
JDBC 一、JDBC概述 什麼是JDBC? **JDBC 是使用 Java 語言操作關係型資料庫的一套 API。**這套 API 是交由不同的資料庫廠商實現的。我們利用 JDBC 編寫操作資料庫的代碼,真正執行的是各個資料庫的實現類(驅動)。 全稱:(Java DataBase Connectiv ...
資料庫與I/O原理
數據會持久化到磁碟,查詢數據是就會有I/O操作,相對於緩存操作,I/O操作的時間成本相當高昂。
I/O操作的基本單位是一個磁碟頁面,比如16KB的頁面大小。當數據量比較大時,單表數據就會分佈在多個磁碟頁面。
如果沒有索引,就必須按順序載入磁碟頁面到緩存進行查找,判斷數據是否存在。隨著數據量的增長,磁碟I/O操作的次數也會越來越多。
因此,有必要通過一些輔助的數據結構來提交檢索的速度。
從上面可以看出,想要快速讀取到數據,可從以下幾個方面著手
1. 如何儘量減少磁碟IO操作
2. 如何快速定位到數據所在的磁碟頁面
3. 如何快速定位數據在磁碟頁面內的位置
資料庫索引是什麼
索引是存儲引擎用於快速查找記錄的一種數據結構。
舉個類似的例子,當我們要閱讀《高性能MySQL》的第五章時,一般會先查找目錄,找到第五章對應的頁碼,然後翻到對應頁碼即可。
目錄一般不會超過10頁,整本書有將近700頁。
如果沒有目錄,那麼我們只能順序或者使用二分的方法來查找第五章,需要翻頁的次數就會更多。
索引的作用與書籍的目錄相似,用於輔助快速查找目標數據。
存儲結構
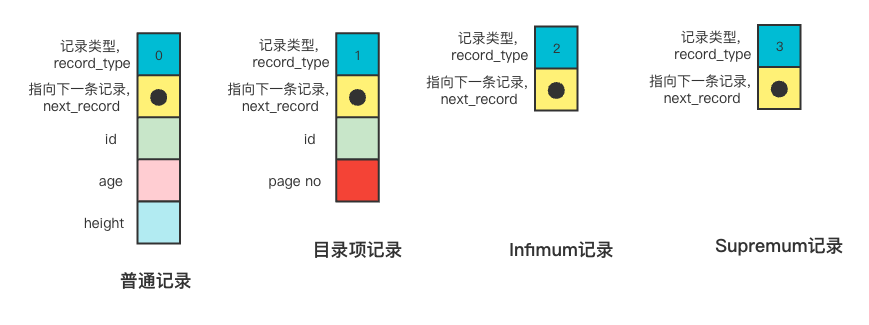
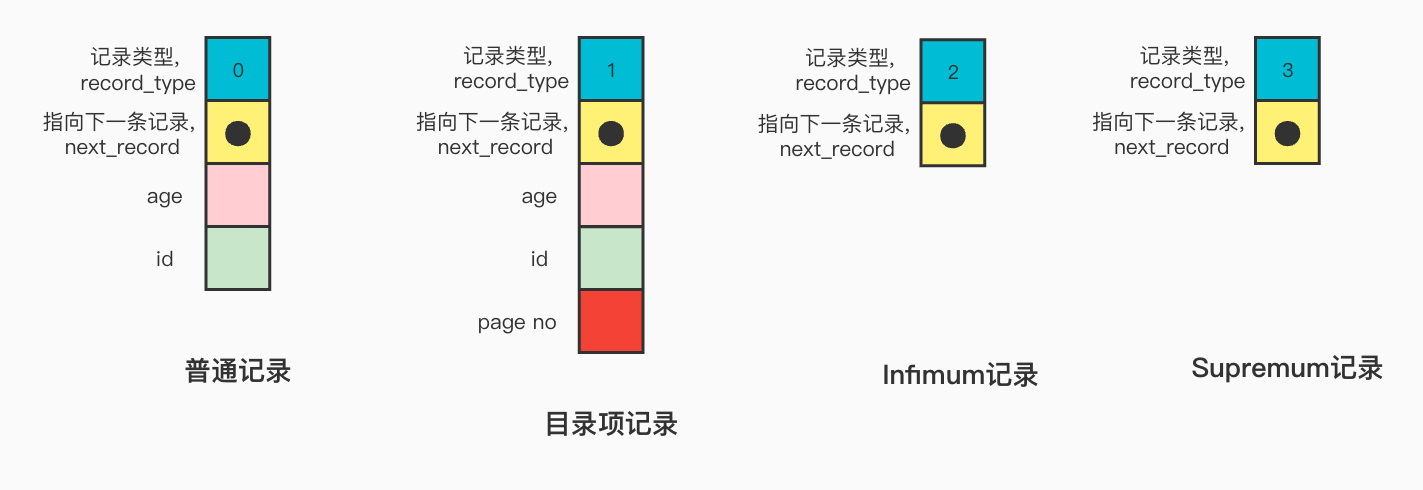
記錄(行)格式
InnoDB支持四種記錄格式,分別是REDUNDANT、COMPACT、DYNAMIC和COMPRESSED,MySQL5.7預設是DYNAMIC格式。
下圖是DYNAMIC行格式的示意圖

記錄頭信息的格式示意圖如下
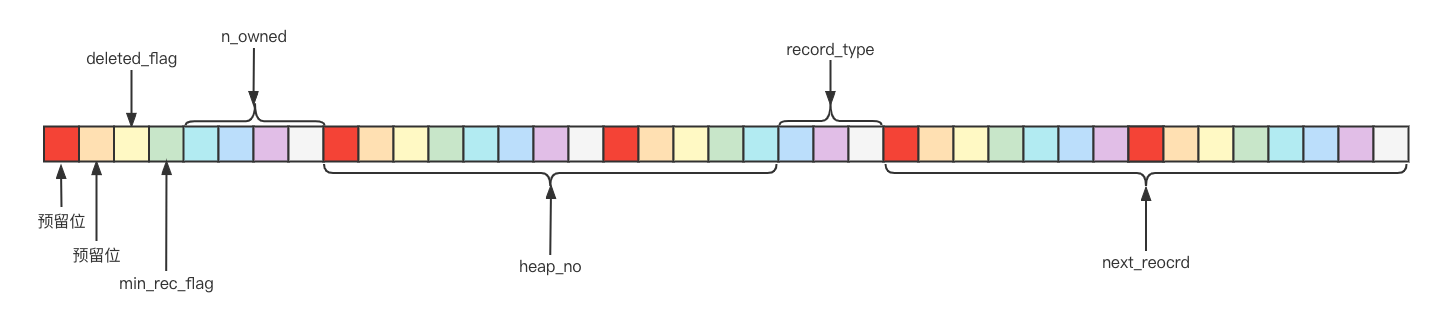
部分欄位含義
deleted_flag:顧名思義,該記錄是否被刪除的標誌
min_rec_flag:B+樹每層非葉子結點中最小的記錄項的標誌
n_owned: 頁面中分組的
heap_on: 表示當前記錄在頁面堆中的相對記錄
record_type: 表示當前記錄的類型,0表示普通記錄,1表示B+樹非葉子結點的目錄項記錄,2表示Infimum記錄,3表示Supremum記錄。
next_record: 指向下一條記錄,表示下一條記錄的相對位置
記錄示例
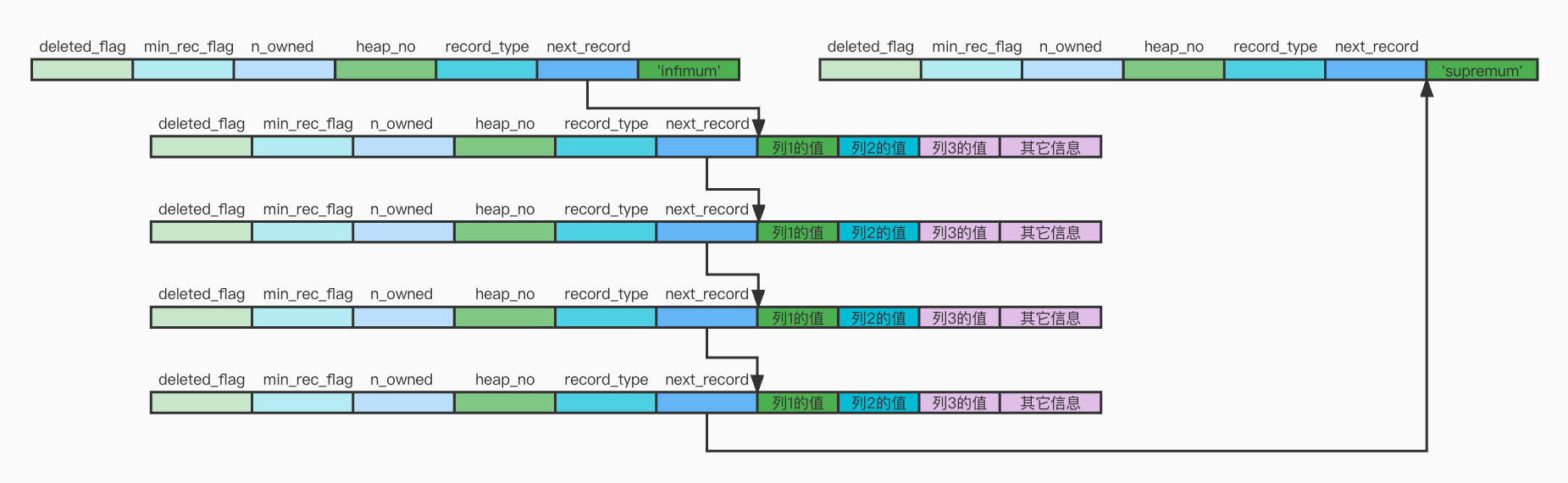
所有頁面都有兩條虛擬記錄,即Infimum和Supremum。
Infimum代表頁面中的最小的記錄,而Supremum則代表頁面中最大的記錄。
數據排序
頁內的記錄串聯成一個單向鏈表。
如果表有主鍵,會根據主鍵排序;
沒主鍵有唯一非空索引,會根據該索引排序;
兩者都沒有,InnoDB會自動生成一個row_id列並根據該列進行排序。
頁面格式
頁是InnoDB管理存儲空間的基本單位,一個頁的大小一般是16K。
數據頁面的結構如下圖
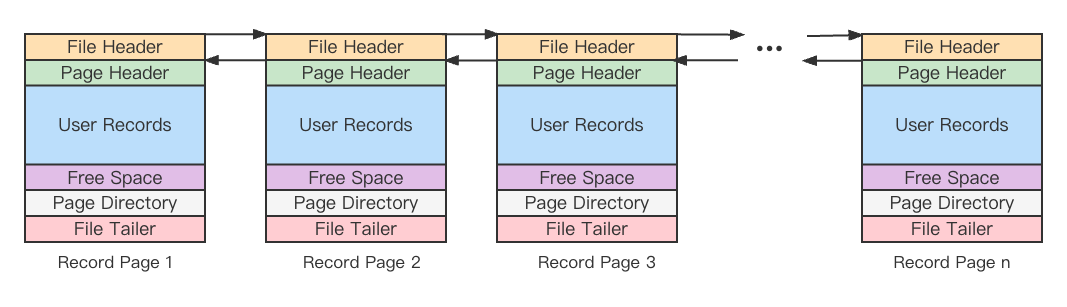
File Header:頁面通用信息,如當前頁號、上一頁/下一頁頁號
Page Header:頁面的各種狀態信息,如分組數量,記錄數
User Records:記錄的有序鏈表
Free Space:頁面中尚未使用的空間
Page Directory:對User Records數據進行分組,減少遍歷鏈表的次數,加速查找
File Tailer:校驗頁面數據是否完整
數據查找
頁面內的數據是有序的單向鏈表。
假設單行數據128B,而單個磁碟頁面大小可以是16KB,因此一個磁碟頁面最多可以存放128條數據。這樣挨個查找太慢。
可以利用有序鏈表的特性,對有序數據進行分組,記錄每組的最大值,形成一個有序分組列表。先二分查找有序分組列表,再查找分組內的數據。
這裡就會涉及的行記錄的n_owned和頁面的Page Directory了,InnoDB分組規則如下
1. Infimum記錄所在的分組只能有一條記錄
2. Supremum記錄所在的分組擁有的記錄數量為1~8條
3. 其它分組擁有的記錄數量為4~8條
4. 分組指向組內ID最大的行。
查找過程
下圖是簡化的行記錄和Page Directory。
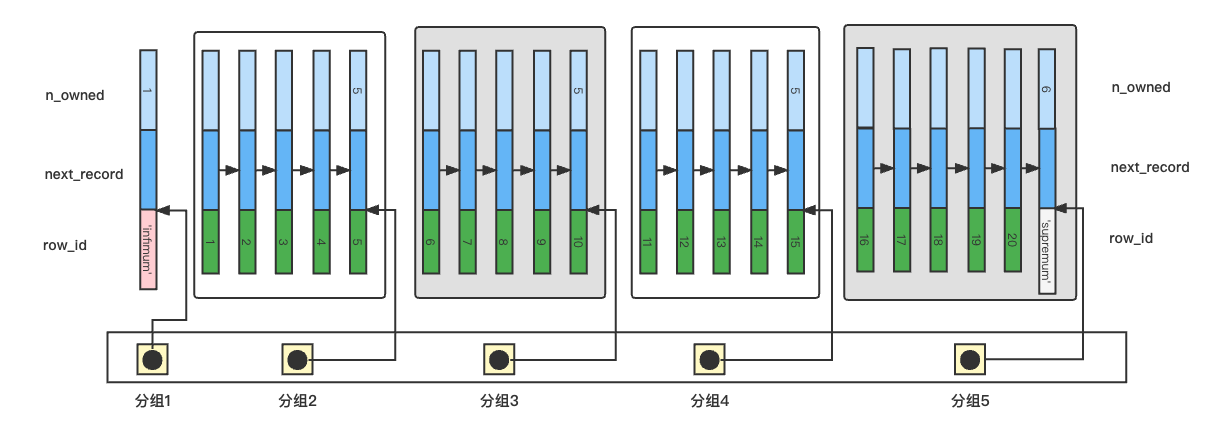
在上圖中查找ID=17的記錄
1. 利用分組進行二分查找,
(1 + 5) / 2 = 3,分組3的最大ID為10,因此繼續在右半區間查找
(3 + 5) / 2 = 4,分組最大的ID為15,17位於右半區間,又應為5 - 4 = 1,因此,17位於分組5
2. 組內順序查找
在分組內遍歷單向鏈表,查找到ID=17的記錄
B+樹索引
B+樹數據結構
在B樹詳解,這邊隨筆中介紹了B樹的查找、插入、刪除操作,可以深入理解B數的數據結構
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵ID', `age` int NOT NULL DEFAULT '0' COMMENT '年齡', `height` int NOT NULL DEFAULT '0' COMMENT '身高' PRIMARY KEY (`id`) KEY `age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=COMPACT
聚簇索引
為了方便畫圖表示,下麵是簡化的聚簇索引各種記錄格式
聚簇索引結構舉例
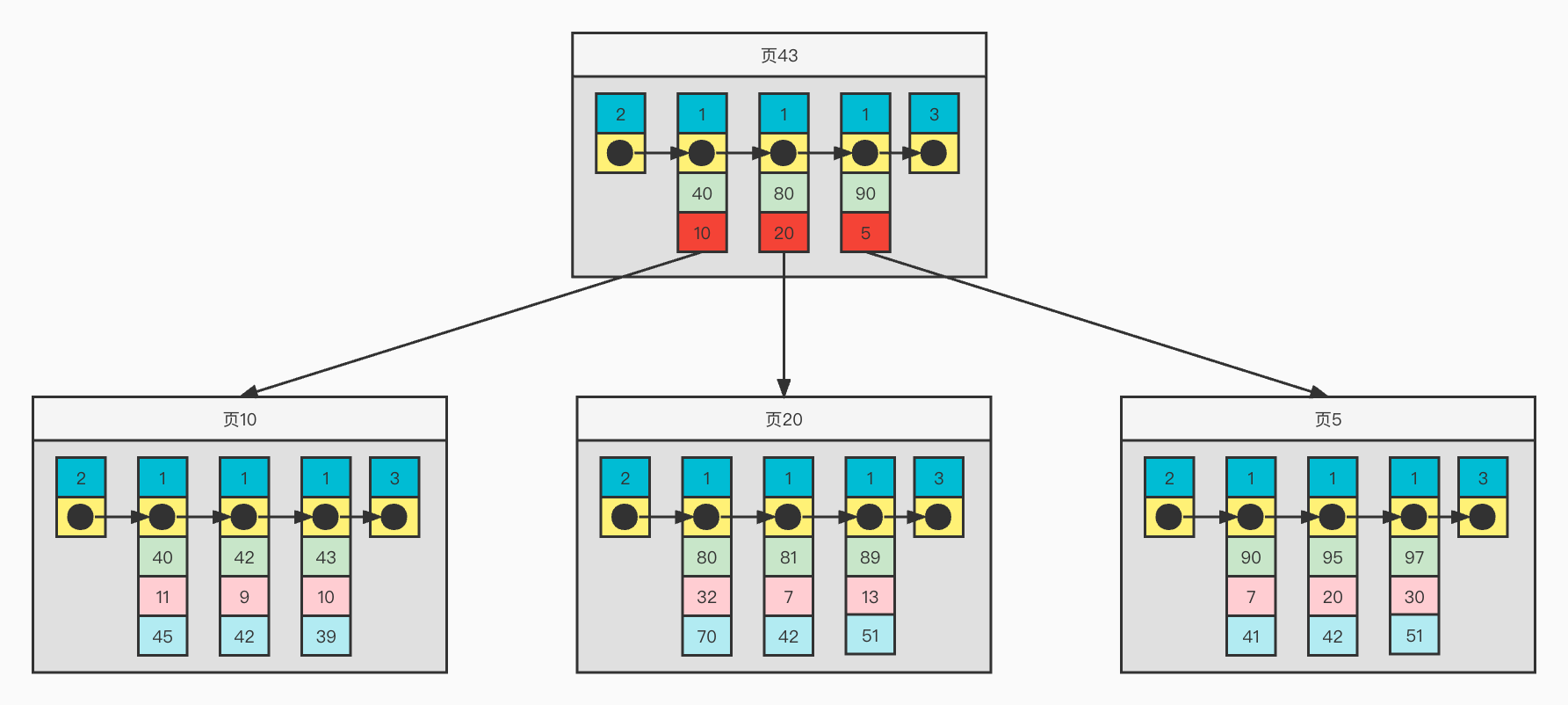
從上圖可以看出,
1)頁面內記錄按照主鍵增長的順序構成一個單項鏈表
2)對於普通記錄,則是一個按照主鍵有序的雙向鏈表
二級索引
為了方便畫圖表示,下麵是簡化的二級索引各種記錄格式
二級索引結構舉例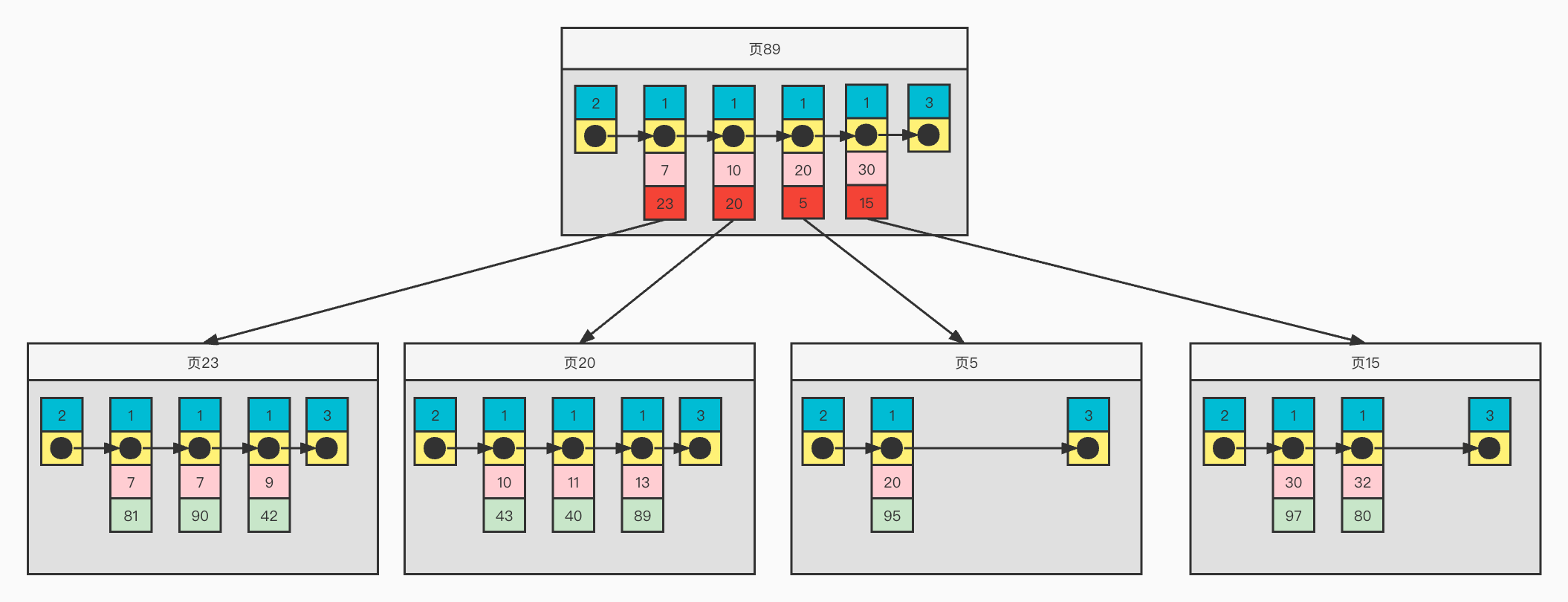
1)頁面內記錄按照二級索引age增長的順序構成一個單項鏈表
2)對於普通記錄,則是一個按照age有序的雙向鏈表
3)普通記錄並沒沒有包含完整的信息,而是<age,主鍵>的組合,需要取其它信息如height還需要進行回表
回表: 資料庫根據索引(非主鍵)找到了指定的記錄所在行後,還需要根據索引上保存的主鍵 ID 再次到數據塊里獲取數據。
建立索引的原則
1. 儘量使用占用空間少的索引
索引欄位占用空間小,意味著單個頁面可以存放更多的目錄項目記錄,使得B+數更加扁平,從而減少IO次數
2. 選擇頻繁作為查詢條件的欄位作為索引
頻繁作為查詢條件的欄位作為索引,減少查詢的時間,避免全表查詢。
3. 選擇區分度高的欄位作為索引
例如性別隻有男1女2兩種情況,如果建立索引,目錄項只有兩條記錄,意義不大。還增加了維護索引的成本。
4. 最左匹配原則
多個欄位構成聯合索引時,這幾個欄位的順序十分重要。
假設有聯合索引<a,b,c>
目錄項記錄是先按a排序,如果a相等再按b排序,如果a和b都相等,再按c排序。
如果查詢條件只有(b,c),則改索引並不會生效。如果只有(a),那索引只是部分生效。
《MySQL是怎麼運行的》


