
大家好,這篇文章主要跟大家聊下 Java 線程池面試中可能會問到的一些問題。 全程乾貨,耐心看完,你能輕鬆應對各種線程池面試。 相信各位 Javaer 在面試中或多或少肯定被問到過線程池相關問題吧,線程池是一個相對比較複雜的體系,基於此可以問出各種各樣、五花八門的問題。 若你很熟悉線程池,如果可以, ...
大家好,這篇文章主要跟大家聊下 Java 線程池面試中可能會問到的一些問題。
全程乾貨,耐心看完,你能輕鬆應對各種線程池面試。
相信各位 Javaer 在面試中或多或少肯定被問到過線程池相關問題吧,線程池是一個相對比較複雜的體系,基於此可以問出各種各樣、五花八門的問題。
若你很熟悉線程池,如果可以,完全可以滔滔不絕跟面試官扯一個小時線程池,一般面試也就一個小時左右,那麼這樣留給面試官問其他問題的時間就很少了,或者其他問題可能問的也就不深入了,那你通過面試的幾率是不就更大點了呢。

下麵我們開始列下線程池面試可能會被問到的問題以及該怎麼回答,以下只是參考答案,你也可以加入自己的理解。
1. 面試官:日常工作中有用到線程池嗎?什麼是線程池?為什麼要使用線程池?
一般面試官考察你線程池相關知識前,大概率會先問這個問題,如果你說沒用過,不瞭解,ok,那就沒以下問題啥事了,估計你的面試結果肯定也凶多吉少了。
作為 JUC 包下的門面擔當,線程池是名副其實的 JUC 一哥,不瞭解線程池,那說明你對 JUC 包其他工具也瞭解的不咋樣吧,對 JUC 沒深入研究過,那就是沒掌握到 Java 的精髓,給面試官這樣一個印象,那結果可想而知了。
所以說,這一分一定要吃下,那我們應該怎麼回答好這問題呢?
可以這樣說:
電腦發展到現在,摩爾定律在現有工藝水平下已經遇到難易突破的物理瓶頸,通過多核 CPU 並行計算來提升伺服器的性能已經成為主流,隨之出現了多線程技術。
線程作為操作系統寶貴的資源,對它的使用需要進行控制管理,線程池就是採用池化思想(類似連接池、常量池、對象池等)管理線程的工具。
JUC 給我們提供了 ThreadPoolExecutor 體系類來幫助我們更方便的管理線程、並行執行任務。
下圖是 Java 線程池繼承體系:
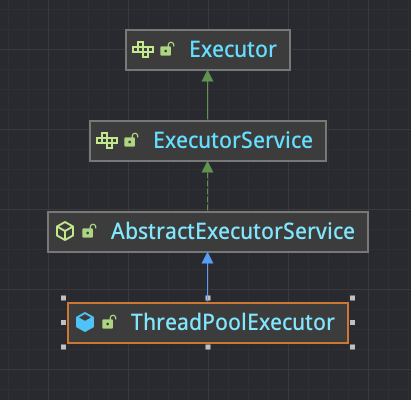
使用線程池可以帶來以下好處:
降低資源消耗。降低頻繁創建、銷毀線程帶來的額外開銷,復用已創建線程
降低使用複雜度。將任務的提交和執行進行解耦,我們只需要創建一個線程池,然後往裡面提交任務就行,具體執行流程由線程池自己管理,降低使用複雜度
提高線程可管理性。能安全有效的管理線程資源,避免不加限制無限申請造成資源耗盡風險
提高響應速度。任務到達後,直接復用已創建好的線程執行
線程池的使用場景簡單來說可以有:
快速響應用戶請求,響應速度優先。比如一個用戶請求,需要通過 RPC 調用好幾個服務去獲取數據然後聚合返回,此場景就可以用線程池並行調用,響應時間取決於響應最慢的那個 RPC 介面的耗時;又或者一個註冊請求,註冊完之後要發送簡訊、郵件通知,為了快速返回給用戶,可以將該通知操作丟到線程池裡非同步去執行,然後直接返回客戶端成功,提高用戶體驗。
單位時間處理更多請求,吞吐量優先。比如接受 MQ 消息,然後去調用第三方介面查詢數據,此場景並不追求快速響應,主要利用有限的資源在單位時間內儘可能多的處理任務,可以利用隊列進行任務的緩衝

2. 面試官:ThreadPoolExecutor 都有哪些核心參數?
其實一般面試官問你這個問題並不是簡單聽你說那幾個參數,而是想要你描述下線程池執行流程。
青銅回答:
包含核心線程數(corePoolSize)、最大線程數(maximumPoolSize),空閑線程超時時間(keepAliveTime)、時間單位(unit)、阻塞隊列(workQueue)、拒絕策略(handler)、線程工廠(ThreadFactory)這7個參數。
鑽石回答:
回答完包含這幾個參數之後,會再主動描述下線程池的執行流程,也就是 execute() 方法執行流程。
execute()方法執行邏輯如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
可以總結出如下主要執行流程,當然看上述代碼會有一些異常分支判斷,可以自己順理加到下述執行主流程里
判斷線程池的狀態,如果不是RUNNING狀態,直接執行拒絕策略
如果當前線程數 < 核心線程池,則新建一個線程來處理提交的任務
如果當前線程數 > 核心線程數且任務隊列沒滿,則將任務放入阻塞隊列等待執行
如果 核心線程池 < 當前線程池數 < 最大線程數,且任務隊列已滿,則創建新的線程執行提交的任務
如果當前線程數 > 最大線程數,且隊列已滿,則執行拒絕策略拒絕該任務
王者回答:
在回答完包含哪些參數及 execute 方法的執行流程後。然後可以說下這個執行流程是 JUC 標準線程池提供的執行流程,主要用在 CPU 密集型場景下。
像 Tomcat、Dubbo 這類框架,他們內部的線程池主要用來處理網路 IO 任務的,所以他們都對 JUC 線程池的執行流程進行了調整來支持 IO 密集型場景使用。
他們提供了阻塞隊列 TaskQueue,該隊列繼承 LinkedBlockingQueue,重寫了 offer() 方法來實現執行流程的調整。
@Override
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) return super.offer(o);
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o);
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o);
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false;
//if we reached here, we need to add it to the queue
return super.offer(o);
}
可以看到他在入隊之前做了幾個判斷,這裡的 parent 就是所屬的線程池對象
1.如果 parent 為 null,直接調用父類 offer 方法入隊
2.如果當前線程數等於最大線程數,則直接調用父類 offer()方法入隊
3.如果當前未執行的任務數量小於等於當前線程數,仔細思考下,是不是說明有空閑的線程呢,那麼直接調用父類 offer() 入隊後就馬上有線程去執行它
4.如果當前線程數小於最大線程數量,則直接返回 false,然後回到 JUC 線程池的執行流程回想下,是不是就去添加新線程去執行任務了呢
5.其他情況都直接入隊
具體可以看之前寫過的這篇文章
動態線程池(DynamicTp),動態調整Tomcat、Jetty、Undertow線程池參數篇
可以看出噹噹前線程數大於核心線程數時,JUC 原生線程池首先是把任務放到隊列里等待執行,而不是先創建線程執行。
如果 Tomcat 接收的請求數量大於核心線程數,請求就會被放到隊列中,等待核心線程處理,這樣會降低請求的總體響應速度。
所以 Tomcat並沒有使用 JUC 原生線程池,利用 TaskQueue 的 offer() 方法巧妙的修改了 JUC 線程池的執行流程,改寫後 Tomcat 線程池執行流程如下:
判斷如果當前線程數小於核心線程池,則新建一個線程來處理提交的任務
如果當前當前線程池數大於核心線程池,小於最大線程數,則創建新的線程執行提交的任務
如果當前線程數等於最大線程數,則將任務放入任務隊列等待執行
如果隊列已滿,則執行拒絕策略
然後還可以再說下線程池的 Worker 線程模型,繼承 AQS 實現了鎖機制。線程啟動後執行 runWorker() 方法,runWorker() 方法中調用 getTask() 方法從阻塞隊列中獲取任務,獲取到任務後先執行 beforeExecute() 鉤子函數,再執行任務,然後再執行 afterExecute() 鉤子函數。若超時獲取不到任務會調用 processWorkerExit() 方法執行 Worker 線程的清理工作。
詳細源碼解讀可以看之前寫的文章:

3. 面試官:什麼是阻塞隊列?說說常用的阻塞隊列有哪些?
阻塞隊列 BlockingQueue 繼承 Queue,是我們熟悉的基本數據結構隊列的一種特殊類型。
當從阻塞隊列中獲取數據時,如果隊列為空,則等待直到隊列有元素存入。當向阻塞隊列中存入元素時,如果隊列已滿,則等待直到隊列中有元素被移除。提供 offer()、put()、take()、poll() 等常用方法。
JDK 提供的阻塞隊列的實現有以下幾種:
1)ArrayBlockingQueue:由數組實現的有界阻塞隊列,該隊列按照 FIFO 對元素進行排序。維護兩個整形變數,標識隊列頭尾在數組中的位置,在生產者放入和消費者獲取數據共用一個鎖對象,意味著兩者無法真正的並行運行,性能較低。
2)LinkedBlockingQueue:由鏈表組成的有界阻塞隊列,如果不指定大小,預設使用 Integer.MAX_VALUE 作為隊列大小,該隊列按照 FIFO 對元素進行排序,對生產者和消費者分別維護了獨立的鎖來控制數據同步,意味著該隊列有著更高的併發性能。
3)SynchronousQueue:不存儲元素的阻塞隊列,無容量,可以設置公平或非公平模式,插入操作必須等待獲取操作移除元素,反之亦然。
4)PriorityBlockingQueue:支持優先順序排序的無界阻塞隊列,預設情況下根據自然序排序,也可以指定 Comparator。
5)DelayQueue:支持延時獲取元素的無界阻塞隊列,創建元素時可以指定多久之後才能從隊列中獲取元素,常用於緩存系統或定時任務調度系統。
6)LinkedTransferQueue:一個由鏈表結構組成的無界阻塞隊列,與LinkedBlockingQueue相比多了transfer和tryTranfer方法,該方法在有消費者等待接收元素時會立即將元素傳遞給消費者。
7)LinkedBlockingDeque:一個由鏈表結構組成的雙端阻塞隊列,可以從隊列的兩端插入和刪除元素。

4. 面試官:你剛說到了 Worker 繼承 AQS 實現了鎖機制,那 ThreadPoolExecutor 都用到了哪些鎖?為什麼要用鎖?
1)mainLock 鎖
ThreadPoolExecutor 內部維護了 ReentrantLock 類型鎖 mainLock,在訪問 workers 成員變數以及進行相關數據統計記賬(比如訪問 largestPoolSize、completedTaskCount)時需要獲取該重入鎖。
面試官:為什麼要有 mainLock?
private final ReentrantLock mainLock = new ReentrantLock();
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<Worker>();
/**
* Tracks largest attained pool size. Accessed only under
* mainLock.
*/
private int largestPoolSize;
/**
* Counter for completed tasks. Updated only on termination of
* worker threads. Accessed only under mainLock.
*/
private long completedTaskCount;
可以看到 workers 變數用的 HashSet 是線程不安全的,是不能用於多線程環境的。largestPoolSize、completedTaskCount 也是沒用 volatile 修飾,所以需要在鎖的保護下進行訪問。
面試官:為什麼不直接用個線程安全容器呢?
其實 Doug 老爺子在 mainLock 變數的註釋上解釋了,意思就是說事實證明,相比於線程安全容器,此處更適合用 lock,主要原因之一就是串列化 interruptIdleWorkers() 方法,避免了不必要的中斷風暴
面試官:怎麼理解這個中斷風暴呢?
其實簡單理解就是如果不加鎖,interruptIdleWorkers() 方法在多線程訪問下就會發生這種情況。一個線程調用interruptIdleWorkers() 方法對 Worker 進行中斷,此時該 Worker 出於中斷中狀態,此時又來一個線程去中斷正在中斷中的 Worker 線程,這就是所謂的中斷風暴。
面試官:那 largestPoolSize、completedTaskCount 變數加個 volatile 關鍵字修飾是不是就可以不用 mainLock 了?
這個其實 Doug 老爺子也考慮到了,其他一些內部變數能用 volatile 的都加了 volatile 修飾了,這兩個沒加主要就是為了保證這兩個參數的準確性,在獲取這兩個值時,能保證獲取到的一定是修改方法執行完成後的值。如果不加鎖,可能在修改方法還沒執行完成時,此時來獲取該值,獲取到的就是修改前的值。
2)Worker 線程鎖
剛也說了 Worker 線程繼承 AQS,實現了 Runnable 介面,內部持有一個 Thread 變數,一個 firstTask,及 completedTasks 三個成員變數。
基於 AQS 的 acquire()、tryAcquire() 實現了 lock()、tryLock() 方法,類上也有註釋,該鎖主要是用來維護運行中線程的中斷狀態。在 runWorker() 方法中以及剛說的 interruptIdleWorkers() 方法中用到了。
面試官:這個維護運行中線程的中斷狀態怎麼理解呢?
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
在runWorker() 方法中獲取到任務開始執行前,需要先調用 w.lock() 方法,lock() 方法會調用 tryAcquire() 方法,tryAcquire() 實現了一把非重入鎖,通過 CAS 實現加鎖。
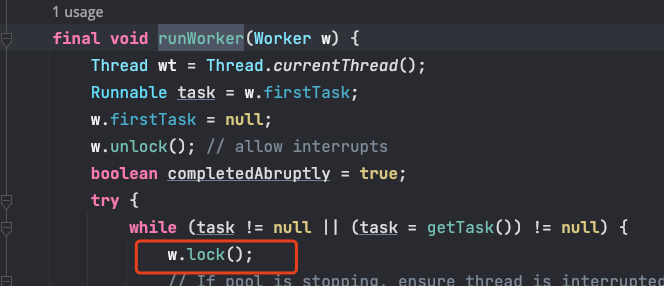
interruptIdleWorkers() 方法會中斷那些等待獲取任務的線程,會調用 w.tryLock() 方法來加鎖,如果一個線程已經在執行任務中,那麼 tryLock() 就獲取鎖失敗,就保證了不能中斷運行中的線程了。
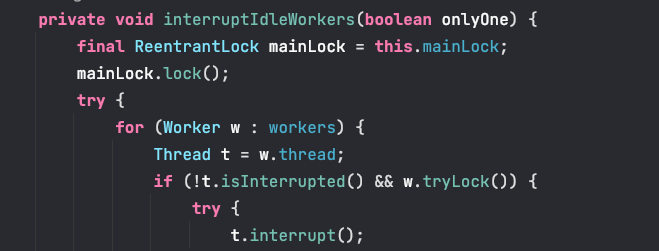
所以 Worker 繼承 AQS 主要就是為了實現了一把非重入鎖,維護線程的中斷狀態,保證不能中斷運行中的線程。

5. 面試官:你在項目中是怎樣使用線程池的?Executors 瞭解嗎?
這裡面試官主要想知道你日常工作中使用線程池的姿勢,現在大多數公司都在遵循阿裡巴巴 Java 開發規範,該規範里明確說明不允許使用
Executors 創建線程池,而是通過 ThreadPoolExecutor 顯示指定參數去創建
你可以這樣說,知道 Executors 工具類,很久之前有用過,也踩過坑,Executors 創建的線程池有發生 OOM 的風險。
Executors.newFixedThreadPool 和 Executors.SingleThreadPool 創建的線程池內部使用的是無界(Integer.MAX_VALUE)的 LinkedBlockingQueue 隊列,可能會堆積大量請求,導致 OOM
Executors.newCachedThreadPool 和Executors.scheduledThreadPool 創建的線程池最大線程數是用的Integer.MAX_VALUE,可能會創建大量線程,導致 OOM
自己在日常工作中也有封裝類似的工具類,但是都是記憶體安全的,參數需要自己指定適當的值,也有基於 LinkedBlockingQueue 實現了記憶體安全阻塞隊列 MemorySafeLinkedBlockingQueue,當系統記憶體達到設置的剩餘閾值時,就不在往隊列里添加任務了,避免發生 OOM
我們一般都是在 Spring 環境中使用線程池的,直接使用 JUC 原生 ThreadPoolExecutor 有個問題,Spring 容器關閉的時候可能任務隊列里的任務還沒處理完,有丟失任務的風險。
我們知道 Spring 中的 Bean 是有生命周期的,如果 Bean 實現了 Spring 相應的生命周期介面(InitializingBean、DisposableBean介面),在 Bean 初始化、容器關閉的時候會調用相應的方法來做相應處理。
所以最好不要直接使用 ThreadPoolExecutor 在 Spring 環境中,可以使用 Spring 提供的 ThreadPoolTaskExecutor,或者 DynamicTp 框架提供的 DtpExecutor 線程池實現。
也會按業務類型進行線程池隔離,各任務執行互不影響,避免共用一個線程池,任務執行參差不齊,相互影響,高耗時任務會占滿線程池資源,導致低耗時任務沒機會執行;同時如果任務之間存在父子關係,可能會導致死鎖的發生,進而引發 OOM。
更多使用姿勢參考之前發的文章:

6. 面試官:剛你說到了通過 ThreadPoolExecutor 來創建線程池,那核心參數設置多少合適呢?
這個問題該怎麼回答呢?
可能很多人都看到過《Java 併發編程事件》這本書里介紹的一個線程數計算公式:
Ncpu = CPU 核數
Ucpu = 目標 CPU 利用率,0 <= Ucpu <= 1
W / C = 等待時間 / 計算時間的比例
要程式跑到 CPU 的目標利用率,需要的線程數為:
Nthreads = Ncpu * Ucpu * (1 + W / C)
這公式太偏理論化了,很難實際落地下來,首先很難獲取準確的等待時間和計算時間。再著一個服務中會運行著很多線程,比如 Tomcat 有自己的線程池、Dubbo 有自己的線程池、GC 也有自己的後臺線程,我們引入的各種框架、中間件都有可能有自己的工作線程,這些線程都會占用 CPU 資源,所以通過此公式計算出來的誤差一定很大。
所以說怎麼確定線程池大小呢?
其實沒有固定答案,需要通過壓測不斷的動態調整線程池參數,觀察 CPU 利用率、系統負載、GC、記憶體、RT、吞吐量 等各種綜合指標數據,來找到一個相對比較合理的值。
所以不要再問設置多少線程合適了,這個問題沒有標準答案,需要結合業務場景,設置一系列數據指標,排除可能的干擾因素,註意鏈路依賴(比如連接池限制、三方介面限流),然後通過不斷動態調整線程數,測試找到一個相對合適的值。

7. 面試官:你們線程池是咋監控的?
因為線程池的運行相對而言是個黑盒,它的運行我們感知不到,該問題主要考察怎麼感知線程池的運行情況。
可以這樣回答:
我們自己對線程池 ThreadPoolExecutor 做了一些增強,做了一個線程池管理框架。主要功能有監控告警、動態調參。主要利用了 ThreadPoolExecutor 類提供的一些 set、get方法以及一些鉤子函數。
動態調參是基於配置中心實現的,核心參數配置在配置中心,可以隨時調整、實時生效,利用了線程池提供的 set 方法。
監控,主要就是利用線程池提供的一些 get 方法來獲取一些指標數據,然後採集數據上報到監控系統進行大盤展示。也提供了 Endpoint 實時查看線程池指標數據。
同時定義了5中告警規則。
線程池活躍度告警。活躍度 = activeCount / maximumPoolSize,當活躍度達到配置的閾值時,會進行事前告警。
隊列容量告警。容量使用率 = queueSize / queueCapacity,當隊列容量達到配置的閾值時,會進行事前告警。
拒絕策略告警。當觸發拒絕策略時,會進行告警。
任務執行超時告警。重寫 ThreadPoolExecutor 的 afterExecute() 和 beforeExecute(),根據當前時間和開始時間的差值算出任務執行時長,超過配置的閾值會觸發告警。
任務排隊超時告警。重寫 ThreadPoolExecutor 的 beforeExecute(),記錄提交任務時時間,根據當前時間和提交時間的差值算出任務排隊時長,超過配置的閾值會觸發告警
通過監控+告警可以讓我們及時感知到我們業務線程池的執行負載情況,第一時間做出調整,防止事故的發生。

8. 面試官:你在使用線程池的過程中遇到過哪些坑或者需要註意的地方?
這個問題其實也是在考察你對一些細節的掌握程度,就全甩鍋給年輕剛畢業沒經驗的自己就行。可以適當多說些,也證明自己對線程池有著豐富的使用經驗。
1)OOM 問題。剛開始使用線程都是通過 Executors 創建的,前面說了,這種方式創建的線程池會有發生 OOM 的風險。
2)任務執行異常丟失問題。可以通過下述4種方式解決
在任務代碼中增加 try、catch 異常處理
如果使用的 Future 方式,則可通過 Future 對象的 get 方法接收拋出的異常
為工作線程設置 setUncaughtExceptionHandler,在 uncaughtException 方法中處理異常
可以重寫 afterExecute(Runnable r, Throwable t) 方法,拿到異常 t
3)共用線程池問題。整個服務共用一個全局線程池,導致任務相互影響,耗時長的任務占滿資源,短耗時任務得不到執行。同時父子線程間會導致死鎖的發生,今兒導致 OOM
4)跟 ThreadLocal 配合使用,導致臟數據問題。我們知道 Tomcat 利用線程池來處理收到的請求,會復用線程,如果我們代碼中用到了 ThreadLocal,在請求處理完後沒有去 remove,那每個請求就有可能獲取到之前請求遺留的臟值。
5)ThreadLocal 線上程池場景下會失效,可以考慮用阿裡開源的 Ttl 來解決
以上提到的線程池動態調參、通知告警在開源動態線程池項目 DynamicTp 中已經實現了,可以直接引入到自己項目中使用。
關於 DynamicTp
DynamicTp 是一個基於配置中心實現的輕量級動態線程池管理工具,主要功能可以總結為動態調參、通知報警、運行監控、三方包線程池管理等幾大類。

經過多個版本迭代,目前最新版本 v1.0.8 具有以下特性
特性 ✅
-
代碼零侵入:所有配置都放在配置中心,對業務代碼零侵入
-
輕量簡單:基於 springboot 實現,引入 starter,接入只需簡單4步就可完成,順利3分鐘搞定
-
高可擴展:框架核心功能都提供 SPI 介面供用戶自定義個性化實現(配置中心、配置文件解析、通知告警、監控數據採集、任務包裝等等)
-
線上大規模應用:參考美團線程池實踐,美團內部已經有該理論成熟的應用經驗
-
多平臺通知報警:提供多種報警維度(配置變更通知、活性報警、容量閾值報警、拒絕觸發報警、任務執行或等待超時報警),已支持企業微信、釘釘、飛書報警,同時提供 SPI 介面可自定義擴展實現
-
監控:定時採集線程池指標數據,支持通過 MicroMeter、JsonLog 日誌輸出、Endpoint 三種方式,可通過 SPI 介面自定義擴展實現
-
任務增強:提供任務包裝功能,實現TaskWrapper介面即可,如 MdcTaskWrapper、TtlTaskWrapper、SwTraceTaskWrapper,可以支持線程池上下文信息傳遞
-
相容性:JUC 普通線程池和 Spring 中的 ThreadPoolTaskExecutor 也可以被框架監控,@Bean 定義時加 @DynamicTp 註解即可
-
可靠性:框架提供的線程池實現 Spring 生命周期方法,可以在 Spring 容器關閉前儘可能多的處理隊列中的任務
-
多模式:參考Tomcat線程池提供了 IO 密集型場景使用的 EagerDtpExecutor 線程池
-
支持多配置中心:基於主流配置中心實現線程池參數動態調整,實時生效,已支持 Nacos、Apollo、Zookeeper、Consul、Etcd,同時也提供 SPI 介面可自定義擴展實現
-
中間件線程池管理:集成管理常用第三方組件的線程池,已集成Tomcat、Jetty、Undertow、Dubbo、RocketMq、Hystrix等組件的線程池管理(調參、監控報警)
項目地址
目前累計 1.7k star,感謝你的 star,歡迎 pr,業務之餘一起給開源貢獻一份力量
gitee地址:https://gitee.com/dromara/dynamic-tp
github地址:https://github.com/dromara/dynamic-tp

