
一 、Ribbon概述 Netflixfa 發佈的一個負載均衡器,有助於控制HTTP和TCP客戶端行為。在SpringCloud中,Ribbon提供了客戶端負載均衡的功能,Ribbon自動從服務註冊中心Eureka中讀取到的服務提供者的列表信息(動態獲取服務列表方式),在調用服務節點提供的服務時,基 ...
一 、Ribbon概述
Netflixfa 發佈的一個負載均衡器,有助於控制HTTP和TCP客戶端行為。在SpringCloud中,Ribbon提供了客戶端負載均衡的功能,Ribbon自動從服務註冊中心Eureka中讀取到的服務提供者的列表信息(動態獲取服務列表方式),在調用服務節點提供的服務時,基於內置的負載均衡演算法,合理進行負載。
1、Ribbon的主要作用
(1)服務調用 基於Ribbon實現服務調用, 是通過拉取到的所有服務列表組成(服務名-請求路徑的)映射關係。藉助RestTemplate最終進行調用;
(2)負載均衡 當有多個服務提供者時,Ribbon可以根據負載均衡的演算法自動的選擇需要調用的服務地址。
2、服務調用Ribbon高級
(1)負載均衡概述
在搭建網站時,如果單節點的 web服務性能和可靠性都無法達到要求;或者是在使用外網服務時,經常擔心被人攻破,一不小心就會有打開外網埠的情況,通常這個時候加入負載均衡就能有效解決服務問題。 負載均衡是一種基礎的網路服務,其原理是通過運行在前面的負載均衡服務,按照指定的負載均衡演算法,將流量分配到後端服務集群上,從而為系統提供並行擴展的能力。 負載均衡的應用場景包括流量包、轉發規則以及後端服務,由於該服務有內外網個例、健康檢查等功 能,能夠有效提供系統的安全性和可用性。

(2) 客戶端負載均衡與服務端負載均衡
服務端負載均衡:先發送請求到負載均衡伺服器或者軟體,然後通過負載均衡演算法,在多個伺服器之間選擇一個進行訪 問;即在伺服器端再進行負載均衡演算法分配。
客戶端負載均衡:客戶端會有一個伺服器地址列表,在發送請求前通過負載均衡演算法選擇一個伺服器,然後進行訪問,這是客戶端負載均衡;即在客戶端就進行負載均衡演算法分配。
3、Feign簡介
Feign是Netflix開發的聲明式,模板化的HTTP客戶端,其靈感來自Retrofit、JAXRS-2.0以及WebSocket. Feign可幫助我們更加便捷、優雅的調用HTTP API。 在SpringCloud中,使用Feign非常簡單。 Feign支持多種註解,例如Feign自帶的註解或者JAX-RS註解等。 SpringCloud對Feign進行了增強,使Feign支持了SpringMVC註解,並整合了Ribbon和Eureka, 從而讓Feign的使用更加方便。
3.1 基於Feign的服務調用
(1)引入依賴 在服務消費者 shop_service_order 添加Fegin依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
(2)啟動類添加Feign的支持
@SpringBootApplication(scanBasePackages="cn.itcast.order") @EntityScan("cn.itcast.entity") @EnableFeignClients public class OrderApplication { public static void main(String[] args) { SpringApplication.run(OrderApplication.class, args); } }
通過@EnableFeignClients註解開啟Spring Cloud Feign的支持功能
(3)啟動類激活FeignClient
創建一個Feign介面,此介面是在Feign中調用微服務的核心介面 在服務消費者 shop_service_order 添加一個 ProductFeginClient 介面
//指定需要調用的微服務名稱 @FeignClient(name="shop-service-product") public interface ProductFeginClient { //調用的請求路徑 @RequestMapping(value = "/product/{id}",method = RequestMethod.GET) public Product findById(@PathVariable("id") Long id); }
定義各參數綁定時,@PathVariable、@RequestParam、@RequestHeader等可以指定參數屬性,在Feign中綁定參數必須通過value屬性來指明具體的參數名,不然會拋出異常 @FeignClient:註解通過name指定需要調用的微服務的名稱,用於創建Ribbon的負載均衡器。 所以Ribbon會把shop-service-product解析為註冊中心的服務。
3.2 Feign和Ribbon的聯繫
Ribbon是一個基於HTTP和TCP客戶端的負載均衡的工具。可以在客戶端配置 RibbonServerList(服務端列表),使用 HttpClient 或 RestTemplate 模擬http請求,步驟相當繁瑣。
Feign是在Ribbon的基礎上進行了一次改進,是一個使用起來更加方便的HTTP客戶端。採用介面的方式,只需要創建一個介面,然後在上面添加註解即可,將需要調用的其他服務的方法定義成抽象方法即可,不需要自己構建http請求。然後就像是調用自身工程的方法調用,而感覺不到是調用遠程方法,使得編寫客戶端變得非常容易。
3.3 負載均衡
Feign中本身已經集成了Ribbon依賴和自動配置,因此我們不需要額外引入依賴,也不需要再註冊 RestTemplate 對象。
二、服務熔斷Hystrix入門
1、服務容錯的核心知識
(1)雪崩效應
在微服務架構中,一個請求需要調用多個服務是非常常見的。如客戶端訪問A服務,而A服務需要調用B服務,B服務需要調用C服務,由於網路原因或者自身的原因,如果B服務或者C服務不能及時響應,A服務將處於阻塞狀態,直到B服務C服務響應。此時若有大量的請求涌入,容器的線程資源會被消耗完畢, 導致服務癱瘓。服務與服務之間的依賴性,故障會傳播,造成連鎖反應,會對整個微服務系統造成災難 性的嚴重後果,這就是服務故障的“雪崩”效應。
雪崩是系統中的蝴蝶效應導致其發生的原因多種多樣,有不合理的容量設計,或者是高併發下某一個方 法響應變慢,亦或是某台機器的資源耗盡。從源頭上我們無法完全杜絕雪崩源頭的發生,但是雪崩的根本原因來源於服務之間的強依賴,所以我們可以提前評估,做好熔斷、隔離、限流。
(2) 服務隔離
顧名思義,它是指將系統按照一定的原則劃分為若幹個服務模塊,各個模塊之間相對獨立,無強依賴。 當有故障發生時,能將問題和影響隔離在某個模塊內部,而不擴散風險,不波及其它模塊,不影響整體的系統服務。
(3)熔斷降級
在互聯網系統中,當下游服務因訪問壓力過大而響應變慢或失敗,上游服務為了保護系統整體的可用性,可以暫時切斷對下游服務的調用。這種犧牲局部,保全整體的措施就叫做熔斷。
所謂降級,就是當某個服務熔斷之後,伺服器將不再被調用,此時客戶端可以自己準備一個本地的 fallback回調,返回一個預設值。
(4)服務限流
限流可以認為服務降級的一種,限流就是限制系統的輸入和輸出流量已達到保護系統的目的。一般來說系統的吞吐量是可以被測算的,為了保證系統的穩固運行,一旦達到的需要限制的閾值,就需要限制流 量並採取少量措施以完成限制流量的目的。比如:推遲解決,拒絕解決,或者部分拒絕解決等等。
2、Hystrix介紹
Hystrix是由Netflix開源的一個延遲和容錯庫,用於隔離訪問遠程系統、服務或者第三方庫,防止級聯失敗,從而提升系統的可用性與容錯性。Hystrix主要通過以下幾點實現延遲和容錯。
包裹請求:使用HystrixCommand包裹對依賴的調用邏輯,每個命令在獨立線程中執行。這使用了設計模式中的“命令模式”。
跳閘機制:當某服務的錯誤率超過一定的閾值時,Hystrix可以自動或手動跳閘,停止請求該服務一段時間。
資源隔離:Hystrix為每個依賴都維護了一個小型的線程池(或者信號量)。如果該線程池已滿, 發往該依賴的請求就被立即拒絕,而不是排隊等待,從而加速失敗判定。
監控:Hystrix可以近乎實時地監控運行指標和配置的變化,例如成功、失敗、超時、以及被拒絕 的請求等。
回退機制:當請求失敗、超時、被拒絕,或當斷路器打開時,執行回退邏輯。回退邏輯由開發人員自行提供,例如返回一個預設值。
自我修複:斷路器打開一段時間後,會自動進入“半開”狀態。
3、 Rest實現服務熔斷
(2)配置依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
(3)開啟熔斷
在啟動類 OrderApplication 中添加 @EnableCircuitBreaker 註解開啟對熔斷器的支持。
@EntityScan("cn.itcast.entity")
//@EnableCircuitBreaker //開啟熔斷器
//@SpringBootApplication
@SpringCloudApplication public class OrderApplication { //創建RestTemplate對象 @Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(OrderApplication.class, args); } }
可以看到,我們類上的註解越來越多,在微服務中,經常會引入上面的三個註解,於是Spring就提供了 一個組合註解:@SpringCloudApplication
4)配置熔斷降級業務邏輯
@RestController @RequestMapping("/order") public class OrderController { @Autowired private RestTemplate restTemplate; //下訂單 @GetMapping("/product/{id}") @HystrixCommand(fallbackMethod = "orderFallBack") public Product findProduct(@PathVariable Long id) { return restTemplate.getForObject("http://shop-serviceproduct/product/1", Product.class); } //降級方法 public Product orderFallBack(Long id) { Product product = new Product(); product.setId(-1l); product.setProductName("熔斷:觸發降級方法"); return product; } }
為 findProduct方法編寫一個回退方法findProductFallBack,該方法與 findProduct 方法具有相同的參數與返回值類型,該方法返回一個預設的錯誤信息。 在 Product 方法上,使用註解@HystrixCommand的fallbackMethod屬性,指定熔斷觸發的降級方法是findProductFallBack 。因為熔斷的降級邏輯方法必須跟正常邏輯方法保證相同的參數列表和返回值聲明。在findProduct 方法上HystrixCommand(fallbackMethod = "findProductFallBack") 用來聲明一個降級邏輯的方法。
4、斷路器聚合監控Turbine
在微服務架構體系中,每個服務都需要配置Hystrix DashBoard監控。如果每次只能查看單個實例的監控數據,就需要不斷切換監控地址,這顯然很不方便。要想看這個系統的Hystrix Dashboard數據就需要用到Hystrix Turbine。Turbine是一個聚合Hystrix 監控數據的工具,它可以將所有相關微服務的 Hystrix 監控數據聚合到一起,方便使用。引入Turbine後,整個監控系統架構如下:
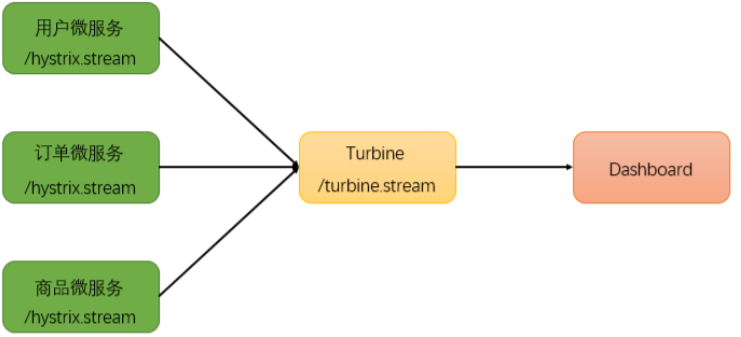
(1) 搭建TurbineServer 創建工程 shop_hystrix_turbine 引入相關坐標
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-turbine</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency>
(2) 配置多個微服務的hystrix監控 在application.yml的配置文件中開啟turbine併進行相關配置
server:
port: 8031
spring:
application:
name: microservice-hystrix-turbine
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
instance:
prefer-ip-address: true
turbine:
# 要監控的微服務列表,多個用,分隔
appConfig: shop-service-order
clusterNameExpression: "'default'"
eureka相關配置 : 指定註冊中心地址
turbine相關配置:指定需要監控的微服務列表
turbine會自動的從註冊中心中獲取需要監控的微服務,並聚合所有微服務中的 /hystrix.stream 數據
(3)配置啟動類
@SpringBootApplication @EnableTurbine @EnableHystrixDashboard public class TurbineServerApplication { public static void main(String[] args) { SpringApplication.run(TurbineServerApplication.class, args); } }
作為一個獨立的監控項目,需要配置啟動類,開啟HystrixDashboard監控平臺,並激活Turbine
5、熔斷器的狀態
熔斷器有三個狀態 CLOSED 、 OPEN 、 HALF_OPEN 熔斷器預設關閉狀態,當觸發熔斷後狀態變更為 OPEN ,在等待到指定的時間,Hystrix會放請求檢測服務是否開啟,這期間熔斷器會變為 HALF_OPEN 半 開啟狀態,熔斷探測服務可用則繼續變更為 CLOSED 關閉熔斷器。
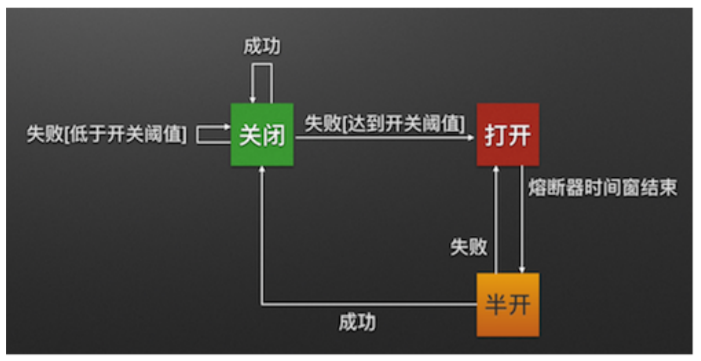
Closed:關閉狀態(斷路器關閉),所有請求都正常訪問。代理類維護了最近調用失敗的次數, 如果某次調用失敗,則使失敗次數加1。如果最近失敗次數超過了在給定時間內允許失敗的閾值, 則代理類切換到斷開(Open)狀態。此時代理開啟了一個超時時鐘,當該時鐘超過了該時間,則切換到半斷開(Half-Open)狀態。該超時時間的設定是給了系統一次機會來修正導致調用失敗的錯誤。
Open:打開狀態(斷路器打開),所有請求都會被降級。Hystix會對請求情況計數,當一定時間 內失敗請求百分比達到閾值,則觸發熔斷,斷路器會完全關閉。預設失敗比例的閾值是50%,請求 次數最少不低於20次。
Half Open:半開狀態,open狀態不是永久的,打開後會進入休眠時間(預設是5S)。隨後斷路 器會自動進入半開狀態。此時會釋放1次請求通過,若這個請求是健康的,則會關閉斷路器,否則 繼續保持打開,再次進行5秒休眠計時。
熔斷器的預設觸發閾值是20次請求,不好觸發。休眠時間時5秒,時間太短,不易觀察,為了測試方便,我們可以通過配置修改熔斷策略:
circuitBreaker.requestVolumeThreshold=5
circuitBreaker.sleepWindowInMilliseconds=10000
circuitBreaker.errorThresholdPercentage=50
requestVolumeThreshold:觸發熔斷的最小請求次數,預設20
errorThresholdPercentage:觸發熔斷的失敗請求最小占比,預設50%
sleepWindowInMilliseconds:熔斷多少秒後去嘗試請求
6、熔斷器的隔離策略
微服務使用Hystrix熔斷器實現了服務的自動降級,讓微服務具備自我保護的能力,提升了系統的穩定性,也較好的解決雪崩效應。其使用方式目前支持兩種策略:
(1)線程池隔離策略:使用一個線程池來存儲當前的請求,線程池對請求作處理,設置任務返回處理超時時間,堆積的請求堆積入線程池隊列。這種方式需要為每個依賴的服務申請線程池,有一定的資源消耗,好處是可以應對突發流量(流量洪峰來臨時,處理不完可將數據存儲到線程池隊里慢慢處理)。
(2)信號量隔離策略:使用一個原子計數器(或信號量)來記錄當前有多少個線程在運行,請求來先判斷計數器的數值,若超過設置的最大線程個數則丟棄該類型的新請求,若不超過則執行計數操作請求來計數器+1,請求返回計數器-1。這種方式是嚴格的控制線程且立即返回模式,無法應對突發流量(流量洪峰來臨時,處理的線程超過數量,其他的請求會直接返回,不繼續去請求依賴的服務)。
線程池和型號量兩種策略功能支持對比如下:

hystrix.command.default.execution.isolation.strategy : 配置隔離策略
ExecutionIsolationStrategy.SEMAPHORE 信號量隔離
ExecutionIsolationStrategy.THREAD 線程池隔離
hystrix.command.default.execution.isolation.maxConcurrentRequests : 最大信號量上限
7、Hystrix的核心源碼
Hystrix 底層基於 RxJava,RxJava 是響應式編程開發庫,因此Hystrix的整個實現策略簡單說即:把一個HystrixCommand封裝成一個Observable(待觀察者),針對自身要實現的核心功能,對Observable進行各種裝飾,併在訂閱各步裝飾的Observable,以便在指定事件到達時,添加自己的業務。
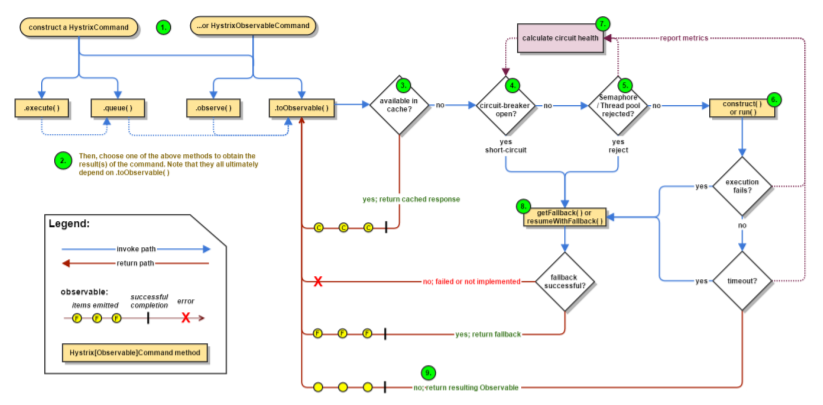
Hystrix主要有4種調用方式:
toObservable() 方法 :未做訂閱,只是返回一個Observable ;
observe() 方法 :調用 #toObservable() 方法,並向 Observable 註冊 rx.subjects.ReplaySubject 發起訂閱;
queue() 方法 :調用 #toObservable() 方法的基礎上,調用:Observable#toBlocking() 和 BlockingObservable#toFuture() 返回 Future 對象;
execute() 方法 :調用 #queue() 方法的基礎上,調用 Future#get() 方法,同步返回 #run() 的執行結果。
主要的執行邏輯:
1). 每次調用創建一個新的HystrixCommand,把依賴調用封裝在run()方法中.
2). 執行execute()/queue做同步或非同步調用.
3). 判斷熔斷器(circuit-breaker)是否打開,如果打開跳到步驟8,進行降級策略,如果關閉進入步驟4
4). 判斷線程池/隊列/信號量是否跑滿,如果跑滿進入降級步驟8,否則繼續後續步驟5
5). 調用HystrixCommand的run方法.運行依賴邏輯,依賴邏輯調用超時,執行步驟6
6). 判斷邏輯是否調用成功。返回成功調用結果;調用出錯,執行步驟7
7). 計算熔斷器狀態,所有的運行狀態(成功, 失敗, 拒絕,超時)上報給熔斷器,用於統計從而判斷熔斷器狀態.
8). getFallback()降級邏輯。
以下四種情況將觸發getFallback調用:
1). run()方法拋出非HystrixBadRequestException異常。
2). run()方法調用超時
3). 熔斷器開啟攔截調用
4). 線程池/隊列/信號量是否跑滿
5). 沒有實現getFallback的Command將直接拋出異常,fallback降級邏輯調用成功直接返回,降 級邏輯調用失敗拋出異常.
9). 返回執行成功結果
8、請求合併
Hystrix支持將多個請求自動合併為一個請求,通過合併可以減少HystrixCommand併發執行所需的線程和網路連接數量,極大地節省了開銷,提高了系統效率。請求合併是由Hystrix自動合併進行的,並不需要在開發時進行代碼介入(註意,這裡只是說合併請求不需要代碼介入,但對於批量請求的處理,還是需要寫一些代碼的)。需要註意的是,多個請求能自動合併的前提是請求之間要足夠“近”,即執行的間隔時長要足夠小(預設為10ms,可通過hystrix.collapser.default.timerDelayInMilliseconds進行設置),即執行間隔超過10ms的請求不會合併執行。
如果沒有啟用請求合併,那麼在HystrixCommand執行的線程池和後端業務執行中都會存在大量的併發,很可能會造成性能瓶頸。另外,如果要讓Hystrix能夠使用到請求合併,那麼業務代碼必須提供能夠批量處理的介面。
9、服務熔斷Hystrix的替換方案
18年底Netflix官方宣佈Hystrix 已經足夠穩定,不再積極開發 Hystrix,該項目將處於維護模式。就目前來看Hystrix是比較穩定的,並且Hystrix只是停止開發新的版本,並不是完全停止維護,Bug什麼的依然會維護的。因此短期內,Hystrix依然是繼續使用的。但從長遠來看,Hystrix總會達到它的生命周期。
(1)替換方案介紹
Alibaba Sentinel
Sentinel 是阿裡巴巴開源的一款斷路器實現,目前在Spring Cloud的孵化器項目Spring Cloud Alibaba 中的一員Sentinel本身在阿裡內部已經被大規模採用,非常穩定。因此可以作為一個較好的替代品。
Resilience4J
Resilicence4J 一款非常輕量、簡單,並且文檔非常清晰、豐富的熔斷工具,這也是Hystrix官方推薦的替代產品。不僅如此,Resilicence4j還原生支持Spring Boot 1.x/2.x,而且監控也不像Hystrix一樣弄 Dashboard/Hystrix等一堆輪子,而是支持和Micrometer(Pivotal開源的監控門面,Spring Boot 2.x 中的Actuator就是基於Micrometer的)、prometheus(開源監控系統,來自谷歌的論文)、以及 Dropwizard metrics(Spring Boot曾經的模仿對象,類似於Spring Boot)進行整合。
(1.1) Sentinel概述
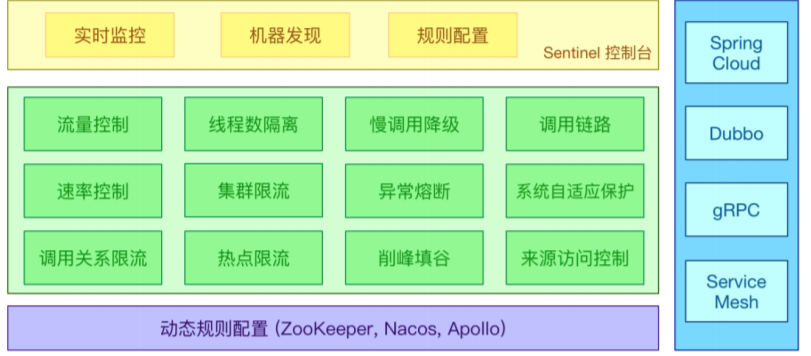
Sentinel 以流量為切入點,從流量控制、熔斷降級、系統負載保護等多個維度保護服務的穩定性。
Sentinel 具有以下特征:
豐富的應用場景:Sentinel 承接了阿裡巴巴近 10 年的雙十一大促流量的核心場景,例如秒殺(即 突發流量控制在系統容量可以承受的範圍)、消息削峰填谷、集群流量控制、實時熔斷下游不可用 應用等。
完備的實時監控:Sentinel 同時提供實時的監控功能。可以在控制臺中看到接入應用的單台機器秒級數據,甚至 500 台以下規模的集群的彙總運行情況。
廣泛的開源生態:Sentinel 提供開箱即用的與其它開源框架/庫的整合模塊,例如與 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相應的依賴併進行簡單的配置即可快速地接入 Sentinel。 完善的SPI擴展點:Sentinel 提供簡單易用、完善的 SPI 擴展介面。可以通過實現擴展介面來快速地定製邏輯。例如定製規則管理、適配動態數據源等。
Sentinel 的主要特性:
(1.2) Sentinel與Hystrix的區別
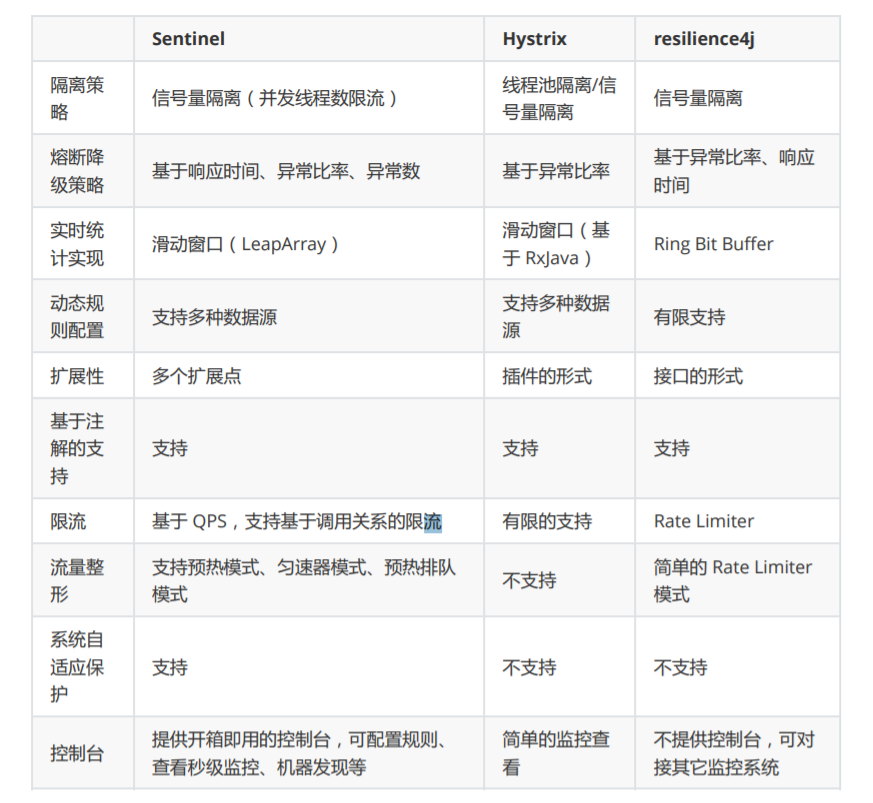
(1.3) 遷移方案
Sentinel官方提供了詳細的由Hystrix 遷移到Sentinel 的方法

感謝閱讀,借鑒了不少大佬資料,如需轉載,請註明出處,謝謝!https://www.cnblogs.com/huyangshu-fs/p/13882618.html


