
摘要: “一分鐘,我要這個人的全部信息”,霸道總裁拍了拍你,並提出這個要求。 本文分享自華為雲社區《大規模數據如何實現數據的高效追溯》,作者: DevAI。 “一分鐘,我要這個人的全部信息”,霸道總裁拍了拍你,並提出這個要求。秘書開始發力,找到了:姓名、年齡、聯繫方式、愛好,這些信息。不太夠?那就再 ...
摘要: “一分鐘,我要這個人的全部信息”,霸道總裁拍了拍你,並提出這個要求。
本文分享自華為雲社區《大規模數據如何實現數據的高效追溯》,作者: DevAI。
“一分鐘,我要這個人的全部信息”,霸道總裁拍了拍你,並提出這個要求。秘書開始發力,找到了:姓名、年齡、聯繫方式、愛好,這些信息。不太夠?那就再加上親朋好友信息,近期活動信息,更完整展現這個人。雖然是個段子,但也給與我們一些啟示:對象本身的信息可能不夠“全”,周邊關聯的數據也是對象信息的重要組成,這些關聯數據對在進行數據分析和挖掘時十分有用。
現實生活中關聯關係十分普遍,比如人的社交、商品生產和消費行為之間都是關聯關係。數據分析時,為了更好的利用關聯關係,常使用圖作為數據結構,使用圖結構保存數據的資料庫被稱為圖資料庫。傳統的關係型資料庫,以表格視角對數據進行呈現,可以方便的對數據進行查詢管理,而圖資料庫更關註節點和周邊節點的聯繫,是一種網狀結構,適用於追溯分析、社交網路分析、異構信息挖掘等等應用。華為雲提供的圖資料庫服務就是GES(Graph Engine Service)[1]。
基於圖資料庫可以做很多有趣的應用,數據追溯就是一個很常見的應用。數據追溯,就是把各環節產生的數據進行關聯與溯源。疫情中,查看商品的流通過程,檢查商品是否有可能有接觸傳染源。測試活動中,通過構建測試過程網路,分析測試活動的完備性,用於進行質量評估。這些都是追溯的典型使用場景。若以傳統關係型資料庫構建數據追溯,需要獨立構造和維護多個關係表,並實現多對多的關係網路,不易於理解複雜的業務邏輯,與此同時,也會伴隨著追溯查詢實現複雜和查詢緩慢的問題。
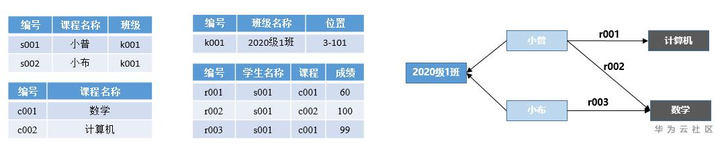
圖1 關係型資料庫和圖資料庫對比
用一個例子簡單說明圖資料庫在數據分析領域的優勢。圖1是一個簡單的選課系統,記錄了學生選課以及相應的課程信息。如右圖所示,我們根據圖資料庫的表達方式把這些信息轉化為一張圖。可以看出,圖可以更加直觀地表達選課和班級等關係,清楚地呈現實體之間的關係,更方便進行關聯分析。比如,根據圖我們可以很容易找到和小布一起上數學課的同學,也可以快速找到選課興趣相同的同學。通過圖資料庫可以很方便查詢到周邊節點信息,非常適用於追溯實現。那如何基於圖資料庫如何實現追溯服務?接下來我們將以華為雲GES為例,分析基於GES圖資料庫追溯服務的實現和優化。
什麼是圖
在圖資料庫中,圖由以下部分組成:
- 點:圖中的實體對象,在圖中表現為一個節點。例如,社會的人,流通的商品等都可以抽象為圖中的一個節點。
- 邊:圖中節點與節點之間的關係。如人與人的社會關係,商品的購買行為等。
- 屬性:用於描述圖中節點或者邊的屬性,比如編號、名稱等。聚類和分類分析中,權重是常常作為關係屬性,也就是邊的屬性。
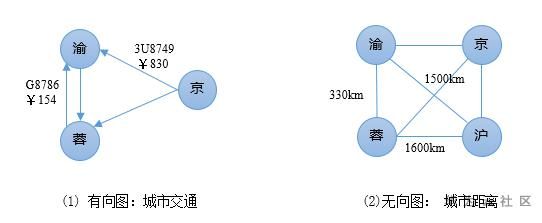
圖2 有向圖與無向圖
根據邊是否有方向,可以把圖分為有向圖和無向圖。對於有向圖來說,邊的起點和終點是確定的。圖2中,城市是一個節點,城市間的距離和城市之間交通方式為邊。城市交通就是一個有向圖,不同方向交通方式用不同的邊表示,而城市間距離是無向圖,因為距離和方向無關。GES使用時,需要將點和邊處理成不同的對象,點邊都需要定義需要的屬性。點主要就是包含實體的信息,而邊需要指定起點與終點。
定義GES圖
GES建立圖的步驟可以參考官方文檔[2]。主要就是對節點和邊進行定義,將數據處理為點和邊文件,最後導入GES中,可通過界面或API導入。處理無向圖時,即不區分邊的起點和終點,通常也會設定一個預設方向,即指定邊的起點和終點,這是為了處理和導入數據方便,在實際查詢中可以忽略這種方向設定。
在GES構建圖的過程中,定義點和邊以及相關屬性的文件被稱為元數據。點和邊的類型被稱為label,每個label可具有多個屬性,如上文提到的名稱、權重等,都可以作為點或邊的屬性。在GES中,label一旦定義並創建成功將不被允許修改,如果必須要修改label定義,就需要格式化圖並重新創建導入元數據文件到圖中。
節點通常是由現實中的實體抽象而來,GES節點屬性常用的數據結構包含了float、int、double、long、char、char array、date、bool、enum和string等。通常來說節點中,字元串類型的屬性較多,非字元串屬性可以根據數據類型進行選擇。字元串類型有兩個選擇:string和char array。char array有數據長度限制,通常為256,而string類型沒有長度限制。但是在GES中使用char array更有優勢,這是因為char array數據存放在記憶體中,string類型數據存放在硬碟中,因此char array查詢效率更高,這也是GES元數據定義需要註意的地方。在我們項目的場景中,節點的名稱和編號都是常用的查詢條件,綜合考慮屬性特征,如節點名稱較長而節點編號較短,最終名稱使用了string類型,而編號選擇了char array類型。
GES查詢優化
定義好節點信息後,可以在圖中進行查詢。GES使用的是Gremlin[3]進行查詢。Gremlin是一個開源的流式查詢語言,查詢實現靈活,不同圖資料庫對查詢語句的分解以及優化處理都不相同,因此,不同的寫法可能查詢效率可能不同。接下來我們就一種追溯查詢場景進行分析。
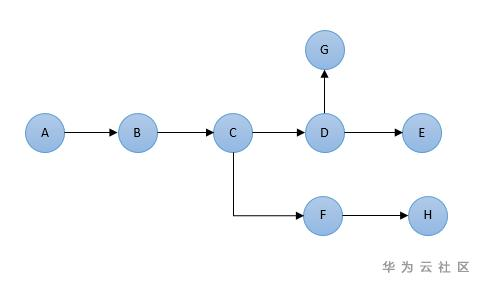
圖3 多分支查詢場景分析
如圖3所示,字母代表label,也就是一種節點類型。可以看到該場景具有較多查詢分支,按照圖中的節點要求,Gremlin查詢語句直接實現如下:
g.V(id).hasLabel('A').ouE().otherV().hasLabel('B').ouE().otherV().hasLabel('C').as('c').outE().otherV().hasLabel('F').outE().otherV().hasLabel('H').select('c').outE().otherV().hasLabel('D').as('d').outE().otherV().hasLabel('G').select('d').outE().otherV().hasLabel('H')
基於當前Gremlin,GES Gremlin server會將查詢分解為多個查詢原子操作,並由GES engine·執行。對於這種多跳的複雜查詢,會解析為較多的原子操作並頻繁交互,這會導致的查詢效率低下。對於這種場景,考慮使用optional語句進行查詢,效率會得到提升。查詢語句如下:
g.V(id).hasLabel('A').ouE().otherV().hasLabel('B').ouE().otherV().hasLabel('C').as('c').optional(outE().otherV().hasLabel('F').outE().otherV().hasLabel('H')).optional(select('c').outE().otherV().hasLabel('D').as('d').optional(outE().otherV().hasLabel('G')).optional(select('d').outE().otherV().hasLabel('H')))
optional在一定程度上可以降低分支的查詢範圍,從而提升查詢效率。在項目實際使用中,使用optional可以提升查詢性能1倍左右。但是optional不是所有場景都適用,Gremlin實現需要根據查詢場景、數據規模和數據特點進行優化處理,例如圖中節點的稀疏程度和分支的數量都是可以考慮優化的點。
在對GES查詢優化時,即使對Gremlin語句進行了優化,也有可能達不到期望的查詢性能。這是因為使用Gremlin時,處理查詢過程中Gremlin server解析後的原子操作可能會和GES engine頻繁交互,反而會降低查詢性能,而且針對Gremlin查詢優化處理範圍也有限。雖然Gremlin是圖資料庫通用的查詢腳本定義方式,但是各個廠家對於Gremlin腳本優化處理不同,因此更推薦使用GES原生API。原生API針對固定場景做了更多的優化,並且減少了Gremlin解析處理過程,因此性能更優,但同時也引入了通用性和效率之間的平衡問題,畢竟API沒有通用的定義實現。
下麵我們將介紹幾種常見的追溯查詢場景。這些場景都可以通過Gremlin查詢實現,但是如果通過使用GES系統API,可以獲取更好的查詢性能。
場景(1) 追溯某個節點前(後)n層節點
該查詢較為常見,主要用於查詢某個節點的父子節點,對於圖1 的場景可以找到班級的所有同學,該場景Gremlin實現如下:
g.V(id).repeat(out()).times(n).emit().path()
這種場景下,推薦使用GES演算法文檔中的k-hop演算法解決該問題,需要註意,這個演算法介面只會返回滿足查詢條件的子圖中的所有點,但沒有節點詳情和邊信息,如果需要節點詳情可以採用batch-query批量進行節點詳情查詢。如果需要邊信息,推薦場景(2) 使用的API。
場景(2) 按條件追溯某個節點之前(後)n層節點,節點篩選條件相同
g.V(id).repeat(outE().otherV().hasLabel('A')).times(n).emit().path()
這種場景下,推薦使用repeat-query方法。該方法可以快速實現某個起點前後n跳查詢,並且可以限定節點查詢條件,並且所有點的查詢過濾條件相同。在查詢中,如果不同的點需要使用不同的查詢條件進行過濾,可以先不指定點查詢條件,待返回查詢結果後再進行過濾。不指定點的查詢場景可以退化為場景(1),並且該API可以同時返回節點和邊的詳情。
場景(3) 按條件追溯某個節點之前(後)n層節點,不同節點篩選條件不同
圖3的例子就是一個這樣的場景,每層的查詢label不同。這種情況下,推薦使用filtered-query進行查詢,該方法需要詳細指定每個節點的過濾屬性,相當於將每個查詢條件都在參數中一一指定,實現完全滿足條件的查詢。項目中,相對於Gremlin 查詢,filtered-query的查詢性能可以提升10倍左右。
上述三個場景中repeat-query和k-hop具有更好的泛化能力,可以隨意指定查詢跳數n,需要設定的參數簡單。而filtered-query需要詳細指定查詢中每層節點的屬性,參數較為複雜,具體使用中可以根據業務需求進行選擇。
GES還提供了很多演算法,如Node2vec, subgraph2vec,GCN演算法,本文只介紹了基於GES進行節點快速查詢並提供追溯服務,後續也會考慮如何基於建立好的圖,進行一些數據節點融合,也可以進行相似度分析、質量評估和流程推薦等,更好地挖掘數據的價值。
文章來自PaaS技術創新Lab,PaaS技術創新Lab隸屬於華為雲,致力於綜合利用軟體分析、數據挖掘、機器學習等技術,為軟體研發人員提供下一代智能研發工具服務的核心引擎和智慧大腦。我們將聚焦軟體工程領域硬核能力,不斷構築研發利器,持續交付高價值商業特性!加入我們,一起開創研發新“境界”!
PaaS技術創新Lab主頁鏈接:https://www.huaweicloud.com/lab/paas/home.html
【參考資料】
- 華為雲GES產品介紹: https://support.huaweicloud.com/productdesc-ges/ges_04_0001.html
- 華為雲GES用戶指南: https://support.huaweicloud.com/usermanual-ges/ges_01_0009.html
- Gremlin官方文檔:https://tinkerpop.apache.org/docs/3.3.11/


