
前文回顧 實現一個簡單的Database1(譯文) 實現一個簡單的Database2(譯文) 實現一個簡單的Database3(譯文) 譯註:cstsck在github維護了一個簡單的、類似sqlite的資料庫實現,通過這個簡單的項目,可以很好的理解資料庫是如何運行的。本文是第三篇,主要是實現資料庫 ...
前文回顧
實現一個簡單的Database3(譯文)
譯註:cstsck在github維護了一個簡單的、類似sqlite的資料庫實現,通過這個簡單的項目,可以很好的理解資料庫是如何運行的。本文是第三篇,主要是實現資料庫的實現記憶體中的數據結構並存儲數據
Part 3 在記憶體中,只追加的單表資料庫
我們從一個小型的,有許多限制的資料庫開始。現在資料庫將:
- 支持兩個操作:插入一行並列印所有行
- 數據駐留在記憶體中(沒有持久化到磁碟)
- 支持單個、硬編碼的表
我們的硬編碼表將用來存儲用戶數據,看起來就行下麵展示的這樣:
| column | type |
|---|---|
| id | integer |
| username | varchar(32) |
| varchar(255) |
這是一個簡單的方案,但是它將讓我們的資料庫能夠支持不同的數據類型和不同大小的文本數據類型。插入語句現在看起來像下麵這樣:
insert 1 cstack [email protected]
這意味我們需要升級prepare_statement()函數來解析參數:
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email);
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
return PREPARE_SUCCESS;
}
if (strcmp(input_buffer->buffer, "select") == 0) {
我們把這些解析出的的參數存儲到Statement對象中的一個新的數據結構Row中。
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
typedef struct {
StatementType type;
+ Row row_to_insert; // only used by insert statement
} Statement;
現在我們需要copy這些數據到其他一些代表table的數據結構中。SQLite為了支持快速查找、插入和刪除操作而使用B-tree。我們將從一些簡單的開始。像B-tree,它把行數據分組成頁(pages),但是為了替換把這些頁(pages)組織成一顆樹的這種方法,這裡我們把頁來組織成數組(array)。
這是我的計劃:
- 存儲行數據到叫做頁(pages)的記憶體塊中
- 每頁儘量多的去存儲適合他的大小的數據(在頁的大小範圍內,儘量多的存儲數據)
- 在每頁中行數據將被序列化為緊湊表示(compact representation)
- 頁只有在需要時候才會被分配
- 保持固定大小的指針數組指向頁
首先我們定義一個緊湊表示的行(row):
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
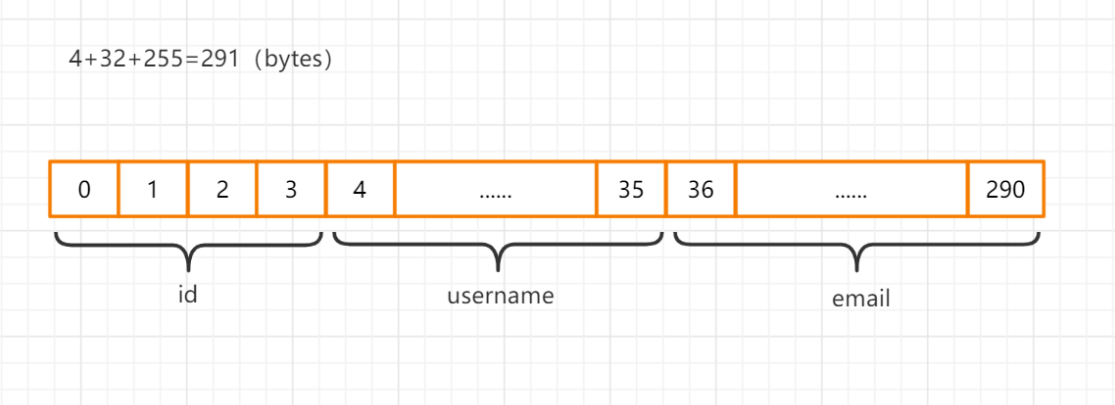
這意味著一個序列化的行的佈局看起來就像下麵這樣:
| column | size (bytes) | offset |
|---|---|---|
| id | 4 | 0 |
| username | 32 | 4 |
| 255 | 36 | |
| total | 291 |
譯註:畫個圖來直觀的看一下這個行數據存儲格式
我們還需要編碼來轉換緊湊表示。(即把數據序列化與反序列化)
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void* source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
接下來,實現一個表的結構指向存儲行的頁並跟蹤頁中有多少行:
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
我把數據頁大小設定為4KB,因為它與大多數電腦架構的虛擬記憶體系統中使用數據頁大小相同。這意味著資料庫中的一個數據頁的大小和系統中的一頁大小正好相同。操作系統在把數據頁移入或者移出記憶體的時候會作為一個完整的單位來操作,而不會拆散他們。
在分配page時我設置了一個很隨意的限制,限制分配100個page。當切換到一個tree結構時,我們資料庫的最大限制就只是受到系統文件的大小限制了(儘管我仍然是限制在記憶體中一次可以有多少page可以保持)。
行不能超出page的邊界。由於page在記憶體中可能不會彼此相鄰,這個假設可以讓讀/寫行數據更簡單。
說到這一點,下麵是我們如何弄清楚在記憶體中去哪裡讀/寫特定行。
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void* page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
現在我們通過execute_statement()函數可以從表結構中讀/寫了。
-void execute_statement(Statement* statement) {
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table* table) {
switch (statement->type) {
case (STATEMENT_INSERT):
- printf("This is where we would do an insert.\n");
- break;
+ return execute_insert(statement, table);
case (STATEMENT_SELECT):
- printf("This is where we would do a select.\n");
- break;
+ return execute_select(statement, table);
}
}
最後,我們需要初始化table,創建各自的記憶體釋放函數並且需要處理一些報錯情況:
+ Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
在主函數中調用table初始化,並處理報錯:
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
@@ -105,13 +203,22 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
- execute_statement(&statement);
- printf("Executed.\n");
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
+ }
}
}
做了這些修改後我們就能實際保存數據到資料庫了。
~ ./db
db > insert 1 cstack [email protected]
Executed.
db > insert 2 bob [email protected]
Executed.
db > select
(1, cstack, [email protected])
(2, bob, [email protected])
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
~
現在是寫一些測試的好時機,有幾個原因:
- 我們計劃大幅度修改存儲表的數據結構,並且測試是可捕獲回歸
- 還有一些邊界條件我們沒有手動測試(例如填滿一張表)
我們將在下一部分中解決這些問題。現在,看一下這一部分完整的區別(與上一部分對比,行開頭“+”為新增,“-”為刪除):
@@ -2,6 +2,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
+#include <stdint.h>
typedef struct {
char* buffer;
@@ -10,6 +11,105 @@ typedef struct {
} InputBuffer;
+typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
+
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum {
+ PREPARE_SUCCESS,
+ PREPARE_SYNTAX_ERROR,
+ PREPARE_UNRECOGNIZED_STATEMENT
+ } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
+typedef struct {
+ StatementType type;
+ Row row_to_insert; //only used by insert statement
+} Statement;
+
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
+
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
+
+void print_row(Row* row) {
+ printf("(%d, %s, %s)\n", row->id, row->username, row->email);
+}
+
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void *source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
+
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +140,105 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ free_table(table);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email
+ );
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table *table) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ return execute_insert(statement, table);
+ case (STATEMENT_SELECT):
+ return execute_select(statement, table);
+ }
+}
+
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer, table)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
+ }
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
}
}
Enjoy GreatSQL

