
點亮 ⭐️ Star · 照亮開源之路 https://github.com/apache/dolphinscheduler 本文目錄 1 DolphinScheduler的設計與策略 1.1 分散式設計 1.1.1 中心化 1.1.2 去中心化 1.2 DophinScheduler架構設計 ...
點亮 ⭐️ Star · 照亮開源之路
https://github.com/apache/dolphinscheduler

本文目錄
-
1 DolphinScheduler的設計與策略
-
1.1 分散式設計
-
1.1.1 中心化
-
1.1.2 去中心化
-
1.2 DophinScheduler架構設計
-
1.3 容錯問題
-
1.3.1 宕機容錯
-
1.3.2 失敗重試
-
1.4 遠程日誌訪問
-
2 DolphinScheduler源碼分析
-
2.1 工程模塊介紹與配置文件
-
2.1.1 工程模塊介紹
-
2.1.2 配置文件
-
2.2 Api主要任務操作介面
-
2.3 Quaterz架構與運行流程
-
2.3.1 概念與架構
-
2.3.2 初始化與執行流程
-
2.3.3 集群運轉
-
2.4 Master啟動與執行流程
-
2.4.1 概念與執行邏輯
-
2.4.2 集群與槽(slot)
-
2.4.3 代碼執行流程
-
2.5 Work啟動與執行流程
-
2.5.1 概念與執行邏輯
-
2.5.2 代碼執行流程
-
2.6 rpc交互
-
2.6.1 Master與Worker交互
-
2.6.2 其他服務與Master交互
-
2.7 負載均衡演算法
-
2.7.1 加權隨機
-
2.7.2 線性負載
-
2.7.3 平滑輪詢
-
2.8 日誌服務
-
2.9 報警
-
3 後記
-
3.1 Make friends
-
3.2 參考文獻
前言
研究Apache Dolphinscheduler也是機緣巧合,平時負責基於xxl-job二次開發出來的調度平臺,因為遇到了併發性能瓶頸,到了不得不優化重構的地步,所以搜索市面上應用較廣的調度平臺以借鑒優化思路。
在閱讀完DolphinScheduler代碼之後,便生出了將其設計與思考記錄下來的念頭,這便是此篇文章的來源。因為沒有正式生產使用,業務理解不一定透徹,理解可能有偏差,歡迎大家交流討論。
1 DolphinScheduler的設計與策略
大家能關註DolphinScheduler那麼一定對調度系統有了一定的瞭解,對於調度所涉及的到一些專有名詞在這裡就不做過多的介紹,重點介紹一下流程定義,流程實例,任務定義,任務實例。(沒有作業這個概念確實也很新奇,可能是不想和Quartz的JobDetail重疊)。
-
任務定義:各種類型的任務,是流程定義的關鍵組成,如sql,shell,spark,mr,python等;
-
任務實例:任務的實例化,標識著具體的任務執行狀態;
-
流程定義:一組任務節點通過依賴關係建立的起來的有向無環圖(DAG);
-
流程實例:通過手動或者定時調度生成的流程實例;
-
定時調度:系統採用Quartz 分散式調度器,並同時支持cron表達式可視化的生成;
1.1 分散式設計
分散式系統的架構設計基本分為中心化和去中心化兩種,各有優劣,憑藉各自的業務選擇。
1.1.1 中心化
中心化設計比較簡單,集群中的節點安裝角色可以分為Master和Slave兩種,如下圖:
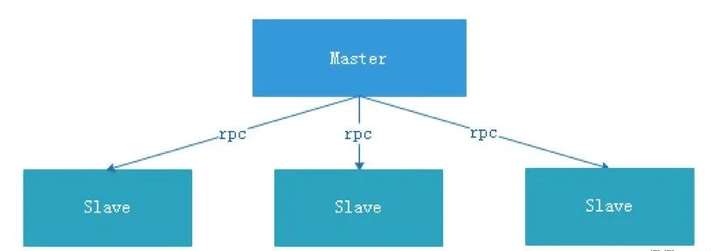
Master: Master的角色主要負責任務分發並監督Slave的健康狀態,可以動態的將任務均衡到Slave上,以致Slave節點不至於“忙死”或”閑死”的狀態。
中心化設計存在一些問題。
第一點,一旦Master出現了問題,則群龍無首,整個集群就會崩潰。
為瞭解決這個問題,大多數Master/Slave架構模式都採用了主備Master的設計方案,可以是熱備或者冷備,也可以是自動切換或手動切換,而且越來越多的新系統都開始具備自動選舉切換Master的能力,以提升系統的可用性。
第二點,如果Scheduler在Master上,雖然可以支持一個DAG中不同的任務運行在不同的機器上,但是會產生Master的過負載。如果Scheduler在Slave上,一個DAG中所有的任務都只能在某一臺機器上進行作業提交,在並行任務比較多的時候,Slave的壓力可能會比較大。
xxl-job就是採用這種設計方式,但是存在相應的問題。管理器(admin)宕機集群會崩潰,Scheduler在管理器上,管理器負責所有任務的校驗和分發,管理器存在過載的風險,需要開發者想方案解決。
1.1.2 去中心化
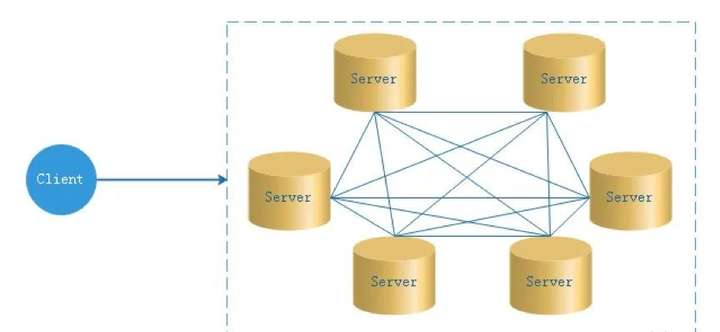
在去中心化設計里,通常沒有Master/Slave的概念,所有的角色都是一樣的,地位是平等的,去中心化設計的核心設計在於整個分散式系統中不存在一個區別於其他節點的“管理者”,因此不存在單點故障問題。
但由於不存在“管理者”節點所以每個節點都需要跟其他節點通信才得到必須要的機器信息,而分散式系統通信的不可靠性,則大大增加了上述功能的實現難度。實際上,真正去中心化的分散式系統並不多見。
反而動態中心化分散式系統正在不斷涌出。在這種架構下,集群中的管理者是被動態選擇出來的,而不是預置的,並且集群在發生故障的時候,集群的節點會自發的舉行會議來選舉新的管理者去主持工作。
一般都是基於Raft演算法實現的選舉策略。Raft演算法,目前社區也有相應的PR,還沒合併。
-
PR鏈接:https://github.com/apache/dolphinscheduler/issues/10874
-
動態展示見鏈接:http://thesecretlivesofdata.com/
DolphinScheduler的去中心化是Master/Worker註冊到註冊中心,實現Master集群和Worker集群無中心。
1.2 DophinScheduler架構設計
隨手盜用一張官網的系統架構圖,可以看到調度系統採用去中心化設計,由UI,API,MasterServer,Zookeeper,WorkServer,Alert等幾部分組成。
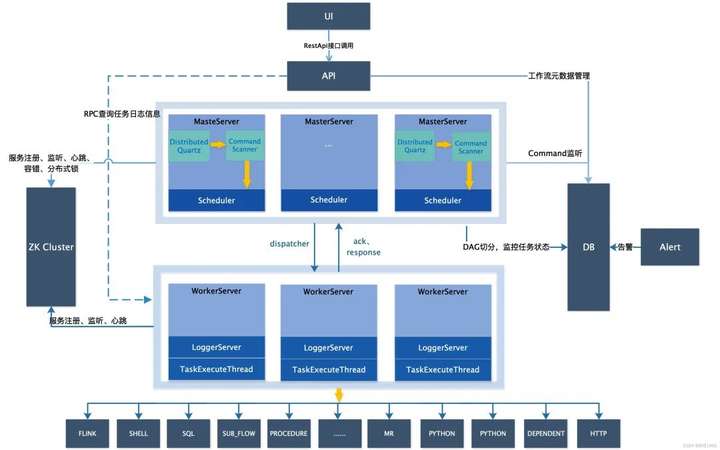
API: API介面層,主要負責處理前端UI層的請求。該服務統一提供RESTful api向外部提供請求服務。介面包括工作流的創建、定義、查詢、修改、發佈、下線、手工啟動、停止、暫停、恢復、從該節點開始執行等等。
MasterServer: MasterServer採用分散式無中心設計理念,MasterServer集成了Quartz,主要負責 DAG 任務切分、任務提交監控,並同時監聽其它MasterServer和WorkerServer的健康狀態。MasterServer服務啟動時向Zookeeper註冊臨時節點,通過監聽Zookeeper臨時節點變化來進行容錯處理。WorkServer:WorkerServer也採用分散式無中心設計理念,WorkerServer主要負責任務的執行和提供日誌服務。WorkerServer服務啟動時向Zookeeper註冊臨時節點,並維持心跳。
ZooKeeper: ZooKeeper服務,系統中的MasterServer和WorkerServer節點都通過ZooKeeper來進行集群管理和容錯。另外系統還基於ZooKeeper進行事件監聽和分散式鎖。
**Alert:**提供告警相關介面,介面主要包括兩種類型的告警數據的存儲、查詢和通知功能,支持豐富的告警插件自由拓展配置。
1.3 容錯問題
容錯分為服務宕機容錯和任務重試,服務宕機容錯又分為Master容錯和Worker容錯兩種情況;
1.3.1 宕機容錯
服務容錯設計依賴於ZooKeeper的Watcher機制,實現原理如圖:
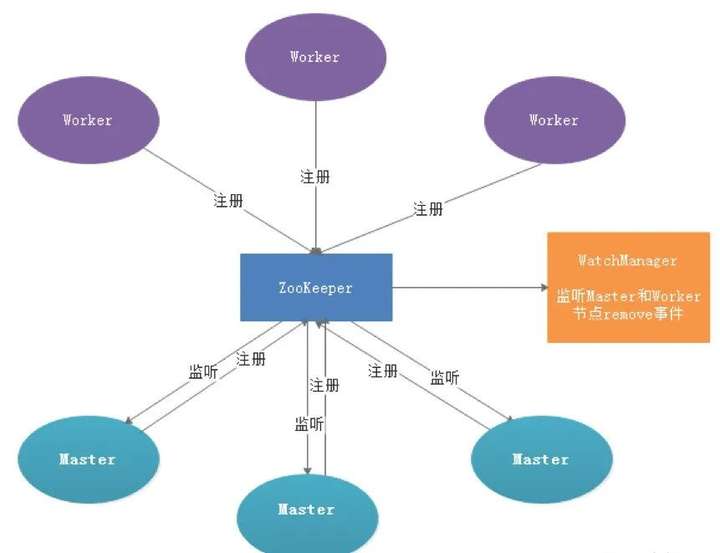
其中Master監控其他Master和Worker的目錄,如果監聽到remove事件,則會根據具體的業務邏輯進行流程實例容錯或者任務實例容錯,容錯流程圖相對官方文檔裡面的流程圖,人性化了些,大家可以參考一下,具體如下所示。
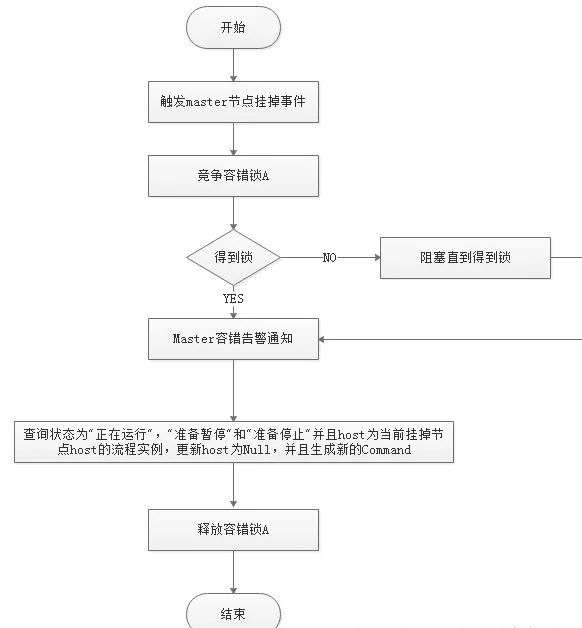
ZooKeeper Master容錯完成之後則重新由DolphinScheduler中Scheduler線程調度,遍歷 DAG 找到“正在運行”和“提交成功”的任務,對“正在運行”的任務監控其任務實例的狀態,對“提交成功”的任務需要判斷Task Queue中是否已經存在,如果存在則同樣監控任務實例的狀態,如果不存在則重新提交任務實例。
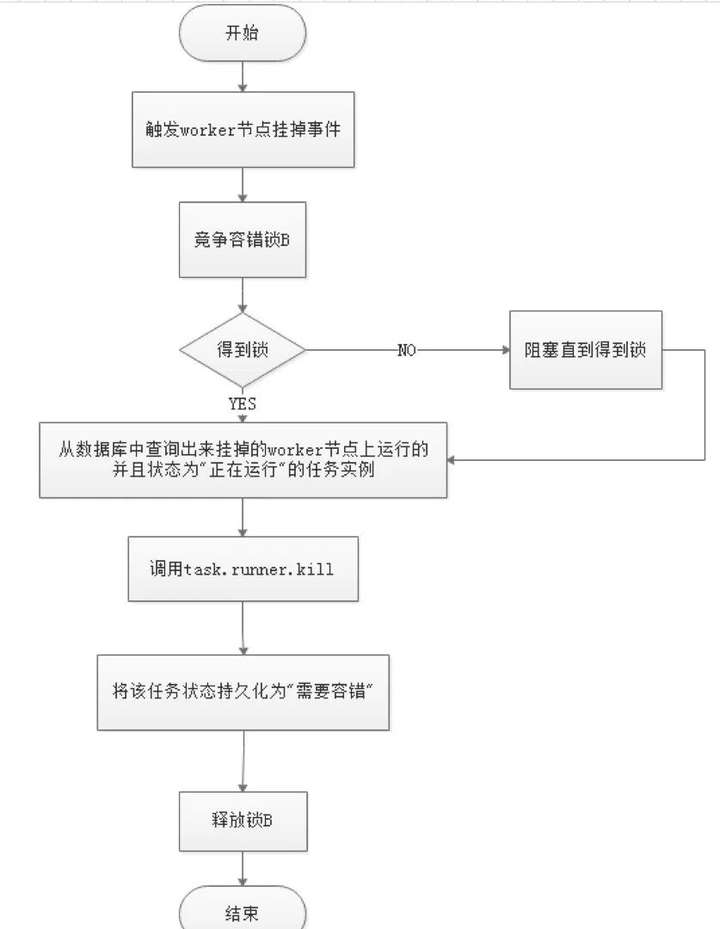
Master Scheduler線程一旦發現任務實例為” 需要容錯”狀態,則接管任務併進行重新提交。註意由於” 網路抖動”可能會使得節點短時間內失去和ZooKeeper的心跳,從而發生節點的remove事件。
對於這種情況,我們使用最簡單的方式,那就是節點一旦和ZooKeeper發生超時連接,則直接將Master或Worker服務停掉。
1.3.2 失敗重試
這裡首先要區分任務失敗重試、流程失敗恢復、流程失敗重跑的概念:
-
任務失敗重試是任務級別的,是調度系統自動進行的,比如一個Shell任務設置重試次數為3次,那麼在Shell任務運行失敗後會自己再最多嘗試運行3次。
-
流程失敗恢復是流程級別的,是手動進行的,恢復是從只能從失敗的節點開始執行或從當前節點開始執行。流程失敗重跑也是流程級別的,是手動進行的,重跑是從開始節點進行。
接下來說正題,我們將工作流中的任務節點分了兩種類型。
-
一種是業務節點,這種節點都對應一個實際的腳本或者處理語句,比如Shell節點、MR節點、Spark節點、依賴節點等。
-
還有一種是邏輯節點,這種節點不做實際的腳本或語句處理,只是整個流程流轉的邏輯處理,比如子流程節等。
每一個業務節點都可以配置失敗重試的次數,當該任務節點失敗,會自動重試,直到成功或者超過配置的重試次數。邏輯節點不支持失敗重試。但是邏輯節點里的任務支持重試。
如果工作流中有任務失敗達到最大重試次數,工作流就會失敗停止,失敗的工作流可以手動進行重跑操作或者流程恢復操作。
1.4 遠程日誌訪問
由於Web(UI)和Worker不一定在同一臺機器上,所以查看日誌不能像查詢本地文件那樣。
有兩種方案:
-
將日誌放到ES搜索引擎上;
-
通過netty通信獲取遠程日誌信息;
介於考慮到儘可能的DolphinScheduler的輕量級性,所以選擇了RPC實現遠程訪問日誌信息,具體代碼的實踐見2.8章節。
2 DolphinScheduler源碼分析
上一章的講解可能初步看起來還不是很清晰,本章的主要目的是從代碼層面一一介紹第一張講解的功能。關於系統的安裝在這裡並不會涉及,安裝運行請大家自行探索。
2.1 工程模塊介紹與配置文件
2.1.1 工程模塊介紹
-
dolphinscheduler-alert 告警模塊,提供告警服務;
-
dolphinscheduler-api web應用模塊,提供 Rest Api 服務,供 UI 進行調用;
-
dolphinscheduler-common 通用的常量枚舉、工具類、數據結構或者基類 dolphinscheduler-dao 提供資料庫訪問等操作;
-
dolphinscheduler-remote 基於netty的客戶端、服務端 ;
-
dolphinscheduler-server 日誌與心跳服務 ;
-
dolphinscheduler-log-server LoggerServer 用於Rest Api通過RPC查看日誌;
-
dolphinscheduler-master MasterServer服務,主要負責 DAG 的切分和任務狀態的監控 ;
-
dolphinscheduler-worker WorkerServer服務,主要負責任務的提交、執行和任務狀態的更新;
-
dolphinscheduler-service service模塊,包含Quartz、Zookeeper、日誌客戶端訪問服務,便於server模塊和api模塊調用 ;
-
dolphinscheduler-ui 前端模塊;
2.1.2 配置文件
dolphinscheduler-common common.properties
#本地工作目錄,用於存放臨時文件
data.basedir.path=/tmp/dolphinscheduler
#資源文件存儲類型: HDFS,S3,NONE
resource.storage.type=NONE
#資源文件存儲路徑
resource.upload.path=/dolphinscheduler
#hadoop是否開啟kerberos許可權
hadoop.security.authentication.startup.state=false
#kerberos配置目錄
java.security.krb5.conf.path=/opt/krb5.conf
#kerberos登錄用戶
[email protected]
#kerberos登錄用戶keytab
login.user.keytab.path=/opt/hdfs.headless.keytab
#kerberos過期時間,整數,單位為小時
kerberos.expire.time=2
# 如果存儲類型為HDFS,需要配置擁有對應操作許可權的用戶
hdfs.root.user=hdfs
#請求地址如果resource.storage.type=S3,該值類似為: s3a://dolphinscheduler. 如果resource.storage.type=HDFS, 如果 hadoop 配置了 HA,需要複製core-site.xml 和 hdfs-site.xml 文件到conf目錄
fs.defaultFS=hdfs://mycluster:8020
aws.access.key.id=minioadmin
aws.secret.access.key=minioadmin
aws.region=us-east-1
aws.endpoint=http://localhost:9000
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port=8088
#yarn resourcemanager 地址, 如果resourcemanager開啟了HA, 輸入HA的IP地址(以逗號分隔),如果resourcemanager為單節點, 該值為空即可
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
#如果resourcemanager開啟了HA或者沒有使用resourcemanager,保持預設值即可. 如果resourcemanager為單節點,你需要將ds1 配置為resourcemanager對應的hostname
yarn.application.status.address=http://ds1:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address=http://ds1:19888/ws/v1/history/mapreduce/jobs/%s
# datasource encryption enable
datasource.encryption.enable=false
# datasource encryption salt
datasource.encryption.salt=!@#$%^&*
# data quality option
data-quality.jar.name=dolphinscheduler-data-quality-dev-SNAPSHOT.jar
#data-quality.error.output.path=/tmp/data-quality-error-data
# Network IP gets priority, default inner outer
# Whether hive SQL is executed in the same session
support.hive.oneSession=false
# use sudo or not, if set true, executing user is tenant user and deploy user needs sudo permissions; if set false, executing user is the deploy user and doesn't need sudo permissions
sudo.enable=true
# network interface preferred like eth0, default: empty
#dolphin.scheduler.network.interface.preferred=
# network IP gets priority, default: inner outer
#dolphin.scheduler.network.priority.strategy=default
# system env path
#dolphinscheduler.env.path=dolphinscheduler_env.sh
#是否處於開發模式
development.state=false
# rpc port
alert.rpc.port=50052
# Url endpoint for zeppelin RESTful API
zeppelin.rest.url=http://localhost:8080

dolphinscheduler-api application.yaml
server:
port: 12345
servlet:
session:
timeout: 120m
context-path: /dolphinscheduler/
compression:
enabled: true
mime-types: text/html,text/xml,text/plain,text/css,text/javascript,application/javascript,application/json,application/xml
jetty:
max-http-form-post-size: 5000000
spring:
application:
name: api-server
banner:
charset: UTF-8
jackson:
time-zone: UTC
date-format: "yyyy-MM-dd HH:mm:ss"
servlet:
multipart:
max-file-size: 1024MB
max-request-size: 1024MB
messages:
basename: i18n/messages
datasource:
# driver-class-name: org.postgresql.Driver
# url: jdbc:postgresql://127.0.0.1:5432/dolphinscheduler
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
username: root
password: root
hikari:
connection-test-query: select 1
minimum-idle: 5
auto-commit: true
validation-timeout: 3000
pool-name: DolphinScheduler
maximum-pool-size: 50
connection-timeout: 30000
idle-timeout: 600000
leak-detection-threshold: 0
initialization-fail-timeout: 1
quartz:
auto-startup: false
job-store-type: jdbc
jdbc:
initialize-schema: never
properties:
org.quartz.threadPool:threadPriority: 5
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.tablePrefix: QRTZ_
org.quartz.jobStore.acquireTriggersWithinLock: true
org.quartz.scheduler.instanceName: DolphinScheduler
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.jobStore.useProperties: false
org.quartz.threadPool.makeThreadsDaemons: true
org.quartz.threadPool.threadCount: 25
org.quartz.jobStore.misfireThreshold: 60000
org.quartz.scheduler.makeSchedulerThreadDaemon: true
# org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.clusterCheckinInterval: 5000
management:
endpoints:
web:
exposure:
include: '*'
metrics:
tags:
application: ${spring.application.name}
registry:
type: zookeeper
zookeeper:
namespace: dolphinscheduler
# connect-string: localhost:2181
connect-string: 10.255.158.70:2181
retry-policy:
base-sleep-time: 60ms
max-sleep: 300ms
max-retries: 5
session-timeout: 30s
connection-timeout: 9s
block-until-connected: 600ms
digest: ~
audit:
enabled: false
metrics:
enabled: true
python-gateway:
# Weather enable python gateway server or not. The default value is true.
enabled: true
# The address of Python gateway server start. Set its value to `0.0.0.0` if your Python API run in different
# between Python gateway server. It could be be specific to other address like `127.0.0.1` or `localhost`
gateway-server-address: 0.0.0.0
# The port of Python gateway server start. Define which port you could connect to Python gateway server from
# Python API side.
gateway-server-port: 25333
# The address of Python callback client.
python-address: 127.0.0.1
# The port of Python callback client.
python-port: 25334
# Close connection of socket server if no other request accept after x milliseconds. Define value is (0 = infinite),
# and socket server would never close even though no requests accept
connect-timeout: 0
# Close each active connection of socket server if python program not active after x milliseconds. Define value is
# (0 = infinite), and socket server would never close even though no requests accept
read-timeout: 0
# Override by profile
---
spring:
config:
activate:
on-profile: mysql
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8
quartz:
properties:
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
dolphinscheduler-master application.yaml
spring:
banner:
charset: UTF-8
application:
name: master-server
jackson:
time-zone: UTC
date-format: "yyyy-MM-dd HH:mm:ss"
cache:
# default enable cache, you can disable by `type: none`
type: none
cache-names:
- tenant
- user
- processDefinition
- processTaskRelation
- taskDefinition
caffeine:
spec: maximumSize=100,expireAfterWrite=300s,recordStats
datasource:
#driver-class-name: org.postgresql.Driver
#url: jdbc:postgresql://127.0.0.1:5432/dolphinscheduler
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
username: root
password:
hikari:
connection-test-query: select 1
minimum-idle: 5
auto-commit: true
validation-timeout: 3000
pool-name: DolphinScheduler
maximum-pool-size: 50
connection-timeout: 30000
idle-timeout: 600000
leak-detection-threshold: 0
initialization-fail-timeout: 1
quartz:
job-store-type: jdbc
jdbc:
initialize-schema: never
properties:
org.quartz.threadPool:threadPriority: 5
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.tablePrefix: QRTZ_
org.quartz.jobStore.acquireTriggersWithinLock: true
org.quartz.scheduler.instanceName: DolphinScheduler
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.jobStore.useProperties: false
org.quartz.threadPool.makeThreadsDaemons: true
org.quartz.threadPool.threadCount: 25
org.quartz.jobStore.misfireThreshold: 60000
org.quartz.scheduler.makeSchedulerThreadDaemon: true
# org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.clusterCheckinInterval: 5000
registry:
type: zookeeper
zookeeper:
namespace: dolphinscheduler
# connect-string: localhost:2181
connect-string: 10.255.158.70:2181
retry-policy:
base-sleep-time: 60ms
max-sleep: 300ms
max-retries: 5
session-timeout: 30s
connection-timeout: 9s
block-until-connected: 600ms
digest: ~
master:
listen-port: 5678
# master fetch command num
fetch-command-num: 10
# master prepare execute thread number to limit handle commands in parallel
pre-exec-threads: 10
# master execute thread number to limit process instances in parallel
exec-threads: 100
# master dispatch task number per batch
dispatch-task-number: 3
# master host selector to select a suitable worker, default value: LowerWeight. Optional values include random, round_robin, lower_weight
host-selector: lower_weight
# master heartbeat interval, the unit is second
heartbeat-interval: 10
# master commit task retry times
task-commit-retry-times: 5
# master commit task interval, the unit is millisecond
task-commit-interval: 1000
state-wheel-interval: 5
# master max cpuload avg, only higher than the system cpu load average, master server can schedule. default value -1: the number of cpu cores * 2
max-cpu-load-avg: -1
# master reserved memory, only lower than system available memory, master server can schedule. default value 0.3, the unit is G
reserved-memory: 0.3
# failover interval, the unit is minute
failover-interval: 10
# kill yarn jon when failover taskInstance, default true
kill-yarn-job-when-task-failover: true
server:
port: 5679
management:
endpoints:
web:
exposure:
include: '*'
metrics:
tags:
application: ${spring.application.name}
metrics:
enabled: true
# Override by profile
---
spring:
config:
activate:
on-profile: mysql
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
quartz:
properties:
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
dolphinscheduler-worker application.yaml
spring:
banner:
charset: UTF-8
application:
name: worker-server
jackson:
time-zone: UTC
date-format: "yyyy-MM-dd HH:mm:ss"
datasource:
#driver-class-name: org.postgresql.Driver
#url: jdbc:postgresql://127.0.0.1:5432/dolphinscheduler
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
username: root
#password: root
password:
hikari:
connection-test-query: select 1
minimum-idle: 5
auto-commit: true
validation-timeout: 3000
pool-name: DolphinScheduler
maximum-pool-size: 50
connection-timeout: 30000
idle-timeout: 600000
leak-detection-threshold: 0
initialization-fail-timeout: 1
registry:
type: zookeeper
zookeeper:
namespace: dolphinscheduler
# connect-string: localhost:2181
connect-string: 10.255.158.70:2181
retry-policy:
base-sleep-time: 60ms
max-sleep: 300ms
max-retries: 5
session-timeout: 30s
connection-timeout: 9s
block-until-connected: 600ms
digest: ~
worker:
# worker listener port
listen-port: 1234
# worker execute thread number to limit task instances in parallel
exec-threads: 100
# worker heartbeat interval, the unit is second
heartbeat-interval: 10
# worker host weight to dispatch tasks, default value 100
host-weight: 100
# worker tenant auto create
tenant-auto-create: true
# worker max cpuload avg, only higher than the system cpu load average, worker server can be dispatched tasks. default value -1: the number of cpu cores * 2
max-cpu-load-avg: -1
# worker reserved memory, only lower than system available memory, worker server can be dispatched tasks. default value 0.3, the unit is G
reserved-memory: 0.3
# default worker groups separated by comma, like 'worker.groups=default,test'
groups:
- default
# alert server listen host
alert-listen-host: localhost
alert-listen-port: 50052
server:
port: 1235
management:
endpoints:
web:
exposure:
include: '*'
metrics:
tags:
application: ${spring.application.name}
metrics:
enabled: true
主要關註資料庫,quartz, zookeeper, masker, worker配置。
2.2 API主要任務操作介面
其他業務介面可以不用關註,只需要關註最最主要的流程上線功能介面,此介面可以發散出所有的任務調度相關的代碼。
介面:/dolphinscheduler/projects/{projectCode}/schedules/{id}/online;此介面會將定義的流程提交到Quartz調度框架;代碼如下:
public Map<String, Object> setScheduleState(User loginUser, long projectCode, Integer id, ReleaseState scheduleStatus) { Map<String, Object> result = new HashMap<>();
Project project = projectMapper.queryByCode(projectCode); // check project auth boolean hasProjectAndPerm = projectService.hasProjectAndPerm(loginUser, project, result); if (!hasProjectAndPerm) { return result; }
// check schedule exists Schedule scheduleObj = scheduleMapper.selectById(id);
if (scheduleObj == null) { putMsg(result, Status.SCHEDULE_CRON_NOT_EXISTS, id); return result; } // check schedule release state if (scheduleObj.getReleaseState() == scheduleStatus) { logger.info("schedule release is already {},needn't to change schedule id: {} from {} to {}", scheduleObj.getReleaseState(), scheduleObj.getId(), scheduleObj.getReleaseState(), scheduleStatus); putMsg(result, Status.SCHEDULE_CRON_REALEASE_NEED_NOT_CHANGE, scheduleStatus); return result; } ProcessDefinition processDefinition = processDefinitionMapper.queryByCode(scheduleObj.getProcessDefinitionCode()); if (processDefinition == null || projectCode != processDefinition.getProjectCode()) { putMsg(result, Status.PROCESS_DEFINE_NOT_EXIST, String.valueOf(scheduleObj.getProcessDefinitionCode())); return result; } List<ProcessTaskRelation> processTaskRelations = processTaskRelationMapper.queryByProcessCode(projectCode, scheduleObj.getProcessDefinitionCode()); if (processTaskRelations.isEmpty()) { putMsg(result, Status.PROCESS_DAG_IS_EMPTY); return result; } if (scheduleStatus == ReleaseState.ONLINE) { // check process definition release state if (processDefinition.getReleaseState() != ReleaseState.ONLINE) { logger.info("not release process definition id: {} , name : {}", processDefinition.getId(), processDefinition.getName()); putMsg(result, Status.PROCESS_DEFINE_NOT_RELEASE, processDefinition.getName()); return result; } // check sub process definition release state List<Long> subProcessDefineCodes = new ArrayList<>(); processService.recurseFindSubProcess(processDefinition.getCode(), subProcessDefineCodes); if (!subProcessDefineCodes.isEmpty()) { List<ProcessDefinition> subProcessDefinitionList = processDefinitionMapper.queryByCodes(subProcessDefineCodes); if (subProcessDefinitionList != null && !subProcessDefinitionList.isEmpty()) { for (ProcessDefinition subProcessDefinition : subProcessDefinitionList) { /** * if there is no online process, exit directly */ if (subProcessDefinition.getReleaseState() != ReleaseState.ONLINE) { logger.info("not release process definition id: {} , name : {}", subProcessDefinition.getId(), subProcessDefinition.getName()); putMsg(result, Status.PROCESS_DEFINE_NOT_RELEASE, String.valueOf(subProcessDefinition.getId())); return result; } } } } }
// check master server exists List<Server> masterServers = monitorService.getServerListFromRegistry(true);
if (masterServers.isEmpty()) { putMsg(result, Status.MASTER_NOT_EXISTS); return result; }
// set status scheduleObj.setReleaseState(scheduleStatus);
scheduleMapper.updateById(scheduleObj);
try { switch (scheduleStatus) { case ONLINE: logger.info("Call master client set schedule online, project id: {}, flow id: {},host: {}", project.getId(), processDefinition.getId(), masterServers); setSchedule(project.getId(), scheduleObj); break; case OFFLINE: logger.info("Call master client set schedule offline, project id: {}, flow id: {},host: {}", project.getId(), processDefinition.getId(), masterServers); deleteSchedule(project.getId(), id); break; default: putMsg(result, Status.SCHEDULE_STATUS_UNKNOWN, scheduleStatus.toString()); return result; } } catch (Exception e) { result.put(Constants.MSG, scheduleStatus == ReleaseState.ONLINE ? "set online failure" : "set offline failure"); throw new ServiceException(result.get(Constants.MSG).toString(), e); }
putMsg(result, Status.SUCCESS); return result; }
public void setSchedule(int projectId, Schedule schedule) {
logger.info("set schedule, project id: {}, scheduleId: {}", projectId, schedule.getId());
quartzExecutor.addJob(ProcessScheduleJob.class, projectId, schedule);
}


