
GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。 GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。 前文回顧 實現一個簡單的Database1(譯文) 實現一個簡單的Database2(譯文) 實現一個簡單的Database3(譯文) 實現一個簡單的D ...
- GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。
- GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。
前文回顧
譯註:cstsck在github維護了一個簡單的、類似sqlite的資料庫實現,通過這個簡單的項目,可以很好的理解資料庫是如何運行的。本文是第六篇,主要是實現數據持久化游標
Part 6 游標抽象
跟上一節相比,這一節篇幅相對要簡短的多。我們只是稍微重構一下,這樣就可以讓開始實現B-tree更簡單一些。
在代碼中新添加一個Cursor對象,它用來代表表中的一個位置(location)。
你可能希望對游標執行的操作:
- 在表開頭時創建一個游標
- 在表結尾時創建一個游標
- 訪問游標指向的行
- 將游標移動到下一行
這就是我們將要實現的游標的一些行為。然後,我們還想做到:
- 刪除游標指向的一行數據
- 修改游標指向的一行數據
- 使用給定的ID搜索一張表,並創建一個游標指向這個ID所在的行
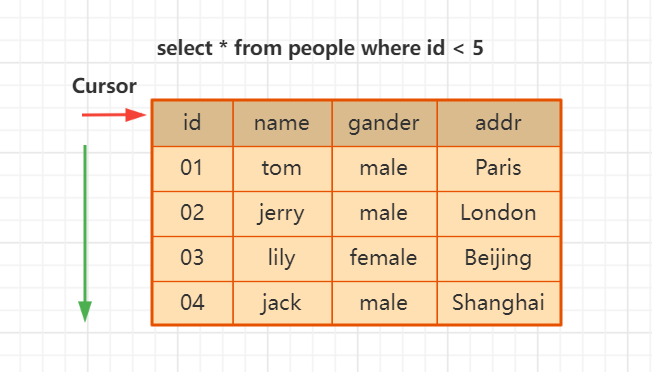
_譯註:這裡簡單介紹一下游標,Cursor原本就有箭頭、游標的意思,用來指示事物以示關註。游標是數據的一種訪問機制,一種處理數據的方法,例如查詢返回的結果是一行或者多行的結果集(這已經是SQL被處理後的結果集),我們需要對結果集進行查詢,sql語句就不管用了,因為這已經是返回的結果集了,這個時候就需要用游標來遍歷這個返回的結果集了。可以理解游標是一個指向Row的指針,訪問一行後,游標就會指向下一行。例如 fetchone()、fetchall() 等函數就是通過游標來訪問結果集的,返回具體一行或者多行的數據。下麵是游標圖示:
不磨嘰了,下麵就是Cursor類型結構:
+typedef struct {
+ Table* table;
+ uint32_t row_num;
+ bool end_of_table; // Indicates a position one past the last element
+} Cursor;
根據現在我們的表數據結構,只需要行號即可識別表中的位置。
游標對它所屬的表還有一個引用(所以我們的游標函數還可以僅僅把游標作為參數)。
最後,它還有一個boolean類型的屬性叫做 end_of_table 。這樣我們就可以用來表示表結尾之後的位置(在這裡我們可能會插入一個新行)。
table_start() 和 table_end() 創建一個新的游標:
+Cursor* table_start(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = 0;
+ cursor->end_of_table = (table->num_rows == 0);
+
+ return cursor;
+}
+
+Cursor* table_end(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = table->num_rows;
+ cursor->end_of_table = true;
+
+ return cursor;
+}
我們的 row_slot() 函數要變成 cursor_value() 了,它返回一個指針類型,指向游標描述的位置:
-void* row_slot(Table* table, uint32_t row_num) {
+void* cursor_value(Cursor* cursor) {
+ uint32_t row_num = cursor->row_num;
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = get_page(table->pager, page_num);
+ void* page = get_page(cursor->table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
在我們當前的表結構中推進游標就像讓行號遞增一樣簡單。這在B-tree書中會有一點小複雜。
+void cursor_advance(Cursor* cursor) {
+ cursor->row_num += 1;
+ if (cursor->row_num >= cursor->table->num_rows) {
+ cursor->end_of_table = true;
+ }
+}
最後我們就能改變我們的“虛擬機”方法來使用游標抽象了。當插入一行數據時,我們在表結尾打開一個游標,寫入這個游標的位置,然後關閉游標。
Row* row_to_insert = &(statement->row_to_insert);
+ Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
當查詢表中的所有行時,我們在表的開頭打開一個游標,列印行數據,然後推進游標到下一行,重覆這個過程直到表的結尾。
ExecuteResult execute_select(Statement* statement, Table* table) {
+ Cursor* cursor = table_start(table);
+
Row row;
- for (uint32_t i = 0; i < table->num_rows; i++) {
- deserialize_row(row_slot(table, i), &row);
+ while (!(cursor->end_of_table)) {
+ deserialize_row(cursor_value(cursor), &row);
print_row(&row);
+ cursor_advance(cursor);
}
+
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
好了,就是它!就像我說的,這是短小的重構,應該能夠有助於我們把表的數據結構重寫為B-tree。execute_select() 和 execute_insert() 函數完全可以通過游標來與表交互,而對於表的存儲方式不需要假設任何事情。
譯註:在之前實現資料庫的page組織方式的代碼中,作者使用數組(array)來組織數據頁page,主要是考慮快速實現存放數據,沒有考慮性能優化。後面會使用B-tree來進行重構,而在此之前,先實現了游標。_
這是於上一部分對比,代碼的不同:
@@ -78,6 +78,13 @@ struct {
} Table;
+typedef struct {
+ Table* table;
+ uint32_t row_num;
+ bool end_of_table; // Indicates a position one past the last element
+} Cursor;
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -126,12 +133,38 @@ void* get_page(Pager* pager, uint32_t page_num) {
return pager->pages[page_num];
}
-void* row_slot(Table* table, uint32_t row_num) {
- uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = get_page(table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+Cursor* table_start(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = 0;
+ cursor->end_of_table = (table->num_rows == 0);
+
+ return cursor;
+}
+
+Cursor* table_end(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = table->num_rows;
+ cursor->end_of_table = true;
+
+ return cursor;
+}
+
+void* cursor_value(Cursor* cursor) {
+ uint32_t row_num = cursor->row_num;
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = get_page(cursor->table->pager, page_num);
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+void cursor_advance(Cursor* cursor) {
+ cursor->row_num += 1;
+ if (cursor->row_num >= cursor->table->num_rows) {
+ cursor->end_of_table = true;
+ }
}
Pager* pager_open(const char* filename) {
@@ -327,19 +360,28 @@ ExecuteResult execute_insert(Statement* statement, Table* table) {
}
Row* row_to_insert = &(statement->row_to_insert);
+ Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement* statement, Table* table) {
+ Cursor* cursor = table_start(table);
+
Row row;
- for (uint32_t i = 0; i < table->num_rows; i++) {
- deserialize_row(row_slot(table, i), &row);
+ while (!(cursor->end_of_table)) {
+ deserialize_row(cursor_value(cursor), &row);
print_row(&row);
+ cursor_advance(cursor);
}
+
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
Enjoy GreatSQL


