
Hello,大家好,我是烤鴨,這幾天消失了一下,主要是線上系統出了點小bug和sql性能問題,在努力搬磚,就把之前的設計模式系列放了一下下,正好趁這個複習鞏固了一下sql執行計劃和sql優化等相關的東西,本篇文章我主要用來學習mysql的執行計劃和索引分類,也和大家分享下吧,也請大神們不吝賜教。 先 ...
Hello,大家好,我是烤鴨,這幾天消失了一下,主要是線上系統出了點小bug和sql性能問題,在努力搬磚,就把之前的設計模式系列放了一下下,正好趁這個複習鞏固了一下sql執行計劃和sql優化等相關的東西,本篇文章我主要用來學習mysql的執行計劃和索引分類,也和大家分享下吧,也請大神們不吝賜教。
先來熟悉一下索引吧。索引是在存儲引擎中實現的,不同的存儲引擎可能會使用不同索引,Myisam和InnoDB存儲引擎只能支持BTREE索引,不能更換,而MEMORY/HEAP存儲引擎支持HASH和BTREE索引;
常用的索引我們分為三大類:包括單列索引(普通索引、唯一索引、主鍵索引等)、組合索引、全文索引等;
1、單列索引:一個索引只包含一列,但是一張表中可以有多個單列索引;
1.1普通索引,沒有什麼限制,允許在定義索引列中插入空值和重覆值,純粹是為了查詢數據更快點;
1.2唯一索引,索引列中的值必須是唯一的,允許空值;
1.3主鍵索引,是一種特殊的唯一索引,不允許有空值;
2、組合索引:在表中的多個欄位組合上創建的索引,只有在查詢條件中使用這些欄位的左邊欄位時,索引才會被使用,使用組合索引時候遵循左首碼集合的原則,例如有id、name、age這3個欄位構成的組合索引,索引行中就按照id/name/age的順序存放,索引可以索引下麵欄位組合(id/name/age)、(id/name)、(id/age)、id,如果要查詢的欄位構不成索引的最左首碼,那麼是不會使用索引的,如(name/age)、age組合就不會使用索引;
3、全文索引(fulltext索引):mysql5.6之前的版本,只有在Myisam存儲引擎上使用,mysql5.6之後的版本innodb和myisam存儲引擎均支持全文索引,並且只能在char、varchar、text類型的欄位上才能使用全文索引;全文索引主要用來查找文本中的關鍵字,而不是直接與索引中的值比較,更像是一個搜索引擎,而不是簡單地where語句參數的匹配,在數據量較大的時候,先將數據寫入到一張沒有全文索引表中,再創建fulltext索引的速度,要比先為一張表建立fulltext索引,再將數據寫入的速度快很多。
覆蓋索引是select的數據列只用從索引中就能夠取得,不必讀取數據行(它包括在查詢里的Select、Join和Where子句用到的所有列)。索引是高效找到行的一個方法,但是一般資料庫也能使用索引找到一個列的數據,因此不必讀取整個數據行,索引的葉子節點存儲了它們的索引數據,當能通過讀取索引就可以得到所需要的數據,那就不需要讀取數據行了,一個索引包含了(或者覆蓋率)滿足查詢結果的數據就叫做覆蓋索引。
索引的創建和簡單用法參見:
那麼我們怎麼知道是否使用了覆蓋索引呢?如果使用了覆蓋索引,在Extra欄位會輸出Using index欄位,那麼我們就可以知道當前查詢使用了覆蓋索引。
下麵開始學習sql執行計劃啦!!!
我使用的mysql版本是5.6.16-log,建表語句如下:
CREATE TABLE `actor` ( `id` int(11) NOT NULL, `name` varchar(45) DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `film` ( `id` int(11) NOT NULL, `name` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `film_actor` ( `id` int(11) NOT NULL, `film_id` int(11) NOT NULL, `actor_id` int(11) NOT NULL, `remark` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_film_actor_id` (`film_id`,`actor_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO actor (id,name,update_time) VALUES (1,'郭德綱',NULL), (2,'周潤發',NULL), (3,'劉華強',NULL);
INSERT INTO film (id,name) VALUES (4,'九層妖塔'), (2,'建國大業'), (3,'烈火英雄'), (1,'百團大戰');
INSERT INTO film_actor (id,film_id,actor_id,remark) VALUES (1,1,1,NULL), (2,2,1,NULL), (3,2,2,NULL), (4,4,3,NULL), (5,3,3,NULL);
mysql執行計劃的定義:通過explain關鍵字來模擬sql優化器執行sql語句,從而分析sql的執行過程;
sql語句執行過程:
1、客戶端發送一條sql查詢請求給資料庫伺服器;
2、資料庫伺服器檢查緩存,如果命中,直接返回存儲在緩存中的結果,否則進入下一階段;
3、伺服器進行sql解析、預處理、再由優化器生成對應的執行計劃;
4、伺服器在根據生成的執行計劃,調用存儲引擎的API來執行查詢;
5、將結果返回給客戶端,同時緩存查詢結果;
explain中的列:

1、id(查詢執行順序)
id值相同時從上向下執行;id值相同被視為一組;id值越大優先順序越高,最先執行,id值為Null則最後執行,示例如下;

2、select_type
simple:表示查詢中不包含子查詢或者union,示例如下;

primary:當查詢中包含任何複雜的子部分,最外層的查詢會被標記為primary,示例如下;
derived:在from的列表中包含的子查詢會被標記為derived,示例如下;

subquery:在select或者where列表中包含了子查詢,則子查詢中被標記成了subquery,示例如下;
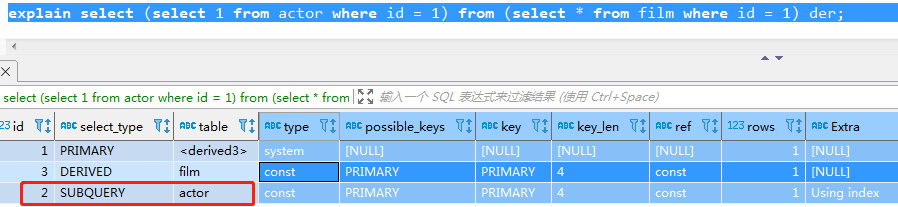
union::兩個select查詢時前一個標記為primary,後一個標記為union。union出現在from從句子查詢中,外層的select會被標記為primary,union中的第一個查詢為derived, 第二個子查詢標記為union;
unionresult:從union表獲取結果的select被標記成union result,示例如下;

3、table
顯示這行數據是關於哪張表的,當from子句中有子查詢時,table用<derivedN>表示,按照N的序號從大到小執行;當有union時,select_type類型為union result,table列的值為<union1,2>,1、2表示參與union的select的行id;
4、type(重要)
顯示連接使用了何種類型,從最好到最差的連接類型為system>constant>eq_ref>ref>range>index>all,查詢一般的保證達到range級別,最好達到ref;
a、null:mysql能夠在優化階段分解查詢語句,在執行階段不用再訪問表或索引,例如:在索引列中選取最小值,可以單獨查找索引來完成,不需要在執行時訪問表;
b、system:表中只有一行數據。屬於const的特例,如果物理表中就一行數據則為All;
c、const:查詢結果最多有一個匹配行,可以被視為常量,只讀一次查詢速度非常快,一般情況下把主鍵或者唯一索引作為唯一查詢條件的查詢的情況都是const,mysql優化器就會將該查詢轉換成一個常量;
d、eq_ref:唯一性索引掃描,對於每個索引鍵,表中只有一條記錄與之匹配,常見於主鍵或唯一索引,常見於聯合查詢,讀取主表和關聯表中的每一行組成新的一行,當連接部分使用索引的時候,索引是主鍵索引或者非空唯一索引的時候會使用此種連接類型,eq_ref可用於=運算比較的索引列,比較值可以是常量或使用此表之前讀取的表中的列的表達式;
e、ref:不使用唯一性索引掃描,而是使用普通索引或者唯一性索引的部分首碼,索引要和某個值比較,可能會匹配到多個符合條件的行;
1、簡單select語句,假設某個表中存在一列name,name是普通索引(非唯一索引);
2、關聯表查詢,採用了聯合索引的左邊首碼部分;
f、range:掃描部分索引、索引範圍掃描,對索引的掃描開始於某一點,返回匹配值域的行,常見於between、<、>等的查詢;
g、index:掃描索引就能拿到結果,一般是掃描某個二級索引,這種掃描不會從索引樹的根節點開始快速查找,而是直接對二級索引的葉子節點進行遍歷和掃描,速度還是比較慢的,這種查詢一般使用覆蓋索引,二級索引一般比較小,通常比ALL快一點;
h、all:即全表掃描,掃描聚簇索引的所有葉子結點,通常情況就需要增加索引來優化了;
index merge:對多個索引分別進行條件掃描,然後將它們各自的結果進行合併;
5、possible_keys
a、查詢條件欄位涉及到的索引,可能沒有使用;
b、explain時可能出現possible_keys列有值,而key沒有值的情況,這種情況是因為表中的數據不多,mysql認為索引對此查詢幫助不大,選擇了全表查詢;
c、如果該列是null,則沒有相關索引。在這種情況下,可以通過檢查where子句看是否可以創造一個適當的索引來提高查詢性能,然後查看explain查看效果;
6、key
實際使用的索引,如果為null,則沒有使用索引;如果想強制mysql使用或者忽略possible_key是列中的所列,在查詢中使用force index、ignore index;
7、key_len
表示索引中使用的位元組數,查詢中使用的索引的長度(最大可能長度),並非實際使用長度,理論上長度越短越好,key_len是根據表定義計算而得出的,不是通過表內檢索出的。
例如:explain select * from film_actor where film_id = 2;

索引長度的計算規則如下表:

從這個我們也可以看出varchar(n)保存的字元串的最大長度是65535;
8、ref:顯示索引的哪一列被使用了,如果可能的話,是一個常量const;
9、rows:表統計信息,大致估算找出所需的記錄所需要讀取的行數,註意這個不是結果集里的行數。
10、Extra常見類型:
Using filesort:說明mysql會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取,mysql無法利用索引完成的排序稱為“文件排序”;
Using temporary:使用了臨時表保存中間結果,mysql在對查詢結果排序時使用臨時表,常見於order by和group by;
Using index:表示相應的select操作中使用了覆蓋索引(Covering Index),避免了訪問表的數據行,效率還可以,如果同時出現了Using Where,表示索引被用來執行索引鍵值的查找;如果沒有同時出現Using where,表示索引用來讀取數據而非執行查找動作,覆蓋索引的含義是所查詢的列是和建立的索引欄位和個數是一一對應的;
Using where: 表示使用了where過濾;
Using join buffer:表明使用了連接緩存,如果在查詢的時候有多次join,則可能會產生臨時表;
impossible where:表示where子句後面的條件總是false,不能用來獲取任何元素;
distinct:優化distinct操作,mysql一旦找到了第一個匹配的行之後就不再進行搜索了;
常用的SQL使用註意事項和一些建議:
1、儘量不要使用select *,而是使用具體的欄位,避免了不需要的列返回給客戶端調用,節約流量,可能會用到覆蓋索引,直接從索引中獲取要查詢的列數據,減少了回表查詢,調高查詢效率;
2、避免在where子句中使用OR來進行條件關聯,有可能造成索引失效,示例如下;
第一中寫法:
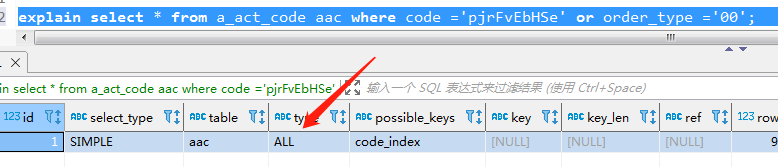
aac表中code列上面建立了索引,order_type列上沒有索引,where查詢條件後面採用了or連接過濾條件,導致了全表掃描,可以將以上面寫法改成下麵:
第二種寫法:

對於以上兩種寫法:第一中寫法,假設先走了code索引,但是order_type沒有索引還得來一遍全表掃描;而第二種寫法是分為三個步驟的:全表掃描+索引掃描+結果合併,直接一次全表掃描就行了。
3、儘量使用數值類型代替字元串;處理引擎在執行查詢和連接時候,如果是字元串類型則會逐個比較字元,要是數值類型的話直接比較一次就可以了,字元串的連接性能也會大大降低。
4、使用varchar替代char,varchar的存儲是按實際長度來存儲的,可以節省存儲空間,而char是按照定義長度來存儲的,不足補充空格;
5、應儘量避免在where子句中使用!=或<>操作符,這種情況可能會造成索引失效,經過sql優化器優化,執行引擎發現使用索引的代價比不走索引還要大,就會放棄使用索引直接走全表掃描;
6、在inner join 、left join、right join都滿足條件的狀況下,優先使用inner join;inner join內連接,只保留左右兩張表中都匹配的結果集;left join 左連接,以左表為主表,返回左表中的所有行,即使右表中沒有匹配的行;right join右連接,以右表為主表,返回右表中的所有數據,即使坐標中沒有匹配的行;如果是inner join等值連接,返回的行數比較小,所以效率較高;左右連接的話,按照“小表驅動大表的原則”,用小表作為主表;
7、按照上一條“小表驅動大表”的原則,在含有複雜子查詢的sql語句中,在滿足條件的情況下,應該將小表放在裡面層層過濾,縮小查詢的範圍;
8、分組過濾的時候,應該先過濾,再分組,調高效率;
9、執行delete或update語句,加個limit或者迴圈分批次刪除,降低誤刪數據的代價,避免長事務,數據量大的話,容易把cpu打滿,一次性刪除數據太多的話可能造成鎖表;
10、union會對篩選掉重覆的記錄,所以會在連接後對所產生的結果集先進行排序運算,然後在刪除重覆記錄返回,如果數據量比較大的情況下可能會使用磁碟排序,在union all也滿足條件的情況下,可以用union all替代union;
11、多條寫數據,建議採用批量提交減少事務提交的次數,提高性能;
12、關聯查詢的表連接不要太多,關聯表的個數越多,編譯的時間和開銷也越大,每次關聯在記憶體中都會產生一個臨時表;
13、索引並不是越多越好,索引雖然提高了查詢性能,但是會降低數據寫入的速度,並且索引的存儲是要占用空間的,索引也是排序的,排序是要花費時間的,insert和update操作可能會導致重建索引,如果數據量巨大,這筆消耗也是非常驚人的;
14、查詢時候在索引列上使用資料庫的內置函數會導致索引失效;
15、創建聯合索引,進行查詢的時候,必須滿足最左原則;
16、優化like查詢,進行模糊查詢的時候,應當使用右模糊查詢,全模糊和左模糊查詢會導致索引失效;
17、where後面的欄位,留意其數據類型的隱式轉換,查詢條件類型和資料庫列欄位不匹配的話,可能會造成數據類型的隱式轉換,造成索引失效;
18、索引不適合建在有大量重覆數據的欄位上,比如性別,排序欄位應創建索引,索引列的數據應該最夠的“散列”,這樣查詢效果可能會更好;
19、去重distinct過濾欄位要少,資料庫引擎對數據的比較、過濾是一個很耗費資源的操作;
20、儘量避使用游標;
21、表設計時候增加必要的註釋,說明欄位的用途。
好了,暫時先給本篇文章畫個句號,以後等想起來啥再慢慢補充吧,歡迎大神們批評指正,希望大神們不吝賜教,共同學習進步!
本文來自博客園,作者:一隻烤鴨朝北走,僅用於技術學習,所有資源都來源於網路,部分是轉發,部分是個人總結。歡迎共同學習和轉載,轉載請在醒目位置標明原文。如有侵權,請留言告知,及時撤除。轉載請註明原文鏈接:https://www.cnblogs.com/wha6239/p/16660969.html


