
一、前言 Caffeine是一個高性能的 Java 緩存庫,底層數據存儲採用ConcurrentHashMap 優點:因為Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了紅黑樹,在hash衝突嚴重時也能有良好的讀性能。多線程環境中,不同的key可以併發寫,相同的ke ...
一、前言
Caffeine是一個高性能的 Java 緩存庫,底層數據存儲採用ConcurrentHashMap
-
優點:因為Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了紅黑樹,在hash衝突嚴重時也能有良好的讀性能。多線程環境中,不同的key可以併發寫,相同的key會加鎖,天然的解決了緩存擊穿問題和緩存雪崩問題。
-
缺點:因為底層數據結構是ConcurrentHashMap,所有不能作為分散式緩存,同時如果使用不當,會帶來數據不一致的問題
本文主要內容是探討Caffeine使用不當時,數據一致性安全問題
二、問題發生場景
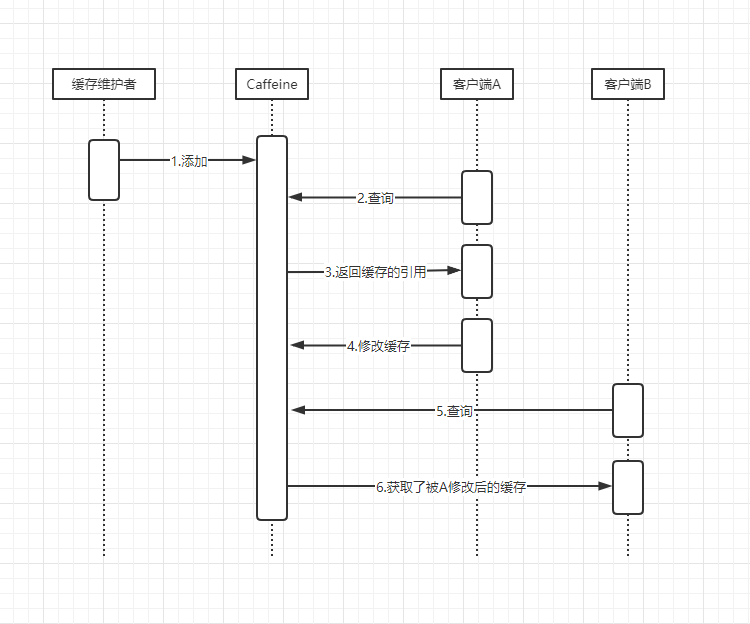
如下圖所示,問題的根源在於A能直接拿到緩存地址的引用,然後通過引用就能隨意修改引用指向的緩存對象,要解決這個問題,可以在步驟三這裡,將緩存對象深拷貝後的副本的引用返回給客戶端,這樣客戶端對緩存的任何操作,改變的只是副本,緩存本身只能由維護者來更新
三、如何進行對象的深拷貝
實現方式:
- 緩存實體類本身封裝成不可變類對象,類和屬性全部用final修飾,不提供能改變屬性的方法,屬性的值只能在對象創建過程中設置
- 緩存獲取API返回緩存實體後,重新創建一個新對象,對於基本類型的屬性可以用set方法簡單設置,註意對象類型的屬性每一層都要重新創建,特繁瑣,然後set,稍不小心就會出現淺拷貝問題,所有這裡要不建議用BeanUtils等工具類
- 使用Jackson將緩存對象先系列化為Json字元串,然後將Json字元串反序列化為對象,這裡一定能得到一個安全的深拷貝對象
因為我們的項目中已經在大量使用Caffeine,方案1和2需要對大量的實體類和緩存獲取介面進行大量的改造,工作量巨大,後面採用方案3
四、怎麼獲取泛型T的Type
後面需要使用Jackson對泛型V進行反序列化,需要用到泛型V的Type屬性,如果是普通對象用class,比如User.class,這裡只有泛型無法知道class,之所以採用泛型,是因為緩存是面向任意數據類型的,定義泛型是為了更強的通用性,下麵是獲取泛型T的Typede代碼,參考了Jackson的TypeReference類的源碼
//拷貝了的緩存對象,原來緩存操作類的裝飾者
public abstract class CopiedCache<K, V> implements Cache<K, V>, LoadingCache<K, V> {
/**
* 被裝飾的緩存實例
*/
private final Cache<K, V> cache;
/**
* 泛型V的類型,反序列化時會用到
*/
protected final Type vType;
public CopiedCache(Cache<K, V> cache) {
this.cache = cache;
//獲取泛型V的類型,參考Jackson的TypeReference類的源碼
Type superClass = getClass().getGenericSuperclass();
if (superClass instanceof Class<?>) { // sanity check, should never happen
throw new IllegalArgumentException("Internal error: TypeReference constructed without actual type information");
}
//獲取泛型參數列表,下標0表示K,1表示V,後面的反序列化只用到了V的Type
vType = ((ParameterizedType) superClass).getActualTypeArguments()[1];
/**
* json字元串反序列化對象:
* ObjectMapper om = new ObjectMapper(new JsonFactory());
*
* 普通對象
* OM.readValue(json, XXX.class);
*
* 泛型對象
* OM.readValue(json, OM.getTypeFactory().constructType(vType));
*/
}
/**
*其餘部分省略,這裡主要說明如何獲取泛型的class
*
* 1.這個類最初設計時不是抽象類,創建對象的代碼:
* LoadingCache<Long, UserDetails> userCache = new CopiedCache<>(cache);
* 如果這麼做,構造方法中使用類似TypeReference的方法,無法獲取泛型V的class
*
* 2.經測試分析,在泛型類中,只能通過子類來獲取泛型類型,為了強制使用此類,CopiedCache設計成了泛型,初始化時可以用
* 匿名內部類來代替子類,創建該類對象的代碼:
* LoadingCache<Long, UserDetails> userCache = new CopiedCache<Long, UserDetails>(cache) {};
*
*/
}
五、裝飾模式
使用裝飾模式是為了對Caffeine中緩存查詢方法做增強處理(主要是對緩存對象進行深拷貝),對目標類的某些方法進行增強的實現方式:
- 直接在目標類的方法上修改,這裡Caffeine是三方庫,根本沒法改,硬要改的話,只能是改它的源代碼重新生成jar包,這個包會成為野包,個人感覺此法不妥,這麼做了面向對象的開閉原則(對擴展開放,對修改關閉)
- Spring AOP,這樣額外引入了Spring框架,而且Caffeine中涉及查詢方法太多,可能需要定義特別多的切點,比較麻煩
- 裝飾模式,Cache和LoadingCache是Caffeine中的緩存操作介面,充當被裝飾者的角色,CopiedCache充當裝飾者,CopiedCache持有被裝飾者的引用,對象創建時需傳入被裝飾者引用,同時實現了被裝飾者的介面。通過繼承重寫需要增強的方法,對於不需要增強的方法,直接委托給被裝飾者調用,最後可以依據里氏替換原則,只需將緩存操作介面的引用指向CopiedCache,原來緩存查詢相關的代碼不用作任何改變,極大降低耦合度
裝飾模式類圖:

六、代碼實現
改造前,緩存初始化及緩存查詢的實現代碼
//緩存初始化
LoadingCache<Long, UserDetails> userCache = Caffeine.newBuilder()
.maximumSize(1024L)
.expireAfterWrite(Duration.ofMinutes(15))
.build(delegate::getUserDetails);
//這裡userDetails就是緩存,客戶端拿到後執行userDetails.setXXX,將會破壞緩存一致性
UserDetails userDetails = userCache.get(userId);
改造後,緩存初始化及緩存查詢的實現代碼
//緩存初始化
LoadingCache<Long, UserDetails> cache = Caffeine.newBuilder()
.maximumSize(1024L)
.expireAfterWrite(Duration.ofMinutes(15))
.build(delegate::getUserDetails);
//對原生的緩存類進行裝飾,註意後面的小括弧,CopiedCache是抽象類,這裡創建了匿名子類,可以將泛型類型傳給父類
LoadingCache<Long, UserDetails> userCache = new CopiedCache<Long, UserDetails>(cache) {};
//這裡userDetails是緩存的拷貝,類似的調用邏輯不需要做任何的修改,自動實現了增強效果
UserDetails userDetails = userCache.get(userId);
裝飾類的代碼
@ThreadSafe
public abstract class CopiedCache<K, V> implements Cache<K, V>, LoadingCache<K, V> {
/**
* 被裝飾的緩存實例
*/
private final Cache<K, V> cache;
/**
* 泛型V的類型,反序列化時會用到
*/
protected final Type vType;
public CopiedCache(Cache<K, V> cache) {
this.cache = cache;
//獲取泛型V的類型
Type superClass = getClass().getGenericSuperclass();
if (superClass instanceof Class<?>) { // sanity check, should never happen
throw new IllegalArgumentException("Internal error: TypeReference constructed without actual type information");
}
vType = ((ParameterizedType) superClass).getActualTypeArguments()[1];
}
@Nullable
@Override
public V get(@Nonnull K key) {
//委托裝飾類去調用
V v = (V) ((LoadingCache) cache).get(key);
//下麵的copy方法就是增強的邏輯
return copy(v);
}
@Nonnull
@Override
public Map<K, V> getAll(@Nonnull Iterable<? extends K> keys) {
//委托給裝飾類去調用
Map<K, V> map = ((LoadingCache) cache).getAll(keys);
return copyMap(map);
}
@Override
public void put(@Nonnull K key, @Nonnull V value) {
//不需要增強,直接委托給被裝飾類來調用
cache.put(key, value);
}
/**
* 普通對象的深拷貝,實現方式:序列化+反序列化
* @param v
* @return V
*/
private V copy(V v) {
return JSON.parse(JSON.stringify(v), vType);
}
//這裡省略了其他方法...
/**
* Map對象的深拷貝,實現方式:序列化+反序列化
* @param map
* @return java.util.Map<K,V>
*/
private Map<K,V> copyMap(Map<K,V> map) {
Map copiedMap = new LinkedHashMap();
Maps.each(map, (k, v) -> copiedMap.put(k, copy(v)));
return copiedMap;
}
}

