
背景介紹 StoneDB 是一款相容 MySQL 的開源 HTAP 資料庫。StoneDB 的整體架構分為三層,分別是應用層、服務層和存儲引擎層。應用層主要負責客戶端的連接管理和許可權驗證;服務層提供了 SQL 介面、查詢緩存、解析器、優化器、執行器等組件;Tianmu 引擎所在的存儲引擎層是 Sto ...
背景介紹
StoneDB 是一款相容 MySQL 的開源 HTAP 資料庫。StoneDB 的整體架構分為三層,分別是應用層、服務層和存儲引擎層。應用層主要負責客戶端的連接管理和許可權驗證;服務層提供了 SQL 介面、查詢緩存、解析器、優化器、執行器等組件;Tianmu 引擎所在的存儲引擎層是 StoneDB 的核心,數據的組織和壓縮、以及基於知識網格的查詢優化均是在 Tianmu 引擎實現。
本文主要為大家介紹 StoneDB 的讀操作、寫操作執行過程,方便大家瞭解引擎架構、內部邏輯和各個功能模塊。
一、Tianmu 引擎架構
1 Tianmu 存儲引擎在 Server 組件中的位置
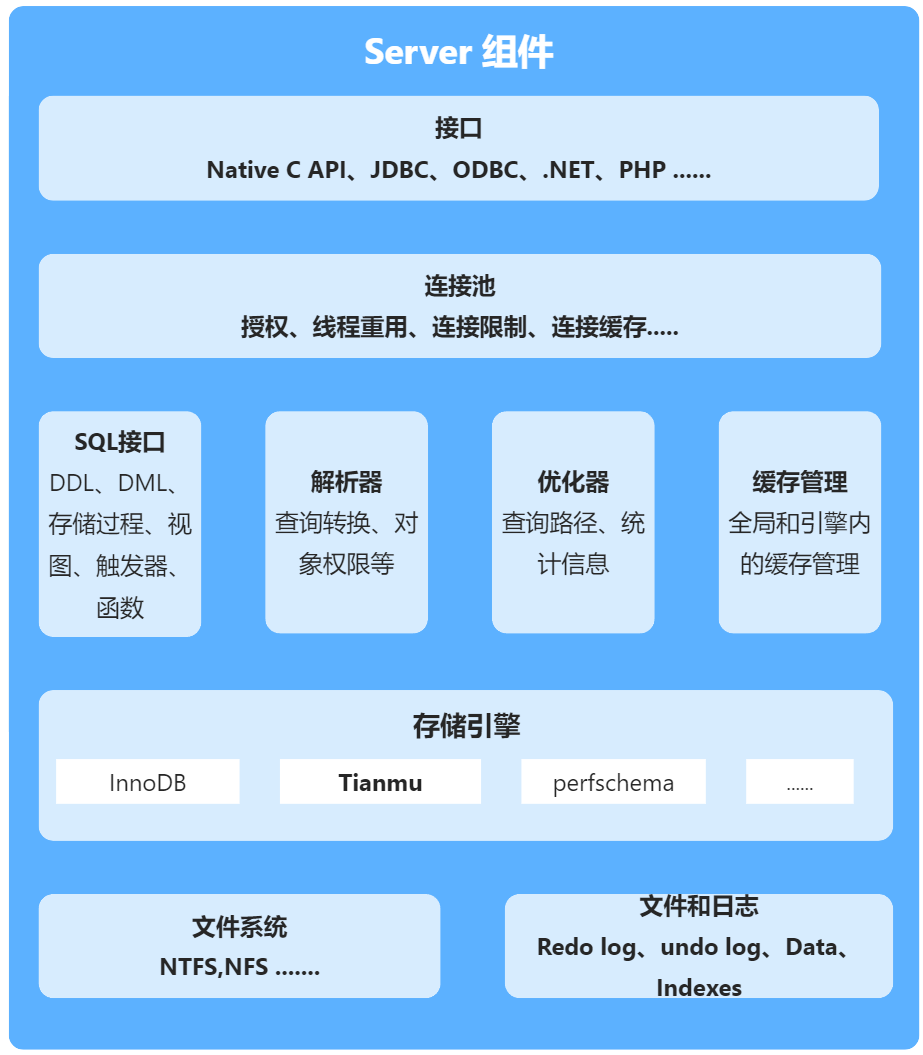
2 Tianmu 引擎架構圖
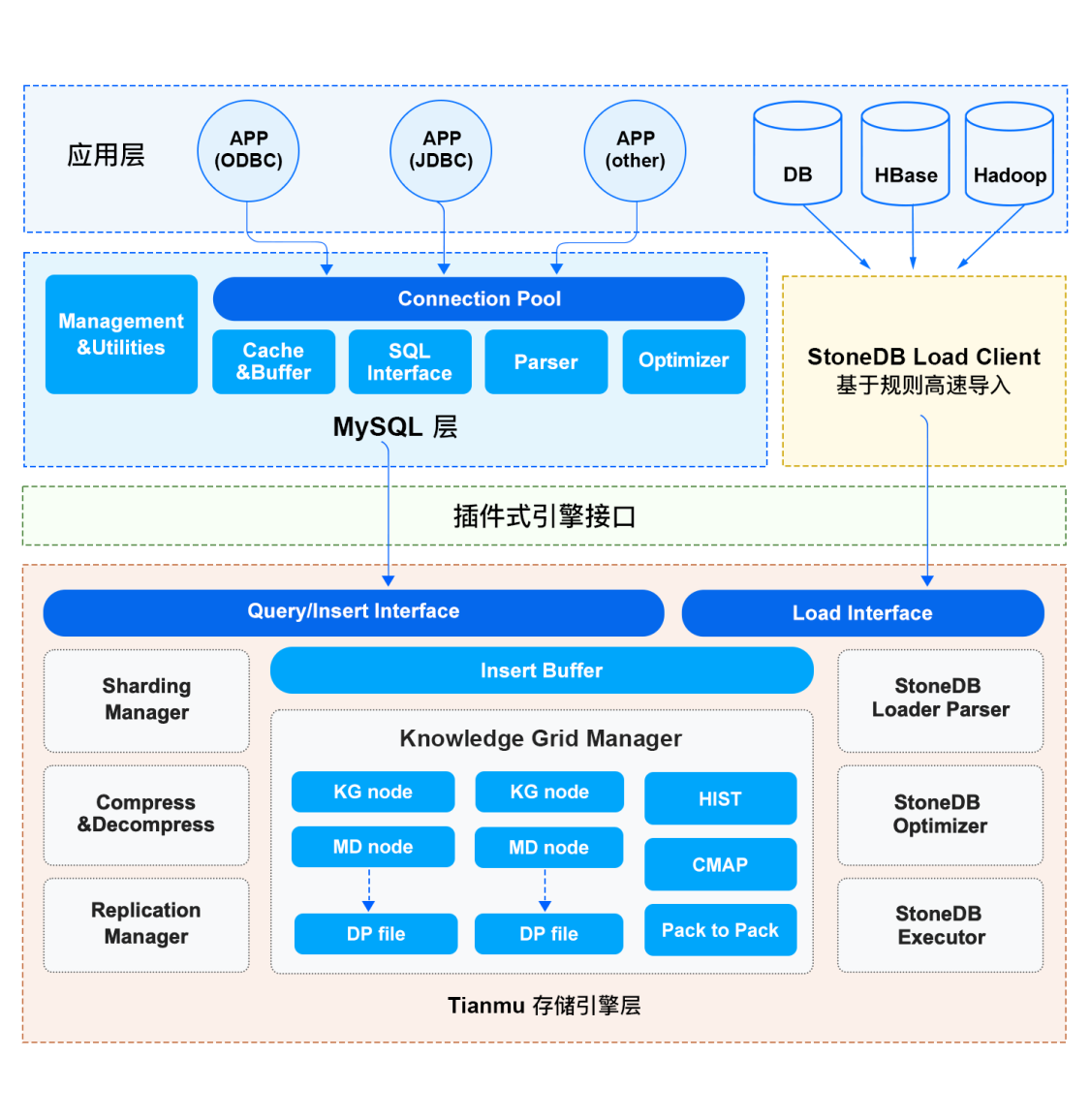
3 Tianmu 引擎各個模塊介紹
Tianmu Parser
解析客戶端傳來的 SQL ,進行關鍵字提取、解析,生成解析樹。解析的詞包括 select、update、delete、or、group by 等,對不支持的語法會向客戶端拋出異常:ERROR:You have an error in your SQL syntax.
比如,執行如下語句:
select * from user where userId =1234;
在分析器中就通過語義規則器將 select、from、where 這些關鍵詞提取和匹配出來, MySQL 會自動判斷關鍵詞和非關鍵詞,將用戶的匹配欄位和自定義語句識別出來。這個階段也會做一些校驗,比如校驗當前資料庫是否存在 user 表,同時假如 user 表中不存在 userId 這個欄位同樣會報錯:unknown column in field list.
解析入口:
parse_sql()
Tianmu Optimizer
對於來自客戶端的請求,首先由查詢優化器進行基於知識網格的優化,產生執行計劃後再交給執行引擎去處理。基於知識網格中的信息進行粗燥集(Rough Set)構建,並確定此次請求所需使用到的數據包。
優化入口:
optimize_select()
Insert Buffer
InnoDB 的 insert buffer 是為輔助索引的插入做的優化設計,而 Tianmu 的 insert buffer 是為整張表的插入做的優化設計。當向表插入數據時,數據先暫存到 Tianmu 的 insert buffer,然後再從 insert buffer 批量刷新到磁碟,從系統的表現來看是吞吐量提高了。如果不經過 insert buffer,而是直接寫入磁碟,由於 Tianmu 不支持事務,只能一行接著一行往磁碟寫入,系統的吞吐量是不高的,插入效率固然不高。Tianmu 的 insert buffer 由變數 stonedb_insert_delayed 控制,預設為 on 表示開啟。
插入緩存入口:
Engine::insert_buffer
Knowledge Grid Manager
Tianmu 引擎利用知識網格架構來對查詢優化器、計劃執行和壓縮演算法等提供支持。知識網格是 Tianmu 引擎進行快速數據查詢的關鍵,在查詢計劃分析與構建過程中,通過知識網格可以消除或大量減少需要解壓的數據塊,降低 IO 消耗,提高查詢響應時間和網路利用率。 對於大部分統計/聚合性查詢,Tianmu 引擎往往只需要使用知識網格就能返回查詢結果(而不需要讀取數據), 這種情況下在 1s 時間內就可以返回查詢結果。
入口函數:
RCAttr::ApproxAnswerSize
Knowledge Grid
Knowledge Grid,即知識網格,是 Tianmu 引擎進行快速數據查詢的關鍵,在查詢計劃分析與構建過程中,通過知識網格可以消除或大量減少需要解壓的數據塊,降低 IO 消耗,提高查詢響應時間和網路利用率。
KN Node
Knowledge Node(KN Node),即知識節點,除了基礎元數據外,還包括數據特征以及更深度的數據統信息,知識節點在數據查詢/裝載過程中會動態計算。
DPN
Data Pack Node(DPN),即數據包節點,又叫元數據節點(Metadata Node,MD Node),與數據包(DP)之間保持一一對應關係,數據包節點中包含了其對應數據包的元數據信息。
數據結構:
struct DPN{}
獲取DPN:
DPN &get_dpn
Data Pack
Data Pack(DP),即數據包,是存儲的最底層,列中每份大小固定的單元組成一個數據塊。
DP 是存儲的最底層,列中每份大小固定的單元組成一個數據塊。數據塊比列更小,具有更好的壓縮比率,又比磁碟預設存儲單元單元更 大,具有更好的查詢性能。 物理數據按固定數據塊存儲 (DP)、 數據塊大小固定(典型值128KB)、優化 IO 效率、提供基於塊 (Block) 的高效壓縮/加密演算法。
獲取 DP:
Pack *get_pack(size_t i)
CMAP
字元過濾,粗糙集過濾尋找可疑包,生成字元點陣圖文件。
RSIndex_CMap::RSIndex_CMap;
HIST
整形過濾,粗糙集過濾尋找可疑包,生產直方圖文件。
RSIndex_Hist::RSIndex_Hist
Replication Manager
StoneDB 複製引擎, StoneDB 本身與常見關係資料庫的高可用架構一樣(例如 MySQL ),為了保證強一致性,都會將數據更新在 Master 上執行,然後通過複製技術將副本導入到 Slave 節點。但是與 MySQL 標準的 binlog 複製不同,Tianmu 引擎中存儲的不是原始數據,而是壓縮後的數據塊(DP) 。此時如果使用 binlog 的方式來進行複製,會導致網路上產生大量數據流量。為瞭解決這一點,Tianmu 實現了基於壓縮後數據塊的高效數據複製支持,相對於 binlog 複製,該技術可以大大降低網路傳輸所需的數據量。
Compress&Decompress
數據壓縮和解壓模塊,Tianmu 基於列數據類型和特定領域優化的壓縮演算法,因為列中所有記錄的類型一致,可以基於數據類型選擇壓縮演算法,列中重覆值越高壓縮效果越好。除了常規的壓縮演算法外,針對特殊場景提供高效的壓縮演算法,如 Email 地址, IP 地址, URL 等 。
壓縮入口:
Compress()
解壓入口:
CprsErr Decompress
二、讀操作執行過程
對於來自客戶端的請求,首先由查詢優化器進行基於知識網格的優化,產生執行計劃後再交給執行引擎去處理。
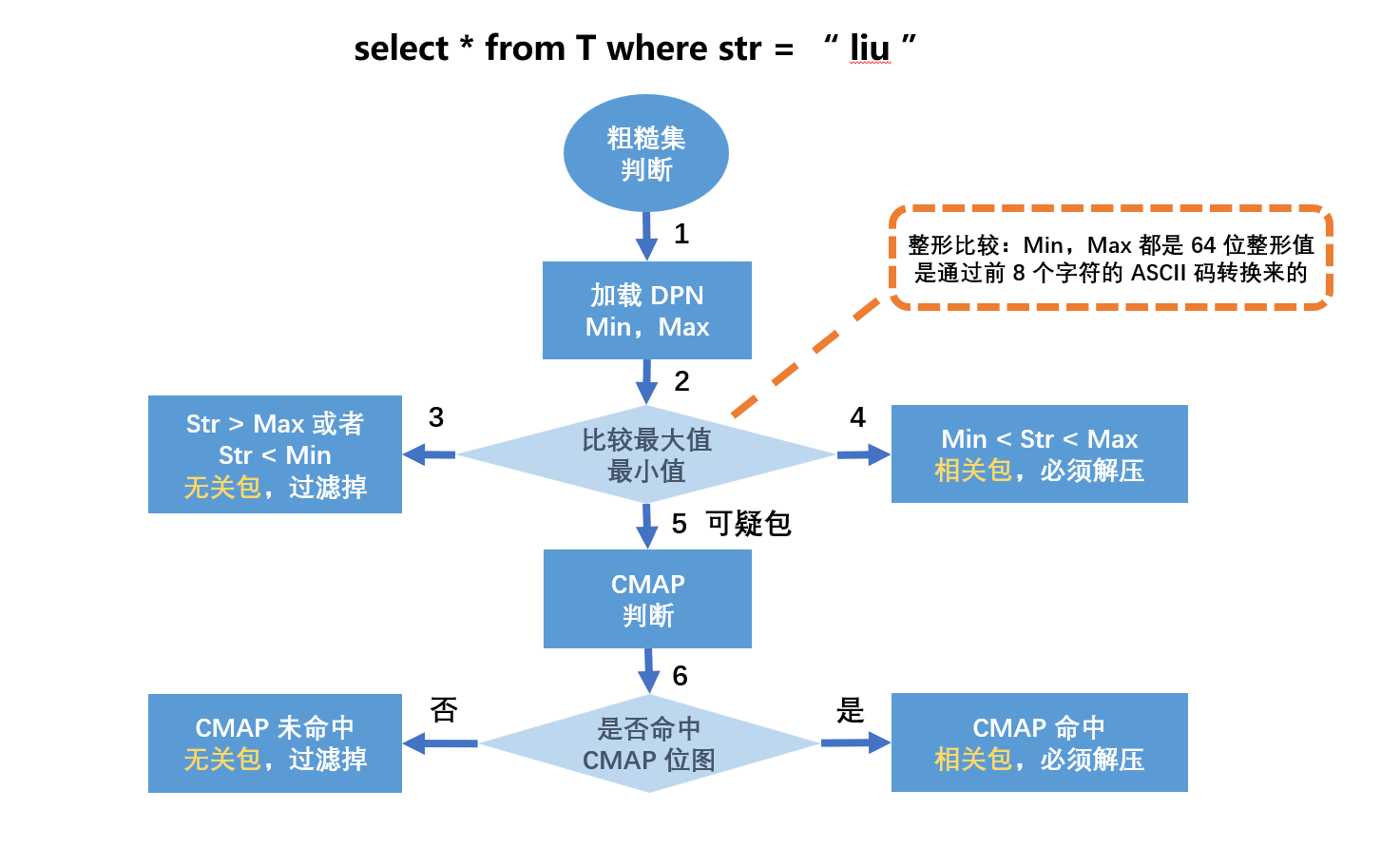
- 基於知識網格中的信息進行粗燥集(Rough Set)構建, 並確定此次請求所需使用到的數據包(DP)。
- 基於知識節點和數據包節點,確定查詢涉及到的數據包集合,並將數據包歸類:
- 相關 DP:滿足查詢條件限制的 DP(直接讀取並返回);
- 可疑 DP:DP 中部分數據滿足查詢條件(解壓後進行處理再返回)
- 不相關 DP:與查詢條件完全不相關(直接忽略)。
執行計劃構建時, 會完全規避不相關 DP,僅讀取並解壓相關 DP,按照特定情況決定是否讀取可疑 DP。例如,對於一個查詢請求,通過 Knowledge Grid 可以確定 3 個相關和 1 個可疑 DP。如果此請求包含聚合函數,此時只需要解壓可疑 DP 並計算聚合值,再結合 3 個相關 DP 的數據包節點 (DPN)中的統計值即可得出結果。如果此請求需要返回具體數據,那麼無論相關 DP 還是可疑 DP,都需要讀取數據塊並解壓縮,以獲得結果集。
-
如果查詢請求的結果可以直接從 DPN 中產生(例如 count, max, min 等操作),則直接返回元信息節點中的數據,無需訪問物理數據文件。
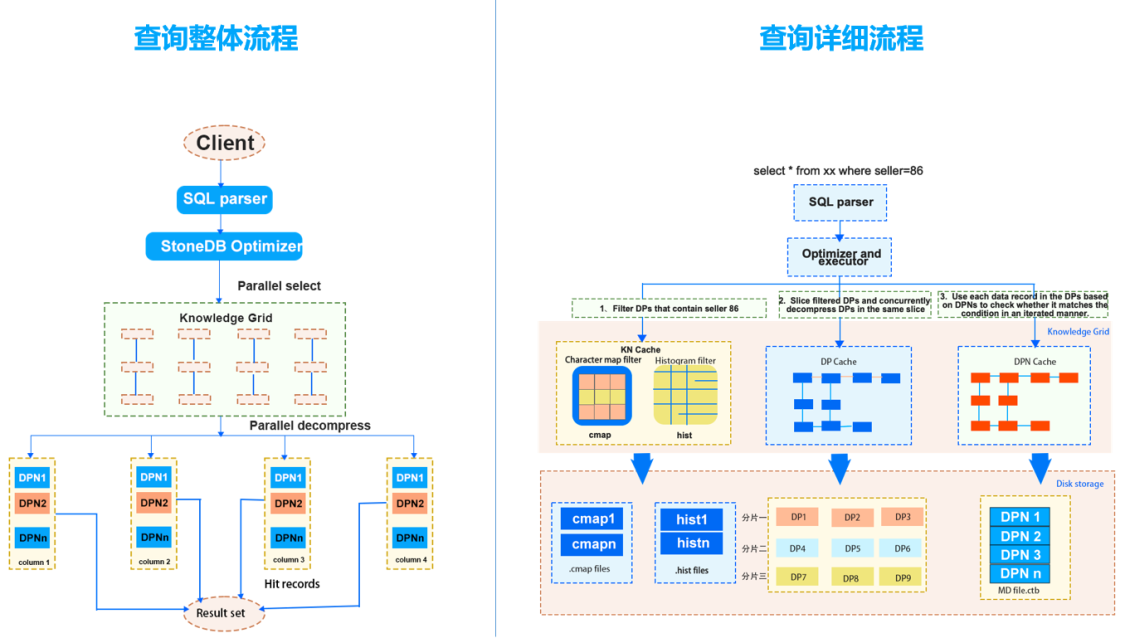
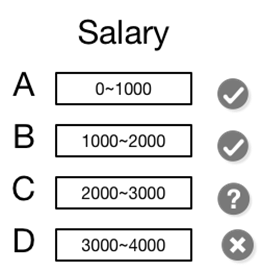
例如:SELECT count(*) FROM employees where salary < 2500: -
通過 Knowledge Grid 知識,查找包含 salary < 2500 的 DP,此處可以看到只有 A/B/C 三個 DP 涉及到該查詢。
-
DP A 與 B 屬於相關 DP, 只需直接從對應的 DPN 中獲取 count 值即可。
-
DP C 屬於不相關 DP,需要讀取數據塊並解壓,執行函數計算後才能返回結果集。
-
這裡只有 DP C 會被讀取並解壓,DP A 與 B 並不消耗 IO 資源。
執行代碼:
Engine::HandleSelect();
Engine::GetTableShare();
class ColumnShare;
ColumnShare::map_dpn();
ColumnShare::read_meta();
ColumnShare::scan_dpn();
TableShare::TableShare();
RCAttr::RoughCheck;
RSIndex_CMap::RSIndex_CMap;
CprsErr Decompress;
TempTable::SendResult();
三、寫操作執行過程
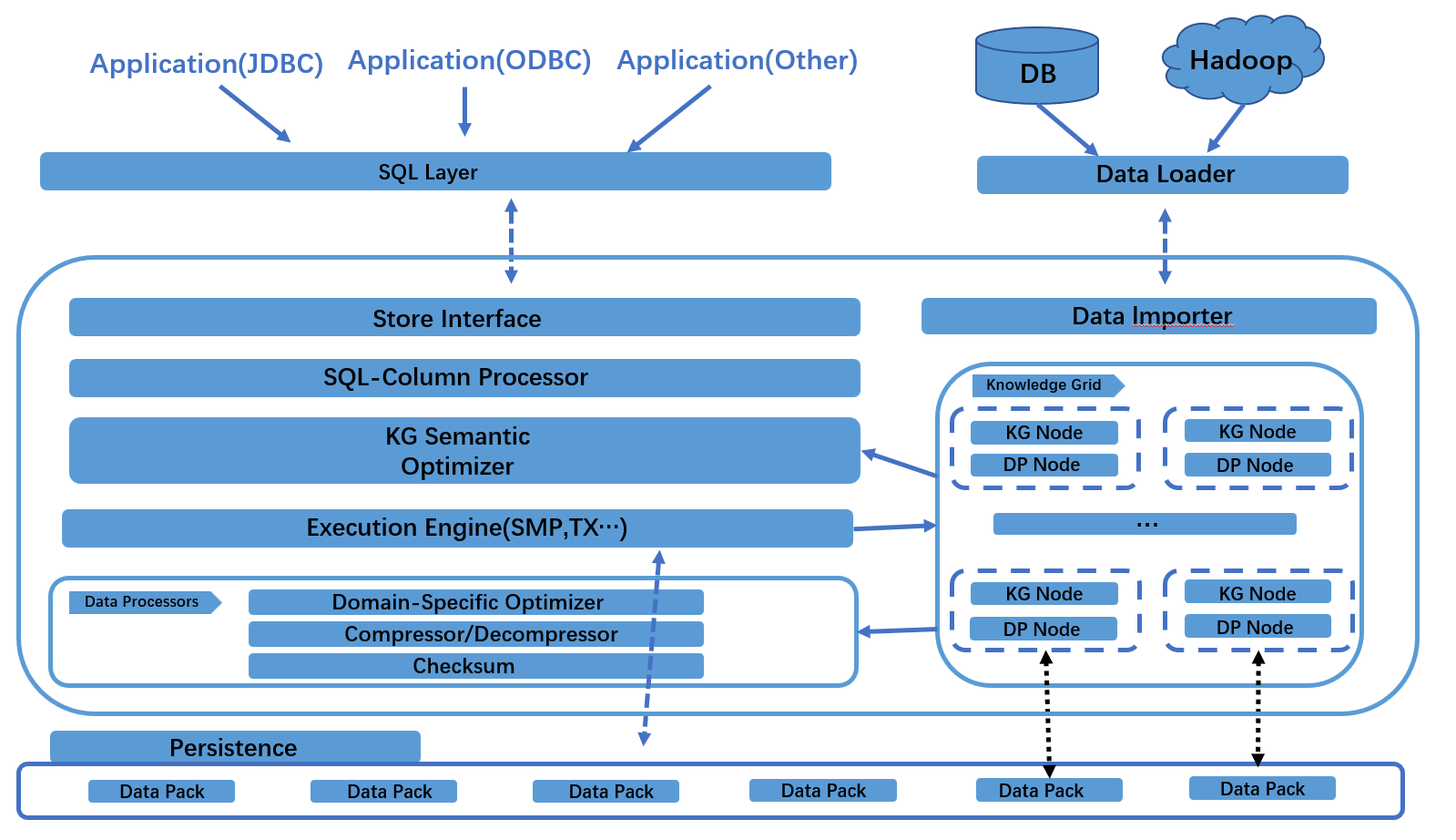
來自客戶端的請求經過連接器、分析器後,由查詢優化器進行基於知識網格的優化,產生執行計劃,經過數據的壓縮、校驗後再交給執行引擎去處理。
Tianmu 執行引擎將數據組織為兩個層次:物理存儲介質上的的數據塊(Data Pack,DP),記憶體上的知識網格層(Knowledge Grid,KG)。
入口函數:
write_row


