
Kotlin協程是學習Kotlin的重中之重,也是運用koitlin的關鍵。本篇文章主要介紹Kotlin協程的創建、協程調度與協程掛起部分內容,對相關內容進行細緻解析。 ...
vivo 互聯網客戶端團隊- Ruan Wen
本文是Kotlin協程解析系列文章的開篇,主要介紹Kotlin協程的創建、協程調度與協程掛起相關的內容
一、協程引入
Kotlin 中引入 Coroutine(協程) 的概念,可以幫助編寫非同步代碼。
在使用和分析協程前,首先要瞭解一下:
協程是什麼?
為什麼需要協程?
協程最為人稱道的就是可以用看起來同步的方式寫出非同步的代碼,極大提高了代碼的可讀性。在實際開發中最常見的非同步操作莫過於網路請求。通常我們需要通過各種回調的方式去處理網路請求,很容易就陷入到地獄回調中。
WalletHttp.target(VCoinTradeSubmitResult.class).setTag(tag)
.setFullUrl(Constants.VCOIN_TRADE_SUBMIT_URL).setParams(params)
.callback(new HttpCallback<VCoinTradeSubmitResult>() {
@Override
public void onSuccess(VCoinTradeSubmitResult vCoinTradeSubmitResult) {
super.onSuccess(vCoinTradeSubmitResult);
if (mView == null) {
return;
}
//......
}
}).post();
上述示例是一個項目開發中常見的一個網路請求操作,通過介面回調的方式去獲取網路請求結果。實際開發中也會經常遇到連續多個介面請求的情況,例如我們項目中的個人中心頁的邏輯就是先去非同步獲取。
本地緩存,獲取失敗的話就需要非同步刷新一下賬號token,然後網路請求相關個人中心的其他信息。這裡簡單舉一個支付示例,進行支付時,可能要先去獲取賬號token,然後依賴該token再去做支付。
請求操作,根據支付返回數據再去查詢支付結果,這種情況通過回調就可能演變為“地獄回調”。
//獲取賬號token
WalletHttp.target(Account.class).setTag(tag)
.setFullUrl(Constants.ACCOUNT_URL).setParams(params)
.callback(new HttpCallback<Account>() {
@Override
public void onSuccess(Account account) {
super.onSuccess(account);
//根據賬號token進行支付操作
WalletHttp.target(Pay.class).setFullUrl(Constants.PAY_URL).addToken(account.getToken()).callback(new HttpCallback<Pay>() {
@Override
public void onSuccess(Pay pay){
super.onSuccess(pay);
//根據支付操作返回查詢支付結果
WalletHttp.target(PayResult.class).setFullUrl(Constants.RESULT_URL).addResultCode(pay.getResultCode()).callback(new HttpCallback<PayResult>() {
@Override
public void onSuccess(PayResult result){
super.onSuccess(result);
//......
}
}).post();
}
}).post();
}
}).post();
對於這種場景,kotlin協程“同步方式寫出非同步代碼”的這個特性就可以很好的解決上述問題。若上述場景用kotlin 協程代碼實現呢,可能就為:
fun postItem(tag: String, params: Map<String, Any?>) = viewModelScope.launch {
// 獲取賬號信息
val account = repository.queryAccount(tag, params)
// 進行支付操作
val pay = repository.paySubmit(tag,account.token)
//查詢支付結果
val result = repository.queryPayResult(tag,pay.resultCode)
//......
}
可以看出,協程代碼非常簡潔,以順序的方式書寫非同步代碼,代碼可讀性極強。
如果想要將原先的網路回調請求也改寫成這種同步模式呢,只需要對原先請求回調用協程提供的suspendCancellableCoroutine等方法進行封裝處理,即可讓早期的非同步代碼也享受上述“同步代碼”的絲滑。
協程:
一種非搶占式或者協作式的電腦程式併發調度實現,程式可以主動掛起或者恢復執行,其核心點是函數或一段程式能夠被掛起,稍後再在掛起的位置恢復,通過主動讓出運行權來實現協作,程式自己處理掛起和恢復來實現程式執行流程的協作調度。
協程本質上是輕量級線程。
協程的特點有:
協程可以讓非同步代碼同步化,其本質是輕量級線程。
可在單個線程運行多個協程,其支持掛起,不會使運行協程的線程阻塞。
可以降低非同步程式的設計複雜度。
Kotlin協程實現層次:
基礎設施層:標準庫的協程API,主要對協程提供了概念和語義上最基本的支持;
業務框架層:協程的上層框架支持,基於標準庫實現的封裝,也是我們日常開發使用的協程擴展庫。

二、協程啟動
具體在使用協程前,首先要配置對Kotlin協程的依賴。
(1)項目根目錄build.gradle
buildscript {
...
ext.kotlin_coroutines = 'xxx'
...
}
(2)Module下build.gradle
dependencies {
...
//協程標準庫
implementation "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_coroutines"
//依賴協程核心庫,包含協程公共API部分
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:$kotlin_coroutines"
//依賴android支持庫,協程Android平臺的具體實現方式
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:$kotlin_coroutines"
...
}
2.1 Thread 啟動
在Java中,可以通過Thread開啟併發操作:
new Thread(new Runnable() {
@Override
public void run() {
//... do what you want
}
}).start();
在Kotlin中,使用線程更為便捷:
val myThread = thread {
//.......
}
這個Thread方法有個參數start預設為true,即創造出來的線程預設啟動,你可以自定義啟動時機:
val myThread = thread(start = false) {
//......
}
myThread.start()
2.2 協程啟動
動協程需要三部分:上下文、啟動模式、協程體。
啟動方式一般有三種,其中最簡單的啟動協程的方式為:
GlobalScope.launch {
//......
}
GlobalScope.launch()屬於協程構建器Coroutine builders,Kotlin 中還有其他幾種 Builders,負責創建協程:
runBlocking:T
使用runBlocking頂層函數創建,會創建一個新的協程同時阻塞當前線程,直到協程結束。適用於main函數和單元測試
launch
創建一個新的協程,不會阻塞當前線程,必須在協程作用域中才可以調用。它返回的是一個該協程任務的引用,即Job對象。這是最常用的啟動協程的方式。
async
創建一個新的協程,不會阻塞當前線程,必須在協程作用域中才可以調用,並返回Deffer對象。可通過調用Deffer.await()方法等待該子協程執行完成並獲取結果。常用於併發執行-同步等待和獲取返回值的情況。
2.2.1 runBlocking
public fun <T> runBlocking(context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T): T
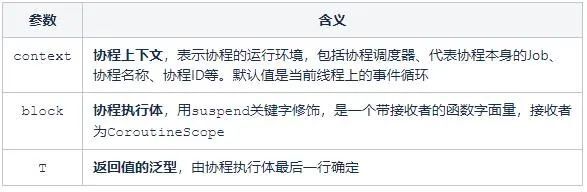
runBlocking是一個頂層函數,可以在任意地方獨立使用。它能創建一個新的協程同時阻塞當前線程,直到其內部所有邏輯以及子協程所有邏輯全部執行完成。常用於main函數和測試中。
//main函數中應用
fun main() = runBlocking {
launch { // 創建一個新協程,runBlocking會阻塞線程,但內部運行的協程是非阻塞的
delay(1000L)
println("World!")
}
println("Hello,")
delay(2000L) // 延時2s,保證JVM存活
}
//測試中應用
class MyTest {
@Test
fun testMySuspendingFunction() = runBlocking {
// ......
}
}
2.2.2 launch
launch是最常用的用於啟動協程的方式,會在不阻塞當前線程的情況下啟動一個協程,並返回對該協程任務的引用,即Job對象。
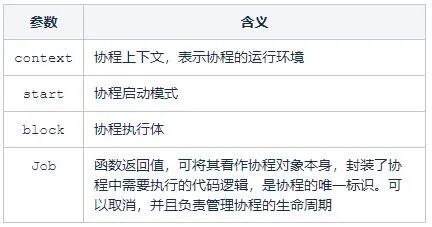
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
協程需要運行在協程上下文環境中,在非協程環境中的launch有兩種:GlobalScope 與 CoroutineScope 。
- GlobalScope.launch()
在應用範圍內啟動一個新協程,不會阻塞調用線程,協程的生命周期與應用程式一致。
fun launchTest() {
print("start")
GlobalScope.launch {
delay(1000)//1秒無阻塞延遲
print("GlobalScope.launch")
}
print("end")
}
/** 列印結果
start
end
GlobalScope.launch
*/
這種啟動的協程存在組件被銷毀但協程還存在的情況,一般不推薦。其中GlobalScope本身就是一個作用域,launch屬於其子作用域。
- CoroutineScope.launch()
啟動一個新的協程而不阻塞當前線程,並返回對協程的引用作為一個Job。
fun launchTest2() {
print("start")
val job = CoroutineScope(Dispatchers.IO).launch {
delay(1000)
print("CoroutineScope.launch")
}
print("end")
}
協程上下文控制協程生命周期和線程調度,使得協程和該組件生命周期綁定,組件銷毀時,協程一併銷毀,從而實現安全可靠地協程調用。這是在應用中最推薦的協程使用方式。
關於launch,根據業務需求需要創建一個或多個協程,則可能就需要在一個協程中啟動子協程。
fun launchTest3() {
print("start")
GlobalScope.launch {
delay(1000)
print("CoroutineScope.launch")
//在協程內創建子協程
launch {
delay(1500)
print("launch 子協程")
}
}
print("end")
}
/**** 列印結果
start
end
CoroutineScope.launch
launch 子協程
*/
2.2.3 async
async類似於launch,都是創建一個不會阻塞當前線程的新的協程。區別在於:async的返回是Deferred對象,可通過Deffer.await()等待協程執行完成並獲取結果,而 launch 不行。常用於併發執行-同步等待和獲取返回值的情況。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>

註意:
-
await() 不能在協程之外調用,因為它需要掛起直到計算完成,而且只有協程可以以非阻塞的方式掛起。所以把它放到協程中。
-
如果Deferred不執行await()則async內部拋出的異常不會被logCat或try Catch捕獲,但是依然會導致作用域取消和異常崩潰; 但當執行await時異常信息會重新拋出
-
如果將async函數中的啟動模式設置為CoroutineStart.LAZY懶載入模式時則只有調用Deferred對象的await時(或者執行async.satrt())才會開始執行非同步任務。
三、協程補充知識
在敘述協程啟動內容,涉及到了Job、Deferred、啟動模式、作用域等概念,這裡補充介紹一下上述概念。
3.1 Job
Job 是協程的句柄,賦予協程可取消,賦予協程以生命周期,賦予協程以結構化併發的能力。
Job是launch構建協程返回的一個協程任務,完成時是沒有返回值的。可以把Job看成協程對象本身,封裝了協程中需要執行的代碼邏輯,協程的操作方法都在Job身上。Job具有生命周期並且可以取消,它也是上下文元素,繼承自CoroutineContext。
在日常 Android 開發過程中,協程配合 Lifecycle 可以做到自動取消。
Job生命周期
Job 的生命周期分為 6 種狀態,分為
-
New
-
Active
-
Completing
-
Cancelling
-
Cancelled
-
Completed
通常外界會持有 Job 介面作為引用被協程調用者所持有。Job 介面提供 isActive、isCompleted、isCancelled 3 個變數使外界可以感知 Job 內部的狀態。

val job = launch(start = CoroutineStart.LAZY) {
println("Active")
}
println("New")
job.join()
println("Completed")
/**列印結果**/
New
Active
Completed
/**********
* 1. 以 lazy 方式創建出來的協程 state 為 New
* 2. 對應的 job 調用 join 函數後,協程進入 Active 狀態,並開始執行協程對應的具體代碼
* 3. 當協程執行完畢後,由於沒有需要等待的子協程,協程直接進入 Completed 狀態
*/
關於Job,常用的方法有:
//活躍的,是否仍在執行
public val isActive: Boolean
//啟動協程,如果啟動了協程,則為true;如果協程已經啟動或完成,則為false
public fun start(): Boolean
//取消Job,可通過傳入Exception說明具體原因
public fun cancel(cause: CancellationException? = null)
//掛起協程直到此Job完成
public suspend fun join()
//取消任務並等待任務完成,結合了[cancel]和[join]的調用
public suspend fun Job.cancelAndJoin()
//給Job設置一個完成通知,當Job執行完成的時候會同步執行這個函數
public fun invokeOnCompletion(handler: CompletionHandler): DisposableHandle
Job父子層級
對於Job,還需要格外關註的是Job的父子層級關係。
-
一個Job可以包含多個子Job。
-
當父Job被取消後,所有的子Job也會被自動取消。
-
當子Job被取消或者出現異常後父Job也會被取消。
-
具有多個子 Job 的父Job 會等待所有子Job完成(或者取消)後,自己才會執行完成。
3.2 Deferred
Deferred繼承自Job,具有與Job相同的狀態機制。
它是async構建協程返回的一個協程任務,可通過調用await()方法等待協程執行完成並獲取結果。其中Job沒有結果值,Deffer有結果值。
public interface Deferred<out T> : Job
3.3 作用域
協程作用域(CoroutineScope):協程定義的作用範圍,本質是一個介面。
確保所有的協程都會被追蹤,Kotlin 不允許在沒有使用CoroutineScope的情況下啟動新的協程。CoroutineScope可被看作是一個具有超能力的ExecutorService的輕量級版本。它能啟動新的協程,同時這個協程還具備suspend和resume的優勢。
每個協程生成器launch、async等都是CoroutineScope的擴展,並繼承了它的coroutineContext,自動傳播其所有元素和取消。
啟動協程需要作用域,但是作用域又是在協程創建過程中產生的。
public interface CoroutineScope {
/**
* 此域的上下文。Context被作用域封裝,用於在作用域上擴展的協程構建器的實現。
*/
public val coroutineContext: CoroutineContext
}
官方提供的常用作用域:
- runBlocking:
頂層函數,可啟動協程,但會阻塞當前線程
- GlobalScope
全局協程作用域。通過GlobalScope創建的協程不會有父協程,可以把它稱為根協程。它啟動的協程的生命周期只受整個應用程式的生命周期的限制,且不能取消,在運行時會消耗一些記憶體資源,這可能會導致記憶體泄露,不適用於業務開發。
- coroutineScope
創建一個獨立的協程作用域,直到所有啟動的協程都完成後才結束自身。
它是一個掛起函數,需要運行在協程內或掛起函數內。當這個作用域中的任何一個子協程失敗時,這個作用域失敗,所有其他的子協程都被取消。
- supervisorScope
與coroutineScope類似,不同的是子協程的異常不會影響父協程,也不會影響其他子協程。(作用域本身的失敗(在block或取消中拋出異常)會導致作用域及其所有子協程失敗,但不會取消父協程。)
- MainScope
為UI組件創建主作用域。一個頂層函數,上下文是SupervisorJob() + Dispatchers.Main,說明它是一個在主線程執行的協程作用域,通過cancel對協程進行取消。
fun scopeTest() {
GlobalScope.launch {//父協程
launch {//子協程
print("GlobalScope的子協程")
}
launch {//第二個子協程
print("GlobalScope的第二個子協程")
}
}
val mainScope = MainScope()
mainScope.launch {//啟動協程
//todo
}
}
Jetpack 的Lifecycle相關組件提供了已經綁定UV聲明周期的作用域供我們直接使用:
- lifecycleScope:
Lifecycle Ktx庫提供的具有生命周期感知的協程作用域,與Lifecycle綁定生命周期,生命周期被銷毀時,此作用域將被取消。會與當前的UI組件綁定生命周期,界面銷毀時該協程作用域將被取消,不會造成協程泄漏,推薦使用。
- viewModelScope:
與lifecycleScope類似,與ViewModel綁定生命周期,當ViewModel被清除時,這個作用域將被取消。推薦使用。
3.4 啟動模式
前述進行協程創建啟動時涉及到了啟動模式CoroutineStart,其是一個枚舉類,為協程構建器定義啟動選項。在協程構建的start參數中使用。
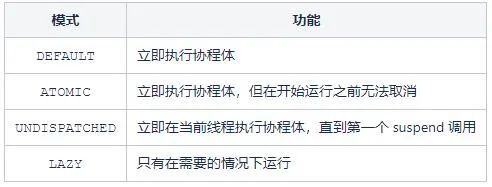
DEFAULT模式
DEFAULT 是餓漢式啟動,launch 調用後,會立即進入待調度狀態,一旦調度器 OK 就可以開始執行。
suspend fun main() {
log(1)
val job = GlobalScope.launch{
log(2)
}
log(3)
Thread.sleep(5000) //防止程式退出
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
前述示例代碼採用預設的啟動模式和預設的調度器,,運行結果取決於當前線程與後臺線程的調度順序。
/**可能的運行結果一****/
[main]:1
[main]:3
[main]:2
/**可能的運行結果二****/
[main]:1
[main]:2
[main]:3
LAZY模式
LAZY 是懶漢式啟動,launch 後並不會有任何調度行為,協程體不會進入執行狀態,直到我們需要他的運行結果時進行執行,其launch 調用後會返回一個 Job 實例。
對於這種情況,可以:
-
調用Job.start,主動觸發協程的調度執行
-
調用Job.join,隱式的觸發協程的調度執行
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.LAZY){
log(2)
}
log(3)
job.join()
log(4)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
對於join,一定要等待協程執行完畢,所以其運行結果一定為:
[main]:1
[main]:3
[DefaultDispatcher-worker-1]:2
[main]:4
如果把join()換為start(),則輸出結果不一定。
ATOMIC模式
ATOMIC 只有涉及 cancel 的時候才有意義。調用cancel的時機不同,結果也有差異。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.ATOMIC){
log(2)
}
job.cancel()
log(3)
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
前述代碼示例創建協程後立即cancel,由於是ATOMIC模式,因此協程一定會被調度,則log 1、2、3一定都會被列印輸出。如果將模式改為DEFAULT模式,則log 2有可能列印輸出,也可能不會。
其實cancel 調用一定會將該 job 的狀態置為 cancelling,只不過ATOMIC 模式的協程在啟動時無視了這一狀態。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.ATOMIC) {
log(2)
delay(1000)
log(3)
}
job.cancel()
log(4)
job.join()
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
/**列印輸出結果可能如下****/
[main]:1
[DefaultDispatcher-worker-1]:2
[main]:4
前述代碼中,2和3中加了一個delay,delay會使得協程體的執行被掛起,1000ms 之後再次調度後面的部分。對於 ATOMIC 模式,它一定會被啟動,實際上在遇到第一個掛起點之前,它的執行是不會停止的,而 delay 是一個 suspend 函數,這時我們的協程迎來了自己的第一個掛起點,恰好 delay 是支持 cancel 的,因此後面的 3 將不會被列印。
UNDISPATCHED模式
協程在這種模式下會直接開始在當前線程下執行,直到第一個掛起點。
與ATOMIC的不同之處在於 UNDISPATCHED 不經過任何調度器即開始執行協程體。遇到掛起點之後的執行就取決於掛起點本身的邏輯以及上下文當中的調度器了。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.UNDISPATCHED) {
log(2)
delay(100)
log(3)
}
log(4)
job.join()
log(5)
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
協程啟動後會立即在當前線程執行,因此 1、2 會連續在同一線程中執行,delay 是掛起點,因此 3 會等 100ms 後再次調度,這時候 4 執行,join 要求等待協程執行完,因此等 3 輸出後再執行 5。
結果如下:
[main]:1
[main]:2
[main]:4
[DefaultDispatcher-worker-1]:3
[DefaultDispatcher-worker-1]:5
3.5 withContext
withContext {}不會創建新的協程。在指定協程上運行掛起代碼塊,放在該塊內的任何代碼都始終通過IO調度器執行,並掛起該協程直至代碼塊運行完成。
public suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T
withContext會使用新指定的上下文的dispatcher,將block的執行轉移到指定的線程中。
它會返回結果, 可以和當前協程的父協程存在交互關係, 主要作用為了來回切換調度器。
coroutineScope{
launch(Dispatchers.Main) { // 在 UI 線程開始
val image = withContext(Dispatchers.IO) { // 切換到 IO 線程,併在執行完成後切回 UI 線程
getImage(imageId) // 將會運行在 IO 線程
}
avatarIv.setImageBitmap(image) // 回到 UI 線程更新 UI
}
}
四、協程調度
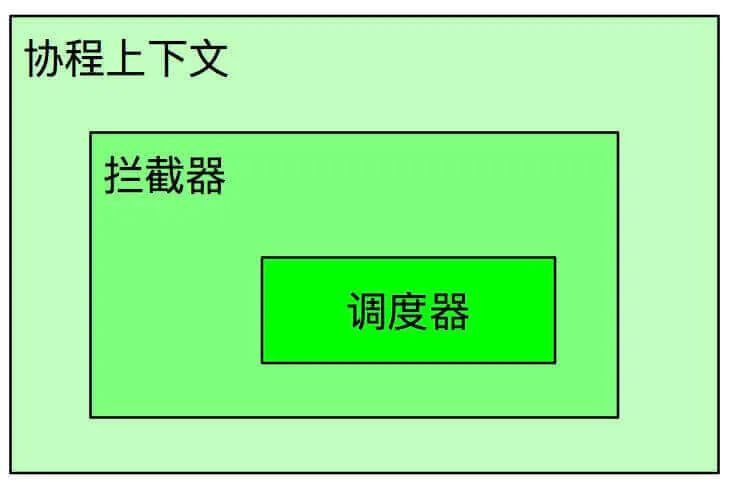
4.1 協程上下文
在協程啟動部分提到,啟動協程需要三個部分,其中一個部分就是上下文,其介面類型是CoroutineContext,通常所見的上下文類型是CombinedContext或者EmptyCoroutineContext,一個表示上下文組合,另一個表示空。
協程上下文是Kotlin協程的基本結構單元,主要承載著資源獲取,配置管理等工作,是執行環境的通用數據資源的統一管理者。除此之外,也包括攜帶參數,攔截協程執行等,是實現正確的線程行為、生命周期、異常以及調試的關鍵。
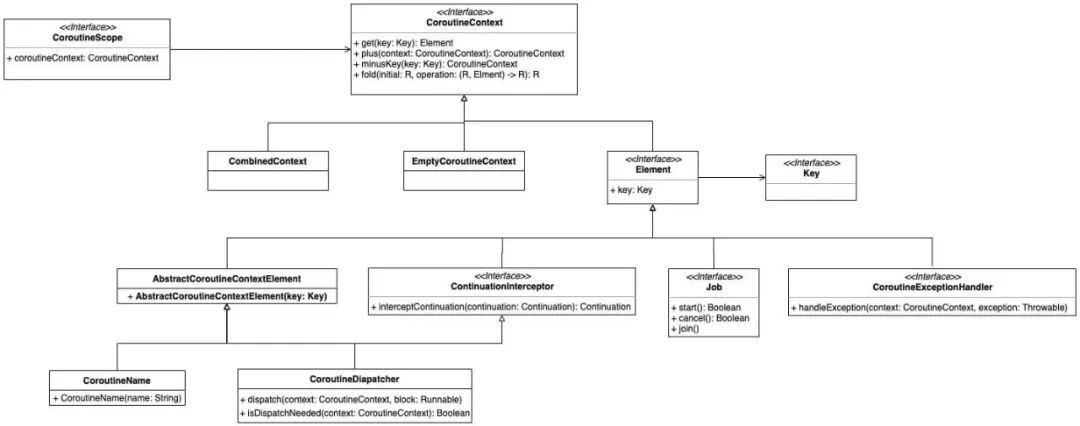
協程使用以下幾種元素集定義協程行為,他們均繼承自CoroutineContext:
【Job】:協程的句柄,對協程的控制和管理生命周期。
【CoroutineName】:協程的名稱,用於調試
【CoroutineDispatcher】:調度器,確定協程在指定的線程執行
【CoroutineExceptionHandler】:協程異常處理器,處理未捕獲的異常
這裡回顧一下launch和async兩個函數簽名。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>
兩個函數第一個參數都是CoroutineContext類型。
所有協程構建函數都是以CoroutineScope的擴展函數的形式被定義的,而CoroutineScope的介面唯一成員就是CoroutineContext類型。
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
簡而言之,協程上下文是協程必備組成部分,管理了協程的線程綁定、生命周期、異常處理和調試。
4.1.1 協程上下文結構
看一下CoroutineContext的介面方法:
public interface CoroutineContext {
//操作符[]重載,可以通過CoroutineContext[Key]這種形式來獲取與Key關聯的Element
public operator fun <E : Element> get(key: Key<E>): E?
//提供遍歷CoroutineContext中每一個Element的能力,並對每一個Element做operation操作
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
//操作符+重載,可以CoroutineContext + CoroutineContext這種形式把兩個CoroutineContext合併成一個
public operator fun plus(context: CoroutineContext): CoroutineContext = .......
//返回一個新的CoroutineContext,這個CoroutineContext刪除了Key對應的Element
public fun minusKey(key: Key<*>): CoroutineContext
//Key定義,空實現,僅僅做一個標識
public interface Key<E : Element>
///Element定義,每個Element都是一個CoroutineContext
public interface Element : CoroutineContext {
//每個Element都有一個Key實例
public val key: Key<*>
......
}
}
Element:協程上下文的一個元素,本身就是一個單例上下文,裡面有一個key,是這個元素的索引。
可知,Element本身也實現了CoroutineContext介面。
這裡我們再看一下官方解釋:
/**
Persistent context for the coroutine. It is an indexed set of [Element] instances.
An indexed set is a mix between a set and a map.
Every element in this set has a unique [Key].*/
從官方解釋可知,CoroutineContext是一個Element的集合,這種集合被稱為indexed set,介於set 和 map 之間的一種結構。set 意味著其中的元素有唯一性,map 意味著每個元素都對應一個鍵。
如果將協程上下文內部的一系列上下文稱為子上下文,上下文為每個子上下文分配了一個Key,它是一個帶有類型信息的介面。
這個介面通常被實現為companion object。
//Job
public interface Job : CoroutineContext.Element {
/**
* Key for [Job] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<Job>
}
//攔截器
public interface ContinuationInterceptor : CoroutineContext.Element {
/**
* The key that defines *the* context interceptor.
*/
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
}
//協程名
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
/**
* Key for [CoroutineName] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineName>
}
//異常處理器
public interface CoroutineExceptionHandler : CoroutineContext.Element {
/**
* Key for [CoroutineExceptionHandler] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
}
源碼中定義的子上下文,都會在內部聲明一個靜態的Key,類內部的靜態變數意味著被所有類實例共用,即全局唯一的 Key 實例可以對應多個子上下文實例。
在一個類似 map 的結構中,每個鍵必須是唯一的,因為對相同的鍵 put 兩次值,新值會代替舊值。通過上述方式,通過鍵的唯一性保證了上下文中的所有子上下文實例都是唯一的。
我們按照這個格式仿寫一下然後反編譯。
class MyElement :AbstractCoroutineContextElement(MyElement) {
companion object Key : CoroutineContext.Key<MyElement>
}
//反編譯的java文件
public final class MyElement extends AbstractCoroutineContextElement {
@NotNull
public static final MyElement.Key Key = new MyElement.Key((DefaultConstructorMarker)null);
public MyElement() {
super((kotlin.coroutines.CoroutineContext.Key)Key);
}
public static final class Key implements kotlin.coroutines.CoroutineContext.Key {
private Key() {
}
// $FF: synthetic method
public Key(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
對比kt和Java文件,可以看到Key就是一個靜態變數,且其實現類未做處理,作用與HashMap中的Key類似。
Key是靜態變數,全局唯一,為Element提供唯一性保障。
前述內容總結如下:
協程上下文是一個元素的集合,單個元素本身也是一個上下文,其定義是遞歸的,自己包含若幹個自己。
協程上下文這個集合有點像 set 結構,其中的元素都是唯一的,不重覆的。其通過給每一個元素配有一個靜態的鍵實例,構成一組鍵值對的方式實現。這使其類似 map 結構。這種介於 set 和 map 之間的結構稱為indexed set。
CoroutineContext.get()獲取元素
關於CoroutineContext,我們先看一下其是如何取元素的。
這裡看一下Element、CombinedContext、EmptyCoroutineContext的內部實現,其中CombinedContext就是CoroutineContext集合結構的實現,EmptyCoroutineContext就表示一個空的CoroutineContext,它裡面是空實現。
@SinceKotlin("1.3")
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
override fun <E : Element> get(key: Key<E>): E? {
var cur = this
while (true) {
//如果輸入 key 和右元素的 key 相同,則返回右元素
cur.element[key]?.let { return it }
// 若右元素不匹配,則向左繼續查找
val next = cur.left
if (next is CombinedContext) {
cur = next
} else { // 若左上下文不是混合上下文,則結束遞歸
return next[key]
}
}
}
......
}
public interface Element : CoroutineContext {
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
// 如果給定鍵和元素本身鍵相同,則返回當前元素,否則返回空
if (this.key == key) this as E else null
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
//返回空
public override fun <E : Element> get(key: Key<E>): E? = null
}
通過Key檢索Element,返回值只能是Element或null,鏈表節點中的元素值,其中CombinedContext利用while迴圈實現了類似遞歸的效果,其中較早被遍歷到的元素自然具有較高的優先順序。
//使用示例
println(coroutineContext[CoroutineName])
println(Dispatchers.Main[CoroutineName])
CoroutineContext.minusKey()刪除元素
同理看一下Element、CombinedContext、EmptyCoroutineContext的內部實現。
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
public override fun minusKey(key: Key<*>): CoroutineContext {
//如果element就是要刪除的元素,返回left,否則說明要刪除的元素在left中,繼續從left中刪除對應的元素
element[key]?.let { return left }
//在左上下文中去掉對應元素
val newLeft = left.minusKey(key)
return when {
//如果left中不存在要刪除的元素,那麼當前CombinedContext就不存在要刪除的元素,直接返回當前CombinedContext實例
newLeft === left -> this
//如果left中存在要刪除的元素,刪除了這個元素後,left變為了空,那麼直接返回當前CombinedContext的element就行
newLeft === EmptyCoroutineContext -> element
//如果left中存在要刪除的元素,刪除了這個元素後,left不為空,那麼組合一個新的CombinedContext返回
else -> CombinedContext(newLeft, element)
}
}
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
public override fun minusKey(key: Key<*>): CoroutineContext = this
......
}
public interface Element : CoroutineContext {
//如果key和自己的key匹配,那麼自己就是要刪除的Element,返回EmptyCoroutineContext(表示刪除了自己),否則說明自己不需要被刪除,返回自己
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
......
}
如果把CombinedContext和Element結合來看,那麼CombinedContext的整體結構如下:

其結構類似鏈表,left就是指向下一個結點的指針,get、minusKey操作大體邏輯都是先訪問當前element,不滿足,再訪問left的element,順序都是從right到left。
CoroutineContext.fold()元素遍歷
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
//先對left做fold操作,把left做完fold操作的的返回結果和element做operation操作
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = initial
......
}
public interface Element : CoroutineContext {
//對傳入的initial和自己做operation操作
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
......
}
fold也是遞歸的形式操作,fold的操作大體邏輯是:先訪問left,直到遞歸到最後的element,然後再從left到right的返回,從而訪問了所有的element。
CoroutineContext.plus()添加元素
關於CoroutineContext的元素添加方法,直接看其plus()實現,也是唯一沒有被重寫的方法。
public operator fun plus(context: CoroutineContext): CoroutineContext =
//如果要相加的CoroutineContext為空,那麼不做任何處理,直接返回
if (context === EmptyCoroutineContext) this else
//如果要相加的CoroutineContext不為空,那麼對它進行fold操作,可以把acc理解成+號左邊的CoroutineContext,element理解成+號右邊的CoroutineContext的某一個element
context.fold(this) { acc, element ->
//首先從左邊CoroutineContext中刪除右邊的這個element
val removed = acc.minusKey(element.key)
//如果removed為空,說明左邊CoroutineContext刪除了和element相同的元素後為空,那麼返回右邊的element即可
if (removed === EmptyCoroutineContext) element else {
//如果removed不為空,說明左邊CoroutineContext刪除了和element相同的元素後還有其他元素,那麼構造一個新的CombinedContext返回
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
plus方法大部分情況下返回一個CombinedContext,即我們把兩個CoroutineContext相加後,返回一個CombinedContext,在組合成CombinedContext時,+號右邊的CoroutineContext中的元素會覆蓋+號左邊的CoroutineContext中的含有相同key的元素。
這個覆蓋操作就在fold方法的參數operation代碼塊中完成,通過minusKey方法刪除掉重覆元素。
plus方法中可以看到裡面有個對ContinuationInterceptor的處理,目的是讓ContinuationInterceptor在每次相加後都能變成CoroutineContext中的最後一個元素。
ContinuationInterceptor繼承自Element,稱為協程上下文攔截器,作用是在協程執行前攔截它,從而在協程執行前做出一些其他的操作。通過把ContinuationInterceptor放在最後面,協程在查找上下文的element時,總能最快找到攔截器,避免了遞歸查找,從而讓攔截行為前置執行。
4.1.2 CoroutineName
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
CoroutineName是用戶用來指定的協程名稱的,用於方便調試和定位問題。
GlobalScope.launch(CoroutineName("GlobalScope")) {
launch(CoroutineName("CoroutineA")) {//指定協程名稱
val coroutineName = coroutineContext[CoroutineName]//獲取協程名稱
print(coroutineName)
}
}
/** 列印結果
CoroutineName(CoroutineA)
*/
協程內部可以通過coroutineContext這個全局屬性直接獲取當前協程的上下文。
4.1.3 上下文組合
如果要傳遞多個上下文元素,CoroutineContext可以使用"+"運算符進行合併。由於CoroutineContext是由一組元素組成的,所以加號右側的元素會覆蓋加號左側的元素,進而組成新創建的CoroutineContext。
GlobalScope.launch {
//通過+號運算添加多個上下文元素
var context = CoroutineName("協程1") + Dispatchers.Main
print("context == $context")
context += Dispatchers.IO //添加重覆Dispatchers元素,Dispatchers.IO 會替換 ispatchers.Main
print("context == $context")
val contextResult = context.minusKey(context[CoroutineName]!!.key)//移除CoroutineName元素
print("contextResult == $contextResult")
}
/**列印結果
context == [CoroutineName(協程1), Dispatchers.Main]
context == [CoroutineName(協程1), Dispatchers.IO]
contextResult == Dispatchers.IO
*/
如果有重覆的元素(key一致)則右邊的會代替左邊的元素,相關原理參看協程上下文結構章節。
4.1.4 CoroutineScope 構建
CoroutineScope實際上是一個CoroutineContext的封裝,當我們需要啟動一個協程時,會在CoroutineScope的實例上調用構建函數,如async和launch。
在構建函數中,一共出現了3個CoroutineContext。
查看協程構建函數async和launch的源碼,其第一行都是如下代碼:
val newContext = newCoroutineContext(context)
進一步查看:
@ExperimentalCoroutinesApi
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = coroutineContext + context //CoroutineContext拼接組合
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug
}
構建器內部進行了一個CoroutineContext拼接操作,plus左值是CoroutineScope內部的CoroutineContext,右值是作為構建函數參數的CoroutineContext。
抽象類AbstractCoroutineScope實現了CoroutineScope和Job介面。大部分CoroutineScope的實現都繼承自AbstractCoroutineScope,意味著他們同時也是一個Job。
public abstract class AbstractCoroutine<in T>(
parentContext: CoroutineContext,
initParentJob: Boolean,
active: Boolean
) : JobSupport(active), Job, Continuation<T>, CoroutineScope {
/**
* The context of this coroutine that includes this coroutine as a [Job].
*/
public final override val context: CoroutineContext = parentContext + this
//重寫了父類的coroutineContext屬性
public override val coroutineContext: CoroutineContext get() = context
}
從上述分析可知:coroutine context = parent context + coroutine job
4.1.5 典型用例
全限定Context
launch( Dispatchers.Main + Job() + CoroutineName("HelloCoroutine") + CoroutineExceptionHandler { _, _ -> /* ... */ }) {
/* ... */
}
全限定Context,即全部顯式指定具體值的Elements。不論你用哪一個CoroutineScope構建該協程,它都具有一致的表現,不會受到CoroutineScope任何影響。
CoroutineScope Context
基於Activity生命周期實現一個CoroutineScope
abstract class ScopedAppActivity:
AppCompatActivity(),
CoroutineScope
{
protected lateinit var job: Job
override val coroutineContext: CoroutineContext
get() = job + Dispatchers.Main // 註意這裡使用+拼接CoroutineContext
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
job = Job()
}
override fun onDestroy() {
super.onDestroy()
job.cancel()
}
}
Dispatcher:使用Dispatcher.Main,以在UI線程進行繪製
Job:在onCreate時構建,在onDestroy時銷毀,所有基於該CoroutineContext創建的協程,都會在Activity銷毀時取消,從而避免Activity泄露的問題
臨時指定參數
CoroutineContext的參數主要有兩個來源:從scope中繼承+參數指定。我們可以用withContext便捷地指定某個參數啟動子協程,例如我們想要在協程內部執行一個無法被取消的子協程:
withContext(NonCancellable) {
/* ... */
}
讀取協程上下文參數
通過頂級掛起只讀屬性coroutineContext獲取協程上下文參數,它位於 kotlin-stdlib / kotlin.coroutines / coroutineContext
println("Running in ${coroutineContext[CoroutineName]}")
Nested Context內嵌上下文
內嵌上下文切換:在協程A內部構建協程B時,B會自動繼承A的Dispatcher。
可以在調用async時加入Dispatcher參數,切換到工作線程
// 錯誤的做法,在主線程中直接調用async,若耗時過長則阻塞UI
GlobalScope.launch(Dispatchers.Main) {
val deferred = async {
/* ... */
}
/* ... */
}
// 正確的做法,在工作線程執行協程任務
GlobalScope.launch(Dispatchers.Main) {
val deferred = async(Dispatchers.Default) {
/* ... */
}
/* ... */
}
4.2 協程攔截器
@SinceKotlin("1.3")
public interface ContinuationInterceptor : CoroutineContext.Element {
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
public fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
//......
}
-
無論在CoroutineContext後面 放了多少個攔截器,Key 為 ContinuationInterceptor 的攔截器只能有一個。
-
Continuation 在調用其 Continuation#resumeWith() 方法,會執行其 suspend 修飾的函數的代碼塊,如果我們提前攔截到,可以做點其他事情,比如說切換線程,這是 ContinuationInterceptor 的主要作用。
協程的本質就是回調,這個回調就是被攔截的Continuation。OkHttp用攔截器做緩存,打日誌,模擬請求等,協程攔截器同理。
我們通過Dispatchers 來指定協程發生的線程,Dispatchers 實現了 ContinuationInterceptor介面。
這裡我們自定義一個攔截器放到協程上下文,看一下會發生什麼。
class MyContinuationInterceptor: ContinuationInterceptor{
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>) = MyContinuation(continuation)
}
class MyContinuation<T>(val continuation: Continuation<T>): Continuation<T> {
override val context = continuation.context
override fun resumeWith(result: Result<T>) {
log("<MyContinuation> $result" )
continuation.resumeWith(result)
}
}
suspend fun main(args: Array<String>) { // start main coroutine
GlobalScope.launch(MyContinuationInterceptor()) {
log(1)
val job = async {
log(2)
delay(1000)
log(3)
"Hello"
}
log(4)
val result = job.await()
log("5. $result")
}.join()
log(6)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
/******列印結果******/
[main]:<MyContinuation> Success(kotlin.Unit) //11
[main]:1
[main]:<MyContinuation> Success(kotlin.Unit) //22
[main]:2
[main]:4
[kotlinx.coroutines.DefaultExecutor]:<MyContinuation> Success(kotlin.Unit) //33
[kotlinx.coroutines.DefaultExecutor]:3
[kotlinx.coroutines.DefaultExecutor]:<MyContinuation> Success(Hello)
[kotlinx.coroutines.DefaultExecutor]:5. Hello
[kotlinx.coroutines.DefaultExecutor]:6
- 所有協程啟動時,都有一次Continuation.resumeWith 的操作,協程有機會調度到其他線程的關鍵之處就在於此。
- delay是掛起點,1s之後需要繼續調度執行該協程,因此就有了33處日誌。
前述分析CoroutineContext的plus方法涉及到了ContinuationInterceptor,plus每次都會將ContinuationInterceptor添加到拼接鏈的尾部,這裡再詳細解釋一下原因。
public operator fun plus(context: CoroutineContext): CoroutineContext =
//如果要相加的CoroutineContext為空,那麼不做任何處理,直接返回
if (context === EmptyCoroutineContext) this else
//如果要相加的CoroutineContext不為空,那麼對它進行fold操作,可以把acc理解成+號左邊的CoroutineContext,element理解成+號右邊的CoroutineContext的某一個element
context.fold(this) { acc, element ->
//首先從左邊CoroutineContext中刪除右邊的這個element
val removed = acc.minusKey(element.key)
//如果removed為空,說明左邊CoroutineContext刪除了和element相同的元素後為空,那麼返回右邊的element即可
if (removed === EmptyCoroutineContext) element else {
//如果removed不為空,說明左邊CoroutineContext刪除了和element相同的元素後還有其他元素,那麼構造一個新的CombinedContext返回
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
原因一:CombinedContext的結構決定。
其有兩個元素,left是一個前驅集合,element為一個純粹CoroutineContext,它的get方法每次都是從element開始進行查找對應Key的CoroutineContext對象;沒有匹配到才會去left集合中進行遞歸查找。為了加快查找ContinuationInterceptor類型的實例,才將它加入到拼接鏈的尾部,對應的就是element。
原因二:ContinuationInterceptor使用很頻繁
每次創建協程都會去嘗試查找當前協程的CoroutineContext中是否存在ContinuationInterceptor。這裡我們用launch來驗證一下
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.()
->
Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
如果使用的launch使用的是預設參數,此時Coroutine就是StandaloneCoroutine,然後調用start方法啟動協程。
start(block, receiver, this)
}
public operator fun <T> invoke(block: suspend () -> T, completion: Continuation<T>): Unit =
when (this) {
DEFAULT -> block.startCoroutineCancellable(completion)
ATOMIC -> block.startCoroutine(completion)
UNDISPATCHED -> block.startCoroutineUndispatched(completion)
LAZY -> Unit // will start lazily
}
如果我們使用預設參數,看一下預設參數對應執行的block.startCoroutineCancellable(completion)
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
-
首先通過createCoroutineUnintercepted來創建一個協程
-
然後再調用intercepted方法進行攔截操作
-
最後調用resumeCancellable,即Continuation的resumeWith方法,啟動協程,所以每次啟動協程都會自動回調一次resumeWith方法
這裡看一下intercepted
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
(this as? ContinuationImpl)?.intercepted() ?: this
看其在ContinuationImpl的intercepted方法實現
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
-
首先獲取到ContinuationInterceptor實例
-
然後調用它的interceptContinuation方法返回一個處理過的Continuation(多次調用intercepted,對應的interceptContinuation只會調用一次)
至此可知,ContinuationInterceptor的攔截是通過interceptContinuation方法進行
下麵再看一個ContinuationInterceptor的典型示例
val interceptor = object : ContinuationInterceptor {
override val key: CoroutineContext.Key<*> = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> {
println("intercept todo something. change run to thread")
return object : Continuation<T> by continuation {
override fun resumeWith(result: Result<T>) {
println("create new thread")
thread {
continuation.resumeWith(result)
}
}
}
}
}
println(Thread.currentThread().name)
lifecycleScope.launch(interceptor) {
println("launch start. current thread: ${Thread.currentThread().name}")
withContext(Dispatchers.Main) {
println("new continuation todo something in the main thread. current thread: ${Thread.currentThread().name}")
}
launch {
println("new continuation todo something. current thread: ${Thread.currentThread().name}")
}
println("launch end. current thread: ${Thread.currentThread().name}")
}
/******列印結果******/
main
// 第一次launch
intercept todo something. change run to thread
create new thread
launch start. current thread: Thread-2
new continuation todo something in the main thread. current thread: main
create new thread
// 第二次launch
intercept todo something. change run to thread
create new thread
launch end. current thread: Thread-7
new continuation todo something. current thread: Thread-8
-
首先程式運行在main線程,啟動協程時將自定義的interceptor加入到上下文中,協程啟動時進行攔截,將在main線程運行的程式切換到新的thread線程
-
withContext沒有攔截成功,具體原因在下麵的調度器再詳細解釋,簡單來說就是我們自定義的interceptor被替換了。
-
launch start與launch end所處的線程不一樣,因為withContext結束之後,它內部還會進行一次線程恢復,將自身所處的main線程切換到之前的線程。協程每一個掛起後恢復都是通過回調resumeWith進行的,然而外部launch協程我們進行了攔截,在它返回的Continuation的resumeWith回調中總是會創建新的thread。
4.3 調度器
CoroutineDispatcher調度器指定指定執行協程的目標載體,它確定了相關的協程在哪個線程或哪些線程上執行。可以將協程限制在一個特定的線程執行,或將它分派到一個線程池,亦或是讓它不受限地運行。
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
//將可運行塊的執行分派到給定上下文中的另一個線程上
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
//返回一個continuation,它封裝了提供的[continuation],攔截了所有的恢復
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
//......
}
協程需要調度的位置就是掛起點的位置,只有當掛起點正在掛起的時候才會進行調度,實現調度需要使用協程的攔截器。
調度的本質就是解決掛起點恢復之後的協程邏輯在哪裡運行的問題。調度器也屬於協程上下文一類,它繼承自攔截器。
-
【val Default】: CoroutineDispatcher
-
【val Main】: MainCoroutineDispatcher
-
【val Unconfined】: CoroutineDispatcher
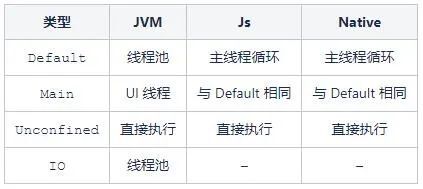
IO僅在 Jvm 上有定義,它基於 Default 調度器背後的線程池,並實現了獨立的隊列和限制,因此協程調度器從 Default 切換到 IO 並不會觸發線程切換
關於調度器介紹到這裡,還沒有詳細解釋前述協程攔截器中的withContext為什麼攔截失敗。這裡針對這個詳細看一下源碼實現。
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
其返回類型為MainCoroutineDispatcher,繼承自CoroutineDispatcher。
public abstract class MainCoroutineDispatcher : CoroutineDispatcher()
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
public open fun dispatchYield(context: CoroutineContext, block: Runnable): Unit = dispatch(context, block)
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
......
}
CoroutineDispatch實現了ContinuationInterceptor,根據前述解釋的CoroutineContext結構,可知我們自定義的攔截器沒有生效是因為被替換了。
CoroutineDispatch中的isDispatchNeeded就是判斷是否需要分發,然後dispatch就是執行分發。
ContinuationInterceptor重要的方法就是interceptContinuation,在CoroutineDispatcher中直接返回了DispatchedContinuation對象,它是一個Continuation類型,看一下其resumeWith實現。
override fun resumeWith(result: Result<T>) {
val context = continuation.context
val state = result.toState()
//判斷是否需要分發
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_ATOMIC
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_ATOMIC) {
withCoroutineContext(this.context, countOrElement) {
//不需要分發,直接使用原先的continuation對象的resumewith
continuation.resumeWith(result)
}
}
}
}
那麼分發的判斷邏輯是怎麼實現的?這要根據具體的dispatcher來看。
如果我們拿的是Dispatchers.Main,其dispatcher為HandlerContext。
internal class HandlerContext private constructor(
private val handler: Handler,
private val name: String?,
private val invokeImmediately: Boolean
) : HandlerDispatcher(), Delay {
override fun isDispatchNeeded(context: CoroutineContext): Boolean {
return !invokeImmediately || Looper.myLooper() != handler.looper
}
override fun dispatch(context: CoroutineContext, block: Runnable) {
if (!handler.post(block)) {
cancelOnRejection(context, block)
}
}
......
其中HandlerContext繼承於HandlerDispatcher,而HandlerDispatcher繼承於MainCoroutineDispatcher
Dispatcher的基本實現原理大致為:
-
首先在協程進行啟動的時候通過攔截器的方式進行攔截


