
上一篇文章詳細給大家介紹了標簽的設計與加工,在標簽生命周期流程中,標簽體系設計完成後,便進入標簽加工與上線運行階段,一般來說數據開發團隊會主導此過程,但我們需要關心以下幾個問題: ·標簽如何快速創建和實現標簽邏輯的線上化管理 ·業務人員怎麼參與到標簽建設流程中 ·百萬級別的標簽如何落表 一、加工方式 ...
上一篇文章詳細給大家介紹了標簽的設計與加工,在標簽生命周期流程中,標簽體系設計完成後,便進入標簽加工與上線運行階段,一般來說數據開發團隊會主導此過程,但我們需要關心以下幾個問題:
·標簽如何快速創建和實現標簽邏輯的線上化管理
·業務人員怎麼參與到標簽建設流程中
·百萬級別的標簽如何落表
一、加工方式:傳統VS線上
當企業無標簽系統時,一般由數據開發在離線數倉中完成標簽的加工和運行,運營或市場同學需要某個標簽需要通過產品經理向數據開發提需求,這個過程存在很多問題:
· 標簽資產不可見:標簽是存在於表裡的欄位,業務人員不清楚現在有多少標簽;標簽的加工邏輯與業務邏輯是否一致只能查看SQL代碼;新上線的標簽只有部分人知道,標簽價值散髮慢等
· 標簽資產不可管:加工好的標簽,有多少在真正被使用,有多少沒人用,完全黑盒,不用的標簽每天繼續運行浪費計算與存儲資源
· 標簽加工效率低:當業務人員需要某個簡單標簽時,也需要提交需求給數據開發,加工到上線基本需要2-3天流程
基於以上這些問題,標簽的線上化創建與管理顯得尤為重要,線上化主要包含以下內容:
· 標簽線上化加工
· 標簽線上化管理
· 標簽線上化更新
其讓標簽加工過程以及有哪些標簽變得透明,業務人員也可以參與進標簽建設的流程中。
二、各類型標簽加工
標簽類型的區分在此處便不再贅述了。在袋鼠雲智能標簽產品——「客戶數據洞察」中,我們按照標簽加工邏輯,將標簽分為以下類型,各類型標簽的加工層次如下圖:
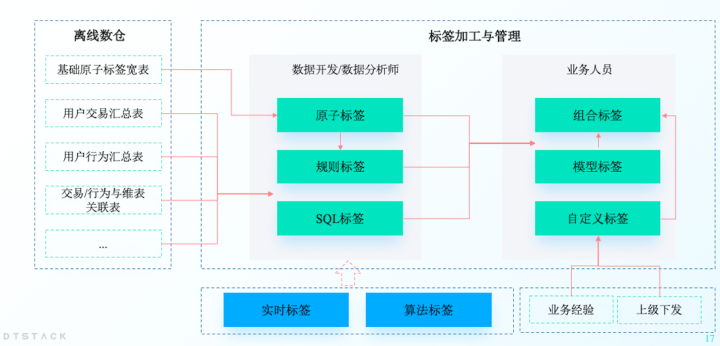
接下來,我們來看看具體各類型標簽的加工。
1、原子標簽
該類標簽由數據開發在數倉加工中完成,一般基於數倉DWD、DWS層的明細表與彙總表加工而來,處理邏輯較為複雜,同時維表中的一些欄位也可以作為原子標簽。這類標簽一般包含哪些內容呢?
● 建立用戶的標簽體系:
用戶維表中的用戶基礎屬性:性別、年齡、置業、會員等級、手機號、身份證號等信息,一般用戶系統會有該類信息。
● 基於交易表加工的交易指標
最近30天購買次數、最近30天交易金額、最近7天購買次數、最近7天交易金額。這部分標簽也建議放在數倉中實現,有以下幾點原因:
·因為其本身也是一個指標,除後續作為標簽進行畫像分析外,也常用於在數據門戶、BI報表中分析,可作為對外服務的指標放在ADS層中,並且市場上也會有專門指標管理的產品,來實現該指標的加工
· 這類標簽若屬於同一個統計維度(如都計算最近7天),數據開發可以在一個SQL片段中計算多個標簽,節約計算成本
· 若業務人員直接基於DWS層的輕度彙總表(每天彙總的交易次數、交易金額)、或DWD層的明細表(每條交易記錄一行數據)來加工最近30天購買次數這個標簽,需要針對對應的欄位進行求和,稍微涉及到一點SQL理解,有一些難度
故該類使用場景多、對於業務人員有計算難度,可在數倉中合併加工降低成本的標簽,可在數倉中作為原子標簽加工。
● 基於行為表加工的行為指標
可經過數倉加工成如下表格式,加工行為類的標簽,便於後續業務人員去衍生。
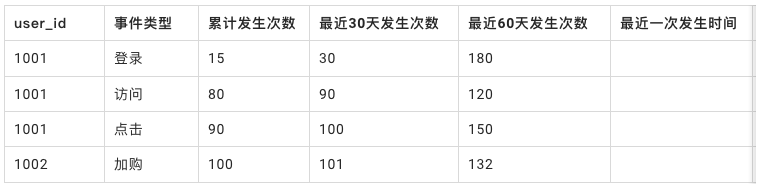
原子標簽在數倉加工好後,可導入到標簽系統中,進行線上化管理。
2、規則標簽
該類標簽配置可由數據開發或數據分析師來完成,可基於單張表或關聯表中的欄位進行線上化加工,可設置統計周期、數據過濾條件,其內置常用的聚合函數(求和、均值、計數、去重技術、最大值、最小值等)、操作符(大於、小於、區間、有值、無值、包含等),通過規則化的線上配置完成標簽加工。配置界面如以下:
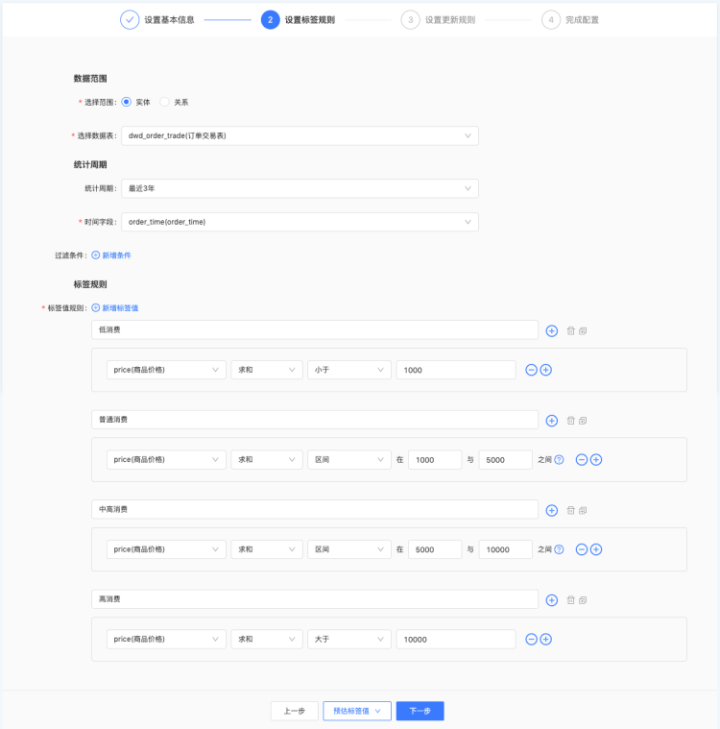
根據上面的描述,該類標簽可以將指標的類型的標簽在數倉或指標平臺加工好,導入至標簽平臺作為原子標簽,再基於這些原子標簽取操作符更好。但在實際場景中,基於不同考慮,有的客戶也會在標簽平臺直接加工此類型標簽,如以下場景:
· 數倉無對應的基礎標簽,但業務人員很著急需要該標簽某標簽,走正常的排期、數倉加工、測試,上線到使用基本2天以上了,基於這種情況可以通過該類標簽在標簽系統直接配置,5分鐘即可配置、更新完成,業務人員便可以使用了
· 客戶方想把標簽的加工邏輯線上化呈現、方便查找與追溯,通過可視化的方式線上配置
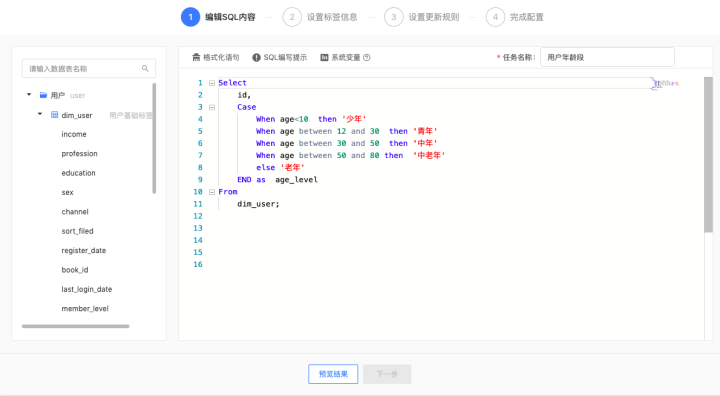
3、SQL標簽
SQL標簽主要由數據開發、數據分析師使用,主要解決通過規則標簽無法表達的邏輯,如用到排序函數、字元轉化函數、子查詢等內容,可以通過標準SQL語法靈活完成標簽加工。
4、模型標簽
模型標簽可由業務人員創建。系統集成常見的用戶分層RFM模型,用戶營銷AIPL模型、用戶生命周期模型,用戶輸入對應的指標值區間,便可定義對應的標簽值。
以RFM模型舉例,基於該模型生成“客戶價值”標簽。可基於最近一次購買時間、最近一年消費金額、最近一年消費頻率等幾個原子標簽,進行不同區間的取值,給用戶打上“重要價值客戶”、“重要發展客戶”、“重要發展客戶”、“重要輓留客戶”等。
5、組合標簽
模型標簽可由業務人員創建。基於已生成的原子、規則、SQL、模型標簽等,進行規則衍生,生成組合標簽。如組合標簽“高收入低購買”用戶,可通過“收入水平”衍生標簽,與“最近3年消費金額區間”衍生標簽組合加工,如下圖:
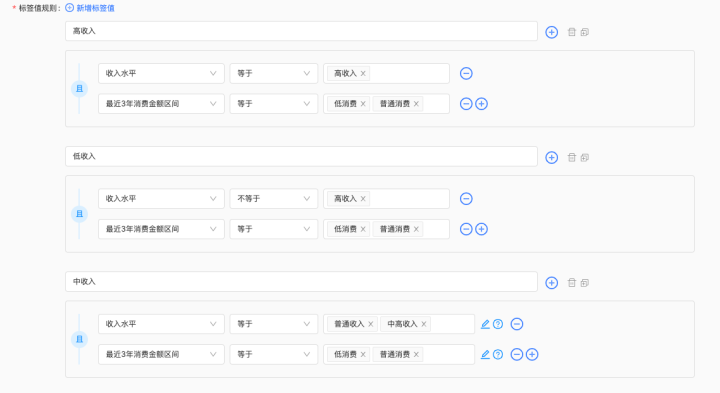
6、自定義標簽
自定義標簽可由業務人員創建。手動為某些用戶打上標簽,該類標簽手動導入,常見場景如下:
· 客服人員和用戶ID為1001的用戶溝通後,給該用戶打上”性格:溫和、有耐心”標簽
· 如監管機構提供的一些信貸黑名單用戶,該類標簽可直接導入進標簽系統,為用戶打上新的標簽
7、演算法標簽
演算法標簽由演算法開發同學創建,該類標簽可在演算法平臺完成,將算好的結果存儲至Hive表中,標簽系統可獲取演算法標簽的元數據,拿到演算法標簽的中文名、英文名,註冊至標簽系統中,在標簽系統中完成演算法標簽的標簽信息查看、標簽查詢等。
如利用機器學習模型加工預測類的演算法標簽,如根據用戶的特征,預測哪些用戶是否即將流失,流失的概率等,從而在用戶流失之前做一些措施來輓留。
8、實時標簽
實時標簽由數據開發同學創建,該類標簽可在流計算平臺完成,實時行為數據打入到kafka中,用FlinkSQL消費,再輸出到Kafka、或數據表中,下游直接訂閱或查詢。
三、標簽更新與落庫
標簽配置完成後,便需要進行標簽更新與落庫,即將標簽打到對象(如用戶)的身上,這樣業務同學就可以根據標簽圈選目標群組啦。在此處我們需要說明以下幾個問題:
1、技術選型
首先說明一下標簽加工的技術選型,在袋鼠雲智能標簽產品「客戶數據洞察」中我們用的 Trino(Presto)高性能分析引擎讀寫 Hive 表的方式,標簽表存儲在Hive中。主要有以下幾點原因:
· 隨著國家對數字化轉型的支持,從金融、政府到小企業都在建設數倉,進行數字化應用,在這個過程中,大多採用的是分散式的Hadoop系統作為計算存儲引擎(不論是開源Hadoop,還是發行版的CDH、TDH、FusionInsight等),Hive表便是最常用的存儲形式。標簽是基於數倉模型搭建出來的,與數倉用同一種存儲可以節省存儲資源以及不用兩種存儲之間進行數據交換
· 而用Trino(Presto)的原因是其首先是一個分析型引擎,讀寫速度均可;其次是其SQL語法完備、函數豐富、靈活,可以處理絕大多是業務場景的需求;並且支持跨庫同時讀取,如Trino可以同時取Hive與MySQL的數據進行數據處理
但沒有一種完美的技術選型,只能貼合企業自己的業務,選取最合適的技術。在這裡我們就不分析各種標簽的技術選型了。
2、落表方式
上面我們介紹了有各種類型的標簽,那麼標簽如何落表呢,大家看下麵這個圖:
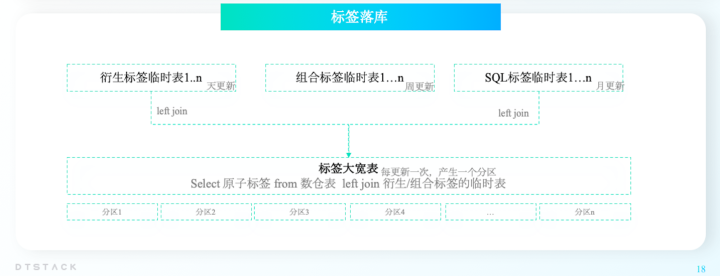
在業務場景中,存在有的標簽需要每天更新,如最近30天消費金額區間;而有的標簽周更新、月更新即可,更新頻率不高,如活動類型偏好。
這樣,便需要支持每個標簽有不同的更新頻率,但hive2.x版本不支持單列更新,為瞭解決該問題,我們將每個標簽先在臨時表存一下(就包含2列,1列用戶ID,1列標簽)該臨時表即建即用即刪,每個標簽只有一個臨時表(非分區表),每個標簽占用的占用不大,又能解決標簽更新周期不一致的問題。
但如果後續的標簽圈群、群組畫像分析,我們基於這些單獨表的去做聯合查詢,那效率會很低。
因為每個用營銷活動,我們需要5個標簽圈選出來一批人群,並查詢出這群人的性別、年齡、月消費、會員等級、是否活躍用戶等信息,加起來用到了10個標簽左右,會涉及到10個表的join操作,客戶集群資源不豐裕的情況,查詢速度慢。
所有我們便將多個臨時表通過聚合任務,將所有的臨時表join到一張標簽大寬表中,進行固化,這張表是一個分區表,可以每天存儲一份全量用戶標簽信息,當然可以自行設置該表的更新周期與保存多少個分區。
這樣,業務人員進行圈群和分析就可以一張表查詢數據,查詢效率大大提升。通過標簽跑批時間的消耗換取業務的查詢速度。
但會遇到有些企業標簽數量在500-1000個之間,用戶量在千萬、億級別,這樣的話,用一張表去存所有的標簽會遇到標簽大寬表跑批時間過長或跑不出來的情況,所以便需要分表,可以根據標簽數量分表。
綜上,以上加工存儲方式,有缺點的地方便是大寬表加工時,需要join多個臨時表,消耗記憶體,跑批時間長。
四、寫在最後的話
為解決該問題,袋鼠雲智能標簽產品「客戶數據洞察」在引入數據湖Iceberg進行標簽表的存儲,其可以實現單列更新,每個標簽可以單獨更新,這樣,便不需要那些臨時表了,解決加工效率的問題。
標簽加工與落庫是標簽體系完成後重要的步驟,本篇文章向大家分享了標簽加工與落庫過程中需要關註的註意點,講述了不同標簽的加工內容以及標簽的更新與落庫等內容。
歡迎大家留言與我們討論,也可以分享下自己見到的一些好的標簽加工方式,我們共同進步。
袋鼠雲開源框架釘釘技術交流qun(30537511),歡迎對大數據開源項目有興趣的同學加入交流最新技術信息,開源項目庫地址:https://github.com/DTStack

