
1. 前言 筆者在 《從 Linux 內核角度看 IO 模型的演變》一文中曾對 Socket 文件在內核中的相關數據結構為大家做了詳盡的闡述。 又在此基礎之上介紹了針對 socket 文件的相關操作及其對應在內核中的處理流程: 並與 epoll 的工作機制進行了串聯: 通過這些內容的串聯介紹,我想大 ...
1. 前言
筆者在 《從 Linux 內核角度看 IO 模型的演變》一文中曾對 Socket 文件在內核中的相關數據結構為大家做了詳盡的闡述。
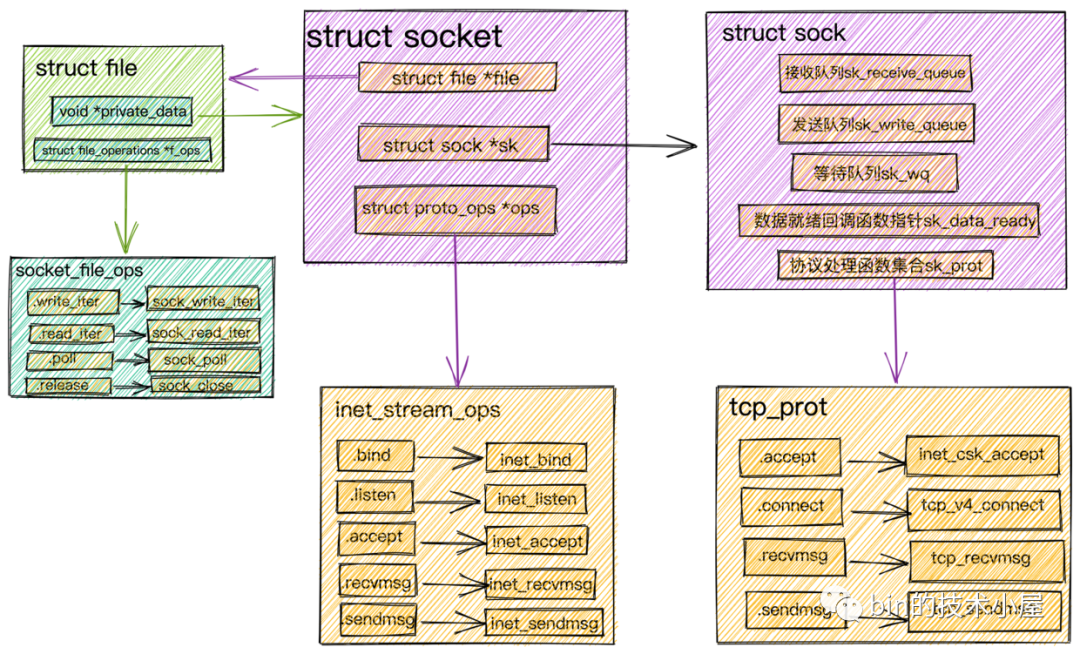
又在此基礎之上介紹了針對 socket 文件的相關操作及其對應在內核中的處理流程:
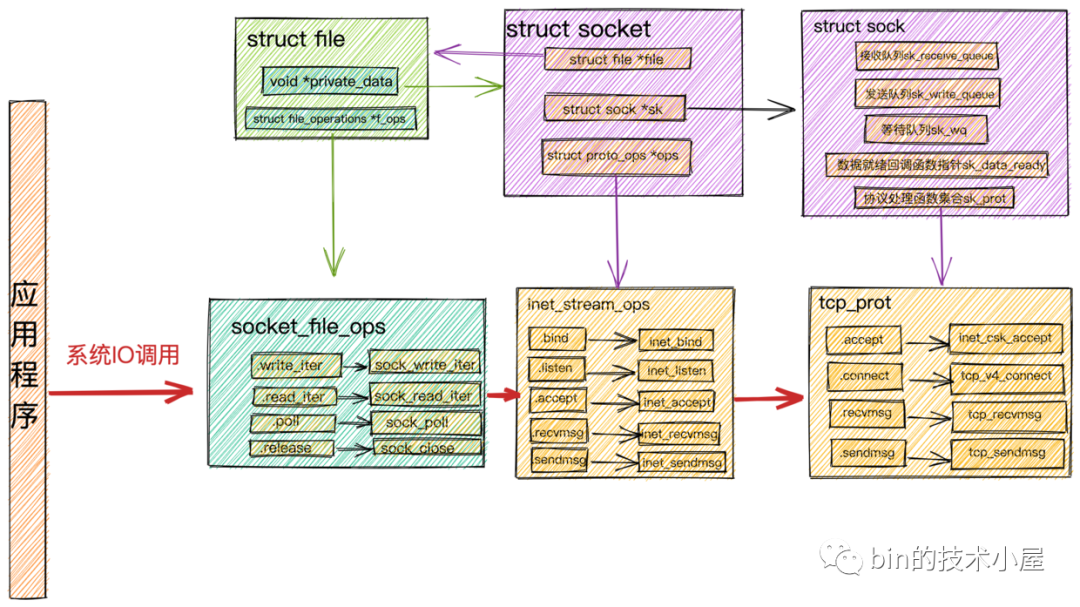
並與 epoll 的工作機制進行了串聯:
通過這些內容的串聯介紹,我想大家現在一定對 socket 文件非常熟悉了,在我們利用 socket 文件介面在與內核進行網路數據讀取,發送的相關交互的時候,不可避免的涉及到一個新的問題,就是我們如何在用戶空間設計一個位元組緩衝區來高效便捷的存儲管理這些需要和 socket 文件進行交互的網路數據。
於是筆者又在 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實現》 一文中帶大家從 JDK NIO Buffer 的頂層設計開始,詳細介紹了 NIO Buffer 中的頂層抽象設計以及行為定義,隨後我們選取了在網路應用程式中比較常用的 ByteBuffer 來詳細介紹了這個Buffer具體類型的實現,並以 HeapByteBuffer 為例說明瞭JDK NIO 在不同位元組序下的 ByteBuffer 實現。
現在我們已經熟悉了 socket 文件的相關操作及其在內核中的實現,但筆者覺得這還不夠,還是有必要在為大家介紹一下 JDK NIO 如何利用 ByteBuffer 對普通文件進行讀寫的相關原理及其實現,為大家徹底打通 Linux 文件操作相關知識的系統脈絡,於是就有了本文的內容。
下麵就讓我們從一個普通的 IO 讀寫操作開始聊起吧~~~

2. JDK NIO 讀取普通文件
我們先來看一個利用 NIO FileChannel 來讀寫普通文件的例子,由這個簡單的例子開始,慢慢地來一步一步深入本質。
JDK NIO 中的 FileChannel 比較特殊,它只能是阻塞的,不能設置非阻塞模式。FileChannel的讀寫方法均是線程安全的。
註意:下麵的例子並不是最佳實踐,之所以這裡引入 HeapByteBuffer 是為了將上篇文章的內容和本文銜接起來。事實上,對於 IO 的操作一般都會選擇 DirectByteBuffer ,關於 DirectByteBuffer 的相關內容筆者會在後面的文章中詳細為大家介紹。
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer = ByteBuffer.allocate(4096);
fileChannel.read(heapByteBuffer);
我們首先利用 RandomAccessFile 在內核中打開指定的文件 file-read-write.txt 並獲取到它的文件描述符 fd = 5000。
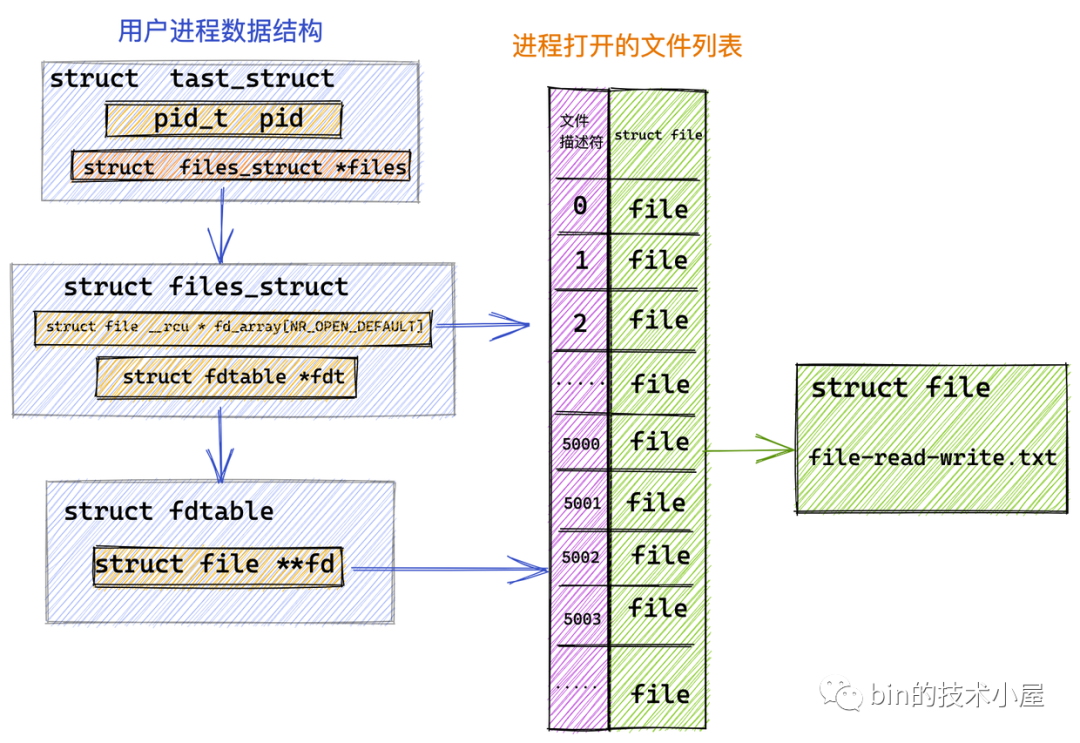
隨後我們在 JVM 堆中開闢一塊 4k 大小的虛擬記憶體 heapByteBuffer,用來讀取文件中的數據。
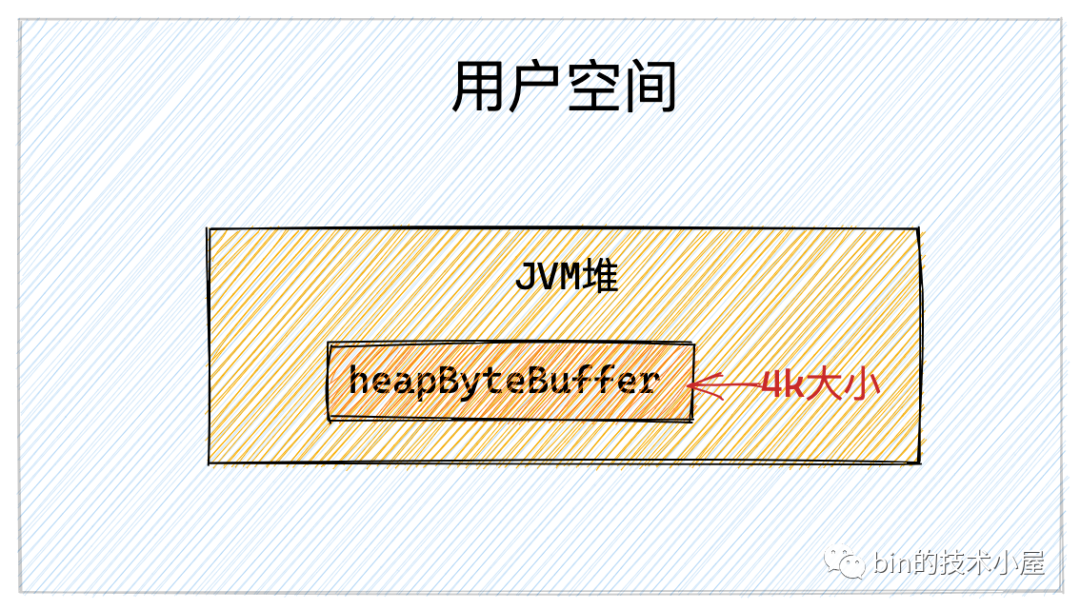
操作系統在管理記憶體的時候是將記憶體分為一頁一頁來管理的,每頁大小為 4k ,我們在操作記憶體的時候一定要記得進行頁對齊,也就是偏移位置以及讀取的記憶體大小需要按照 4k 進行對齊。具體為什麼?文章後邊會從內核角度詳細為大家介紹。
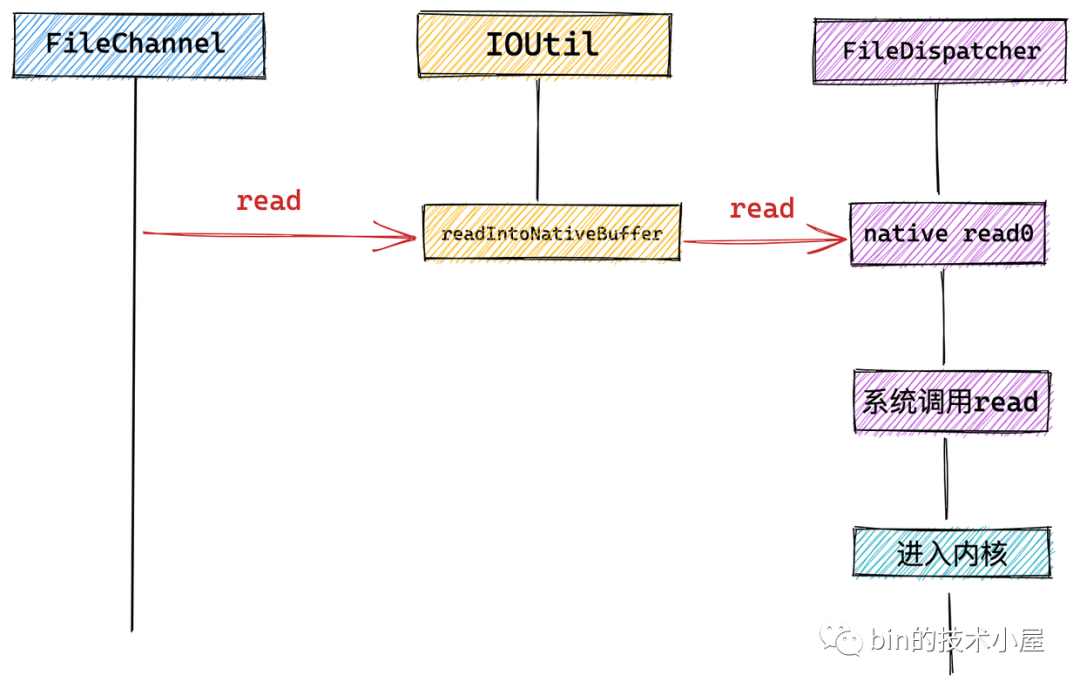
最後通過 FileChannel#read 方法觸發底層系統調用 read。進行文件讀取。
public class FileChannelImpl extends FileChannel {
// 前邊介紹打開的文件描述符 5000
private final FileDescriptor fd;
// NIO 中用它來觸發 native read 和 write 的系統調用
private final FileDispatcher nd;
// 讀寫文件時加鎖,前邊介紹 FileChannel 的讀寫方法均是線程安全的
private final Object positionLock = new Object();
public int read(ByteBuffer dst) throws IOException {
synchronized (positionLock) {
.......... 省略 .......
try {
.......... 省略 .......
do {
n = IOUtil.read(fd, dst, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
return IOStatus.normalize(n);
} finally {
.......... 省略 .......
}
}
}
}
我們看到在 FileChannel 中會調用 IOUtil 的 read 方法,NIO 中的所有 IO 操作全部封裝在 IOUtil 類中。
而 NIO 中的 SocketChannel 以及這裡介紹的 FileChannel 底層依賴的系統調用可能不同,這裡會通過 NativeDispatcher 對具體 Channel 操作實現分發,調用具體的系統調用。對於 FileChannel 來說 NativeDispatcher 的實現類為 FileDispatcher。對於 SocketChannel 來說 NativeDispatcher 的實現類為 SocketDispatcher。
下麵我們進入 IOUtil 裡面來一探究竟~~
public class IOUtil {
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
.......... 省略 .......
.... 創建一個臨時的directByteBuffer....
try {
int n = readIntoNativeBuffer(fd, directByteBuffer, position, nd);
.......... 省略 .......
.... 將directByteBuffer中讀取到的內容再次拷貝到heapByteBuffer中給用戶返回....
return n;
} finally {
.......... 省略 .......
}
}
private static int readIntoNativeBuffer(FileDescriptor fd, ByteBuffer bb,
long position, NativeDispatcher nd)
throws IOException
{
int pos = bb.position();
int lim = bb.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
.......... 省略 .......
if (position != -1) {
.......... 省略 .......
} else {
n = nd.read(fd, ((DirectBuffer)bb).address() + pos, rem);
}
if (n > 0)
bb.position(pos + n);
return n;
}
}
我們看到 FileChannel 的 read 方法最終會調用到 NativeDispatcher 的 read 方法。前邊我們介紹了這裡的 NativeDispatcher 就是 FileDispatcher 在 NIO 中的實現類為 FileDispatcherImpl,用來觸發 native 方法執行底層系統調用。
class FileDispatcherImpl extends FileDispatcher {
int read(FileDescriptor fd, long address, int len) throws IOException {
return read0(fd, address, len);
}
static native int read0(FileDescriptor fd, long address, int len)
throws IOException;
}
最終在 FileDispatcherImpl 類中觸發了 native 方法 read0 的調用,我們繼續到 FileDispatcherImpl.c 文件中去查看 native 方法的實現。
// FileDispatcherImpl.c 文件
JNIEXPORT jint JNICALL Java_sun_nio_ch_FileDispatcherImpl_read0(JNIEnv *env, jclass clazz,
jobject fdo, jlong address, jint len)
{
jint fd = fdval(env, fdo);
void *buf = (void *)jlong_to_ptr(address);
// 發起 read 系統調用進入內核
return convertReturnVal(env, read(fd, buf, len), JNI_TRUE);
}
系統調用 read(fd, buf, len) 最終是在 native 方法 read0 中被觸發的。下麵是系統調用 read 在內核中的定義。
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count){
...... 省略 ......
}
這樣一來我們就從 JDK NIO 這一層逐步來到了用戶空間與內核空間的邊界處 --- OS 系統調用 read 這裡,馬上就要進入內核了。
下麵我們就來看一下當系統調用 read 發起之後,用戶進程在內核態具體做了哪些事情?
3. 從內核角度探秘文件讀取本質
內核將文件的 IO 操作根據是否使用記憶體(頁高速緩存 page cache)做磁碟熱點數據的緩存,將文件 IO 分為:Buffered IO 和 Direct IO 兩種類型。
進程在通過系統調用 open() 打開文件的時候,可以通過將參數 flags 賦值為 O_DIRECT 來指定文件操作為 Direct IO。預設情況下為 Buffered IO。
int open(const char *pathname, int flags, mode_t mode);
而 Java 在 JDK 10 之前一直是不支持 Direct IO 的,到了 JDK 10 才開始支持 Direct IO。但是在 JDK 10 之前我們可以使用第三方的 Direct IO 框架 Jaydio 來通過 Direct IO 的方式對文件進行讀寫操作。
Jaydio GitHub :https://github.com/smacke/jaydio
下麵筆者就帶大家從內核角度深度剖析下這兩種 IO 類型各自的特點:
3.1 Buffered IO
大部分文件系統預設的文件 IO 類型為 Buffered IO,當進程進行文件讀取時,內核會首先檢查文件對應的頁高速緩存 page cache 中是否已經緩存了文件數據,如果有則直接返回,如果沒有才會去磁碟中去讀取文件數據,而且還會根據非常精妙的預讀演算法來預先讀取後續若幹文件數據到 page cache 中。這樣等進程下一次順序讀取文件時,想要的數據已經預讀進 page cache 中了,進程直接返回,不用再到磁碟中去龜速讀取了,這樣一來就極大地提高了 IO 性能。
比如一些著名的消息隊列中間件 Kafka , RocketMq 對消息日誌文件進行順序讀取的時候,訪問速度接近於記憶體。這就是 Buffered IO 中頁高速緩存 page cache 的功勞。在本文的後面,筆者會為大家詳細的介紹這一部分內容。
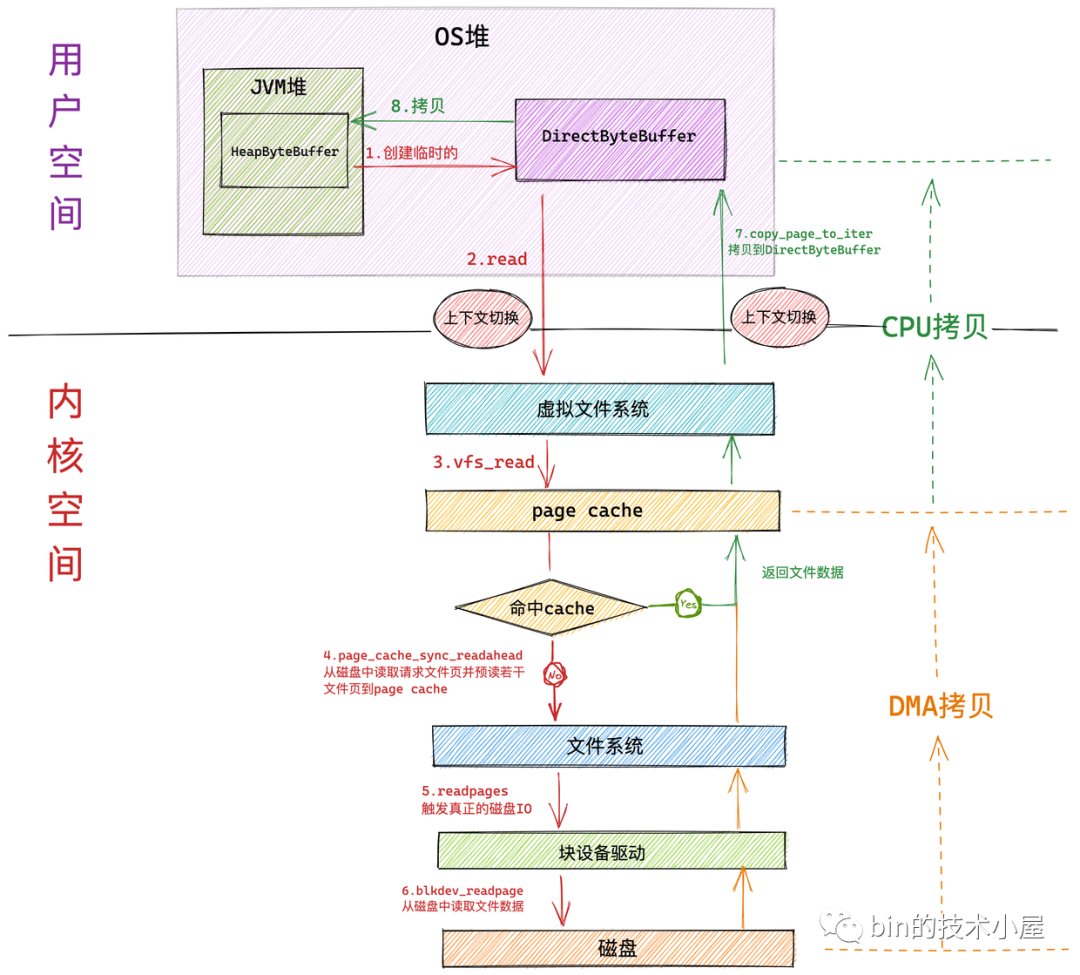
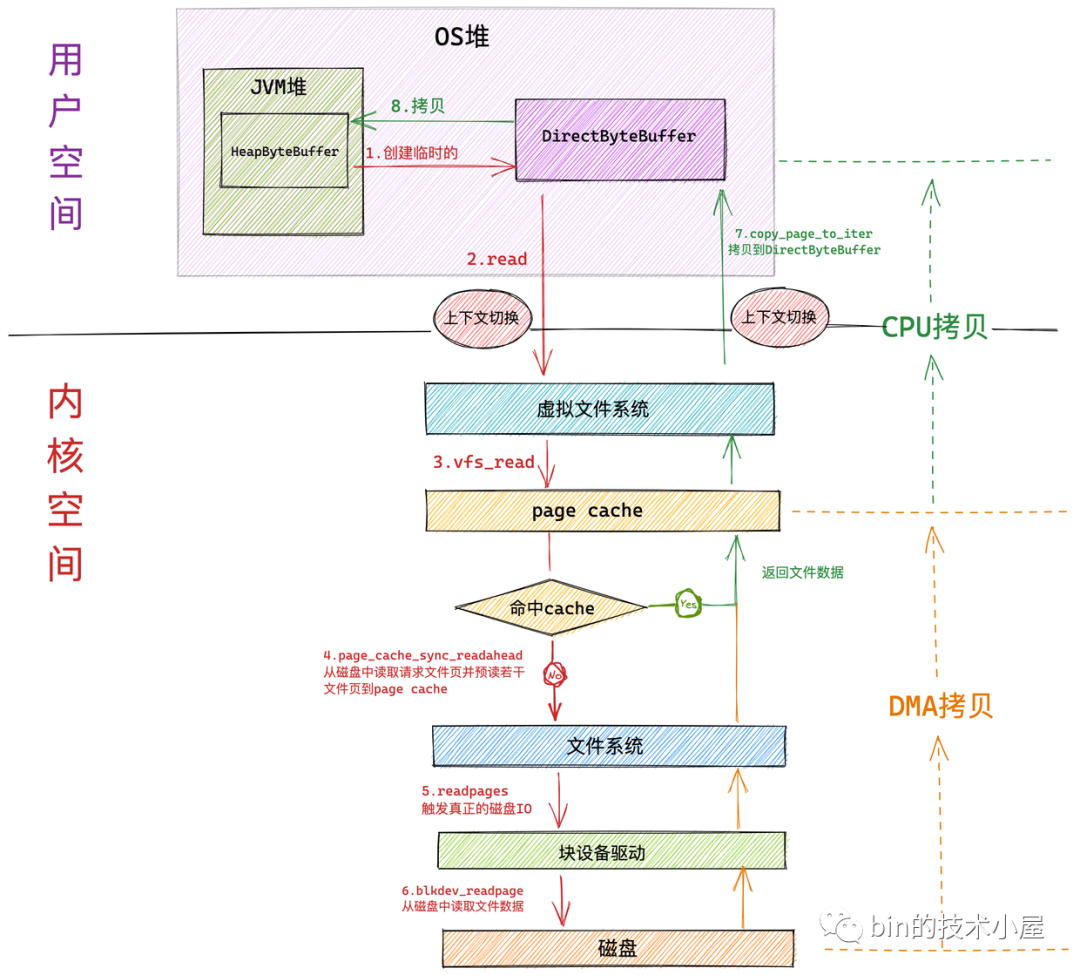
如果我們使用在上篇文章 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實現》 中介紹的 HeapByteBuffer 來接收 NIO 讀取文件數據的時候,整個文件讀取的過程分為如下幾個步驟:
- NIO 首先會將創建一個臨時的 DirectByteBuffer 用於臨時接收文件數據。
具體為什麼會創建一個臨時的 DirectByteBuffer 來接收數據以及關於 DirectByteBuffer 的原理筆者會在後面的文章中為大家詳細介紹。這裡大家可以把它簡單看成在 OS 堆中的一塊虛擬記憶體地址。
-
隨後 NIO 會在用戶態調用系統調用 read 向內核發起文件讀取的請求。此時發生第一次上下文切換。
-
用戶進程隨即轉到內核態運行,進入虛擬文件系統層,在這一層內核首先會查看讀取文件對應的頁高速緩存 page cache 中是否含有請求的文件數據,如果有直接返回,避免一次磁碟 IO。並根據內核預讀演算法從磁碟中非同步預讀若幹文件數據到 page cache 中(文件順序讀取高性能的關鍵所在)。
在內核中,一個文件對應一個 page cache 結構,註意:這個 page cache 在記憶體中只會有一份。
-
如果進程請求數據不在 page cache 中,則會進入文件系統層,在這一層調用塊設備驅動程式觸發真正的磁碟 IO。並根據內核預讀演算法同步預讀若幹文件數據。請求的文件數據和預讀的文件數據將被一起填充到 page cache 中。
-
在塊設備驅動層完成真正的磁碟 IO。在這一層會從磁碟中讀取進程請求的文件數據以及內核預讀的文件數據。
-
磁碟控制器 DMA 將從磁碟中讀取的數據拷貝到頁高速緩存 page cache 中。發生第一次數據拷貝。
-
隨後 CPU 將 page cache 中的數據拷貝到 NIO 在用戶空間臨時創建的緩衝區 DirectByteBuffer 中,發生第二次數據拷貝。
-
最後系統調用 read 返回。進程從內核態切換回用戶態。發生第二次上下文切換。
-
NIO 將 DirectByteBuffer 中臨時存放的文件數據拷貝到 JVM 堆中的 HeapBytebuffer 中。發生第三次數據拷貝。
我們看到如果使用 HeapByteBuffer 進行 NIO 文件讀取的整個過程中,一共發生了 兩次上下文切換和三次數據拷貝,如果請求的數據命中 page cache 則發生兩次數據拷貝省去了一次磁碟的 DMA 拷貝。
3.2 Direct IO
在上一小節中,筆者介紹了 Buffered IO 的諸多好處,尤其是在進程對文件進行順序讀取的時候,訪問性能接近於記憶體。
但是有些情況,我們並不需要 page cache。比如一些高性能的資料庫應用程式,它們在用戶空間自己實現了一套高效的高速緩存機制,以充分挖掘對資料庫獨特的查詢訪問性能。所以這些資料庫應用程式並不希望內核中的 page cache起作用。否則內核會同時處理 page cache 以及預讀相關操作的指令,會使得性能降低。
另外還有一種情況是,當我們在隨機讀取文件的時候,也不希望內核使用 page cache。因為這樣違反了程式局部性原理,當我們隨機讀取文件的時候,內核預讀進 page cache 中的數據將很久不會再次得到訪問,白白浪費 page cache 空間不說,還額外增加了預讀的磁碟 IO。
基於以上兩點原因,我們很自然的希望內核能夠提供一種機制可以繞過 page cache 直接對磁碟進行讀寫操作。這種機制就是本小節要為大家介紹的 Direct IO。
下麵是內核採用 Direct IO 讀取文件的工作流程:
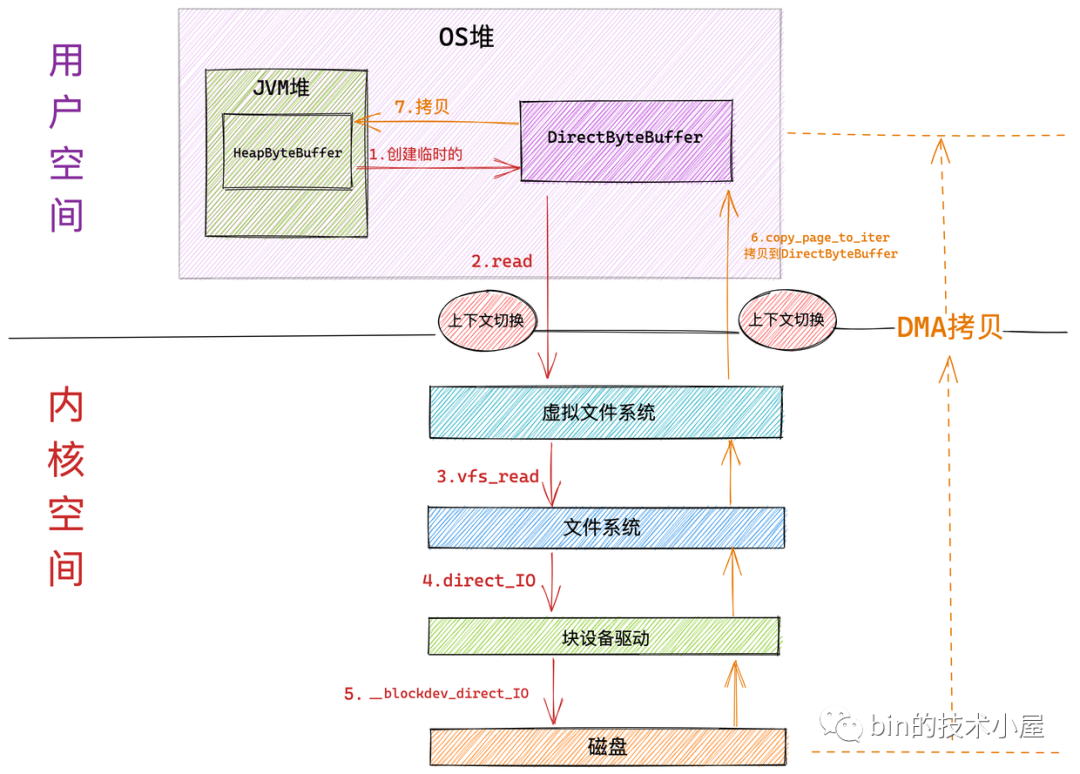
Direct IO 和 Buffered IO 在進入內核虛擬文件系統層之前的流程全部都是一樣的。區別就是進入到虛擬文件系統層之後,Direct IO 會繞過 page cache 直接來到文件系統層通過 direct_io 調用來到塊驅動設備層,在塊設備驅動層調用 __blockdev_direct_IO 對磁碟內容直接進行讀寫。
-
和 Buffered IO 一樣,在系統調用 read 進入內核以及 Direct IO 完成從內核返回的時候各自會發生一次上下文切換。共兩次上下文切換
-
磁碟控制器 DMA 從磁碟中讀取數據後直接拷貝到用戶空間緩衝區 DirectByteBuffer 中。只發生一次 DMA 拷貝
-
隨後 NIO 將 DirectByteBuffer 中臨時存放的數據拷貝到 JVM 堆 HeapByteBuffer 中。發生第二次數據拷貝。
-
註意塊設備驅動層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送數據完成之後才會返回,這裡的傳送指的是直接從磁碟拷貝到用戶空間緩衝區中,當 Direct IO 模式下的 read() 或者 write() 系統調用返回之後,進程就可以安全放心地去讀取用戶緩衝區中的數據了。
從整個 Direct IO 的過程中我們看到,一共發生了兩次上下文的切換,兩次的數據拷貝。
4. Talk is cheap ! show you the code
下麵是系統調用 read 在內核中的完整定義:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count) {
// 根據文件描述符獲取文件對應的 struct file結構
struct fd f = fdget_pos(fd);
.....
// 獲取當前文件的讀取位置 offset
loff_t pos = file_pos_read(f.file);
// 進入虛擬文件系統層,執行具體的文件操作
ret = vfs_read(f.file, buf, count, &pos);
......
}
首先會根據文件描述符 fd 通過 fdget_pos 方法獲取 struct fd 結構,進而可以獲取到文件的 struct file 結構。
struct fd {
struct file *file;
int need_put;
};
file_pos_read 獲取當前文件的讀取位置 offset,並通過 vfs_read 進入虛擬文件系統層。
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
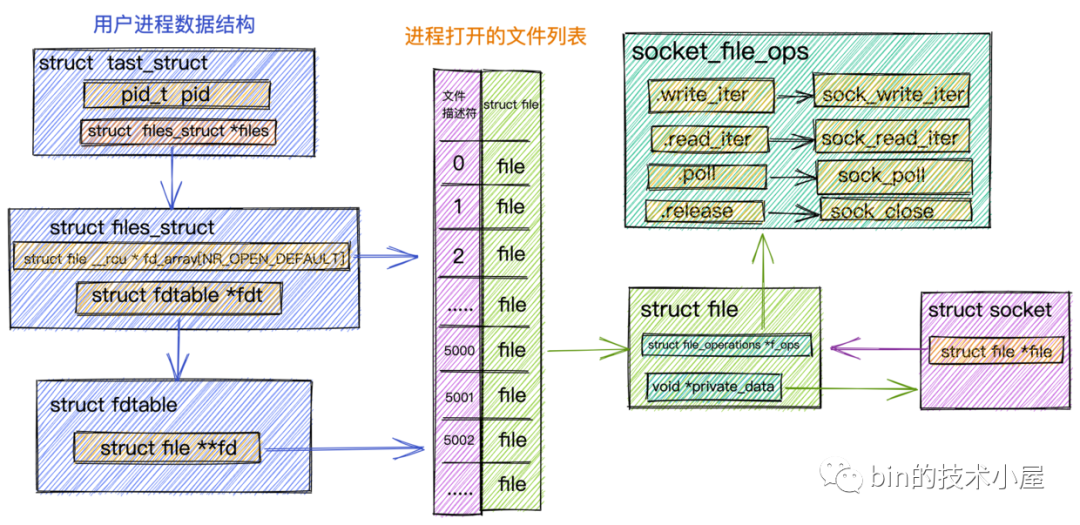
這裡我們看到內核對文件的操作全部定義在 struct file 結構中的 f_op 欄位中。
struct file {
const struct file_operations *f_op;
}
對於 Java 程式員來說,file_operations 大家可以把它當做內核針對文件相關操作定義的一個公共介面(其實就是一個函數指針),它只是一個介面。具體的實現根據不同的文件類型有所不同。
比如我們在《聊聊Netty那些事兒之從內核角度看IO模型》一文中詳細介紹過的 Socket 文件。針對 Socket 文件類型,這裡的 file_operations 指向的是 socket_file_ops。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
而本小節中我們討論的是對普通文件的操作,針對普通文件的操作定義在具體的文件系統中,這裡我們以 Linux 中最為常見的 ext4 文件系統為例說明:
在 ext4 文件系統中管理的文件對應的 file_operations 指向 ext4_file_operations,專門用於操作 ext4 文件系統中的文件。
const struct file_operations ext4_file_operations = {
......省略........
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......省略.........
}
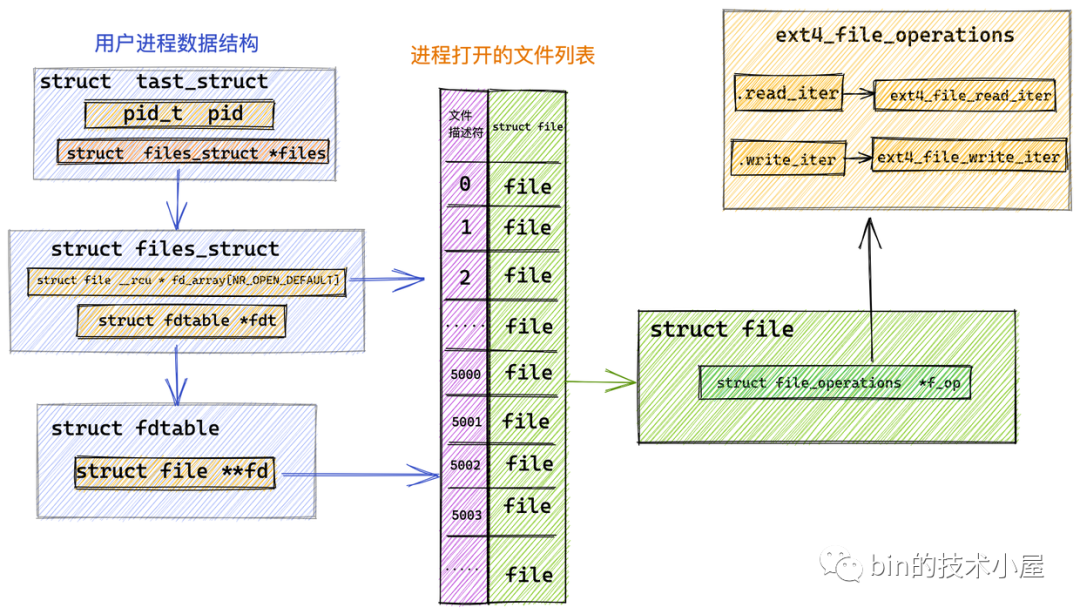
從圖中我們可以看到 ext4 文件系統定義的相關文件操作 ext4_file_operations 並未定義 .read 函數指針。而是定義了 .read_iter 函數指針,指向 ext4_file_read_iter 函數。
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
所以在虛擬文件系統 VFS 中,__vfs_read 調用的是 new_sync_read 方法,在該方法中會對系統調用傳進來的參數進行重新封裝。比如:
-
struct file *filp : 要讀取文件的 struct file 結構。
-
char __user *buf :用戶空間的 Buffer,這裡指的我們例子中 NIO 創建的臨時 DirectByteBuffer。
-
size_t count :進行讀取的位元組數。也就是我們傳入的用戶態緩衝區 DirectByteBuffer 剩餘可容納的容量大小。
-
loff_t *pos :文件當前讀取位置偏移 offset。
將這些參數重新封裝到 struct iovec 和 struct kiocb 結構體中。
ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
// 將 DirectByteBuffer 以及要讀取的位元組數封裝進 iovec 結構體中
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
// 利用文件 struct file 初始化 kiocb 結構體
init_sync_kiocb(&kiocb, filp);
// 設置文件讀取偏移
kiocb.ki_pos = *ppos;
// 讀取文件位元組數
kiocb.ki_nbytes = len;
// 初始化 iov_iter 結構
iov_iter_init(&iter, READ, &iov, 1, len);
// 最終調用 ext4_file_read_iter
ret = filp->f_op->read_iter(&kiocb, &iter);
.......省略......
return ret;
}
struct iovec 結構體主要用來封裝用來接收文件數據用的用戶緩存區相關的信息:
struct iovec
{
void __user *iov_base; // 用戶空間緩存區地址 這裡是 DirectByteBuffer 的地址
__kernel_size_t iov_len; // 緩衝區長度
}
但是內核中一般會使用 struct iov_iter 結構體對 struct iovec 進行包裝,iov_iter 中可以包含多個 iovec。這一點從 struct iov_iter 結構體的命名關鍵字 iter 上可以看得出來。
struct iov_iter {
......省略.....
const struct iovec *iov;
}
之所以使用 struct iov_iter 結構體來包裝 struct iovec 是為了相容 readv() 系統調用,它允許用戶使用多個用戶緩存區去讀取文件中的數據。JDK NIO Channel 支持的 scatter 操作底層原理就是 readv 系統調用。
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer1 = ByteBuffer.allocate(4096);
ByteBuffer heapByteBuffer2 = ByteBuffer.allocate(4096);
ByteBuffer[] scatter = { heapByteBuffer1, heapByteBuffer2 };
fileChannel.read(scatter);
struct kiocb 結構體則是用來封裝文件 IO 相關操作的狀態和進度信息:
struct kiocb {
struct file *ki_filp; // 要讀取的文件 struct file 結構
loff_t ki_pos; // 文件讀取位置偏移,表示文件處理進度
void (*ki_complete)(struct kiocb *iocb, long ret); // IO完成回調
int ki_flags; // IO類型,比如是 Direct IO 還是 Buffered IO
........省略.......
};
當 struct iovec 和 struct kiocb 在 new_sync_read 方法中被初始化好之後,最終通過 file_operations 中定義的函數指針 .read_iter 調用到 ext4_file_read_iter 方法中,從而進入 ext4 文件系統執行具體的讀取操作。
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
........省略........
return generic_file_read_iter(iocb, to);
}
ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
........省略........
if (iocb->ki_flags & IOCB_DIRECT) {
........ Direct IO ........
// 獲取 page cache
struct address_space *mapping = file->f_mapping;
........省略........
// 繞過 page cache 直接從磁碟中讀取數據
retval = mapping->a_ops->direct_IO(iocb, iter);
}
........ Buffered IO ........
// 從 page cache 中讀取數據
retval = generic_file_buffered_read(iocb, iter, retval);
}
generic_file_read_iter 會根據 struct kiocb 中的 ki_flags 屬性判斷文件 IO 操作是 Direct IO 還是 Buffered IO。
4.1 Direct IO
我們可以通過 open 系統調用在打開文件的時候指定相關 IO 操作的模式是 Direct IO 還是 Buffered IO:
int open(const char *pathname, int flags, mode_t mode);
-
char *pathname : 指定要文件的路徑。
-
int flags :指定文件的訪問模式。比如:O_RDONLY(只讀),O_WRONLY,(只寫), O_RDWR(讀寫),O_DIRECT(Direct IO)。預設為 Buffered IO。
-
mode_t mode :可選,指定打開文件的許可權
而 Java 在 JDK 10 之前一直是不支持 Direct IO,到了 JDK 10 才開始支持 Direct IO。
Path path = Paths.get("file-read-write.txt");
FileChannel fc = FileChannel.open(p, ExtendedOpenOption.DIRECT);
如果在文件打開的時候,我們設置了 Direct IO 模式,那麼以後在對文件進行讀取的過程中,內核將會繞過 page cache,直接從磁碟中讀取數據到用戶空間緩衝區 DirectByteBuffer 中。這樣就可以避免一次數據從內核 page cache 到用戶空間緩衝區的拷貝。
當應用程式期望使用自定義的緩存演算法從而可以在用戶空間實現更加高效更加可控的緩存邏輯時(比如資料庫等應用程式),這時應該使用直接 Direct IO。在隨機讀取,隨機寫入的場景中也是比較適合用 Direct IO。
操作系統進程在接下來使用 read() 或者 write() 系統調用去讀寫文件的時候使用的是 Direct IO 方式,所傳輸的數據均不經過文件對應的高速緩存 page cache (這裡就是網上常說的內核緩衝區)。
我們都知道操作系統是將記憶體分為一頁一頁的單位進行組織管理的,每頁大小 4K ,那麼同樣文件中的數據在磁碟中的組織形式也是按照一塊一塊的單位來組織管理的,每塊大小也是 4K ,所以我們在使用 Direct IO 讀寫數據時必須要按照文件在磁碟中的組織單位進行磁碟塊大小對齊,緩衝區的大小也必須是磁碟塊大小的整數倍。具體表現在如下幾點:
-
文件的讀寫位置偏移需要按照磁碟塊大小對齊。
-
用戶緩衝區 DirectByteBuffer 起始地址需要按照磁碟塊大小對齊。
-
使用 Direct IO 進行數據讀寫時,讀寫的數據大小需要按照磁碟塊大小進行對齊。這裡指 DirectByteBuffer 中剩餘數據的大小。
當我們採用 Direct IO 直接讀取磁碟中的文件數據時,內核會從 struct file 結構中獲取到該文件在記憶體中的 page cache。而我們多次提到的這個 page cache 在內核中的數據結構就是 struct address_space 。我們可以根據 file->f_mapping 獲取。
struct file {
// page cache
struct address_space *f_mapping;
}
和前面我們介紹的 struct file 結構中的 file_operations 一樣,內核中將 page cache 相關的操作全部定義在 struct address_space_operations 結構中。這裡和前邊介紹的 file_operations 的作用是一樣的,只是內核針對 page cache 操作定義的一個公共介面。
struct address_space {
const struct address_space_operations *a_ops;
}
具體的實現會根據文件系統的不同而不同,這裡我們還是以 ext4 文件系統為例:
static const struct address_space_operations ext4_aops = {
.direct_IO = ext4_direct_IO,
};
內核通過 struct address_space_operations 結構中定義的 .direct_IO 函數指針,具體函數為 ext4_direct_IO 來繞過 page cache 直接對磁碟進行讀寫。
採用 Direct IO 的方式對文件的讀寫操作全部是在 ext4_direct_IO 這一個函數中完成的。
由於磁碟文件中的數據是按照塊為單位來組織管理的,所以文件系統其實就是一個塊設備,通過 ext4_direct_IO 繞過 page cache 直接來到了文件系統的塊設備驅動層,最終在塊設備驅動層調用 __blockdev_direct_IO 來完成磁碟的讀寫操作。
註意:塊設備驅動層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送數據完成之後才會返回,這裡的傳送指的是直接從磁碟拷貝到用戶空間緩衝區中,當 Direct IO 模式下的 read() 或者 write() 系統調用返回之後,進程就可以安全放心地去讀取用戶緩衝區中的數據了。
4.2 Buffered IO
Buffered IO 相關的讀取操作封裝在 generic_file_buffered_read 函數中,其核心邏輯如下:
-
由於文件在磁碟中是以塊為單位組織管理的,每塊大小為 4k,記憶體是按照頁為單位組織管理的,每頁大小也是 4k。文件中的塊數據被緩存在 page cache 中的緩存頁中。所以首先通過 find_get_page 方法查找我們要讀取的文件數據是否已經緩存在了 page cache 中。
-
如果 page cache 中不存在文件數據的緩存頁,就需要通過 page_cache_sync_readahead 方法從磁碟中讀取數據並緩存到 page cache 中。於此同時還需要同步預讀若幹相鄰的數據塊到 page cache 中。這樣在下一次順序讀取的時候,直接就可以從 page cache 中讀取了。
-
如果此次讀取的文件數據已經存在於 page cache 中了,就需要調用 PageReadahead 來判斷是否需要進一步預讀數據到緩存頁中。如果是,則從磁碟中非同步預讀若幹頁到 page cache 中。具體預讀多少頁是根據內核相關預讀演算法來動態調整的。
-
經過上面幾個流程,此時文件數據已經存在於 page cache 中的緩存頁中了,最後內核調用 copy_page_to_iter 方法將 page cache 中的數據拷貝到用戶空間緩衝區 DirectByteBuffer 中。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
// 獲取文件在內核中對應的 struct file 結構
struct file *filp = iocb->ki_filp;
// 獲取文件對應的 page cache
struct address_space *mapping = filp->f_mapping;
// 獲取文件的 inode
struct inode *inode = mapping->host;
...........省略...........
// 開始 Buffered IO 讀取邏輯
for (;;) {
// 用於從 page cache 中獲取緩存的文件數據 page
struct page *page;
// 根據文件讀取偏移計算出 第一個位元組所在物理頁的索引
pgoff_t index;
// 根據文件讀取偏移計算出 第一個位元組所在物理頁中的頁內偏移
unsigned long offset;
// 在 page cache 中查找是否有讀取數據在記憶體中的緩存頁
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT) {
....... 如果設置的是非同步IO,則直接返回 -EAGAIN ......
}
// 要讀取的文件數據在 page cache 中沒有對應的緩存頁
// 則從磁碟中讀取文件數據,並同步預讀若幹相鄰的數據塊到 page cache中
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
// 再一次觸發緩存頁的查找,這一次就可以找到了
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
//如果讀取的文件數據已經在 page cache 中了,則判斷是否進行近一步的預讀操作
if (PageReadahead(page)) {
//非同步預讀若幹文件數據塊到 page cache 中
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
..............省略..............
//將 page cache 中的數據拷貝到用戶空間緩衝區 DirectByteBuffer 中
ret = copy_page_to_iter(page, offset, nr, iter);
}
}

到這裡關於文件讀取的兩種模式 Buffered IO 和 Direct IO 在內核中的主幹邏輯流程筆者就為大家介紹完了。
但是大家可能會對 Buffered IO 中的兩個細節比較感興趣:
-
如何在 page cache 中查找我們要讀取的文件數據 ?也就是說上面提到的 find_get_page 函數是如何實現的?
-
文件預讀的過程是怎麼樣的?內核中的預讀演算法又是什麼樣的呢?
在為大家解答這兩個疑問之前,筆者先為大家介紹一下內核中的頁高速緩存 page cache。
5. 頁高速緩存 page cache
筆者在《一文聊透對象在 JVM 中的記憶體佈局,以及記憶體對齊和壓縮指針的原理及應用》 文章中為大家介紹 CPU 的高速緩存時曾提到過,根據摩爾定律:晶元中的晶體管數量每隔 18 個月就會翻一番。導致 CPU 的性能和處理速度變得越來越快,而提升 CPU 的運行速度比提升記憶體的運行速度要容易和便宜的多,所以就導致了 CPU 與記憶體之間的速度差距越來越大。
CPU 與記憶體之間的速度差異到底有多大呢? 我們知道寄存器是離 CPU 最近的,CPU 在訪問寄存器的時候速度近乎於 0 個時鐘周期,訪問速度最快,基本沒有時延。而訪問記憶體則需要 50 - 200 個時鐘周期。
所以為了彌補 CPU 與記憶體之間巨大的速度差異,提高 CPU 的處理效率和吞吐,於是我們引入了 L1 , L2 , L3 高速緩存集成到 CPU 中。CPU 訪問高速緩存僅需要用到 1 - 30 個時鐘周期,CPU 中的高速緩存是對記憶體熱點數據的一個緩存。
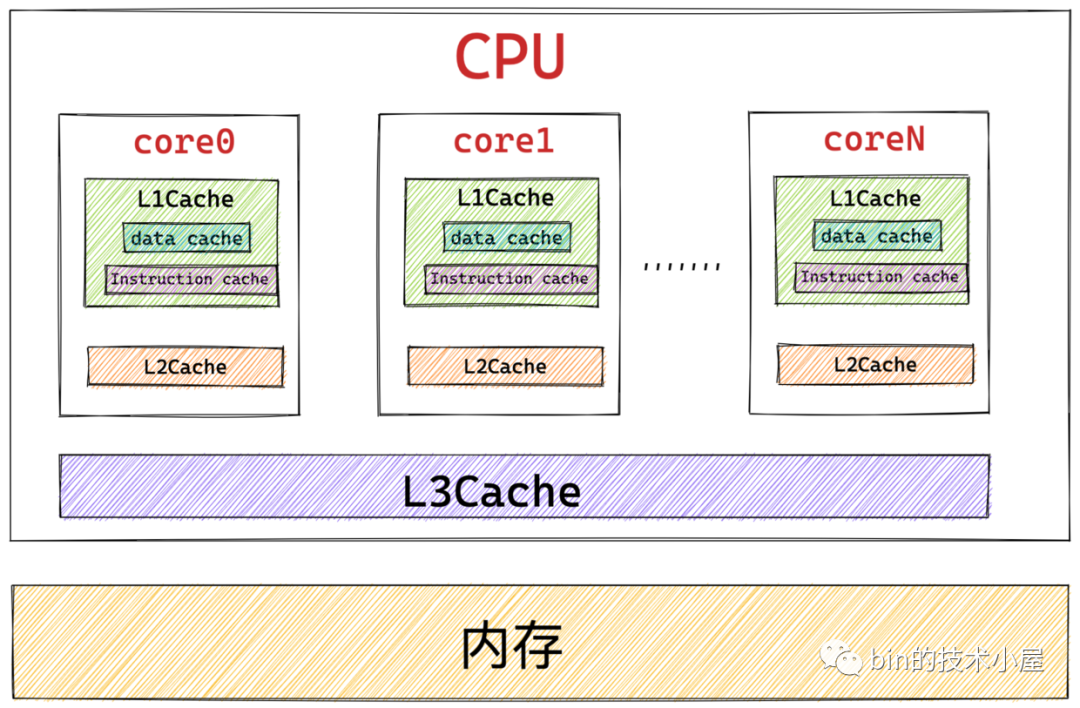
而本文我們討論的主題是記憶體與磁碟之間的關係,CPU 訪問磁碟的速度就更慢了,需要用到大概約幾千萬個時鐘周期.
我們可以看到 CPU 訪問高速緩存的速度比訪問記憶體的速度快大約10倍,而訪問記憶體的速度要比訪問磁碟的速度快大約 100000 倍。
引入 CPU 高速緩存的目的在於消除 CPU 與記憶體之間的速度差距,CPU 用高速緩存來存放記憶體中的熱點數據。那麼同樣的道理,本小節中我們引入的頁高速緩存 page cache 的目的是為了消除記憶體與磁碟之間的巨大速度差距,page cache 中緩存的是磁碟文件的熱點數據。
另外我們根據程式的時間局部性原理可以知道,磁碟文件中的數據一旦被訪問,那麼它很有可能在短期被再次訪問,如果我們訪問的磁碟文件數據緩存在 page cache 中,那麼當進程再次訪問的時候數據就會在 page cache 中命中,這樣我們就可以把對磁碟的訪問變為對物理記憶體的訪問,極大提升了對磁碟的訪問性能。
程式局部性原理表現為:時間局部性和空間局部性。時間局部性是指如果程式中的某條指令一旦執行,則不久之後該指令可能再次被執行;如果某塊數據被訪問,則不久之後該數據可能再次被訪問。空間局部性是指一旦程式訪問了某個存儲單元,則不久之後,其附近的存儲單元也將被訪問。
在前邊的內容中我們多次提到操作系統是將物理記憶體分為一個一個的頁面來組織管理的,每頁大小為 4k ,而磁碟中的文件數據在磁碟中是分為一個一個的塊來組織管理的,每塊大小也為 4k。
page cache 中緩存的就是這些記憶體頁面,頁面中的數據對應於磁碟上物理塊中的數據。page cache 中緩存的大小是可以動態調整的,它可以通過占用空閑記憶體來擴大緩存頁面的容量,當記憶體不足時也可以通過回收頁面來緩解記憶體使用的壓力。
正如我們上小節介紹的 read 系統調用在內核中的實現邏輯那樣,當用戶進程發起 read 系統調用之後,內核首先會在 page cache 中檢查請求數據所在頁面是否已經緩存在 page cache 中。
-
如果緩存命中,內核直接會把 page cache 中緩存的磁碟文件數據拷貝到用戶空間緩衝區 DirectByteBuffer 中,從而避免了龜速的磁碟 IO。
-
如果緩存沒有命中,內核會分配一個物理頁面,將這個新分配的頁面插入 page cache 中,然後調度磁碟塊 IO 驅動從磁碟中讀取數據,最後用從磁碟中讀取的數據填充這個物里頁面。
根據前面介紹的程式時間局部性原理,當進程在不久之後再來讀取數據的時候,請求的數據已經在 page cache 中了。極大地提升了文件 IO 的性能。
page cache 中緩存的不僅有基於文件的緩存頁,還會緩存記憶體映射文件,以及磁碟塊設備文件。這裡大家只需要有這個概念就行,本文我們主要聚焦於基於文件的緩存頁。在筆者後面的文章中,我們還會再次介紹到這些剩餘類型的緩存頁。
在我們瞭解了 page cache 引入的目的以及 page cache 在磁碟 IO 中所發揮的作用之後,大家一定會很好奇這個 page cache 在內核中到底是怎麼實現的呢?
讓我們先從 page cache 在內核中的數據結構開始聊起~~~~
6. page cache 在內核中的數據結構
page cache 在內核中的數據結構是一個叫做 address_space 的結構體:struct address_space。
這個名字起的真是有點詞不達意,從命名上根本無法看出它是表示 page cache 的,所以大家在日常開發中一定要註意命名的精準規範。
每個文件都會有自己的 page cache。struct address_space 結構在記憶體中只會保留一份。
什麼意思呢?比如我們可以通過多個不同的進程打開一個相同的文件,進程每打開一個文件,內核就會為它創建 struct file 結構。這樣在內核中就會有多個 struct file 結構來表示同一個文件,但是同一個文件的 page cache 也就是 struct address_space 在內核中只會有一個。
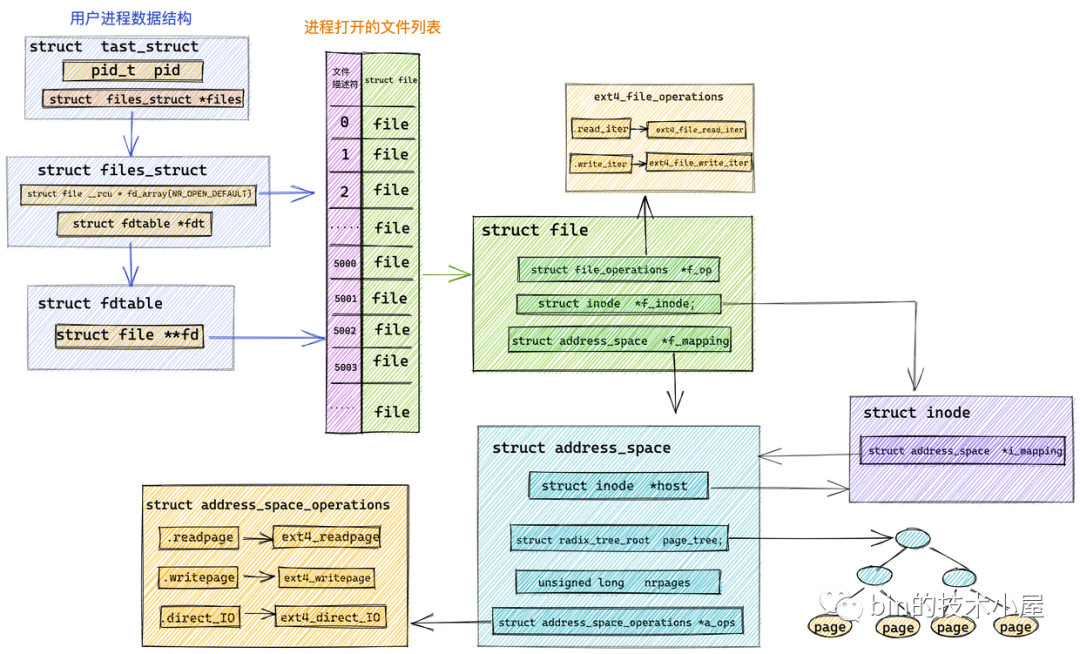
struct address_space {
struct inode *host; // 關聯 page cache 對應文件的 inode
struct radix_tree_root page_tree; // 這裡就是 page cache。裡邊緩存了文件的所有緩存頁面
spinlock_t tree_lock; // 訪問 page_tree 時用到的自旋鎖
unsigned long nrpages; // page cache 中緩存的頁面總數
..........省略..........
const struct address_space_operations *a_ops; // 定義對 page cache 中緩存頁的各種操作方法
..........省略..........
}
struct inode *host:一個文件對應一個 page cache 結構 struct address_space ,文件的 inode 描述了一個文件的所有元信息。在 struct address_space 中通過 host 指針與文件的 inode 關聯。而在 inode 結構體 struct inode 中又通過 i_mapping 指針與文件的 page cache 進行關聯。
struct inode {
struct address_space *i_mapping; // 關聯文件的 page cache
}
-
struct radix_tree_root page_tree: page cache 中緩存的所有文件頁全部存儲在 radix_tree 這樣一個高效搜索樹結構當中。在文件 IO 相關的操作中,內核需要頻繁大量地在 page cache 中搜索請求頁是否已經緩存在頁高速緩存中,所以針對 page cache 的搜索操作必須是高效的,否則引入 page cache 所帶來的性能提升將會被低效的搜索開銷所抵消掉。 -
unsigned long nrpages:記錄了當前文件對應的 page cache 緩存頁面的總數。 -
const struct address_space_operations *a_ops:a_ops 定義了 page cache 中所有針對緩存頁的 IO 操作,提供了管理 page cache 的各種行為。比如:常用的頁面讀取操作 readPage() 以及頁面寫入操作 writePage() 等。保證了所有針對緩存頁的 IO 操作必須是通過 page cache 進行的。
struct address_space_operations {
// 寫入更新頁面緩存
int (*writepage)(struct page *page, struct writeback_control *wbc);
// 讀取頁面緩存
int (*readpage)(struct file *, struct page *);
// 設置緩存頁為臟頁,等待後續內核回寫磁碟
int (*set_page_dirty)(struct page *page);
// Direct IO 繞過 page cache 直接操作磁碟
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
........省略..........
}
前邊我們提到 page cache 中緩存的不僅僅是基於文件的頁,它還會緩存記憶體映射頁,以及磁碟塊設備文件,況且基於文件的記憶體頁背後也有不同的文件系統。所以內核只是通過 a_ops 定義了操作 page cache 緩存頁 IO 的通用行為定義。而具體的實現需要各個具體的文件系統通過自己定義的 address_space_operations 來描述自己如何與 page cache 進行交互。比如前邊我們介紹的 ext4 文件系統就有自己的 address_space_operations 定義。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
在我們從整體上瞭解了 page cache 在內核中的數據結構 struct address_space 之後,我們接下來看一下 radix_tree 這個數據結構是如何支持內核來高效搜索文件頁的,以及 page cache 中這些被緩存的文件頁是如何組織管理的。
7. 基樹 radix_tree
正如前邊我們提到的,在文件 IO 相關的操作中,內核會頻繁大量地在 page cache 中查找請求頁是否在頁高速緩存中。還有就是當我們訪問大文件時(linux 能支持大到幾個 TB 的文件),page cache 中將會充斥著大量的文件頁。
基於上面提到的兩個原因:一個是內核對 page cache 的頻繁搜索操作,另一個是 page cache 中會緩存大量的文件頁。所以內核需要採用一個高效的搜索數據結構來組織管理 page cache 中的緩存頁。
本小節我們就來介紹下,page cache 中用來存儲緩存頁的數據結構 radix_tree。
在 linux 內核 5.0 版本中 radix_tree 已被替換成 xarray 結構。感興趣的同學可以自行瞭解下。
在 page cache 結構 struct address_space 中有一個類型為 struct radix_tree_root 的欄位 page_tree,它表示的是 radix_tree 的根節點。
struct address_space {
struct radix_tree_root page_tree; // 這裡就是 page cache。裡邊緩存了文件的所有緩存頁面
..........省略..........
}
struct radix_tree_root {
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode; // radix_tree 根節點
};
radix_tree 中的節點類型為 struct radix_tree_node。
struct radix_tree_node {
void __rcu *slots[RADIX_TREE_MAP_SIZE]; //包含 64 個指針的數組。用於指向下一層節點或者緩存頁
unsigned char offset; //父節點中指向該節點的指針在父節點 slots 數組中的偏移
unsigned char count;//記錄當前節點的 slots 數組指向了多少個節點
struct radix_tree_node *parent; // 父節點指針
struct radix_tree_root *root; // 根節點
..........省略.........
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; // radix_tree 中的二維標記數組,用於標記子節點的狀態。
};
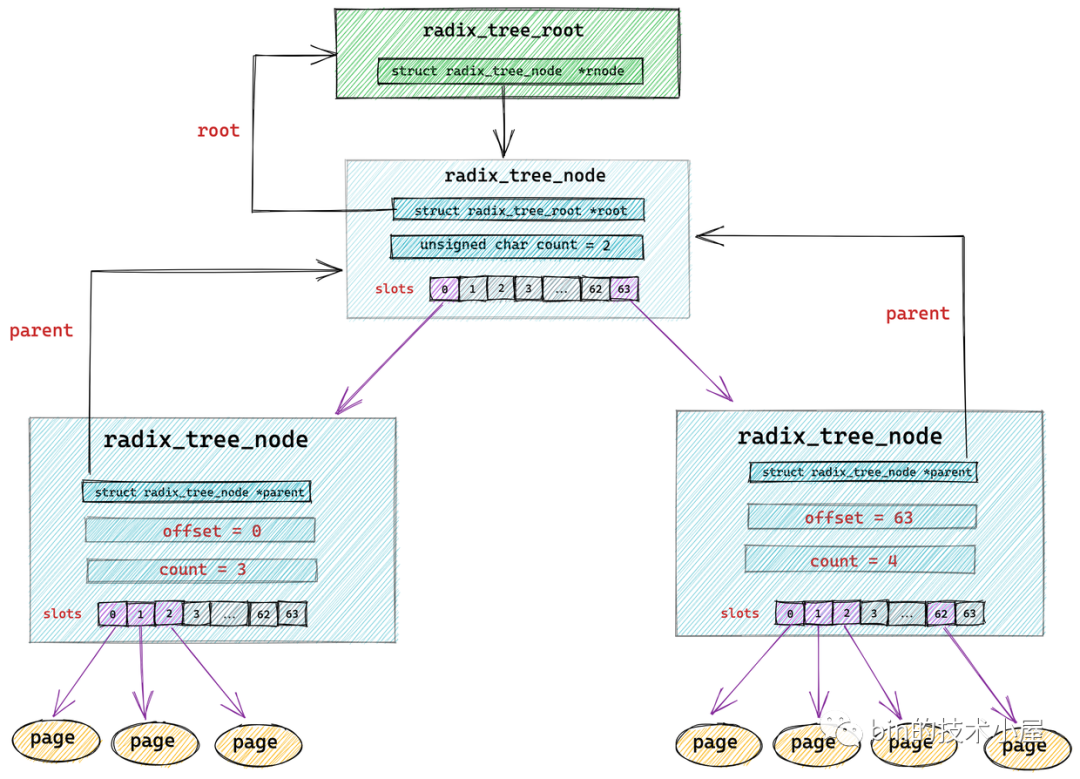
void __rcu *slots[RADIX_TREE_MAP_SIZE] :radix_tree 樹中的每個節點中包含一個 slots ,它是一個包含 64 個指針的數組,每個指針指向它的下一層節點或者緩存頁描述符 struct page。
radix_tree 將緩存頁全部存放在它的葉子結點中,所以它的葉子結點類型為 struct page。其餘的節點類型為 radix_tree_node。最底層的 radix_tree_node 節點中的 slots 指向緩存頁描述符 struct page。
unsigned char offset 用於表示父節點的 slots 數組中指向當前節點的指針,在父節點的slots數組中的索引。
unsigned char count 用於記錄當前 radix_tree_node 的 slots 數組中指向的節點個數,因為 slots 數組中的指針有可能指向 null 。
這裡大家可能已經註意到了在 struct radix_tree_node 結構中還有一個 long 型的 tags 二維數組 tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]。那麼這個二維數組到底是用來幹嘛的呢?我們接著往下看~~
7.1 radix_tree 的標記
經過前面的介紹我們知道,頁高速緩存 page cache 的引入是為了在記憶體中緩存磁碟的熱點數據儘可能避免龜速的磁碟 IO。
而在進行文件 IO 的時候,內核會頻繁大量的在 page cache 中搜索請求數據是否已經緩存在 page cache 中,如果是,內核就直接將 page cache 中的數據拷貝到用戶緩衝區中。從而避免了一次磁碟 IO。
這就要求內核需要採用一種支持高效搜索的數據結構來組織管理這些緩存頁,所以引入了基樹 radix_tree。
到目前為止,我們還沒有涉及到緩存頁的狀態,不過在文章的後面我們很快就會涉及到,這裡提前給大家引出來,讓大家腦海裡先有個概念。
那麼什麼是緩存頁的狀態呢?
我們知道在 Buffered IO 模式下,對於文件 IO 的操作都是需要經過 page cache 的,後面我們即將要介紹的 write 系統調用就會將數據直接寫到 page cache 中,並將該緩存頁標記為臟頁(PG_dirty)直接返回,隨後內核會根據一定的規則來將這些臟頁回寫到磁碟中,在會寫的過程中這些臟頁又會被標記為 PG_writeback,表示該頁正在被回寫到磁碟。
PG_dirty 和 PG_writeback 就是緩存頁的狀態,而內核不僅僅是需要在 page cache 中高效搜索請求數據所在的緩存頁,還需要高效搜索給定狀態的緩存頁。
比如:快速查找 page cache 中的所有臟頁。但是如果此時 page cache 中的大部分緩存頁都不是臟頁,那麼順序遍歷 radix_tree 的方式就實在是太慢了,所以為了快速搜索到臟頁,就需要在 radix_tree 中的每個節點 radix_tree_node
中加入一個針對其所有子節點的臟頁標記,如果其中一個子節點被標記被臟時,那麼這個子節點對應的父節點 radix_tree_node 結構中的對應臟頁標記位就會被置 1 。
而用來存儲臟頁標記的正是上小節中提到的 tags 二維數組。其中第一維 tags[] 用來表示標記類型,有多少標記類型,數組大小就為多少,比如 tags[0] 表示 PG_dirty 標記數組,tags[1] 表示 PG_writeback 標記數組。
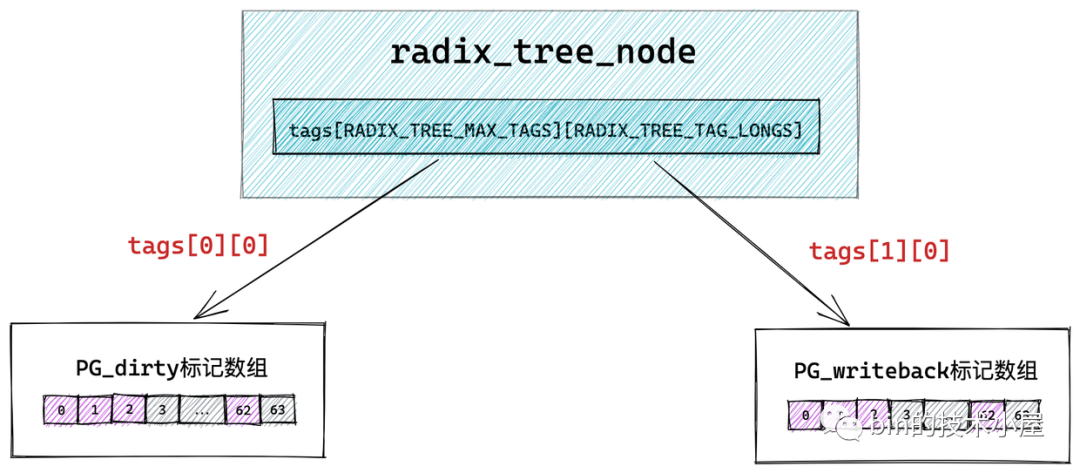
第二維 tags[][] 數組則表示對應標記類型針對每一個子節點的標記位,因為一個 radix_tree_node 節點中包含 64 個指針指向對應的子節點,所以二維 tags[][] 數組的大小也為 64 ,數組中的每一位表示對應子節點的標記。tags[0][0] 指向 PG_dirty 標記數組,tags[1][0] 指向PG_writeback 標記數組。
而緩存頁( radix_tree 中的葉子結點)這些標記是存放在其對應的頁描述符 struct page 里的 flag 中。
struct page {
unsigned long flags;
}
只要一個緩存頁(葉子結點)被標記,那麼從這個葉子結點一直到 radix_tree 根節點的路徑將會全部被標記。這就好比你在一盆清水中滴入一滴墨水,不久之後整盆水就會變為黑色。
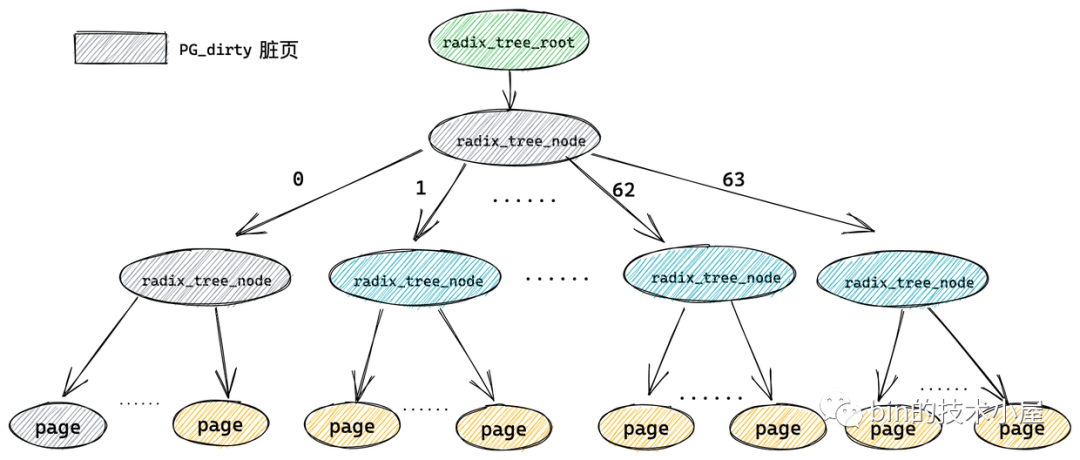
這樣內核在 radix_tree 中搜索被標記的臟頁(PG_dirty)或者正在回寫的頁(PG_writeback)時,就可以迅速跳過哪些標記為 0 的中間節點的所有子樹,中間節點對應的標記為 0 說明其所有的子樹中包含的緩存頁(葉子結點)都是乾凈的(未標記)。從而達到在 radix_tree 中迅速搜索指定狀態的緩存頁的目的。
8. page cache 中查找緩存頁
在我們明白了 radix_tree 這個數據結構之後,接下來我們來看一下在《4.2 Buffered IO》小節中遺留的問題:內核如何通過 find_get_page 在 page cache 中高效查找緩存頁?
在介紹 find_get_page 之前,筆者先來帶大家看看 radix_tree 具體是如何組織和管理其中的緩存頁 page 的。
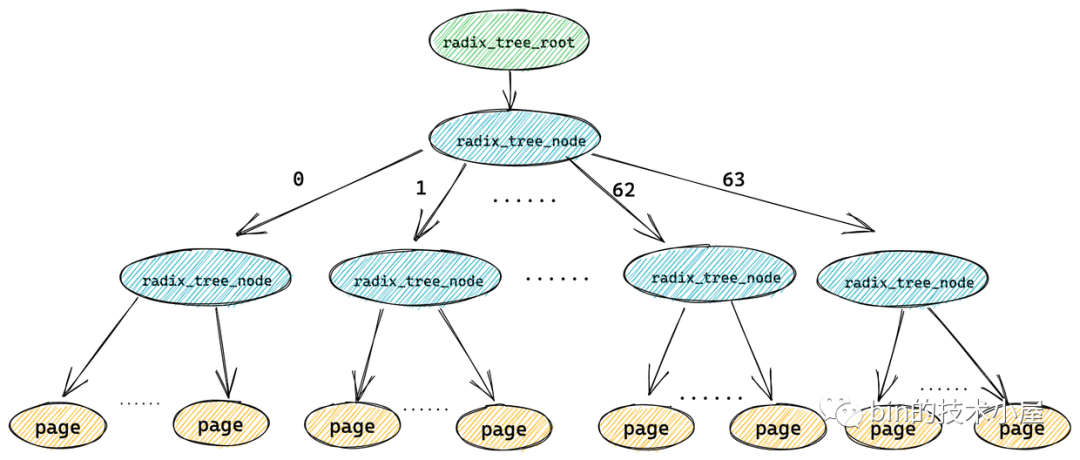
經過上小節相關內容的介紹,我們瞭解到在 radix_tree 中每個節點 radix_tree_node 包含一個大小為 64 的指針數組 slots 用於指向它的子節點或者緩存頁描述符(葉子節點)。
一個 radix_tree_node 節點下邊最多可容納 64 個子節點,如果 radix_tree 的深度為 1 (不包括葉子節點),那麼這顆 radix_tree 就可以緩存 64 個文件頁。而每頁大小為 4k,所以一顆深度為 1 的 radix_tree 可以緩存 256k 的文件內容。
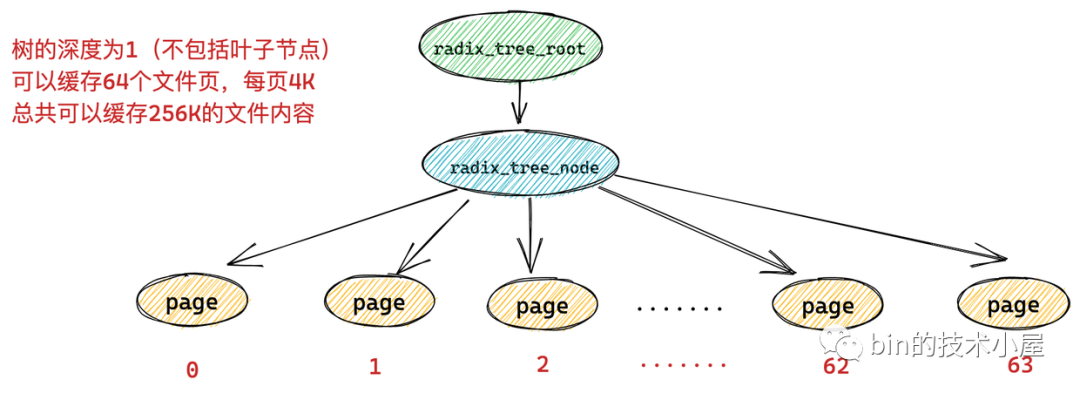
而如果一顆 radix_tree 的深度為 2,那麼它就可以緩存 64 * 64 = 4096 個文件頁,總共可以緩存 16M 的文件內容。
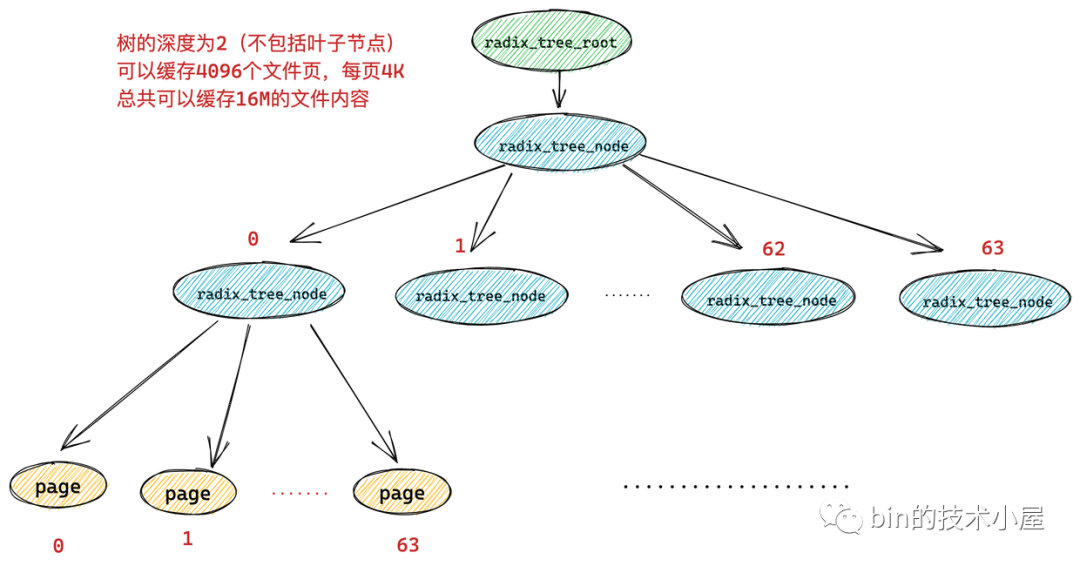
依次類推我們可以得到不同的 radix_tree 深度可以緩存多大的文件內容:
| radix_tree 深度 | page 最大索引值 | 緩存文件大小 |
|---|---|---|
| 1 | 2^6 - 1 = 63 | 256K |
| 2 | 2^12 - 1 = 4095 | 16M |
| 3 | 2^18 - 1 = 262143 | 1G |
| 4 | 2^24 -1 =16777215 | 64G |
| 5 | 2^30 - 1 | 4T |
| 6 | 2^36 - 1 | 64T |
通過以上內容的介紹,我們看到在 radix_tree 是根據緩存頁的 index (索引)來組織管理緩存頁的,內核會根據這個 index 迅速找到對應的緩存頁。在緩存頁描述符 struct page 結構中保存了其在 page cache 中的索引 index。
struct page {
unsigned long flags; //緩存頁標記
struct address_space *mapping; // 緩存頁所在的 page cache
unsigned long index; // 頁索引
...
}
事實上 find_get_page 函數也是根據緩存頁描述符中的這個 index 來在 page cache 中高效查找對應的緩存頁。
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
return pagecache_get_page(mapping, offset, 0, 0);
}
-
struct address_space *mapping: 為讀取文件對應的 page cache 頁高速緩存。 -
pgoff_t offset: 為所請求的緩存頁在 page cache 中的索引 index,類型為 long 型。
那麼在內核是如何利用這個 long 型的 offset 在 page cache 中高效搜索指定的緩存頁呢?
經過前邊我們對 radix_tree 結構的介紹,我們已經知道 radix_tree 中每個節點 radix_tree_node 包含一個大小為 64 的指針數組 slots 用於指向它的子節點或者緩存頁描述符。
一個 radix_tree_node 節點下邊最多可容納 64 個子節點,如果 radix_tree 的深度為 1 (不包括葉子節點),那麼這顆 radix_tree 就可以緩存 64 個文件頁。只能表示 0 - 63 的索引範圍,所以 long 型的緩存頁 offset 的低 6 位可以表示這個範圍,對應於第一層 radix_tree_node 節點的 slots 數組下標。
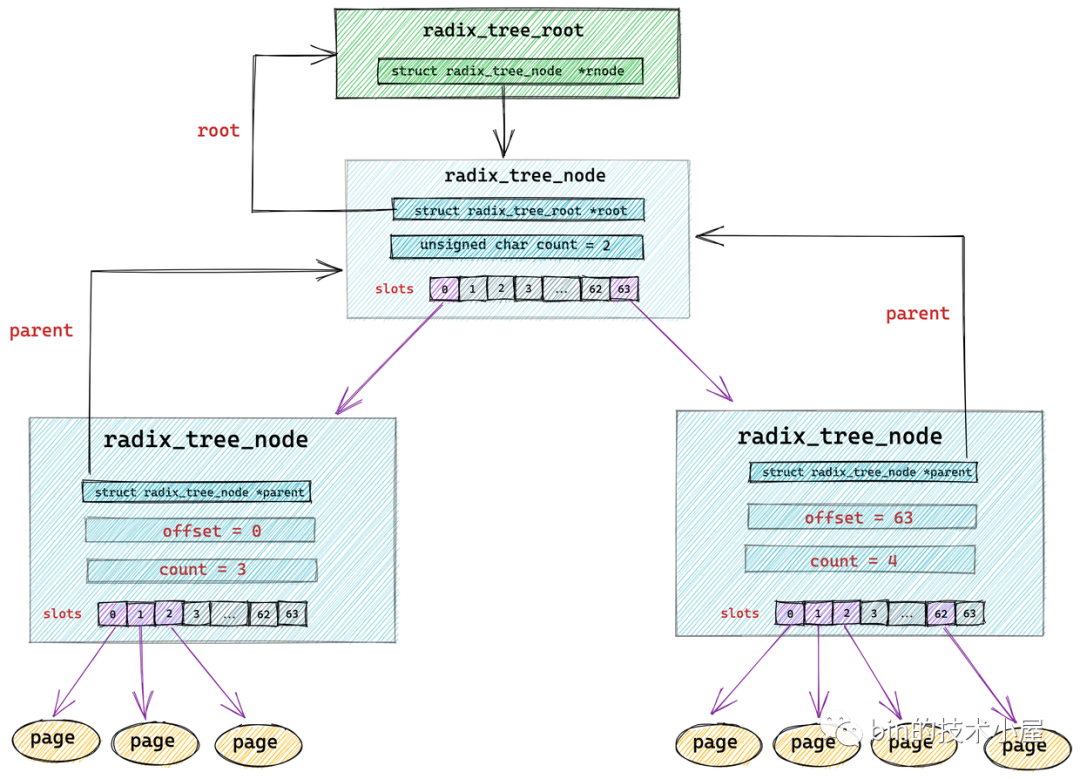
如果一顆 radix_tree 的深度為 2(不包括葉子節點),那麼它就可以緩存 64 * 64 = 4096 個文件頁,表示的索引範圍為 0 - 4095,在這種情況下,緩存頁索引 offset 的低 12 位可以分成 兩個 6 位的欄位,高位的欄位用來表示第一層節點的 slots 數組的下標,低位欄位用於表示第二層節點的 slots 數組下標。
依次類推,如果 radix_tree 的深度為 6 那麼它可以緩存 64T 的文件頁,表示的索引範圍為:0 到 2^36 - 1。 緩存頁索引 offset 的低 36 位可以分成 六 個 6 位的欄位。緩存頁索引的最高位欄位來表示 radix_tree 中的第一層節點中的 slots 數組下標,接下來的 6 位欄位表示第二層節點中的 slots 數組下標,這樣一直到最低的 6 位欄位表示第 6 層節點中的 slots 數組下標。
通過以上根據緩存頁索引 offset 的查找過程,我們看出內核在 page cache 查找緩存頁的時間複雜度和 radix_tree 的深度有關。
在我們理解了內核在 radix_tree 中的查找緩存頁邏輯之後,再來看 find_get_page 的代碼實現就變得很簡單了~~
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
// 在 radix_tree 中根據 緩存頁 offset 查找緩存頁
page = find_get_entry(mapping, offset);
// 緩存頁不存在的話,跳轉到 no_page 處理邏輯
if (!page)
goto no_page;
.......省略.......
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
// 分配新頁
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (fgp_flags & FGP_ACCESSED)
//增加頁的引用計數
__SetPageReferenced(page);
// 將新分配的記憶體頁加入到頁高速緩存 page cache 中
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
.......省略.......
}
return page;
}
-
內核首先調用 find_get_entry 方法根據緩存頁的 offset 到 page cache 中去查找看請求的文件頁是否已經在頁高速緩存中。如果存在直接返回。
-
如果請求的文件頁不在 page cache 中,內核則會首先會在物理記憶體中分配一個記憶體頁,然後將新分配的記憶體頁加入到 page cache 中,並增加頁引用計數。
-
隨後會通過 address_space_operations 重定義的 readpage 激活塊設備驅動從磁碟中讀取請求數據,然後用讀取到的數據填充新分配的記憶體頁。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
9. 文件頁的預讀
之前我們在引入 page cache 的時候提到過,根據程式時間局部性原理:如果進程在訪問某一塊數據,那麼在訪問的不久之後,進程還會再次訪問這塊數據。所以內核引入了 page cache 在記憶體中緩存磁碟中的熱點數據,從而減少對磁碟的 IO 訪問,提升系統性能。
而本小節我們要介紹的文件頁預讀特性是根據程式空間局部性原理:當進程訪問一段數據之後,那麼在不就的將來和其臨近的一段數據也會被訪問到。所以當進程在訪問文件中的某頁數據的時候,內核會將它和臨近的幾個頁一起預讀到 page cache 中。這樣當進程再次訪問文件的時候,就不需要進行龜速的磁碟 IO 了,因為它所請求的數據已經預讀進 page cache 中了。
我們常提到的當你順序讀取文件的時候,性能會非常的高,因為相當於是在讀記憶體,這就是文件預讀的功勞。
但是在我們隨機訪問文件的時候,文件預讀不僅不會提高性能,返回會降低文件讀取的性能,因為隨機讀取文件並不符合程式空間局部性原理,因此預讀進 page cache 中的文件頁通常是無效的,下一次根本不會再去讀取,這無疑是白白浪費了 page cache 的空間,還額外增加了不必要的預讀磁碟 IO。
事實上,在我們對文件進行隨機讀取的場景下,更適合用 Direct IO 的方式繞過 page cache 直接從磁碟中讀取文件,還能減少一次從 page cache 到用戶緩衝區的拷貝。
所以內核需要一套非常精密的預讀演算法來根據進程是順序讀文件還是隨機讀文件來精確地調控預讀的文件頁數,或者直接關閉預讀。
- 進程在讀取文件數據的時候都是逐頁進行讀取的,因此在預讀文件頁的時候內核並不會考慮頁內偏移,而是根據請求數據在文件內部的頁偏移進行讀取。
-
如果進程持續的順序訪問一個文件,那麼預讀頁數也會隨著逐步增加。
-
當發現進程開始隨機訪問文件了(當前訪問的文件頁和最後一次訪問的文件頁 offset 不是連續的),內核就會逐步減少預讀頁數或者徹底禁止預讀。
-
當內核發現進程再重覆的訪問同一文件頁時或者文件中的文件頁已經幾乎全部緩存在 page cache 中了,內核此時就會禁止預讀。
以上幾點就是內核的預讀演算法的核心邏輯,從這個預讀邏輯中我們可以看出,進程在進行文件讀取的時候涉及到兩種不同類型的頁面集合,一個是進程可以請求的文件頁(已經緩存在 page cache 中的文件頁),另一個是內核預讀的文件頁。
而內核也確實按照這兩種頁面集合分為兩個視窗:
-
當前視窗(current window): 表示進程本次文件請求可以直接讀取的頁面集合,這個集合中的頁面全部已經緩存在 page cache 中,進程可以直接讀取返回。當前視窗中包含進程本次請求的文件頁以及上次內核預讀的文件頁集合。表示進程本次可以從 page cache 直接獲取的頁面範圍。
-
預讀視窗(ahead window):預讀視窗的頁面都是內核正在預讀的文件頁,它們此時並不在 page cache 中。這些頁面並不是進程請求的文件頁,但是內核根據空間局部性原理假定它們遲早會被進程請求。預讀視窗內的頁面緊跟著當前視窗後面,並且內核會動態調整預讀視窗的大小(有點類似於 TCP 中的滑動視窗)。
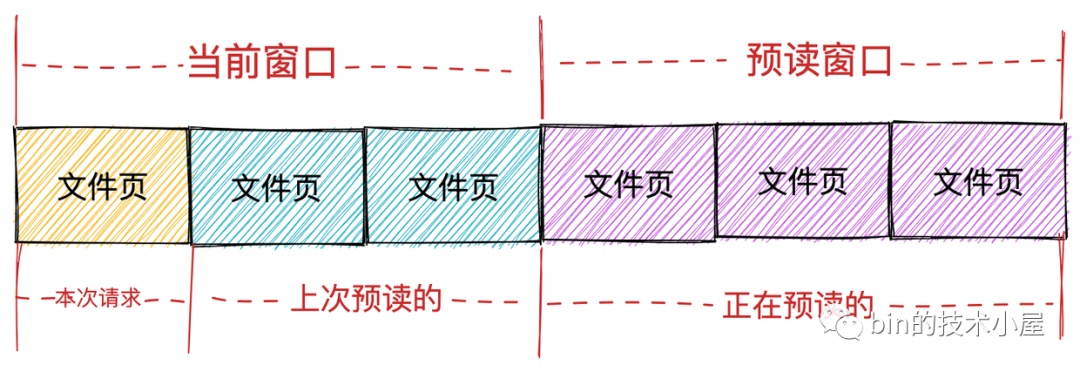
如果進程本次文件請求的第一頁的 offset,緊跟著上一次文件請求的最後一頁的 offset,內核就認為是順序讀取。在順序讀取文件的場景下,如果請求的第一頁在當前視窗內,內核隨後就會檢查是否建立了預讀視窗,如果沒有就會創建預讀視窗並觸發相應頁的讀取操作。
在理想情況下,進程會繼續在當前視窗內請求頁,於此同時,預讀視窗內的預讀頁同時非同步傳送著,這樣進程在順序讀取文件的時候就相當於直接讀取記憶體,極大地提高了文件 IO 的性能。
以上包含的這些文件預讀信息,比如:如何判斷進程是順序讀取還是隨機讀取,當前視窗信息,預讀視窗信息。全部保存在 struct file 結構中的 f_ra 欄位中。
struct file {
struct file_ra_state f_ra;
}
用於描述文件預讀信息的結構體在內核中用 struct file_ra_state 結

