
決策引擎是風控的大腦,而決策樹的編排能力和體驗是構建大腦的手段,如何構建高效、絲滑、穩定可靠的決策樹編排能力,是對風控決策引擎的一大挑戰,本篇文章和大家分享一下過往構建心得。 ...
引言
本篇主要聚焦介紹風控決策引擎中決策樹編排能力的構建。決策引擎是風控的大腦,而決策樹的編排能力和體驗是構建大腦的手段,如何構建高效、絲滑、穩定可靠的決策樹編排能力,是對風控決策引擎的一大挑戰,本篇文章和大家分享一下過往構建心得。
背景
任何系統在初期構建肯定不是往“一步到位”的方向去構建的,只是架構設計者儘量向後期可擴展、可維護的方向去搭建。好的底層設計,不怕產品後期瘋狂迭代,且改動調整方便。糟糕的“填鴨式”代碼,可能在當時為了儘快實現了功能,最終也會逐步發展成“屎山”,維護成本越來越高,要麼跑路,要麼只能另起爐竈。
MVP 小步迭代 1.0
此階段目標:最小化可行產品(MVP);小布迭代,快速上線;一人分飾多角色。
風控部門成立初期,人員少,缺少 UED 和 前端,畢竟風控本身對視覺設計和前端不是剛需,主要是後端研發和策略運營對抗黑產即可。此時為了能儘快上線決策樹功能,研發人員本著小步快跑的思想,直接在代碼層資源目錄 resource 下放置決策樹靜態配置文件(具體實現在下文分解),每次更改都需要發版。本身引擎的構建也是不完善的,需要添加的功能很多,一周發個幾版也是家常便飯的事,此階段大家也是能接受的。
“由靜轉動”2.0
此階段目標:無需發版,生產快速變更;穩定性相關考慮。
隨著部門隊伍的逐步壯大,以及研發流程的規範,風控策略運營人員對於決策編排的響應時效和可視化能力需求越來越迫切,對於研發需要發版才能部署新的決策能力現狀不滿,黑產是高效的,但是研發發版又是需要編排和時間的,大家都要發版,且集中在一個發版周期,策略周一提出的修改,待到周三和大家的需求一起上,此時黑產早擼完跑路了。同時發版是有一定的風險的,出錯了需要立即回滾,此時又延誤了策略上線的時間。
基於上述,我們考慮到是時候開放生產環境直接可視化的編排決策樹能力了,但是我們沒有前端的同學,找別的部門借可能又不熟悉決策引擎這一套流程規範,溝通成本還高。那折中了一個方案:將靜態配置文件挪到 DB 存儲中去,且配置以文本字元的形式展現在前端即可,不需要複雜的前端設計,只需要簡單的表單文本框填充即可滿足研發修改決策流的訴求。這樣讓原本靜態的配置“動”起來,直接在生產可配置,大大提高了生產部署的效率。
可視化決策流編排 3.0
此階段目標:高效、穩定、智能的可視化決策樹編排能力產品構建
接入風控的業務線越來越多,研發人員忙於風險場景對應的變數開發迭代,此時還需要分出一部分精力負責修改決策樹。2.0 版本的決策樹對運營來說就是一段字元串,不是一棵樹,策略運營是沒辦法修改,也不敢修改,出錯的風險太大。考慮到整個風控的體量和模式已經非常穩定了,也有一定的時間去考慮將決策編排做成一個可視化的產品交付策略人員使用了,畢竟決策樹的調整本身也是策略的職責之一,需要將此沉澱為一個高可用的產品。
我們參照了業內 BPMN 工作流的前端樣式設計規範,摘取了在風控決策樹種需要用到的元素,構建了自己的決策引擎智能編排能力,可視化的拖拽節點,可完全交付給策略人員自行配置使用。
設計實現
技術選型
決策樹,實際上就是一個變種 DAG(有向無環圖),圖中的節點在業務層面有不同的屬性及功能。
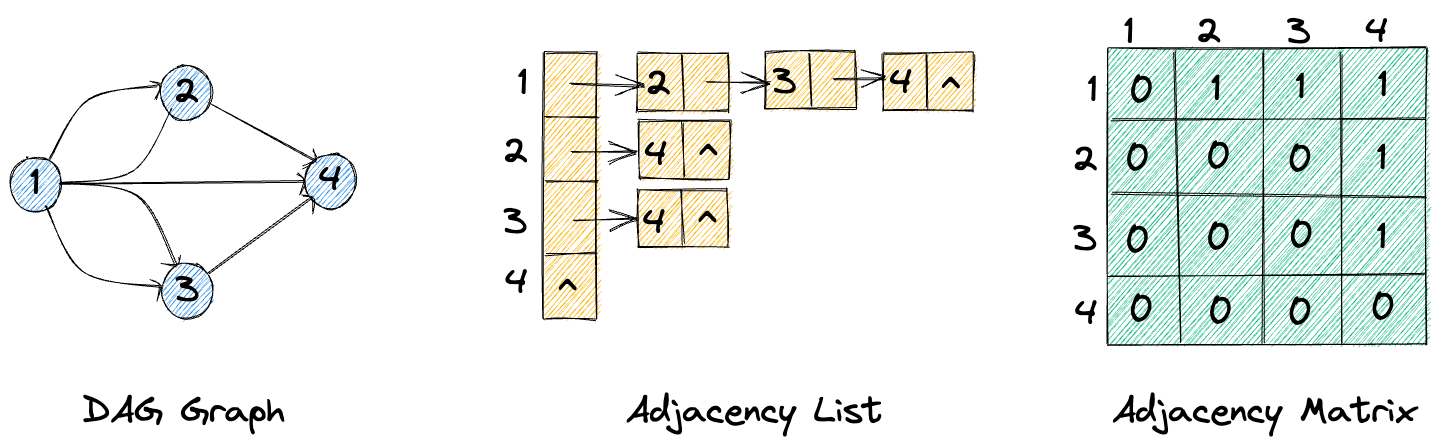
那麼如何存儲這個 DAG 結構呢?用二維數組存儲,是不能滿足節點屬性及邊屬性要求的,一是邊界沒法定義,可能這棵樹很大,二是假設屬性由關聯表來實現,就會很割裂,沒法直觀看得到。
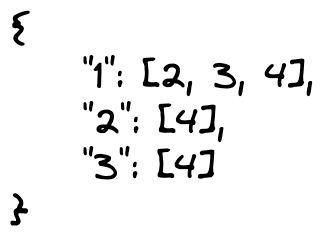
其實圖可以用鏈表表示,鏈表的存儲結構第一反應就是 JSON 或者 XML 來表示。可以想象, 如果用 JSON 來表示的話,層級嵌套關係會非常繁瑣,畢竟 JSON 是用來序列化數據用的,展示方面,還是 XML 添加屬性更為方便直觀。
數據結構
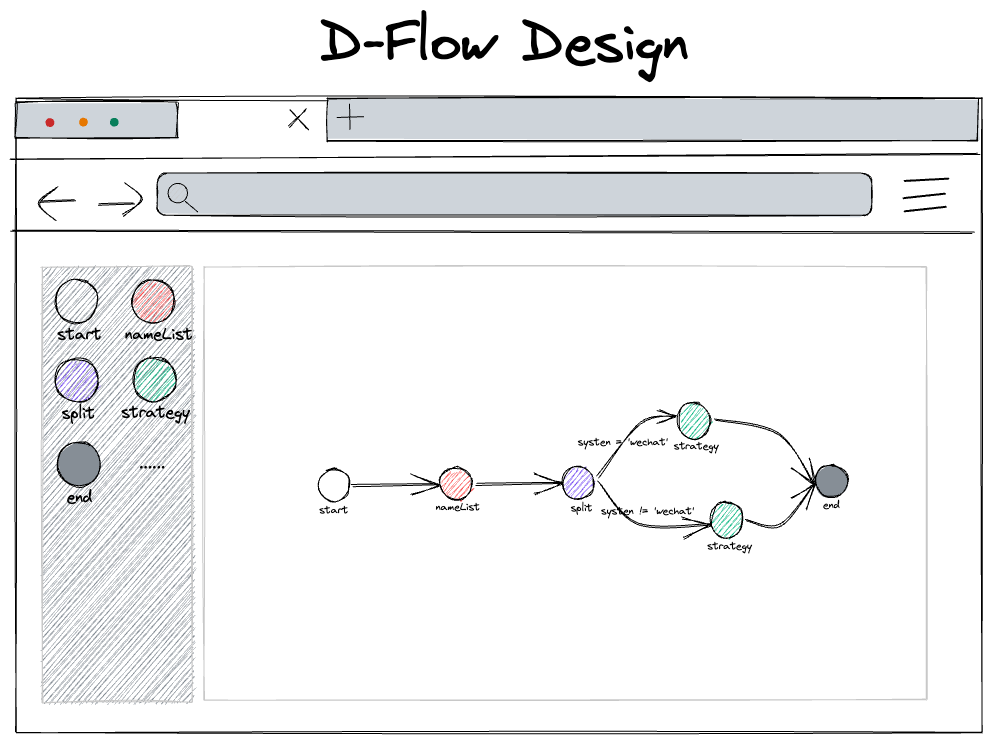
舉例簡易決策樹如下
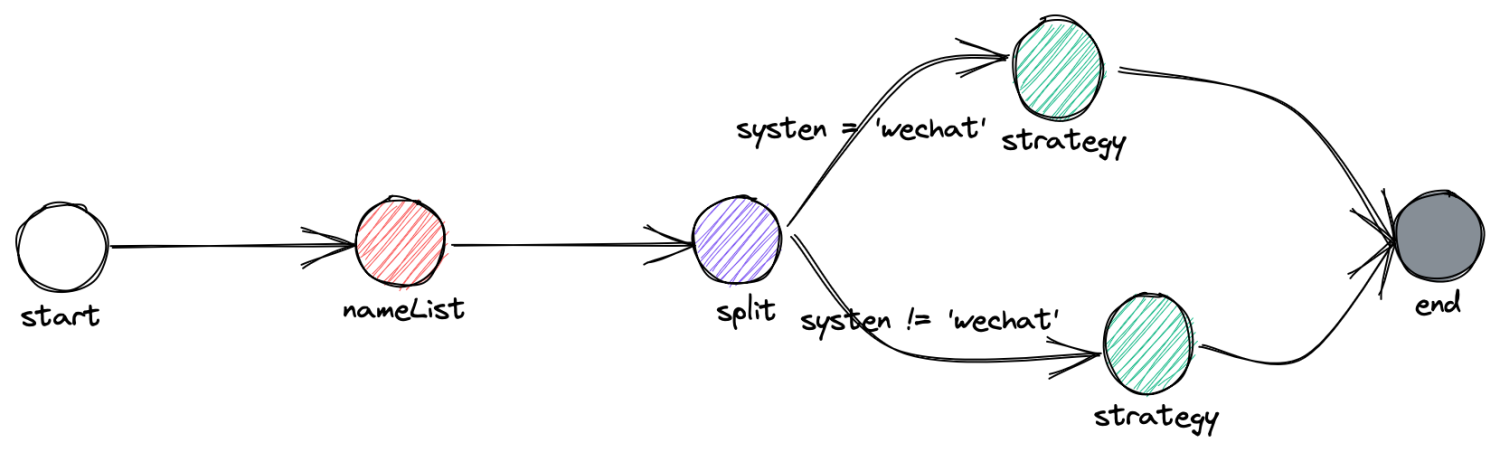
如上決策樹用 XML 數據結構表示如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<flow id="test01" desc="建議決策流">
<!-- 開始節點 -->
<start id="start">
<!-- 鏈接到下一節點 -->
<link to="black01"/>
</start>
<!-- 名單節點 -->
<nameList id="black01" desc="黑名單">
<!-- 名單屬性:名單類型:黑/白/灰;領域類型;適用範圍 -->
<field key="type" val="black"/>
<field key="domain" val="10001,10002"/>
<field key="scope" val="deviceHash,phone,uid"/>
<link to="split01"/>
</nameList>
<!-- 分流節點 -->
<split id="split01" desc="是否為微信渠道">
<!-- 條件分支 -->
<condition order="0" desc="是" expr="system == 'wechat'" to="strategy01"/>
<condition order="10" desc="否" to="strategy02"/>
</split>
<!-- 策略節點 -->
<strategy id="strategy01" desc="微信專屬策略">
<!-- 關聯專屬策略元數據 -->
<field key="strategyGuid" val="25F7C71A5F834F24A12C478CEE4CB9EB"/>
<link to="end"/>
</strategy>
<strategy id="strategy02" desc="非微信渠道策略">
<field key="strategyGuid" val="0FC8A95A4D6A4F169C77950BB4A98D80"/>
<link to="end"/>
</strategy>
<!-- 結束節點 -->
<end id="end" desc="結束"/>
</flow>
上述數據結構非常直觀的表示了當前需要繪製的決策樹數據結構,相較於 JSON 的數據表現形式,XML 更靈活,擴展更方便,在橫向和深度上可以有較好的平衡。
決策流解析
XML 是很成熟的技術實現了,市面上有很多解析 XML 的開源實現,如上數據結構我使用 common-digester解析,POM 中引入如下依賴即可:
<!-- https://mvnrepository.com/artifact/commons-digester/commons-digester -->
<dependency>
<groupId>commons-digester</groupId>
<artifactId>commons-digester</artifactId>
<version>1.8.1</version>
</dependency>
實體關係如下:
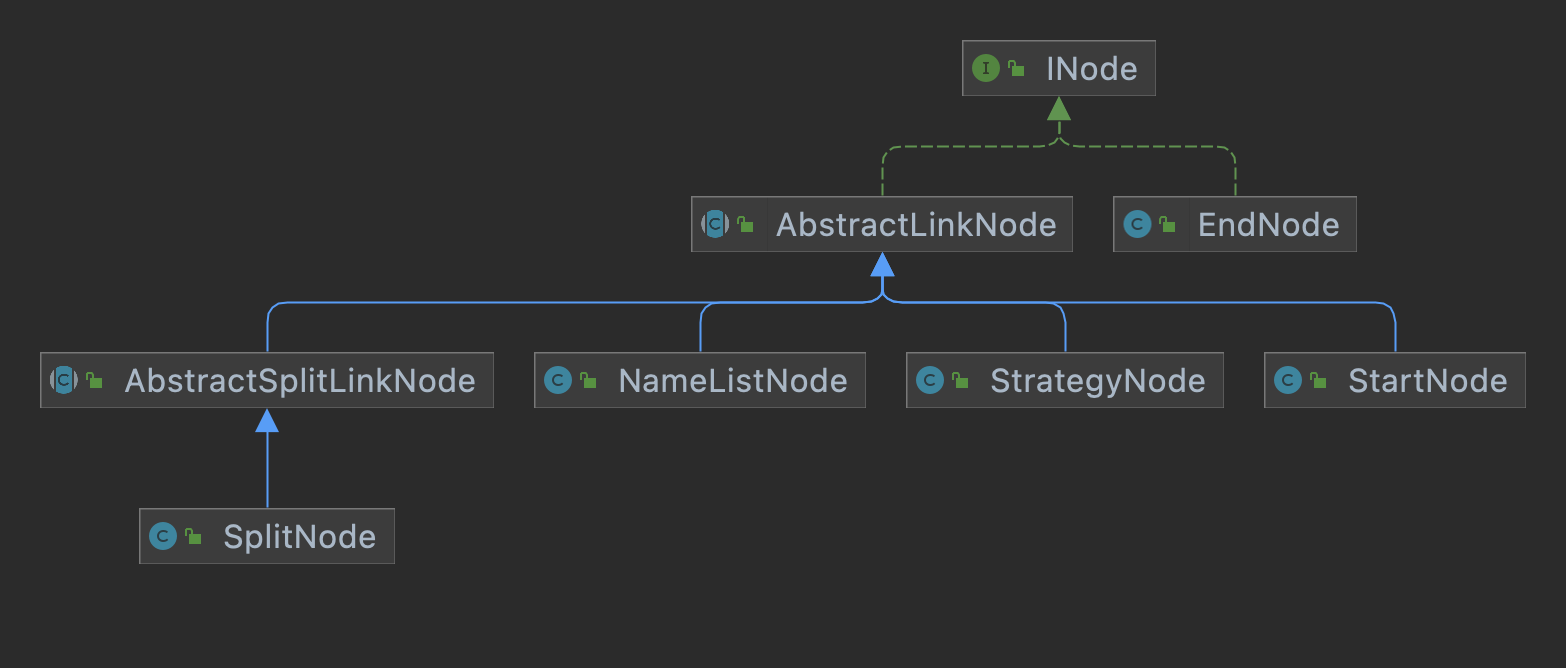
XML 數據解析如下:
@Data
public class FlowEntity {
private String id;
private String desc;
private INode startNode;
private Map<String, INode> nodeMap = new HashMap<>();
}
Digester digester = new Digester();
// parse flow node
digester.addObjectCreate("flow", FlowEntity.class);
digester.addSetProperties("flow");
// parse start node
digester.addObjectCreate("flow/start", StartNode.class);
digester.addSetProperties("flow/start");
// 在 FlowEntity 實現 addNode 方法,將當前節點錄入
digester.addSetNext("flow/start", "addNode");
digester.addObjectCreate("flow/start/link", LinkBranch.class);
digester.addSetProperties("flow/start/link");
// 在 StartNode 實現 addLink 方法,將當前邊錄入
digester.addSetNext("flow/start/link", "addLink");
// parse split node
digester.addObjectCreate("flow/split", SplitNode.class);
digester.addSetProperties("flow/split");
digester.addSetNext("flow/split", "addNode");
digester.addObjectCreate("flow/split/condition", ConditionBranch.class);
digester.addSetProperties("flow/split/condition");
// 在 SplitNode 實現 addCondition 方法,將當前條件錄入
digester.addSetNext("flow/split/condition", "addCondition");
// 省略...
InputStream inputStream = new ByteArrayInputStream(xmlResource.getBytes());
return (FlowEntity) digester.parse(inputStream);
其中 addNode 邏輯為將所有節點都存儲在一個 nodeMap 結構內,並且如果當前節點是開始節點,則賦值到
startNode節點。
當 XML 解析完後,此時關聯關係還沒有建立,輪詢每個節點後將節點與節點之間聯繫起來,並且校驗節點是夠存在,確保能關聯成一個樹。
public void assembleToNode(Map<String, INode> nodeMap) {
if (Objects.isNull(nodeMap)) {
return;
}
if (!nodeMap.containsKey(this.to)) {
throw new RuntimeException(String.format("%s to: %s can't find node from nodeMap", this.desc, this.to));
}
this.toNode = nodeMap.get(this.to);
}
決策流執行
決策的執行只需要從 startNode 執行開始,遞歸執行,直到找到唯一的出口彈出即可。註意,策略介面是有輸出決策結果的,如果是拒絕的話,此時可以直接中斷流程執行,返回結果即可。
@Override
public void execute(FlowContext context) {
// 出口
if (this instanceof EndNode) {
return;
}
// 遞歸執行
this.execute(context);
}
其中,SplitNode節點執行需要計算條件表達式,只要滿足一個條件,即可確定往下走的節點,子類覆蓋實現如下:
註:條件表達式我之前單獨發了一篇文章,感興趣的話歡迎關註,可在我的歷史文章歸檔中查找,此處就不在展開說明瞭。
@Override
public void execute(FlowContext context) {
Validate.notEmpty(condition, "node id: {} desc: {} [condition] is empty", this.getId(), this.getDesc());
// 主動判斷
Optional<ConditionBranch> target = condition.stream().filter(c -> c.evaluate(context)).findFirst();
// TODO: 考慮返回預設兜底分支節點
if (!target.isPresent()) {
throw new RuntimeException("node id: {} ConditionBranch expr execute find nothing, please check your expr condition");
}
target.get().getToNode().execute(context);
}
StrategyNode 節點執行原理和 SplitNode 一致,只需要子類覆寫實現方法,去執行相應的規則引擎,獲取到決策結果,即可判斷走向,此處就不在列出。
如上設計好了決策樹的存儲結構,再配合前端同學構建的基於 BPMN 流圖的樣式配合,定製風控需要的節點信息和表達,即可隨時構建一棵理想的樹(此處一句話帶過,但在絲滑編排和輔助校驗上,前端同學付出了很多,當然這不是本篇文章的重點)。
總結
本文分享了決策引擎中決策流圖的思考及構建過程,從最小可用產品上線支撐業務發展到沉澱出可視化編排能力的工作區。當然,本文僅僅展示了通用決策流的思考構建過程,顯示業務中還是會遇到各種挑戰,比如對性能的要求、對成本的控制等等,挑戰非常多,我將在後續一一分享出來,歡迎關註。
往期精彩
歡迎關註公眾號:咕咕雞技術專欄
個人技術博客:https://jifuwei.github.io/


