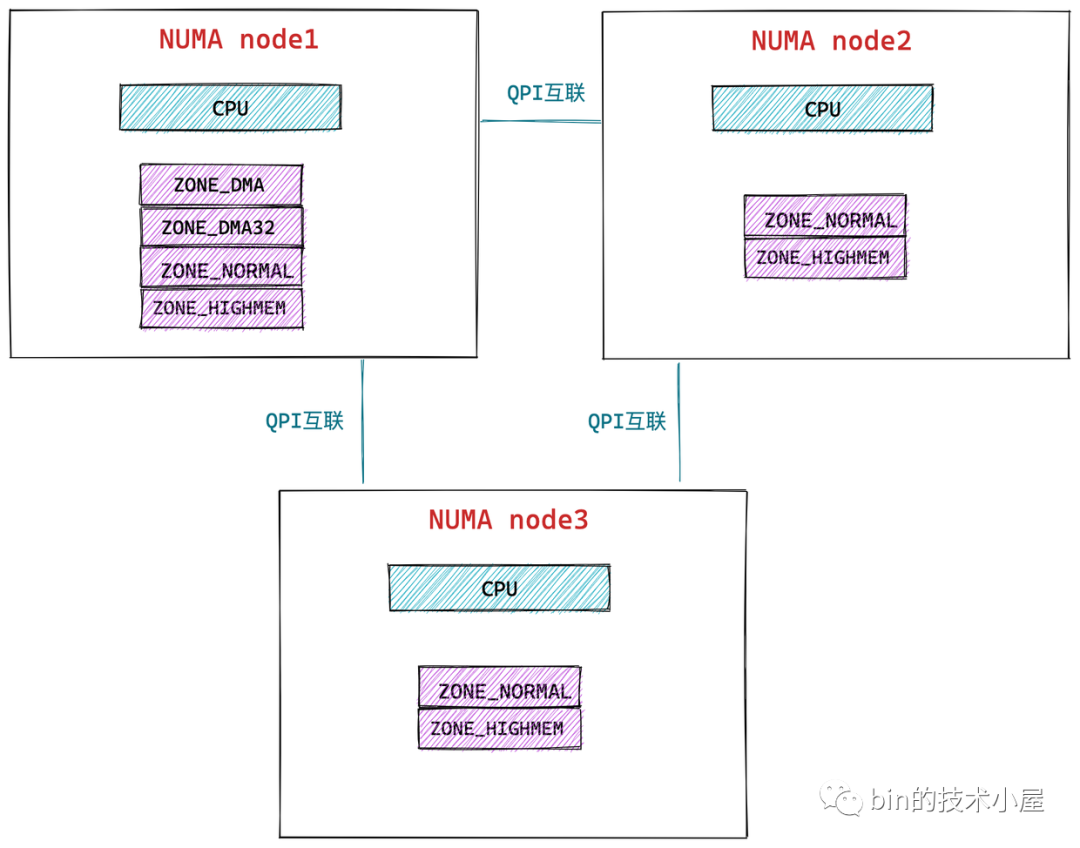
在 NUMA 架構下,記憶體就不是一整片的了,而是被劃分成了一個一個的記憶體節點 (NUMA 節點),每個 CPU 都有屬於自己的本地記憶體節點,CPU 訪問自己的本地記憶體不需要經過匯流排,因此訪問速度是最快的。當 CPU 自己的本地記憶體不足時,CPU 就需要跨節點去訪問其他記憶體節點,這種情況下 CPU 訪問記憶體就會慢很多。
在 NUMA 架構下,任意一個 CPU 都可以訪問全部的記憶體節點,訪問自己的本地記憶體節點是最快的,但訪問其他記憶體節點就會慢很多,這就導致了 CPU 訪問記憶體的速度不一致,所以叫做非一致性記憶體訪問架構。
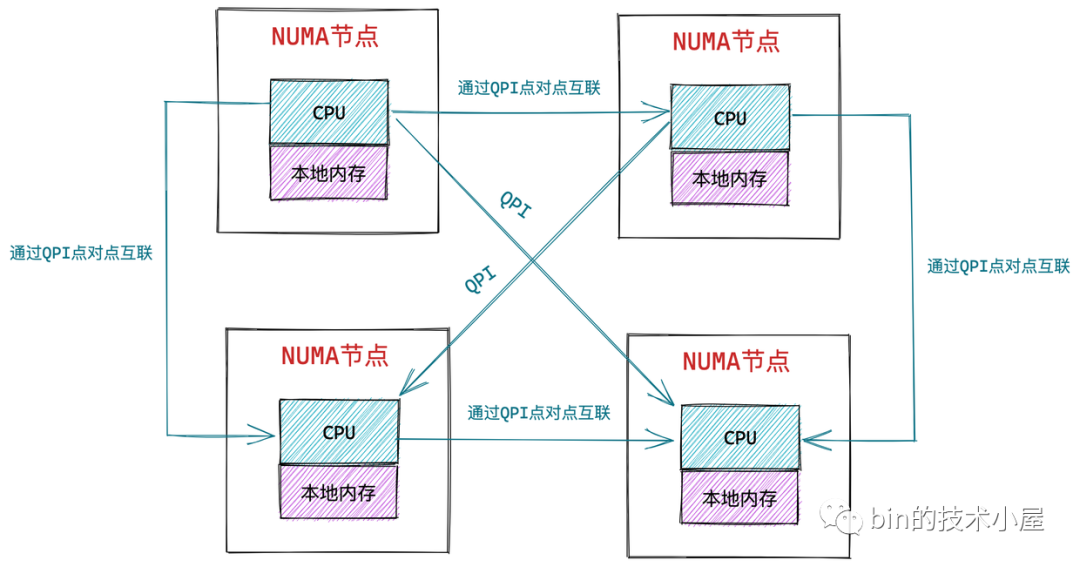
如上圖所示,CPU 和它的本地記憶體組成了 NUMA 節點,CPU 與 CPU 之間通過 QPI(Intel QuickPath Interconnect)點對點完成互聯,在 CPU 的本地記憶體不足的情況下,CPU 需要通過 QPI 訪問遠程 NUMA 節點上的記憶體控制器從而在遠程記憶體節點上分配記憶體,這就導致了遠程訪問比本地訪問多了額外的延遲開銷(需要通過 QPI 遍歷遠程 NUMA 節點)。
在 NUMA 架構下,只有 DISCONTIGMEM 非連續記憶體模型和 SPARSEMEM 稀疏記憶體模型是可用的。而 UMA 架構下,前面介紹的三種記憶體模型都可以配置使用。
3.2.1 NUMA 的記憶體分配策略
NUMA 的記憶體分配策略是指在 NUMA 架構下 CPU 如何請求記憶體分配的相關策略,比如:是優先請求本地記憶體節點分配記憶體呢 ?還是優先請求指定的 NUMA 節點分配記憶體 ?是只能在本地記憶體節點分配呢 ?還是允許當本地記憶體不足的情況下可以請求遠程 NUMA 節點分配記憶體 ?
| 記憶體分配策略 | 策略描述 |
|---|---|
| MPOL_BIND | 必須在綁定的節點進行記憶體分配,如果記憶體不足,則進行 swap |
| MPOL_INTERLEAVE | 本地節點和遠程節點均可允許分配記憶體 |
| MPOL_PREFERRED | 優先在指定節點分配記憶體,當指定節點記憶體不足時,選擇離指定節點最近的節點分配記憶體 |
| MPOL_LOCAL (預設) | 優先在本地節點分配,當本地節點記憶體不足時,可以在遠程節點分配記憶體 |
我們可以在應用程式中通過 libnuma 共用庫中的 API 調用 set_mempolicy 介面設置進程的記憶體分配策略。
#include <numaif.h>
long set_mempolicy(int mode, const unsigned long *nodemask,
unsigned long maxnode);
-
mode : 指定 NUMA 記憶體分配策略。
-
nodemask:指定 NUMA 節點 Id。
-
maxnode:指定最大 NUMA 節點 Id,用於遍歷遠程節點,實現跨 NUMA 節點分配記憶體。
libnuma 共用庫 API 文檔:https://man7.org/linux/man-pages/man3/numa.3.html#top_of_page
set_mempolicy 介面文檔:https://man7.org/linux/man-pages/man2/set_mempolicy.2.html
3.2.2 NUMA 的使用簡介
在我們理解了物理記憶體的 NUMA 架構,以及在 NUMA 架構下的記憶體分配策略之後,本小節筆者來為大家介紹下如何正確的利用 NUMA 提升我們應用程式的性能。
前邊我們介紹了這麼多的理論知識,但是理論的東西總是很虛,正所謂眼見為實,大家一定想親眼看一下 NUMA 架構在電腦中的具體表現形式,比如:在支持 NUMA 架構的機器上到底有多少個 NUMA 節點?每個 NUMA 節點包含哪些 CPU 核,具體是怎樣的一個分佈情況?
前面也提到 CPU 在訪問本地 NUMA 節點中的記憶體時,速度是最快的。但是當訪問遠程 NUMA 節點,速度就會相對很慢,那麼到底有多慢?本地節點與遠程節點之間的訪問速度差異具體是多少 ?
3.2.2.1 查看 NUMA 相關信息
numactl 文檔:https://man7.org/linux/man-pages/man8/numactl.8.html
針對以上具體問題,numactl -H 命令可以給出我們想要的答案:
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
node 0 size: 64794 MB
node 0 free: 55404 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
node 1 size: 65404 MB
node 1 free: 58642 MB
node 2 cpus: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 2 size: 65404 MB
node 2 free: 61181 MB
node 3 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 3 size: 65402 MB
node 3 free: 55592 MB
node distances:
node 0 1 2 3
0: 10 16 32 33
1: 16 10 25 32
2: 32 25 10 16
3: 33 32 16 10
numactl -H 命令可以查看伺服器的 NUMA 配置,上圖中的伺服器配置共包含 4 個 NUMA 節點(0 - 3),每個 NUMA 節點中包含 16個 CPU 核心,本地記憶體大小約為 64G。
大家可以關註下最後 node distances: 這一欄,node distances 給出了不同 NUMA 節點之間的訪問距離,對角線上的值均為本地節點的訪問距離 10 。比如 [0,0] 表示 NUMA 節點 0 的本地記憶體訪問距離。
我們可以很明顯的看到當出現跨 NUMA 節點訪問的時候,訪問距離就會明顯增加,比如節點 0 訪問節點 1 的距離 [0,1] 是16,節點 0 訪問節點 3 的距離 [0,3] 是 33。距離越遠,跨 NUMA 節點記憶體訪問的延時越大。應用程式運行時應減少跨 NUMA 節點訪問記憶體。
此外我們還可以通過 numactl -s 來查看 NUMA 的記憶體分配策略設置:
policy: default
preferred node: current
通過 numastat 還可以查看各個 NUMA 節點的記憶體訪問命中率:
node0 node1 node2 node3
numa_hit 1296554257 918018444 1296574252 828018454
numa_miss 8541758 40297198 7544751 41267108
numa_foreign 40288595 8550361 41488585 8450375
interleave_hit 45651 45918 46654 49718
local_node 1231897031 835344122 1141898045 915354158
other_node 64657226 82674322 594657725 82675425
-
numa_hit :記憶體分配在該節點中成功的次數。
-
numa_miss : 記憶體分配在該節點中失敗的次數。
-
numa_foreign:表示其他 NUMA 節點本地記憶體分配失敗,跨節點(numa_miss)來到本節點分配記憶體的次數。
-
interleave_hit : 在 MPOL_INTERLEAVE 策略下,在本地節點分配記憶體的次數。
-
local_node:進程在本地節點分配記憶體成功的次數。
-
other_node:運行在本節點的進程跨節點在其他節點上分配記憶體的次數。
numastat 文檔:https://man7.org/linux/man-pages/man8/numastat.8.html
3.2.2.2 綁定 NUMA 節點
numactl 工具可以讓我們應用程式指定運行在哪些 CPU 核心上,同時也可以指定我們的應用程式可以在哪些 NUMA 節點上分配記憶體。通過將應用程式與具體的 CPU 核心和 NUMA 節點綁定,從而可以提升程式的性能。
numactl --membind=nodes --cpunodebind=nodes command
-
通過
--membind可以指定我們的應用程式只能在哪些具體的 NUMA 節點上分配記憶體,如果這些節點記憶體不足,則分配失敗。 -
通過
--cpunodebind可以指定我們的應用程式只能運行在哪些 NUMA 節點上。
numactl --physcpubind=cpus command
另外我們還可以通過 --physcpubind 將我們的應用程式綁定到具體的物理 CPU 上。這個選項後邊指定的參數我們可以通過 cat /proc/cpuinfo 輸出信息中的 processor 這一欄查看。例如:通過 numactl --physcpubind= 0-15 ./numatest.out 命令將進程 numatest 綁定到 0~15 CPU 上執行。
我們可以通過 numactl 命令將 numatest 進程分別綁定在相同的 NUMA 節點上和不同的 NUMA 節點上,運行觀察。
numactl --membind=0 --cpunodebind=0 ./numatest.out
numactl --membind=0 --cpunodebind=1 ./numatest.out
大家肯定一眼就能看出綁定在相同 NUMA 節點的進程運行會更快,因為通過前邊對 NUMA 架構的介紹,我們知道 CPU 訪問本地 NUMA 節點的記憶體是最快的。
除了 numactl 這個工具外,我們還可以通過共用庫 libnuma 在程式中進行 NUMA 相關的操作。這裡筆者就不演示了,感興趣可以查看下 libnuma 的 API 文檔:https://man7.org/linux/man-pages/man3/numa.3.html#top_of_page
4. 內核如何管理 NUMA 節點
在前邊我們介紹物理記憶體模型和物理記憶體架構的時候提到過:在 NUMA 架構下,只有 DISCONTIGMEM 非連續記憶體模型和 SPARSEMEM 稀疏記憶體模型是可用的。而 UMA 架構下,前面介紹的三種記憶體模型均可以配置使用。
無論是 NUMA 架構還是 UMA 架構在內核中都是使用相同的數據結構來組織管理的,在內核的記憶體管理模塊中會把 UMA 架構當做只有一個 NUMA 節點的偽 NUMA 架構。這樣一來這兩種架構模式就在內核中被統一管理起來。
下麵筆者先從最頂層的設計開始為大家介紹一下內核是如何管理這些 NUMA 節點的~~
NUMA 節點中可能會包含多個 CPU,這些 CPU 均是物理 CPU,這點大家需要註意一下。
4.1 內核如何統一組織 NUMA 節點
首先我們來看第一個問題,在內核中是如何將這些 NUMA 節點統一管理起來的?
內核中使用了 struct pglist_data 這樣的一個數據結構來描述 NUMA 節點,在內核 2.4 版本之前,內核是使用一個 pgdat_list 單鏈表將這些 NUMA 節點串聯起來的,單鏈表定義在 /include/linux/mmzone.h 文件中:
extern pg_data_t *pgdat_list;
每個 NUMA 節點的數據結構 struct pglist_data 中有一個 next 指針,用於將這些 NUMA 節點串聯起來形成 pgdat_list 單鏈表,鏈表的末尾節點 next 指針指向 NULL。
typedef struct pglist_data {
struct pglist_data *pgdat_next;
}
在內核 2.4 之後的版本中,內核移除了 struct pglist_data 結構中的 pgdat_next 之指針, 同時也刪除了 pgdat_list 單鏈表。取而代之的是,內核使用了一個大小為 MAX_NUMNODES ,類型為 struct pglist_data 的全局數組 node_data[] 來管理所有的 NUMA 節點。
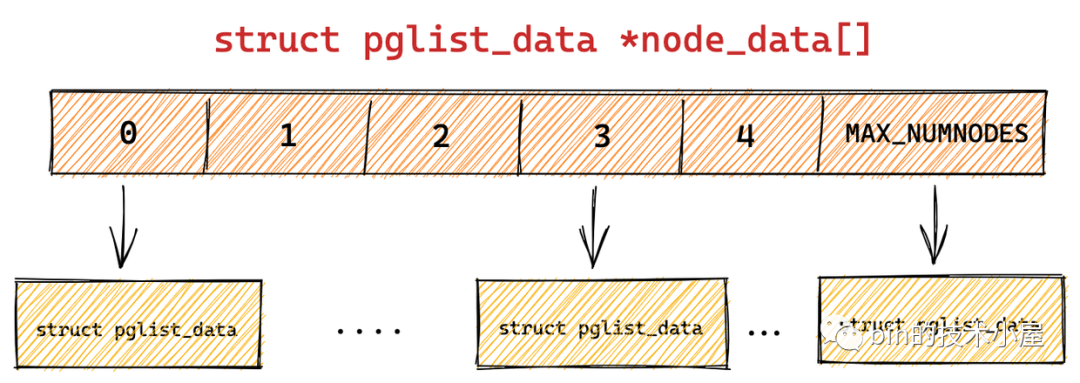
全局數組 node_data[] 定義在文件 /arch/arm64/include/asm/mmzone.h中:
#ifdef CONFIG_NUMA
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[(nid)])
NODE_DATA(nid) 巨集可以通過 NUMA 節點的 nodeId,找到對應的 struct pglist_data 結構。
node_data[] 數組大小 MAX_NUMNODES 定義在 /include/linux/numa.h文件中:
#ifdef CONFIG_NODES_SHIFT
#define NODES_SHIFT CONFIG_NODES_SHIFT
#else
#define NODES_SHIFT 0
#endif
#define MAX_NUMNODES (1 << NODES_SHIFT)
UMA 架構下 NODES_SHIFT 為 0 ,所以內核中只用一個 NUMA 節點來管理所有物理記憶體。
4.2 NUMA 節點描述符 pglist_data 結構
typedef struct pglist_data {
// NUMA 節點id
int node_id;
// 指向 NUMA 節點內管理所有物理頁 page 的數組
struct page *node_mem_map;
// NUMA 節點內第一個物理頁的 pfn
unsigned long node_start_pfn;
// NUMA 節點內所有可用的物理頁個數(不包含記憶體空洞)
unsigned long node_present_pages;
// NUMA 節點內所有的物理頁個數(包含記憶體空洞)
unsigned long node_spanned_pages;
// 保證多進程可以併發安全的訪問 NUMA 節點
spinlock_t node_size_lock;
.............
}
node_id 表示 NUMA 節點的 id,我們可以通過 numactl -H 命令的輸出結果查看節點 id。從 0 開始依次對 NUMA 節點進行編號。
struct page 類型的數組 node_mem_map 中包含了 NUMA節點內的所有的物理記憶體頁。
node_start_pfn 指向 NUMA 節點內第一個物理頁的 PFN,系統中所有 NUMA 節點中的物理頁都是依次編號的,每個物理頁的 PFN 都是全局唯一的(不只是其所在 NUMA 節點內唯一)
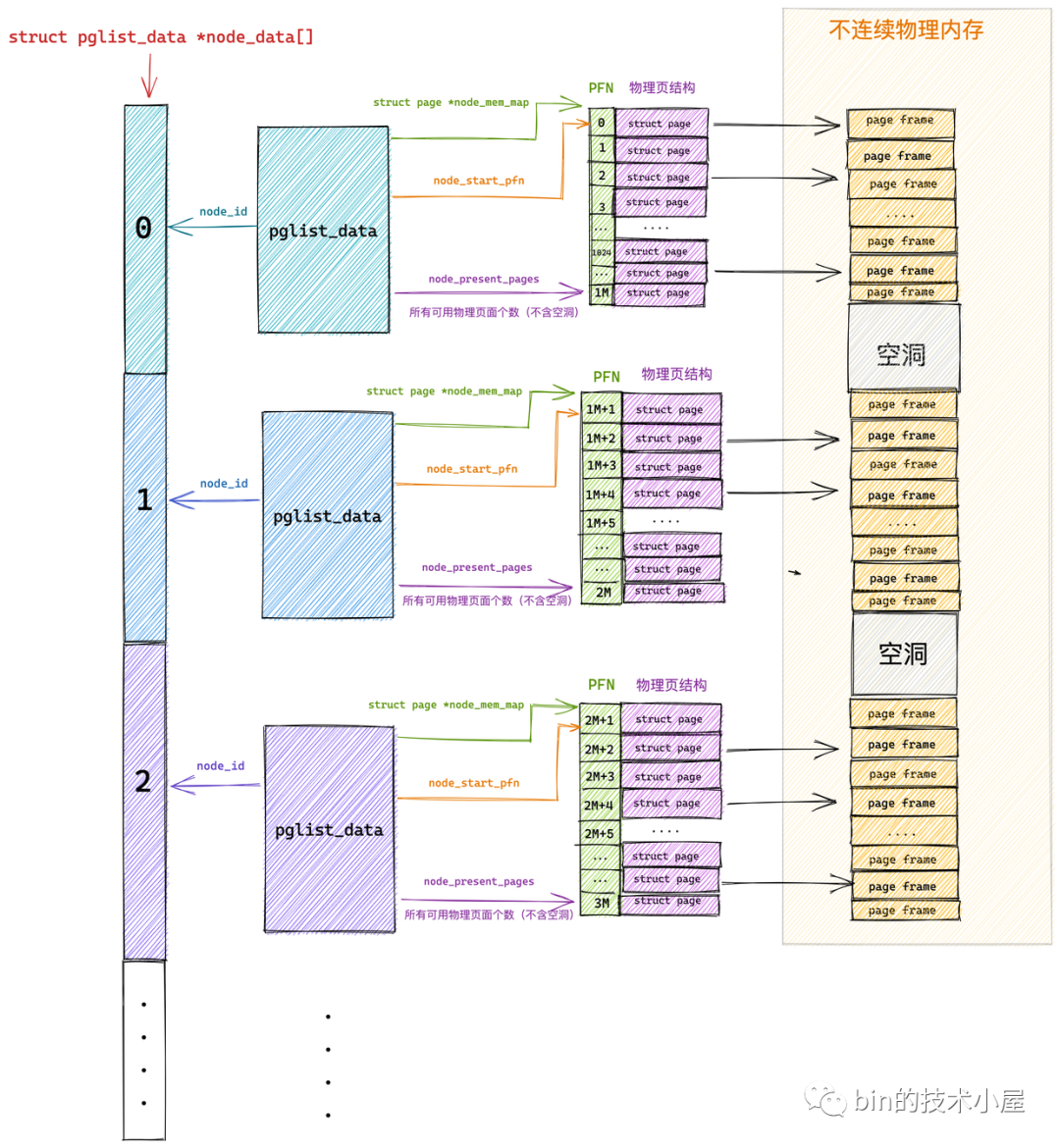
node_present_pages 用於統計 NUMA 節點內所有真正可用的物理頁面數量(不包含記憶體空洞)。
由於 NUMA 節點內包含的物理記憶體並不總是連續的,可能會包含一些記憶體空洞,node_spanned_pages 則是用於統計 NUMA 節點內所有的記憶體頁,包含不連續的物理記憶體地址(記憶體空洞)的頁面數。
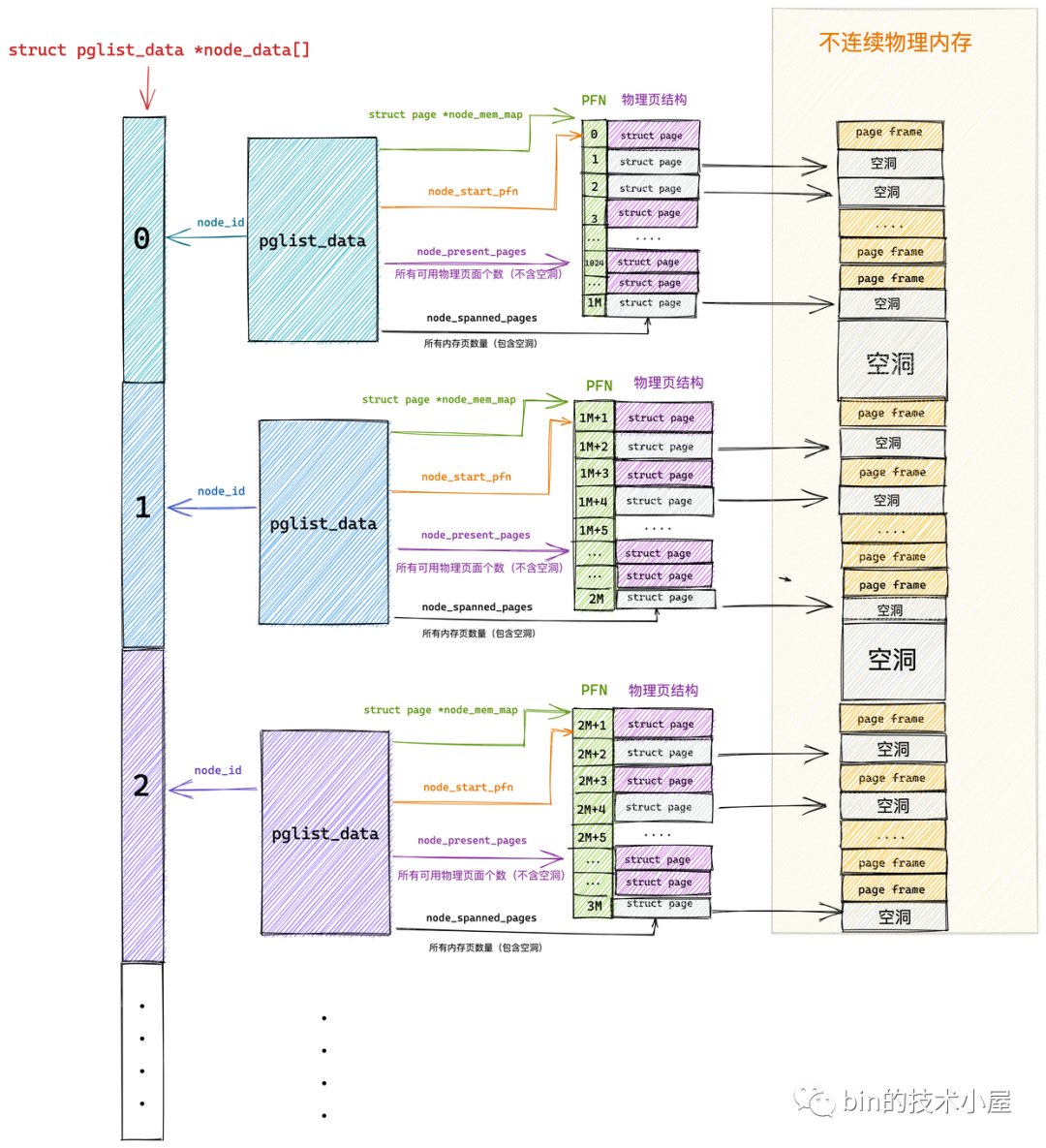
以上內容是筆者從整體上為大家介紹的 NUMA 節點如何管理節點內部的本地記憶體。事實上內核還會將 NUMA 節點中的本地記憶體做近一步的劃分。那麼為什麼要近一步劃分呢?
4.3 NUMA 節點物理記憶體區域的劃分
我們都知道內核對物理記憶體的管理都是以頁為最小單位來管理的,每頁預設 4K 大小,理想狀況下任何種類的數據都可以存放在任何頁框中,沒有什麼限制。比如:存放內核數據,用戶數據,磁碟緩衝數據等。
但是實際的電腦體繫結構受到硬體方面的制約,間接導致限制了頁框的使用方式。
比如在 X86 體繫結構下,ISA 匯流排的 DMA (直接記憶體存取)控制器,只能對記憶體的前16M 進行定址,這就導致了 ISA 設備不能在整個 32 位地址空間中執行 DMA,只能使用物理記憶體的前 16M 進行 DMA 操作。
因此直接映射區的前 16M 專門讓內核用來為 DMA 分配記憶體,這塊 16M 大小的記憶體區域我們稱之為 ZONE_DMA。
用於 DMA 的記憶體必須從 ZONE_DMA 區域中分配。
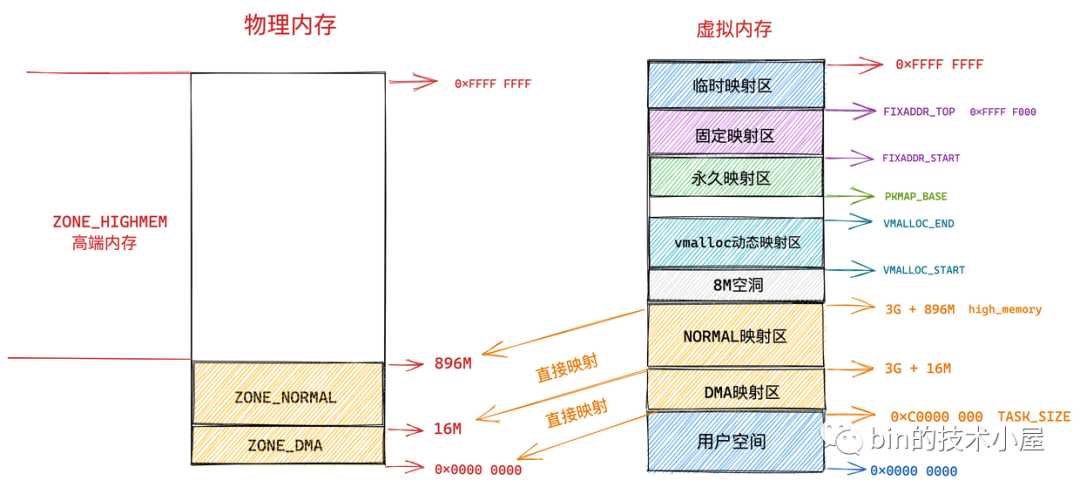
而直接映射區中剩下的部分也就是從 16M 到 896M(不包含 896M)這段區域,我們稱之為 ZONE_NORMAL。從字面意義上我們可以瞭解到,這塊區域包含的就是正常的頁框(沒有任何使用限制)。
ZONE_NORMAL 由於也是屬於直接映射區的一部分,對應的物理記憶體 16M 到 896M 這段區域也是被直接映射至內核態虛擬記憶體空間中的 3G + 16M 到 3G + 896M 這段虛擬記憶體上。
而物理記憶體 896M 以上的區域被內核劃分為 ZONE_HIGHMEM 區域,我們稱之為高端記憶體。
由於內核虛擬記憶體空間中的前 896M 虛擬記憶體已經被直接映射區所占用,而在 32 體繫結構下內核虛擬記憶體空間總共也就 1G 的大小,這樣一來內核剩餘可用的虛擬記憶體空間就變為了 1G - 896M = 128M。
顯然物理記憶體中剩下的這 3200M 大小的 ZONE_HIGHMEM 區域無法繼續通過直接映射的方式映射到這 128M 大小的虛擬記憶體空間中。
這樣一來物理記憶體中的 ZONE_HIGHMEM 區域就只能採用動態映射的方式映射到 128M 大小的內核虛擬記憶體空間中,也就是說只能動態的一部分一部分的分批映射,先映射正在使用的這部分,使用完畢解除映射,接著映射其他部分。
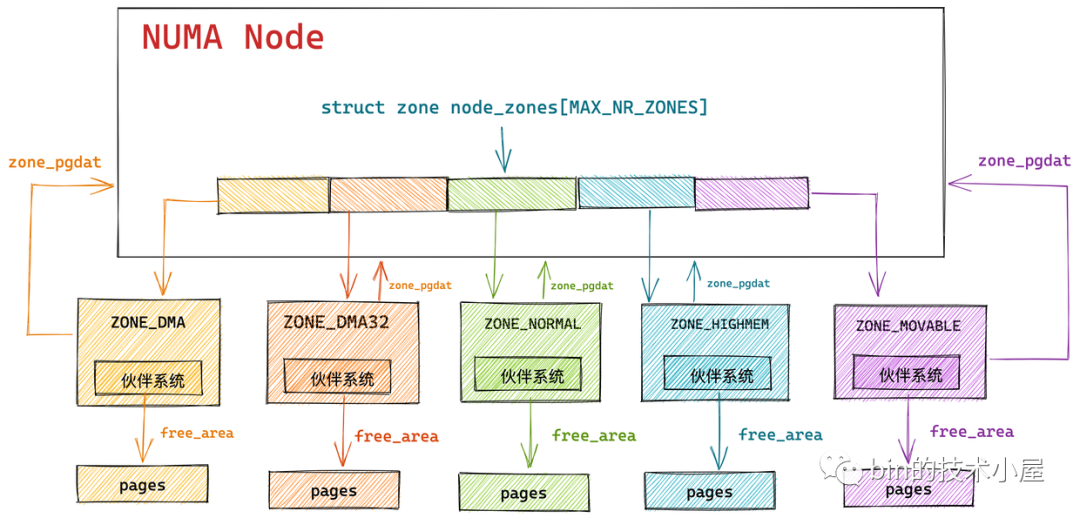
所以內核會根據各個物理記憶體區域的功能不同,將 NUMA 節點內的物理記憶體主要劃分為以下四個物理記憶體區域:
-
ZONE_DMA:用於那些無法對全部物理記憶體進行定址的硬體設備,進行 DMA 時的記憶體分配。例如前邊介紹的 ISA 設備只能對物理記憶體的前 16M 進行定址。該區域的長度依賴於具體的處理器類型。
-
ZONE_DMA32:與 ZONE_DMA 區域類似,該區域內的物理頁面可用於執行 DMA 操作,不同之處在於該區域是提供給 32 位設備(只能定址 4G 物理記憶體)執行 DMA 操作時使用的。該區域只在 64 位系統中起作用,因為只有在 64 位系統中才會專門為 32 位設備提供專門的 DMA 區域。
-
ZONE_NORMAL:這個區域的物理頁都可以直接映射到內核中的虛擬記憶體,由於是線性映射,內核可以直接進行訪問。
-
ZONE_HIGHMEM:這個區域包含的物理頁就是我們說的高端記憶體,內核不能直接訪問這些物理頁,這些物理頁需要動態映射進內核虛擬記憶體空間中(非線性映射)。該區域只在 32 位系統中才會存在,因為 64 位系統中的內核虛擬記憶體空間太大了(128T),都可以進行直接映射。
以上這些物理記憶體區域的劃分定義在 /include/linux/mmzone.h 文件中:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
// 充當結束標記, 在內核中想要迭代系統中所有記憶體域時, 會用到該常量
__MAX_NR_ZONES
};
大家可能註意到內核中定義的 zone_type 除了上邊為大家介紹的四個物理記憶體區域,又多出了兩個區域:ZONE_MOVABLE 和 ZONE_DEVICE。
ZONE_DEVICE 是為支持熱插拔設備而分配的非易失性記憶體( Non Volatile Memory ),也可用於內核崩潰時保存相關的調試信息。
ZONE_MOVABLE 是內核定義的一個虛擬記憶體區域,該區域中的物理頁可以來自於上邊介紹的幾種真實的物理區域。該區域中的頁全部都是可以遷移的,主要是為了防止記憶體碎片和支持記憶體的熱插拔。
既然有了這些實際的物理記憶體區域,那麼內核為什麼又要劃分出一個 ZONE_MOVABLE 這樣的虛擬記憶體區域呢 ?
因為隨著系統的運行會伴隨著不同大小的物理記憶體頁的分配和釋放,這種記憶體不規則的分配釋放隨著系統的長時間運行就會導致記憶體碎片,記憶體碎片會使得系統在明明有足夠記憶體的情況下,依然無法為進程分配合適的記憶體。

如上圖所示,假如現在系統一共有 16 個物理記憶體頁,當前系統只是分配了 3 個物理頁,那麼在當前系統中還剩餘 13 個物理記憶體頁的情況下,如果內核想要分配 8 個連續的物理頁的話,就會由於記憶體碎片的存在導致分配失敗。(只能分配最多 4 個連續的物理頁)
內核中請求分配的物理頁面數只能是 2 的次冪!!
如果這些物理頁處於 ZONE_MOVABLE 區域,它們就可以被遷移,內核可以通過遷移頁面來避免記憶體碎片的問題:

內核通過遷移頁面來規整記憶體,這樣就可以避免記憶體碎片,從而得到一大片連續的物理記憶體,以滿足內核對大塊連續記憶體分配的請求。所以這就是內核需要根據物理頁面是否能夠遷移的特性,而劃分出 ZONE_MOVABLE 區域的目的。
到這裡,我們已經清楚了 NUMA 節點中物理記憶體區域的劃分,下麵我們繼續回到 struct pglist_data 結構中看下內核如何在 NUMA 節點中組織這些劃分出來的記憶體區域:
typedef struct pglist_data {
// NUMA 節點中的物理記憶體區域個數
int nr_zones;
// NUMA 節點中的物理記憶體區域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 節點的備用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
} pg_data_t;
nr_zones 用於統計 NUMA 節點內包含的物理記憶體區域個數,不是每個 NUMA 節點都會包含以上介紹的所有物理記憶體區域,NUMA 節點之間所包含的物理記憶體區域個數是不一樣的。
事實上只有第一個 NUMA 節點可以包含所有的物理記憶體區域,其它的節點並不能包含所有的區域類型,因為有些記憶體區域比如:ZONE_DMA,ZONE_DMA32 必須從物理記憶體的起點開始。這些在物理記憶體開始的區域可能已經被劃分到第一個 NUMA 節點了,後面的物理記憶體才會被依次劃分給接下來的 NUMA 節點。因此後面的 NUMA 節點並不會包含 ZONE_DMA,ZONE_DMA32 區域。
ZONE_NORMAL、ZONE_HIGHMEM 和 ZONE_MOVABLE 是可以出現在所有 NUMA 節點上的。
node_zones[MAX_NR_ZONES] 數組包含了 NUMA 節點中的所有物理記憶體區域,物理記憶體區域在內核中的數據結構是 struct zone 。
node_zonelists[MAX_ZONELISTS] 是 struct zonelist 類型的數組,它包含了備用 NUMA 節點和這些備用節點中的物理記憶體區域。備用節點是按照訪問距離的遠近,依次排列在 node_zonelists 數組中,數組第一個備用節點是訪問距離最近的,這樣當本節點記憶體不足時,可以從備用 NUMA 節點中分配記憶體。
各個 NUMA 節點之間的記憶體分配情況我們可以通過前邊介紹的
numastat命令查看。
4.4 NUMA 節點中的記憶體規整與回收
記憶體可以說是電腦系統中最為寶貴的資源了,再怎麼多也不夠用,當系統運行時間長了之後,難免會遇到記憶體緊張的時候,這時候就需要內核將那些不經常使用的記憶體頁面回收起來,或者將那些可以遷移的頁面進行記憶體規整,從而可以騰出連續的物理記憶體頁面供內核分配。
內核會為每個 NUMA 節點分配一個 kswapd 進程用於回收不經常使用的頁面,還會為每個 NUMA 節點分配一個 kcompactd 進程用於記憶體的規整避免記憶體碎片。
typedef struct pglist_data {
.........
// 頁面回收進程
struct task_struct *kswapd;
wait_queue_head_t kswapd_wait;
// 記憶體規整進程
struct task_struct *kcompactd;
wait_queue_head_t kcompactd_wait;
..........
} pg_data_t;
NUMA 節點描述符 struct pglist_data 結構中的 struct task_struct *kswapd 屬性用於指向內核為 NUMA 節點分配的 kswapd 進程。
kswapd_wait 用於 kswapd 進程周期性回收頁面時使用到的等待隊列。
同理 struct task_struct *kcompactd 用於指向內核為 NUMA 節點分配的 kcompactd 進程。
kcompactd_wait 用於 kcompactd 進程周期性規整記憶體時使用到的等待隊列。
本小節筆者主要為大家介紹 NUMA 節點的數據結構 struct pglist_data。詳細的記憶體回收會在本文後面的章節單獨介紹。
4.5 NUMA 節點的狀態 node_states
如果系統中的 NUMA 節點多於一個,內核會維護一個點陣圖 node_states,用於維護各個 NUMA 節點的狀態信息。
如果系統中只有一個 NUMA 節點,則沒有節點點陣圖。
節點點陣圖以及節點的狀態掩碼值定義在 /include/linux/nodemask.h 文件中:
typedef struct { DECLARE_BITMAP(bits, MAX_NUMNODES); } nodemask_t;
extern nodemask_t node_states[NR_NODE_STATES];
節點的狀態可通過以下掩碼表示:
enum node_states {
N_POSSIBLE, /* The node could become online at some point */
N_ONLINE, /* The node is online */
N_NORMAL_MEMORY, /* The node has regular memory */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};
N_POSSIBLE 表示 NUMA 節點在某個時刻可以變為 online 狀態,N_ONLINE 表示 NUMA 節點當前的狀態為 online 狀態。
我們在本文《2.3.1 物理記憶體熱插拔》小節中提到,在稀疏記憶體模型中,NUMA 節點的狀態可以在系統運行的過程中隨時切換 online ,offline 的狀態,用來支持記憶體的熱插拔。
N_NORMAL_MEMORY 表示節點沒有高端記憶體,只有 ZONE_NORMAL 記憶體區域。
N_HIGH_MEMORY 表示節點有 ZONE_NORMAL 記憶體區域或者有 ZONE_HIGHMEM 記憶體區域。
N_MEMORY 表示節點有 ZONE_NORMAL,ZONE_HIGHMEM,ZONE_MOVABLE 記憶體區域。
N_CPU 表示節點包含一個或多個 CPU。
此外內核還提供了兩個輔助函數用於設置或者清除指定節點的特定狀態:
static inline void node_set_state(int node, enum node_states state)
static inline void node_clear_state(int node, enum node_states state)
內核提供了 for_each_node_state 巨集用於迭代處於特定狀態的所有 NUMA 節點。
#define for_each_node_state(__node, __state) \
for_each_node_mask((__node), node_states[__state])
比如:for_each_online_node 用於迭代所有 online 的 NUMA 節點:
#define for_each_online_node(node) for_each_node_state(node, N_ONLINE)
5. 內核如何管理 NUMA 節點中的物理記憶體區域
在前邊《4.3 NUMA 節點物理記憶體區域的劃分》小節的介紹中,由於實際的電腦體繫結構受到硬體方面的制約,間接限制了頁框的使用方式。於是內核會根據各個物理記憶體區域的功能不同,將 NUMA 節點內的物理記憶體劃分為:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 這幾個物理記憶體區域。
ZONE_MOVABLE 區域是內核從邏輯上的劃分,區域中的物理頁面來自於上述幾個記憶體區域,目的是避免記憶體碎片和支持記憶體熱插拔(前邊筆者已經介紹過了)。
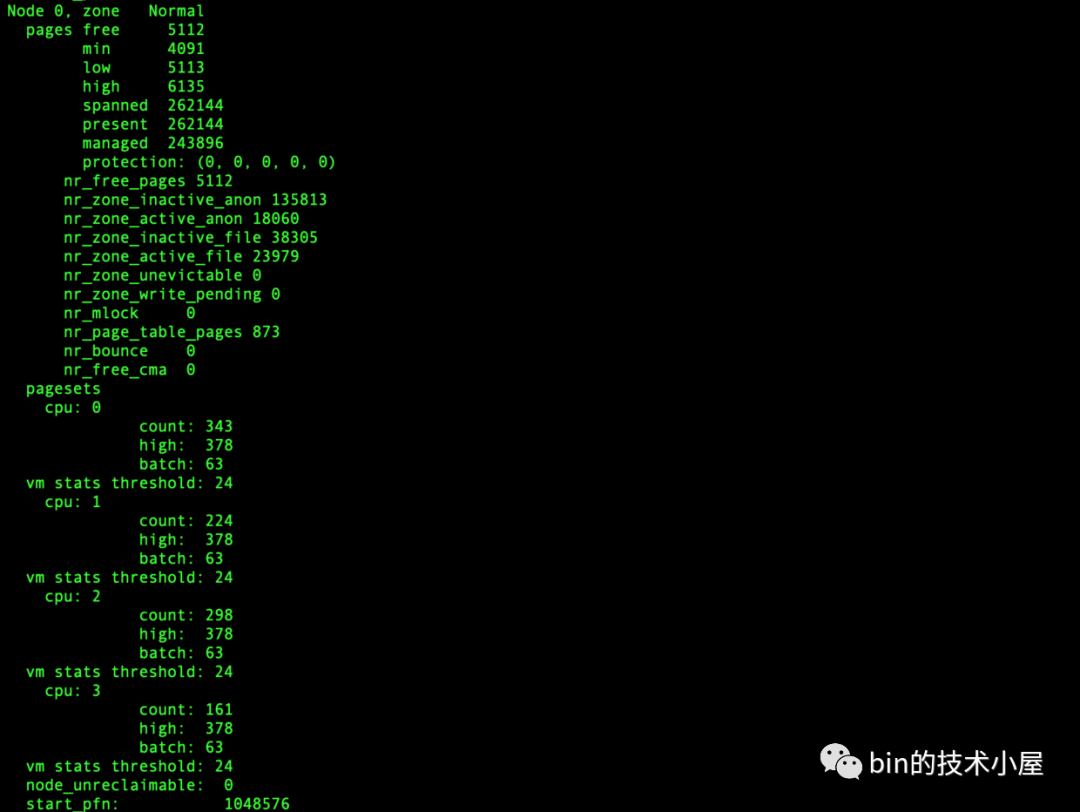
我們可以通過 cat /proc/zoneinfo | grep Node 命令來查看 NUMA 節點中記憶體區域的分佈情況:

筆者使用的伺服器是 64 位,所以不包含 ZONE_HIGHMEM 區域。
通過 cat /proc/zoneinfo 命令來查看系統中各個 NUMA 節點中的各個記憶體區域的記憶體使用情況:
下圖中我們以 NUMA Node 0 中的 ZONE_NORMAL 區域為例說明,大家只需要瀏覽一個大概,圖中每個欄位的含義筆者會在本小節的後面一一為大家介紹~~~
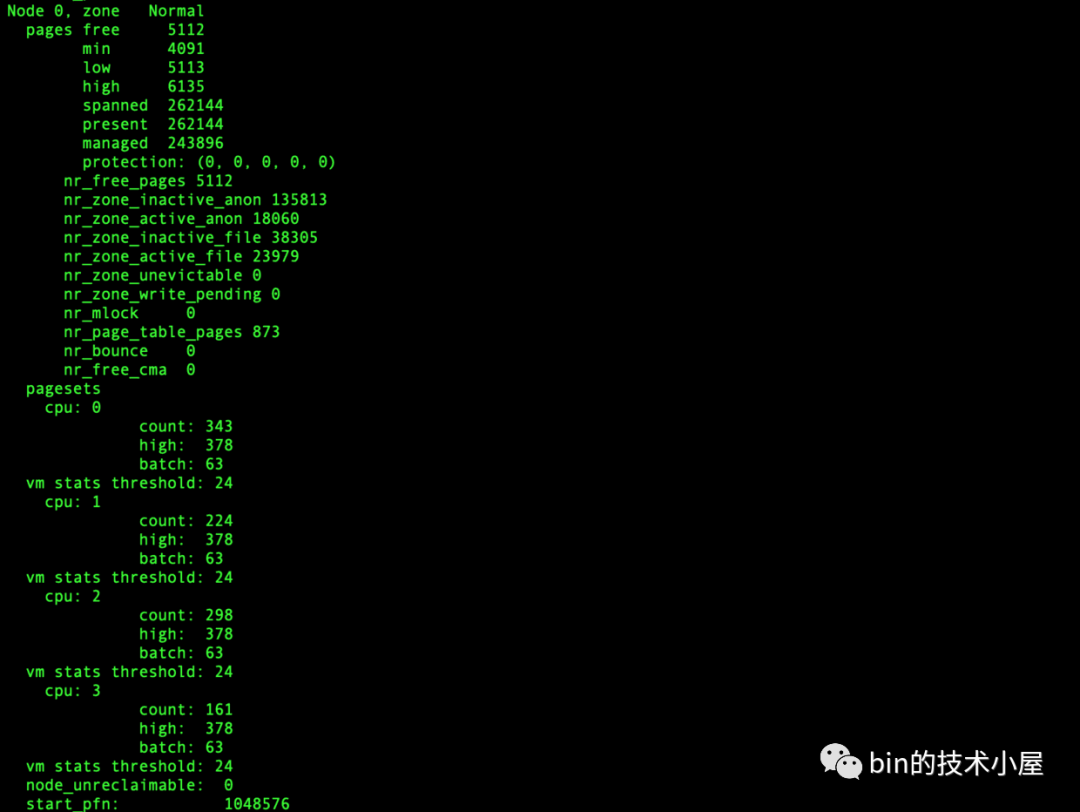
內核中用於描述和管理 NUMA 節點中的物理記憶體區域的結構體是 struct zone,上圖中顯示的 ZONE_NORMAL 區域中,物理記憶體使用統計的相關數據均來自於 struct zone 結構體,我們先來看一下內核對 struct zone 結構體的整體佈局情況:
struct zone {
.............省略..............
ZONE_PADDING(_pad1_)
.............省略..............
ZONE_PADDING(_pad2_)
.............省略..............
ZONE_PADDING(_pad3_)
.............省略..............
} ____cacheline_internodealigned_in_smp;
由於 struct zone 結構體在內核中是一個訪問非常頻繁的結構體,在多處理器系統中,會有不同的 CPU 同時大量頻繁的訪問 struct zone 結構體中的不同欄位。
因此內核對 struct zone 結構體的設計是相當考究的,將這些頻繁訪問的欄位信息歸類為 4 個部分,並通過 ZONE_PADDING 來分割。
目的是通過 ZONE_PADDING 來填充位元組,將這四個部分,分別填充到不同的 CPU 高速緩存行(cache line)中,使得它們各自獨占 cache line,提高訪問性能。
根據前邊物理記憶體區域劃分的相關內容介紹,我們知道內核會把 NUMA 節點中的物理記憶體區域頂多劃分為 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 這幾個物理記憶體區域。因此 struct zone 的實例在內核中會相對比較少,通過 ZONE_PADDING 填充位元組,帶來的 struct zone 結構體實例記憶體占用增加是可以忽略不計的。
在結構體的最後內核還是用了 ____cacheline_internodealigned_in_smp 編譯器關鍵字來實現最優的高速緩存行對齊方式。
關於 CPU 高速緩存行對齊的詳細內容,感興趣的同學可以回看下筆者之前的文章 《一文聊透對象在JVM中的記憶體佈局,以及記憶體對齊和壓縮指針的原理及應用》 。
筆者為了使大家能夠更好地理解內核如何使用 struct zone 結構體來描述記憶體區域,從而把結構體中的欄位按照一定的層次結構重新排列介紹,這並不是原生的欄位對齊方式,這一點需要大家註意!!!
struct zone {
// 防止併發訪問該記憶體區域
spinlock_t lock;
// 記憶體區功能變數名稱稱:Normal ,DMA,HighMem
const char *name;
// 指向該記憶體區域所屬的 NUMA 節點
struct pglist_data *zone_pgdat;
// 屬於該記憶體區域中的第一個物理頁 PFN
unsigned long zone_start_pfn;
// 該記憶體區域中所有的物理頁個數(包含記憶體空洞)
unsigned long spanned_pages;
// 該記憶體區域所有可用的物理頁個數(不包含記憶體空洞)
unsigned long present_pages;
// 被伙伴系統所管理的物理頁數
atomic_long_t managed_pages;
// 伙伴系統的核心數據結構
struct free_area free_area[MAX_ORDER];
// 該記憶體區域記憶體使用的統計信息
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
struct zone 是會被內核頻繁訪問的一個結構體,在多核處理器中,多個 CPU 會併發訪問 struct zone,為了防止併發訪問,內核使用了一把 spinlock_t lock 自旋鎖來防止併發錯誤以及不一致。
name 屬性會根據該記憶體區域的類型不同保存記憶體區域的名稱,比如:Normal ,DMA,HighMem 等。
前邊我們介紹 NUMA 節點的描述符 struct pglist_data 的時候提到,pglist_data 通過 struct zone 類型的數組 node_zones 將 NUMA 節點中劃分的物理記憶體區域連接起來。
typedef struct pglist_data {
// NUMA 節點中的物理記憶體區域個數
int nr_zones;
// NUMA 節點中的物理記憶體區域
struct zone node_zones[MAX_NR_ZONES];
}
這些物理記憶體區域也會通過 struct zone 中的 zone_pgdat 指向自己所屬的 NUMA 節點。
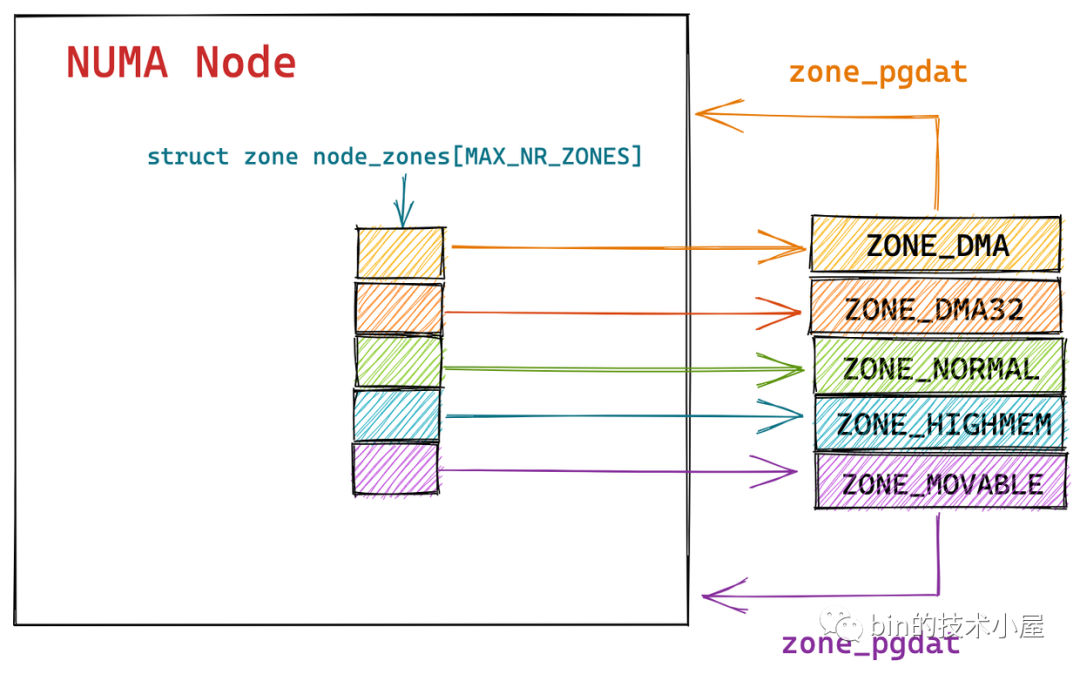
NUMA 節點 struct pglist_data 結構中的 node_start_pfn 指向 NUMA 節點內第一個物理頁的 PFN。同理物理記憶體區域 struct zone 結構中的 zone_start_pfn 指向的是該記憶體區域內所管理的第一個物理頁面 PFN 。
後面的屬性也和 NUMA 節點對應的欄位含義一樣,比如:spanned_pages 表示該記憶體區域內所有的物理頁總數(包含記憶體空洞),通過 spanned_pages = zone_end_pfn - zone_start_pfn 計算得到。
present_pages 則表示該記憶體區域內所有實際可用的物理頁面總數(不包含記憶體空洞),通過 present_pages = spanned_pages - absent_pages(pages in holes) 計算得到。
在 NUMA 架構下,物理記憶體被劃分成了一個一個的記憶體節點(NUMA 節點),在每個 NUMA 節點內部又將其所管理的物理記憶體按照功能不同劃分成了不同的記憶體區域,每個記憶體區域管理一片用於具體功能的物理記憶體,而內核會為每一個記憶體區域分配一個伙伴系統用於管理該記憶體區域下物理記憶體的分配和釋放。
物理記憶體在內核中管理的層級關係為:
None -> Zone -> page
struct zone 結構中的 managed_pages 用於表示該記憶體區域內被伙伴系統所管理的物理頁數量。
數組 free_area[MAX_ORDER] 是伙伴系統的核心數據結構,筆者會在後面的系列文章中詳細為大家介紹伙伴系統的實現。
vm_stat 維護了該記憶體區域物理記憶體的使用統計信息,前邊介紹的 cat /proc/zoneinfo命令的輸出數據就來源於這個 vm_stat。
5.1 物理記憶體區域中的預留記憶體
除了前邊介紹的關於物理記憶體區域的這些基本信息之外,每個物理記憶體區域 struct zone 還為操作系統預留了一部分記憶體,這部分預留的物理記憶體用於內核的一些核心操作,這些操作無論如何是不允許記憶體分配失敗的。
什麼意思呢?內核中關於記憶體分配的場景無外乎有兩種方式:
-
當進程請求內核分配記憶體時,如果此時記憶體比較充裕,那麼進程的請求會被立刻滿足,如果此時記憶體已經比較緊張,內核就需要將一部分不經常使用的記憶體進行回收,從而騰出一部分記憶體滿足進程的記憶體分配的請求,在這個回收記憶體的過程中,進程會一直阻塞等待。
-

