
更多技術交流、求職機會,歡迎關註位元組跳動數據平臺微信公眾號,回覆【1】進入官方交流群 相信大家都對大名鼎鼎的ClickHouse有一定的瞭解了,它強大的數據分析性能讓人印象深刻。但在位元組大量生產使用中,發現了ClickHouse依然存在了一定的限制。本篇將詳細介紹我們是如何為ClickHouse增強 ...
更多技術交流、求職機會,歡迎關註位元組跳動數據平臺微信公眾號,回覆【1】進入官方交流群
相信大家都對大名鼎鼎的ClickHouse有一定的瞭解了,它強大的數據分析性能讓人印象深刻。但在位元組大量生產使用中,發現了ClickHouse依然存在了一定的限制。本篇將詳細介紹我們是如何為ClickHouse增強高可用能力的。
位元組遇到的ClickHouse可用性問題
隨著位元組業務的快速發展,產品快速擴張,承載業務的ClickHouse集群節點數也快速增加。另一方面,按照天進行的數據分區也快速增加,一個集群管理的庫表特別多,開始出現元數據不一致的情況。兩方面結合,導致集群的可用性極速下降,以至於到了業務難以接受的程度。直觀的問題有三類:
1、故障變多
典型的例子如硬體故障,幾乎每天都會出現。另外,當集群達到一定的規模,Zookeeper會成為瓶頸,增加故障發生頻率。
2、故障恢復時間長
因為數據分區變多,導致一旦發生故障,恢復時間經常會需要1個小時以上,這是業務方完全不能接受的。
3、運維複雜度提升
以往只需要一個人負責運維的集群,由於節點增加和分區變多,運維複雜度和難度成倍的增加,目前運維人數增加了幾人也依然拙荊見肘,依然難保證集群的穩定運行。
可用性問題已經成為制約業務發展的重要問題,因此我們決定將影響高可用的問題一一拆解,並逐個解決。
提升高可用能力的方案
一、降低Zookeeper壓力
問題所在:
原生ClickHouse 使用 ReplicatedMergeTree 引擎來實現數據同步。原理上,ReplicatedMergeTree 基於 ZooKeeper 完成多副本的選主、數據同步、故障恢復等功能。由於 ReplicatedMergeTree 對 ZooKeeper 的使用比較重,除了每組副本一些表級別的元信息,還存儲了邏輯日誌、part 信息等潛在數量級較大的信息。Zookeeper並不是一個能做到良好線性擴展的系統,當ZooKeeper 在相對較高的負載情況下運行時,往往性能表現並不佳,甚至會出現副本無法寫入,數據也無法同步的情況。在位元組內部實際使用和運維 ClickHouse 的過程中,ZooKeeper 也是非常容易成為一個瓶頸的組件。
改造思路:
ReplicatedMergeTree 支持 insert_quorum,insert_quorum 是指如果副本數為3,insert_quorum=2,要成功寫入至少兩個副本才會返回寫入成功。
新分區在副本之間複製的流程如下:
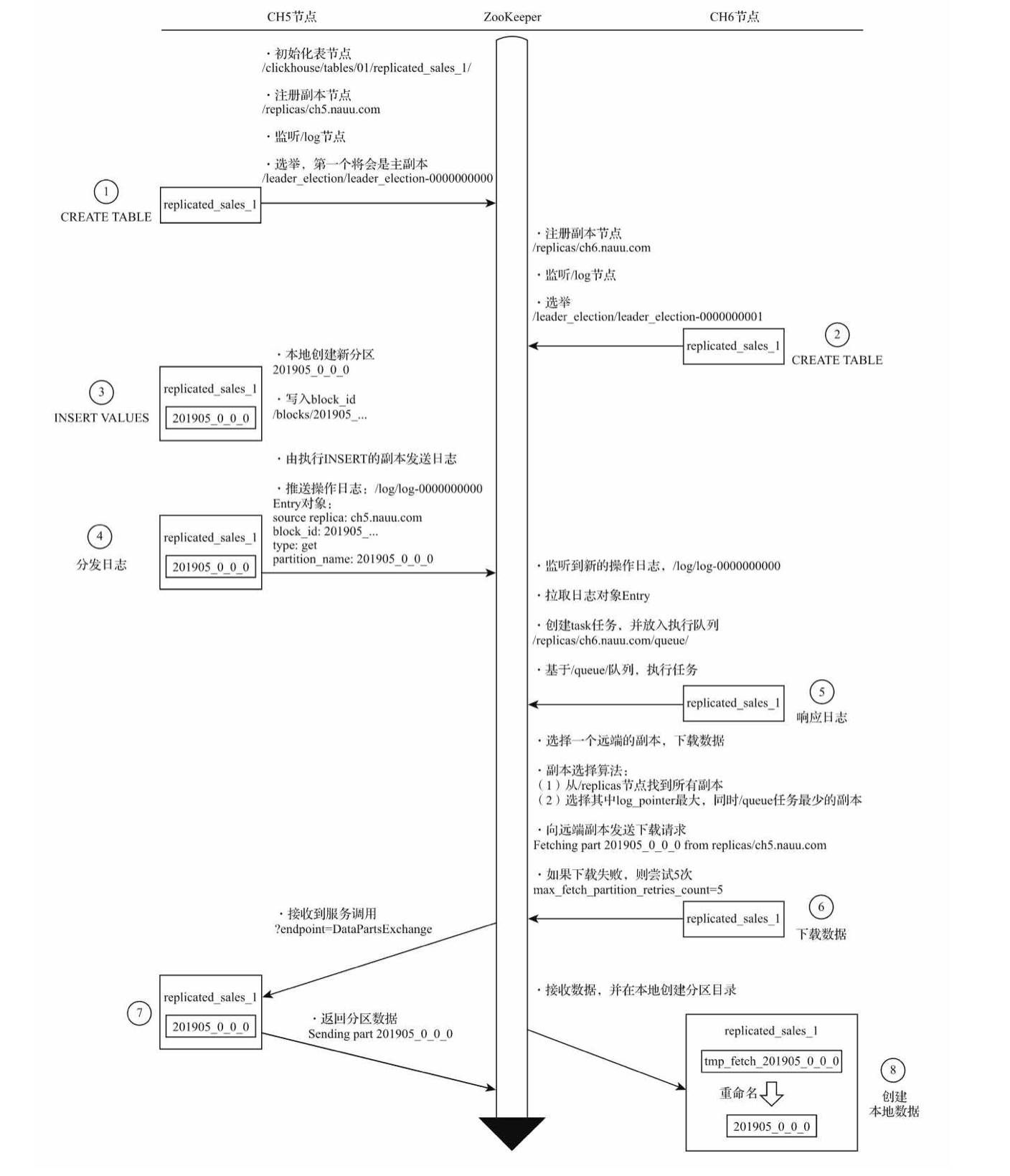
可以看到,反覆在 zookeeper 中進行分發日誌、數據交換等步驟,這正是引起瓶頸的原因之一。
為了降低對 ZooKeeper 的負載,在ByteHouse中重新實現了一套 HaMergeTree 引擎。通過HaMergeTree降低對 ZooKeeper 的請求次數,減少在 ZooKeeper 上存儲的數據量,新的 HaMergeTree 同步引擎:
1)保留ZooKeeper上表級別的元信息;
2)簡化邏輯日誌的分配;
3)將 part 信息從 ZooKeeper 日誌移除。
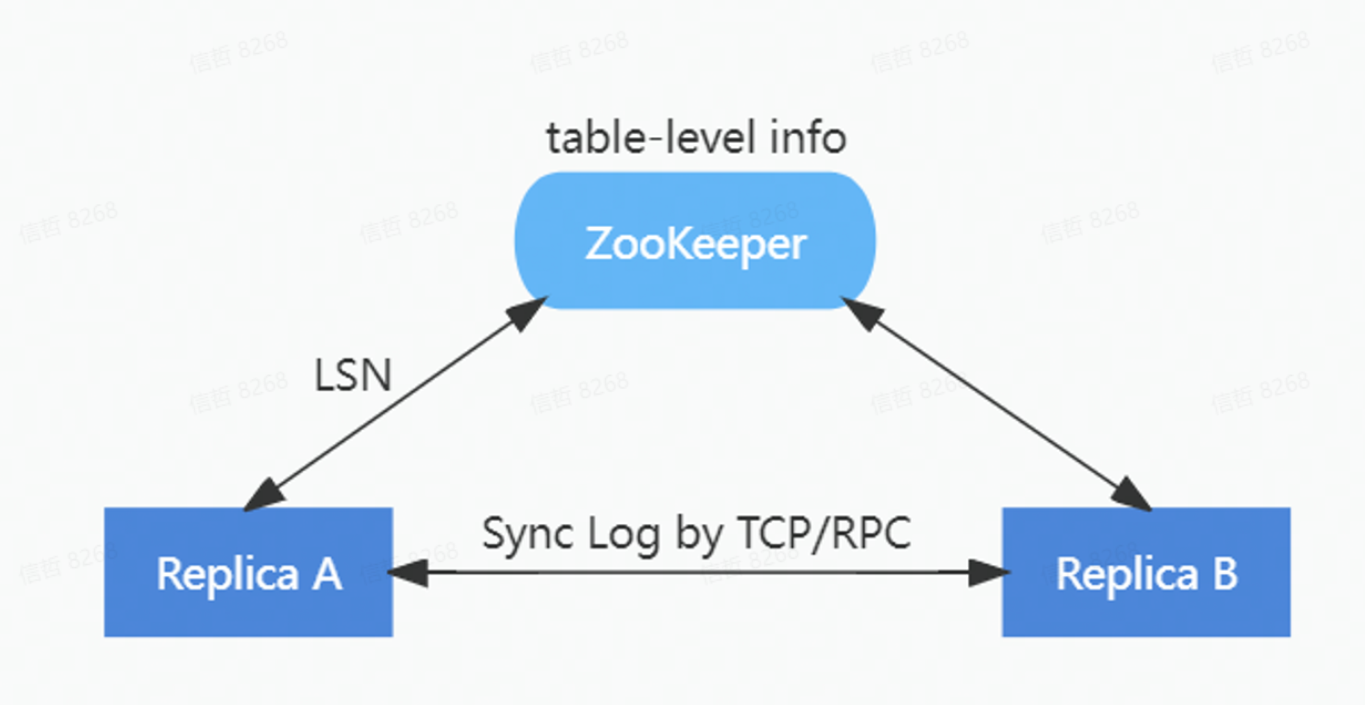
HaMergeTree 減少了操作日誌等信息在zookeeper裡面的存放,來減少zookeeper的負載,zookeeper裡面只是存放log LSN, 具體日誌在副本之間通過gossip協議同步回放。
在保持和ReplicatedMergeTree完全相容的前提下,新的 HaMergeTree 極大減輕了對 ZooKeeper 的負載,實現了 ZooKeeper 集群的壓力與數據量不相關。上線後,因Zookeeper導致的異常大量減少。無論是單集群幾百甚至上千節點,還是單節點上萬張表,都能保障良好的穩定性。
二、提升故障恢復能力
問題所在:
雖然所有數據從業者都在做各種努力,想要保證線上生產環境不出故障,但是現實中還是難以避免會遇到各式各樣的問題。主要是由下麵這幾種因素引起的:
軟體缺陷:軟體設計本身的Bug引起的系統非正常終止,或依賴的組件相容引發的問題。
硬體故障:常見的有磁碟損壞、內容故障、CPU故障等,當集群規模擴大後發生的頻率也線性增加。
記憶體溢出導致進程被停止:在OLAP資料庫中經常發生。
意外因素:如斷電、誤操作等引發的問題。
由於原生ClickHouse希望達到極致性能的初衷,所以在ClickHouse系統中元數據常駐於記憶體中,這導致了ClickHouse server重啟時間非常長。因而當故障發生後,恢復的時間也很長,動輒一到兩個小時,相當於業務也要中斷一到兩個小時。當故障頻繁出現,造成的業務損失是無法估量的。
改造思路:
為瞭解決上述問題,在ByteHouse中採用了元數據持久化的方案,將元數據持久化到RocksDB, Server啟動時直接從RocksDB載入元數據,記憶體中也僅僅存放必要的Part信息。因此可以減少元數據對記憶體的占用,以及加速集群的啟動以及故障恢復時間。
如下圖所示,元數據持久化整體上採用了RocksDB+Meta in Memory的方式,每個Table都會對應一個RocksDB資料庫存放該表所有Part的元信息。Table首次啟動時,從文件系統中載入的Part元數據將被持久化到RocksDB中;之後重啟時就可以直接從RocksDB中載入Part。每個表從RocksDB或者文件系統載入的Part將只在記憶體中存放必要的Part信息。在實際使用Part時,將通過記憶體中存放的Part元信息去RocksDB中讀取並載入對應Part。
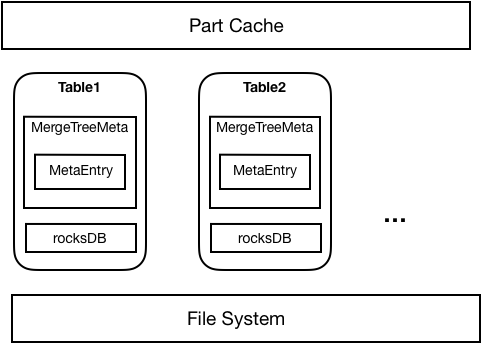
完成元數據持久化後,在性能基本無損失的情況下,單機支持的part不再受記憶體容量的限制,可以達到100萬以上。最重要的是,故障恢復的時間顯著縮短,只需要此前的幾十分之一的時間就可以完成。例如在原生ClickHouse中需要一到兩個小時的恢復時間,在ByteHouse中只需要3分鐘,大大提高的系統的高可用能力,為業務提供了堅實保障。
三、其他方面
除了以上兩點,在ByteHouse中在其他很多方面都為高可用能力做了增強,如通過HaKafka引擎提升了數據寫入的高可用性,提升實時數據寫入的容錯率,可自動切換主備寫入;增加了監控運維平臺,實現對關鍵指標的監控、告警;增加多種問題診斷工具,能實現故障的快速定位。
對於數據分析平臺來說,穩定性是重中之重。我們對ByteHouse的高可用能力的提升是不會停止的,在極致性能的背後,力圖為用戶提供最強有力的穩定性保障。
立即跳轉火山引擎ByteHouse官網瞭解詳情


