
分治的理解 把規模為n的問題P(n),分解為k個規模較小、互相獨立、結構與原來問題結構相同的子問題,又進一步的分解每個子問題,直到某個閥值n0為止。遞歸地解這些子問題,再把子問題的解合併起來,得到原問題的解。 divide-and-conquer(P) { if ( | P | <= n0) adh ...
分治的理解
把規模為n的問題P(n),分解為k個規模較小、互相獨立、結構與原來問題結構相同的子問題,又進一步的分解每個子問題,直到某個閥值n0為止。遞歸地解這些子問題,再把子問題的解合併起來,得到原問題的解。
divide-and-conquer(P)
{
if ( | P | <= n0) adhoc(P); //解決小規模的問題
divide P into smaller subinstances P1,P2,...,Pk;//分解問題
for (i=1,i<=k,i++)
yi=divide-and-conquer(Pi); //遞歸的解各子問題
return merge(y1,...,yk); //將各子問題的解合併為原問題的解
}
人們從大量實踐中發現,在用分治法設計演算法時,最好使子問題的規模大致相同。即將一個問題分成大小相等的k個子問題的處理方法是行之有效的。這種使子問題規模大致相等的做法是出自一種平衡(balancing)子問題的思想,它幾乎總是比子問題規模不等的做法要好。
分治法設計步驟
三個步驟組成:
-
劃分步:把輸入的問題實例劃分為k個子問題。儘量使k個子問題的規模大致相同。在很多情況下,使k=2。也有k=1的劃分,仍把問題劃分成兩部分,取其中的一部分,而丟棄另一部分,如二叉檢索問題用分治法處理 。
-
治理步:當問題的規模大於某個預定義的閥值n0時,治理步由k個遞歸調用組成。
閥值n0的選取:閥值可為任何正常數,大小與演算法的性能有關。取決於演算法中的adhoc對閥值n0的敏感程度,以及merge的處理情況。
-
組合步:把子問題的解組合起來,對分治演算法的實際性能至關重要 。演算法的有效性很大程度上依賴於組合步的實現!
分治法的複雜性分析
一個分治法將規模為n的問題分成k個規模為n/m的子問題去解。設分解閥值n0=1,且adhoc解規模為1的問題耗費1個單位時間。再設將原問題分解為k個子問題以及用merge將k個子問題的解合併為原問題的解需用f(n)個單位時間。用T(n)表示該分治法解規模為|P|=n的問題所需的計算時間,則有:
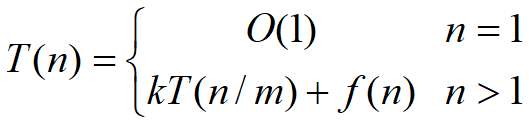
題目
給定數組a[0:n-1],試設計一個演算法,在最壞情況下用┌ 3n/2-2 ┐次比較找出a[0:n-1]中元素的最大值和最小值。
-
演算法思想
- 用分治法求最大值和次大值首先將問題劃分,即將劃分成長度相等的兩個序列,遞歸求出 左邊的最大值次大值,再求出右邊的的最大值次大值,比較左右兩邊,最後得出問題的解。
-
複雜度分析:
-
把問題劃分為左右兩種的情況,需要分別遞歸求解,時間複雜度可如下計算:
-
有遞推公式為:
-
- T(n)= 1 n=l - T(n)=2T(n/2)+l n>l -
所以,分治演算法的時間複雜度是n+[logn]-2,當n為奇數時,logn取上線,當n為偶數時,logn取下線。
-
-
#include<stido.h> int a[100]; void maxcmax(int i,int j,int &max,int &cmax){ int lmax,lcmax,rmax,rcmax; int mid; if(i==j){ max=a[i]; cmax=a[i]; } else if(i==j-1){ if(a[i]<a[j]){ max=a[j]; cmax=a[i]; }else{ max=a[i]; cmax=a[j]; } }else{ mid = (i+j)/2; maxcmax(i,mid,lmax,lcmax); maxcmax(mid+1,j,rmax,rcmax); if(lmax>rmax){ if(lcmax>rmax){ max=lmax; cmax=lcmax; }else{ max=lmax; cmax=rmax; } }else{ if(rcmax>lmax){ if(rcmax==rcmax){ max=lmax; cmax=lcmax; }else{ max=lmax; cmax=rmax; } }else{ max=rmax; cmax=lmax; } } } }


