
To digitally transform the business, AI must be real-time. For AI to be real-time, we need real-time analytics.[1] Hybrid transaction/analytical proce ...

To digitally transform the business, AI must be real-time. For AI to be real-time, we need real-time analytics.[1]
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that "breaks the wall" between transaction processing and analytics. It enables more informed and "in business real time" decision making.
——Defined by Gartner
背景篇-引言
自 StoneDB 開源的第一天,我們就說要做真正的 HTAP,那麼究竟我們對 HTAP是怎麼理解的?解讀一門技術,就要從其發展背景入手,本篇文章中我們將從 OLTP 和 OLAP 最近的發展介紹及各自遇到的問題為基礎,引出 HTAP 相關概念。

OLTP:特點、適用場景、遇到的問題、最新進展
對事務型數據進行處理稱為聯機事務處理 (On Line Transaction Processing, OLTP)。OLTP 系統其主要的使用場景為記錄日常運營中與業務系統之間的交互記錄,並且支持以該數據進行查詢分析以獲得分析結果。
事務數據是指一種信息,用於跟蹤與組織活動相關的交互,常為:業務事務。例如:從客戶收到的付款、對供應商進行的付款、從庫存移動的產品、接受的訂單或交付的服務。表示事務本身的事務事件通常包含時間維度、數值等。
事務通常需要原子性和一致性。原子性意味著整個事務始終作為一個工作單元成功或失敗,永遠不會處於半完成狀態。如果無法完成某個事務,資料庫系統必須回退任何已完成的該事務的一部分工作,從而能夠保證整個工作要麼完成,要麼失敗。一致性意味著事務始終讓數據處於最終有效狀態,如果已將某個事務的一部分提交到資料庫,那麼該源事務中所有其他作用域內操作也將處於最終有效狀態並提交到資料庫中。事務型資料庫可以使用各種鎖定策略(如悲觀鎖定)支持事務的強一致性,以確保所有用戶和進程的所有數據在業務的上下文中具有強一致性。
事務型數據最常見的部署體繫結構是三層體繫結構。在該體繫結構中,事務型數據在數據存儲層被使用。三層體繫結構通常包含:表示層、業務邏輯層和數據存儲層。
適用場景
如果業務系統對數據完整性和實時性有約束要求,同時在業務的處理過程中需要保證數據的嚴格完整性,而且更改後的數據需要嚴格的持久性,此時OLTP 會是你的首要選擇。因為,OLTP 系統設計用於高效地處理和存儲事務,以及查詢事務數據。
面臨挑戰
實現和使用 OLTP 系統可能會帶來一些挑戰:
(1)OLTP 系統不是特別適合用於處理大量數據場景的複雜查詢。在大數據量複雜查詢場景下, OLTP 系統會消耗大量的計算資源和存儲資源,所以執行上可能較慢。而且如果此時其它事務也正在對某些複雜查詢的數據進行操作,往往會觸發系統中的鎖機制,這會導致整個系統性能的下降。
(2)在 OLTP 系統中,資料庫對象的命名約定通常簡潔而精煉,這對業務用戶專業素養要求較高。OLTP 系統中增強的規範化與簡潔的命名約定共同使得業務用戶在沒有 DBA 或數據開發者幫助的情況下難以執行查詢。
(3)歷史記錄以及在任何一個表中存儲太多數據都會導致查詢性能變慢。常見的解決方案是在 OLTP 系統中維護一個相關時間範圍(例如當前統計年度)並將歷史數據卸載到其他系統,例如:數據倉庫。

OLAP:特點、適用場景、遇到的問題、最新進展
聯機分析處理(英語:Online analytical processing),簡稱 OLAP,用來快速解決多維分析問題的一種方法。OLAP 是更廣泛的商業智能範疇的一部分,它還包括關係資料庫、報告編寫和數據挖掘。
企業用來存儲其所有事務和記錄的資料庫稱為聯機事務處理 (OLTP) 資料庫。它們通常包含對組織有價值的大量信息。OLTP 的資料庫不是為分析而設計的。因此,從這些資料庫中檢索答案從時間和工作量角度而言成本高昂。OLAP 系統設計用來以高性能方式從數據中提取商業智能信息。這是因為 OLAP 資料庫針對高頻讀取和低頻寫入進行了優化。
適用場景
- 需要快速執行複雜的分析和即席查詢,且不能對 OLTP 系統產生負面影響;
- 為業務用戶提供一種簡單的方式來基於數據生成報表;
- 提供大量聚合,這些聚合將使用戶能夠快速獲得響應結果。OLAP 適用於大量數據且查詢多為聚合計算的場景下。OLAP 系統針對高頻讀取應用場景(例如分析和商業智能)進行了優化。
面臨挑戰
OLAP 系統中的數據更新較少,具體取決於業務需求,這意味著 OLAP 系統更適用於戰略級業務決策,而非適用於立即對更改做出響應。另外,還需要規劃一定級別的數據清理和業務流程來使 OLAP 系統中的數據保持最新。
與 OLTP 系統中使用的傳統的規範化關係表不同,OLAP 的數據模型通常是多維的,在這種模型中,每個屬性映射到一個列,其難以或無法直接映射到實體關係或面向對象的模型。
**

OLTP VS OLAP
OLTP 和 OLAP 從不同維度之間的對比關係如下所示:
| 對比維度 | OLTP | OLAP |
|---|---|---|
| 一句話特征 | 小事務眾多的場景 | 使用複雜查詢來處理較大數據量的場景 |
| ACID | 強 | 弱 |
| 面向用戶 | 資料庫操作人員 | 決策人員、高級管理人員,資料庫科學家、業務分析師和知識工作者 |
| 使用場景 | 金融(如銀行、股票)、電商、旅行預訂等 | 商業智能(BI)、數據挖掘和氣壓決策支持應用程式 |
| 基本操作 | 主要為:insert, update, delete為主 | 主要為聚合操作,視窗操作等為主 |
| 操作數據範圍 | 通常讀寫數據量較小(數十條記錄) | 通常讀寫數據量大(數百萬條記錄) |
| 主要衡量指標 | 事務吞吐量(TPS) | 查詢響應速度(QPS) |
| 響應時間要求 | 實時性要求高,通常毫秒級 | 實時性要求低,依賴於所處理的數據量,時間範圍由小時,分鐘秒級,亞秒級等 |
| 數據源 | 業務系統實時事務數據 | 業務系統中的歷史數據,事務型數據 |
| 資料庫表設計規範 | 通常需要滿足三範式(3NF) | 不作規範 |
| 數據量/磁碟空間 | 較小,MB~TB級 | 較大,GB~PB級 |
| 併發量 | 需要支持大併發環境 | 對併發量要求不高 |
| 穩定性 | 要求高 | 要求高 |
| 可用性(備份,恢復) | 完整的備份,恢復能力(全量,增量) | 主要按時間點進行備份/恢復,備份/恢復要求不高 |
| 數據完整性要求 | 強一致性要求 | 數據完整性要求不高 |
| 系統吞吐量,IOPS | 低 | 高 |
| 挑戰 | 1.高吞吐量,保證數據完整性,可靠性等;2.完整的生態工具,不同異構產品間協調使用難度; | 1.海量數據高效,低成本的數據存儲;2.複雜查詢高效處理; |
| 可靠性要求 | 通常要求高可靠性:主備、同城災備、異地災備 | 可靠性要求相對低,一般同城災備 |
| 讀特性 | 簡單查詢為主、每次查詢只返回少量數據 | 複雜查詢為主、對大量數據進行彙總 |
| 寫特性 | 1.隨機、低延遲、小數據量;2.數據更新、刪除頻繁 | 1.很少有更新、刪除操作;2.大數據量批量、並行導入 |
| 數據模型 | ER(實體、關係) | 星型或者雪花、星座 |
| 數據粒度 | 行級 record | 多表 |
| 數據結構 | 高度結構化、複雜,適合操作計算 | 簡單、適合分析 |
| 數據欄位 | 動態變化,按欄位更新 | 靜態、很少直接更新,定時添加、刷新 |
| 數據返回值 | 一般為記錄本身或該記錄的多個列 | 一般為聚合計算結果 |
隨著時間的推移,越來越多的業務對於 AP 的要求越來越向著 TP 的指標看齊,例如:要求 AP 系統能夠實時反映出當前 TP 系統中的實際數據。同時,AP 系統可以支持數據的更新等等。總之,TP 系統和 AP 系統之間的邊界在業務層面和用戶層面上也越來越模糊,市場上迫切希望能夠出現一種新的架構或者稱之為者解決方案,能夠同時滿足業務對於 TP 負載和 AP 負載的需求。因此,HTAP 的概念隨之而誕生。2014年 Gartner 給出了 HTAP 的明確概念:Systems that can support both OLTP (On-line transaction processing) as well as OLAP (on-line analytics processing) within a single transaction.[4]

HTAP:HTAP概念引入的目的,定義,適用場景介紹,HTAP的商業驅動力——問題的源動力?
商業上的驅動力
當前市場上對於數據的處理方式越加的註重多種類型的負載混合進行,即對於用戶或者業務端來說,有一個統一的處理邏輯或者架構。如對於廣告計算,用戶畫像,分控,物流,地理信息等商業場景下,原有的處理方式為在海量的歷史數據中通過 AP(分析型處理)資料庫或者自建的大數據平臺,完成對於歷史數據的計算,然後將 AP 計算的結果作為 TP(事務型處理)的輸入結構,完成對於實時計算需求。
因此,在原有的架構環境下,對於此類的應用需要部署兩套環境分別應對 AP 和 TP 兩類負載,從而造成整個架構變得複雜,中間涉及到的組件較多,無法及時將 TP 數據實時更新到 AP 系統中,從而影響 BI 等應用的時效性。
" 陳舊的報告、缺失的數據、缺乏高級分析以及完全缺乏實時分析對於任何需要新見解以在商業客戶時代保持競爭力的企業來說都是一種無法忍受的狀態。"[2]
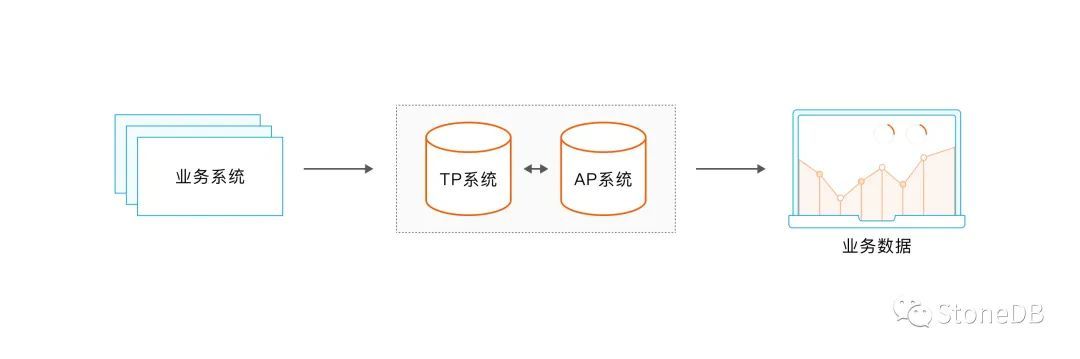
架構1:異構架構模式
商業上的驅動力,其原動力來自業務端的需求,沒有業務端的需求變化,不會導致商業上的驅動力,由於現在市場中無論是互聯網企業還是其他傳統型企業,在其早期業務的發展過程中通常會採用架構一的方式來往滿足業務需求;但該種架構在後期的使用過程中存在著各種各樣的問題,如 AP 模塊和 TP 模塊之間的數據同步問題,運維的問題等等,而著會導致巨大的運營成本。
隨著業務需要的發展和資料庫技術的發展,使得資料庫產品同時具有處理 AP 和 TP 的能力,且在處理 AP 負載的時候並不會對 TP 負載造成太大的性能波動,更重要的一個特性是在 TP 數據和 AP 數據可以做到“準”(或者實時)實時更新。因此,基於資料庫的此項能力,業務端即可將原有的 AP 處理模塊及 TP 處理模塊進行合併,統一的交由該資料庫進行處理,從而可以簡化業務系統的架構。

架構2:統一架構
HTAP 則為上述問題提供了另外一個解法和思路。將 AP 和 TP 的能力由統一的系統對外提供,由此構成的業務架構簡單化,同時具有一定的擴展特性。產生 HTAP 用戶側的需求或者訴求如下:
- 事務數據及歷史數據的集成。
- 理解用戶需求的超維度數據分析的需要;全局視角來看數據,方能看清事物的本質。(例如:從手機的位置信息,用戶的填表所獲得信息,社交媒體所獲得富媒體信息。)
- 企業運行所需的商業分析的實時性需求。
技術上的驅動力
"May the force be with you." ——Star War.
作為一個新技術產生的另外一個重要的來源:技術驅動力,這才是實現人們想象力的基石。下麵我們從技術的發展角度來看看,推動 HTAP 發展的另一個重要的源動力:in-memory, scale-out技術使得我們的架構可以進行擴展,使得我們可以在一個架構內滿足不同負載需要變為可能。列存技術的發展則是我們實現 HTAP 的基石,分層存儲架構為我們在成本和性能之間找到了一個平衡點。
1. 列存技術
面向列存的數據,最早可以追溯到 1970 年,隨著轉置文件(transposed files)的出現,在面向時間的資料庫(Time oriented Database)中使用轉置文件進行醫療數據記錄。Cantor 被稱為是最早的一個與現代列存資料庫相似的系統。例如:在現代列存資料庫中所常用的壓縮技術,delta 編碼等都可在 Cantor 中尋找到身影。
磁碟頁中數據所採用的兩種數據存儲模型:NSM(row-store, N-array Storage Model)和DSM(column-store, Decomposition Storage Model)。
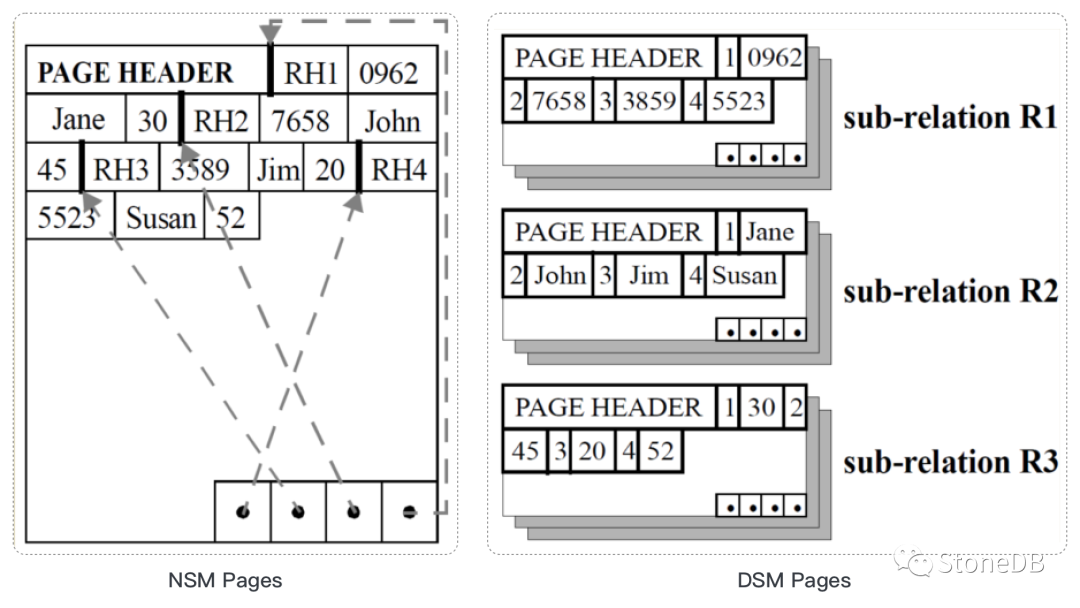
通常資料庫的數據物理上以行,頁,段等方式進行分級管理的,表中的一行數據由 N 個數據屬性構成,N 條數據構成一個頁面,多個頁面又構成了一個段,如此將眾多的記錄高效管理起來。以上便是我們所熟知的行存(Row-based)模型。當前,絕大多數資料庫為行存資料庫。對應行存的優點這裡我們不在贅述。我們來談談其優點的另一面,缺點。拋開應用場景談某個事務的優缺點本身就是一件奇怪的事情。
對應行存方式組織數據,我進行以分析型業務為主的系統中,分析所涉及的數據量通常非常多。即,將會有大量的記錄會參與到分析計算中。而這些大量的記錄需要從磁碟中讀取到我們資料庫的緩存中,由於數據是以行的方式組織,而我們的分析計算只需要特定的幾個屬性,例如:在一條包含:產品 Id,產品產地,產品銷量,銷售時間的記錄,分析計算可能只需要產品 ID 和產品銷量,這兩個屬性便可以得到我們需要的分析結果。對於產品的產地和銷售時間,我們並不關心。由此可以看出,當我們將這條記錄由磁碟讀取到資料庫的緩存中,產品產地,產品銷量這兩個屬性數據便屬於無效工作。其會導致我們這部分的數據屬性所對應的 IO 資源和其在資料庫緩存中的記憶體資源被浪費,而這兩部分資源在資料庫中又屬於非常寶貴的系統資源。
為瞭解決上述問題,在 1985 年,Copeland 和 Khoshafian 提出了 DSM 模型,而這也促成了列存資料庫的發展。與行存的方式不同,DSM 模型中,表中的數據已按屬性(列)的方式進行組織。由上圖中 DSM page 模型可以看出,該種方式下,每個屬性數據組織在一起構成一個子的關係並獨立於其它屬性。由於按屬性為單獨進行數據組織,那麼在磁碟上進行存儲這些數據的時候,我們可以對其進行壓縮處理。
該種數據存儲模型下,我們只需要讀取分析計算所需的屬性數據即可,從而可以節約寶貴的 IO 和 memory 資源。同時,DSM 模型也屬於 CPU Cache 友好型。但是,DSM 有一個問題是:其在將結果返回用戶的時候,或者在上層運算元進行計算的時候需要重構記錄。因為,此時我們獲得的數據是不完整的,而需要返回用戶時候需要一個完整的記錄。
針對上述問題的探索,學術界在 1990 左右進行了積極的嘗試,MonetDB項目應運而生。當然在隨後的歲月里也產生了 C-Store 和 VectorWise 等,到了 2000 年底的時候,列存資料庫百花齊放,涌現出諸如:Vertica, Ingres VectorWise, Paraccel, Infobright, Kickfire等等。當然商業資料庫公司也通過收購,自研等方式在各自的產品中提供了列存能力。例如:IBM BLU, SAP HANA,SQL-Server等。
2. in-memory技術(包括:distributed in-memory)
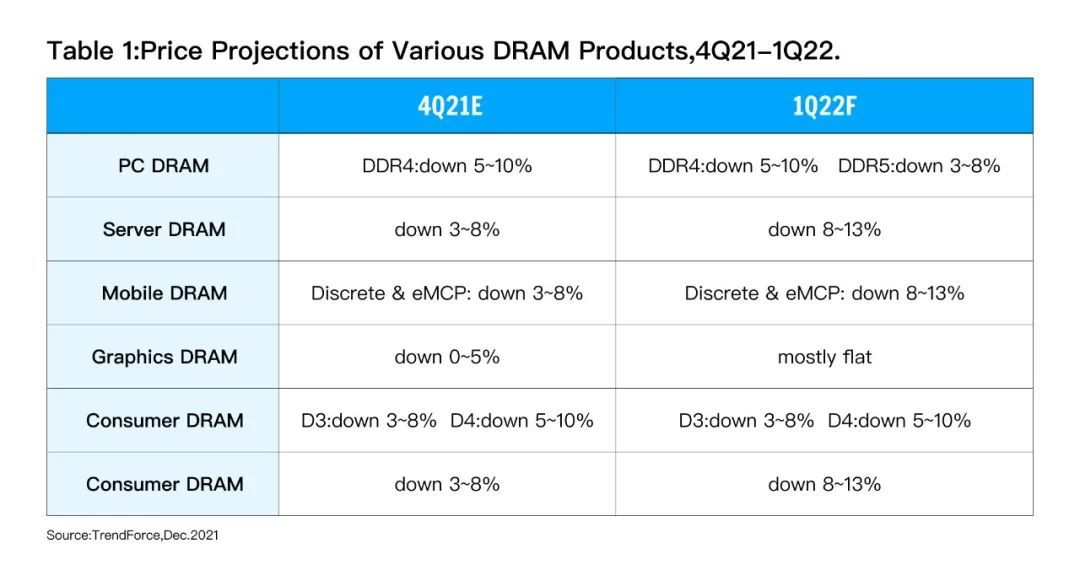
隨著記憶體價格未來的下降,越來越多的個人和組織可以以更加低廉的成本獲得由於技術發展帶來的技術紅利:in-memory 技術。從下表可以看出無論是 PC 上的 DRAM 還是伺服器端的 DRAM 價格在已每季度 3-10% 下降。
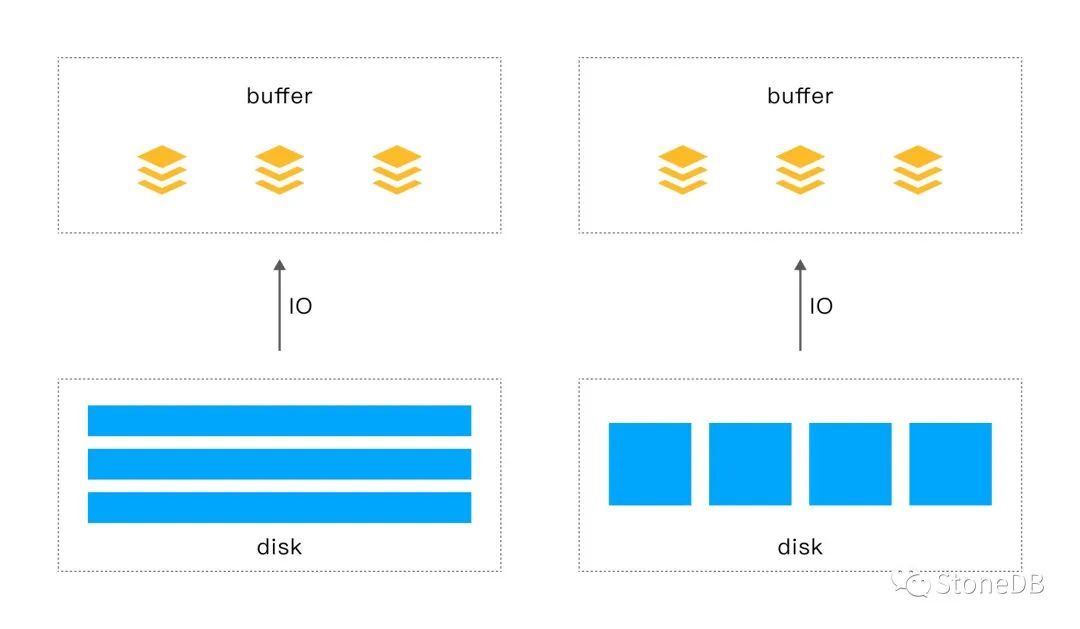
隨著記憶體價格的下降,我們可以在系統的設計時候,使用更為激進的方式——大量使用記憶體,甚至是全量記憶體的方式。
我們從經典的存儲層次架構圖中知道,DRAM 的訪問速度遠大於本地磁碟,但價格遠比磁碟貴。早期,受限制於 DRAM 高昂的價格,DRAM 都作為高速緩存保存由磁碟中所讀取的數據,例如: Buffer Pool。隨著記憶體價格的持續下降使得in-memory 資料庫不再是陽春白雪般的存在,慢慢的進入尋常百姓家。GB 級,TB 級的記憶體資料庫也時常可見。
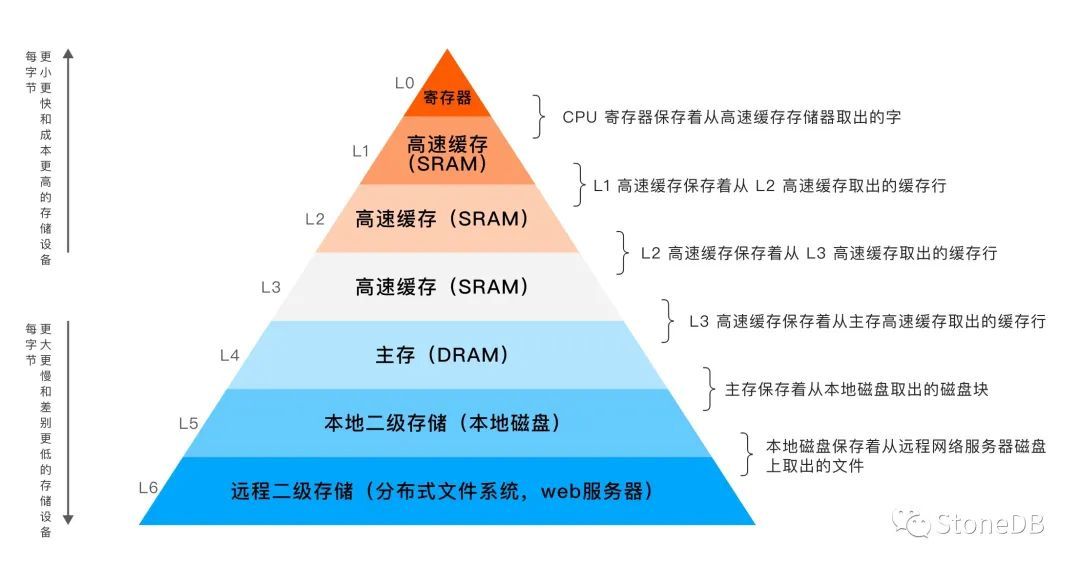
當需要執行Analytical Processing(AP)的時候,可以將 AP 所需數據載入記憶體中,甚至可以將所需的表的數據全部載入至記憶體中,從而獲得急速的處理速度。同時,可以持續的將 TP 引擎中的數據變化實時的同步到 AP 引擎中,從而滿足商業分析的實時性要求。
最後,為了保證系統 crash 的時候可以正確且快速的完成 recovery,需要將記憶體中的數據持久化至磁碟中。
3. 可擴展的架構:(scale-out architect): 水平擴展架構的發展,分散式鎖技術的成熟,記錄的分散式管理
為了滿足更大數據量的處理能力,在單節點的基礎上,通過水平擴展的方式將單節點的系統擴展為分散式多節點的系統,利用多節點的系統資源能力來解決,在大數據量場景下的計算能力不足的問題。與單節點系統不同,分散式系統通常由多個節點構成,通過網路進行通信、為了完成共同的任務而協調工作的電腦節點組成的系統。分散式系統的出現是為了用廉價的、普通的機器完成單個電腦無法完成的計算、存儲任務。其目的是利用更多的機器,處理更多的數據。無論是當前通過中間件的方式來實現的分庫分表,還是分散式式資料庫系統所採用的將數據通過某種分佈策略(例如通過主鍵或者分佈鍵將數據通過 hash 的方式進行分佈或者其它的方式)將數據分佈至 N 個數據節點上,由此使得單節點的處理數據量減少。
可擴展的架構並不算一個陌生的技術,尤其現在分散式計算已然大量的應用在生產系統中,無論是分散式框架技術,分散式文件系統,分散式事務等等都已形成了一套成熟的理論並且在工程上也已日益成熟。
對具有可擴展能力的架構來說,做到業務無感知的動態節點的擴縮其方案也日益成熟,例如:一致性 hash 演算法可以完成負載在分散式環境下的均衡。現在,對於分散式框架的水平擴展能力,無論是在理論上和工程上都有成熟的方案。
隨著具有可水平擴展的分散式架構的發展,分散式系統的能力越來越多的運用在資料庫領域。除了,作為基礎的分散式框架外,分散式事務的發展是使得我們能夠處理跨節點的事務。由此,資料庫系統可以充分的利用多節點的計算能力來實現對於大數據業務場景下的實時性的要求。
對於 HTAP,來說由於其涉及到兩個不同的存儲模型(或稱之為:格式),那麼我們在事務處理方面對於 row-base 和 columnar-base 兩類數據有著不同的處理方式。對於事務的支持這部分需要我們給出仔細的考慮。同時對於 HTAP 所需要的分散式架構其帶來的分散式事務處理這裡也是一個點,好在當前市面上對於分散式事務處理相關技術相對成熟。
最後,當然分散式對於 HTAP 來說,只是一個充分條件,而非必要條件。不考慮用戶實際情況的一上來有最小節點部署要求的解決方案都是“耍流氓”。
4. 數據壓縮(data compression)
考慮到AP場景下,通常所需要處理的數據量巨大,從成本的角度考慮,同時也從IO效率的角度出發,對於數據進行有效的壓縮,將為系統帶來較多的收益。隨著壓縮演算法對於數據類型的支持和壓縮比的提升,對數據進行壓縮,已變為AP系統來一個標準做法。
5. 分層存儲架構(tiered storage)
考慮到用戶的計算資源的情況和數據量的實際業務場景下。通常所需要處理的數據量遠遠大於系統所擁有的計算資源。我們知道越靠近 CPU 的存儲,其單價會越高,為了能夠以最大的性價比的方式對用戶提供搞性能,分層存儲架構應運而生。例如:我們可以使用 DRAM,NVME,SSD,HDD 來構成分層存儲架構。將對於計算實時性有要求的數據載入至 DRAM 中進行計算,以獲得實時計算結果。如果計算過程複雜,中間結果集較大,可將中間結果集保存至 NVME 中,這樣既可以保證數據的實時性,又可以支持更大的數據量,以獲得較高的性價比。同樣,SSD 和 HDD 的也起著同樣的作用。
雖然分層存儲架構看似有著非常誘人和廣闊的使用場景,但是其同樣存在著以下幾個挑戰,使得我們在使用該種方案的時候需要格外小心。
- 首當其衝的,就是在不同層級之間的數據一致性的問題。這個問題比較好理解。在分層存儲架構下,數據通常分佈在不同的存儲層級之間,數據的改寫必然導致數據的不致的問題。在內部分層存儲時,可以採用寫穿透(write through)策略或者寫回(write back)策略。而不同的方法也有各自優缺點,這裡就不再贅述。但是外部分層存儲與內部分層存儲有一個最大的不同是,記憶體儲最終數據需要寫到記憶體中,而外分層存儲中,則不是必須的。當然也可以設計成這樣的實現方案,但是這樣話,分層存儲的性能優勢則必定會受到影響。
- 其次,如何快速的由分層存儲中獲取相應的數據也將是一個不小的挑戰。由於按照分層存儲的架構,越是層級越低其存儲容量越大,訪問速度越慢。如何在這些海量數據中快速定位到所需數據,將給數據的組織,數據的索引等提出挑戰。最後,是性能和成本之間的 trade-off。如何選擇每個分層中的存儲介質,從而能夠保證整體性能優秀,同時又不至於導致存儲成本飆升。

總結
綜上,本文對 HTAP 的產生背景做了詳細的分析,並提煉出商業和技術上的驅動力,顯而易見,一個新型的技術得到追捧,一定離不開技術的成熟、市場的需要和商業的成功,HTAP 就是誕生在這樣的背景下。
那麼,如果我們從 HTAP 的定義及其核心技術出發,一款真正的 HTAP 產品要具備哪些能力?構建真正的 HTAP 時會遇到什麼核心問題?這些核心問題都有哪些解決方案?這些問題的答案將在我們的接下來的文章中揭曉。
可以提前劇透的是:在下一篇文章中,我們將指出,真正的 HTAP 並不應該是簡單地將 TP 和 AP 相加:TP + AP ≠ HTAP。HTAP 一定是將 TP 和 AP 進行高度融合的產物。
將 TP 系統通過簡單的數據同步方式,例如通過 Binlog 等,將 TP 中的數據同步到 AP 系統,然後由 AP 系統進行處理的方式,雖然該種方式從用戶的角度來看似乎其獲得同時處理 TP 和 AP 的能力,但是從本質上來看,我們並不認為其是一個 HTAP 產品。
此文是《什麼是真正的 HTAP》系列文章的第一篇,後續我們將持續更新此系列文章,敬請關註。
參考資料
[1]AI must be real-time: https://splicemachine.com/blog/how-to-measure-an-htap-data-platform-for-ai-applications/
[2]Forrester: Emerging Technology: Translytical Databases Deliver Analytics At The Speed Of Transactions.
[3]_https://docs.microsoft.com/zh-cn/azure/architecture/data-guide/relational-data/online-transaction-processing_
[4]https://www.gartner.com/en/documents/2657815
StoneDB 是國內首款基於 MySQL 的一體化實時 HTAP 開源資料庫,內核引擎完全自研。我們將在開源資料庫領域持續耕耘,不斷與各個開源資料庫社區、企業合作共建,共創國產開源資料庫良好生態。
StoneDB 在6月29日已宣佈正式開源。如果您感興趣,可以通過下方鏈接查看 StoneDB 源碼、閱讀文檔,期待你的貢獻!
StoneDB 開源倉庫
https://github.com/stoneatom/stonedb
作者:李浩
StoneDB 首席架構師、StoneDB PMC
曾在華為、愛奇藝、北大方正從事資料庫內核核心架構設計。超過10年資料庫內核開發經驗,擅長查詢引擎,執行引擎,大規模並行處理等技術。擁有數十項資料庫發明專利,著有《PostgreSQL查詢引擎源碼技術探析》。
編輯 &校對:李明康、王學姣


