
Kafka介紹 Kafka是最初由Linkedin公司開發,是一個分散式、支持分區的(partition)、多副本的(replica),基於zookeeper協調的分散式消息系統,它的最大的特性就是可以實時的處理大量數據以滿足各種需求場景:比如基於hadoop的批處理系統、低延遲的實時系統、Stor ...
Kafka介紹
Kafka是最初由Linkedin公司開發,是一個分散式、支持分區的(partition)、多副本的(replica),基於zookeeper協調的分散式消息系統,它的最大的特性就是可以實時的處理大量數據以滿足各種需求場景:比如基於hadoop的批處理系統、低延遲的實時系統、Storm/Spark流式處理引擎,web/nginx日誌、訪問日誌,消息服務等等,用scala語言編寫,Linkedin於2010年貢獻給了Apache基金會併成為頂級開源項目。
實際上算作是分散式的流處理平臺,具備消息中間間的功能,在大數據領域作為流計算的平臺,也會做消息分發。
Kafka常見的使用場景
【1】日誌收集:一個公司可以用Kafka收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等。
【2】消息系統:解耦和生產者和消費者、緩存消息等。
【3】用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動信息被各個伺服器發佈到kafka的topic中,然後訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、數據倉庫中做離線分析和挖掘。
【4】運營指標:Kafka也經常用來記錄運營監控數據。包括收集各種分散式應用的數據,生產各種操作的集中反饋,比如報警和報告。
Kafka基本概念
【1】kafka是一個分散式的,分區的消息(官方稱之為commit log)服務。它提供一個消息系統應該具備的功能,但是確有著獨特的設計。可以這樣來說,Kafka借鑒了JMS規範的思想,但是確並沒有完全遵循JMS規範。
【2】基礎的消息(Message)相關術語:
| 名稱 | 解釋 |
| Broker | 消息中間件處理節點,一個Kafka節點就是一個broker,一個或者多個Broker可以組成一個Kafka集群 |
| Topic | Kafka根據topic對消息進行歸類,發佈到Kafka集群的每條消息都需要指定一個topic |
| Producer | 消息生產者,向Broker發送消息的客戶端 |
| Consumer | 消息消費者,從Broker讀取消息的客戶端 |
| ConsumerGroup | 每個Consumer屬於一個特定的Consumer Group,一條消息可以被多個不同的Consumer Group消費,但是一個Consumer Group中只能有一個Consumer能夠消費該消息 |
| Partition | 物理上的概念,一個topic可以分為多個partition,每個partition內部消息是有序的 |
【3】從巨集觀層面上看,producer通過網路發送消息到Kafka集群,然後consumer來進行消費,如下圖:
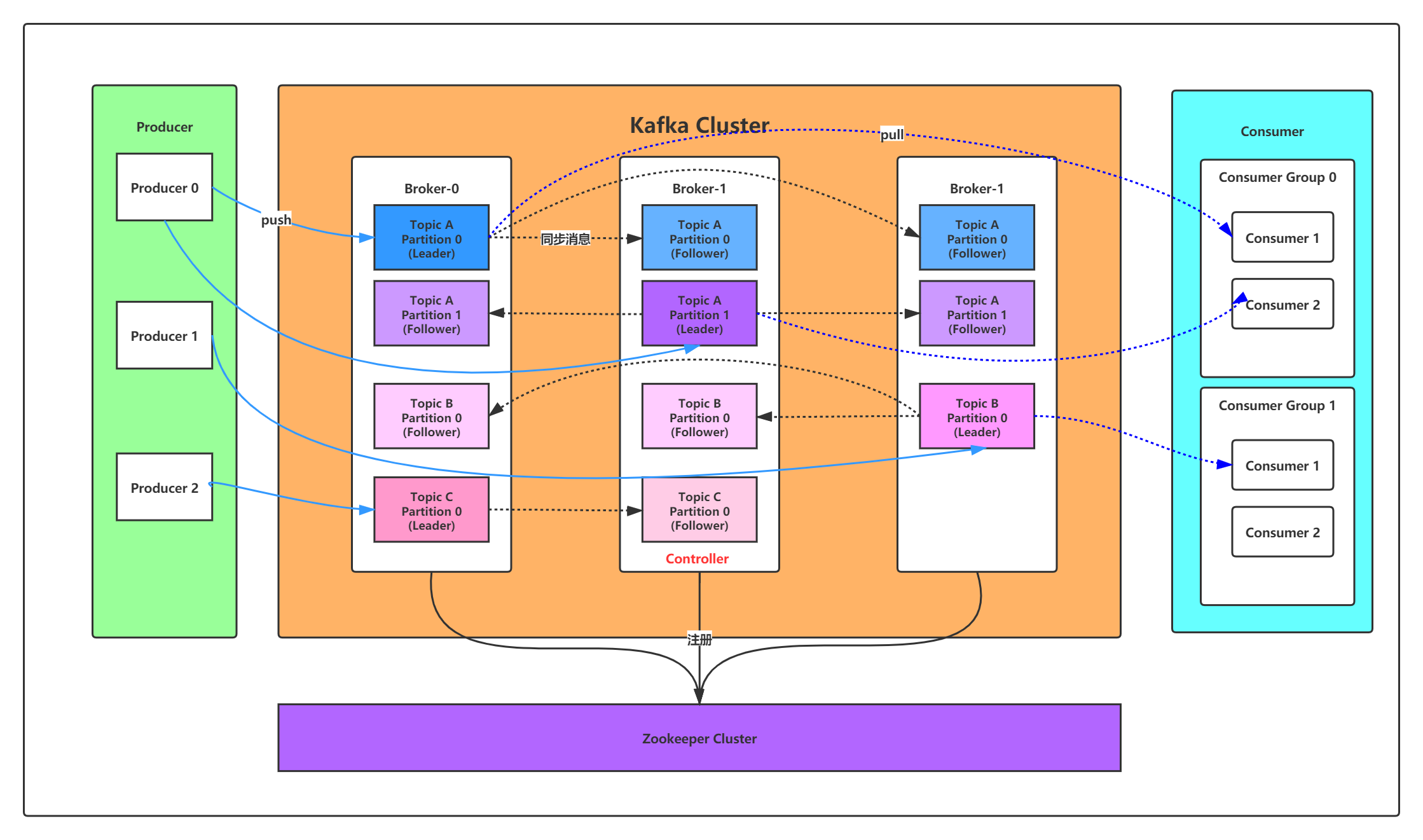
【4】服務端(brokers)和客戶端(producer、consumer)之間通信通過TCP協議來完成。
kafka基本使用(原生API)
創建主題
【1】創建一個名字為“test”的Topic,這個topic只有一個partition,並且備份因數也設置為1:
bin/kafka-topics.sh --create --zookeeper 192.168.65.60:2181 --replication-factor 1 --partitions 1 --topic test
【2】通過以下命令來查看kafka中目前存在的topic
bin/kafka-topics.sh --list --zookeeper 192.168.65.60:2181
【3】除了通過手工的方式創建Topic,當producer發佈一個消息到某個指定的Topic,這個Topic如果不存在,就自動創建。
【4】刪除主題
bin/kafka-topics.sh --delete --topic test --zookeeper 192.168.65.60:2181
發送消息
【1】kafka自帶了一個producer命令客戶端,可以從本地文件中讀取內容,或者我們也可以以命令行中直接輸入內容,並將這些內容以消息的形式發送到kafka集群中。在預設情況下,每一個行會被當做成一個獨立的消息。
【2】運行發佈消息的腳本,然後在命令中輸入要發送的消息的內容:
//指定往哪個broker(也就是伺服器)上發消息
bin/kafka-console-producer.sh --broker-list 192.168.65.60:9092 --topic test >this is a msg >this is a another msg
消費消息
【1】對於consumer,kafka同樣也攜帶了一個命令行客戶端,會將獲取到內容在命令中進行輸出,預設是消費最新的消息:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --topic test
【2】想要消費之前的消息可以通過--from-beginning參數指定,如下命令:
//這裡便凸顯了與傳統消息中間件的不同,消費完,消息依舊保留(預設保留在磁碟一周)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --from-beginning --topic test
【3】通過不同的終端視窗來運行以上的命令,你將會看到在producer終端輸入的內容,很快就會在consumer的終端視窗上顯示出來。
【4】所有的命令都有一些附加的選項;當我們不攜帶任何參數運行命令的時候,將會顯示出這個命令的詳細用法
執行bin/kafka-console-consumer.sh 命令顯示所有的可選參數
消費消息類型分析
消費多主題
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --whitelist "test|test-2"
單播消費
【1】一條消息只能被某一個消費者消費的模式,類似queue模式,只需讓所有消費者在同一個消費組裡即可
【2】分別在兩個客戶端執行如下消費命令,然後往主題里發送消息,結果只有一個客戶端能收到消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --consumer-property group.id=testGroup --topic test
多播消費
【1】一條消息能被多個消費者消費的模式,類似publish-subscribe模式費,針對Kafka同一條消息只能被同一個消費組下的某一個消費者消費的特性,要實現多播只要保證這些消費者屬於不同的消費組即可。我們再增加一個消費者,該消費者屬於testGroup-2消費組,結果兩個客戶端都能收到消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --consumer-property group.id=testGroup-2 --topic test
查看消費組名
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --list
查看消費組的消費偏移量
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --describe --group testGroup
//current-offset:當前消費組的已消費偏移量
//log-end-offset:主題對應分區消息的結束偏移量(HW)
//lag:當前消費組未消費的消息數
主題Topic和消息日誌Log詳解
【1】可以理解Topic是一個類別的名稱,同類消息發送到同一個Topic下麵。對於每一個Topic,下麵可以有多個分區(Partition)日誌文件:【分散式存儲的思想】
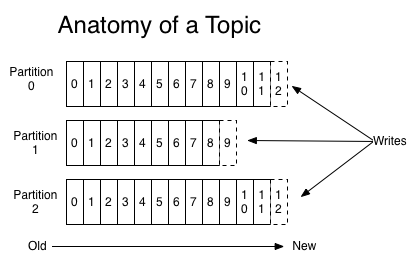
【2】Partition是一個有序的message序列,這些message按順序添加到一個叫做commit log的文件中。每個partition中的消息都有一個唯一的編號,稱之為offset,用來唯一標示某個分區中的message。
【3】每個partition,都對應一個commit log文件。一個partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
【4】kafka一般不會刪除消息,不管這些消息有沒有被消費。只會根據配置的日誌保留時間(log.retention.hours)確認消息多久被刪除,預設保留最近一周的日誌消息。kafka的性能與保留的消息數據量大小沒有關係,因此保存大量的數據消息日誌信息不會有什麼影響。
【5】每個consumer是基於自己在commit log中的消費進度(offset)來進行工作的。在kafka中,消費offset由consumer自己來維護;一般情況下我們按照順序逐條消費commit log中的消息,當然我可以通過指定offset來重覆消費某些消息,或者跳過某些消息。
【6】這意味kafka中的consumer對集群的影響是非常小的,添加一個或者減少一個consumer,對於集群或者其他consumer來說,都是沒有影響的,因為每個consumer維護各自的消費offset。
創建多個分區的主題:
bin/kafka-topics.sh --create --zookeeper 192.168.65.60:2181 --replication-factor 1 --partitions 2 --topic test1
查看下topic的情況
bin/kafka-topics.sh --describe --zookeeper 192.168.65.60:2181 --topic test1

以下是輸出內容的解釋,第一行是所有分區的概要信息,之後的每一行表示每一個partition的信息。
leader節點負責給定partition的所有讀寫請求。
replicas 表示某個partition在哪幾個broker上存在備份。不管這個幾點是不是”leader“,甚至這個節點掛了,也會列出。
isr 是replicas的一個子集,它只列出當前還存活著的,並且已同步備份了該partition的節點。
我們可以運行相同的命令查看之前創建的名稱為”test“的topic
bin/kafka-topics.sh --describe --zookeeper 192.168.65.60:2181 --topic test
 之前設置了topic的partition數量為1,備份因數為1,因此顯示就如上所示了。
可以進入kafka的數據文件存儲目錄查看test和test1主題的消息日誌文件:
之前設置了topic的partition數量為1,備份因數為1,因此顯示就如上所示了。
可以進入kafka的數據文件存儲目錄查看test和test1主題的消息日誌文件:
 消息日誌文件主要存放在分區文件夾里的以log結尾的日誌文件里,如下是test1主題對應的分區0的消息日誌:
消息日誌文件主要存放在分區文件夾里的以log結尾的日誌文件里,如下是test1主題對應的分區0的消息日誌:

當然我們也可以通過如下命令增加topic的分區數量(目前kafka不支持減少分區):
bin/kafka-topics.sh -alter --partitions 3 --zookeeper 192.168.65.60:2181 --topic test
理解Topic,Partition和Broker:
【1】一個topic,代表邏輯上的一個業務數據集,比如按資料庫里不同表的數據操作消息區分放入不同topic,訂單相關操作消息放入訂單topic,用戶相關操作消息放入用戶topic,對於大型網站來說,後端數據都是海量的,訂單消息很可能是非常巨量的,比如有幾百個G甚至達到TB級別,如果把這麼多數據都放在一臺機器上可定會有容量限制問題,那麼就可以在topic內部劃分多個partition來分片存儲數據,不同的partition可以位於不同的機器上,每台機器上都運行一個Kafka的進程Broker。
為什麼要對Topic下數據進行分區存儲?
【1】commit log文件會受到所在機器的文件系統大小的限制,分區之後可以將不同的分區放在不同的機器上,相當於對數據做了分散式存儲,理論上一個topic可以處理任意數量的數據。
【2】為了提高並行度。
集群消費
【1】log的partitions分佈在kafka集群中不同的broker上,每個broker可以請求備份其他broker上partition上的數據。kafka集群支持配置一個partition備份的數量。
【2】針對每個partition,都有一個broker起到“leader”的作用,0個或多個其他的broker作為“follwers”的作用。leader處理所有的針對這個partition的讀寫請求,而followers被動複製leader的結果,不提供讀寫(主要是為了保證多副本數據與消費的一致性)。如果這個leader失效了,其中的一個follower將會自動的變成新的leader。
Producers
【1】生產者將消息發送到topic中去,同時負責選擇將message發送到topic的哪一個partition中。通過round-robin做簡單的負載均衡。也可以根據消息中的某一個關鍵字來進行區分。通常第二種方式使用的更多。
Consumers
【1】傳統的消息傳遞模式有2種:隊列( queue) 和(publish-subscribe)
queue模式:多個consumer從伺服器中讀取數據,消息只會到達一個consumer。
publish-subscribe模式:消息會被廣播給所有的consumer。
【2】Kafka基於這2種模式提供了一種consumer的抽象概念:consumer group。
queue模式:所有的consumer都位於同一個consumer group 下。
publish-subscribe模式:所有的consumer都有著自己唯一的consumer group。
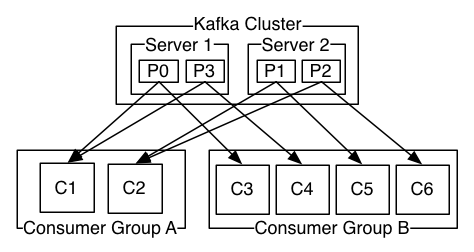
上圖說明:由2個broker組成的kafka集群,某個主題總共有4個partition(P0-P3),分別位於不同的broker上。這個集群由2個Consumer Group消費, A有2個consumer instances ,B有4個。
通常一個topic會有幾個consumer group,每個consumer group都是一個邏輯上的訂閱者( logical subscriber )。每個consumer group由多個consumer instance組成,從而達到可擴展和容災的功能。
消費順序
【1】一個partition同一個時刻在一個consumer group中只能有一個consumer instance在消費,從而保證消費順序。
【2】consumer group中的consumer instance的數量不能比一個Topic中的partition的數量多,否則,多出來的consumer消費不到消息。
【3】Kafka只在partition的範圍內保證消息消費的局部順序性,不能在同一個topic中的多個partition中保證總的消費順序性。
【4】如果有在總體上保證消費順序的需求,那麼我們可以通過將topic的partition數量設置為1,將consumer group中的consumer instance數量也設置為1,但是這樣會影響性能,所以kafka的順序消費很少用。
Java客戶端訪問Kafka
引入maven依賴
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version> </dependency>
消息發送端代碼
public class MsgProducer { private final static String TOPIC_NAME = "my-replicated-topic"; public static void main(String[] args) throws InterruptedException, ExecutionException { /* *********************************配置部分******************************************************/ Properties props = new Properties(); //集群架構訪問集群,防止單節點故障發不出去 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094"); /* 發出消息持久化機制參數 (1)acks=0: 表示producer不需要等待任何broker確認收到消息的回覆,就可以繼續發送下一條消息。性能最高,但是最容易丟消息。(海量數據日誌的話推薦這個,丟些消息其實並不影響) (2)acks=1: 至少要等待leader已經成功將數據寫入本地log,但是不需要等待所有follower是否成功寫入。就可以繼續發送下一條消息。這種情況下,如果follower沒有成功備份數據,而此時leader又掛掉,則消息會丟失。
(一般場景都可以用在這個,適中,也是預設值) (3)acks=-1或all: 需要等待 min.insync.replicas(預設為1,推薦配置大於等於2,即多少個節點寫入成功即可) 這個參數配置的副本個數都成功寫入日誌,這種策略 會保證只要有一個備份存活就不會丟失數據。這是最強的數據保證。一般除非是金融級別,或跟錢打交道的場景才會使用這種配置。(金融場景,對消息十分敏感,不允許丟消息) */ props.put(ProducerConfig.ACKS_CONFIG, "1"); /* 發送失敗會重試,重試次數設置,預設重試間隔100ms,重試能保證消息發送的可靠性,但是也可能造成消息重覆發送,比如網路抖動,所以需要在接收者那邊做好消息接收的冪等性處理。 */ props.put(ProducerConfig.RETRIES_CONFIG, 3); //重試間隔設置 props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
//因為kafka並不是採取,你寫一條,我就發一條的操作,而是在本機申請了,一塊緩衝記憶體。你寫入一條,優先是寫到了本地緩衝記憶體中
//然後客戶端還會有一個線程不斷的從這個本地緩衝記憶體中拿數據放入,發送緩衝區(batch緩衝區【16KB】),拉滿就會發送。(這也是性能為什麼會高的原因之一,還會壓縮數據) //設置發送消息的本地緩衝區,如果設置了該緩衝區,消息會先發送到本地緩衝區,可以提高消息發送性能,預設值是33554432,即32MB props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); /* kafka本地線程會從緩衝區取數據,批量發送到broker, 設置批量發送消息的大小,預設值是16384,即16kb,就是說一個batch滿了16kb就發送出去 */ props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); /* 預設值是0,意思就是消息必須立即被髮送,但這樣會影響性能 一般設置10毫秒左右,就是說這個消息發送完後會進入本地的一個batch,如果10毫秒內,這個batch滿了16kb就會隨batch一起被髮送出去 如果10毫秒內,batch沒滿,那麼也必須把消息發送出去,不能讓消息的發送延遲時間太長 */ props.put(ProducerConfig.LINGER_MS_CONFIG, 10); //把發送的key從字元串序列化為位元組數組 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); //把發送消息value從字元串序列化為位元組數組 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); Producer<String, String> producer = new KafkaProducer<String, String>(props); /* *********************************使用部分******************************************************/ int msgNum = 5; final CountDownLatch countDownLatch = new CountDownLatch(msgNum); //用於非同步的展示 for (int i = 1; i <= msgNum; i++) { Order order = new Order(i, 100 + i, 1, 1000.00); /* *********************************指定分區與不指定分區*****************************************/ //指定發送分區 /*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME , 0, order.getOrderId().toString(), JSON.toJSONString(order));*/ //未指定發送分區,具體發送的分區計算公式:hash(key)%partitionNum ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME , order.getOrderId().toString(), JSON.toJSONString(order)); /* *********************************同步發送與非同步發送(發送完後面還有邏輯優先非同步)*****************************************/ //等待消息發送成功的同步阻塞方法 RecordMetadata metadata = producer.send(producerRecord).get(); System.out.println("同步方式發送消息結果:" + "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset()); //非同步回調方式發送消息 /*producer.send(producerRecord, new Callback() { public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception != null) { System.err.println("發送消息失敗:" + exception.getStackTrace()); } if (metadata != null) { System.out.println("非同步方式發送消息結果:" + "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset()); } countDownLatch.countDown(); } });*/ //業務... } countDownLatch.await(5, TimeUnit.SECONDS); producer.close(); } } @Data public class Order { private Integer orderId; private Integer productId; private Integer productNum; private Double orderAmount; public Order(Integer orderId, Integer productId, Integer productNum, Double orderAmount) { super(); this.orderId = orderId; this.productId = productId; this.productNum = productNum; this.orderAmount = orderAmount; } }
部分說明:
【1】如果不指定分區:
【2】如果配置了重試參數,kafka2.4.1版本如何保證冪等機制:
消息接收端代碼
public class MsgConsumer { private final static String TOPIC_NAME = "my-replicated-topic"; private final static String CONSUMER_GROUP_NAME = "testGroup"; public static void main(String[] args) throws Exception { Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094"); // 消費分組名 props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME); // 是否自動提交offset,預設就是true /*props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自動提交offset的間隔時間 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");*/ props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); /* 當消費主題的是一個新的消費組,或者指定offset的消費方式,offset不存在,那麼應該如何消費 latest(預設) :只消費自己啟動之後發送到主題的消息 earliest:第一次從頭開始消費,以後按照消費offset記錄繼續消費,這個需要區別於consumer.seekToBeginning(每次都從頭開始消費) */ //props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); /* consumer給broker發送心跳的間隔時間,broker接收到心跳如果此時有rebalance發生會通過心跳響應將 rebalance方案下發給consumer,這個時間可以稍微短一點,預設3s */ props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000); /* 服務端broker多久感知不到一個consumer心跳就認為他故障了,會將其踢出消費組,對應的Partition也會被重新分配給其他consumer,預設是10秒 */ props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000); //一次poll最大拉取消息的條數,如果消費者處理速度很快,可以設置大點,如果處理速度一般,可以設置小點,預設500 props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50); /* 如果兩次poll操作間隔超過了這個時間,broker就會認為這個consumer處理能力太弱,會將其踢出消費組,將分區分配給別的consumer消費
有種適者生存的感覺,把處理能力弱的(如2核4G比4核8G弱,而且沒在限定時間內來拿任務)驅逐。【要麼檢查處理過程是否能夠優化縮短時間,要麼調整一次性獲取的條數,要麼增大間隔時間(間隔時間預設的一般不建議調整)】 */ props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(TOPIC_NAME)); // 消費指定分區 //consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); //消息回溯消費 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0))); consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));*/ //指定offset消費 /*consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//指定從TOPIC_NAME的第10條開始消費 consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);*/ //從指定時間點開始消費 /*List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME); //從1小時前開始消費 long fetchDataTime = new Date().getTime() - 1000 * 60 * 60; Map<TopicPartition, Long> map = new HashMap<>();
//將topic的所有partition拿出來 for (PartitionInfo par : topicPartitions) { map.put(new TopicPartition(TOPIC_NAME, par.partition()), fetchDataTime); }
//尋找每個partition的符合時間節點的offset Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
//針對每個partition進行消費 for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) { TopicPartition key = entry.getKey(); OffsetAndTimestamp value = entry.getValue(); if (key == null || value == null) continue; Long offset = value.offset(); System.out.println("partition-" + key.partition() + "|offset-" + offset); System.out.println(); //根據消費里的timestamp確定offset if (value != null) { consumer.assign(Arrays.asList(key)); consumer.seek(key, offset); } }*/ while (true) { /* * poll() API 是拉取消息的長輪詢 */ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(), record.offset(), record.key(), record.value()); } if (records.count() > 0) { // 手動同步提交offset,當前線程會阻塞直到offset提交成功 // 一般使用同步提交,因為提交之後一般也沒有什麼邏輯代碼了 //consumer.commitSync(); // 手動非同步提交offset,當前線程提交offset不會阻塞,可以繼續處理後面的程式邏輯 /*consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if (exception != null) { System.err.println("Commit failed for " + offsets); System.err.println("Commit failed exception: " + exception.getStackTrace()); } } });*/ } } } }
部分說明:
【1】如果設置為 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); 自動提交:
一般需要配置提交時間 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); 【如1秒後提交】,但是由於不可預測到業務完成需要多久時間(假設5s),那麼在處理過程中會出現伺服器宕機的情況,導致消息丟失。如果出現業務執行很快,在0.5s的時候就已經執行業務完成,但是在0.8s的時候伺服器宕機,會造成消息已經消費了,但是中間件不知道(又會發給第二個消費者消費),導致消息重覆消費。【所以自動提交不太可取】
【2】如果設置為 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); 手動提交:
那麼會有兩個選擇:同步提交與非同步提交。
【3】消息回溯消費的機制是怎麼實現的:
因為kafka的消息存儲在log文件裡面,而且對應的還會有index與timeindex(可以加快對於消息的檢索),根據設置給予的offset可以快速定位到是哪個log文件,因為文件名就是offset偏移值。快速拿出數據就可以進行消費了。此外根據時間回溯也是一樣不過量會更大一點。
【4】針對已經存在的tipoc,如果有新的消費組加入,預設是將當前tipoc的最後offset傳給消費組,作為其已消費的記錄。故,如果是要它來幫忙處理消息的,要設置為props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); ,這個消費組如果是已經存在的,那麼這個參數其實不會變動已有的offset。預設處理大數據量的應該採用latest。業務場景則用earliest。
Spring Boot整合Kafka
引入spring boot kafka依賴
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application.yml配置如下:
spring: kafka: bootstrap-servers: 192.168.65.60:9092,192.168.65.60:9093,192.168.65.60:9094 producer: # 生產者 retries: 3 # 設置大於0的值,則客戶端會將發送失敗的記錄重新發送 batch-size: 16384 buffer-memory: 33554432 acks: 1 # 指定消息key和消息體的編解碼方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: default-group enable-auto-commit: false auto-offset-reset: earliest key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: # 當每一條記錄被消費者監聽器(ListenerConsumer)處理之後提交 # RECORD # 當每一批poll()的數據被消費者監聽器(ListenerConsumer)處理之後提交 # BATCH # 當每一批poll()的數據被消費者監聽器(ListenerConsumer)處理之後,距離上次提交時間大於TIME時提交 # TIME # 當每一批poll()的數據被消費者監聽器(ListenerConsumer)處理之後,被處理record數量大於等於COUNT時提交 # COUNT # TIME | COUNT 有一個條件滿足時提交 # COUNT_TIME # 當每一批poll()的數據被消費者監聽器(ListenerConsumer)處理之後, 手動調用Acknowledgment.acknowledge()後提交 # MANUAL # 手動調用Acknowledgment.acknowledge()後立即提交 # MANUAL_IMMEDIATE ack-mode: MANUAL_IMMEDIATE
發送者代碼:
@RestController public class KafkaController { private final static String TOPIC_NAME = "my-replicated-topic"; @Autowired private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("/send") public void send() { kafkaTemplate.send(TOPIC_NAME, 0, "key", "this is a msg"); } }
消費者代碼:
@Component public class MyConsumer { /** * @KafkaListener(groupId = "testGroup", topicPartitions = { * @TopicPartition(topic = "topic1", partitions = {"0", "1"}), * @TopicPartition(topic = "topic2", partitions = "0", * partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100")) * },concurrency = "6") * //concurrency就是同組下的消費者個數,就是併發消費數,必須小於等於分區總數 * @param record */ @KafkaListener(topics = "my-replicated-topic",groupId = "zGroup") public void listenZGroup(ConsumerRecord<String, String> record, Acknowledgment ack) { String value = record.value(); System.out.println(value); System.out.println(record); //手動提交offset //ack.acknowledge(); } //配置多個消費組 /*@KafkaListener(topics = "my-replicated-topic",groupId = "tuGroup") public void listenTuGroup(ConsumerRecord<String, String> record, Acknowledgment ack) { String value = record.value(); System.out.println(value); System.out.println(record); ack.acknowledge(); }*/ }
Kafka設計原理詳解
Kafka核心總控制器Controller
在Kafka集群中會有一個或者多個broker,其中有一個broker會被選舉為控制器(Kafka Controller),它負責管理整個集群中所有分區和副本的狀態。
當某個分區的leader副本出現故障時,由控制器負責為該分區選舉新的leader副本。 當檢測到某個分區的ISR集合發生變化時,由控制器負責通知所有broker更新其元數據信息。 當使用kafka-topics.sh腳本為某個topic增加分區數量時,同樣還是由控制器負責讓新分區被其他節點感知到。
Controller選舉機制
【1】在kafka集群啟動的時候,會自動選舉一臺broker作為controller來管理整個集群,選舉的過程是集群中每個broker都會嘗試在zookeeper上創建一個 /controller 臨時節點,zookeeper會保證有且僅有一個broker能創建成功,這個broker就會成為集群的總控器controller。
【2】當這個controller角色的broker宕機了,此時zookeeper臨時節點會消失,集群里其他broker會一直監聽這個臨時節點,發現臨時節點消失了,就競爭再次創建臨時節點,就是我們上面說的選舉機制,zookeeper又會保證有一個broker成為新的controller。
【3】具備控制器身份的broker需要比其他普通的broker多一份職責,具體細節如下:
1.監聽broker相關的變化。為Zookeeper中的/brokers/ids/節點添加BrokerChangeListener,用來處理broker增減的變化。 2.監聽topic相關的變化。為Zookeeper中的/brokers/topics節點添加TopicChangeListener,用來處理topic增減的變化;為Zookeeper中的/admin/delete_topics節點添加TopicDeletionListener,用來處理刪除topic的動作。 3.從Zookeeper中讀取獲取當前所有與topic、partition以及broker有關的信息併進行相應的管理。對於所有topic所對應的Zookeeper中的/brokers/topics/[topic]節點添加PartitionModificationsListener,用來監聽topic中的分區分配變化。 4.更新集群的元數據信息,同步到其他普通的broker節點中。
Partition副本選舉Leader機制
【1】controller感知到分區leader所在的broker掛了(controller監聽了很多zk節點可以感知到broker存活),controller會從ISR列表(參數unclean.leader.election.enable=false的前提下)里挑第一個broker作為leader(第一個broker最先放進ISR列表,可能是同步數據最多的副本)【這種會阻塞直到ISR列表有數據】,如果參數unclean.leader.election.enable為true,代表在ISR列表裡所有副本都掛了的時候可以在ISR列表以外的副本中選leader,這種設置,可以提高可用性,但是選出的新leader有可能數據少很多。【其實就是知道/broker/ids/下麵的數據沒了】
【2】副本進入ISR列表有兩個條件:
1.副本節點不能產生分區,必須能與zookeeper保持會話以及跟leader副本網路連通
2.副本能複製leader上的所有寫操作,並且不能落後太多。(與leader副本同步滯後的副本,是由 replica.lag.time.max.ms 配置決定的,超過這個時間都沒有跟leader同步過的一次的副本會被移出ISR列表)
消費者消費消息的offset記錄機制
【1】每個consumer會定期將自己消費分區的offset提交給kafka內部topic:__consumer_offsets,提交過去的時候,key是consumerGroupId+topic+分區號,value就是當前offset的值,kafka會定期清理topic里的消息,最後就保留最新的那條數據。【相當於記錄了這個消費組在這個topic的某分區上消費到了哪】
【2】因為__consumer_offsets可能會接收高併發的請求,kafka預設給其分配50個分區(可以通過offsets.topic.num.partitions設置),這樣可以通過加機器的方式抗大併發。
【3】通過如下公式可以選出consumer消費的offset要提交到__consumer_offsets的哪個分區
公式:hash(consumerGroupId) % __consumer_offsets主題的分區數
【4】早期這個就是記錄在zookeeper中,但是併發度不高,所以才轉到了broker中。
消費者Rebalance機制(再平衡機制)
【1】rebalance就是說如果消費組裡的消費者數量有變化或消費的分區數有變化,kafka會重新分配消費者消費分區的關係。比如consumer group中某個消費者掛了,此時會自動把分配給他的分區交給其他的消費者,如果他又重啟了,那麼又會把一些分區重新交還給他。
【2】註意:rebalance只針對subscribe這種不指定分區消費的情況,如果通過assign這種消費方式指定了分區,kafka不會進行rebanlance。
【3】如下情況可能會觸發消費者rebalance
1.消費組裡的consumer增加或減少了 2.動態給topic增加了分區 3.消費組訂閱了更多的topic
【4】rebalance過程中,消費者無法從kafka消費消息,這對kafka的TPS會有影響,如果kafka集群內節點較多,比如數百個,那重平衡可能會耗時極多,所以應儘量避免在系統高峰期的重平衡發生。
消費者Rebalance分區分配策略:
【1】主要有三種rebalance的策略:range、round-robin、sticky。
【2】Kafka 提供了消費者客戶端參數partition.assignment.strategy 來設置消費者與訂閱主題之間的分區分配策略。預設情況為range分配策略。
【3】假設一個主題有10個分區(0-9),現在有三個consumer消費:
1)range策略就是按照分區序號排序,假設 n=分區數/消費者數量 = 3, m=分區數%消費者數量 = 1,那麼前 m 個消費者每個分配 n+1 個分區,後面的(消費者數量-m )個消費者每個分配 n 個分區。比如分區0~3給一個consumer,分區4~6給一個consumer,分區7~9給一個consumer。
2)round-robin策略就是輪詢分配,比如分區0、3、6、9給一個consumer,分區1、4、7給一個consumer,分區2、5、8給一個consumer。
3)sticky策略初始時分配策略與round-robin類似,但是在rebalance的時候,需要保證如下兩個原則。
1)分區的分配要儘可能均勻 。
2)分區的分配儘可能與上次分配的保持相同。
當兩者發生衝突時,第一個目標優先於第二個目標 。這樣可以最大程度維持原來的分區分配的策略。比如對於第一種range情況的分配,如果第三個consumer掛了,那麼重新用sticky策略分配的結果如下:
consumer1除了原有的0~3,會再分配一個7
consumer2除了原有的4~6,會再分配8和9
Rebalance過程
【1】當有消費者加入消費組時,消費者、消費組及組協調器之間會經歷以下幾個階段。圖示過程:

【2】第一階段:選擇組協調器
組協調器GroupCoordinator:每個consumer group都會選擇一個broker作為自己的組協調器coordinator,負責監控這個消費組裡的所有消費者的心跳,以及判斷是否宕機,然後開啟消費者rebalance。
consumer group中的每個consumer啟動時會向kafka集群中的某個節點發送 FindCoordinatorRequest 請求來查找對應的組協調器GroupCoordinator,並跟其建立網路連接。
組協調器選擇方式:
consumer消費的offset要提交到__consumer_offsets的哪個分區,這個分區leader對應的broker就是這個consumer group的coordinator
【3】第二階段:加入消費組JOIN GROUP
在成功找到消費組所對應的 GroupCoordinator 之後就進入加入消費組的階段,在此階段的消費者會向 GroupCoordinator 發送 JoinGroupRequest 請求,並處理響應。然後GroupCoordinator 從一個consumer group中選擇第一個加入group的consumer作為leader(消費組協調器),把consumer group情況發送給這個leader,接著這個leader會負責制定分區方案。
【4】第三階段( SYNC GROUP)
consumer leader通過給GroupCoordinator發送SyncGroupRequest,接著GroupCoordinator就把分區方案下發給各個consumer【心跳的時候】,他們會根據指定分區的leader broker進行網路連接以及消息消費。
producer發佈消息機制剖析
【1】寫入方式
producer 採用 push 模式將消息發佈到 broker,每條消息都被 append 到 patition 中,屬於順序寫磁碟(順序寫磁碟效率比隨機寫記憶體要高,保障 kafka 吞吐率)。
【2】消息路由
producer 發送消息到 broker 時,會根據分區演算法選擇將其存儲到哪一個 partition。其路由機製為:
1. 指定了 patition,則直接使用; 2. 未指定 patition 但指定 key,通過對 key 的 value 進行hash 選出一個 patition 3. patition 和 key 都未指定,使用輪詢選出一個 patition。
【3】寫入流程
如圖:
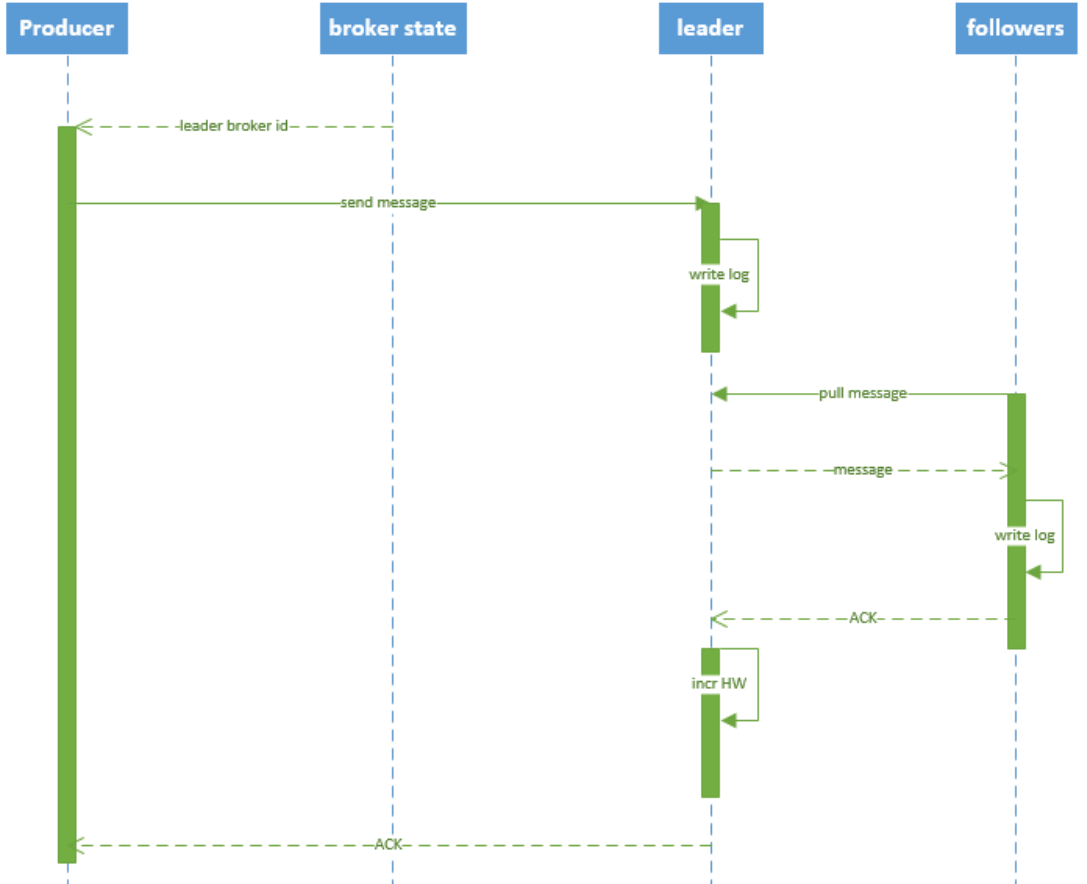
說明:
1. producer 先從 zookeeper 的 "/brokers/.../state" 節點找到該 partition 的 leader 2. producer 將消息發送給該 leader 3. leader 將消息寫入本地 log 4. followers 從 leader pull 消息,寫入本地 log 後 向leader 發送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 後,增加 HW(high watermark,最後 commit 的 offset) 並向 producer 發送 ACK

