
從提升性能角度來說 提升了對CPU的使用效率:目前生產的伺服器大多數都是多核,標配的機器都是 8C/16G。操作系統會將不同的線程分配給不同的核心處理,理論上,有多少核心就有多少個線程並行執行。如果沒有併發編程,CPU的利用率將極大的浪費,假設當前正在處理耗時的 I/O 操作,那麼整個CPU就會處於... ...
背景介紹
為什麼需要學習 Java 併發?
從提升性能角度來說
- 提升了對CPU的使用效率:目前生產的伺服器大多數都是多核,標配的機器都是 8C/16G。操作系統會將不同的線程分配給不同的核心處理,理論上,有多少核心就有多少個線程並行執行。如果沒有併發編程,CPU的利用率將極大的浪費,假設當前正在處理耗時的 I/O 操作,那麼整個CPU就會處於阻塞空閑狀態,後面的指令必須等待前面的執行完才能繼續執行。
- 降低服務 RT:大型互聯網訪問量輕鬆每秒輕鬆過萬,如果沒有併發處理,所有的用戶請求都會排隊等待,那種體驗效果你能想象麽,這樣的服務能力如何能留住客戶?有了併發編程,充分釋放CPU算力,操作系統讓每個客戶輪流使用CPU計算,每個客戶都能得到快速的響應。
- 容錯率高:線程與線程之間的執行不會相互干擾,某個線程執行出現異常退出,不會對其它線程造成影響。
從開發者角度來說
- Java 基礎面試必考察技能:Java 併發面試問題基本必出現,有大型項目研發經驗的同學,處理併發問題多的同學,往往會被青睞。因為越是複雜的系統,併發請求就越多,簡單的業務 + 併發 = 這個業務不簡單。
- 工作中離不開併發:多線程能充分發揮CPU的計算力,這使得我們不得不瞭解併發的原理,以免造成線程安全問題,給生產帶來損失。常用的中間件中大量運用了併發知識,如 MQ、RPC等,如果不熟悉原理,如何能夠調優中間件的使用。
併發編程業務中的實踐
實踐一:風控規則引擎——策略執行
互聯網企業風控安全部門每時每刻都需要和黑灰產對抗,保護企業遭受不必要的經濟損失。風控策略團隊在對抗的過程中,沉澱出一系列風險識別策略,用以檢測當前業務請求中否存在高危操作。
風控安全團隊需要評估業務在運行流程中,是否存在黑產能夠獲取利益點的地方,即“風險卡點”。評估後,需要業務在每次流程經過風險卡點處,需透傳業務信息給風控服務,風控服務在很多時間內進行大量決策計算,並返回業務方決策結果(ACCEPT-通過/REVIEW-人工,需進一步信息確認/REJECT-拒絕,高危操作)。如圖展示的是營銷活動——裂變類活動風險卡點。
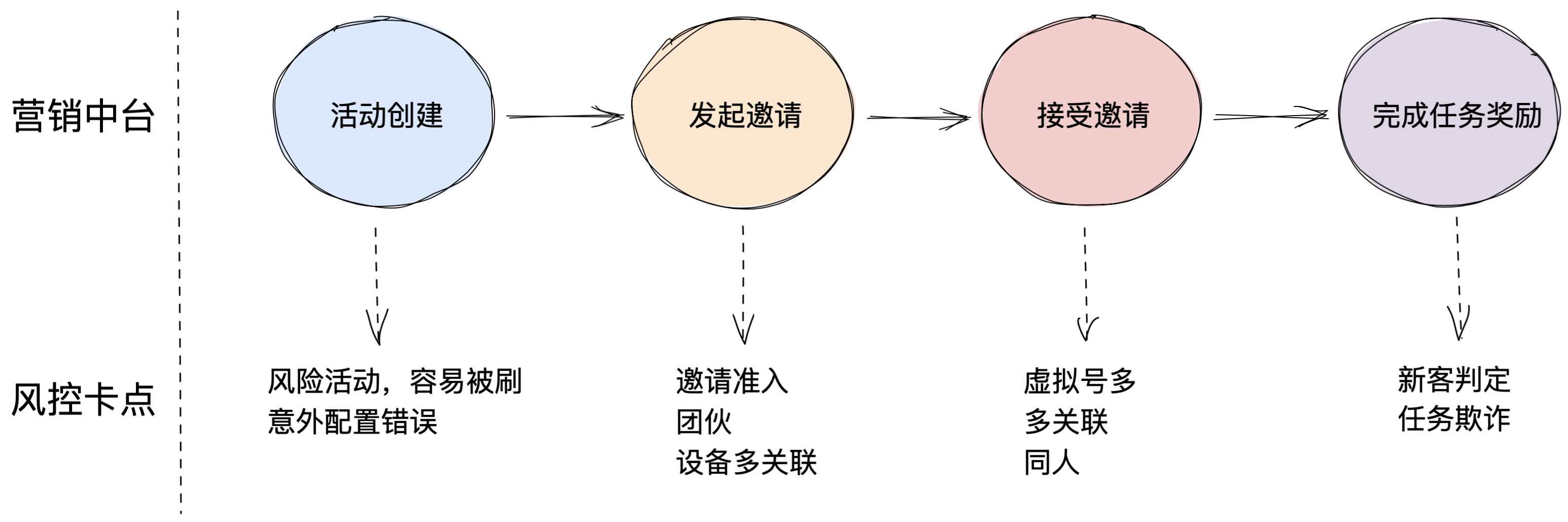
營銷裂變流程風險卡點圖
一條業務請求耗時一般在 300 ~ 500 ms 之間,如果超過這個區間,可能就需要定位調優哪個節點耗時高了。大型互聯網公司系統架構比較複雜,完整的業務可能有幾十甚至上百個服務系統,你觸發的一次請求,可能中途會經過多少服務超過你想象。
如上述,業務對風控服務的性能要求很高,一般控制在 100 ms 以內。但風控內部排查業務請求涉及大量策略和規則,如何短時間內執行完,且又不閹割策略呢?答案是併發變成。風控內部大量使用併發,以滿足海量請求和計算需求,我將以策略規則的執行來舉例如何編寫編髮變成代碼。如下是風控服務一次請求的大致執行流程:
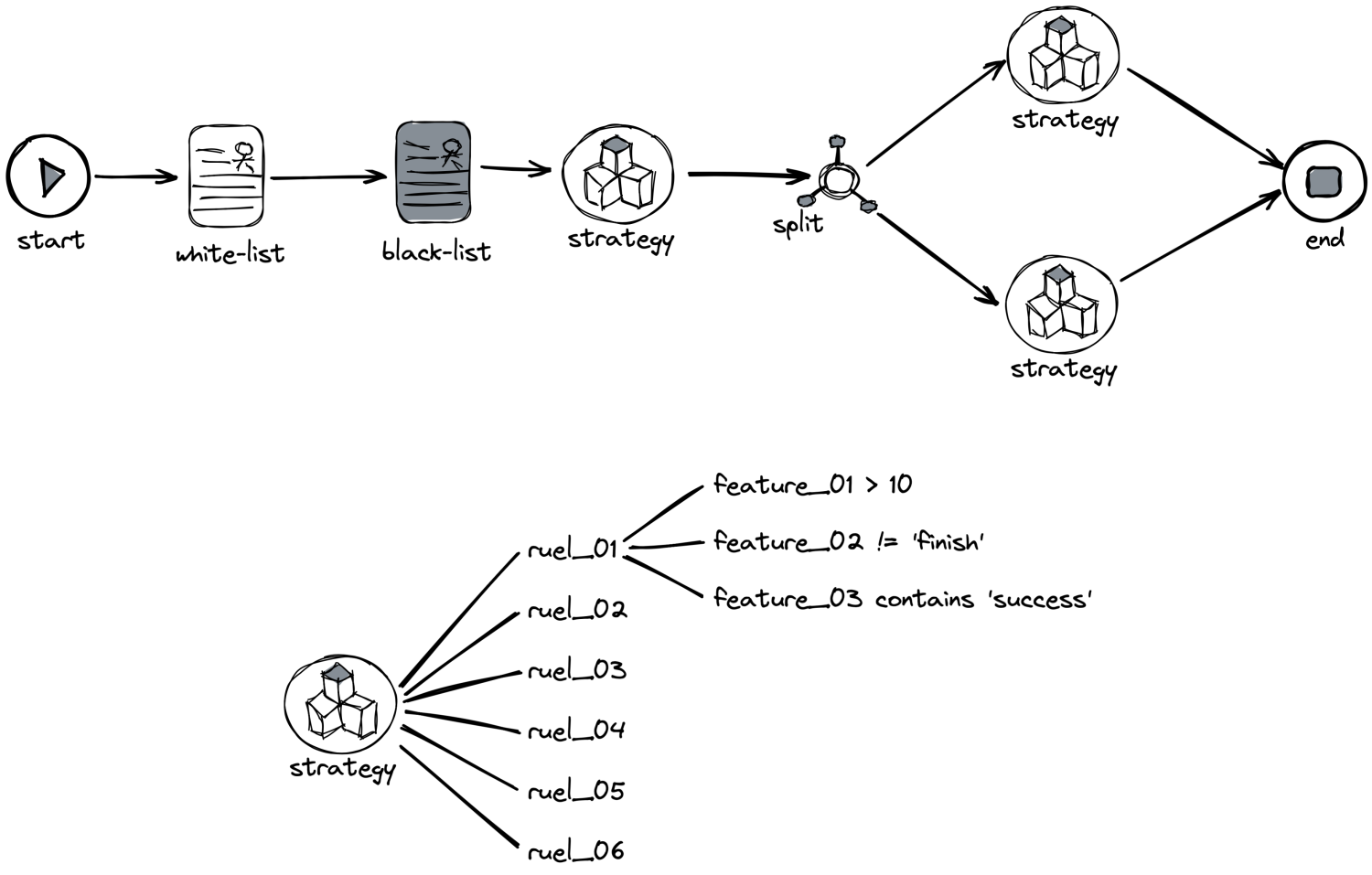
風控流程執行圖
可以看到,一次風控請求的判定,涉及大量的規則判定,此時如果沒有併發,會出現什麼效果?
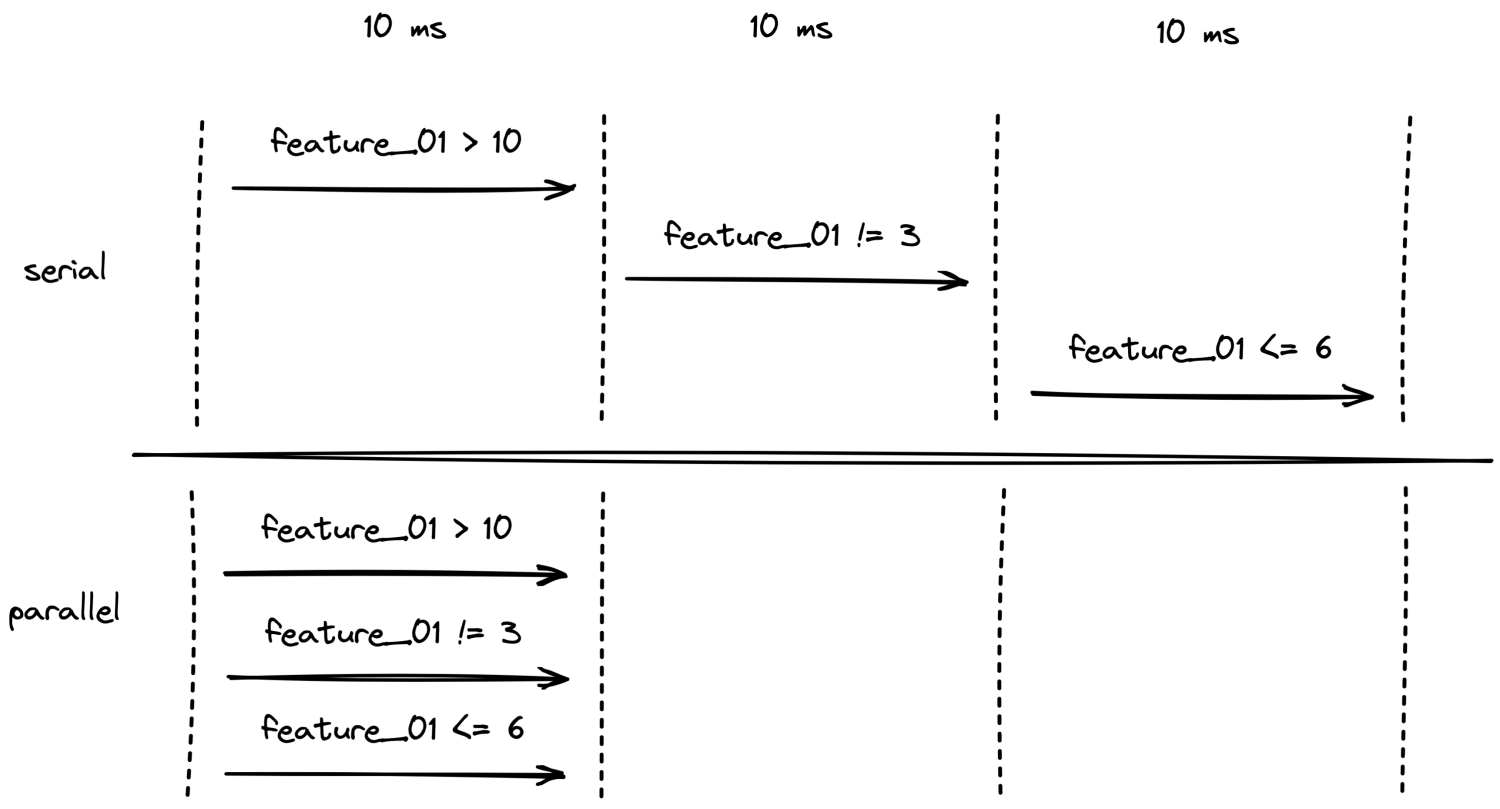
串列&並行執行規則圖
全部串列執行策略和規則的話,可能幾秒都不定能計算出來,此時我們需要使用 Java 併發來滿足性能需求。
核心代碼如下:
public class RuleSessionExecutor {
// 線程池
private final static ExecutorService executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors() * 8,
Runtime.getRuntime().availableProcessors() * 8,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new CustomerThreadFactory("rule-executor"),
new ThreadPoolExecutor.AbortPolicy());
/**
* 規則執行
* @param rules
*/
public void execute(List<CustomerSession> rules) {
final CountDownLatch lock = new CountDownLatch(rules.size());
for (CustomerSession session : rules) {
try {
session.exec();
} catch (Throwable e) {
} finally {
lock.countDown();
}
}
try {
lock.await(50, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("CountDownLatch error", e);
}
}
}
此處用到了 CountDownLatch 併發工具類,下文會使用介紹。
實踐二:風控特征平臺特征載入
如上述實踐一,大量的規則執行前需要大量的特征,如果在每條規則執行內獲取特征,可行,但是會造成特征的重覆獲取問題,浪費了性能。舉例:如果規則人員做 A/B 測試,兩個策略包有交集的特征特別多,此時如果在每個規則內獲取,就等於有交集的特征重覆訪問兩次,這種浪費是沒必要的。此時我們在規則執行前先獲取當前策略包下所有的去重特征,然後獲取所有的特征後,再去執行規則。
那麼此時的問題是,如何批量的去獲取特征呢?
特征的種類很多:
- 輸入型:不耗時-請求上下文攜帶,如訂單金額
- 衍生型:基本不耗時-基於輸入型特征衍生,如依據經緯度計算距離
- 實時統計特征:基本不耗時-感興趣的可以關註我文章 Flink 在風控場景實時特征落地實戰,詳細介紹
- 查詢類:耗時-如依據訂單號調業務 RPC 介面獲取訂單明細信息,通信 + 業務本身耗時
- 外部類:耗時-如第三方風控公司產品,同盾、IPIP等
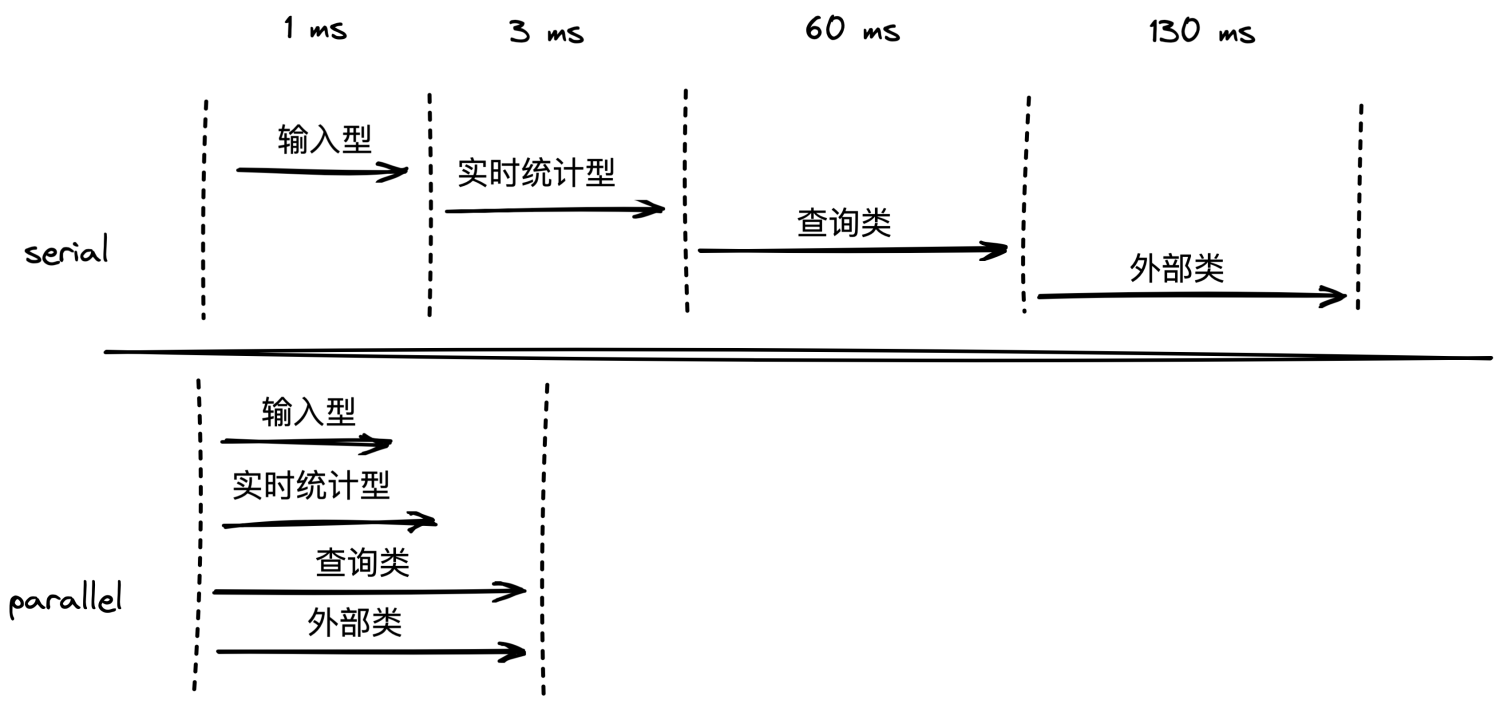
特征同步獲取 & 非同步獲取對比圖
顯然,我們需要併發來支撐性能,核心代碼如下:
public class DataSourceExecutor {
private final static ExecutorService executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors() * 8,
Runtime.getRuntime().availableProcessors() * 8,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new HamThreadFactory("ds-executor"),
new ThreadPoolExecutor.AbortPolicy());
/**
* 特征獲取
*
* @param dataSources
*/
public void execute(List<DataSource> dataSources) {
List<CompletableFuture> futures = Lists.newArrayList();
long timeout = ApolloConfig.getLongProperty(ApolloConfigKey.DS_TIMEOUT_OUTER_KEY, 150L);
for (DataSource ds : dataSources) {
timeout = ds.getExecutionTimeout() > timeout ? ds.getExecutionTimeout() : timeout;
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
ds.execute();
}, executor);
futures.add(future);
}
CompletableFuture<Void> summaryFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture<?>[]{}));
try {
summaryFuture.get(timeout, TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
log.error("DataSource exec error", e);
}
}
}
和規則的批量執行大同小異,單此處用到了 Java 8 CompletableFuture 併發工具類,功能上有所增強,下文會使用介紹。
實踐三:分散式任務跑批
定時任務應該是工作中很常見的需求了,如訂單狀態流轉檢測、對賬等。任務一般都是跑批的,即包含多個子任務,該場景很適合線程池任務隊列併發執行。

任務隊列線程池圖
核心代碼如下:
public void execute(List<Task> tasks) {
tasks.forEach(t -> {
executor.execute(() -> {
try {
log.info("task id: {} begin exec", t.getId());
t.execute();
} catch (Throwable e) {
log.error(String.format("task execute error, uid: %s", t.getId()), e);
} finally {
log.info("task id: {} end exec", t.getId());
}
});
});
}
併發編程常用工具類
線程池
線程池(英語:thread pool):一種線程使用模式。線程過多會帶來調度開銷,進而影響緩存局部性和整體性能。而線程池維護著多個線程,等待著監督管理者分配可併發執行的任務。這避免了在處理短時間任務時創建與銷毀線程的代價。線程池不僅能夠保證內核的充分利用,還能防止過分調度。可用線程數量應該取決於可用的併發處理器、處理器內核、記憶體、網路sockets等的數量【1】。
J.U.C提供的線程池:ThreadPoolExecutor類,幫助開發人員管理線程並方便地執行並行任務。瞭解併合理使用線程池,是一個開發人員必修的基本功。
任務調度
當用戶提交了任務,任務的生命周期將有線程池管控。線程池內部實際上構建了一個生產者/消費者模式,線程與任務是解耦的,沒有強關聯性,這有利於任務的緩衝&復用。瞭解線程池的第一步必須知道任務的運行機制。
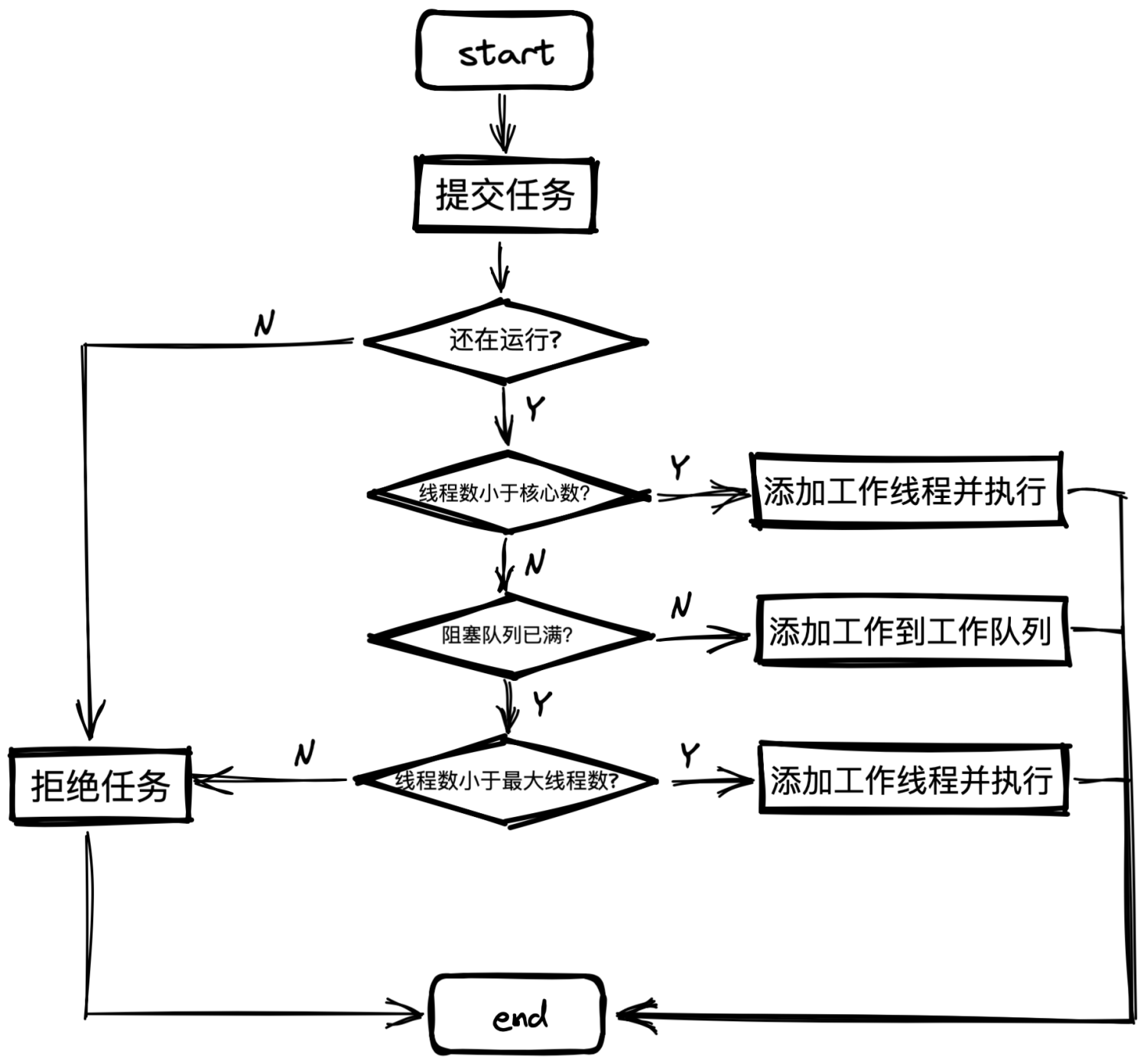
任務執行圖
任務隊列
線程池的本質是對任務和線程的管理,而做到這一點的關鍵是解耦任務和線程,不讓兩者直接關聯,才能做到後續的合理分配工作。線程池中是以生產者消費者模式,通過一個阻塞隊列來實現的。阻塞隊列緩存任務,工作線程從阻塞隊列中獲取任務。
阻塞隊列(BlockingQueue)在隊列的基礎上新增兩個特性。
- 隊列為空時,獲取元素的線程會等待隊列變為非空
- 隊列滿時,存儲元素的線程會等待隊列可用
阻塞隊列常用於生產者和消費者的場景,生產者是往隊列里添加元素的線程,消費者是從隊列里拿元素的線程。阻塞隊列就是生產者存放元素的容器,而消費者也只從容器里拿元素。

阻塞隊列示意圖
阻塞隊列如下表可選擇:
| ArrayBlockingQueue | 有界;數組實現;FIFO; |
|---|---|
| LinkedBlockingQueue | 有界(預設長度Integer.MAX_VALUE,不小心就會記憶體溢出);鏈表實現;FIFO; |
| PriorityBlockingQueue | 無界;平衡二叉樹實現;排序 |
| DelayQueue | 同PriorityBlockingQueue;對象只能在其到期時才能從隊列中取走 |
| SynchronousQueue | 不存儲元素;沒一個put操作需等待take操作 |
| LinkedTransferQueue | 有界;優勢在於相對LinkedBlockingQueue降低了鎖的粒度,性能更高 |
| LinkedBlockingDeque | 相對LinkedBlockingQueue實現雙端阻塞;鎖粒度降低,性能較好 |
任務拒絕
線程池自我保護熔斷部分,當任務有界緩存隊列已滿,證明線程池已經超負荷運轉,處理不過來了。此時需要拒絕新進任務,採用設置的拒接策略,以保護線程池。
用戶可以選擇JDK提供的四種拒絕策略,或者自定義實現RejectedExecutionHandler介面即可
| ThreadPoolExecutor.AbortPolicy() | 丟棄任務並拋出RejectedExecutionException異常;線程池預設拒絕策略;關鍵業務應使用此異常策略,以瞭解線程池的健康狀況 |
|---|---|
| ThreadPoolExecutor.CallerRunsPolicy() | 由主線程去執行當前任務 |
| ThreadPoolExecutor.DiscardOldestPolicy() | 丟棄老任務,重新提交任務;生產不建議使用,有風險 |
| ThreadPoolExecutor.DiscardPolicy() | 丟棄任務&不拋出異常;生產不建議使用,不易發現問題 |
CountDownLatch——同步計數器
CountDownLatch內部使用計數器實現,初始化時計數器數量等於需要處理的等待線程數量,當每個線程執行完畢後需要將計數器減一,當計數器到0後,代表需要等待執行的線程已全部執行完畢,此時會喚醒主線程繼續執行主線任務。

CountDownLatch流程圖
常用場景:
- 1等N:結合線程池釋放CPU算力,如首頁複雜信息流成精,可以分佈載入各模塊信息,計數結束後在交由主線程結構化數據返回
- 最壞匹配:哪一個線程執行完畢,可以立即釋放cnt數量至0,通知主線程執行
核心代碼:
public void demo() {
List<Task> tasks = ...
final CountDownLatch countDownLatch = new CountDownLatch(10);
tasks.forEach(task -> {
try {
// 自己的子線程邏輯
} catch (Throwable e) {
// 有時 Exception 接不到的異常,建議用 Throwable
} finally {
countDownLatch.countDown();
}
});
try {
countDownLatch.await(100, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("countDownLatch InterruptedException", e);
}
}
CompletableFuture
Java 在 1.8 版本提供了 CompletableFuture 來支持非同步編程,CompletableFuture 的功能著實讓人感到震撼。他的複雜度應該也是我見過的最複雜之一了。
我們看個例子來直觀感受下 CompletableFurure 的威力
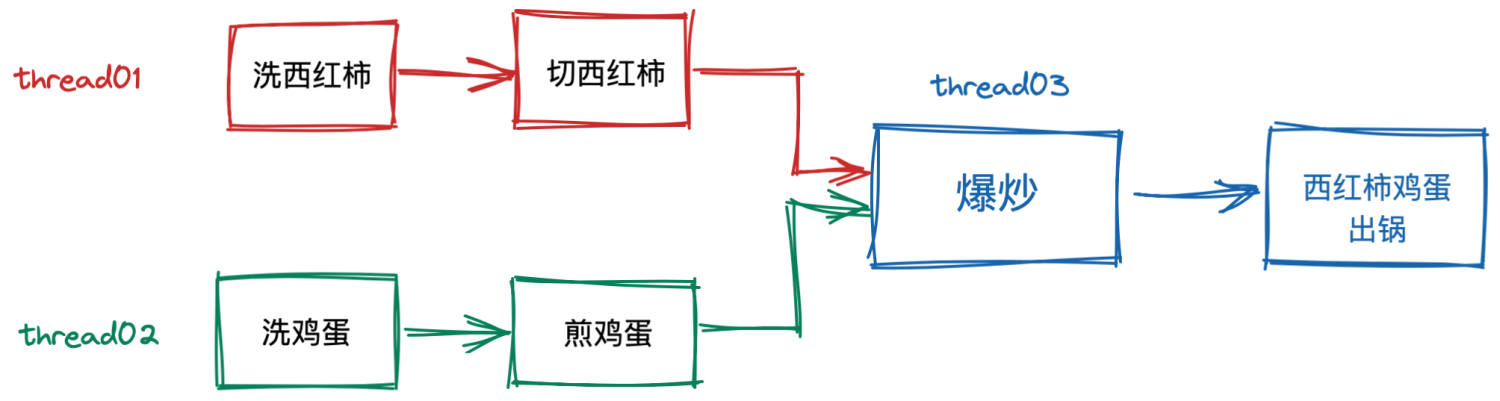
CompletableFuture 之西紅柿炒蛋
// 步驟一:準備西紅柿
CompletableFuture<String> f1 =
CompletableFuture.supplyAsync(() -> {
System.out.println("洗西紅柿");
System.out.println("切它");
return "切好的西紅柿";
});
// 步驟二:準備雞蛋
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(() -> {
System.out.println("洗雞蛋");
System.out.println("煎雞蛋");
return "煎好的雞蛋";
});
// 步驟三:炒雞蛋
CompletableFuture<String> f3 =
f1.thenCombine(f2, (__, tf) -> {
System.out.println("爆炒");
return "西紅柿炒雞蛋";
});
// 等待任務 3 執行結果
System.out.println(f3.join());
CompletableFuture 旨在解決多線程之間的複雜實現邏輯,如上所示,其實都是只包含了業務實現的邏輯,併發編程的邏輯已經被 Lamda 編程巧妙的規避了。即用最少的代碼乾最硬的事,很完美。
此處不對 CompletableFuture 作詳細的描述,如果感興趣可以關註我,因為 CompletableFuture 實現即使用一篇文章都不一定能說完。
常見併發問題及解決
死鎖&定位
死鎖(deadlock),當兩個以上的運算單元,雙方都在等待對方停止執行,以獲取系統資源,但是沒有一方提前退出時,就稱為死鎖。【1】
死鎖的四個條件是:
- 禁止搶占(no preemption):系統資源不能被強制從一個進程中退出。
- 持有和等待(hold and wait):一個進程可以在等待時持有系統資源。
- 互斥(mutual exclusion):資源只能同時分配給一個行程,無法多個行程共用。
- 迴圈等待(circular waiting):一系列進程互相持有其他進程所需要的資源。
定位
jps
jstack pid
// 上面的信息截取
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007fcc68023f58 (object 0x0000000795ea0c00, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x00007fcc68022ab8 (object 0x0000000795ea0c10, a java.lang.Object),
which is held by "Thread-1"
jps 定位運行的 java 程式,然後利用 jstack pid 列印線程信息,拉倒最下麵很明顯發現有提示 deadlock,再依據線程號 0x00007fcc68023f58 尋找到對應的線程即可分析是哪一段代碼引發的問題。
性能調優
Java 併發多線程編程,我們首選的工具一定是線程池。線程池使用面臨的核心的問題在於:線程池的參數並不好配置!
你是否會也遇到過按照經驗去預估線上某個場景線程池最小活躍線程和最大活躍線程數不准或失誤。事實上並無線程池通用的計算公式,因為一臺機器上並不是只有你的一個服務,且一個服務內並不是只有一個線程池,如果按照 I/O密集 或者 CPU密集 預估,還是免不了反覆調試的苦。
那麼我們是否可以將修改線程池參數的成本降下來,這樣至少可以發生故障的時候可以快速調整從而縮短故障恢復的時間呢?
本篇不會多講動態線程池的架構設計,感興趣的可以關註我,後續會發文,此處只給出一個大概的思路:
- 動態調參:支持線程池核心參數動態調整,最小/最大核心線程數
- 任務監控:主要監控阻塞隊列堆積 和 單次線程執行耗時 95 99 線
- 告警:有潛在壓力及時預警修正
- 操作通知&鑒權:生產操作很危險,需謹慎
完善監控
任何系統的運行都離不開監控,只是顆粒度粗細的問題,併發場景,我們尤其需要關註服務線程的監控狀況,尤其是活躍線程數、隊列堆積長度、平均耗時、吞吐量等重要指標。發生預警時能及時通知相應的開發人員降級處理,亦可自動熔斷,保護主服務。
往期精彩
個人技術博客:https://jifuwei.github.io/
公眾號:是咕咕雞


