
序言 作為數據分析師,我們需要經常製作統計分析圖表。但是報表太多的時候往往需要花費我們大部分時間去製作報表。這耽誤了我們利用大量的時間去進行數據分析。但是作為數據分析師我們應該儘可能去挖掘表格圖表數據背後隱藏關聯信息,而不是簡單的統計表格製作圖表再發送報表。既然報表的工作不可免除,那我們應該如何利用 ...
序言
作為數據分析師,我們需要經常製作統計分析圖表。但是報表太多的時候往往需要花費我們大部分時間去製作報表。這耽誤了我們利用大量的時間去進行數據分析。但是作為數據分析師我們應該儘可能去挖掘表格圖表數據背後隱藏關聯信息,而不是簡單的統計表格製作圖表再發送報表。既然報表的工作不可免除,那我們應該如何利用我們所學的技術去更好的處理工作呢?這就需要我們製作一個Python小程式讓它自己去實現,這樣我們就有更多的時間去做數據分析。我們把讓程式自己運行的這個過程稱為自動化。
一、報表自動化目的
1.節省時間,提高效率
自動化總是能夠很好的節省時間,提高我們的工作效率。讓我們的程式編程儘可能的降低每個功能實現代碼的耦合性,更好的維護代碼。這樣我們會節省很多時間讓我們有空去做更多有價值有意義的工作。
2.減少錯誤
編碼實現效果正確無誤的話是是可以一直沿用的,如果是人為來操作的話反而可能會犯一些錯誤。交給固定的程式來做更加讓人放心,需求變更時僅修改部分代碼即可解決問題。
二、報表自動化範圍
首先我們需要根據業務需求來制定我們所需要的報表,並不是每個報表都需要進行自動化的,一些複雜二次開發的指標數據要實現自動化編程的比較複雜的,而且可能會隱藏著各種BUG。所以我們需要對我們工作所要用到的報表的特性進行歸納,以下是我們需要綜合考慮的幾個方面:
1.頻率
對於一些業務上經常需要用到的表,這些表我們可能要納入自動化程式的範圍。例如客戶信息清單、銷售額流量報表、業務流失報表、環比同比報表等。
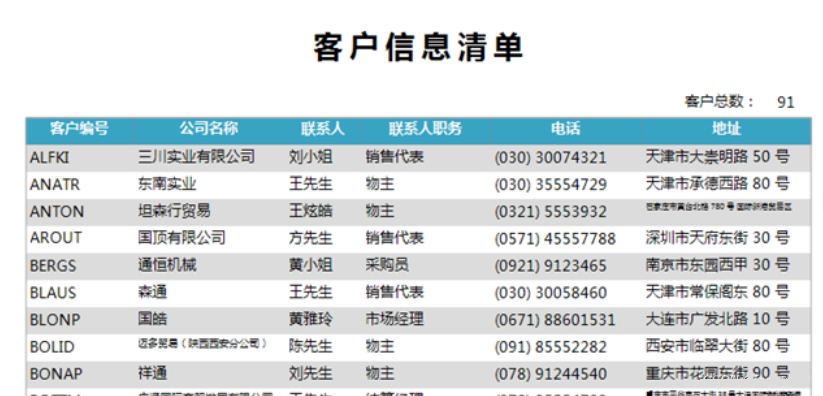
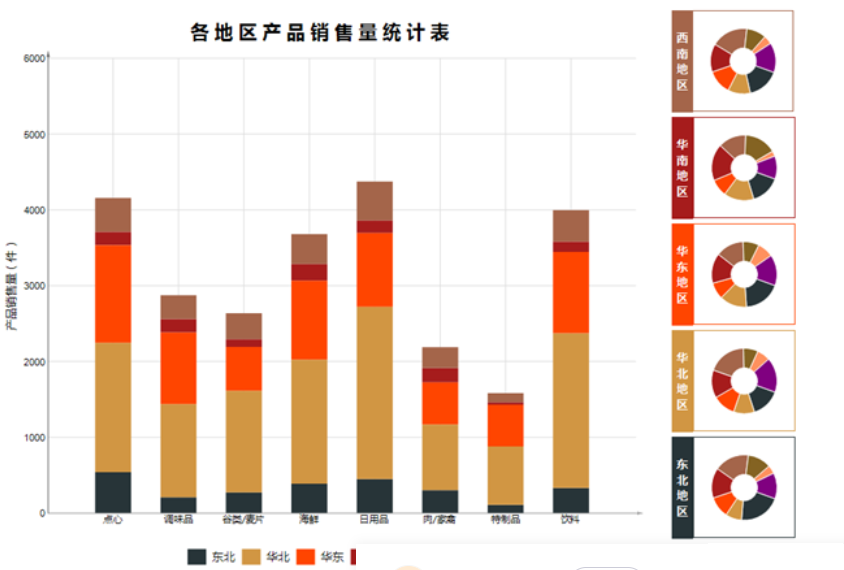
這些使用頻率較高的報表,都很有必要進行自動化。對於那些偶爾需要使用的報表,或者是二次開髮指標,需要複製統計的報表,這些報表就沒必要實現自動化了。
2.開發時間
這就相當於成本和利率一樣,若是有些報表自動化實現困難,還超過了我們普通統計分析所需要的時間,就沒必要去實現自動化。所以開始自動化工作的時候要衡量一下開發腳本所耗費的時間和人工做表所耗費的時間哪個更短了。當然我會提供一套實現方案,但是僅對一些常用簡單的報表。
3.流程
對於我們報表每個過程和步驟,每個公司都有所不同,我們需要根據業務場景去編碼實現各個步驟功能。所以我們製作的流程應該是符合業務邏輯的,製作的程式也應該是符合邏輯的。
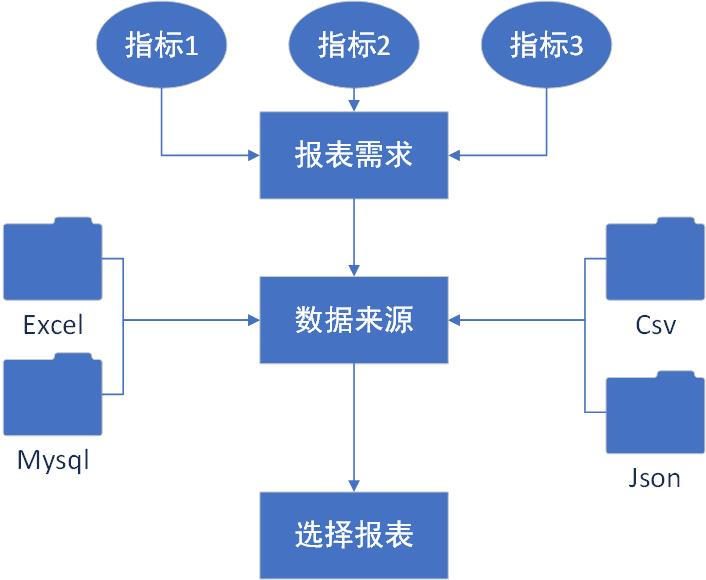
三、實現步驟
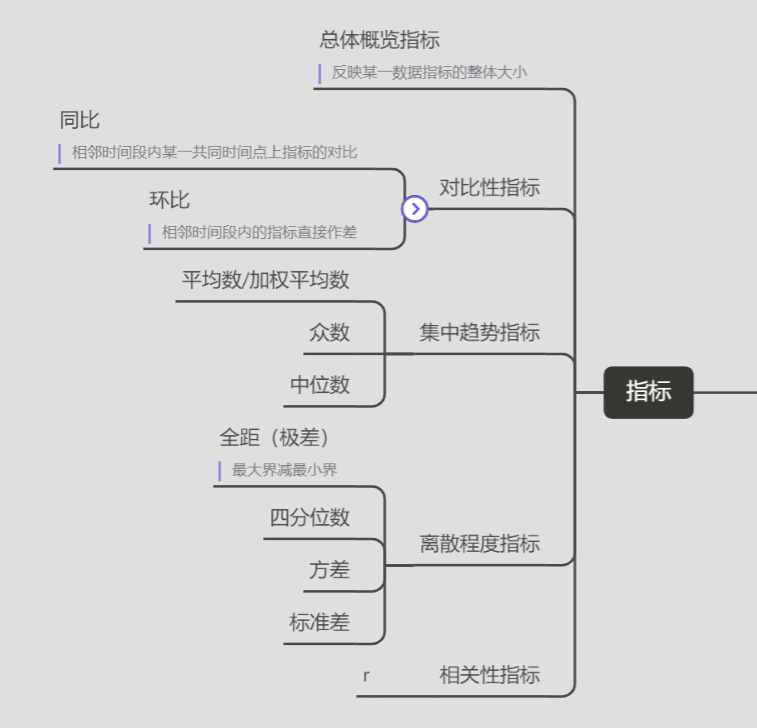
首先我們需要知道我們需要什麼指標,這裡再列出來:
指標
-
總體概覽指標
反映某一數據指標的整體大小 -
對比性指標
1.同比
相鄰時間段內某一共同時間點上指標的對比
2.環比
相鄰時間段內的指標直接作差 -
集中趨勢指標
1.平均數/加權平均數
2.眾數
3.中位數 -
離散程度指標
1.全距(極差)
最大界減最小界
2.四分位數
3.方差
3.標準差 -
相關性指標
r
我們拿一個簡單的報表來進行模擬實現:
第一步:讀取數據源文件
首先我們要瞭解我們的數據是從哪裡來的,也就是數據源。我們最終的數據處理都是轉化為DataFrame來進行分析的,所以需要對數據源進行轉化為DataFrame形式:
import pandas as pd import json import pymysql from sqlalchemy import create_engine # 打開資料庫連接 conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='xxxx', charset = 'utf8' ) engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8') def read_excel(file): df_excel=pd.read_excel(file) return df_excel def read_json(file): with open(file,'r')as json_f: df_json=pd.read_json(json_f) return df_json def read_sql(table): sql_cmd ='SELECT * FROM %s'%table df_sql=pd.read_sql(sql_cmd,engine) return df_sql def read_csv(file): df_csv=pd.read_csv(file) return df_csv # 兄弟們學習python,有時候不知道怎麼學,從哪裡開始學。掌握了基本的一些語法或者做了兩個案例後,不知道下一步怎麼走,不知道如何去學習更加高深的知識。 # 那麼對於這些大兄弟們,我準備了大量的免費視頻教程,PDF電子書籍,以及源代碼! # 還會有大佬解答! # 都在這個群里了 279199867 # 歡迎加入,一起討論 一起學習!
以上代碼均通過測試可以正常使用,但是pandas的read函數針對不同的形式的文件讀取,其read函數參數也有不同的含義,需要直接根據表格的形式來調整。
其他read函數將會在文章寫完之後後續補上,除了read_sql需要連接資料庫之外,其他的都是比較簡單的。
第二步:DataFrame計算
我們以用戶信息為例:
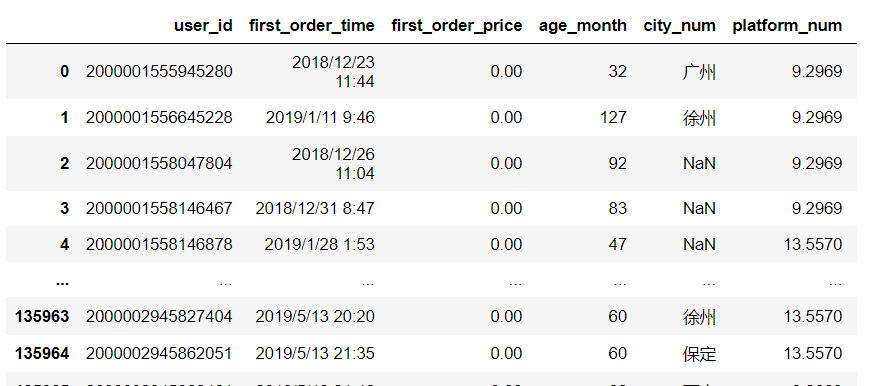
我們需要統計的指標為:
#指標說明
單表圖:
前十個產品受眾最多的地區
產品的受眾地區:
#將城市空值的一行刪除 df=df[df['city_num'].notna()] #刪除error df=df.drop(df[df['city_num']=='error'].index) #統計 df = df.city_num.value_counts()

我們僅獲取前10名的城市就好了,封裝為餅圖:
def pie_chart(df): #將城市空值的一行刪除 df=df[df['city_num'].notna()] #刪除error df=df.drop(df[df['city_num']=='error'].index) #統計 df = df.city_num.value_counts() df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False) pie_chart(read_csv('user_info.csv'))
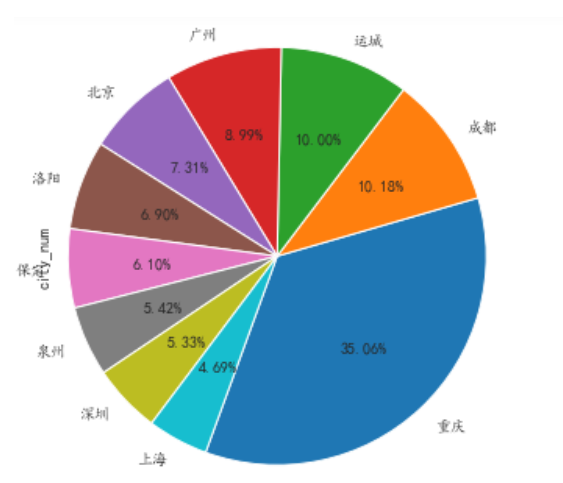
將圖表保存起來:
plt.savefig('fig_cat.png')
要是你覺得matplotlib的圖片不太美觀的話,你也可以換成echarts的圖片,會更加好看一些:
pie = Pie() pie.add("",words) pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地區")) #pie.set_series_opts(label_opts=opts.LabelOpts(user_df)) pie.render_notebook()
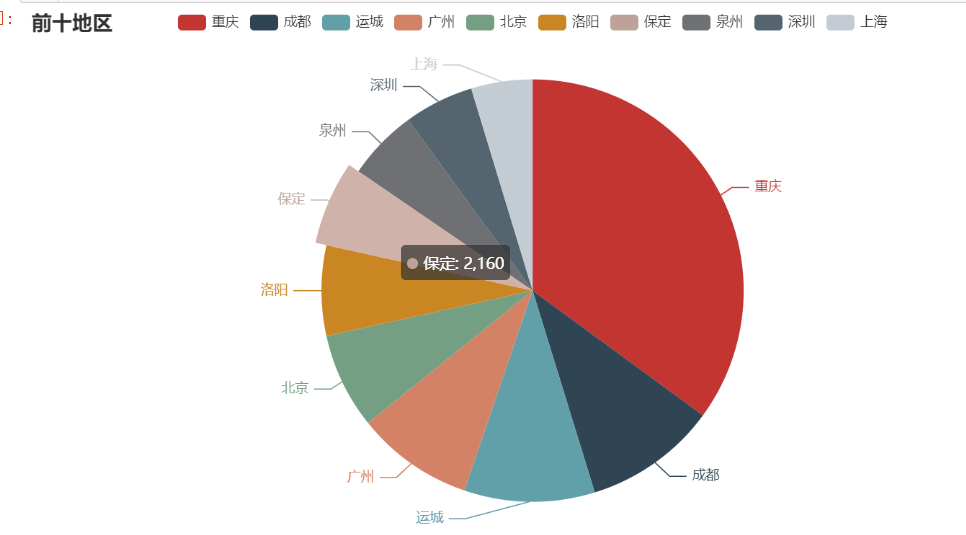
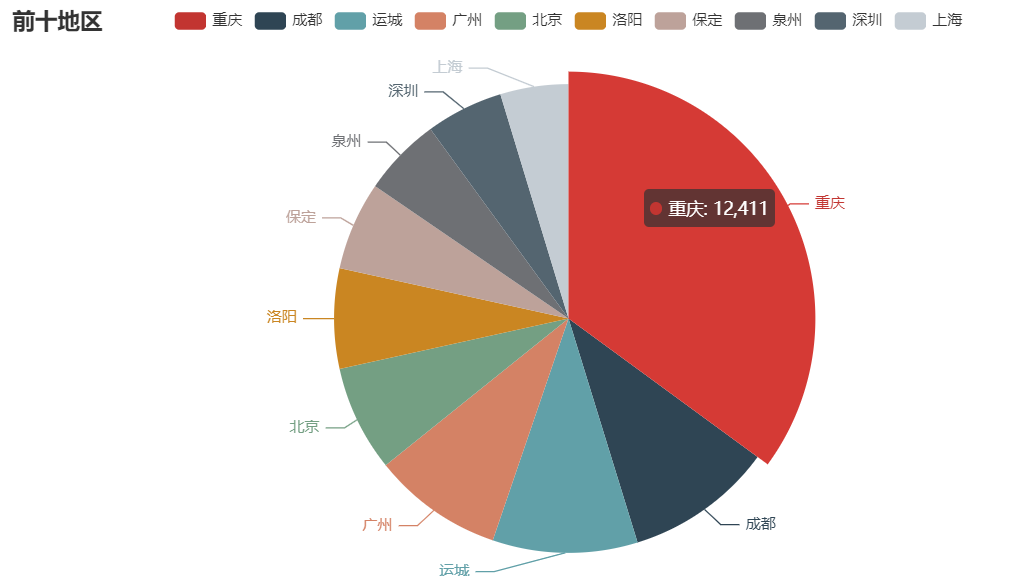
封裝後就可以直接使用了:
def echart_pie(user_df): user_df=user_df[user_df['city_num'].notna()] user_df=user_df.drop(user_df[user_df['city_num']=='error'].index) user_df = user_df.city_num.value_counts() name=user_df.head(10).index.tolist() value=user_df.head(10).values.tolist() words=list(zip(list(name),list(value))) pie = Pie() pie.add("",words) pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地區")) #pie.set_series_opts(label_opts=opts.LabelOpts(user_df)) return pie.render_notebook() user_df=read_csv('user_info.csv') echart_pie(user_df)
可以進行保存,可惜不是動圖:
from snapshot_selenium import snapshot make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")
保存為網頁的形式就可以自動載入JS進行渲染了:
echart_pie(user_df).render('problem.html') os.system('problem.html')
第三步:自動發送郵件
做出來的一系列報表一般都要發給別人看的,對於一些每天需要發送到指定郵箱或者需要發送多封報表的可以使用Python來自動發送郵箱。
在Python發送郵件主要藉助到smtplib和email這個兩個模塊。
smtplib:主要用來建立和斷開與伺服器連接的工作。
email:主要用來設置一些些與郵件本身相關的內容。
不同種類的郵箱伺服器連接地址不一樣,大家根據自己平常使用的郵箱設置相應的伺服器進行連接。這裡博主用網易郵箱展示:
首先需要開啟POP3/SMTP/IMAP服務:
之後便可以根據授權碼使用python登入了。
import smtplib from email import encoders from email.header import Header from email.utils import parseaddr,formataddr from email.mime.application import MIMEApplication from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText #發件人郵箱 asender="[email protected]" #收件人郵箱 areceiver="[email protected]" #抄送人郵箱 acc="[email protected]" #郵箱主題 asubject="謝謝關註" #發件人地址 from_addr="[email protected]" #郵箱授權碼 password="####" #郵件設置 msg=MIMEMultipart() msg['Subject']=asubject msg['to']=areceiver msg['Cc']=acc msg['from']="fanstuck" #郵件正文 body="你好,歡迎關註fanstuck,您的關註就是我繼續創作的動力!" msg.attach(MIMEText(body,'plain','utf-8')) #添加附件 htmlFile = 'C:/Users/10799/problem.html' html = MIMEApplication(open(htmlFile , 'rb').read()) html.add_header('Content-Disposition', 'attachment', filename='html') msg.attach(html) #設置郵箱伺服器地址和介面 smtp_server="smtp.163.com" server = smtplib.SMTP(smtp_server,25) server.set_debuglevel(1) #登錄郵箱 server.login(from_addr,password) #發生郵箱 server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string()) #斷開伺服器連接 server.quit()
運行測試:
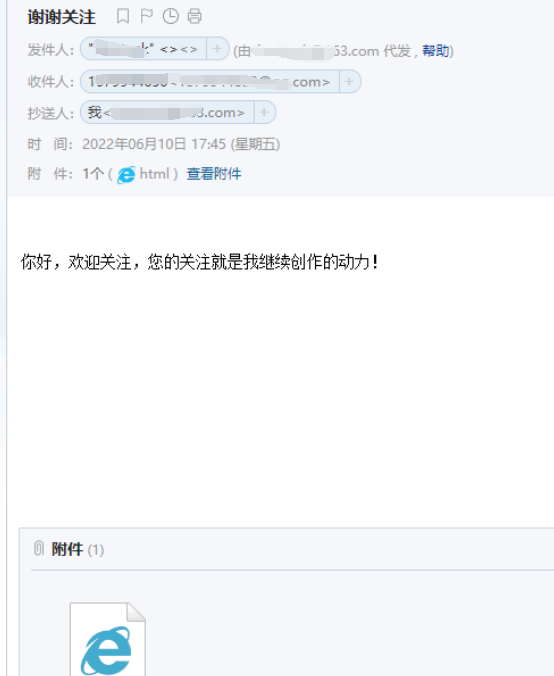
下載文件: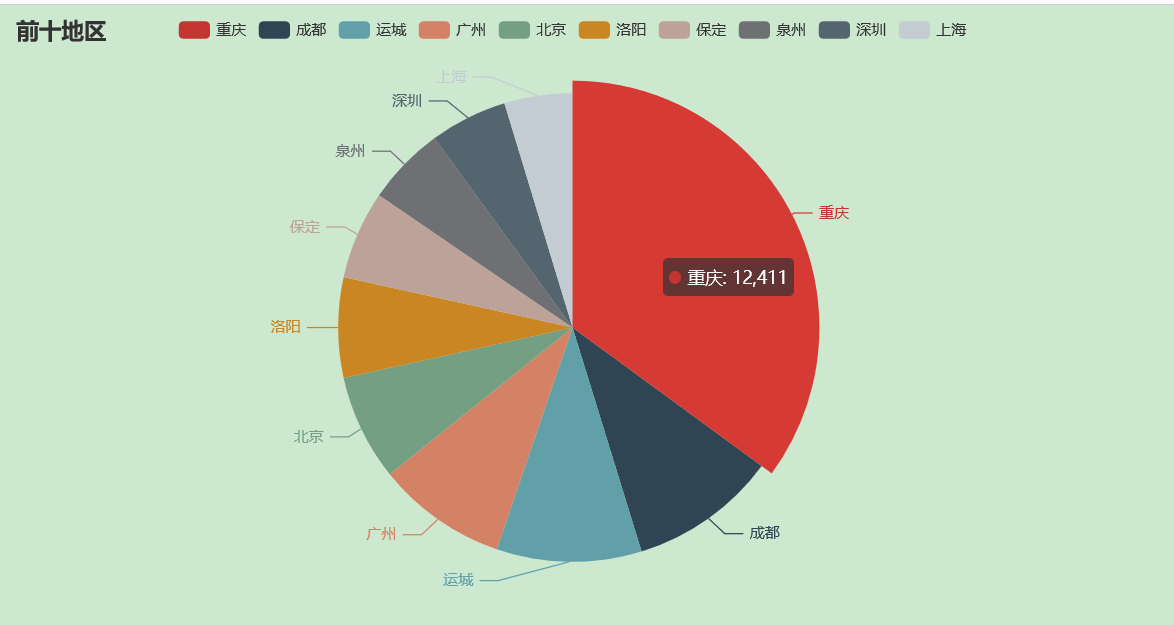
完全沒問題
今天的分享就到這裡,觀眾姥爺們,點關註不迷路~
最後分享一套Python教程:代碼總是學完就忘記?100個實戰項目!讓你沉迷學習丨學以致用丨下一個Python大神就是你!

