
什麼是MQ? 【1】MQ:MessageQueue,消息隊列。 隊列,是一種FIFO 先進先出的數據結構。消息由生產者發送到MQ進行排隊,然後按原來的順序交由消息的消費者進行處理。QQ和微信就是典型的MQ。 為什麼要用MQ(MQ的優點)? MQ的作用主要有以下三個方面: 【1】非同步 例子:快遞員發快 ...
什麼是MQ?
【1】MQ:MessageQueue,消息隊列。 隊列,是一種FIFO 先進先出的數據結構。消息由生產者發送到MQ進行排隊,然後按原來的順序交由消息的消費者進行處理。QQ和微信就是典型的MQ。
為什麼要用MQ(MQ的優點)?
MQ的作用主要有以下三個方面:
【1】非同步
例子:快遞員發快遞,直接到客戶家效率會很低。引入菜鳥驛站後,快遞員只需要把快遞放到菜鳥驛站,就可以繼續發其他快遞去了。客戶再按自己的時間安排去菜鳥驛站取快遞。
作用:非同步能提高系統的響應速度、吞吐量。
【2】解耦
例子:《Thinking in JAVA》很經典,但是都是英文,我們看不懂,所以需要編輯社,將文章翻譯成其他語言,這樣就可以完成英語與其他語言的交流。
作用:
1、服務之間進行解耦,才可以減少服務之間的影響。提高系統整體的穩定性以及可擴展性。
2、另外,解耦後可以實現數據分發。生產者發送一個消息後,可以由一個或者多個消費者進行消費,並且消費者的增加或者減少對生產者沒有影響。
【3】削峰
例子:長江每年都會漲水,但是下游出水口的速度是基本穩定的,所以會漲水。引入三峽大壩後,可以把水儲存起來,下游慢慢排水。
作用:以穩定的系統資源應對突發的流量衝擊。
MQ的缺點
【1】系統可用性降低
系統引入的外部依賴增多,系統的穩定性就會變差。一旦MQ宕機,對業務會產生影響。這就需要考慮如何保證MQ的高可用。
【2】系統複雜度提高
引入MQ後系統的複雜度會大大提高。以前服務之間可以進行同步的服務調用,引入MQ後,會變為非同步調用,數據的鏈路就會變得更複雜。並且還會帶來其他一些問題。比如:如何保證消費不會丟失?不會被重覆調用?怎麼保證消息的順序性等問題。
【3】消息一致性問題
A系統處理完業務,通過MQ發送消息給B、C系統進行後續的業務處理。如果B系統處理成功,C系統處理失敗怎麼辦?這就需要考慮如何保證消息數據處理的一致性。
常用的MQ產品
【1】Kafka、RabbitMQ和RocketMQ。我們對這三個產品做下簡單的比較,重點需要理解他們的適用場景。
【2】圖示:

【3】分別分析三種消息中間件
1.RabbitMQ:消息可靠性很高,功能非常全面,很多高級功能都是從這裡衍生出來的,如死信隊列,延遲隊列。缺點在於吞吐量很低,消息積累會影響消費的性能,而且erlang的語言使用的比較少,定製比較難。適用於公司內部系統的請求扭轉的流程。
2.Kafka:行業的老大哥,基本上是大數據場景必用的組件之一,吞吐量不可挑戰,集群性能很好。之前是依賴zookeeper搭建集群,但是新版本會逐漸拋棄zookeeper。但是會存在丟消失的可能,而且功能單一,很多高級功能都沒有,如死信隊列。最早就是用來做日誌分析的。
3.RocketMQ:最開始是借鑒Kafka,後面逐步優化。吞吐量基本和Kafka是一個量級的,功能也很全面,如RabbitMQ有的都有,還有其他沒有的事務功能。缺點是開源版不如雲上商業版。如延遲隊列,開源會有固定的限制。
MQ使用中的常見問題
【1】如何保證消息不丟失?
1)分析哪些環節會有丟消息的可能
(1)圖示
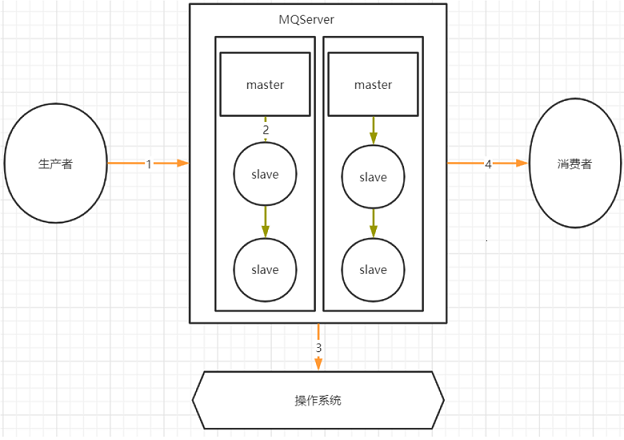
(2)分析
1.其中,1,2,4三個場景都是跨網路的,而跨網路就肯定會有丟消息的可能。
2.而3這個環節,通常MQ存檔時都會先寫入操作系統的緩存page cache中,然後再由操作系統非同步的將消息寫入硬碟。這個中間有個時間差,就可能會造成消息丟失。如果服務掛了,緩存中還沒有來得及寫入硬碟的消息就會丟失。這也是任何用戶態的應用程式無法避免的。
2)分析怎麼處理的
1.為保證消息不丟失,發送端的ACK應答必須是多個節點寫入的應答 兼 採用多次重試的方式(預防網路抖動),其次消息中間件內部持久化,消費端是消費後手動應答。
2.在發送端還應該:區分業務的關鍵性,如果消息不影響主體業務(如,消息通知要做的事情可以延遲很久,但因某些緣故,消息發不出去),這時候採用將消息落盤,然後調用定時任務的形式,延時檢查發送。
3.在消費端還應該:對消費失敗的消息進行次數檢測,如果多次失敗(有可能參數異常,有可能流程出了問題),應該落盤(避免消息堆積),告知程式員處理。
【2】如何保證消息冪等性?
1)分析哪些環節會造成消息重覆消費
1.MQ的自動重試功能:如網路抖動時,生產者發送得不到MQ的回應嘗試多次發送;消費者做完任務,返回給MQ的應答丟失,導致MQ發給了另一個消費者去消費消息。
2.代碼BUG導致消息多次發送。
2)分析怎麼處理的
1.首先在MQ上我們是不能保證消息的冪等性的,所以我們只能在業務中處理。
2.處理冪等問題的關鍵是要給每個消息一個唯一的標識(但這個不能是MQ給我們的消息ID,因為它依舊解決不了生產者發送多次的問題)
3.需要我們自行構建分散式唯一ID(如雪花演算法),能夠添加一個具有業務意義的數據作為唯一鍵會更好,這樣能更好的防止重覆消費問題對業務的影響。比如,針對訂單消息,那就用訂單ID來做唯一鍵。
4.如訂單ID來做唯一鍵,就算真的出現了很不幸的兩個消費者同時消費兩條重覆的數據,那麼在進行MYSQL寫入的時候,事務處理與唯一鍵索引,將是兜底保證業務執行冪等性的關鍵。
5.當然,採用redis的Setnx(要設置超時時間)作為CAS鎖保證只有一個線程執行業務也是可以的,成功後還可以設置標記值來標記該業務已經做完,等下次重覆的消息過來時候,進行redis檢驗的時候就會自動丟棄這些重覆的消息。【這裡面需要衡量的是業務的處理速度,與占用redis的記憶體空間,雖然有過期時間,但是在這段時間內這些數據依舊會占用空間,如果處理速度很快,則占用的空間越多】
【3】如何保證消息的順序?
1)原因:某些場景下,需要保證消息的消費順序,例如一個下單過程,需要先完成扣款,然後扣減庫存,然後通知快遞發貨,這個順序不能亂。如果每個步驟都通過消息進行非同步通知的話,這一組消息就必須保證他們的消費順序是一致的
2)分析該怎麼處理(基於MQ無法保證,那麼更多是在業務層面實現)
方案一:為保證消息的有序性,採用用同步發送的模式去發消息,然後消息發往同一個隊列裡面,然後採用一個消費者去進行消費。
方案二:為保證高性能,採用用非同步發送的模式去發消息,然後消息發往同一個隊列裡面,然後採用一個消費者去進行消費。消費者端接收後,因為可能消息群是亂序的(非同步發送模式),所以構建記憶體隊列(優先順序隊列),將消息排序消費(每個記憶體隊列只允許一個線程消費,可拓展為多個記憶體隊列多個線程)
針對這種,容易出現消息堆積的情況,可擴展為多個隊列,每個隊列都有唯一的一個消費者。在發送端建立消息組ID,根據組ID進行hash決定這一組消息分配至哪個隊列裡面。但是又容易出現數據傾斜的問題,則可以考慮構建hash環與增加虛擬節點的想法,將數據更加均勻的分佈。
【4】數據堆積如何處理?
1)線上有時因為發送方發送消息速度過快,或者消費方處理消息過慢,可能會導致MQ積壓大量未消費消息。此種情況如果積壓了上百萬未消費消息需要緊急處理,可以修改消費端程式,讓其將收到的消息快速轉發到其他隊列,然後再啟動多個消費者同時消費。
2)由於消息數據格式變動或消費者程式有bug,導致消費者一直消費不成功,也可能導致MQ積壓大量未消費消息。此種情況可以將這些消費不成功的消息轉發到其它隊列里去(類似死信隊列),後面再慢慢分析死信隊列里的消息處理問題。
MQ的自動重試功能


