
腳本介紹 下方是演示的表結構: CREATE TABLE `index_test03` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(20) NOT NULL, `create_time` varchar(20) NOT NULL ...
0.1、索引
https://waterflow.link/articles/1666339004798
1、map的結構
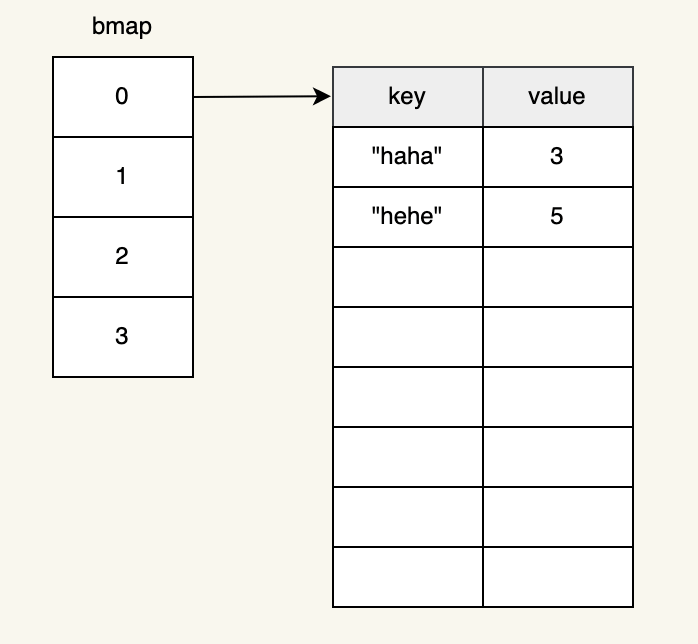
map提供了鍵值對的無序集合,所有的鍵都是不重覆的。在go中map是基於bmap數據結構的。在內部hash表是一個桶數組,每個桶是一個指向鍵值對數組的指針。每個桶裡面可以保存8個元素。我們可以簡化成下麵的結構。
如果我們繼續插入一個元素,hash鍵返回相同的索引,則另一個元素也會插入相同的桶中。
如果正常桶中的元素已滿,還有元素繼續往相同的索引插入的話,go會創建另一個包含8個元素的桶並將前一個桶指向他。
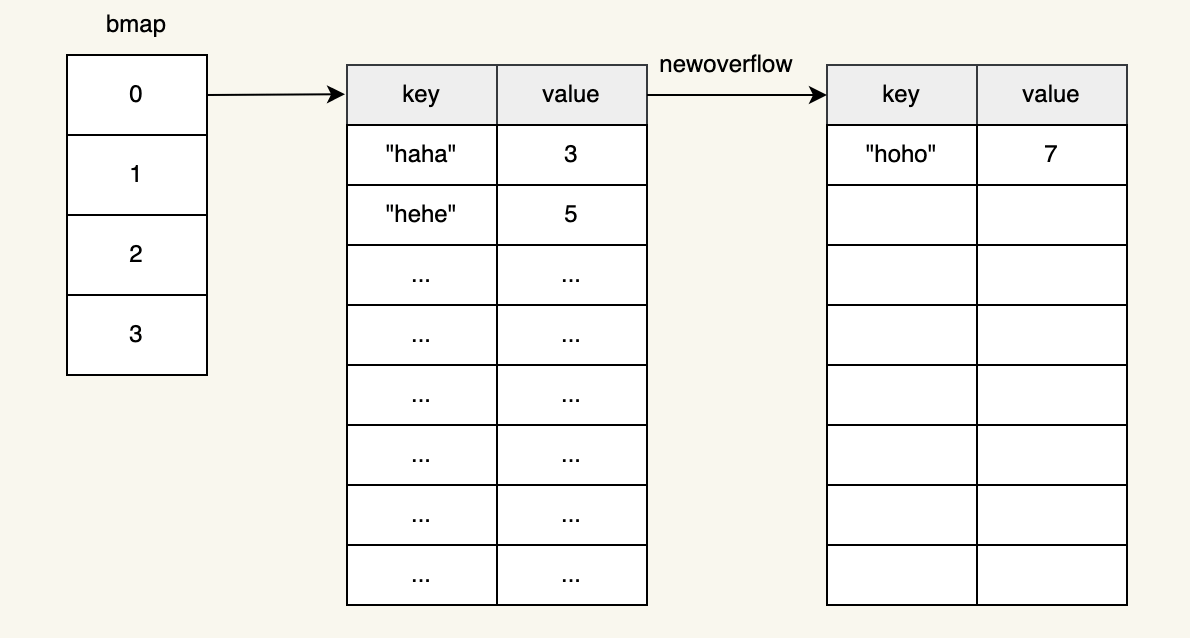
所以當我們讀取、更新和刪除map元素時,Go 必須計算相應的數組索引。 然後 Go 依次遍歷所有鍵,直到找到提供的鍵。 因此,這三個操作的最壞情況時間複雜度為 O(p),其中 p 是桶中元素的總數(預設為一個桶,溢出時為多個桶)。
2、map初始化
首先我們先初始化一個包含3個元素的map:
m := map[string]int{
"haha": 3,
"hehe": 5,
"hoho": 7,
}
我們可能只需要遍歷2個桶就可以找到上面的所有元素。
但是當我們添加100萬個元素的時候,我們可能需要遍歷上千個桶去找到指定的元素。
為了應對元素的增長,map會選擇擴容,一般是當前桶數量增加一倍。那什麼時候會擴容呢?
- 負載因數大於6.5
- 溢出桶太多
當map擴容的時候,所有的鍵都會重新分配到新的桶。所以最壞情況下,插入元素有可能是O(n)。
我們知道,在使用切片時,如果我們預先知道要添加到切片的元素數量,我們可以用給定的大小或容量對其進行初始化。這避免了不斷應對切片增長導致底層數組頻繁複制的問題。map與此類似。實際上,我們可以使用 make 內置函數在創建地圖時提供初始大小。例如,如果我們要初始化一個包含 100 萬個元素的map,可以這樣寫:
m := make(map[string]int, 1000000)
通過指定大小,go使用適當數量的桶創建map以存儲 100 萬個元素。 這節省了大量計算時間,因為map不用動態創建桶並處理桶溢出後rehash的問題。
指定大小 n 並不是說創建最多有100萬個元素的map。 我們可以繼續往map添加元素。 這實際代表著 Go 運行時至少 需要為n 個元素分配記憶體。
我們可以運行下基準測試看下這兩個的性能差異:
package main
import (
"testing"
)
var n = 1000000
func BenchmarkWithSize(b *testing.B) {
for i := 0; i < b.N; i++ {
m := make(map[string]int, n)
for j := 0; j < n; j++ {
m["hhs" + string(rune(j))] = j
}
}
}
func BenchmarkWithoutSize(b *testing.B) {
for i := 0; i < b.N; i++ {
m := make(map[string]int)
for j := 0; j < n; j++ {
m["hhs"+string(rune(j))] = j
}
}
}
go test -bench=.
goos: darwin
goarch: amd64
pkg: go-demo/5
cpu: Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz
BenchmarkWithSize-8 6 178365104 ns/op
BenchmarkWithoutSize-8 3 362949513 ns/op
PASS
ok go-demo/5 4.563s
我們可以看到初始化map大小的性能是高於未設置初始化大小的性能。其中的原因上面應該解釋的很清楚了。
3、map記憶體泄漏
我們看下下麵的一個例子:
package main
import (
"fmt"
"runtime"
)
func main() {
n := 1000000
m := make(map[int]struct{})
printAlloc()
for i := 0; i < n; i++ {
m[i] = struct{}{}
}
printAlloc()
for i := 0; i < n; i++ {
delete(m, i)
}
runtime.GC()
printAlloc()
// 保留對m的引用,確保map不會被回收
runtime.KeepAlive(m)
}
// 列印記憶體分配情況
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d MB\n", m.Alloc/1024/1024)
}
- 首先我們初始化一個map,map的值為空結構體,列印分配堆記憶體的大小。
- 接著我們往map中添加100萬個元素,列印分配堆記憶體的大小。
- 然後我們刪除所有元素,運行垃圾回收,列印分配堆記憶體的大小。
我們運行下上面的代碼:
go run 5.go
0 MB
33 MB
21 MB
當我們添加100萬元素之後,堆裡面會分配33M的數據,像下麵這樣
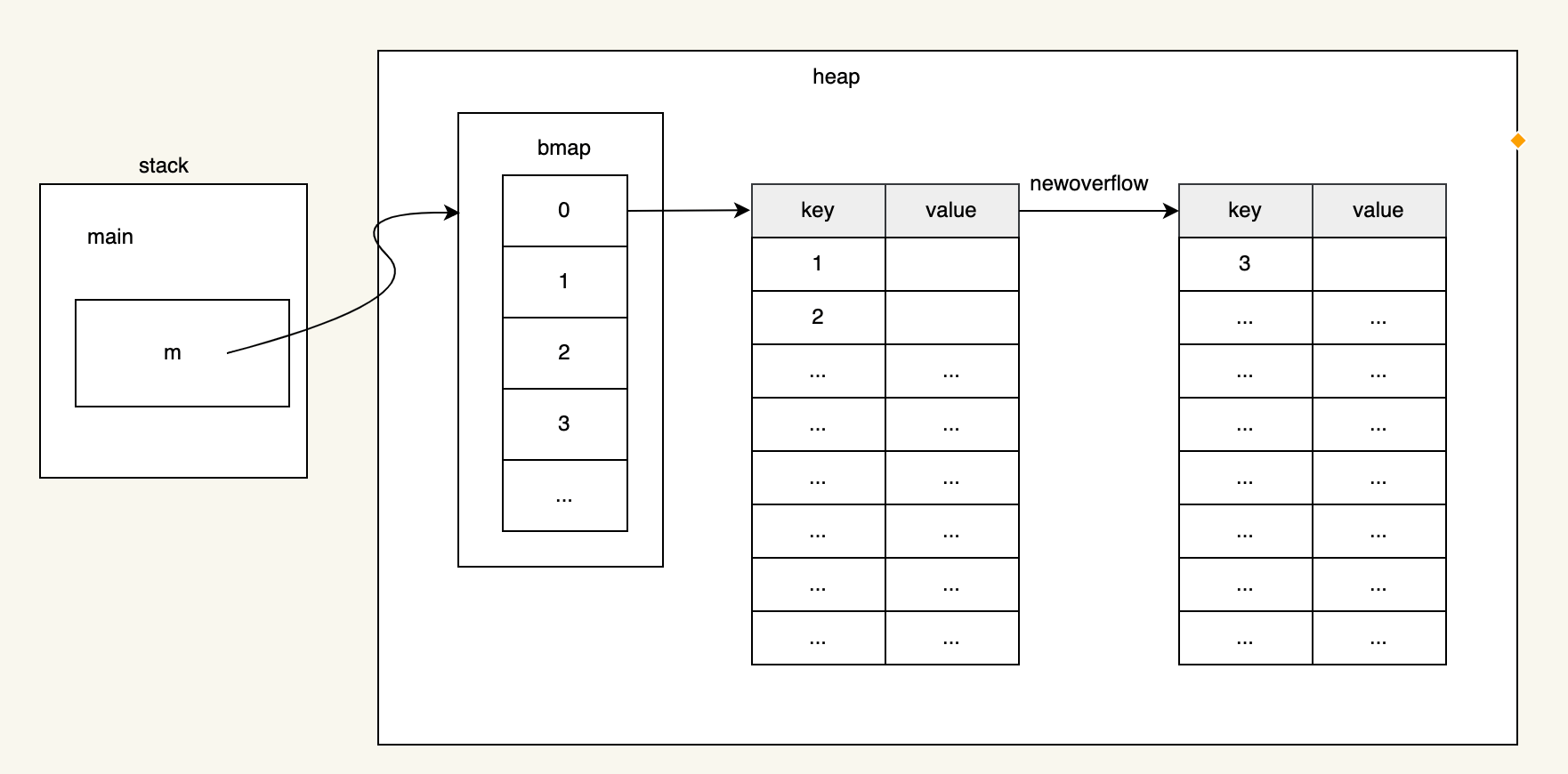
當我們刪除100萬的數據之後,觸發GC回收,實際上GC只是回收了桶裡面的元素數據,桶的數量不會因為刪除操作而減少,所以還有21M的數據
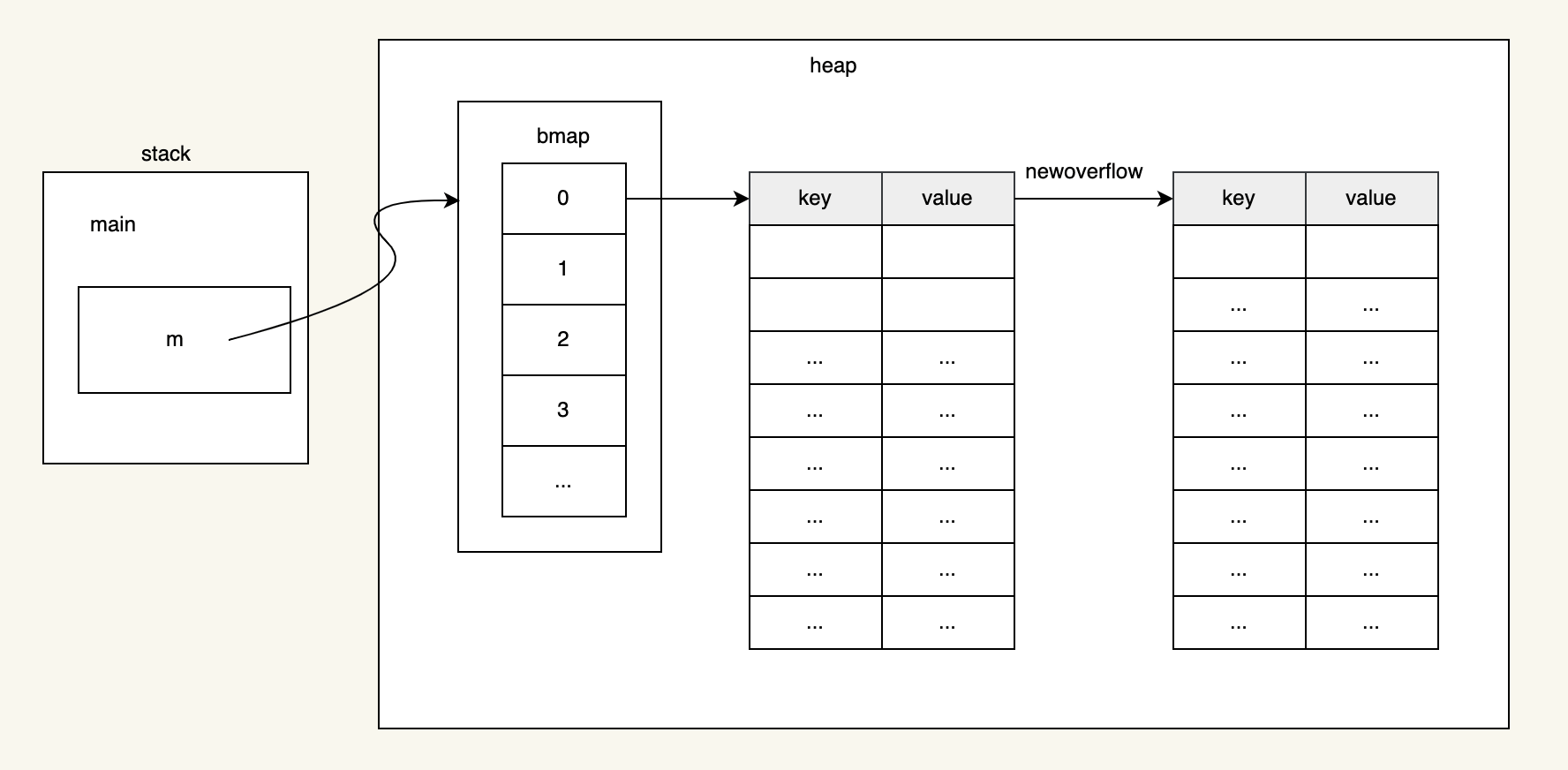
原因是map中的桶數不會縮小。
當然,為瞭解決大量寫入、刪除造成的記憶體泄漏問題,map引入了 sameSizeGrow 這一機制,在出現較多溢出桶時會整理哈希的記憶體減少空間的占用。

