
本文講述了朴素貝葉斯的原理,概率的計算方式,給出代碼的詳細解釋,並最後給出代碼的運行過程的總結,然後又用了兩個實例來講述朴素貝葉斯代碼的計算過程 ...
1.優缺點
優點:-
在數據較少的情況下仍然有效,
-
可以處理多類別問題。
缺點:
-
對於輸入數據的準備方式較為敏感。
-
適用數據類型:標稱型數據
2.朴素貝葉斯的一般過程
(1) 收集數據:可以使用任何方法。本章使用RSS源。
(2) 準備數據:需要數值型或者布爾型數據。
(3) 分析數據:有大量特征時,繪製特征作用不大,此時使用直方圖效果更好。
(4) 訓練演算法:計算不同的獨立特征的條件概率。
(5) 測試演算法:計算錯誤率。
(6) 使用演算法:一個常見的朴素貝葉斯應用是文檔分類。可以在任意的分類場景中使用樸
素貝葉斯分類器,不一定非要是文本。
3.概率論知識補充
3.1條件概率
下圖公式表示在事件A發生的條件下,B發生的概率
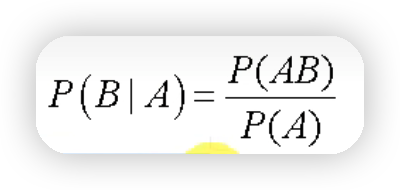
3.2全概率公式
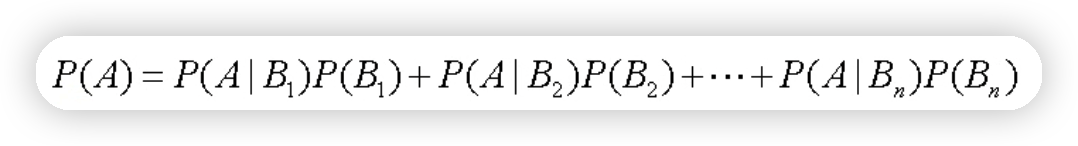
3.3貝葉斯公式
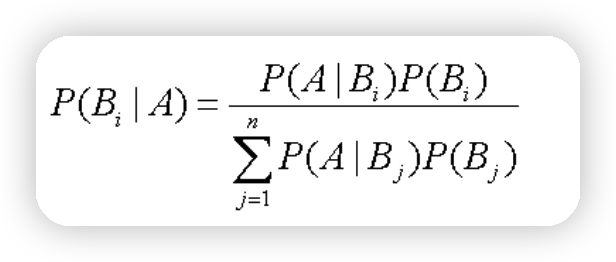

4.使用 Python 進行文本分類
4.1準備數據:從文本中構建詞向量
我們將把文本看成單詞向量或者詞條向量,也就是說將句子轉換為向量
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的詞條
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #類別標簽向量,1代表侮辱性辭彙,0代表不是
return postingList,classVec
#創建辭彙表-文檔向量化的第一步,將所有單詞放入set集合中(去除重覆的單詞)
#原數據集中去掉重覆的單詞之後,一共有32個單詞
def createVocabList(dataSet):
vocabSet = set([]) #創建一個空的不重覆列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取並集
return list(vocabSet)
#詞集法-文檔向量化的第二步
#inputSet - 切分的詞條列表(最初的postingList的每一行)
# vocabList - createVocabList返回的列表
#思想,遍歷inputSet中的每一個單詞,若在vocabList中存在,則將出現的位置的值設置為1即可
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #創建一個其中所含元素都為0的向量
for word in inputSet: #遍歷每個詞條
if word in vocabList: #如果詞條存在於辭彙表中,則置1
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返迴文檔向量
得到的向量集為:

4.2從詞向量計算概率
#朴素貝葉斯分類器訓練函數
# trainMatrix - 訓練文檔矩陣,即setOfWords2Vec返回的returnVec構成的矩陣
# trainCategory - 訓練類別標簽向量,即loadDataSet返回的classVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)#計算訓練的文檔數目 6
numWords = len(trainMatrix[0]) #計算每篇文檔的詞條數 32
pAbusive = sum(trainCategory)/float(numTrainDocs)#文檔屬於侮辱類的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords)#創建numpy.zeros數組,詞條出現數初始化為0
p0Denom = 2.0; p1Denom = 2.0 #分母初始化為0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #統計屬於侮辱類的條件概率所需的數據,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]#計算侮辱性單詞所在行每個單詞出現的頻數
p1Denom += sum(trainMatrix[i])#侮辱性單詞所在行的總共單詞的個數
else: #統計屬於非侮辱類的條件概率所需的數據,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]#計算非侮辱性單詞所在行每個單詞出現的頻數
p0Denom += sum(trainMatrix[i])#非侮辱性單詞所在行單詞的總個數
p1Vect = np.log(p1Num/p1Denom)#計算侮辱性單詞所在行的每個單詞是侮辱性單詞的概率
p0Vect = np.log(p0Num/p0Denom)#計算非侮辱性單詞所在行的每個單詞是非侮辱性單詞的概率
return p0Vect,p1Vect,pAbusive
4.3根據現實情況修改分類器
利用貝葉斯分類器對文檔進行分類時,要計算多個概率的乘積以獲得文檔屬於某個類別的概 率,即計算p(w0|1)p(w1|1)p(w2|1)。如果其中一個概率值為0,那麼最後的乘積也為0。為降低 這種影響,可以將所有詞的出現數初始化為1,並將分母初始化為2。p0Num = np.ones(numWords); p1Num = np.ones(numWords)#創建numpy.zeros數組,詞條出現數初始化為0
p0Denom = 2.0; p1Denom = 2.0 #分母初始化為0
另一個遇到的問題是下溢出,這是由於太多很小的數相乘造成的。當計算乘積 p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)時,由於大部分因數都非常小,所以程式會下溢出或者 得到不正確的答案。(讀者可以用Python嘗試相乘許多很小的數,最後四捨五入後會得到0。)一 種解決辦法是對乘積取自然對數。在代數中有ln(a*b) = ln(a)+ln(b),於是通過求對數可以 避免下溢出或者浮點數舍入導致的錯誤。同時,採用自然對數進行處理不會有任何損失。
p1Vect = np.log(p1Num/p1Denom)#計算侮辱性單詞所在行的每個單詞是侮辱性單詞的概率
p0Vect = np.log(p0Num/p0Denom)#計算非侮辱性單詞所在行的每個單詞是非侮辱性單詞的概率
朴素貝葉斯分類函數
#朴素貝葉斯分類器分類函數
# vec2Classify - 待分類的詞條數組
# p0Vec - 侮辱類的條件概率數組
# p1Vec -非侮辱類的條件概率數組
# pClass1 - 文檔屬於侮辱類的概率
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify*p1Vec)+np.log(pClass1) #計算測試集對應每個單詞是侮辱性的概率
p0 = sum(vec2Classify*p0Vec)+np.log(1.0-pClass1)#計算測試集中對應每個單詞是非侮辱性單詞的概率
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
#測試朴素貝葉斯分類器
def testingNB():
listOPosts,listClasses = loadDataSet() #創建實驗樣本
myVocabList = createVocabList(listOPosts) #創建辭彙表
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #將實驗樣本向量化
p0V,p1V,pAb = trainNB0(trainMat,listClasses)#訓練朴素貝葉斯分類器
testEntry = ['love', 'my', 'dalmation'] #測試樣本1
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))#測試樣本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'屬於侮辱類') #執行分類並列印分類結果
else:
print(testEntry,'屬於非侮辱類')#執行分類並列印分類結果
testEntry = ['stupid', 'garbage']#測試樣本2
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #測試樣本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'屬於侮辱類') #執行分類並列印分類結果
else:
print(testEntry,'屬於非侮辱類')
測試結果:

總結:整個代碼完成的步驟如下:
-
由原始數據得到分類列表,將原始數據存入set集合中去除重覆數據
-
由set集合和原始數據得到向量集
- 迴圈遍歷原始數據的每一行,並判斷該行中每個元素在set集合中是否存在,若存在,則將set集合中對應位置設為1,最後得到一個一行set集合中元素個數這麼多列的一個向量組,依次類推,原始數據每一行都得到一個向量組,最終組成原始數據的向量集
-
計算概率
-
迴圈遍歷分類數據集中每一個元素,根據該元素找到其在向量集中所在的行,然後統計該行每個元素出現的頻次和改行總元素的個數,依次類推,找到每個類別所在行元素出現的頻次,以及該類別對應元素的總個數
-
最後根據每個類別的元素出現的頻次除以該類別下元素的總數,得到每個元素是該類別的概率
-
-
測試數據集
-
首先計算出測試數據集對應的向量集(也就是測試集中的元素出現在set集合中的位置設為1)
-
然後根據該向量集和之前得到的每個元素是每一類別的概率的數據集相乘,就可以得到測試集中每個元素是某一類別的概率
-
然後取算出來的是每個類別的概率的最大值,即測試集就是該類別
-
5.過濾垃圾郵件
Mac電腦的朋友在導入郵件數據的時候如果出現編碼錯誤,可以使用如下命令修改文件的編碼格式
enconv -L zh_CN -x UTF-8 filename
#2.垃圾郵件分類
def textParse(bigString):#將字元串轉換為字元列表
import re
#機器學習與實戰課本上的這種正則表達式的寫法切分會將每一個單詞的每一個字母都單獨切分開,可以自己調試看看
#listOfTokens = re.split(r'\W*', bigString)
listOfTokens =re.split(r'\W+', bigString)#將特殊符號作為切分標誌進行字元串切分,即非字母、非數字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了單個字母(因為在判斷一個郵件是否是垃圾郵件的時候,僅憑一個字母還不能判斷出來)例如大寫的I,其它單詞變成小寫
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26): #遍歷25個txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) #讀取每個垃圾郵件,並字元串轉換成字元串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1)#標記垃圾郵件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())#讀取每個非垃圾郵件,並字元串轉換成字元串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0)#標記非垃圾郵件,1表示垃圾文件
vocabList = createVocabList(docList) #創建辭彙表,不重覆
trainingSet = list(range(50)); testSet = []#創建存儲訓練集的索引值的列表和測試集的索引值的列表
for i in range(10): #從50個郵件中,隨機挑選出40個作為訓練集,10個做測試集
randIndex = int(random.uniform(0, len(trainingSet))) #隨機選取索索引值
testSet.append(trainingSet[randIndex])#添加測試集的索引值
del(trainingSet[randIndex]) #在訓練集列表中刪除添加到測試集的索引值
trainMat = []; trainClasses = [] #創建訓練集矩陣和訓練集類別標簽系向量
for docIndex in trainingSet: #遍歷訓練集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #將生成的詞集模型添加到訓練矩陣中
trainClasses.append(classList[docIndex]) #將類別添加到訓練集類別標簽系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) #訓練朴素貝葉斯模型
errorCount = 0 #錯誤分類計數
for docIndex in testSet: #遍歷測試集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) #測試集的詞集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: #如果分類錯誤
errorCount += 1 #錯誤計數加1
print("分類錯誤的測試集:",docList[docIndex])
print('錯誤率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
測試結果



