
Durid概述 Apache Druid是一個集時間序列資料庫、數據倉庫和全文檢索系統特點於一體的分析性數據平臺。本文將帶你簡單瞭解Druid的特性,使用場景,技術特點和架構。這將有助於你選型數據存儲方案,深入瞭解Druid存儲,深入瞭解時間序列存儲等。 Apache Druid是一個高性能的實時分 ...
Durid概述
Apache Druid是一個集時間序列資料庫、數據倉庫和全文檢索系統特點於一體的分析性數據平臺。本文將帶你簡單瞭解Druid的特性,使用場景,技術特點和架構。這將有助於你選型數據存儲方案,深入瞭解Druid存儲,深入瞭解時間序列存儲等。
Apache Druid是一個高性能的實時分析型資料庫。
上篇文章,我們瞭解了Druid的載入方式,
咱麽主要說兩種,一種是載入本地數據,一種是通過kafka載入流式數據。
數據攝取
4.1 載入本地文件
我們導入演示案例種的演示文件
4.1.1.1 數據選擇
通過UI選擇
local disk
並選擇
Connect data
4.1.1.2 演示數據查看
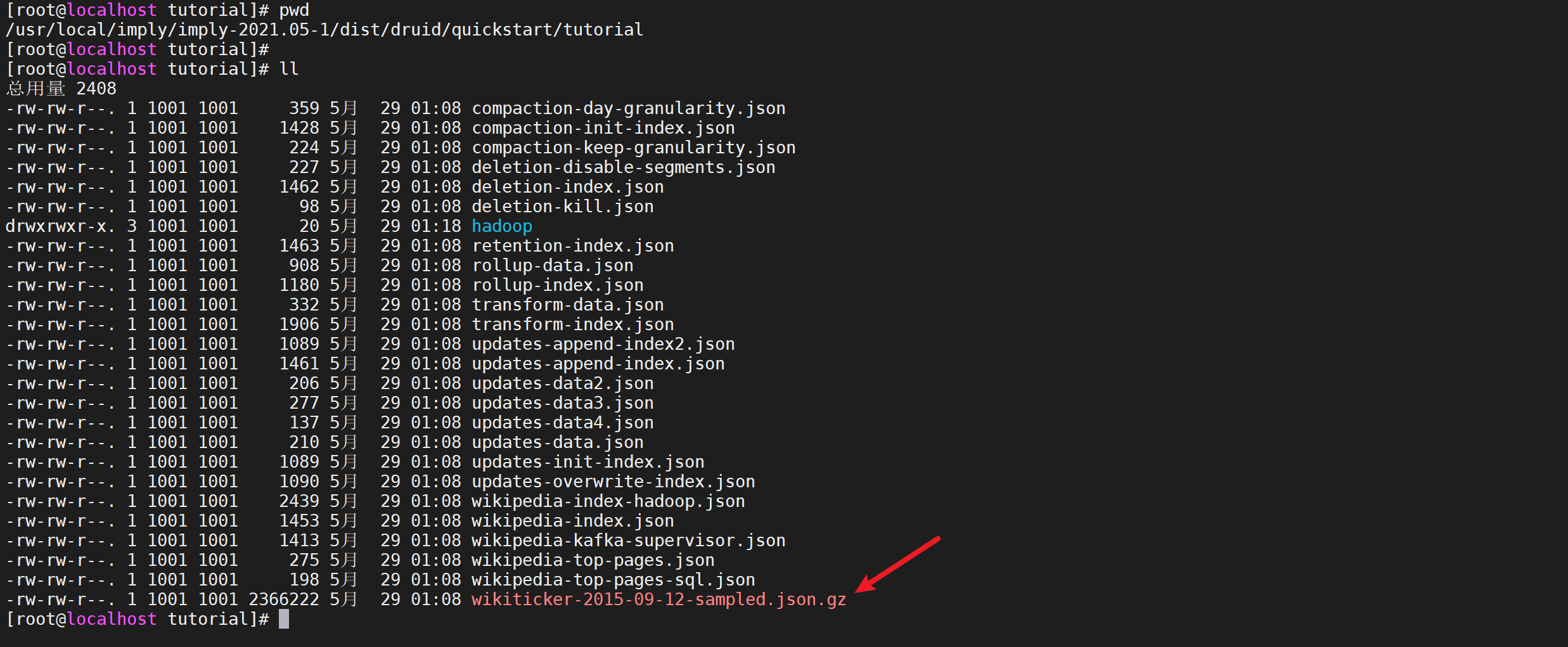
演示數據在
quickstart/tutorial目錄下的wikiticker-2015-09-12-sampled.json.gz文件
4.1.1.3 選擇數據源
因為我們是通過
imply安裝的,在Base directory輸入絕對路徑/usr/local/imply/imply-2021.05-1/dist/druid/quickstart/tutorial,File filter輸入wikiticker-2015-09-12-sampled.json.gz,並選擇apply應用配置,我們數據已經載入進來了
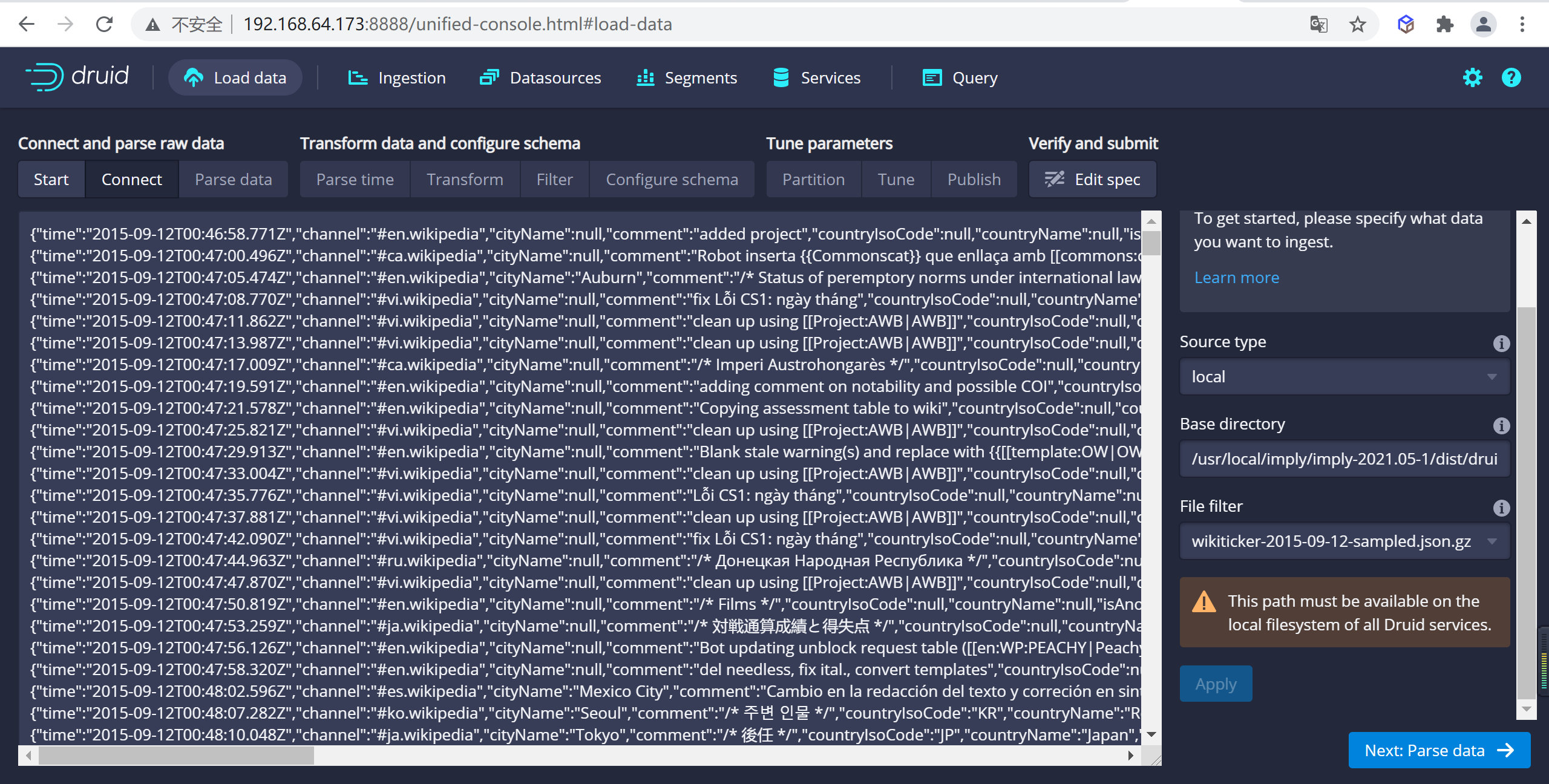
Base directory和File filter分開是因為可能需要同時從多個文件中攝取數據。
4.1.1.4 載入數據
數據定位後,您可以點擊"Next: Parse data"來進入下一步。
數據載入器將嘗試自動為數據確定正確的解析器。在這種情況下,它將成功確定
json。可以隨意使用不同的解析器選項來預覽Druid如何解析您的數據。
4.1.2 數據源規範配置
4.1.2.1 設置時間列
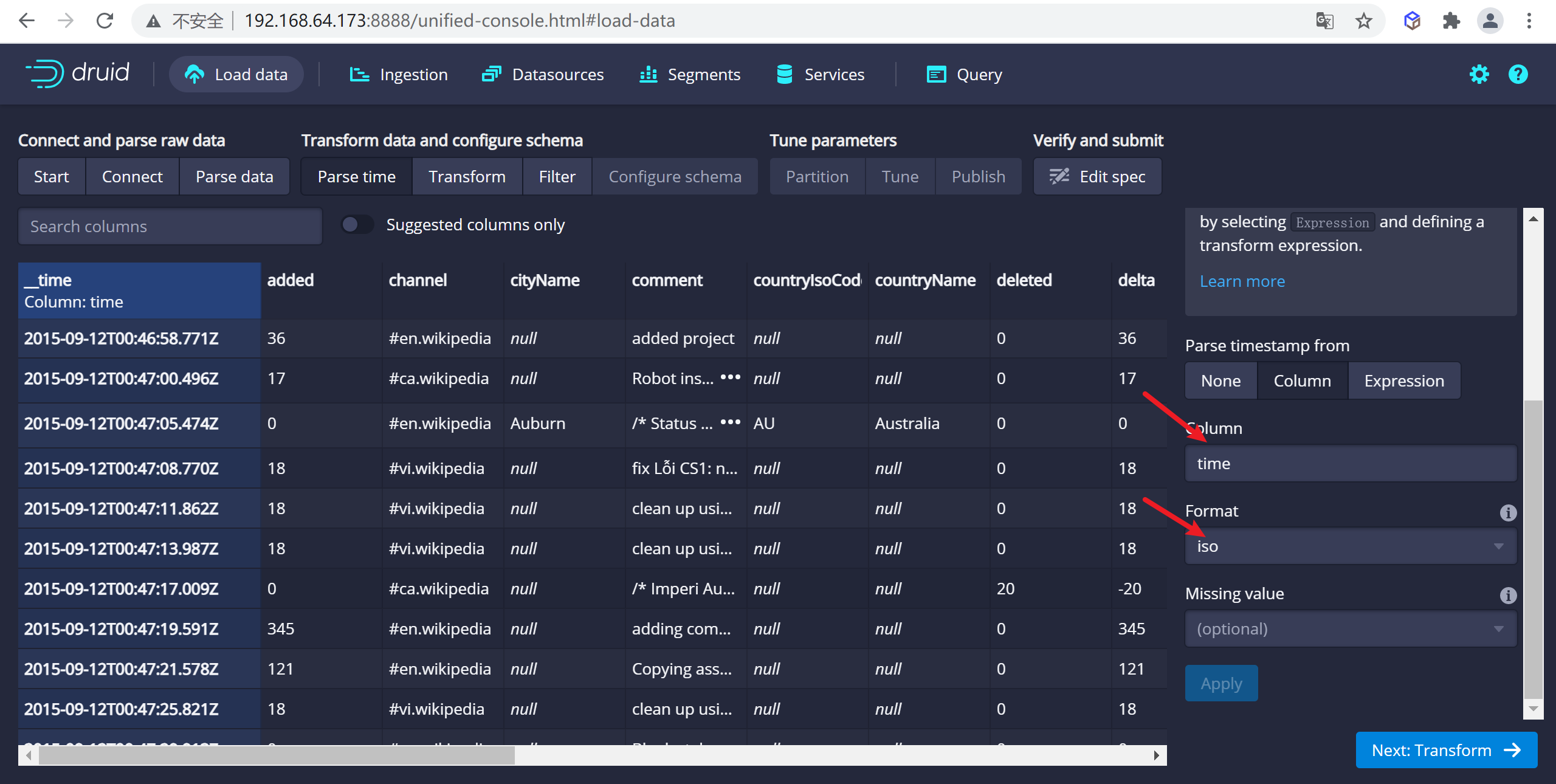
json選擇器被選中後,點擊Next:Parse time進入下一步來決定您的主時間列。
Druid的體繫結構需要一個主時間列(內部存儲為名為_time的列)。如果您的數據中沒有時間戳,請選擇 固定值(Constant Value) 。在我們的示例中,數據載入器將確定原始數據中的時間列是唯一可用作主時間列的候選者。
這裡可以選擇時間列,以及時間的顯示方式
4.1.2.2 設置轉換器
在這裡可以新增虛擬列,將一個列的數據轉換成另一個虛擬列,這裡我們沒有設置,直接跳過
4.1.2.3 設置過濾器
這裡可以設置過濾器,對於某些數據可以不進行顯示,這裡我們也跳過
4.1.2.4 配置schema
在
Configure schema步驟中,您可以配置將哪些維度和指標攝入到Druid中,這些正是數據在被Druid中攝取後出現的樣子。 由於我們的數據集非常小,關掉rollup、確認更改。
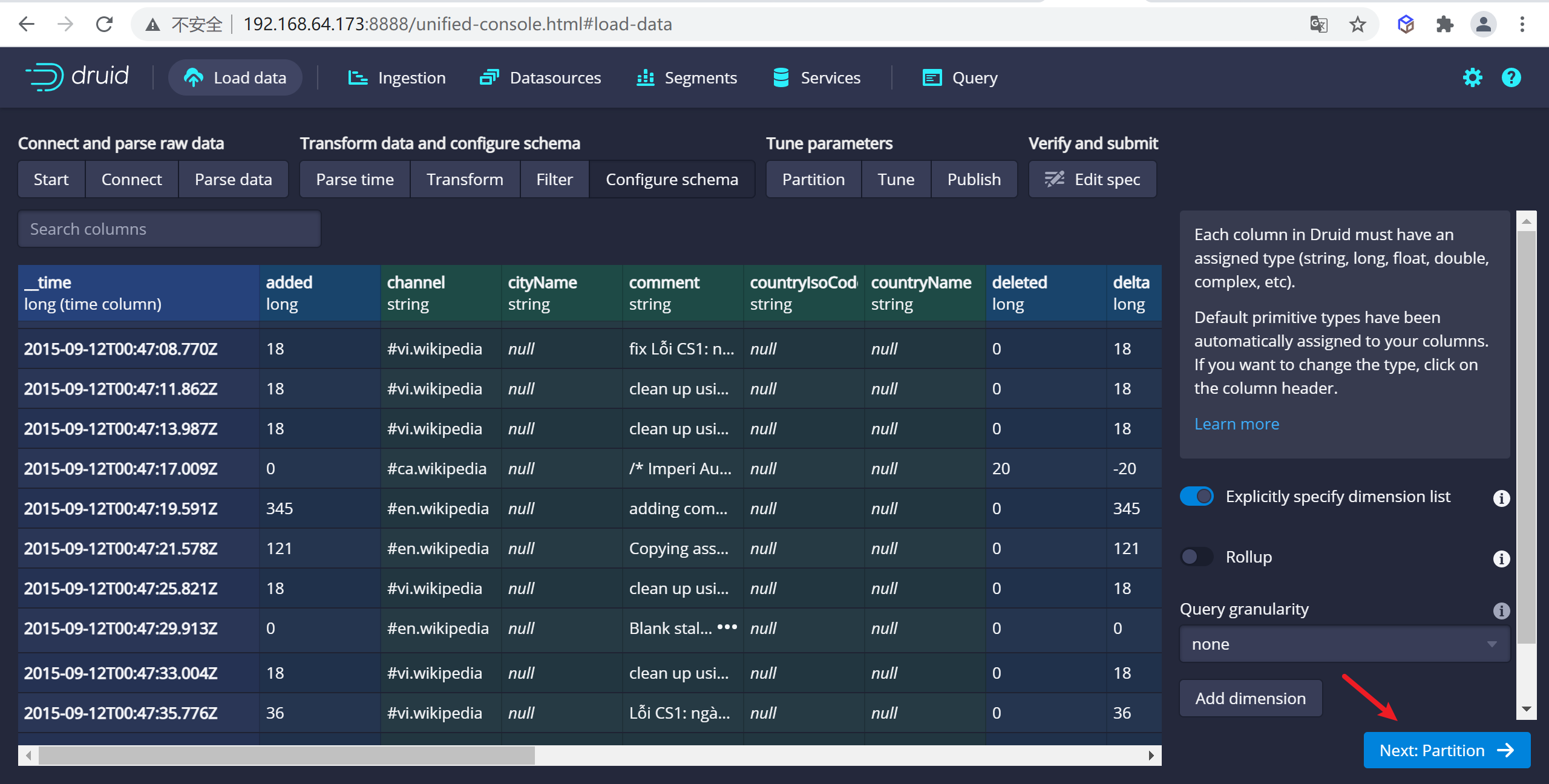
4.1.2.5 配置Partition
一旦對schema滿意後,點擊
Next後進入Partition步驟,該步驟中可以調整數據如何劃分為段文件的方式,因為我們數據量非常小,這裡我們按照DAY進行分段
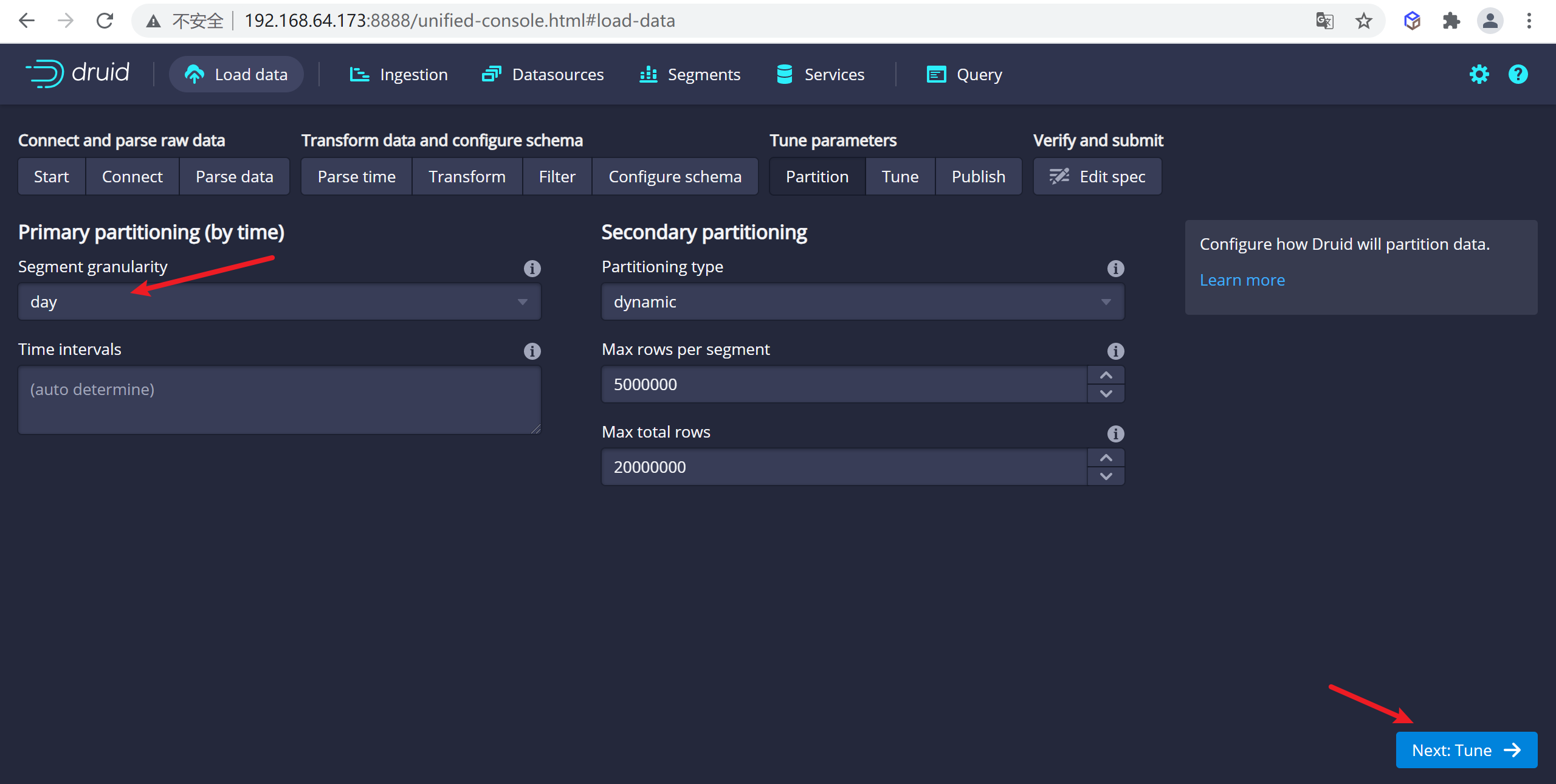
4.1.3 提交任務
4.1.3.1 發佈數據
點擊完成
Tune步驟,進入到Publish步,在這裡我們可以給我們的數據源命名,這裡我們就命名為druid-sampled,
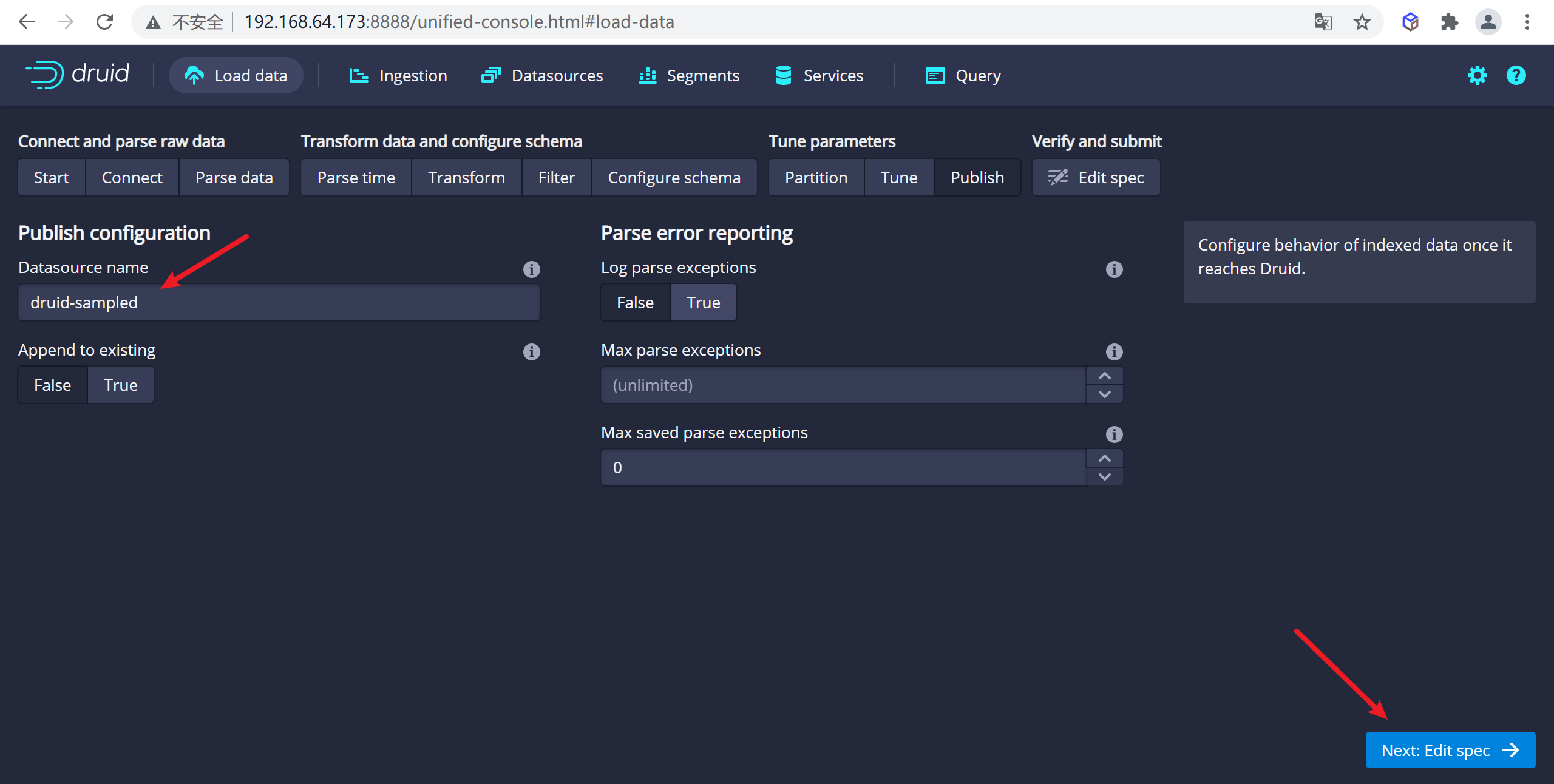
點擊下一步就可以查看我們的數據規範
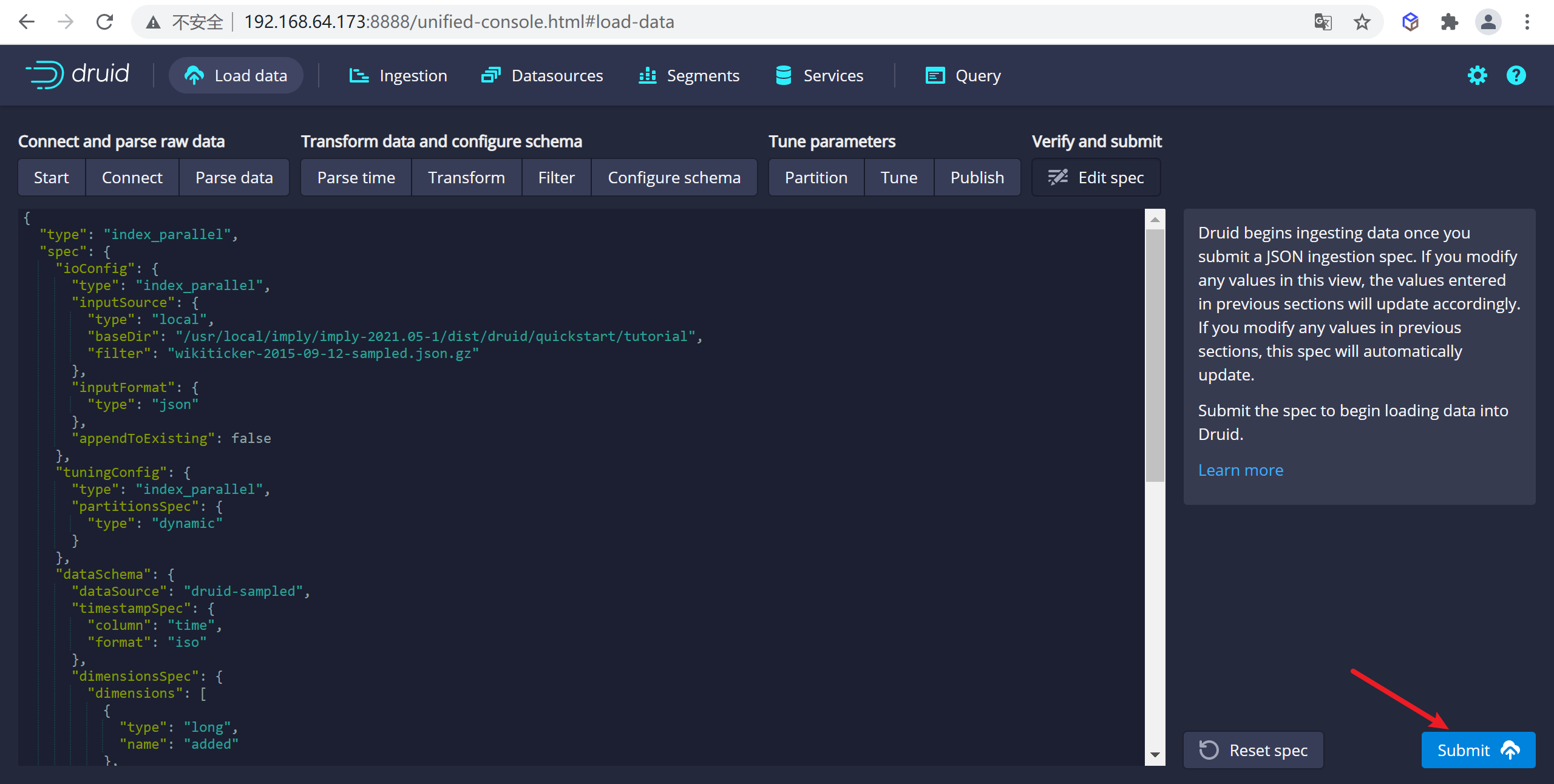
這就是您構建的規範,為了查看更改將如何更新規範是可以隨意返回之前的步驟中進行更改,同樣,您也可以直接編輯規範,併在前面的步驟中看到它。
4.1.3.2 提交任務
對攝取規範感到滿意後,請單擊
Submit,然後將創建一個數據攝取任務。
您可以進入任務視圖,重點關註新創建的任務。任務視圖設置為自動刷新,請等待任務成功。
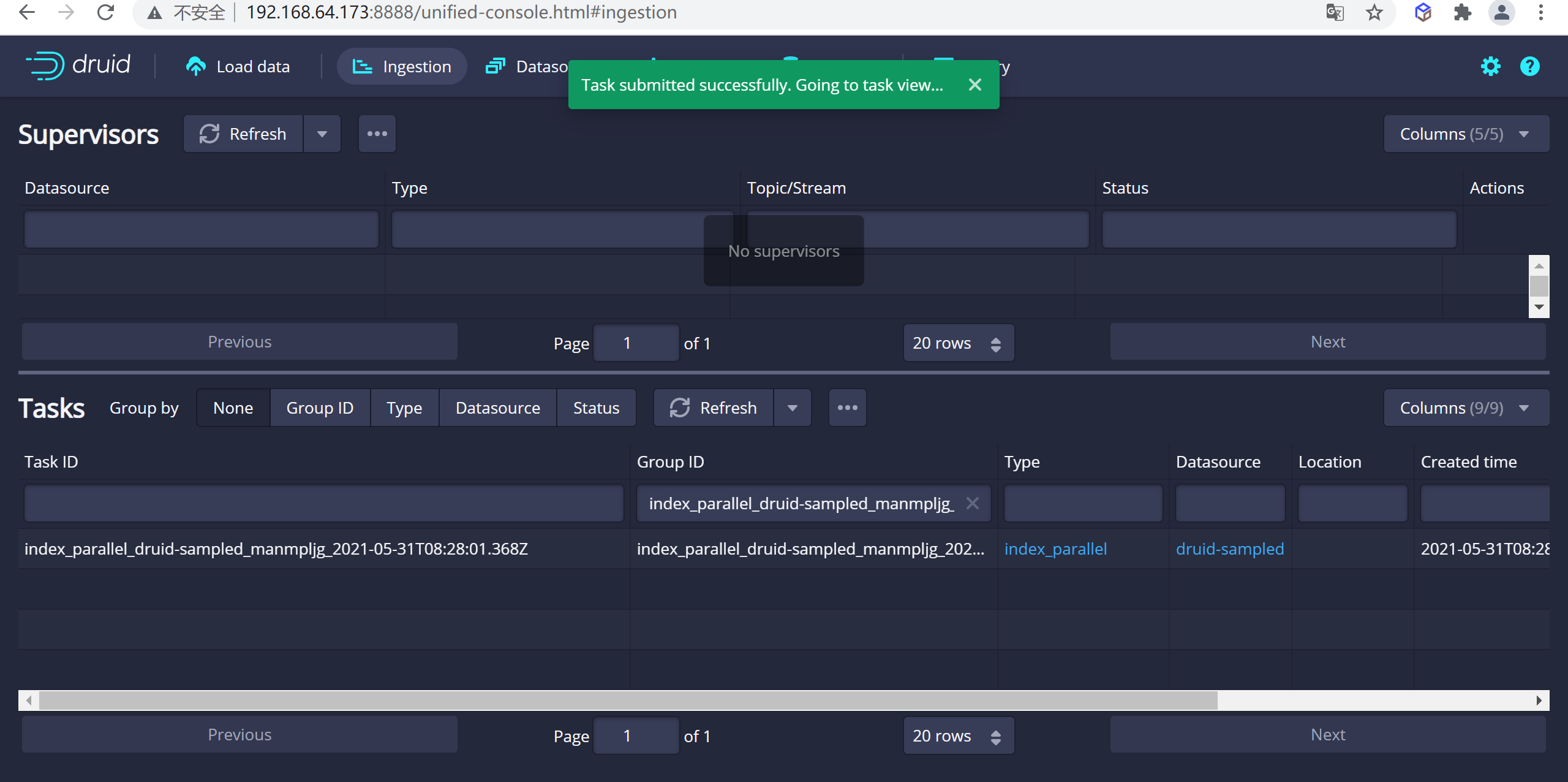
當一項任務成功完成時,意味著它建立了一個或多個段,這些段現在將由Data伺服器接收。
4.1.3.3 查看數據源
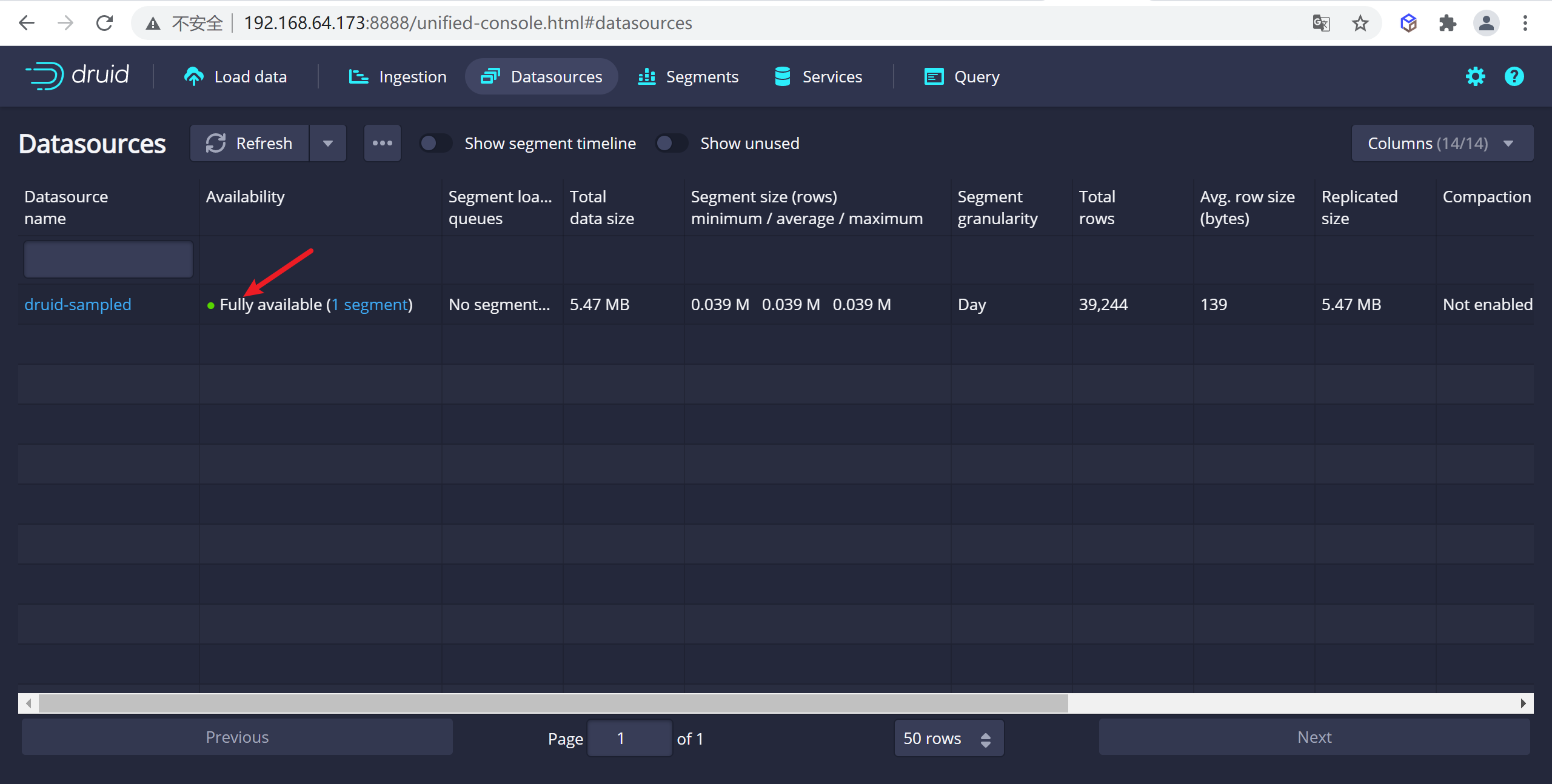
從標題導航到
Datasources視圖,一旦看到綠色(完全可用)圓圈,就可以查詢數據源。此時,您可以轉到Query視圖以對數據源運行SQL查詢。
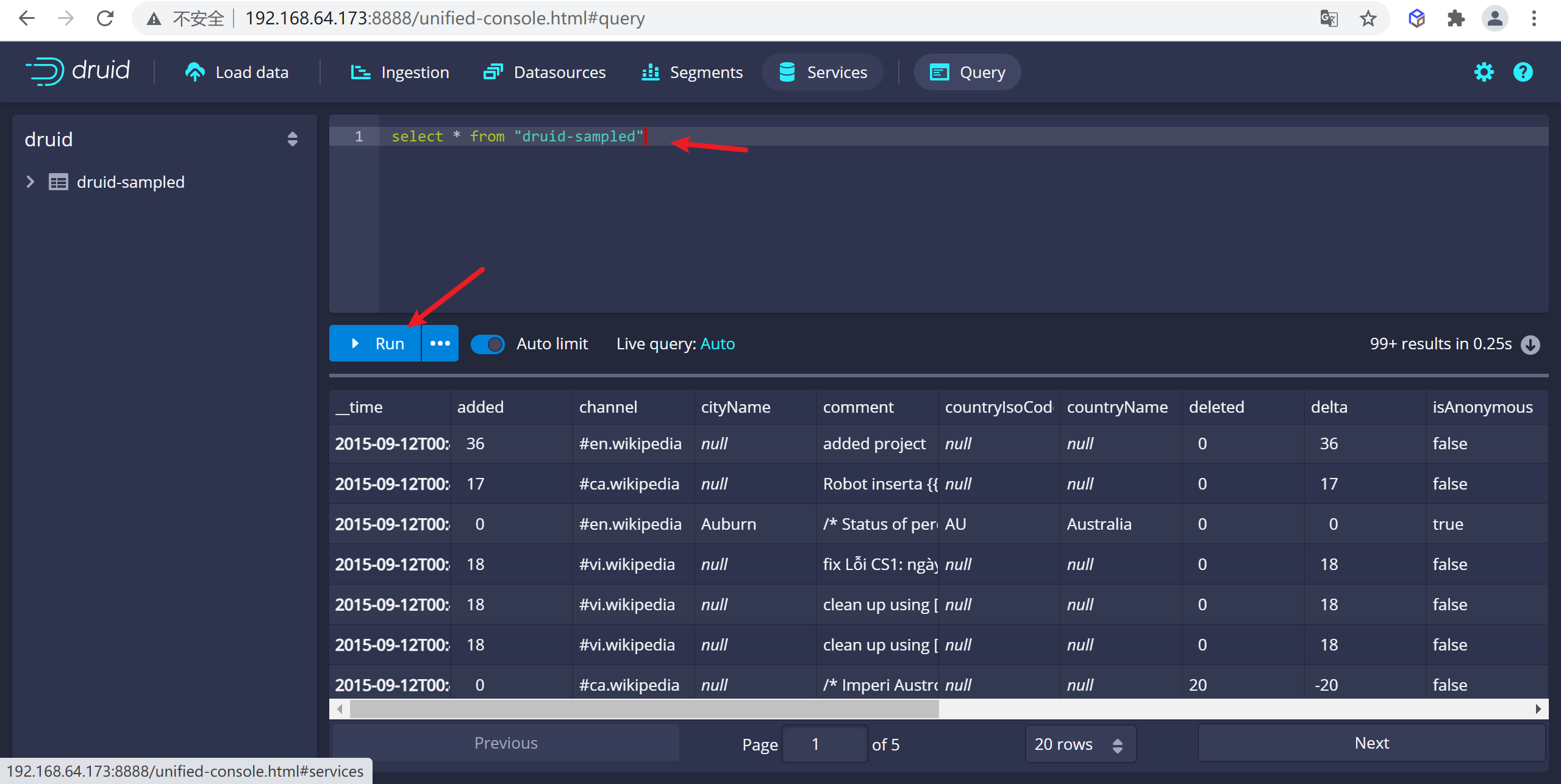
4.1.3.4 查詢數據
可以轉到查詢頁面進行數據查詢,這裡在sql視窗編寫sql後點擊運行就可以查詢數據了
4.2 kafka載入流式數據
4.2.1 安裝Kafka
這裡我們使用
docker-compose的方式啟動kafka
4.2.1.1 編輯資源清單
vi docker-compose.yml
version: '2'
services:
zookeeper:
image: zookeeper
container_name: zookeeper
ports:
- 2181:2181
kafka:
image: wurstmeister/kafka ## 鏡像
volumes:
- /etc/localtime:/etc/localtime ## 掛載位置(kafka鏡像和宿主機器之間時間保持一直)
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.64.190 ## 修改:宿主機IP
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 ## 卡夫卡運行是基於zookeeper的
KAFKA_ADVERTISED_PORT: 9092
KAFKA_LOG_RETENTION_HOURS: 120
KAFKA_MESSAGE_MAX_BYTES: 10000000
KAFKA_REPLICA_FETCH_MAX_BYTES: 10000000
KAFKA_GROUP_MAX_SESSION_TIMEOUT_MS: 60000
KAFKA_NUM_PARTITIONS: 3
KAFKA_DELETE_RETENTION_MS: 1000
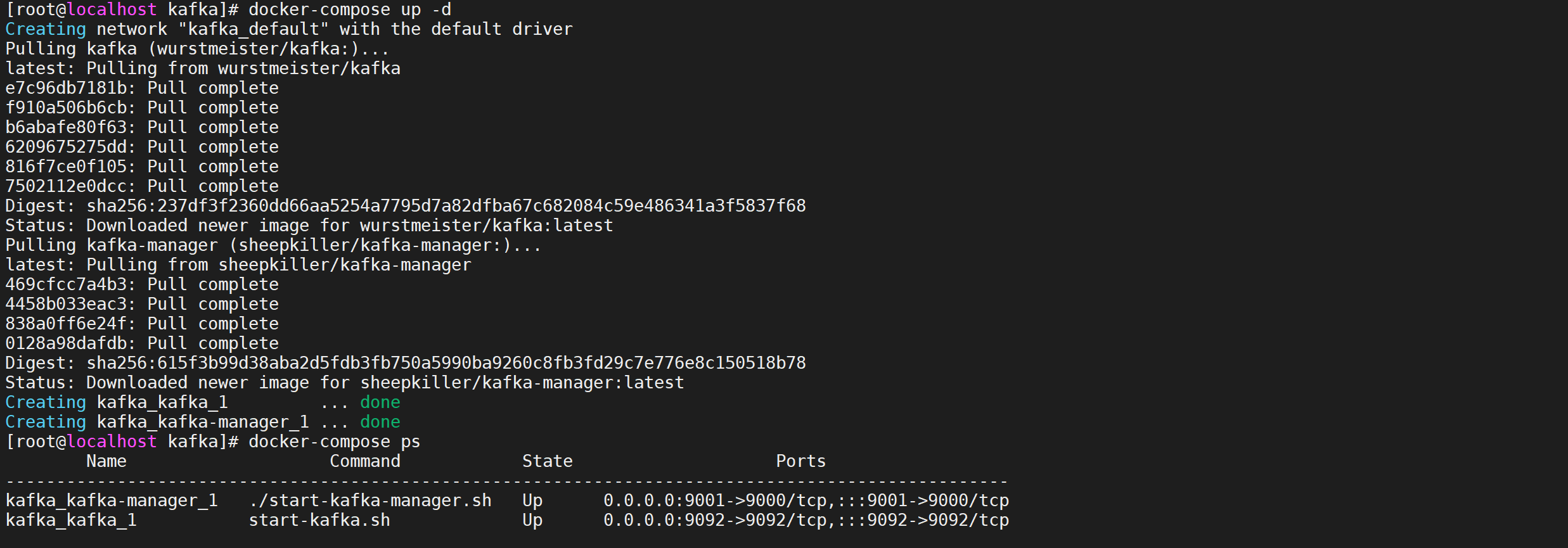
4.2.2.2 啟動容器
docker-compose up -d
docker-compose ps
4.2.3 驗證kafka
啟動kafka後需要驗證kafka是否可用
4.2.3.1 登錄容器
登錄容器併進入指定目錄
#進入容器
docker exec -it kafka_kafka_1 bash
#進入 /opt/kafka_2.13-2.7.0/bin/ 目錄下
cd /opt/kafka_2.13-2.7.0/bin/

4.2.3.2 發送消息
運行客戶端發送消息,註意這裡的連接地址需要寫我們配置的宿主機地址
#運行kafka生產者發送消息
./kafka-console-producer.sh --broker-list 192.168.64.173:9092 --topic test
發送的數據如下
{"datas":[{"channel":"","metric":"temperature","producer":"ijinus","sn":"IJA0101-00002245","time":"1543207156000","value":"80"}],"ver":"1.0"}

4.2.3.3 消費消息
運行消費者消費消息
./kafka-console-consumer.sh --bootstrap-server 192.168.64.173:9092 --topic test --from-beginning

有數據列印說明我們kafka安裝是沒有問題的
4.2.4 發送數據到kafka
4.2.4.1 編寫代碼
編寫代碼發送消息到kafka中
@Component
public class KafkaSender {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 發送消息到kafka
*
* @param topic 主題
* @param message 內容體
*/
public void sendMsg(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
@RestController
@RequestMapping("/taxi")
public class KafkaController {
@Autowired
private KafkaSender kafkaSender;
@RequestMapping("/batchTask/{num}")
public String batchAdd(@PathVariable("num") int num) {
for (int i = 0; i < num; i++) {
Message message = Utils.getRandomMessage();
kafkaSender.sendMsg("message", JSON.toJSONString(message));
}
return "OK";
}
}
4.2.4.2 發送消息
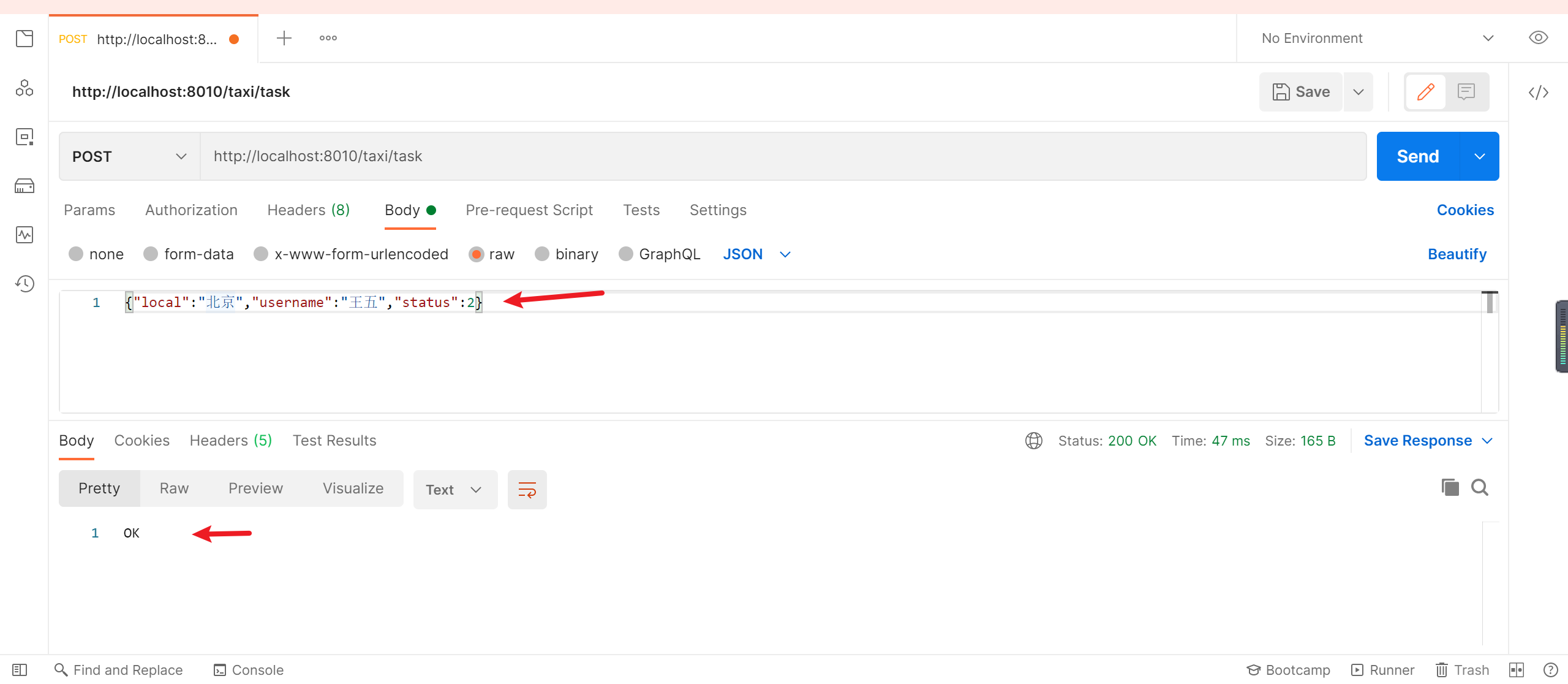
使用postman 發送消息到kafka,消息地址:http://localhost:8010/taxi/batchTask/10,消息數據如下
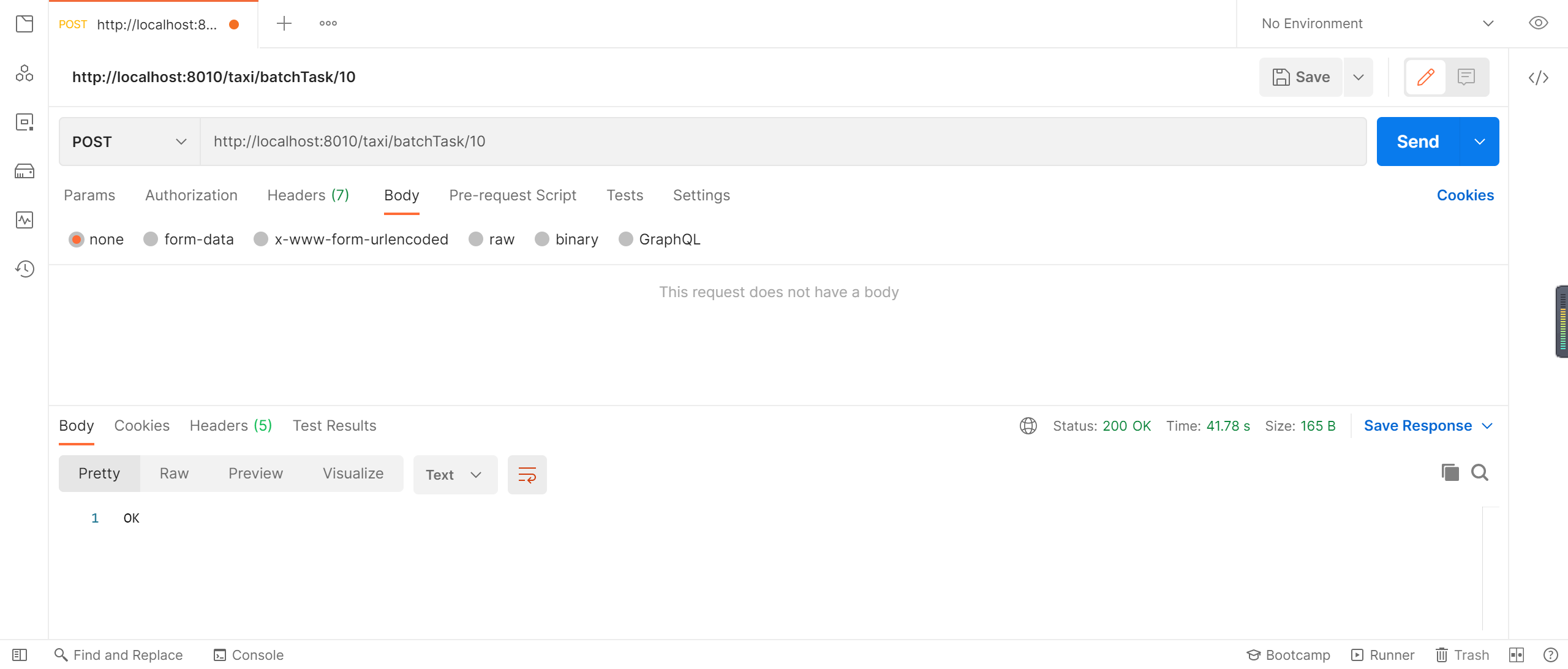
顯示OK說明消息已經發送到了kafka中
4.2.5 數據選擇
4.2.51 kafka數據查看
在load頁面選擇kafka,進行數據攝取模式選擇
4.2.5.2 選擇數據源
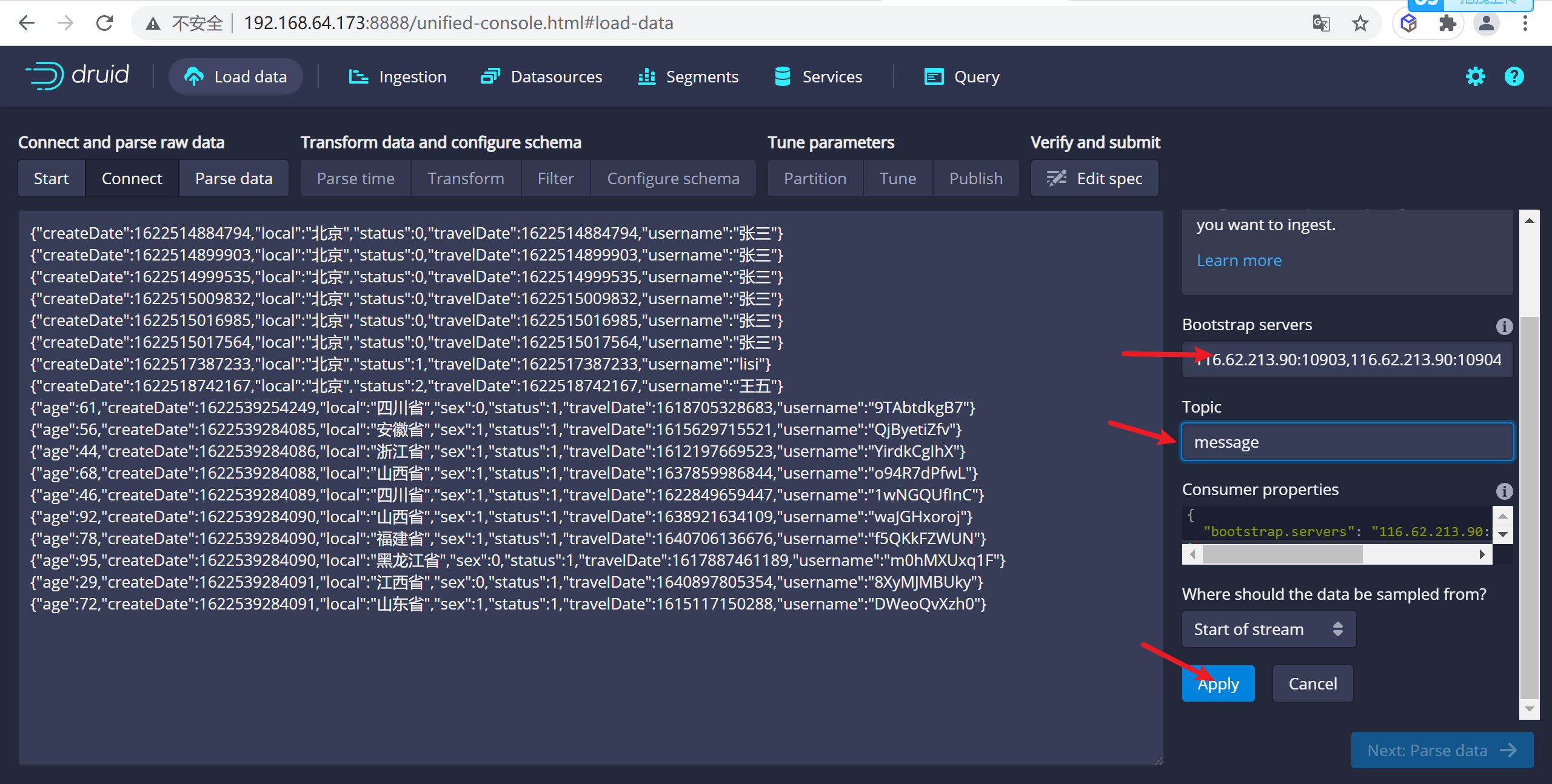
在這裡輸入ZK的地址以及需要選擇數據的
topic
116.62.213.90:10903,116.62.213.90:10904
4.2.5.3 載入數據
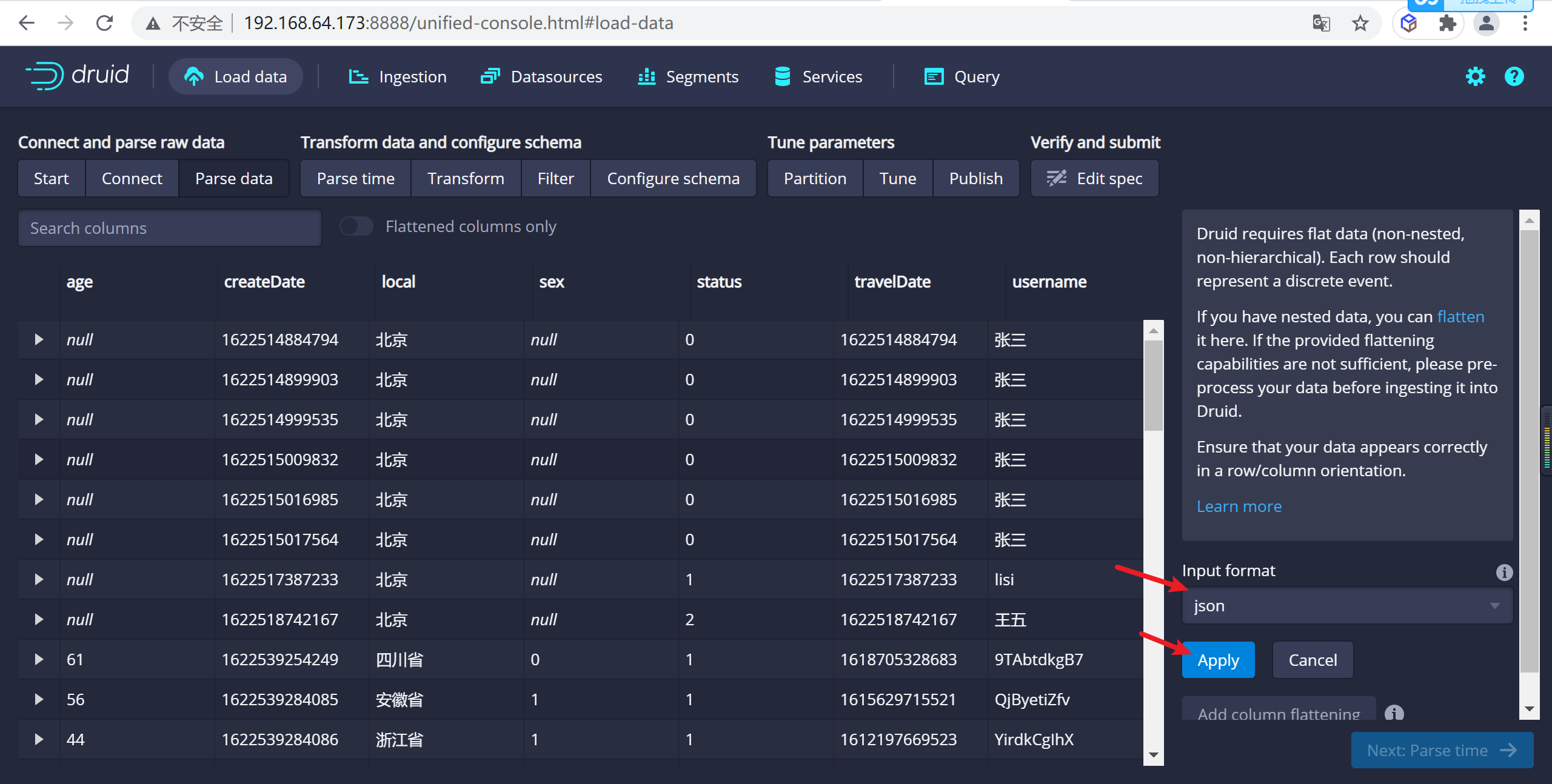
點擊
apply應用配置,設置載入數據源
4.2.6 數據源規範配置
4.2.6.1 設置時間列
json選擇器被選中後,點擊Next:Parse time進入下一步來決定您的主時間列。
因為我們的時間列有兩個創建時間以及打車時間,我們配置時間列為trvelDate
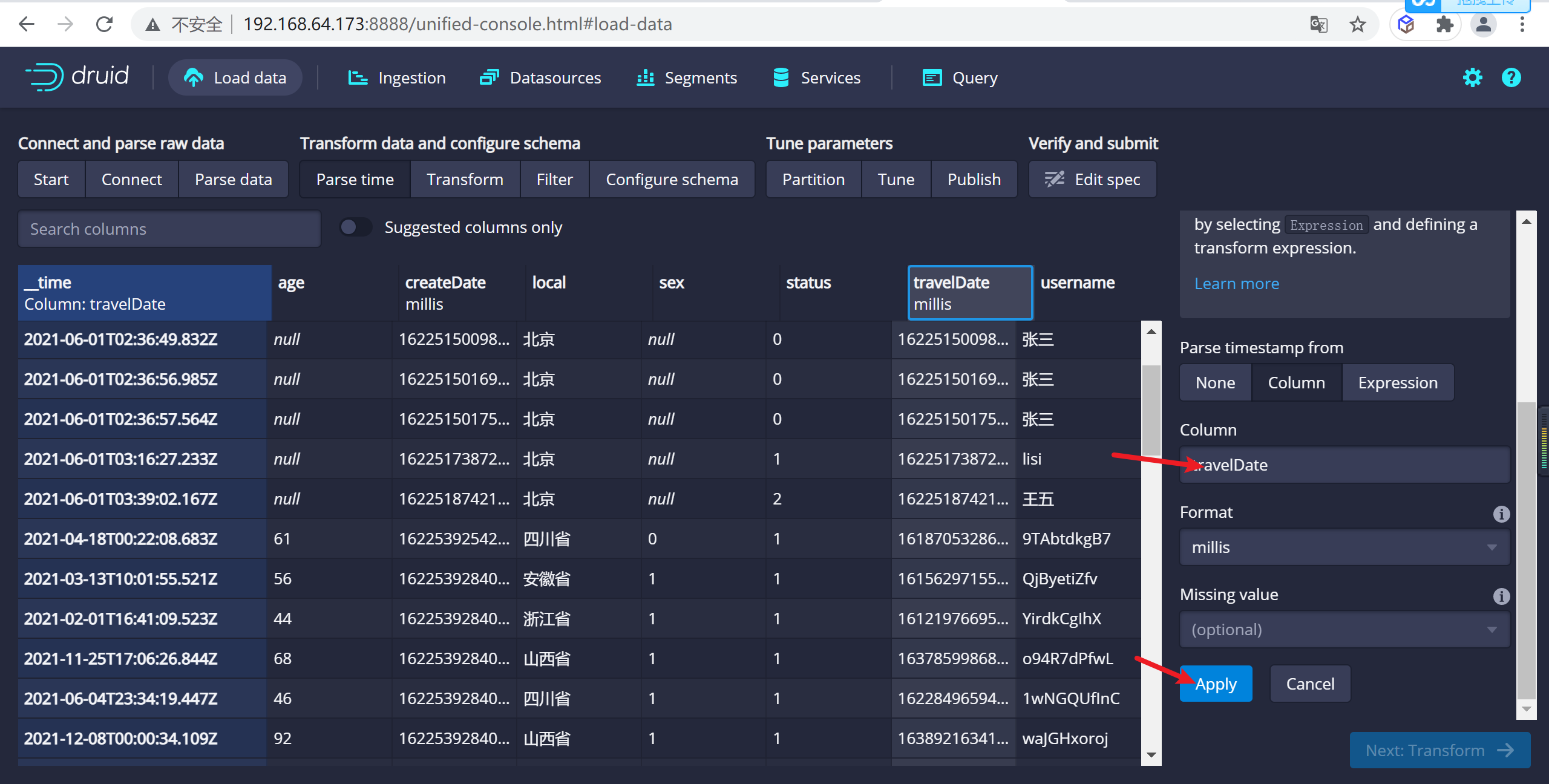
4.2.6.2 設置轉換器
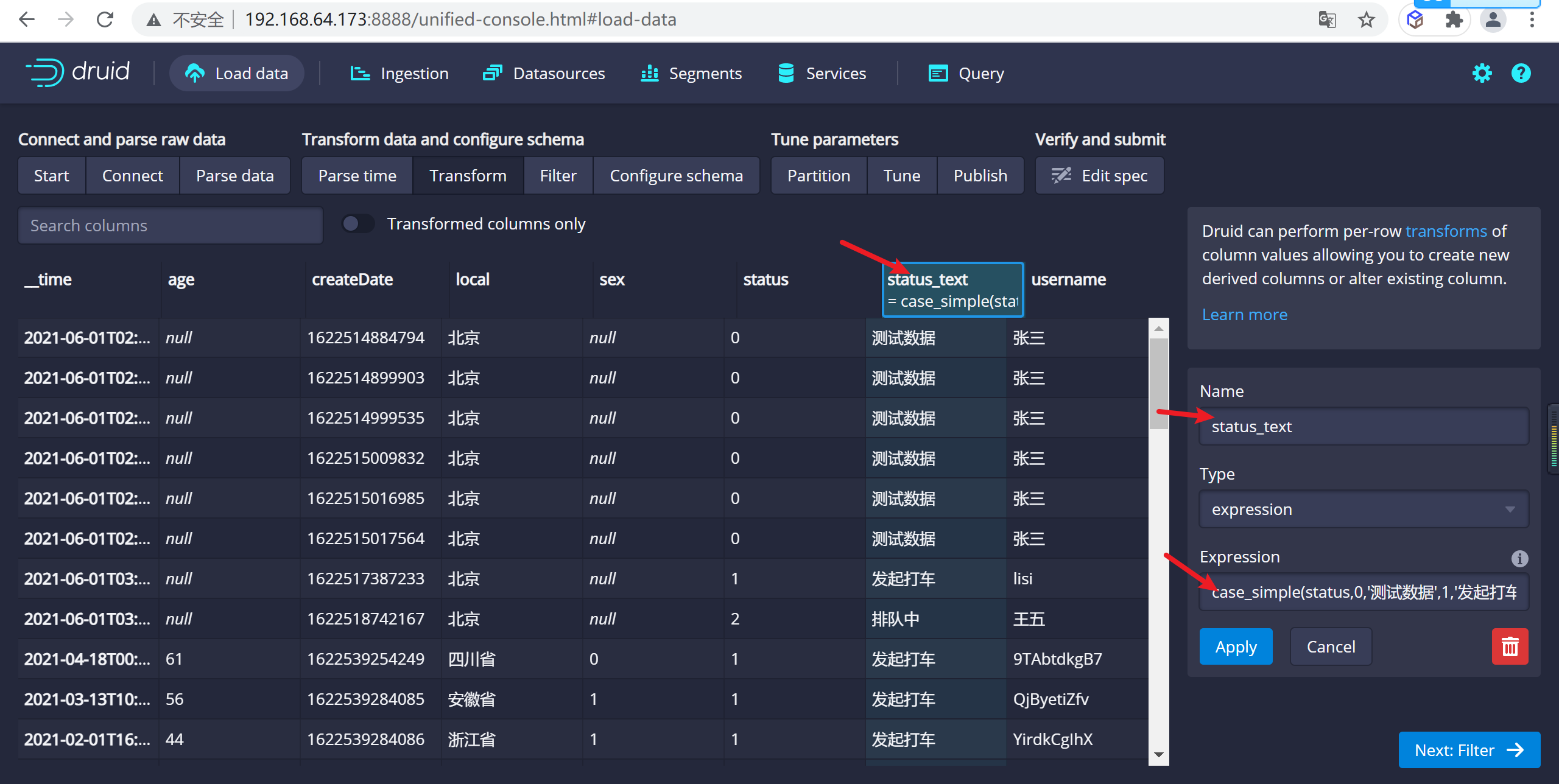
在這裡可以新增虛擬列,將一個列的數據轉換成另一個虛擬列,這裡我們增加一個狀態的虛擬列,來顯示狀態的中文名稱我們定義 0:測試數據, 1:發起打車,2:排隊中,3:司機接單,4:乘客上車,5:完成打車
我們使用case_simple來實現判斷功能,更多判斷功能參考
case_simple(status,0,'測試數據',1,'發起打車',2,'排隊中',3,'司機接單',4,'完成打車','狀態錯誤')
在這裡我們新建了一個
status_text的虛擬列來展示需要中文顯示的列
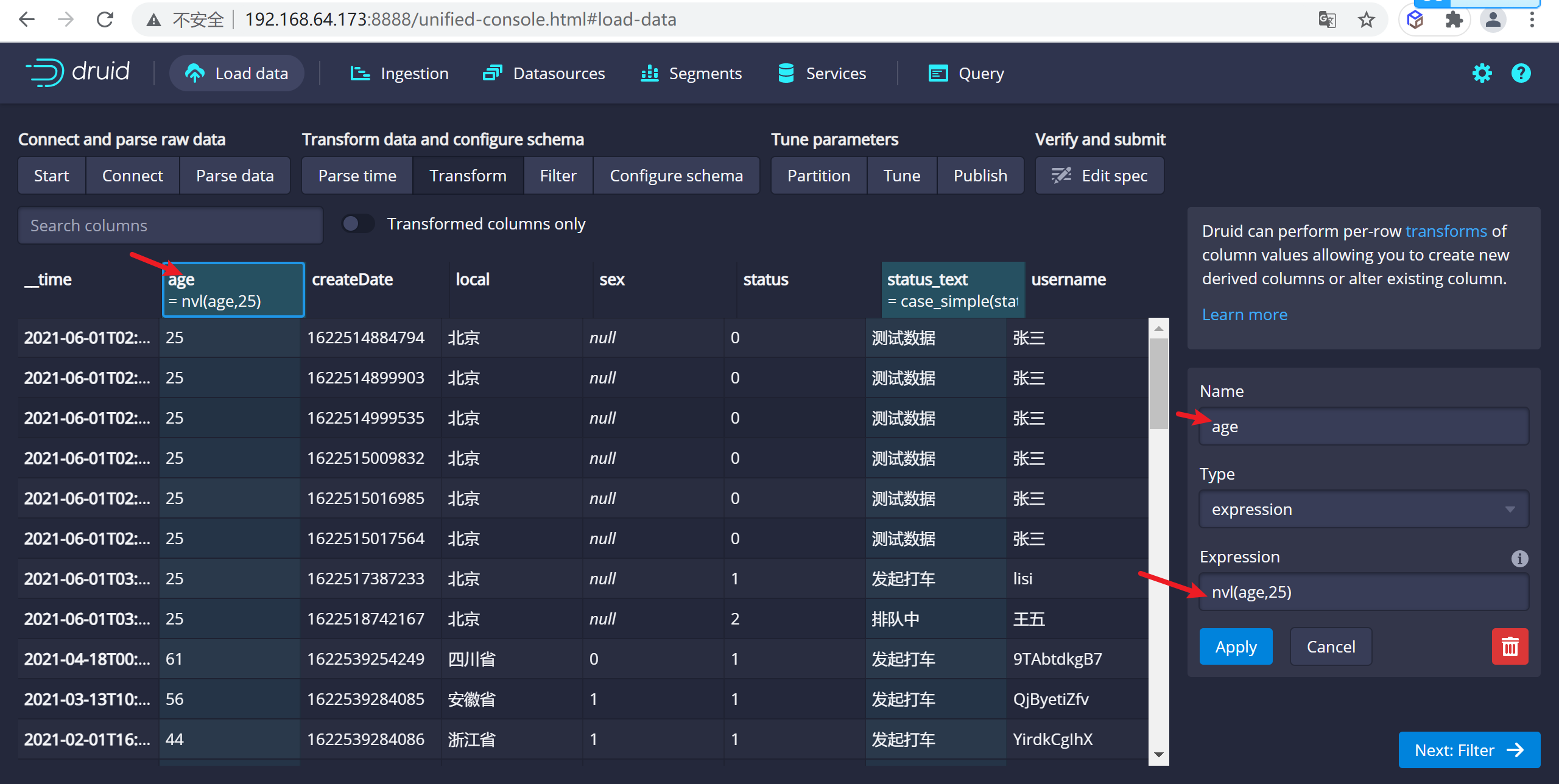
配置年齡預設值,如果為空我們設置為25
nvl(age,25)
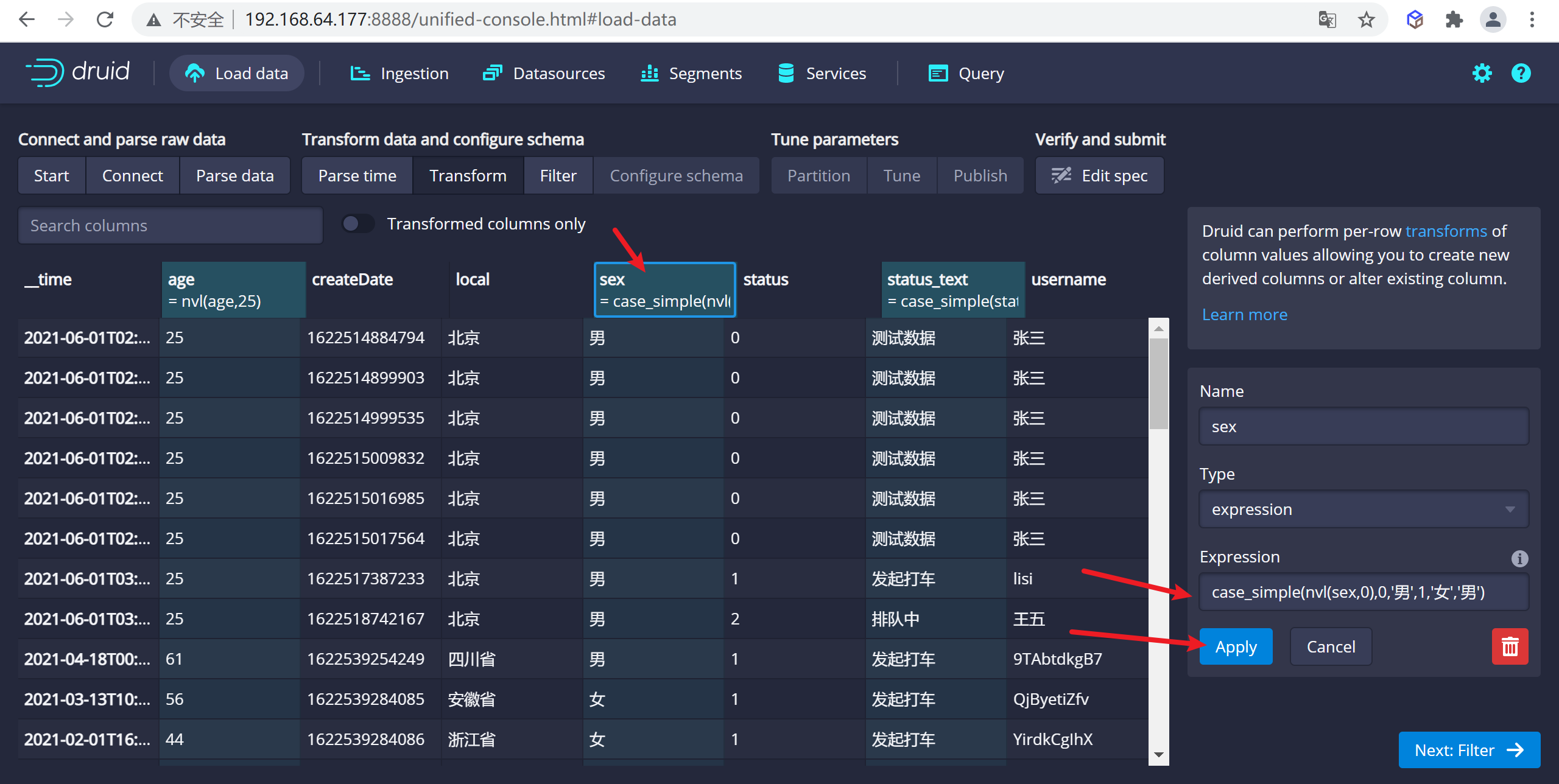
配置性別設置,我們需要設置為男女,0:男,1:女,如果為null,我們設置為男
case_simple(nvl(sex,0),0,'男',1,'女','男')
4.2.6.3 設置過濾器
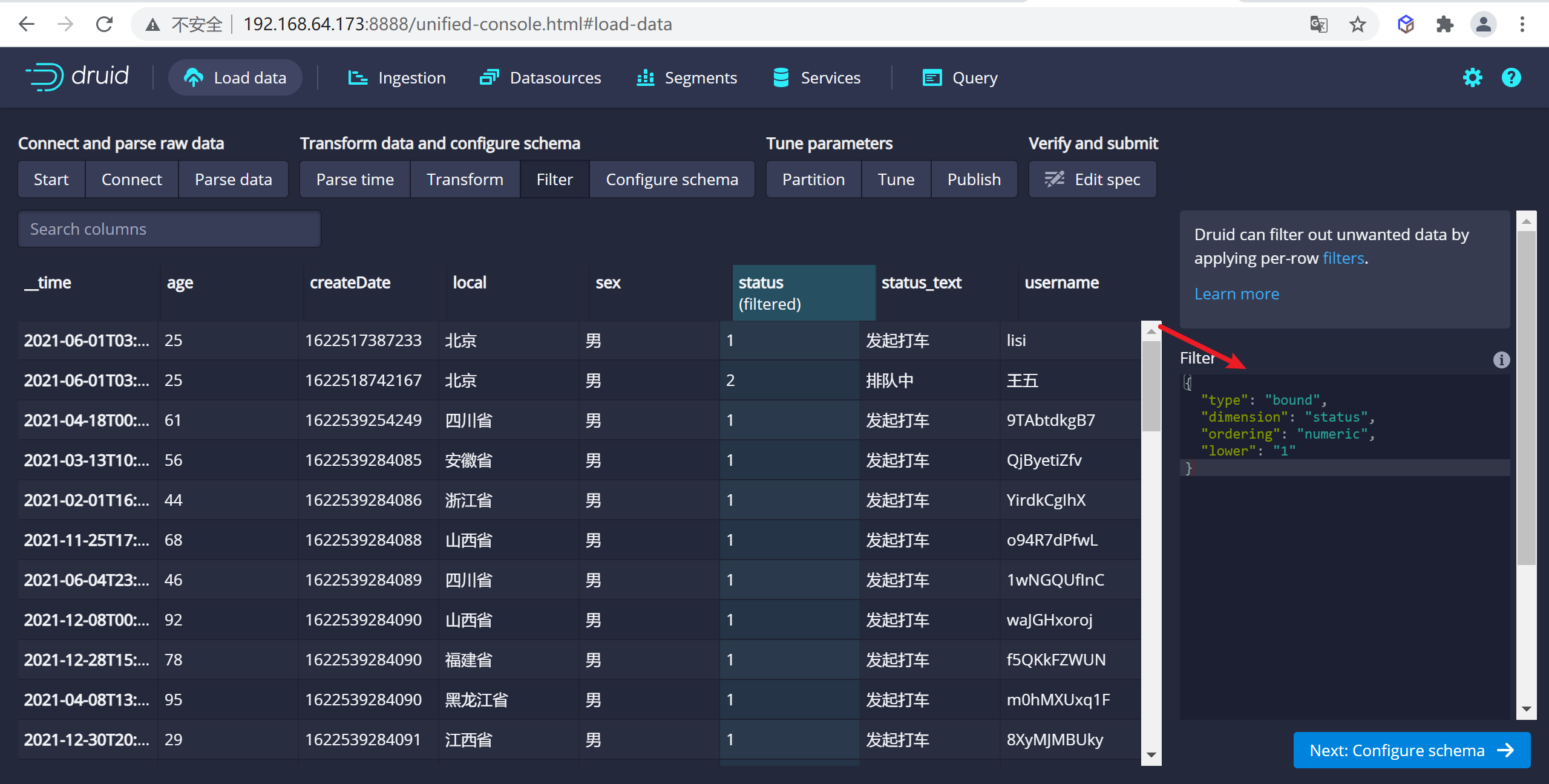
這裡可以設置過濾器,對於某些數據不展示,這裡我們使用
區間過濾器選擇顯示status>=1的數據,具體表達式可用參考
{
"type" : "bound",
"dimension" : "status",
"ordering": "numeric",
"lower": "1",
}
因為我們把數據是0的測試數據不顯示了,所以只顯示了一條數據為1的數據
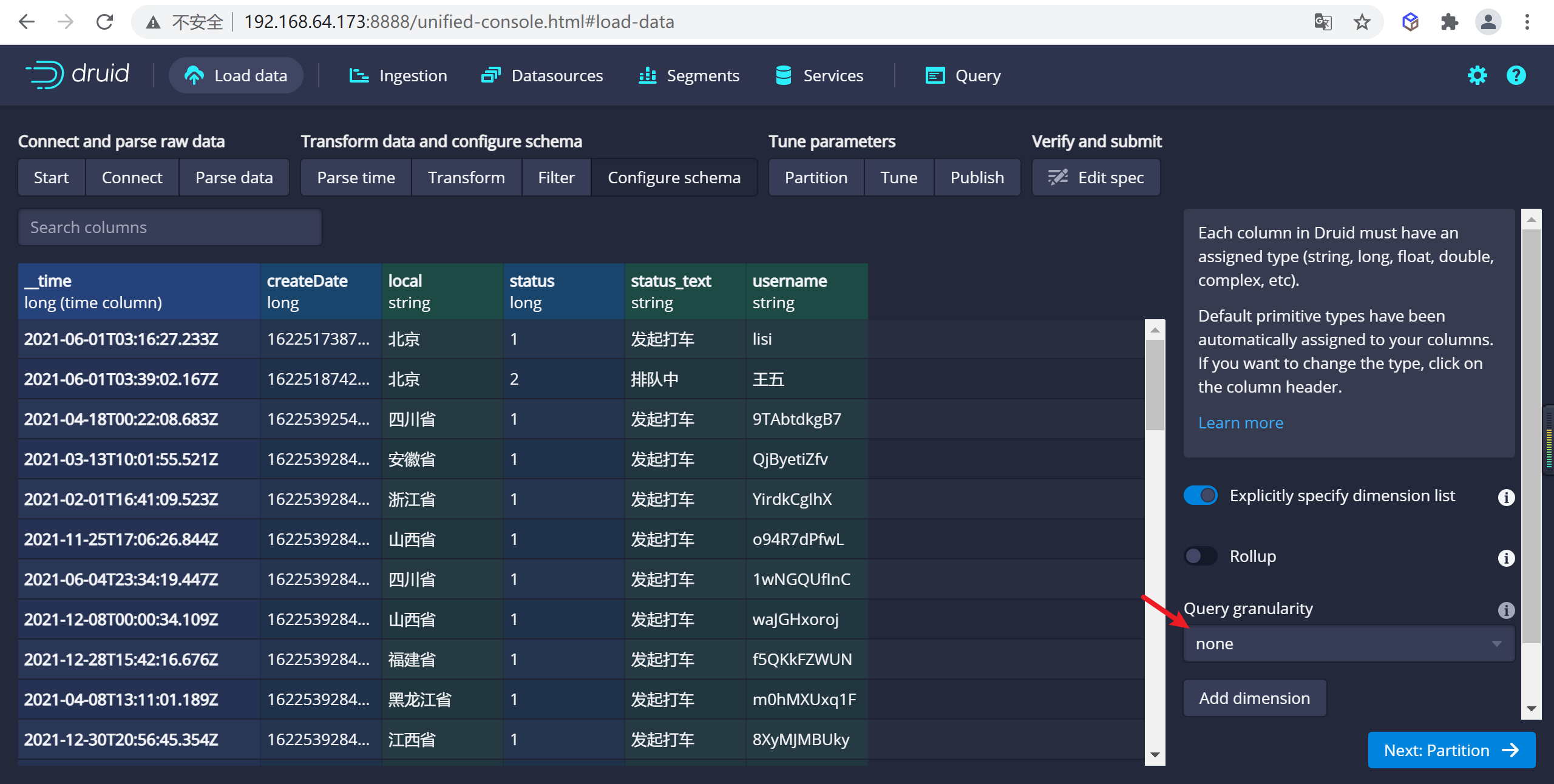
4.2.6.4 配置schema
在
Configure schema步驟中,您可以配置將哪些維度和指標攝入到Druid中,這些正是數據在被Druid中攝取後出現的樣子。 由於我們的數據集非常小,關掉rollup、確認更改。
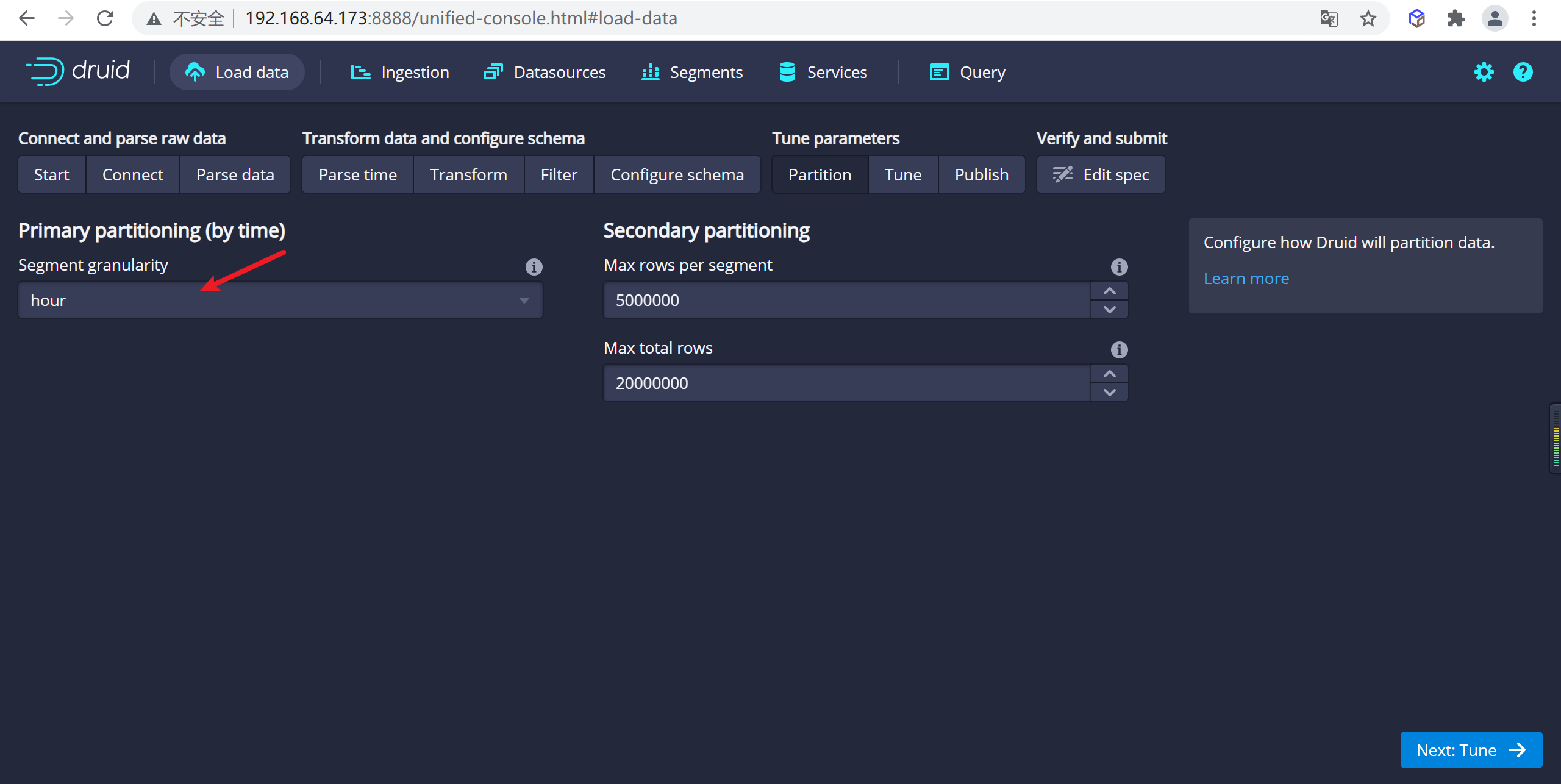
4.2.6.5 配置Partition
一旦對schema滿意後,點擊
Next後進入Partition步驟,該步驟中可以調整數據如何劃分為段文件的方式,因為我們打車一般按照小時來算的,我們設置為分區為``hour
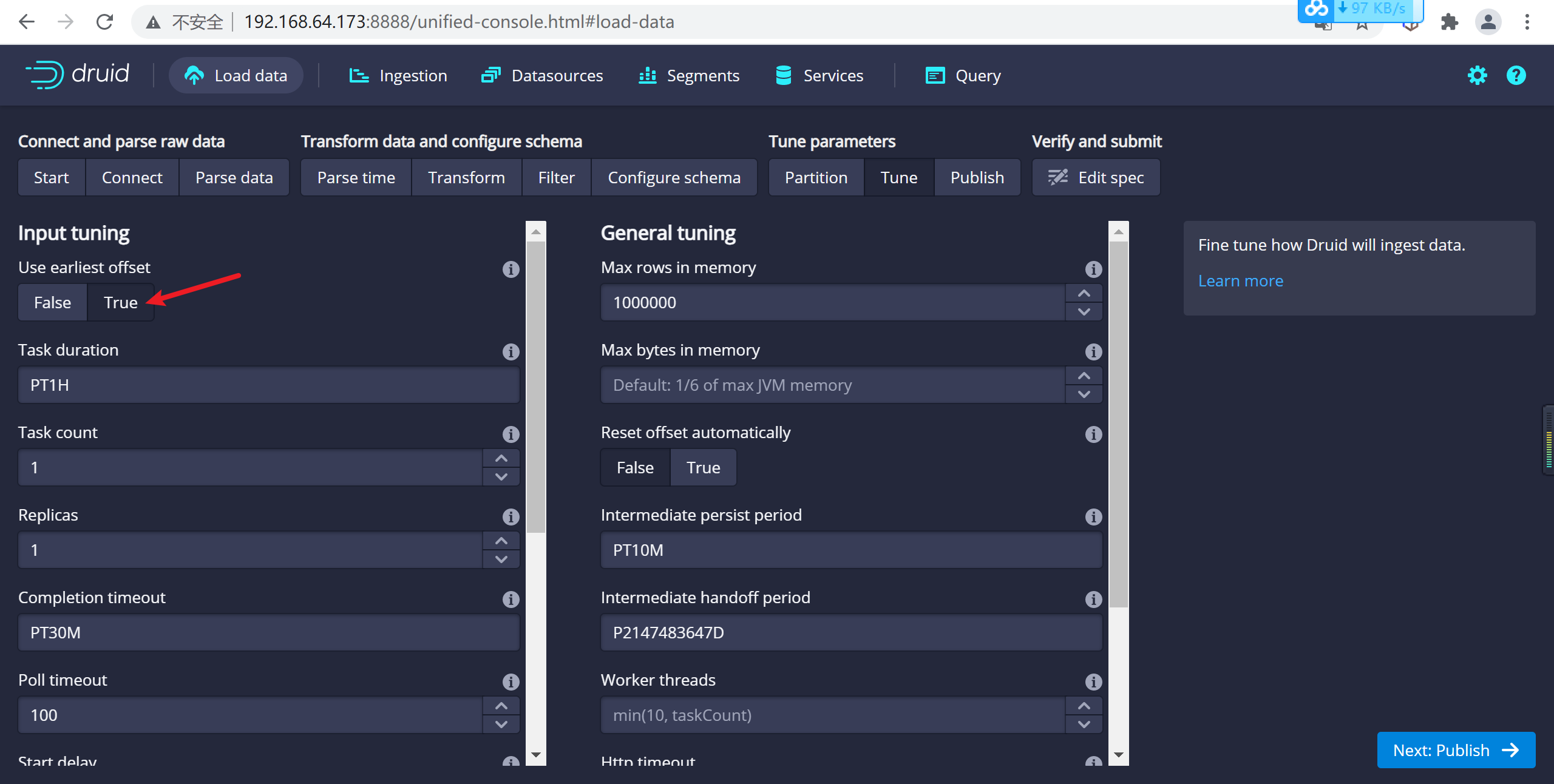
4.2.6.6 配置拉取方式
這裡設置kafka的拉取方式,主要設置偏移量的一些配置
在 Tune 步驟中,將 Use earliest offset 設置為 True 非常重要,因為我們需要從流的開始位置消費數據。 其他沒有任何需要更改的地方,進入到 Publish 步
4.5.7 提交任務
4.2.7.1 發佈數據
點擊完成
Tune步驟,進入到Publish步,在這裡我們可以給我們的數據源命名,這裡我們就命名為taxi-message,
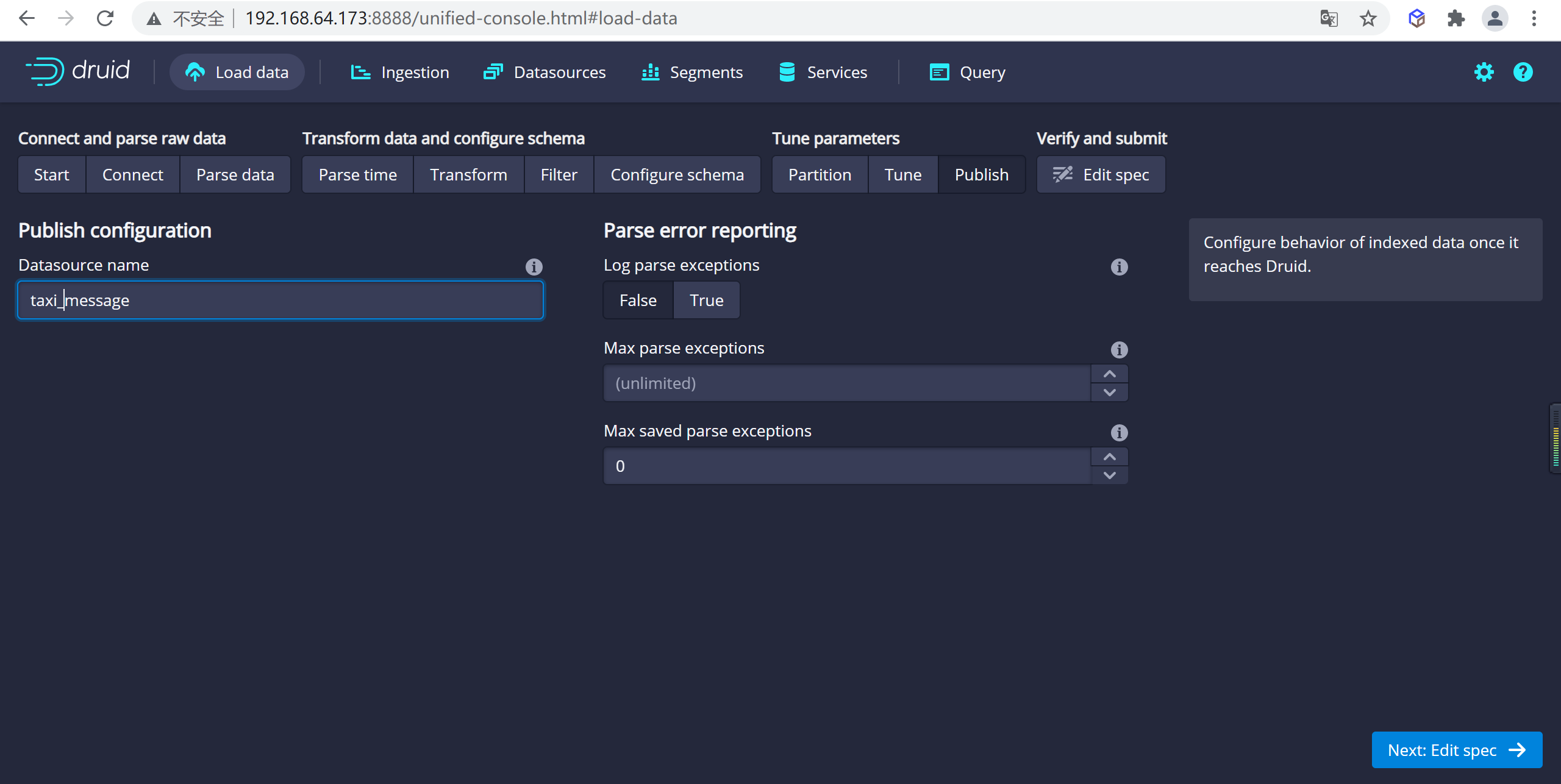
點擊下一步就可以查看我們的數據規範
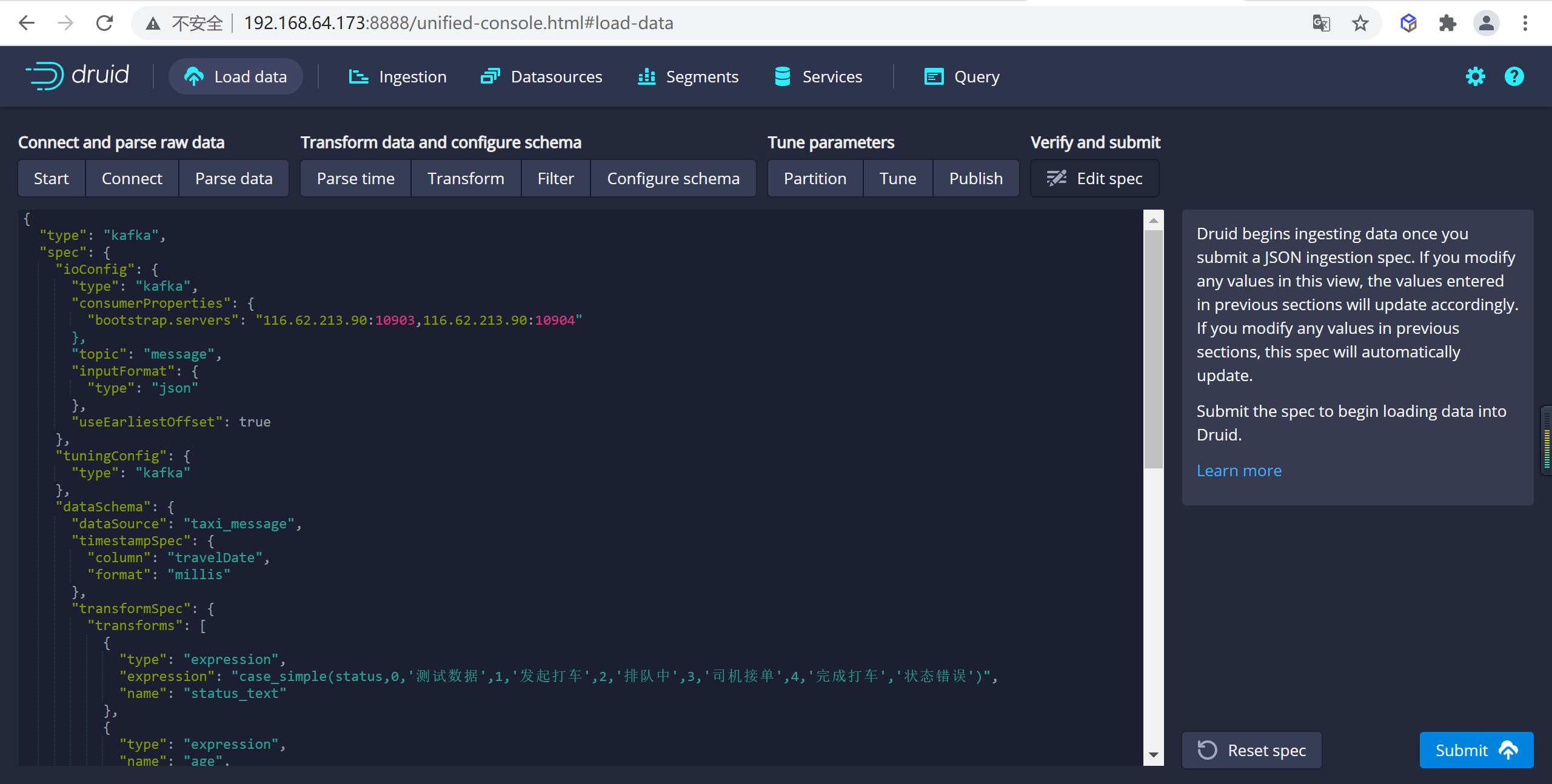
這就是您構建的規範,為了查看更改將如何更新規範是可以隨意返回之前的步驟中進行更改,同樣,您也可以直接編輯規範,併在前面的步驟中看到它。
4.2.7.2 提交任務
對攝取規範感到滿意後,請單擊
Submit,然後將創建一個數據攝取任務。
您可以進入任務視圖,重點關註新創建的任務。任務視圖設置為自動刷新,請等待任務成功。
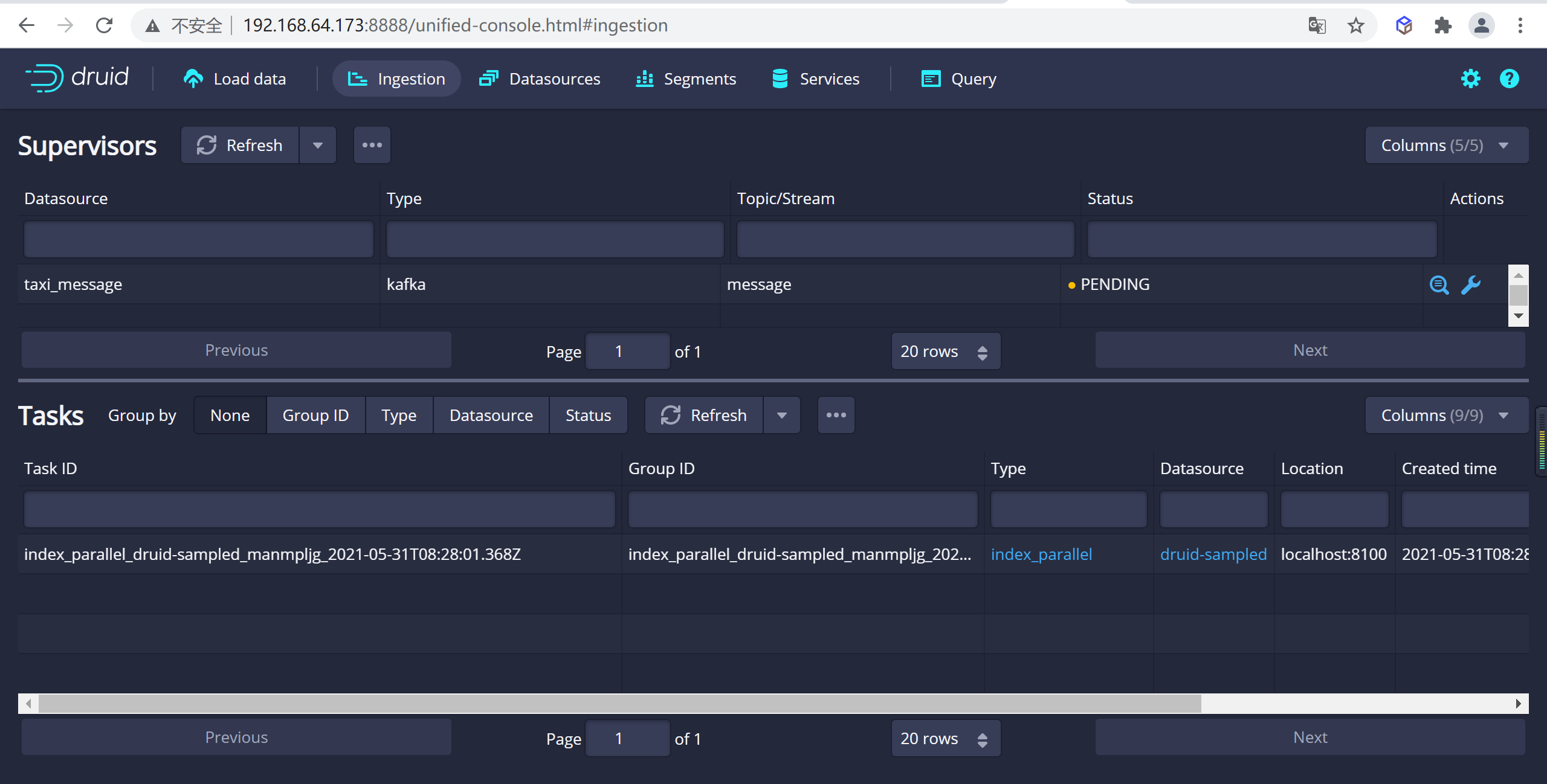
當一項任務成功完成時,意味著它建立了一個或多個段,這些段現在將由Data伺服器接收。
4.2.7.3 查看數據源
從標題導航到
Datasources視圖,一旦看到綠色(完全可用)圓圈,就可以查詢數據源。此時,您可以轉到Query視圖以對數據源運行SQL查詢。
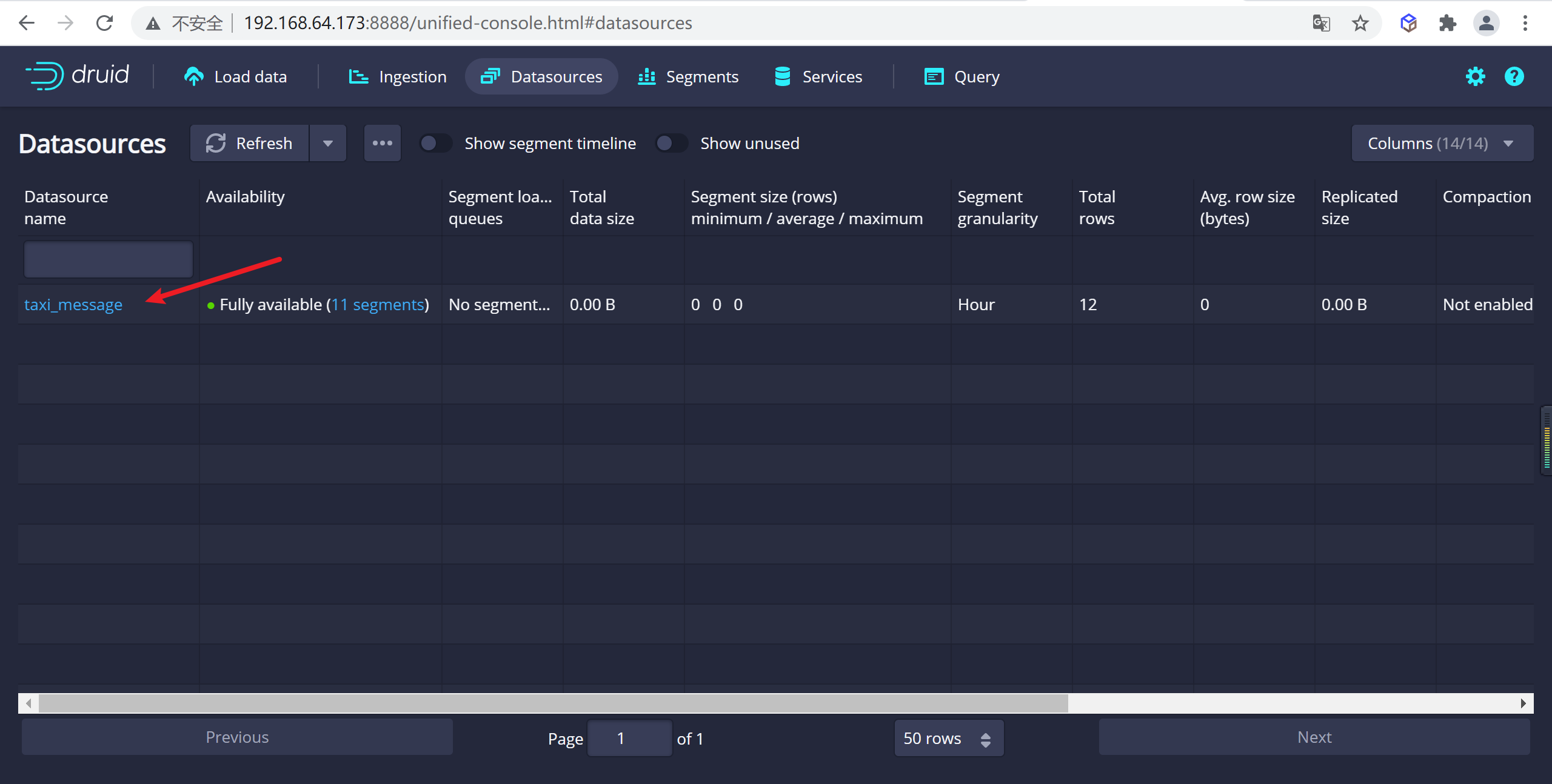
4.2.7.4 查詢數據
可以轉到查詢頁面進行數據查詢,這裡在sql視窗編寫sql後點擊運行就可以查詢數據了
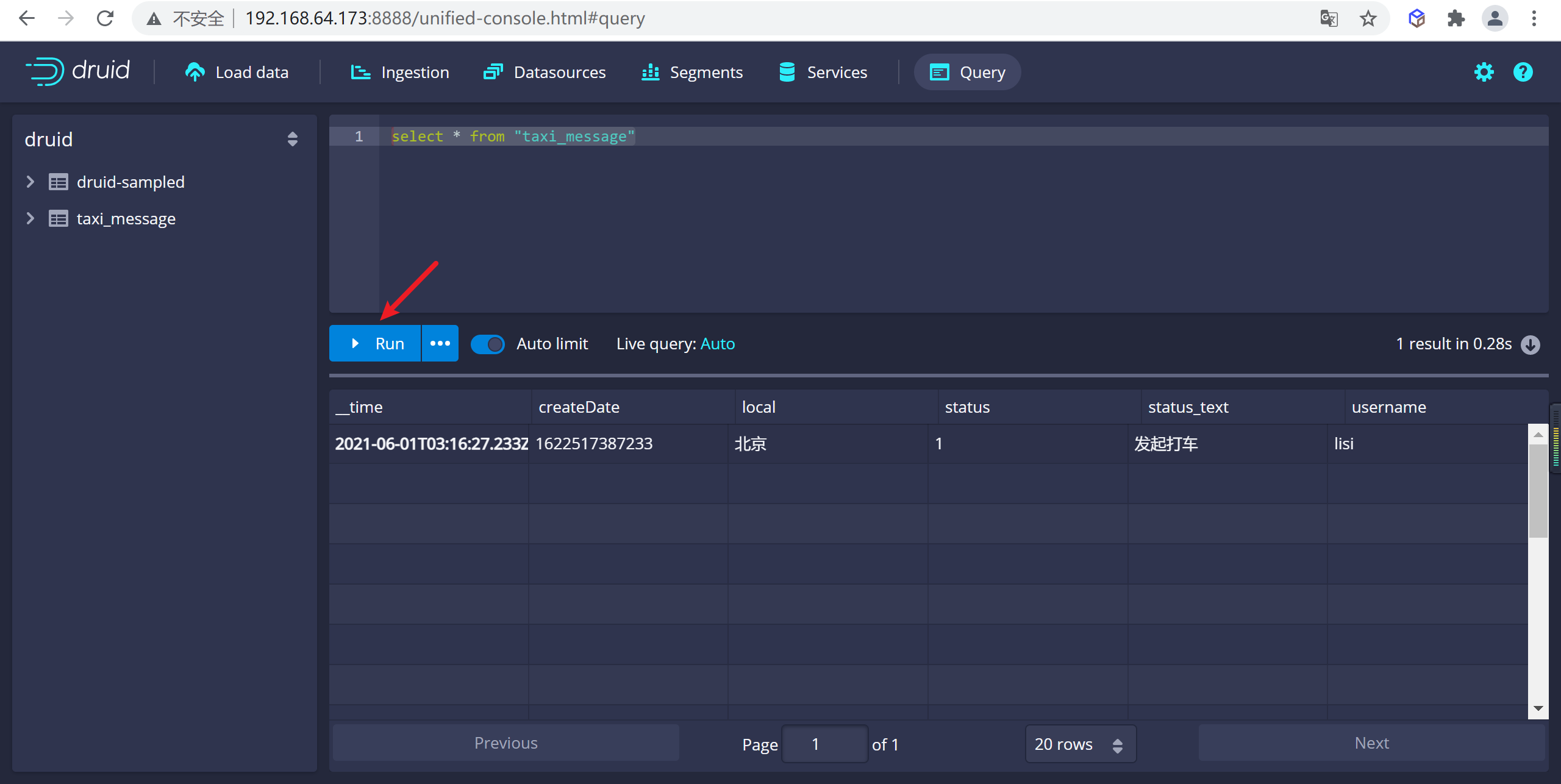
4.2.7.5 動態添加數據
發送一條數據到kafka
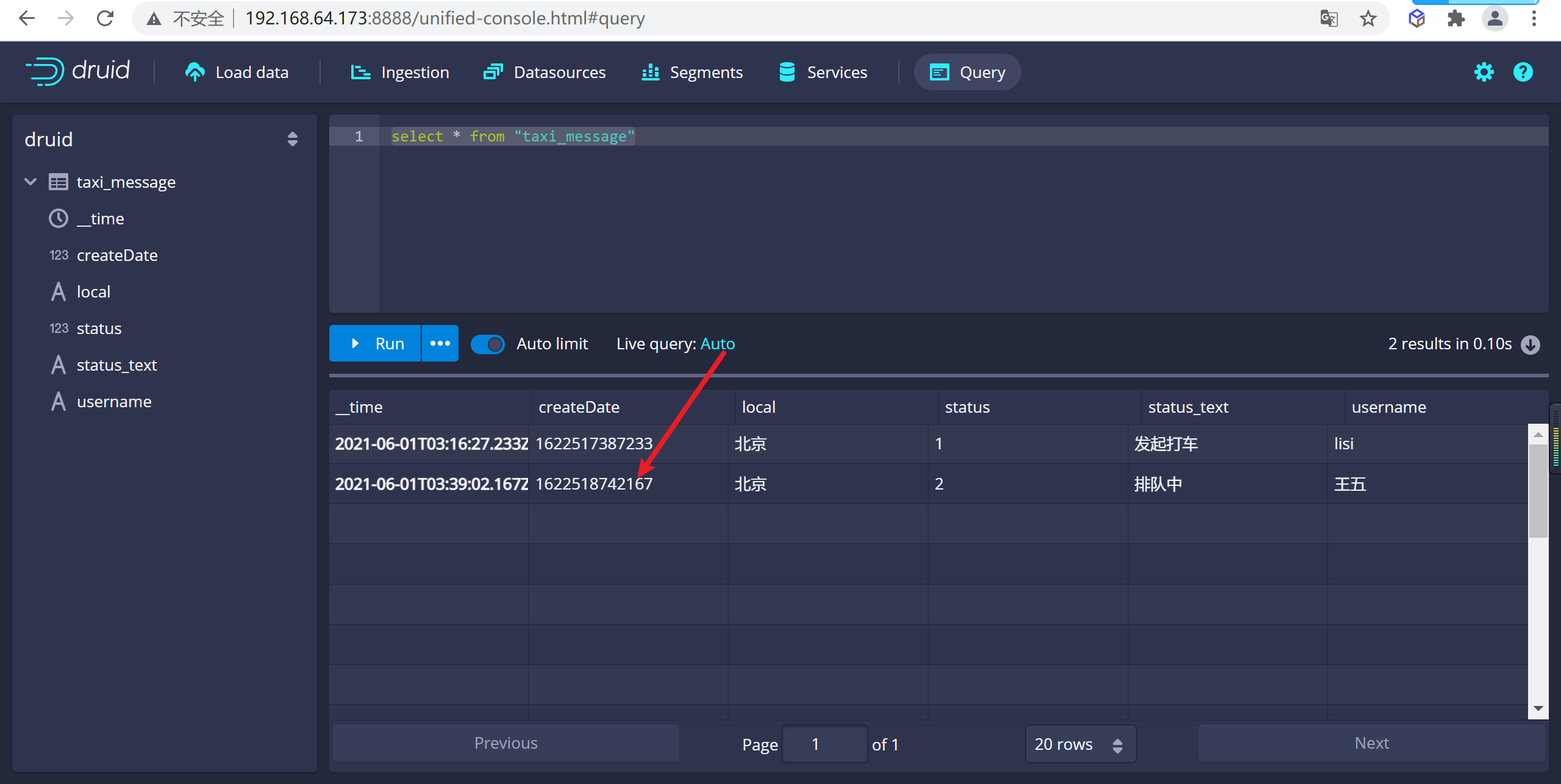
druid 查詢數據,發現新的數據已經進來了
4.2.8 清理數據
4.2.8.1 關閉集群
# 進入impl安裝目錄
cd /usr/local/imply/imply-2021.05-1
# 關閉集群
./bin/service --down

4.2.8.2 等待關閉服務
通過進程查看,查看服務是否已經關閉
ps -ef|grep druid

4.2.8.3 清理數據
通過刪除druid軟體包下的
var目錄的內容來重置集群狀態
ll
rm -rf var

4.2.8.4 重新啟動集群
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &
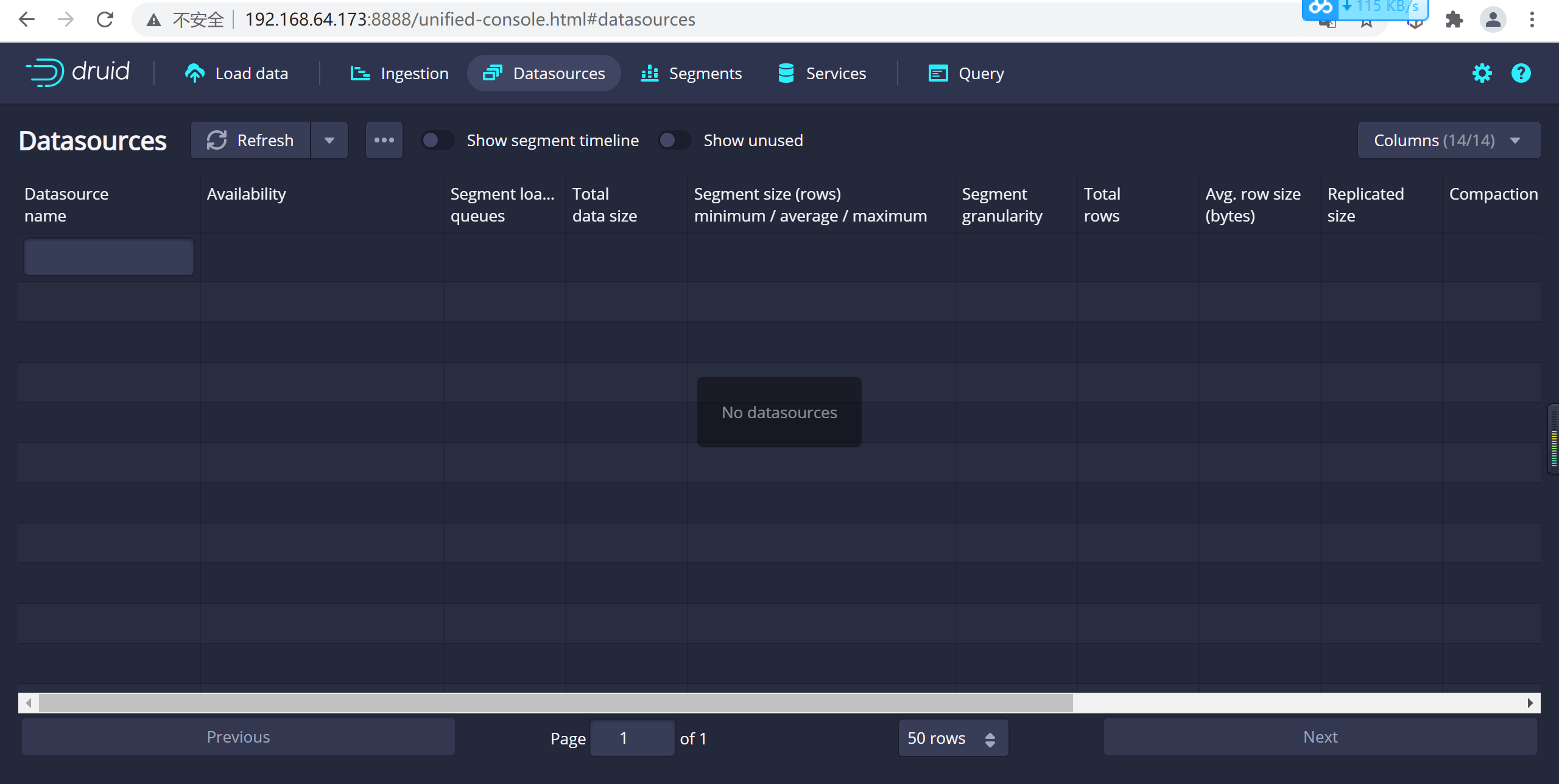
4.2.8.5 查看數據源
登錄後查看數據源,我們發現已經被重置了
本文由傳智教育博學谷 - 狂野架構師教研團隊發佈
如果本文對您有幫助,歡迎關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請註明出處!

