
在設計稿轉網頁中運用基於self-attention機制設計的機器學習模型進行設計稿的佈局,能夠結合dom節點的上下文得出合理的方案. ...
作者:vivo 互聯網前端團隊- Su Ning
在設計稿轉網頁中運用基於self-attention機制設計的機器學習模型進行設計稿的佈局,能夠結合dom節點的上下文得出合理的方案。
一、背景
切圖作為前端的傳統手藝卻是大多數前端開發者都不願面對的工作。
為瞭解決切圖的各種問題,人們絞盡腦汁開發了各種各樣的設計稿轉代碼(D2C)工具,這些D2C工具隨著設計師使用的軟體的變更又在不斷地迭代。
從Photoshop時代,前端需要手動標記節點進行單獨的樣式導出(如圖1),到sketch measure,可以整體頁面輸出(如圖2),其效率、結果都已經有了一個質的提升。
但是還是未能徹底解決切圖的問題,因為設計稿所包含的信息只負責輸出樣式,而沒有辦法輸出網頁佈局,我們還是沒有辦法直接copy生成的代碼到我們的項目中直接使用。
圖1
圖2
在學習現有的D2C案例的過程中,我們發現很多成熟的方案中引用了機器學習輔助代碼的生成,其中絕大多數的工作是用於視覺識別和語義識別,於是我們想,機器學習是否能夠應用到網頁的佈局中呢?
為了驗證我們的猜想,也為瞭解決我們工作中的實際痛點,我們決定自己開發一個D2C工具,希望能夠通過機器幫我們實現網頁佈局的過程,整體工作流程大致如圖3,首先獲取設計稿的元數據,然後對設計稿的數據進行一系列的處理導出自由的dsl,然後根據這個dsl生成相應端的代碼。
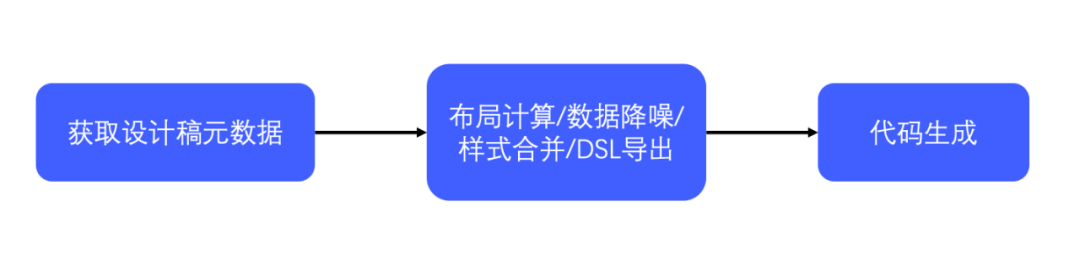
圖3
二、頁面佈局
要處理網頁的佈局需要解決兩個問題,節點的父子關係以及節點之間的位置關係。
2.1 節點的父子關係
節點的父子關係指的是一個節點包含了哪些子節點,又被哪個節點所包含。這部分的內容可以直接使用規則處理,通過節點的頂點位置和中心點的位置信息判斷一個節點是否是另一個節點的子節點。這裡我們就不展開討論了。
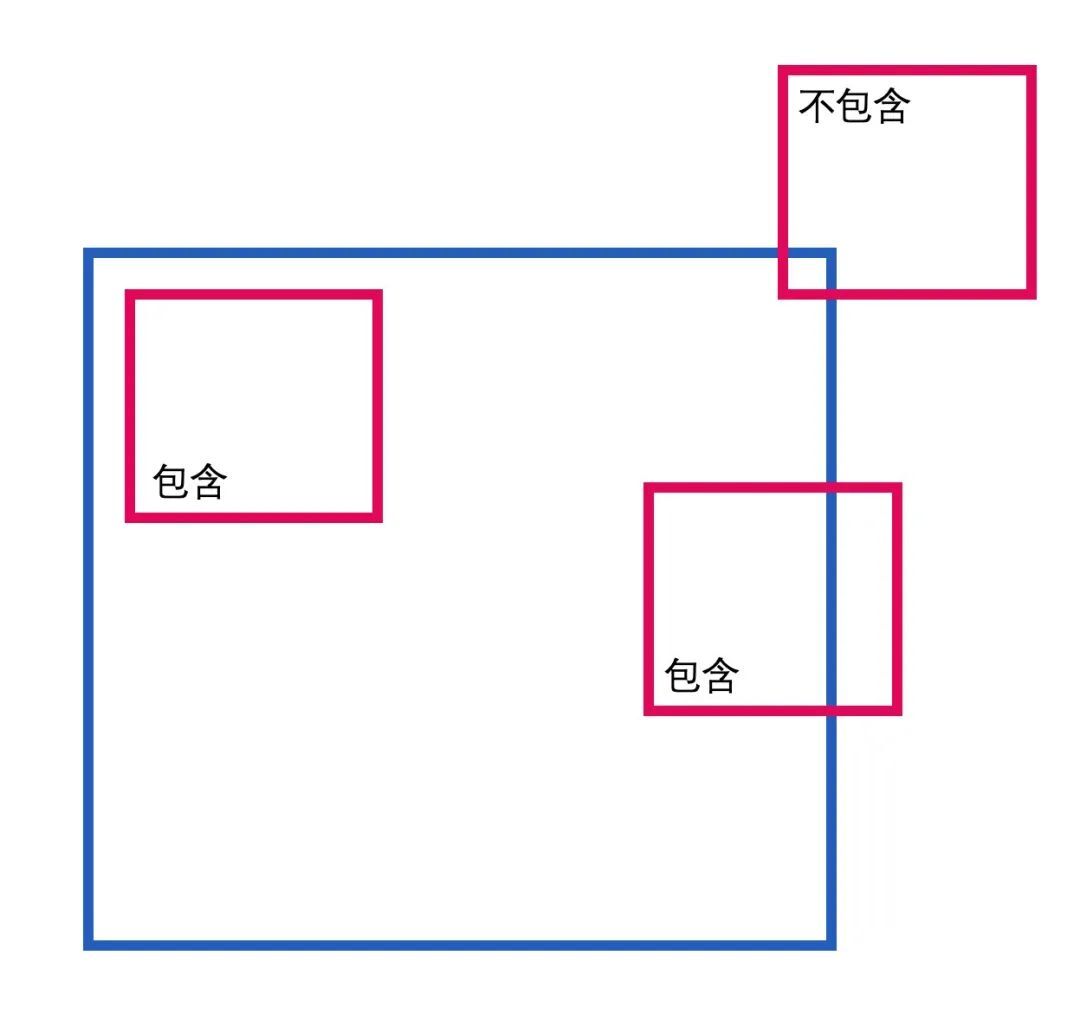
同一層級節點之間的位置關係,才是我們這次著重需要解決的問題。
2.2 節點之間的位置關係
網頁的佈局有很多種,線性佈局,流式佈局,網格佈局,還有隨意定位的絕對定位等等,而我們在導出樣式的時候,無非需要確認兩件事情,節點的定位方式(relative、absolute、fixed)和節點的佈局方向(縱向、橫向)。
線性佈局

流式佈局

網格佈局
按照*時切圖的習慣,我們會首先識別一組*級節點之間有沒有明顯的上下或者左右的位置關係,然後將他們放入到網格中,最後獨立在這些節點外面的節點就是絕對定位。
讓機器識別節點之間的位置關係,就成瞭解決問題的關鍵一環。

判斷節點之間的位置關係只需要節點的位置和寬高信息,因此我們的輸入數據設計如下:
[
{
width:200,
height:50,
x:0,
y:0
},
{
width:200,
height:100,
x:0,
y:60
},
{
width:200,
height:100,
x:210,
y:60
}
]同時我們希望獲得的輸出結果是每一個節點是上下排列,左右排列,還是絕對定位的,輸出的數據設計如下:
[
{
layout:'col'
},
{
layout:'row'
},
{
layout:'absolute'
}
]起初我們是希望通過書寫一定的規則進行佈局的判斷,通過判斷前後兩個節點的位置關係是上下還是左右來進行佈局,然而這樣只關註兩個節點位置關係的規則卻很難判斷絕對定位的節點,並且固定的規則總是不夠靈活。於是我們想到了善於處理分類問題的機器學習。
很顯然通過大量數據訓練的機器學習模型可以很好的模仿我們*時切圖的習慣,在處理各種邊緣場景的時候也能夠更加的靈活。只要進行合理的模型設計,就可以輔助我們進行佈局的處理。
三、為什麼是self-attention?
從上文我們可以看出,我們需要訓練一個模型,輸入一個節點的列表,輸出一個節點的佈局信息,是不是有點像文本識別裡面的詞性翻譯呢?
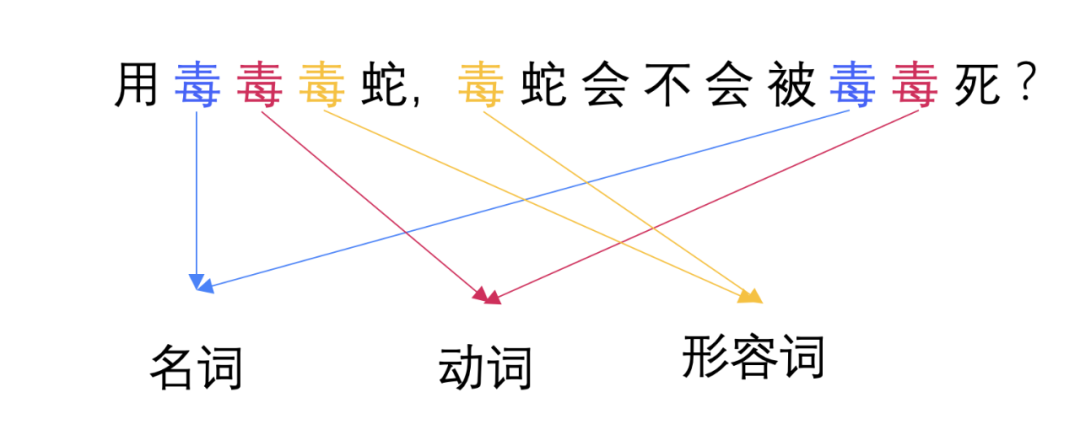
對於具體的一個節點,我們是沒有辦法判斷其真正的佈局的,只有將其放到文檔流中結合上下文來看才能體現出其實際的意義。
在處理詞性標記這塊,RNN(迴圈神經網路)、LSTM(長短期記憶網路)都比較合適此類場景,RNN作為經典的神經網路模型通過將前一次訓練的權重帶入到下一次訓練中建立上下文的關聯,LSTM作為RNN的一種變體解決了RNN難以解決的長期依賴問題,用來訓練網頁佈局看起來是一個不錯的選擇。
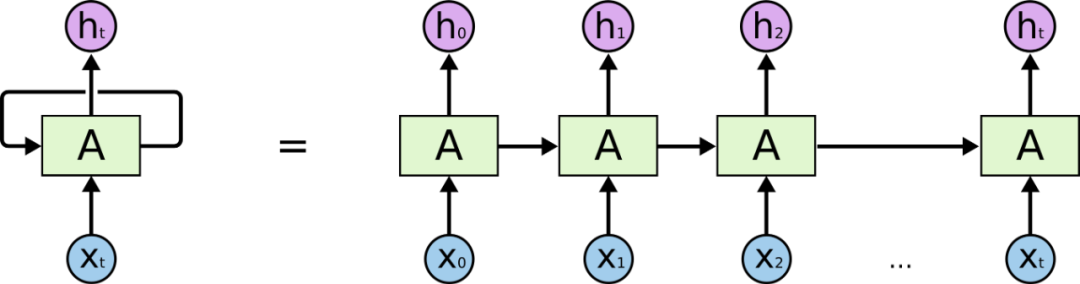
RNN(迴圈神經網路)
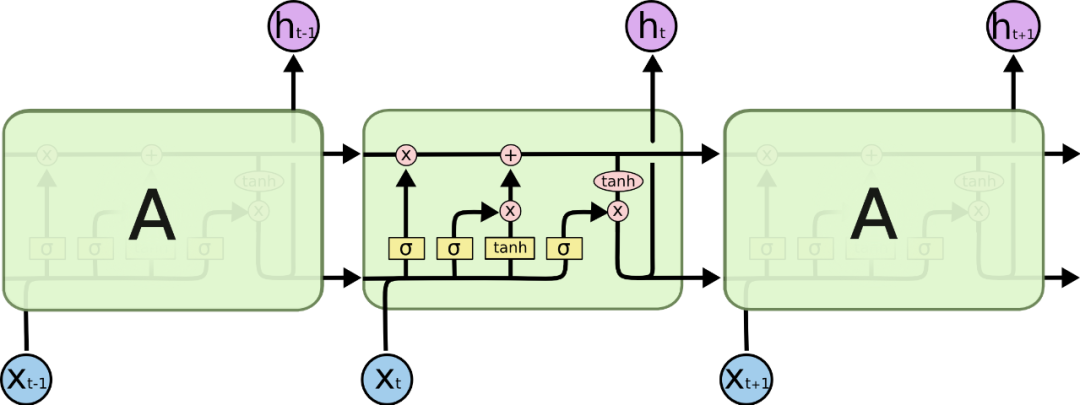
665px LSTM(長短期記憶網路)
使用LSTM的確可以解決我們的問題,但是由於此類神經網路對於時序的依賴導致上下文的數據沒有辦法進行並行運算,這使得我們的電腦沒有辦法更高效的訓練模型,並且網頁佈局只需要獲取不同節點的定位信息,對於裝載的順序並沒有強要求。
隨著2017年的一篇文章《Attention is All you Need》的橫空出世,整個機器學習領域迎來了新一輪的革命,目前最主流的框架transformer、BERT、GPT全是在attention的基礎上發展起來的。
self-attention自註意力機制是attention機制的變體,通過全局關聯權重得出單個向量在全局中的加權信息,因為每一個節點都採用相同的運算方式,所以同一個序列中的節點可以同時進行上下文計算,極大地提升了模型訓練的效率,也更方便我們優化和回歸模型。
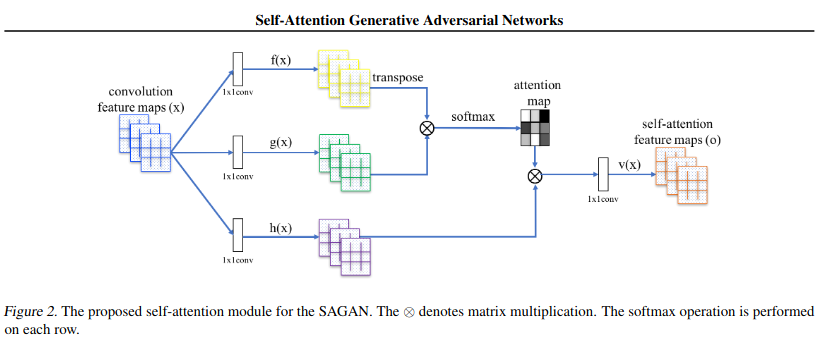
self-attention
綜上,考慮到attention對於上下文更好的關聯和更好的並行性能,我們決定基於此進行建模。
四、模型設計
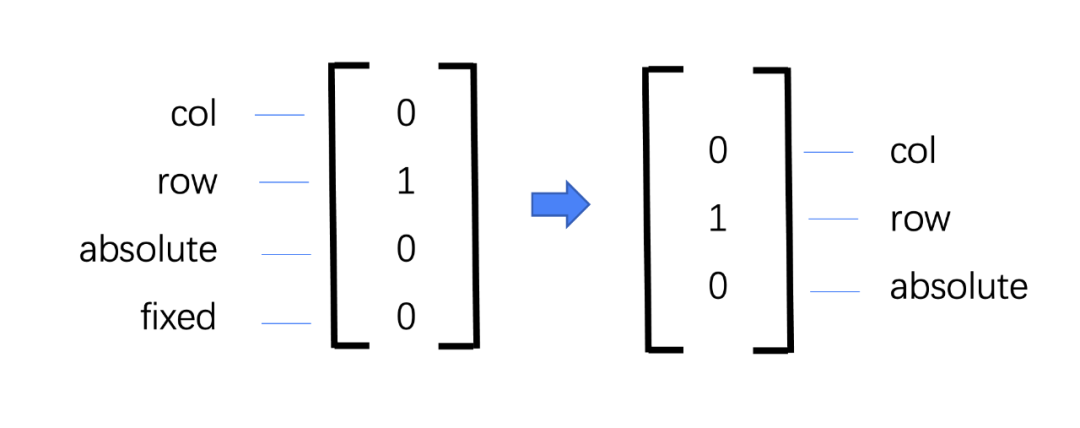
我們起初設計了一個輸出的向量用於識別數據處理的結果,[1,0,0,0]代表是正常的豎向排列,[0,1,0,0]代表了橫向排列,以此類推依次代表了absolute和fixed定位方式,但是後來我們發現fixed由於是相對於整個頁面的定位方式,所以在單一層級下很難做標記,所以我們將輸出值精簡成了豎向排列,橫向排列和絕對定位三種情況。
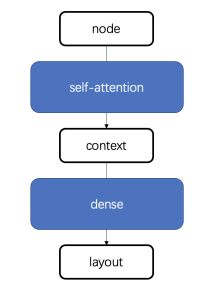
模型的整體設計如下,通過self-attention將節點轉化為上下文信息,再通過前饋神經網路將上下文信息訓練成具體的佈局。
(1)在獲取到一組數據後,為了去掉數值的大小的影響,我們首先對數據進行一次歸一處理,將輸入數據的每一個值分別除以這一組數據中的最大值。
(2)將每一組數據分別進行三次線性變換, 得到每組數據相應的Q,K,V,接下來我們就可以進行self-attention運算了。
(3)我們以node1為例,如果需要計算node1和其他節點的相關性,則需要使用Q1分別和每一個節點的key進行點積操作,將他們的和與V1相乘,為了防止權重值相乘以後過大,最後進行一次softmax計算,就得到了node1和其他節點的上下文信息。
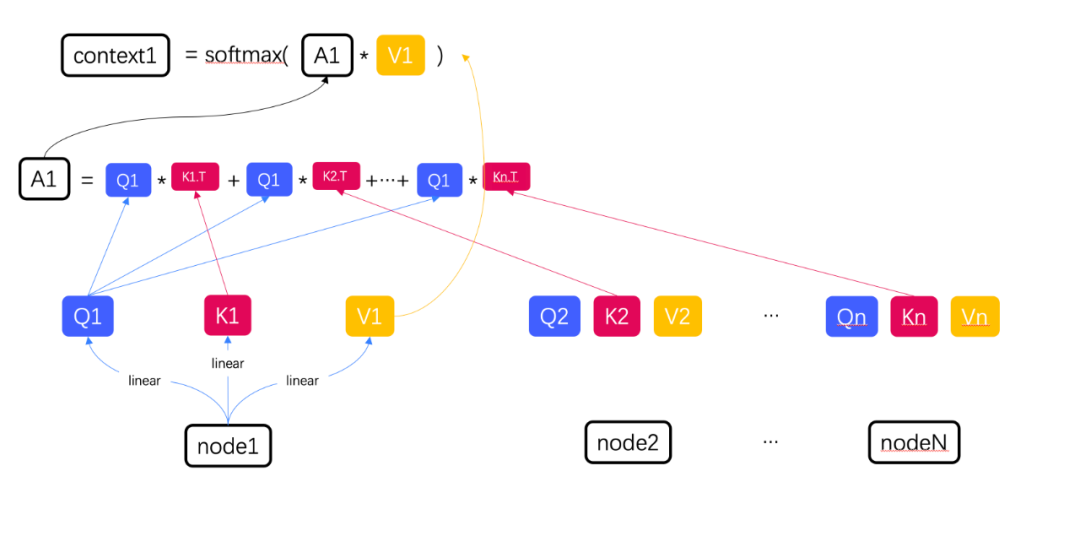
我們將一組數據中所有QKV看成三個矩陣,得到的上下文context的集合就可以看成一個矩陣計算。
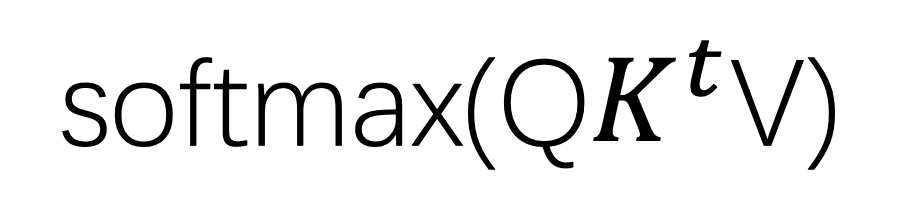
(4)為了提升訓練的效果,每個節點的上下文信息輸入到前饋神經網路進行最後的佈局結果的訓練,將得到的結果進行softmax計算就可以得到單個節點在一組數據中佈局的概率分佈了,由於同一組節點的運算沒有前後順序,故單個節點的運算可以同時進行,配合GPU加速極大地提升了訓練的效率。
五、數據準備
由於機器學習需要海量的數據,數據的數量和質量都會極大地影響模型最終的訓練效果,所以數據的數量和質量都非常重要,我們採用了三種數據源用於數據的訓練,分別是標記過的設計稿,抓取的真實網頁數據,以及自動生成的數據。
5.1 設計稿的標記
在獲取到設計稿數據以後只取每個節點的定位和寬高數據,通過上文的父子關係處理後獲取每一層的節點數據,為了防止出現過擬合的情況我們去掉節點數量相對較少的層級,並對每一層的佈局進行手動標記。設計稿標記數據是質量最好,但也是最費時費力的工作,所以需要其他的數據源進行數量的補充。
5.2 真實網頁的抓取
作為標記設計稿的補充,網頁中的真實數據也是可靠的數據源,但是抓取網頁的過程中最大的難點在於判斷頁面中的節點屬於橫向還是縱向。
由於實現橫向排列的方式千奇百怪,可以通過float,inline-block,flex等等方法,我們如果只獲取網頁中節點的定位和寬高信息,還是需要手動標記他的佈局,所以還是要從節點的css入手,在批量獲取之後進行手動篩選,去掉低質量的數據。相對於標記的設計稿是一個有效的補充。
5.3 網頁生成器
為了更快的生成大量的數據,我們寫了一個網頁生成的演算法,在一開始就決定節點的定位方式,然後將節點渲染成網頁,最後在抓取節點的定位信息,但是隨機生成的數據存在一些不穩定的邊界場景,譬如生成的絕對定位的節點會正好定位到橫向佈局的右邊。這時就需要手動進行甄別。
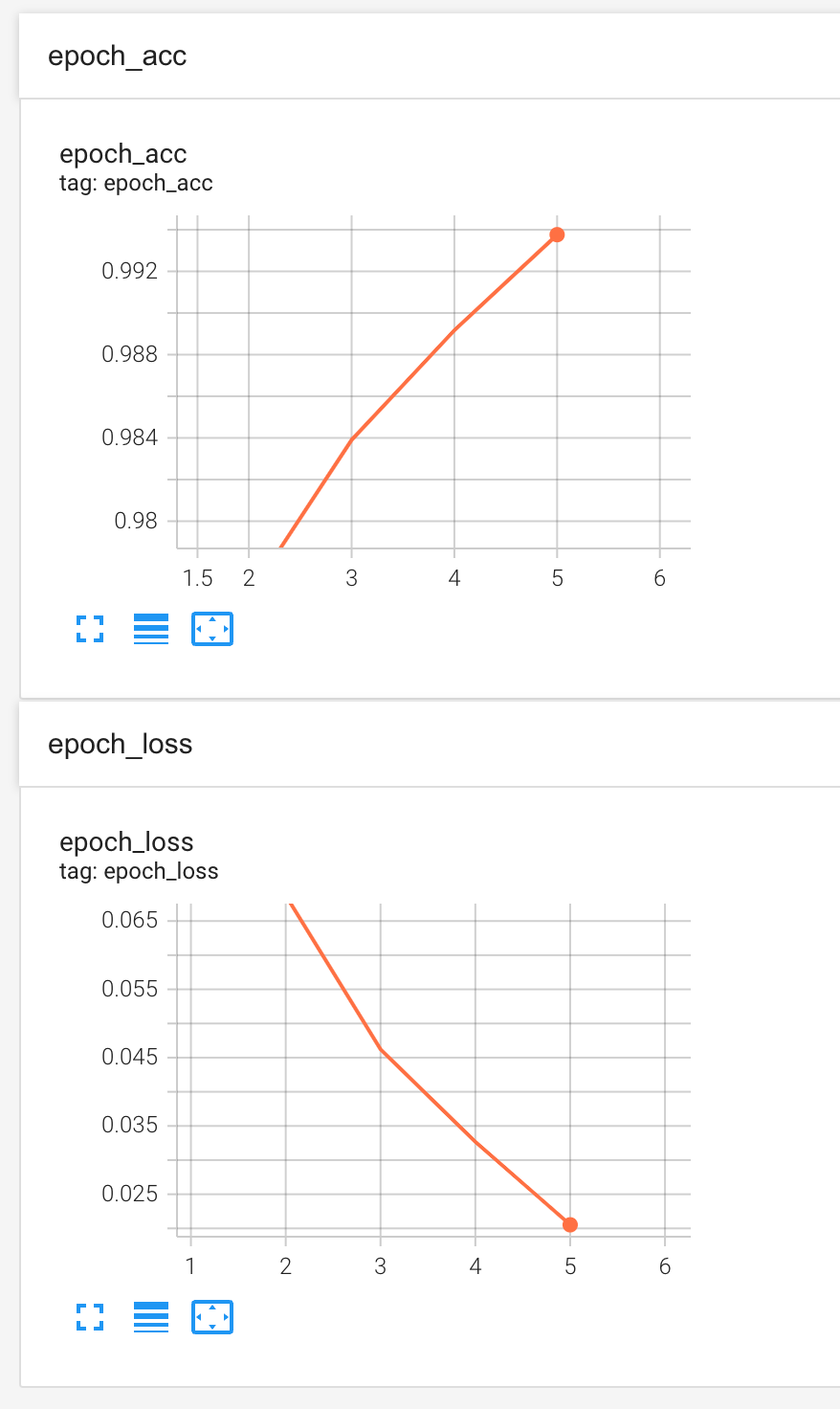
我們最終收集了大約兩萬多條數據,經過反覆的訓練與調試,最終準確率穩定在99.4%左右,達到一個相對可用的水*。
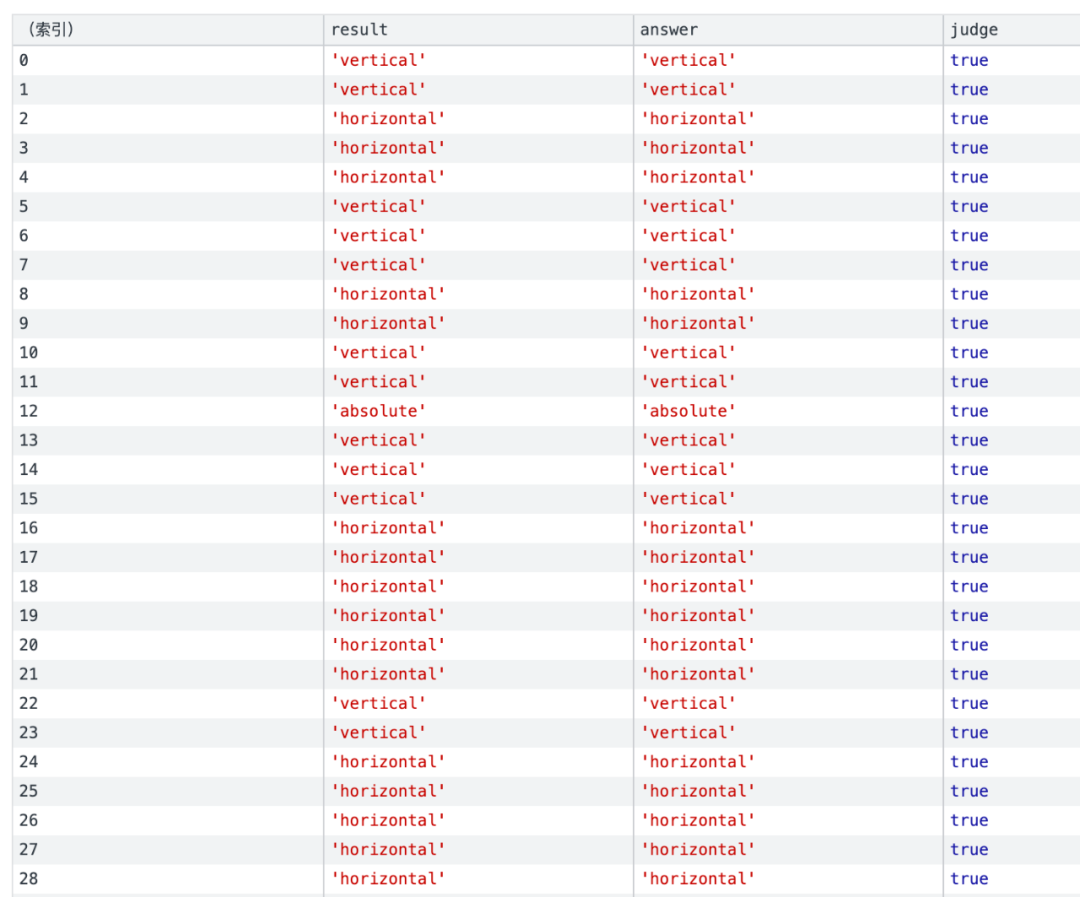
使用真實的dom進行回歸驗證,可以看出準確的識別出了網頁的橫向豎向佈局以及絕對定位的節點。
六、優化方向
6.1 元素換行
設計稿中會出現列表一行放不下然後換行的情況,這些節點應該是屬於橫向的位置關係,但是機器面對兩行會將每一行的首個元素識別成縱向排布,這就需要對重覆節點進行相似度檢測,對相似節點採用相同的佈局策略。
6.2 分組問題
基於規則的分組會導致兩個不相交的節點不會分配到一個組裡面,比如網格中的圖標和文字,導致佈局的時候會分成兩個獨立的組,可以通過訓練常見的佈局結合內容識別進行更精準的分組。
6.3 通用佈局
通過self-attention機制我們不僅可以判斷單個節點在其層級的佈局信息,我們也可以進行發散,通過訓練整個層級的節點數據得出當前節點屬於卡片流,標簽,個人信息頁等功能性的標記,進一步推導出每個節點的功能,再結合節點具體的佈局信息,不僅可以更好的實現網頁的排布,還可以節點的功能推到實現標簽的語義化。
6.4 數據生成
為瞭解決更多的網頁佈局問題,同時減少我們人工標記的工作量,可以運用強化學習模型開發一套網頁生成工具,讓我們的數據更接*真實的網頁佈局,從而使佈局模型訓練的結果更加貼*生產的場景。
七、總結
機器學習非常擅長處理分類問題,相比於傳統的手寫規則佈局,機器學習是基於我們現有的開發習慣進行訓練,最終生成的代碼也更加貼*我們*時的切圖習慣,代碼的可讀性和可維護性都更上一層樓。
而機器生成的靜態頁面相較於不同的人手寫的靜態頁面,遵循一致的代碼規範,代碼風格也更加統一。
在模型搭建的過程中可以將具體的使用場景類比為文本或者圖像領域的內容,便於尋找現有的模型進行遷移學習。
運用機器學習解決網頁佈局問題的核心在於建立節點的上下文的關聯,通過瞭解各種經典的神經網路模型的運行原理我們選出了迴圈神經網路和自註意力機制這種能夠建立上下文關聯的模型,而通過對於其運行原理的進一步瞭解我們選擇了更貼*網頁佈局場景以及運行效率更高的self-attention模型,由此也可以看出瞭解模型的運行機制可以更好的幫助我們解決實際的應用場景。
分享 vivo 互聯網技術乾貨與沙龍活動,推薦最新行業動態與熱門會議。

