
蒼穹之邊,浩瀚之摯,眰恦之美; 悟心悟性,善始善終,惟善惟道! —— 朝槿《朝槿兮年說》 寫在開頭 我國宋代禪宗大師青原行思在《三重境界》中有這樣一句話:“ 參禪之初,看山是山,看水是水;禪有悟時,看山不是山,看水不是水;禪中徹悟,看山仍然山,看水仍然是水。” 作為一名Java Developer, ...
蒼穹之邊,浩瀚之摯,眰恦之美; 悟心悟性,善始善終,惟善惟道! —— 朝槿《朝槿兮年說》

寫在開頭
我國宋代禪宗大師青原行思在《三重境界》中有這樣一句話:“ 參禪之初,看山是山,看水是水;禪有悟時,看山不是山,看水不是水;禪中徹悟,看山仍然山,看水仍然是水。”
作為一名Java Developer,在面對Java併發編程的時候,有過哪些的疑惑與不解 ?對於Java領域中的線程機制與多線程,你都做了哪些功課?是否和我一樣,在看完《Java編程思想》和《Java併發編程實戰》之後,依舊一頭霧水,不知其跡?那麼,希望你看完此篇文章之後,對你有所幫助。
從一定程度上說,Java併發編程之路,實則是一條“看山是山,看山不是山,看山還是山”的修行之路。大多數情況下,當我們覺得有跡可循到有跡可尋時,何嘗不是陷入了另外一個“怪圈”之中?
從搭載Linux系統上的伺服器程式來說,使用Java編寫的是”單進程-多線程"程式,而用C++語言編寫的,可能是“單進程-多線程”程式,“多進程-單線程”程式或者是“多進程-多線程”程式。其中,“多進程-多線程”程式是”單進程-多線程"程式和“多進程-單線程”程式的組合體。
相對於操作系統內核來說,Java程式屬於應用程式,只能在這一個進程裡面,一般我們都是直接利用JDK提供的API開發多個線程實現併發。
而C++直接運行在Linux系統上,可以直接利用Linux系統提供的強大的進程間通信(Inter-Process Communication,IPC),很容易創建多個進程實現併發程式,並實現進程間通信。
但是,多線程的開發難度遠遠高於單線程的開發,主要是需要處理線程間的通信,需要對線程併發做控制,需要做好線程間的協調工作。
對於固定負載情況下,在描述和研究計算併發系統處理能力,以及描述並行處理效果的加速比,一直有一個比較著名的計算公式:
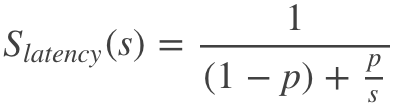
就是我們熟知的阿姆達爾定律(Amdahl"s Law),在這個公式中,
[1]. P:指的是程式中可並行部分的程式在單核上執行的時間占比。一般用作表示可改進性能的部件原先運行占用的時間與系統整體運行需要的時間的比值,取值範圍是0 ≤ P ≤ 1。
[2]. S:指的是處理器的個數(總核心數)。一般用作表示升級加速比,可改進部件原先運行速度與改進後的部件速度的比值,取值範圍是S ≥ 1。
[3]. Slatency(s):指的是程式在S個處理器相對在單個處理器(單核)中速度提升比率。一般用作表示整個任務的提速比。
根據這個公式,我們可以依據可確定程式中可並行代碼的比例,來決定我們實際工作中增加處理器(總核心數)所能帶來的速度提升的上限。
無論是C++開發者在Linux系統中使用的pthread,還是Java開發者使用的java.util.concurrent(JUC)庫,這些線程機制的都需要一定的線程I/O模型來做理論支撐。
所以,接下來,我們就讓我們一起探討和揭開Java領域中的線程I/O模型的神秘面紗,針對那些盤根錯落的枝末細節,才能讓我們更好地瞭解和正確認識ava領域中的線程機制。
關健術語

本文用到的一些關鍵詞語以及常用術語,主要如下:
- 阿姆達爾定律(Amdahl 定律): 用於確定併發系統中性能瓶頸部件在採用措施提示性能後,此部件對系統性能提示的改進程度,即系統加速比。
- 任務(Task): 表示一個程式需要被完成工作內容,與線程非一對一對應的關係,是一個相對概念。
- 併發(Concurrent): 表示至少一個任務或者若幹 個任務同一個時間段內被執行,但是不是順序執行,大多數都是以交替的方式被執行。
- 並行(Parallel): 表示至少一個任務或者若幹 個任務同一個時刻被執行。主要是指一個並行連接通過多個通道在同一時間內傳播多個數據流。
- 串列(Serial): 表示至多一個任務或者只有一個 個任務同一個時刻被執行。主要是指在同一時間內只連接傳輸一個數據流。
- 內核線程(Kernel Thread): 表示由內核管理的線程,處於操作系統內核空間。用戶應用程式通過API和系統調用(system call)來訪問線程工具。
- 應用線程(Application Thread): 表示不需要內核支持而在用戶應用程式中實現的線程,處於應用程式空間,也稱作用戶線程。主要是由JVM管理的線程和JVM自己攜帶的JVM線程。
- 上下文切換(Context Switch): 一般是指任務切換, 或者CPU寄存器切換。當多任務內核決定運行另外的任務時, 它保存正在運行任務的當前狀態, 也就是CPU寄存器中的全部內容。這些內容被保存在任務自己的堆棧中, 入棧工作完成後就把下一個將要運行的任務的當前狀況從該任務的棧中重新裝入CPU寄存器, 並開始下一個任務的運行過程。在Java領域中,線程有生命周期,其上下文信息的保存和恢復的過程。
- 線程安全(Thread Safe): 一段操作共用數據的代碼能夠保證同一個時間內被多個線程執行而依然保證其數據的正確性的考量。
基本概述
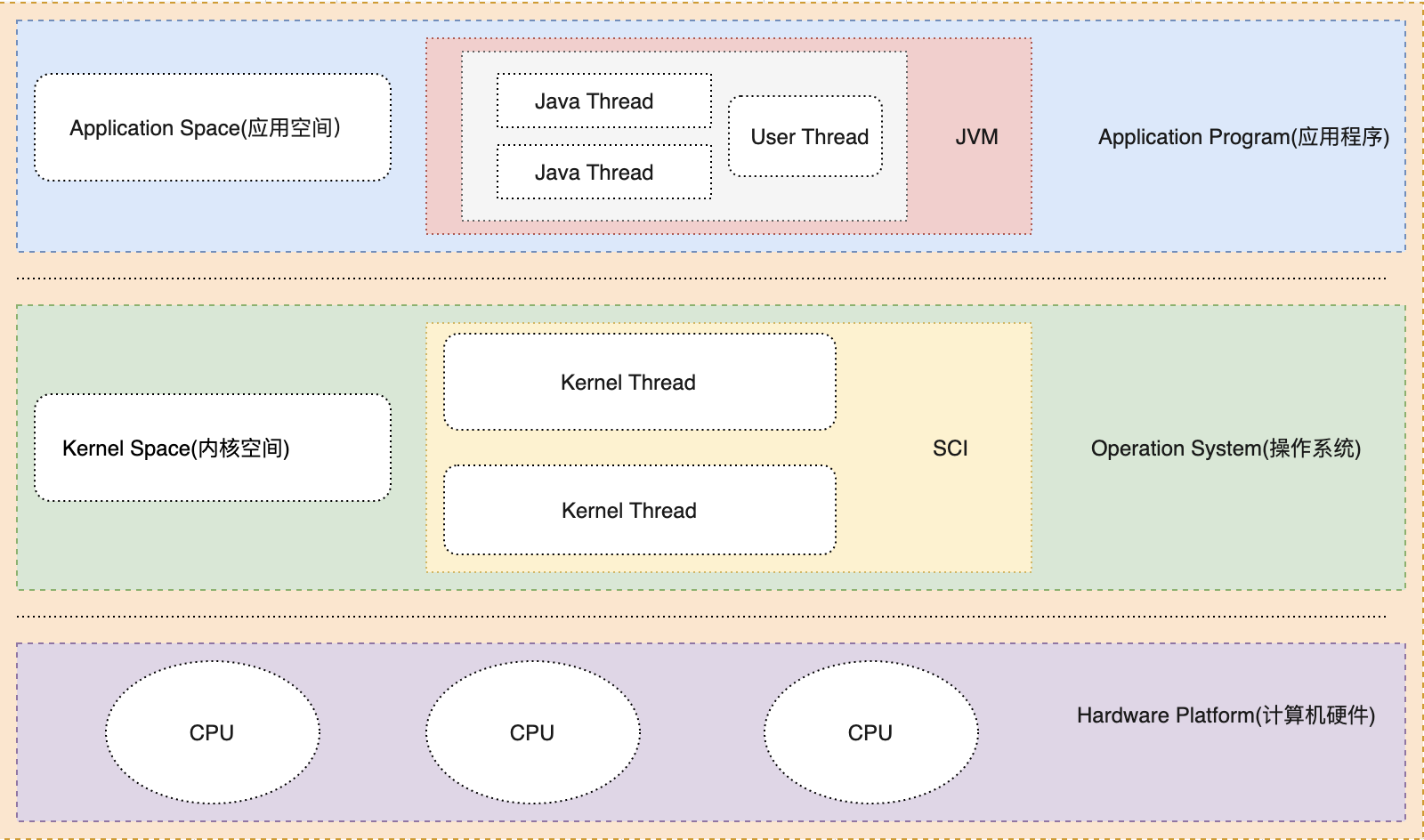
Java領域中的線程主要分為Java層線程(Java Thread) ,JVM層線程(JVM Thread),操作系統層線程(Kernel Thread)。
對於Java領域中,從一定程度上來說,由於Java程式並不直接運行在Linux系統上,而是運行在JVM(Java 虛擬機)上,而一個JVM實例是一個Linux進程,每一個JVM都是一個獨立的“沙盒”,JVM之間相互獨立,互不通信。
按照操作系統和應用程式兩個層次來說,線程主要可以分為內核線程(Kernel Thread) 和應用線程(Application Thread)。
其中,在Java領域中的線程主要分為Java層線程(Java Thread) ,JVM層線程(JVM Thread),操作系統層線程(Kernel Thread)。
一般來說,我們把應用線程看作更高層面的線程,而內核線程需要嚮應用線程提供支持。由此可見,內核線程和應用線程之間存在一定的映射關係。
因此,從線程映射關係來看,不同的操作系統可能採用不同的映射方式,我們把這些映射關係稱為線程的映射,或者可以說作線程映射理論模型(Thread Mappered Theory Model )。
在Java領域中,對於文件的I/O操作,提供了一系列的I/O功能API,主要基於基於流模型實現。我們把這些流模型的設計,稱作為I/O流模型(I/O Stream Model )。
其中,Java對照操作系統內核以及網路通信I/O中的傳統BIO來說,提供並支持了NIO和AIO的功能API設計,我們把這些設計,稱作為線程I/O參考模型(Thread I/O Reference Model )。
另外,對於NIO和AIO還參考了一定的設計模式來實現,我們把這些基於設計模式的設計,稱作為線程設計模式模型(Thread I/O Design Pattern Model )。
綜上所述,在Java領域中,我們在學習和掌握Java併發編程的時候,可以按照:線程映射理論模型->I/O流模型->線程I/O參考模型->線程設計模式模型->線程價值模型等脈絡來一一進行對比分析。
一. Java 領域中的線程映射理論模型
Java 領域中的線程映射模型主要有內核級線程模型(Kernel-Level Thread ,KLT)、應用級線程模型(Application-Level Thread ,ALT)、混合兩級線程模型(Mixture-Level Thread ,MLT)等3種模型。
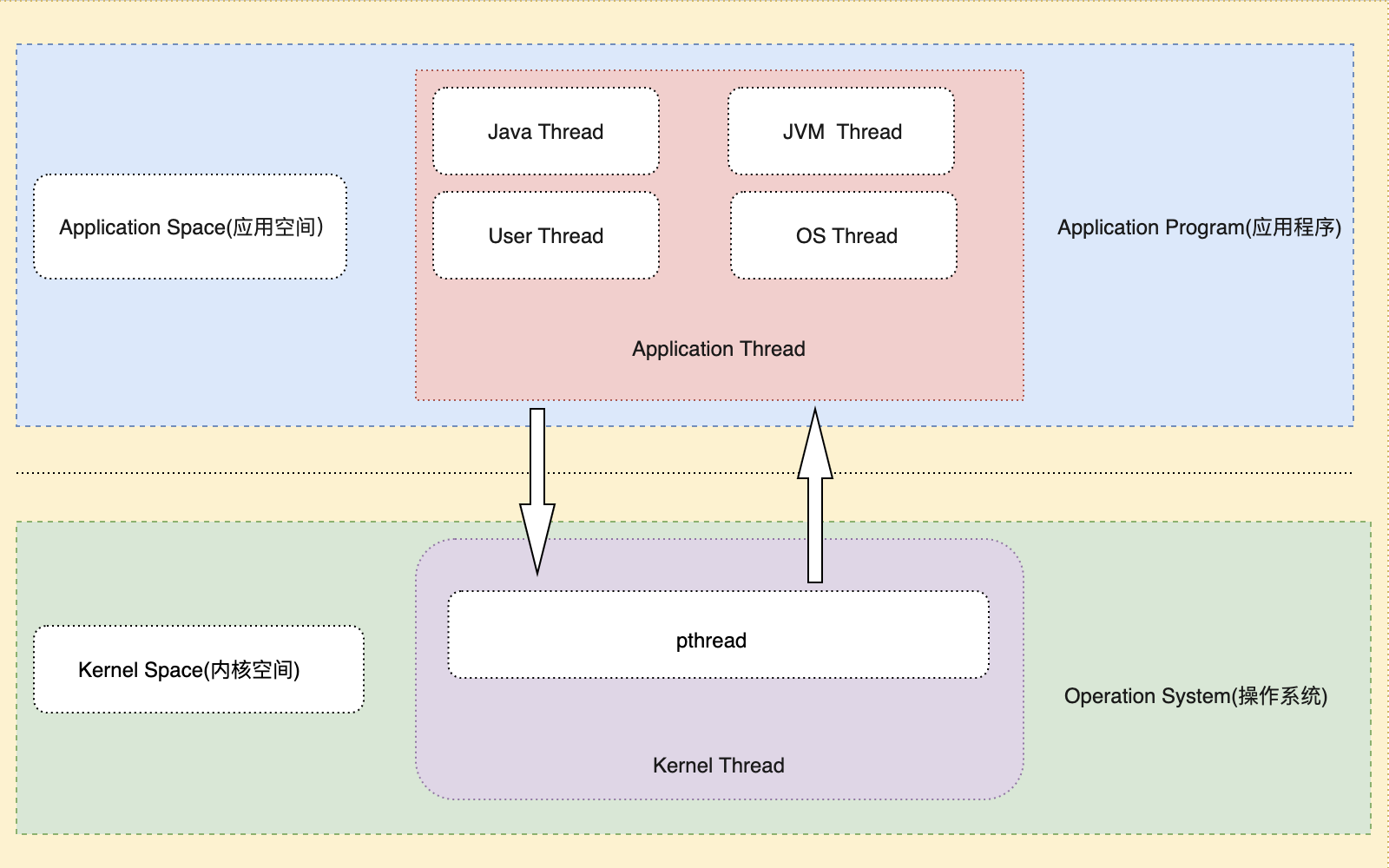
從Java線程映射類型來看,主要有線程一對一(1:1)映射,線程多對多(M:1)映射,線程多對多(M:N)映射等關係。
對應到線程模型來說,線程一對一(1:1)映射對應著內核線程(Kernel-Level Thread ,KLT),線程多對多(M:1)映射對應著應用級線程(Application-Level Thread,ALT),線程多對多(M:N)映射對應著混合兩級線程(Mixture-Level Thread ,MLT)。
因此,Java領域中實現多線程主要有3種模型:內核級線程模型、應用級線程模型、混合兩級線程模型。它們之間最大的差異就在於線程與內核調度實體( Kernel Scheduling Entity,簡稱KSE)之間的對應關係上。
顧名思義,內核調度實體就是可以被內核的調度器調度的對象,因此稱為內核級線程,是操作系統內核的最小調度單元。
綜上所述,接下來,我們來詳細討論Java 領域中的線程映射理論模型。
1. 應用級線程模型
應用級線程模型主要是指(Application-Level Thread ,ALT),就是多個用戶線程映射到同一個內核線程上,用戶線程的創建、調度、同步的所有操作全部都是由用戶空間的線程來完成的。
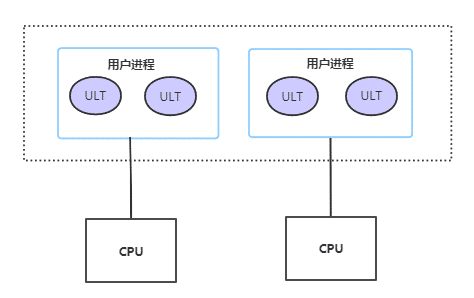
在Java領域中,應用級線程主要是指Java語言編寫應用程式的Java 線程(Java Thread)和JVM虛擬機中JVM線程(JVM Thread)。
在應用級線程模型下,完全建立在用戶空間的線程庫上,不依賴於系統內核,用戶線程的創建、同步、切換和銷毀等操作完全在用戶態執行,不需要切換到內核態。
其中,用戶進程使用系統內核提供的介面——輕量級進程(Light Weight Process,LWP)來使用系統內核線程。
在此種線程模型下,由於一個用戶線程對應一個LWP,因此某個LWP在調用過程中阻塞了不會影響整個進程的執行。
但是各種線程的操作都需要在用戶態和內核態之間頻繁切換,消耗太大,速度相對用戶線程模型來說要慢。
2. 內核級線程模型
內核級線程模型主要是指(Kernel-Level Thread ,KLT),用戶線程與內核線程建立了一對一的關係,即一個用戶線程對應一個內核線程,內核負責每個線程的調度。
在Linux中,對於內核級線程,操作系統會為其創建一套棧:用戶棧+內核棧,其中用戶棧工作在用戶態,內核棧工作在內核態,在發生系統調用時,線程的執行會從用戶棧切換到內核棧。
在內核級線程模型下,完全依賴操作系統內核提供的內核線程來實現多線程。線程的切換調度由系統內核完成,系統內核負責將多個線程執行的任務映射到各個CPU中去執行。
其中,glibc中的pthread_create方法主要是創建一個OS內核級線程,我們不深入細節,主要是為該線程分配了棧資源;需要註意的是這個棧資源對於JVM而言是堆外記憶體,因此堆外記憶體的大小會影響JVM可以創建的線程數。
在JVM概念中,JVM棧用來執行Java方法,而本地方法棧用來執行native方法;但需要註意的是JVM只是在概念上區分了這兩種棧,而並沒有規定如何實現。
在HotSpot中,則是將JVM棧與本地方法棧二合一,使用核心線程的用戶棧來實現(因為JVM棧和本地方法棧都是屬於用戶態的棧),即Java方法與native方法都在同一個用戶棧中調用,而當發生系統調用時,再切換到核心棧運行。
這種設計的好處是線程的各種操作以及切換消耗很低;
但是線程的所有操作都需要在用戶態實現,線程的調度實現起來異常複雜,並且系統內核對ULT無感知,如果線程阻塞則會引起整個進程的阻塞。
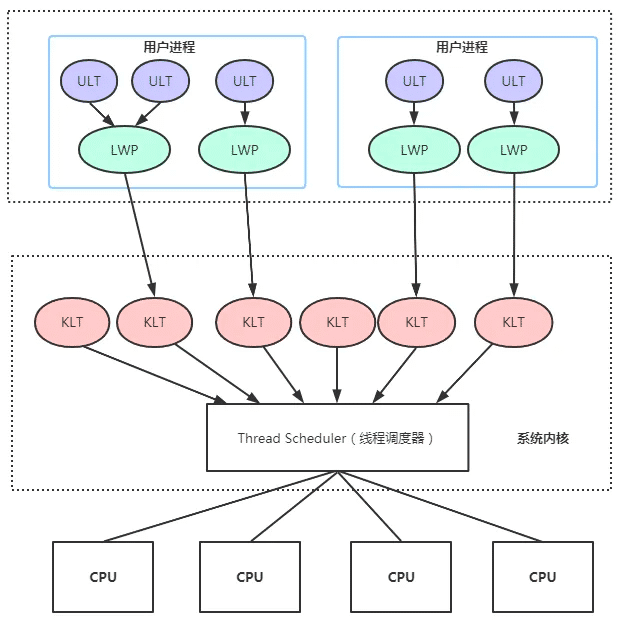
3. 混合兩級線程模型
混合兩級線程模型主要是指(Mixture-Level Thread ,MLT),是應用級線程模型和內核級線程模型等兩種模型的混合版本,用戶線程仍然是在用戶態中創建,用戶線程的創建、切換和銷毀的消耗很低,用戶線程的數量不受限制。
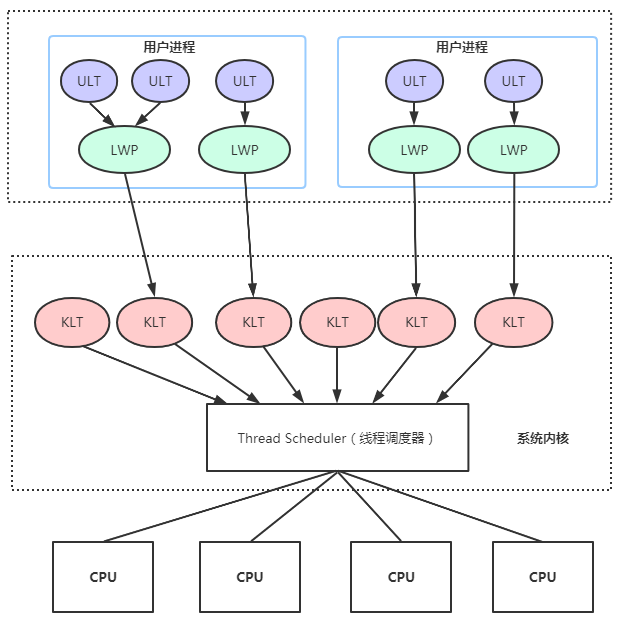
對於混合兩級線程模型,是應用級線程模型和內核級線程模型等兩種模型的混合版本,主要是充分吸收前面兩種線程模型的優點且儘量規避它們的缺點。
在此模型下用戶線程與內核線程是多對多(M : N,通常M >= N)的映射模型。主要是維護一個輕量級進程(Light Weight Process,LWP),在用戶線程和內核線程之間充當橋梁,就可以使用操作系統提供的線程調度和處理器映射功能。
一般來說,Java虛擬機使用的線程模型是基於操作系統提供的原生線程模型來實現的,Windows系統和Linux系統都是使用的內核線程模型,而Solaris系統支持混合線程模型和內核線程模型兩種實現。
還有,Java線程記憶體模型中,可以將虛擬機記憶體劃分為兩部分記憶體:主記憶體和線程工作記憶體,主記憶體是多個線程共用的記憶體,線程工作記憶體是每個線程獨享的記憶體。方法區和堆記憶體就是主記憶體區域,而虛擬機棧、本地方法棧以及程式計數器則屬於每個線程獨享的工作記憶體。
Java記憶體模型規定所有成員變數都需要存儲在主記憶體中,線程會在其工作記憶體中保存需要使用的成員變數的拷貝,線程對成員變數的操作(讀取和賦值等)都是對其工作記憶體中的拷貝進行操作。各個線程之間不能互相訪問工作記憶體,線程間變數的傳遞需要通過主記憶體來完成。
二. Java 領域中的I/O流模型
Java 領域中的I/O模型主要指Java 領域中的I/O模型大致可以分為字元流I/O模型,位元組流I/O模型以及網路通信I/O模型。

在編程語言的I/O類庫中常使用流(Stream)這個概念,代表了任何有能力產出數據的數據源對象或者是有能力接收數據的接收端對象。
流是個抽象的概念,是對輸入輸出設備的高度抽象,一般來說,編程語言都會涉及輸入流和輸出流兩部分。
一定意義上來說,輸入流可以看作一個輸入通道,輸出流可以看作一個輸出通道,其中:
- 輸入流是相對程式而言的,外部傳入數據給程式需要藉助輸入流。
- 輸出流是相對程式而言的,程式把數據傳輸到外部需要藉助輸出流。
由於,“流”模型屏蔽了實際的I/O設備中處理數據的細節,這就意味著我們只需要根據相關的基礎API的功能和設計,便可實現數據處理和交互。
Java IO 方式有很多種,基於不同的 IO 抽象模型和交互方式,可以進行簡單區分:
第一,傳統的 java.io 包,它基於流模型實現,提供了我們最熟知的一些 IO 功能,比如 File 抽象、輸入輸出流等。交互方式是同步、阻塞的方式,也就是說,在讀取輸入流或者寫入輸出流時,在讀、寫動作完成之前,線程會一直阻塞在那裡,它們之間的調用是可靠的線性順序。java.io 包的好處是代碼比較簡單、直觀,缺點則是 IO 效率和擴展性存在局限性,容易成為應用性能的瓶頸。
很多時候,人們也把 java.net 下麵提供的部分網路 API,比如 Socket、ServerSocket、HttpURLConnection 也歸類到同步阻塞 IO 類庫,因為網路通信同樣是 IO 行為。
第二,在 Java 1.4 中引入了 NIO 框架(java.nio 包),提供了 Channel、Selector、Buffer 等新的抽象,可以構建多路復用的、同步非阻塞 IO 程式,同時提供了更接近操作系統底層的高性能數據操作方式。
第三,在 Java 7 中,NIO 有了進一步的改進,也就是 NIO 2,引入了非同步非阻塞 IO 方式,也有很多人叫它 AIO(Asynchronous IO)。非同步 IO 操作基於事件和回調機制,可以簡單理解為,應用操作直接返回,而不會阻塞在那裡,當後臺處理完成,操作系統會通知相應線程進行後續工作。
其中,Java類庫中的I/O類分成輸入和輸出兩部分,主要是對應著實現我們與電腦操作交互時的一種規範和約束,但是對於不同的數據有著不同的實現。
綜上所述,Java 領域中的I/O模型大致可以分為字元流I/O模型,位元組流I/O模型以及網路通信I/O模型等3類。
1. 位元組流I/O模型
位元組流I/O模型是指在I/O操作,數據傳輸過程中,傳輸數據的最基本單位是位元組的流,按照8位傳輸位元組為單位輸入/輸出數據。
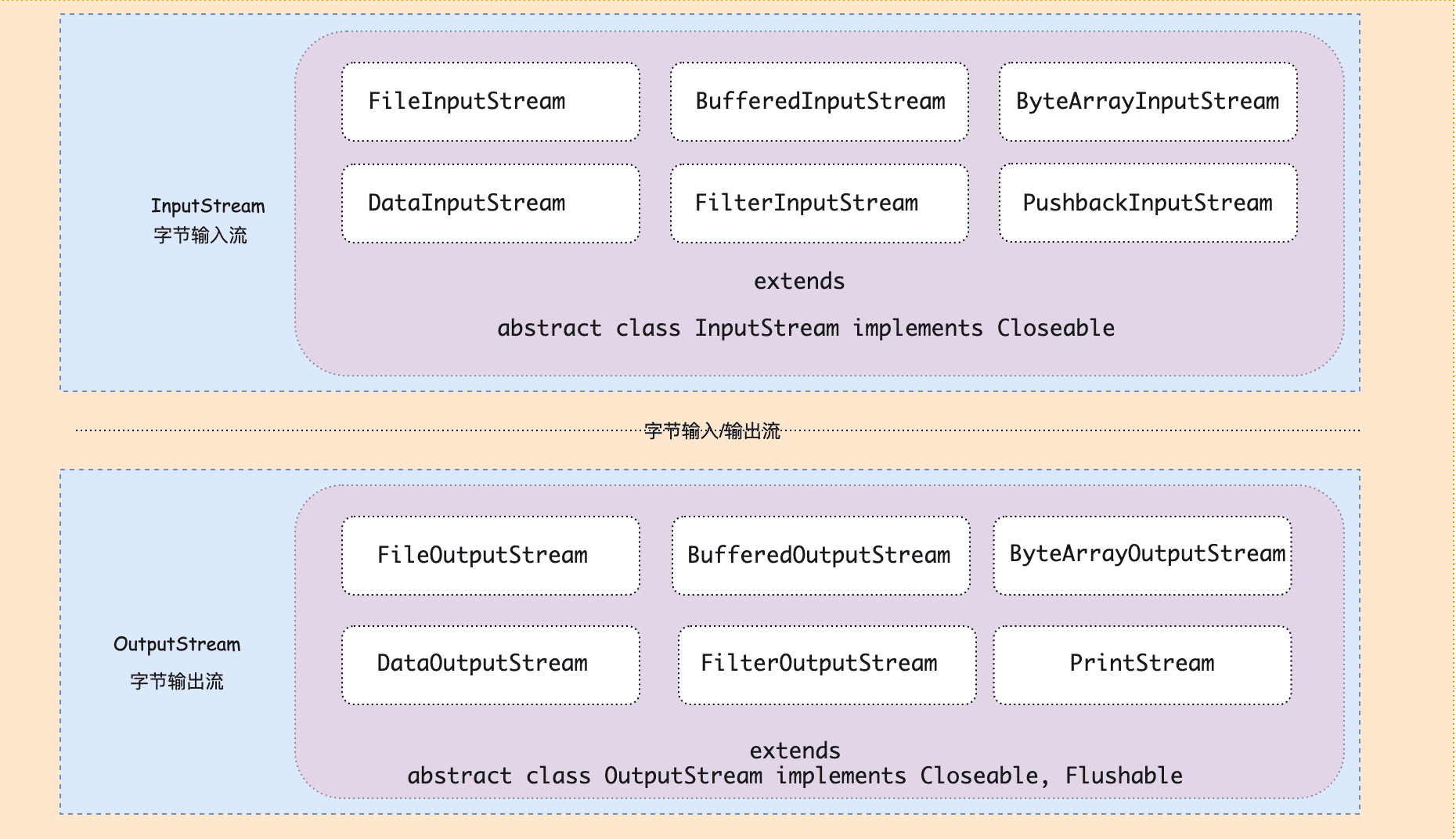
在Java 領域中,對位元組流的類通常以stream結尾,對於位元組數據的操作,提供了輸入流(InputStream)、輸出流(OutputStream)這樣式的設計,是用於讀取或寫入位元組的基礎API,一般常用於操作類似文本或者圖片文件。
2. 字元流I/O模型
字元流I/O模型是指在I/O操作,數據傳輸過程中,傳輸數據的最基本單位是字元的流,按照16位傳輸字元為單位輸入/輸出數據。
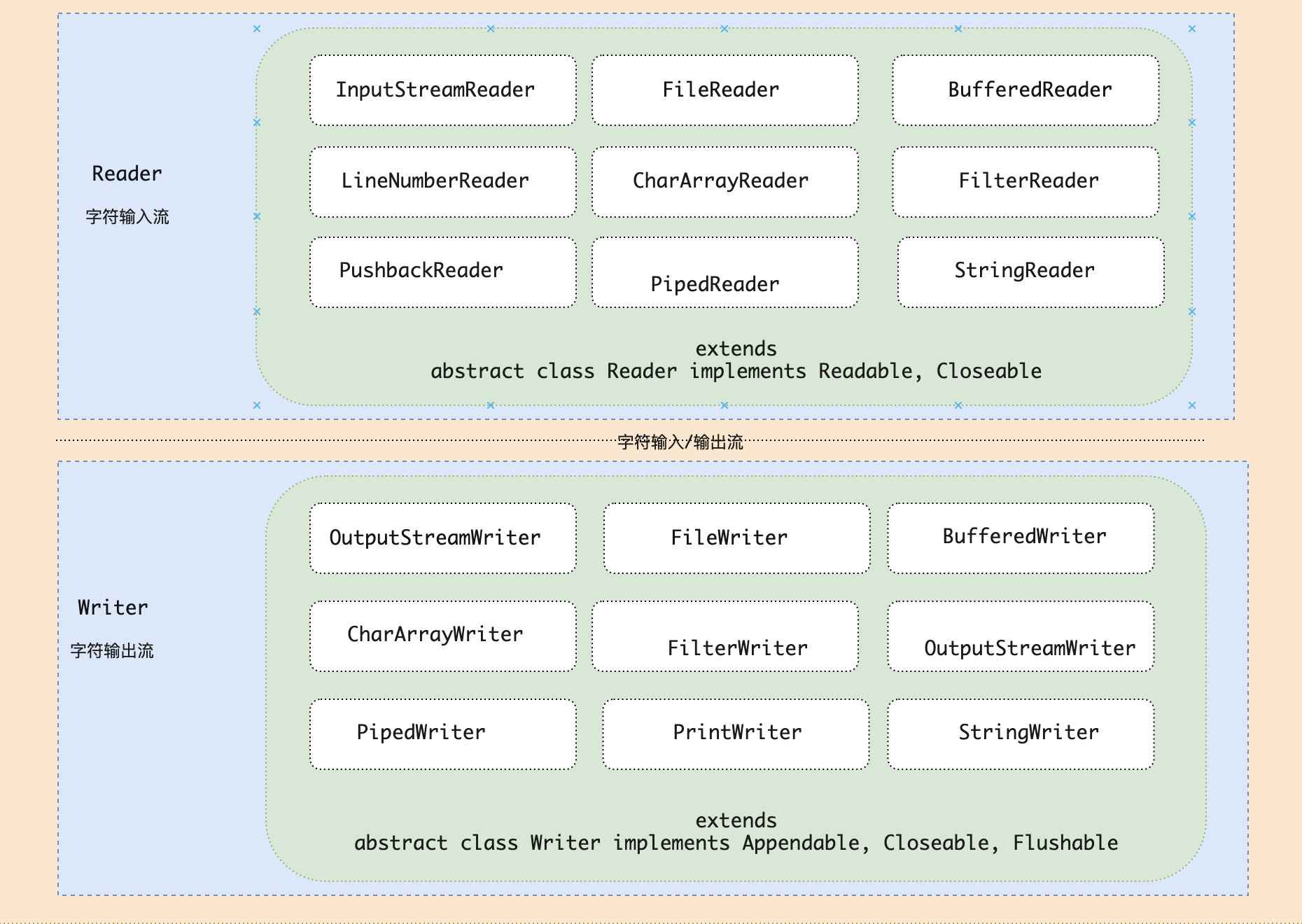
在Java 領域中,對字元流的類通常以reader和writer結尾,對於位元組數據的操作,提供了輸入流(Reader)、輸出流(Writer)這樣式的設計,是用於讀取或寫入位元組的基礎API,一般常用於類似從文件中讀取或者寫入文本信息。
3. 網路通信I/O模型
網路通信I/O模型是指java.net 下,提供的部分網路 API,比如 Socket、ServerSocket、HttpURLConnection 等IO 類庫,實現網路通信同樣是 IO 行為。
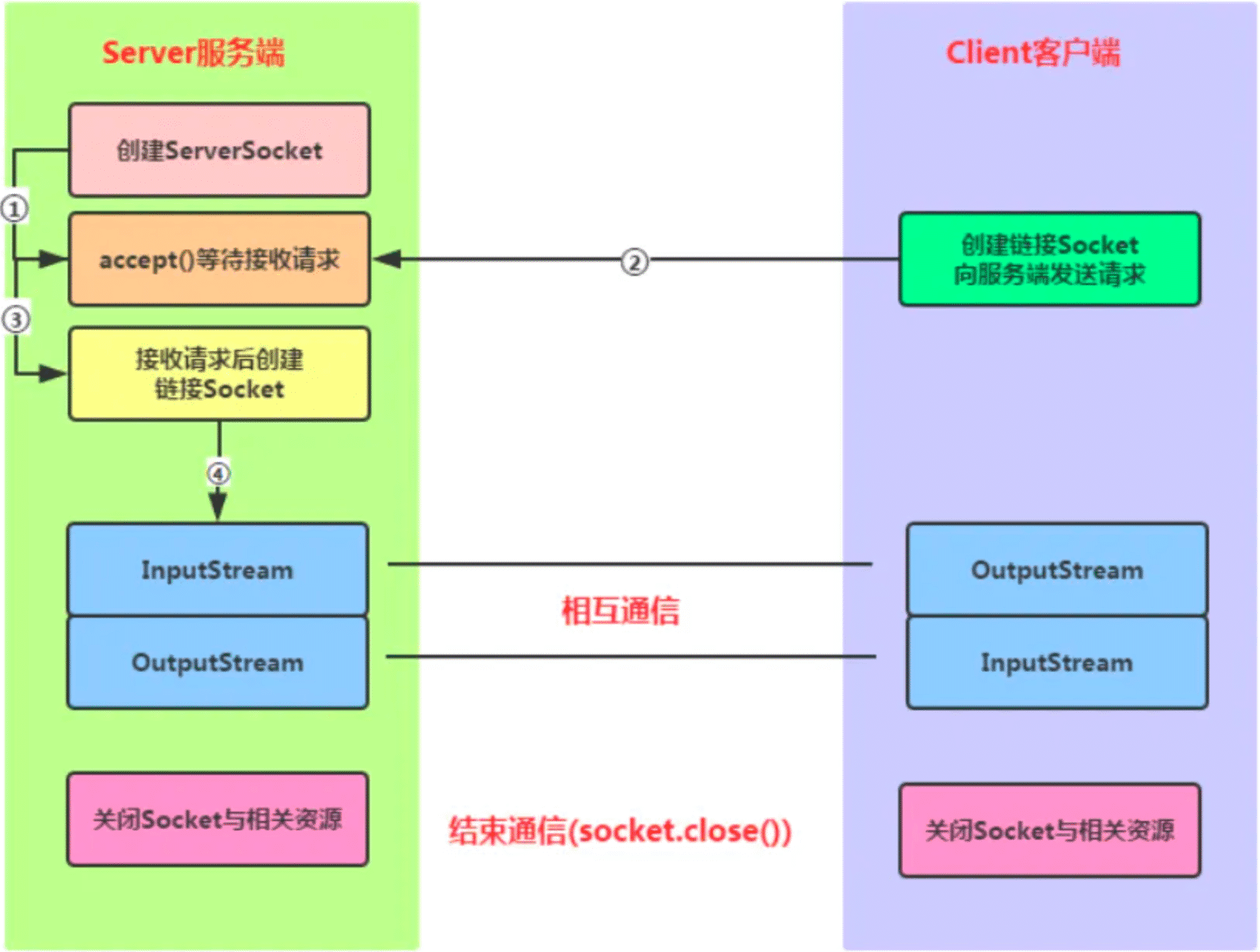
在Java領域中,NIO提供了與傳統BIO模型中的Socket和ServerSocket相對應的SocketChannel和ServerSocketChannel兩種不同的套接字通道實現。SocketChannel可以看作是 socket 的一個完善類,除了提供 Socket 的相關功能外,還提供了許多其他特性,如後面要講到的向選擇器註冊的功能。
其中,新增的SocketChannel和ServerSocketChannel兩種通道都支持阻塞和非阻塞兩種模式。
三. Java 領域中的線程I/O參考模型
在Java領域中,我們對照線程概念(單線程和多線程)來說,可以分為Java 線程-阻塞I/O模型和Java 線程-非阻塞I/O模型兩種。
由於阻塞與非阻塞主要是針對於應用程式對於系統函數調用角度來限定的,從阻塞與非阻塞的意義上來說,I/O可以分為阻塞I/O和非阻塞I/O兩種大類。其中:
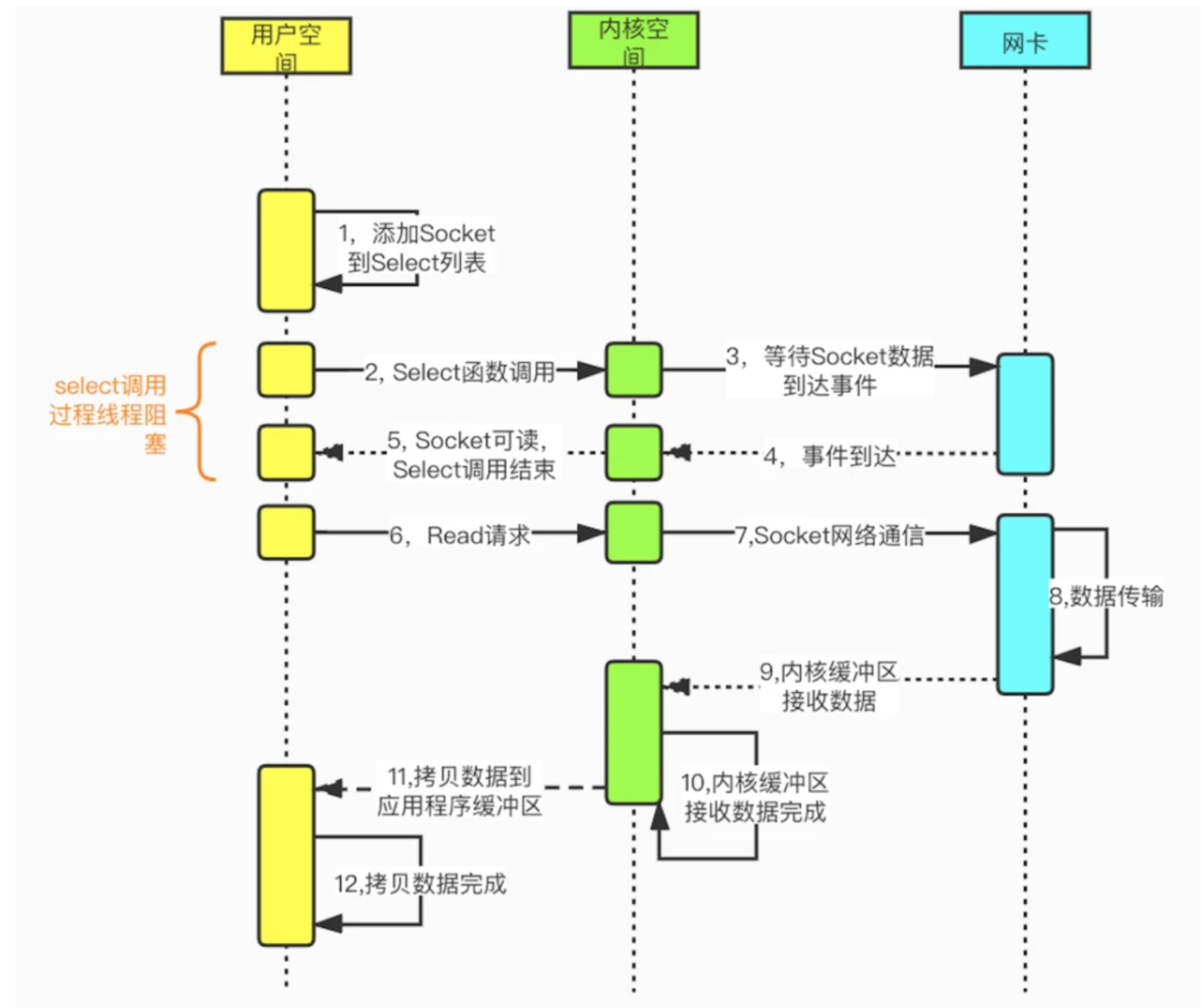
- 阻 塞 I/O : 進行I/O操作時,使當前線程進入阻塞狀態,從具體應用程式來看,如果當一次I/O操作(Read/Write)沒有就緒或者沒有完成,則函數調用則會一直處於等待狀態。
- 非阻塞I/O:進行I/O操作時,使當前線程不進入阻塞狀態,從具體應用程式來看,如果當一次I/O操作(Read/Write)即使沒有就緒或者沒有完成,則函數調用立即返回結果,然後由應用程式輪詢處理。
而同步與非同步主要正針對應用程式對於系統函數調用後,其I/O操作中讀/寫(Read/Write)是由誰完成來限定的,I/O可以分為同步I/O和非同步I/O兩種大類。其中:
- 同步I/O: 進行I/O操作時,可以使當前線程進入進入阻塞或或非阻塞狀態,從具體應用程式來看,如果當一次I/O操作(Read/Write)都是托管給應用程式來完成。
- 非同步I/O: 進行I/O操作時,可以使當前線程進入進入非阻塞狀態,從具體應用程式來看,如果當一次I/O操作(Read/Write)都是托管給操作系統來完成,完成後回調或者事件通知應用程式。
由此可見,按照這些個定義可以知道:
- 當程式在執行I/O操作時,經典的網路I/O操作(Read/Write)場景,主要可以分為阻塞I/O,非阻塞I/O,單線程以及多線程等場景。
- 非同步I/O一定是非阻塞I/O,不存在是非同步還阻塞的情況;同步I/O可能存在阻塞或或非阻塞的情況,還有可能是I/O線程多路復用的情況。
因此,我們可以對其線程I/O模型來說,I/O可以分為同步-阻塞I/O和同步-非阻塞I/O,以及非同步I/O等3種,其中I/O多路復用屬於同步-阻塞I/O。
綜上所所述,,在Java領域中,我們對照線程概念(單線程和多線程)來說,可以分為Java 線程-阻塞I/O模型和Java 線程-非阻塞I/O模型兩種。接下來,我們就詳細地來探討一下。
(一). Java 線程阻塞I/O模型
Java 線程-阻塞I/O模型主要可以分為單線程阻塞I/O模型和多線程阻塞I/O模型。
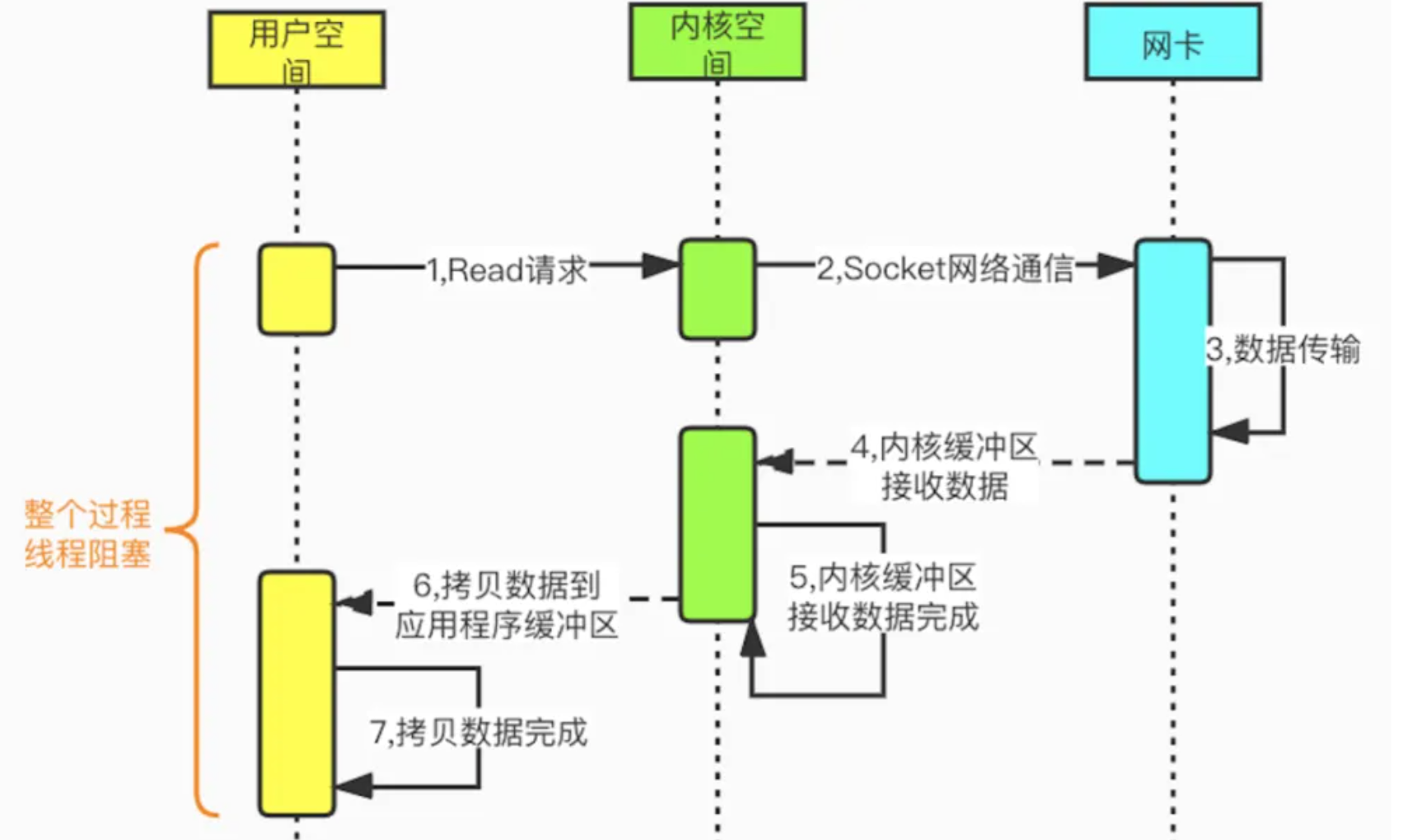
從一個伺服器處理客戶端連接來說,單線程情況下,一般都是以一個線程負責處理所有客戶端連接的I/O操作(Read/Write)操作。
程式在執行I/O操作,一般都是從內核空間複製數據,但內核空間的數據可能需要很長的時間去準備數據,由此很有可能導致用戶空間產生阻塞。
其產生阻塞的過程,主要如下:
- 應用程式發起I/O操作(Read/Write)之後,進入阻塞狀態,然後提交給操作系統內核完成I/O操作。
- 當內核沒有準備數據,需要不斷從網路中讀取數據,一旦準備就緒,則將數據複製到用戶空間供應用程式使用。
- 應用程式從發起讀取數據操作到繼續執行後續處理的這段時間,便是我們說的阻塞狀態。
由此可見,引入Java線程的概念,我們可以把Java 線程-阻塞I/O模型主要可以分為單線程阻塞I/O模型和多線程阻塞I/O模型。
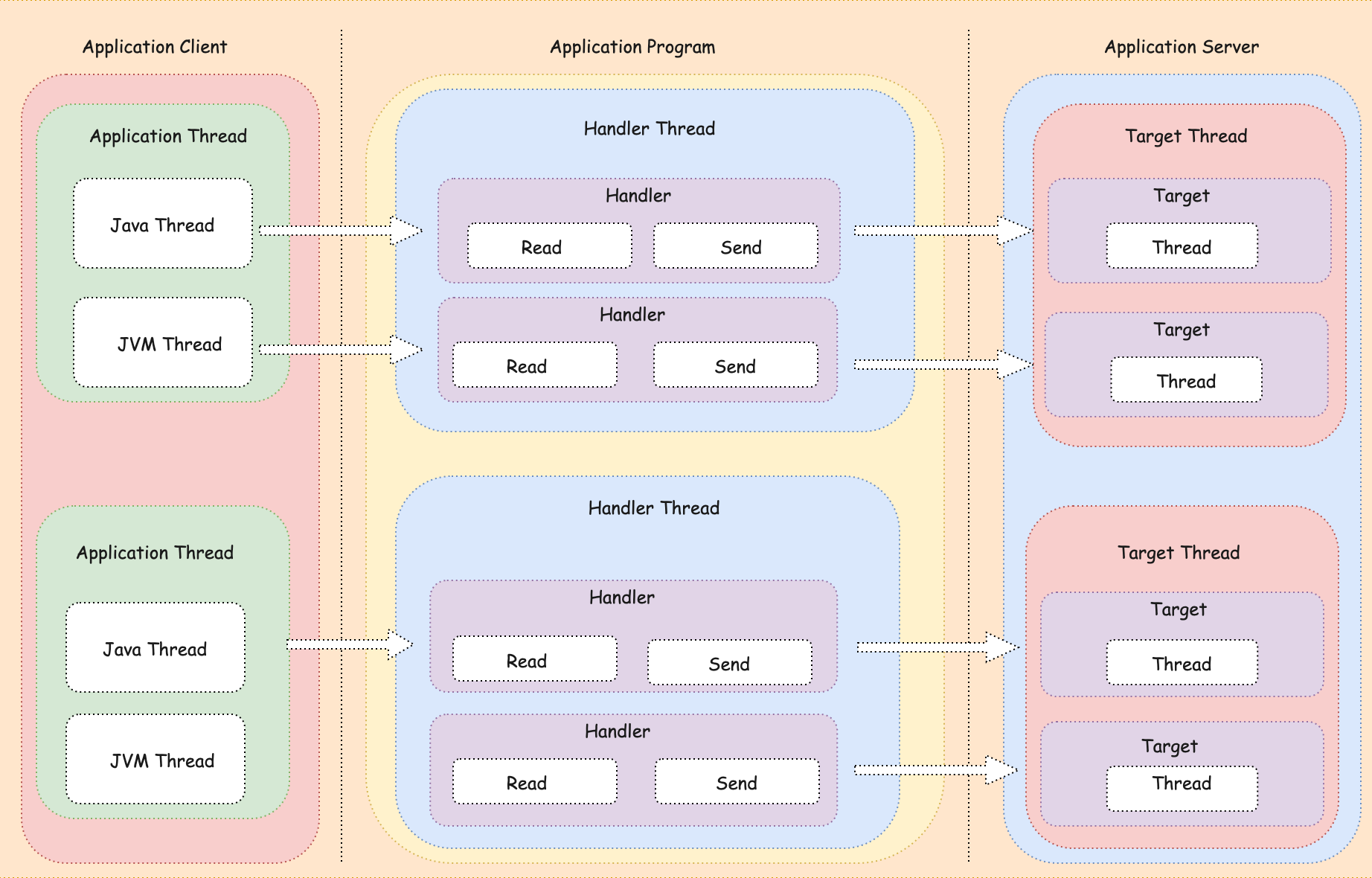
1. 單線程阻塞I/O模型
單線程阻塞I/O模型主要是指對於多個客戶端訪問時,只能同時處理一個客戶端的訪問,並且在I/O操作上是阻塞的,線程會一直處於等待狀態,直到當前線程中前一個客戶端訪問結束後,才繼續開始下一個客戶端的訪問。
單線程阻塞I/O模型是最簡單的伺服器模型,是Java Developer面對網路編程最基礎的模型。
由於對於多個客戶端訪問時,只能同時處理一個客戶端的訪問,並且在I/O操作上是阻塞的,線程會一直處於等待狀態,直到當前線程中前一個客戶端訪問結束後,才繼續開始下一個客戶端的訪問。
也就意味著,客戶端的訪問請求需要一個一個排隊等待,只提供一問一答的服務機制。
這種模型的特點,主要在於單線程和阻塞I/O。其中:
- 單線程 :指的是伺服器端只有一個線程處理客戶端的請求,客戶端連接與伺服器端的處理線程比例關係為N:1,無法同時處理多個連接,只能串列方式連接處理。
- 阻塞I/O:伺服器在I/O操作(Read/Write)操作時是阻塞的,主要表現在讀取客戶端數據時,需要等待客戶端發送數據並且把操作系統內核中的數據複製到用戶空間中的用戶線程中,完成後才解除阻塞狀態;同時,數據回寫客戶端要等待用戶進程把數據寫入到操作系統系統內核後才解除阻塞狀態。
綜上所述,單線程阻塞I/O模型最明顯的特點就是服務機制簡單,伺服器的系統資源開銷小,但是併發能力低,容錯能力也低。
2. 多線程阻塞I/O模型
多線程阻塞I/O模型主要是指對於多個客戶端訪問時,利用多線程機製為每一個客戶端的訪問分配獨立線程,實現同時處理,並且在I/O操作上是阻塞的,線程不會一直處於等待狀態,而是併發處理客戶端的請求訪問。
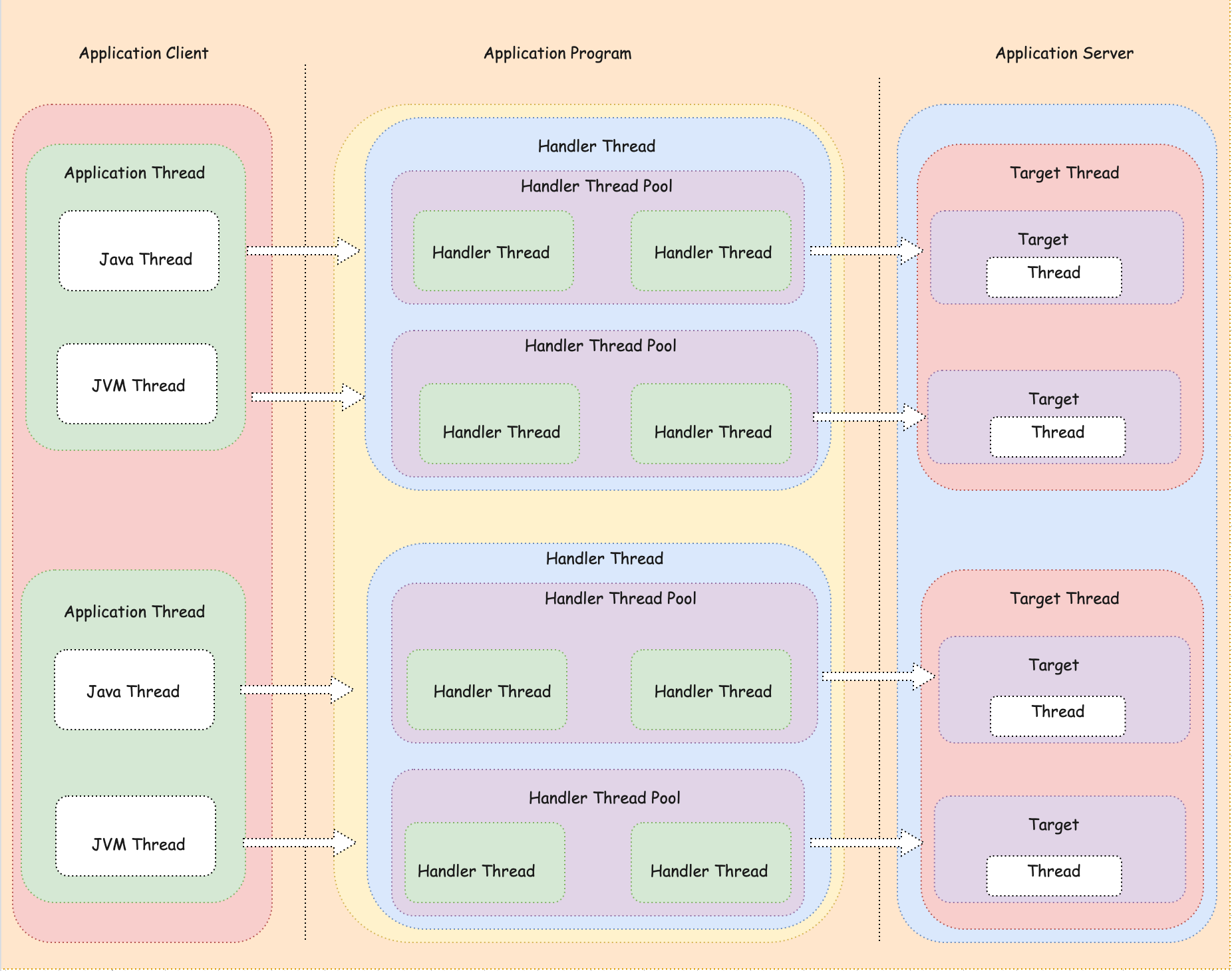
多線程阻塞I/O模型是針對於單線程阻塞I/O模型的缺點,對其進行多線程化改進,使之能對於多個客戶端的請求訪問實現併發響應處理。
也就意味著,客戶端的訪問請求不需要一個一個排隊等待,利用多線程機製為每一個客戶端的訪問分配獨立線程。
這種模型的特點,主要在於多線程和阻塞I/O。其中:
- 多線程 :指的是伺服器端至少有一個線程或者若幹個線程處理客戶端的請求,客戶端連接與伺服器端的處理線程比例關係為M:N,併發同時處理多個連接,可以並行方式連接處理。但客戶端連接與伺服器處理線程的關係是一對一的。
- 阻塞I/O:伺服器在I/O操作(Read/Write)操作時是阻塞的,主要表現在讀取客戶端數據時,需要等待客戶端發送數據並且把操作系統內核中的數據複製到用戶空間中的用戶線程中,完成後才解除阻塞狀態;同時,數據回寫客戶端要等待用戶進程把數據寫入到操作系統系統內核後才解除阻塞狀態。
綜上所述,多線程阻塞I/O模型最明顯的特點就是支持多個客戶端併發響應,處理能力得到極大提高,有一定的併發能力和容錯能力,但是伺服器資源消耗較大,且多線程之間會產生線程切換成本,結構也比較複雜。
(二). Java 線程非阻塞I/O模型
Java 線程-非阻塞I/O模型主要可以分為應用層I/O多路復用模型和內核層I/O多路復用模型,以及內核回調事件驅動I/O模型。
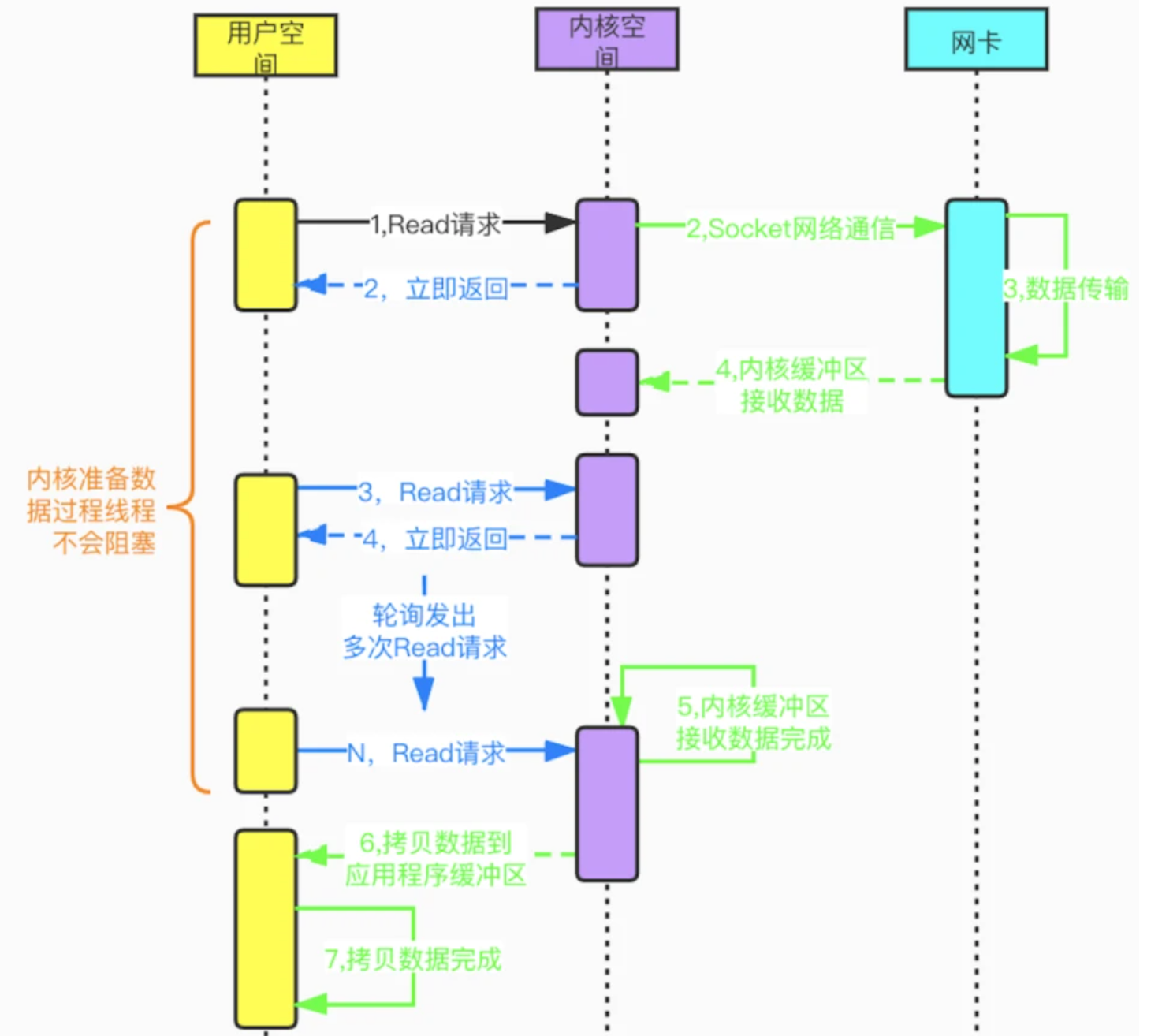
從一個伺服器處理客戶端連接來說,多線程情況下,一般都是至少一個線程或者若幹個線程負責處理所有客戶端連接的I/O操作(Read/Write)操作。
非阻塞I/O模型與阻塞I/O模型,相同的地方在於是程式在執行I/O操作,一般都是從內核空間和應用空間複製數據。
與之不同的是,非阻塞I/O模型不會一直等到內核空間準備好數據,而是立即返回去做其他的事,因此不會產生阻塞。其中:
-
應用程式中的用戶線程包含一個緩衝區,單個線程會不斷輪詢客戶端,以及不斷嘗試進行I/O(Read/Write)操作。
-
一旦內核准好數據,應用程式中的用戶線程就會把數據複製到用戶空間使用。
由此可見,我們可以把Java 線程-非阻塞I/O模型主要可以分為應用層I/O多路復用模型和內核層I/O多路復用模型,以及內核回調事件驅動I/O模型。
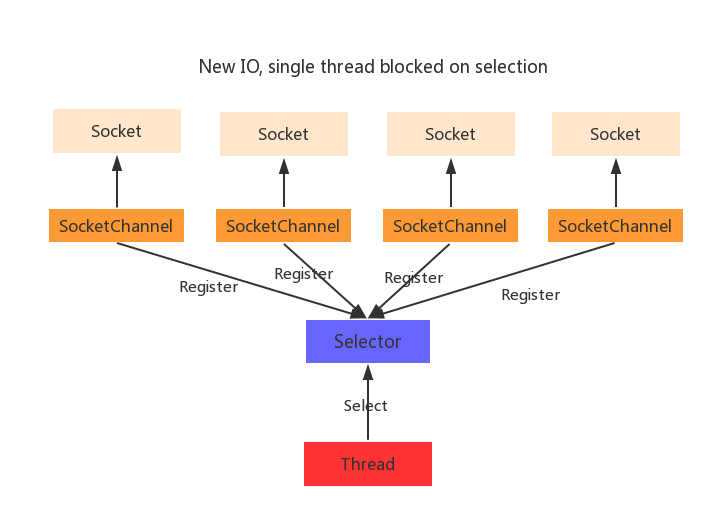
1. 應用層I/O多路復用模型
應用層I/O多路復用模型主要是指當多個客戶端向伺服器發出請求時,伺服器會將每一個客戶端連接維護到一個socket列表中,應用程式中的用戶線程會不斷輪詢sockst列表中的客戶端連接請求訪問,並嘗試進行讀寫。
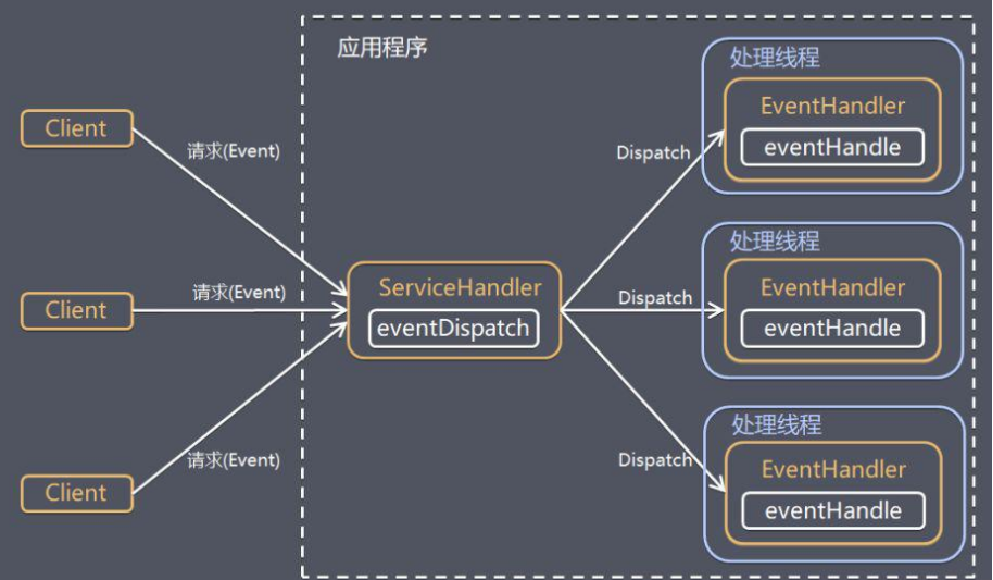
應用層I/O多路復用模型最大的特點就是,不論有多少個socket連接,都可以使用應用程式中的用戶線程的一個線程來管理。
這個線程負責輪詢socket列表,不斷進行嘗試進行I/O(Read/Write)操作,其中:
- I/O(Read)操作:如果成功讀取數據,則對數據進行處理。反之,如果失敗,則下一個迴圈再繼續嘗試。
- I/O(Write)操作:需要先嘗試把數據寫入指定的socket,直到調用成功結束。反之,如果失敗,則下一個迴圈再繼續嘗試。
這種模型,雖然很好地利用了阻塞的時間,使得批處理能提升。但是由於不斷輪詢sockst列表,同時也需要處理數據的拼接。
2. 內核層I/O多路復用模型
內核層I/O多路復用模型主要是指當多個客戶端向伺服器發出請求時,伺服器會將每一個客戶端連接維護到一個socket列表中,操作系統內核不斷輪詢sockst列表,並把遍歷結果組織羅列成一系列的事件,並驅動事件返回到應用層處理,最後托管給應用程式中的用戶線程按照需要處理對應的事件對象。
內核層I/O多路復用模型與應用層I/O多路復用模型,最大的不同就是,輪詢sockst列表是操作系統內核來完成的,有助於檢測效率。
操作系統內核負責輪詢socket列表的過程,其中:
- 首先,最主要的就是將所有連接的標記為可讀事件和可寫事件列表,最後傳入到應用程式的用戶空間處理。
- 然後,操作系統內核覆制數據到應用層的用戶空間的用戶線程,會隨著socket數量的增加,也會形成不小的開銷。
- 另外,當活躍連接數比較少時,內核空間和用戶空間會存在很多無效的數據副本,並且不管是否活躍,都會複製到用戶空間的應用層。
3. 內核回調事件驅動I/O模型
內核回調事件驅動I/O模型主要是指當多個客戶端向伺服器發出請求時,伺服器會將每一個客戶端連接維護到一個socket列表中,操作系統內核不斷輪詢sockst列表,利用回調函數來檢測socket列表是否可讀可寫的一種事件驅動I/O機制。
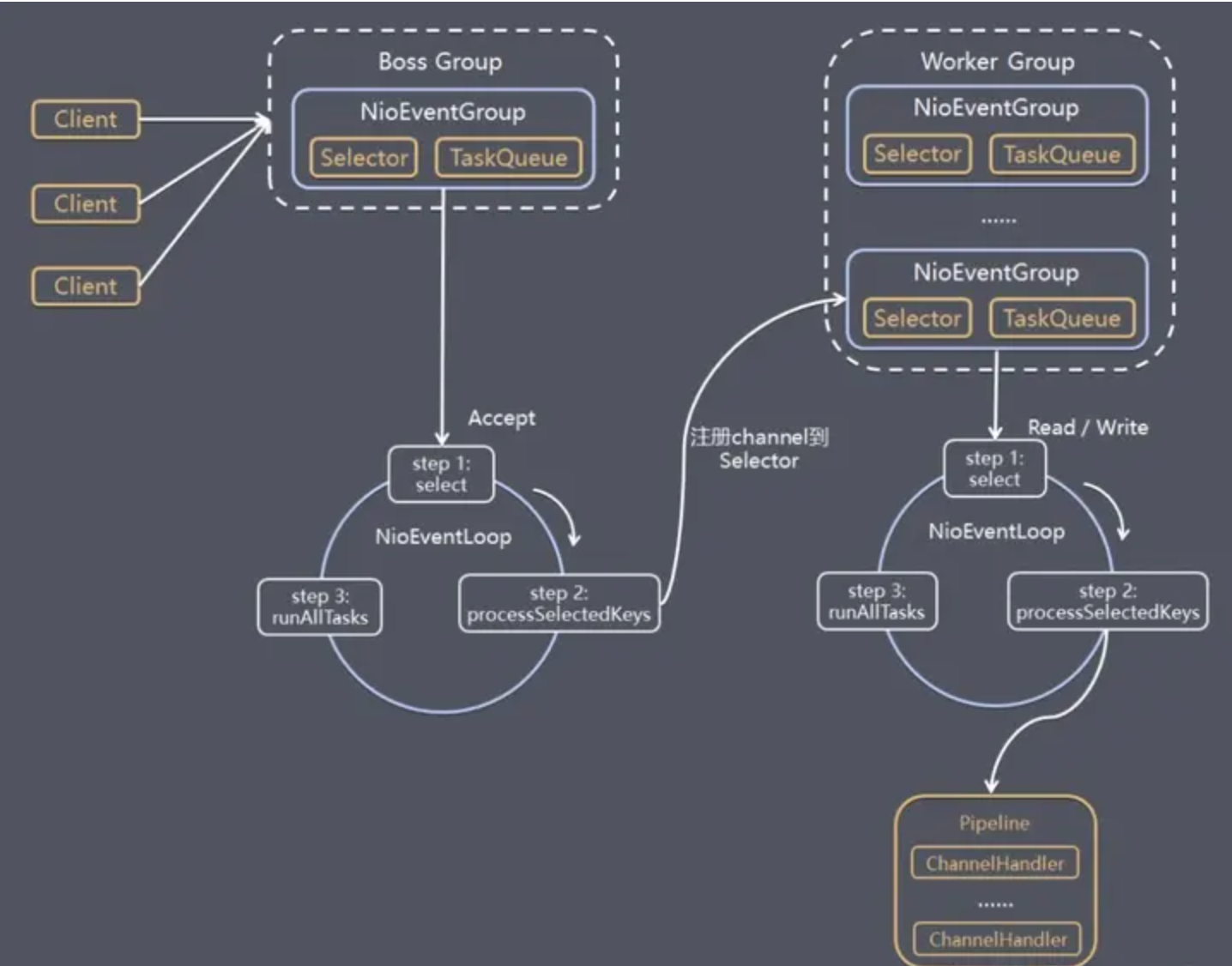
不論是內核層的輪詢sockst列表,還是應用層的輪詢sockst列表,通過迴圈遍歷的方式來檢測socket列表是否可讀可寫的操作方式,其效率都比較低效。
為了尋求一種高效的機制來優化迴圈遍歷方式,因此,提出了會回調函數事件驅動機制。其中,主要是:
- 內核空間:當客戶端往socket發送數據時,內核中socket都對應著一個回調函數,內核就可以直接從網卡中接收數據後,直接調用回調函數。
- 應用空間:回調函數會維護一個事件列表,應用層則獲取事件即可以得到感興趣的事件,然後進行後續操作。
一般來說,內核回調事件驅動的方式主要有2種:
- 第一種:利用可讀列表(ReadList)和可寫列表(WriteList)來標記讀事件(Read-Event)/寫事件(Write-Event)來進行I/O(Read/Write)操作。
- 第二種:利用在應用層中直接指定socket感興趣的事件,通過維護事件列表(EventList)再來進行I/O(Read/Write)操作。
綜上所述,這兩種方式都是有操作系統內核維護客戶端中的所有連接,再通過回調函數不斷更新事件列表,應用空間中的應用層的用戶線程只需要根據輪詢遍歷事件列表即可知道是否進行I/O(Read/Write)操作。
由此可見,這種方式極大地提高了檢測效率,也增強了數據處理能力。
特別指出,在Java領域中,非阻塞I/O的實現完全是基於操作系統內核的非阻塞I/O,Java把操作系統中的非阻塞I/O的差異最大限度的屏蔽並提供了統一的API,JDK自己會幫助我們選擇非阻塞I/O的實現方式。
一般來說,在Linux系統中,只要支持epoll,JDK會優先選擇epoll來實現Java的非阻塞I/O。
(三). Java 線程非同步I/O模型
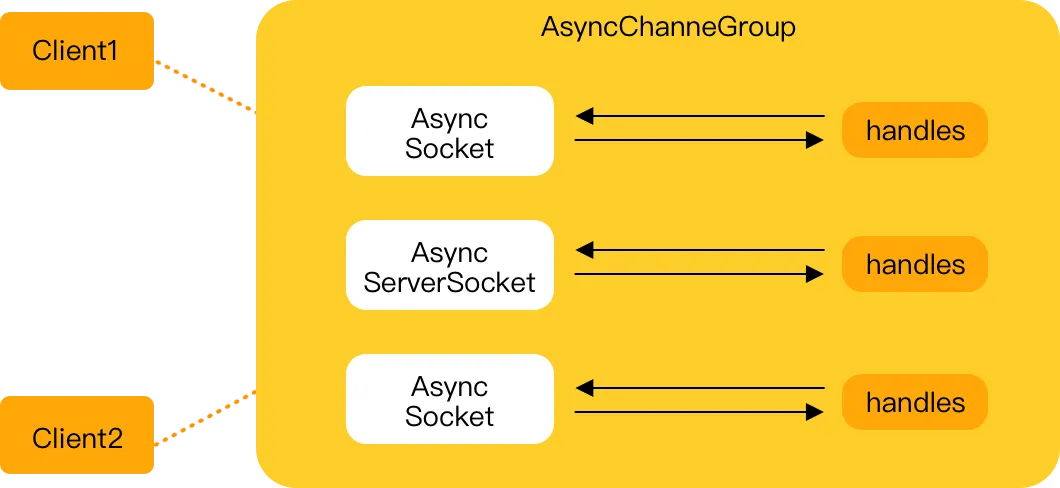
Java 線程非同步I/O模型主要是指非同步非阻塞模型(AIO模型), 需要操作系統負責將數據讀寫到應用傳遞進來的緩衝區供應用程式操作。
對於非阻塞I/O模型(NIO)來說,非同步I/O模型的工作機制來說,與之不同的是採用“訂閱(Subscribe)-通知(Notification)”模式,主要如下:
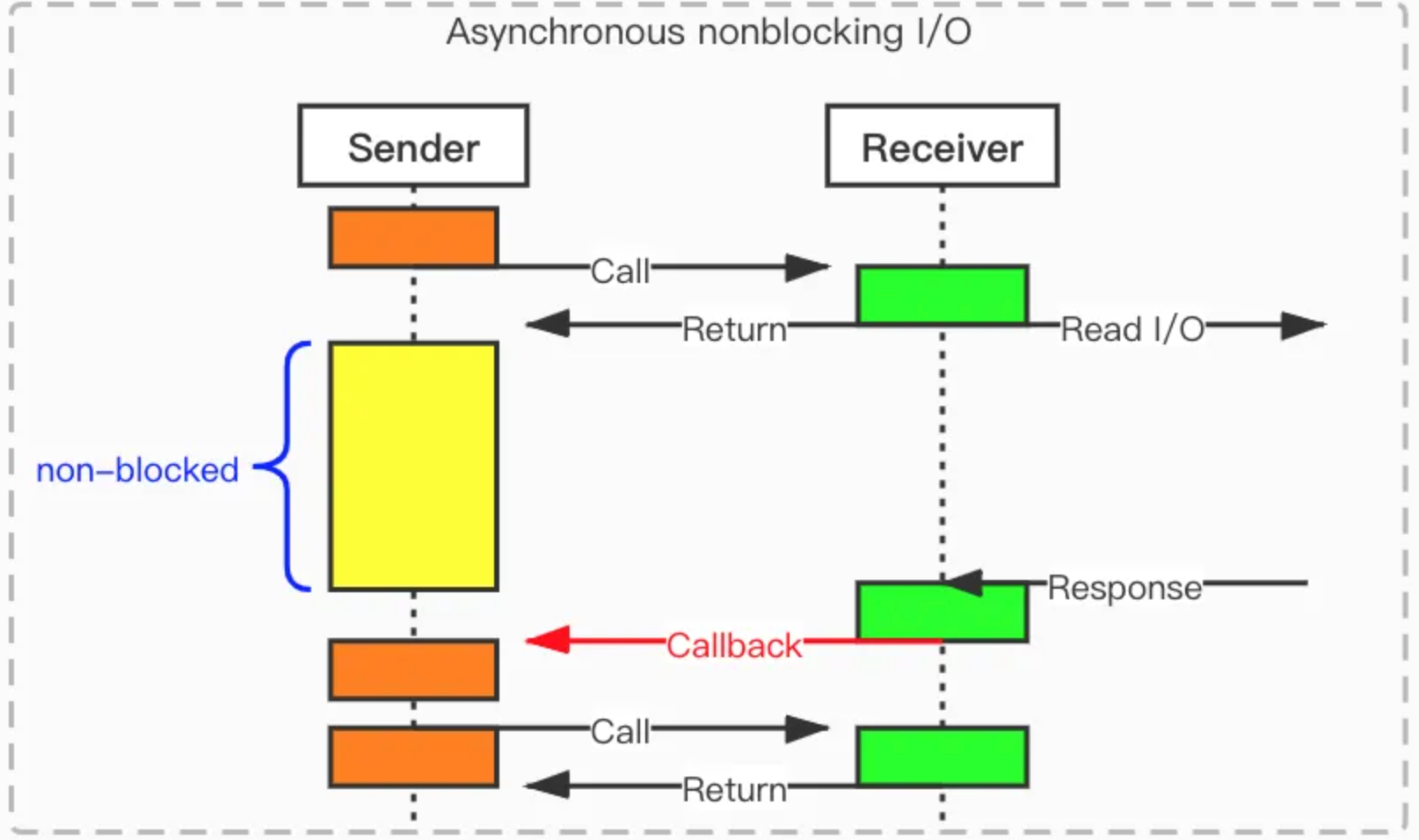
- 訂閱(Subscribe): 用戶線程通過操作系統調用,向內核註冊某個IO操作後,即應用程式向操作系統註冊IO監聽,然後繼續做自己的事情。
- 通知(Notification):當操作系統發生IO事件,並且準備好數據後,即內核在整個IO操作(包括數據準備、數據複製)完成後,再主動通知應用程式,觸發相應的函數,執行後續的業務操作。
在非同步IO模型中,整個內核的數據處理過程中,包括內核將數據從網路物理設備(網卡)讀取到內核緩存區、將內核緩衝區的數據複製到用戶緩衝區,用戶程式都不需要阻塞。
由此可見,非同步I/O模型(AIO模型)需要依賴操作系統的支持,CPU資源開銷比較大,最大的特性是非同步能力,對socket和I/O起作用,適合連接數目比較多以及連接時間長的系統架構。
一般來說,在操作系統里,非同步IO是指Windows系統的IOCP(Input/Output Completion Port),或者C++的網路庫asio。
在Linux系統中,aio雖然是非同步IO模型的具體實現,但是由於不成熟,現在大部分還是依據是否支持epoll等,來模擬和封裝epoll實現的。
在Java領域中,支持非同步I/O模型(AIO模型)是Jdk 1.7版本開始的,基於CompletionHandler介面來實現操作完成回調,其中分別有三個新的非同步通道,AsynchronousFileChannel,AsynchronousSocketChannel和AsynchronousServerSocketChannel。
但是,對於支持非同步編程模式是在Jdk 1.5版本就已經存在,最典型的就是基於Future模型實現的Executor和FutureTask。
由於Future模型存在一定的局限性,在JDK 1.8 之後,對Future的擴展和增強實現又新增了一個CompletableFuture。
由此可見,在Java領域中,對於非同步I/O模型提供了非同步文件通道(AsynchronousFileChannel)和非同步套接字通道(AsynchronousSocketChannel和AsynchronousServerSocketChannel)的實現。 其中:
- 首先,對於非同步文件通道的實現,提供兩種方式獲取操作結果:
- 通過java.util.concurrent.Future類來表示非同步操作的結果:
- 在執行非同步操作的時候傳入一個java.nio.channels.CompletionHandler介面的實現類作為操作完成的回調。
- 其次,對於非同步套接字通道的是實現:
- 非同步Socket Channel是被動執行對象,不需要像 NIO編程那樣創建一個獨立的 I/O線程來處理讀寫操作。
- 對於AsynchronousServerSocketChannel和AsynchronousSocketChannel 都由JDK底層的線程池負責回調並驅動讀寫操作。
- 非同步套接字通道是真正的非同步非阻塞I/O,它對應UNIX網路編程中的事件驅動I/O (AIO),它不需要通過多路復用器(Selector)對註冊的通道進行輪詢操作即可實現非同步讀寫, 從而簡化了 NIO的編程模型。
綜上所述,對於在Java領域中的非同步IO模型,我們在使用的時候,需要依據實際業務場景需要而進行選擇和考量。
⚠️[特別註意]:
[1].IOCP: 輸入輸出完成埠(Input/Output Completion Port,IOCP), 是支持多個同時發生的非同步I/O操作的應用程式編程介面。
[2].epoll: Linux系統中I/O多路復用實現方式的一種,主要是(select,poll,epoll)。都是同步I/O,同時也是阻塞I/O。
[3].Future: 屬於Java JDK 1.5 版本支持的編程非同步模型,在包java.util.concurrent.下麵。
[4].CompletionHandler: 屬於Java JDK 1.7 版本支持的編程非同步I/O模型,在包java.nio.channels.下麵。
[5].CompletableFuture: 屬於Java JDK 1.8 版本對Future的擴展和增強實現編程非同步I/O模型,在java.util.concurrent.下麵。
四. Java 領域中的線程設計模型
Java 領域中的線程設計模型最典型就是基於Reactor模式設計的非阻塞I/O模型和 基於Proactor 模式設計的非同步I/O模型和基於Promise模式的Promise模型。
在Java領域中,對於併發編程的支持,不僅提供了線程機制,也引入了多線程機制,還有許多同步和非同步的實現。
單從設計原則和實現來說,都採用了許多設計模式,其中多線程機制最常見的就是線程池模式。
對於非阻塞I/O模型,主要採用基於Reactor模式設計,而非同步I/O模型,主要採用基於Proactor 模式設計。
當然,還有基於Promise模式的非同步編程模型,不過這算是一個特例。
綜上所述,Java 領域中的線程設計模型最典型就是基於Reactor模式設計的非阻塞I/O模型和 基於Proactor 模式設計的非同步I/O模型和基於Promise模式的Promise模型。
1. 多線程非阻塞I/O模型
多線程非阻塞I/O模型是針對於多線程機制而設計的,根據CPU的數量來創建線程數,並且能夠讓多個線程並行執行的非阻塞I/O模型。
現在的電腦大多數都是多核CPU的,而且操作系統都提供了多線程機制,但是我們也沒有辦法抹掉單線程的優勢。
單線程最大的優勢就是一個CPU只負責一個線程,對於多線程中出現的疑難雜症,它都可以避免,而且編碼簡單。
在一個線程對應一個CPU的情況下,如果多核電腦中 只執行一個線程,那麼就只有一個CPU工作,無法充分發揮CPU和優勢,且資源也無法充分利用。
因此,我們的程式則可以根據CPU的數量來創建線程數,N個CPU對應多個N個線程,便可以充分利用多個CPU。同時也保持了單線程的特點,相當於多個線程並行執行而不是併發執行。
在多核電腦時代,多線程和非阻塞都是提升伺服器處理性能的利器。一般我們都是將客戶端連接按照分組分配給至少一個線程或者若幹線程,每個線程負責處理對應組的連接。
在Java領域中,最常見的多線程阻塞I/O模型就是基於Reactor模式的Reactor模型。
2. 基於Reactor模式的Reactor模型
Reactor模型是指在事件驅動的思想上,基於Reactor的工作模式而設計的非阻塞I/O模型(NIO 模型)。一定程度上來說,可以說是主動模式I/O模型。
對於Reactor模式,我特意在網上查詢了一下資料,查詢的結果都是無疾而終,解釋更是五花八門的。最後,參考一些資料整理得出結論。
引用一下Doug Lea大師在文章“Scalable IO in Java”中對Reactor模式的定義:
Reactor模式由Reactor線程、Handlers處理器兩大角色組成,兩大角色的職責分別如下:
- Reactor線程的職責:負責響應IO事件,並且分發到Handlers處理器。
- Handlers處理器的職責:非阻塞的執行業務處理邏輯。
個人理解,Reactor模式是指在事件驅動的思想上,通過一個或多個輸入同時傳遞給服務處理器的服務請求的事件驅動處理模式。其中,基本思想有兩個:
-
基於 I/O 復用模型:多個連接共用一個阻塞對象,應用程式只需要在一個阻塞對象等待,無需阻塞等待所有連接。當某個連接有新的數據可以處理時,操作系統通知應用程式,線程從阻塞狀態返回,開始進行業務處理
-
基於線程池復用線程資源:不必再為每個連接創建線程,將連接完成後的業務處理任務分配給線程進行處理,一個線程可以處理多個連接的業務。
總體來說,Reactor模式有點類似事件驅動模式。在事件驅動模式中,當有事件觸發時,事件源會將事件分發到Handler(處理器),由Handler負責事件處理。Reactor模式中的反應器角色類似於事件驅動模式中的事件分發器(Dispatcher)角色。
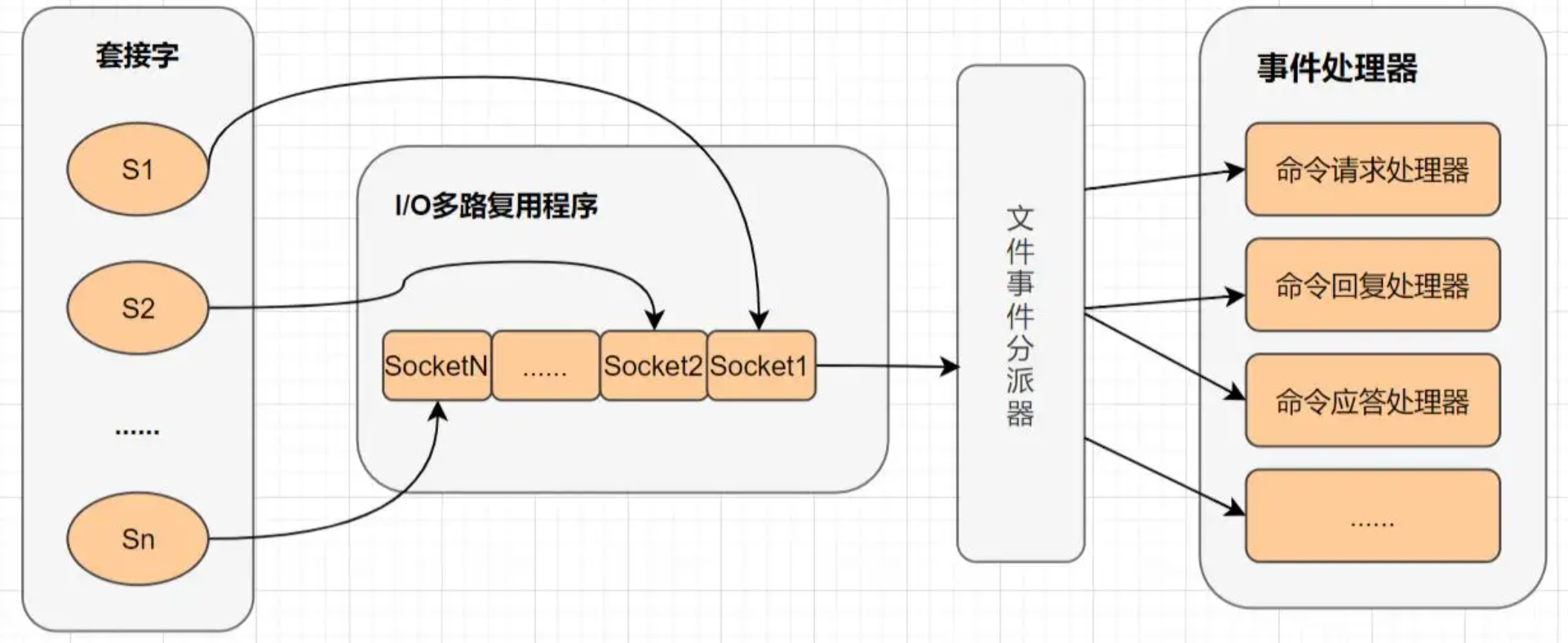
具體來說,在Reactor模式中有Reactor和Handler兩個重要的組件:
- Reactor:負責查詢IO事件,當檢測到一個IO事件時將其發送給相應的Handler處理器去處理。其中,IO事件就是NIO中選擇器查詢出來的通道IO事件。
- Handler:與IO事件(或者選擇鍵)綁定,負責IO事件的處理,完成真正的連接建立、通道的讀取、處理業務邏輯、負責將結果寫到通道等。
從Reactor的代碼實現上來看,實現Reactor模式需要實現以下幾個類:
- EventHandler:事件處理器,可以根據事件的不同狀態創建處理不同狀態的處理器。
- Handler:可以理解為事件,在網路編程中就是一個Socket,在資料庫操作中就是一個DBConnection。
- InitiationDispatcher:用於管理EventHandler,分發event的容器,也是一個事件處理調度器,Tomcat的Dispatcher就是一個很好的實現,用於接收到網路請求後進行第一步的任務分發,分發給相應的處理器去非同步處理,來保證吞吐量。
- Demultiplexer:阻塞等待一系列的Handle中的事件到來,如果阻塞等待返回,即表示在返回的Handler中可以不阻塞的執行返回的事件類型。這個模塊一般使用操作系統的select來實現。在Java NIO中用Selector來封裝,當Selector.select()返回時,可以調用Selector的selectedKeys()方法獲取Set,一個SelectionKey表達一個有事件發生的Channel以及該Channel上的事件類型。
接下來,我們便從具體的常見來一一探討一下Reactor模式下的各種線程模型。
從一定意義上來說, 基於Reactor模式的Reactor模型是非阻塞I/O模型。
2.0. 單Reactor單線程模型
單Reactor單線程模型主要是指將服務端的整個處理事件分為若幹個事件,Reactor 通過事件檢測機制把若幹個事件Handler分發給不同的處理器去處理。簡單來說,Reactor和Handle都放入一個線程中執行。
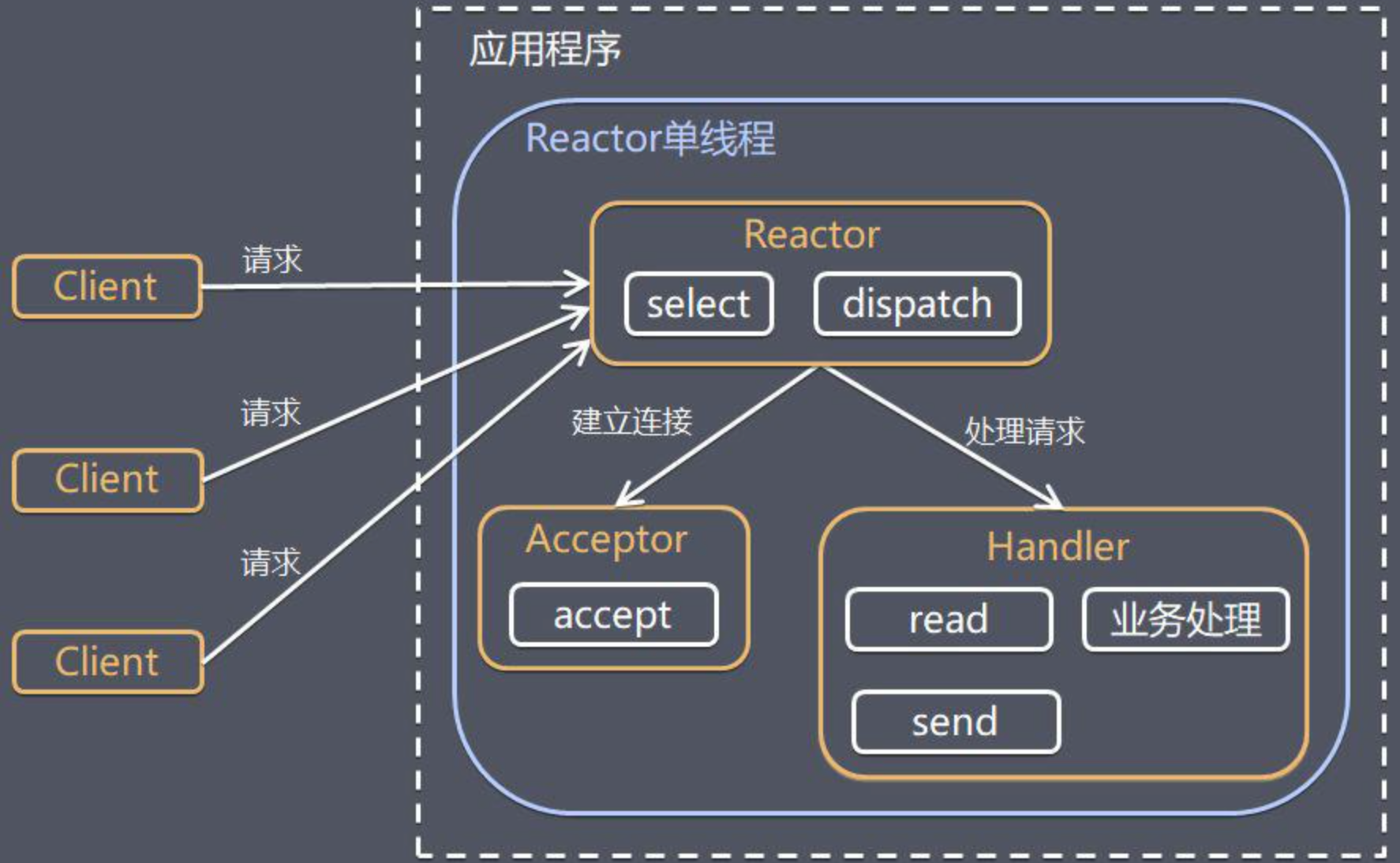
在實際工作中,若幹個客戶端連接訪問服務端,假如會有接收事件(Accept Event),讀事件(Read Event),寫事件(Write Event),以及執行事件(Process Event)等,其中,:
- Reactor 模型則把這些事件都分發到各自的處理器。
- 整個過程,只要有等待處理的事件存在,Reactor 線程模型不斷往後續執行,而且不會阻塞,所以效率很高。
由此可見,單Reactor單線程模型具有簡單,沒有多線程,沒有進程通信。但是從性能上來說,無法發揮多核的極致,一個Handler卡死,導致當前進程無法使用,IO和CPU不匹配。
在Java領域中,對於一個單Reactor單線程模型的實現,主要需用到SelectionKey(選擇鍵)的幾個重要的成員方法:
- void attach(Object o):將對象附加到選擇鍵。可以將任何Java POJO對象作為附件添加到SelectionKey實例。
- Object attachment():從選擇鍵獲取附加對象。與attach(Object o)是配套使用的,其作用是取出之前通過attach(Object o)方法添加到SelectionKey實例的附加對象。這個方法同樣非常重要,當IO事件發生時,選擇鍵將被select方法查詢出來,可以直接將選擇鍵的附件對象取出。
因此,在Reactor模式實現中,通過attachment()方法所取出的是之前通過attach(Object o)方法綁定的Handler實例,然後通過該Handler實例完成相應的傳輸處理。
綜上所述,在Reactor模式中,需要將attach和attachment結合使用:
- 在選擇鍵註冊完成之後調用attach()方法,將Handler實例綁定到選擇鍵。
- 當IO事件發生時調用attachment()方法,可以從選擇鍵取出Handler實例,將事件分發到Handler處理器中完成業務處理。
從一定意義上來說,單Reactor單線程模型是基於單線程的Reactor模式。
2.1. 單Reactor多線程模型
單Reactor多線程模型是指採用多線程機制,將服務端的整個處理事件分為若幹個事件,Reactor 通過事件檢測機制把若幹個事件Handler分發給不同的處理器去處理。
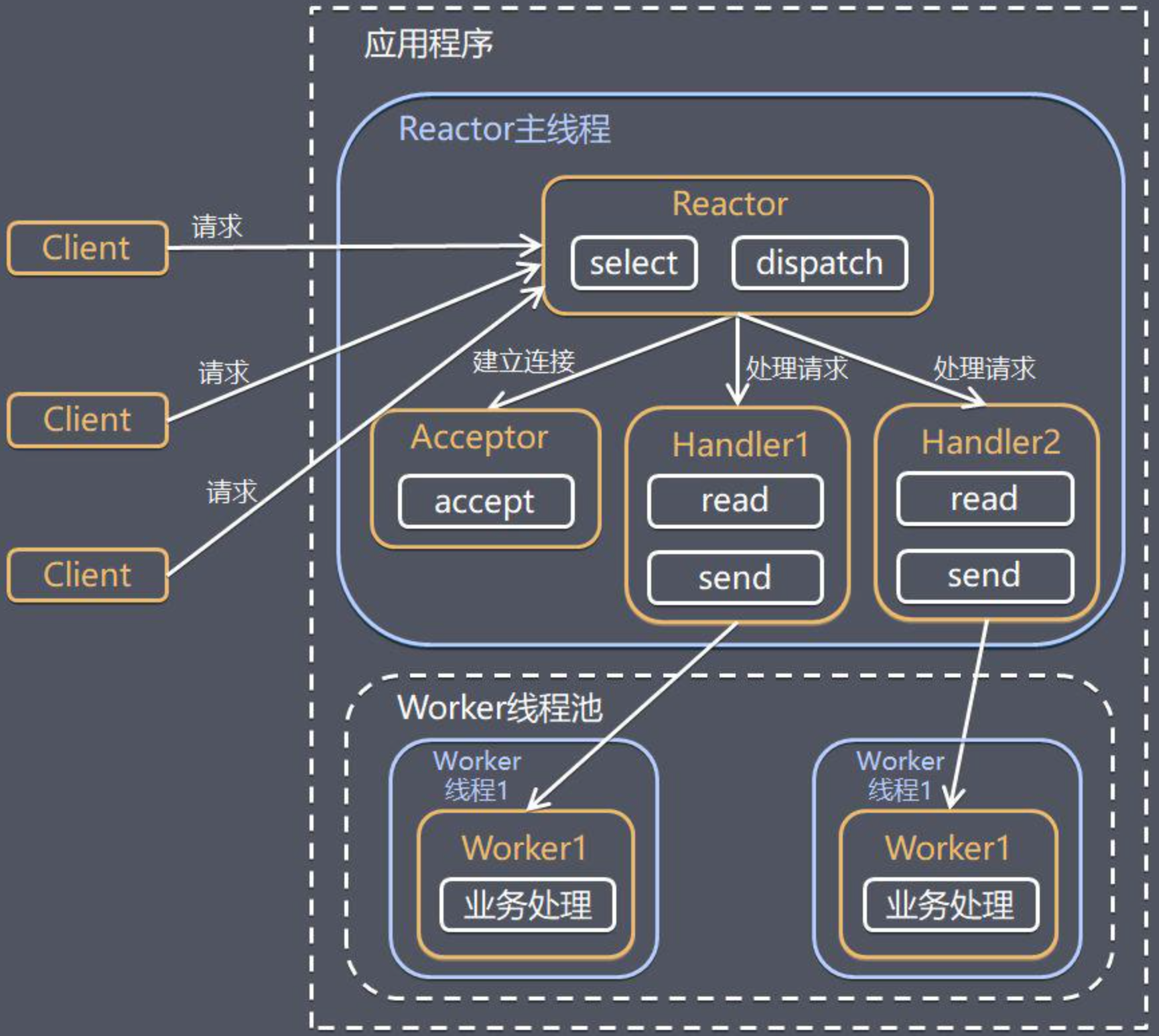
單Reactor多線程模型是基於單線程的Reactor模式的結構,將其利用線程池機制改進多線程模式。
相當於,Reactor對於接收事件(Accept Event),讀事件(Read Event),寫事件(Write Event),以及執行事件(Process Event)等分發到各自的處理器時:
- 首先,對於耗時的任務引入線程池機制,事件處理器自己不執行任務,而是交給線程池來托管,避免了耗時的操作。
- 其次,雖然Reactor只有一個線程,但是也保證了Reactor的高效。
在Java領域中,對於一個單Reactor多線程模型的實現,主要可以從升級Handler和升級Reactor來改進:
- 升級Handler:既要使用多線程,又要儘可能高效率,則可以考慮使用線程池。
- 升級Reactor:可以考慮引入多個Selector(選擇器),提升選擇大量通道的能力。
總體來說,多線程版本的Reactor模式大致如下:
- 將負責數據傳輸處理的IOHandler處理器的執行放入獨立的線程池中。這樣,業務處理線程與負責新連接監聽的反應器線程就能相互隔離,避免伺服器的連接監聽受到阻塞。
- 如果伺服器為多核的CPU,可以將反應器線程拆分為多個子反應器(SubReactor)線程;同時,引入多個選擇器,並且為每一個SubReactor引入一個線程,一個線程負責一個選擇器的事件輪詢。這樣充分釋放了系統資源的能力,也大大提升了反應器管理大量連接或者監聽大量傳輸通道的能力。
由此可見,單Reactor單線程模型具有充分利用的CPU的特點,但是進程通信,複雜,Reactor承放了太多業務,高併發下可能成為性能瓶頸。
從一定意義上來說,單Reactor多線程模型是基於多線程的Reactor模式。
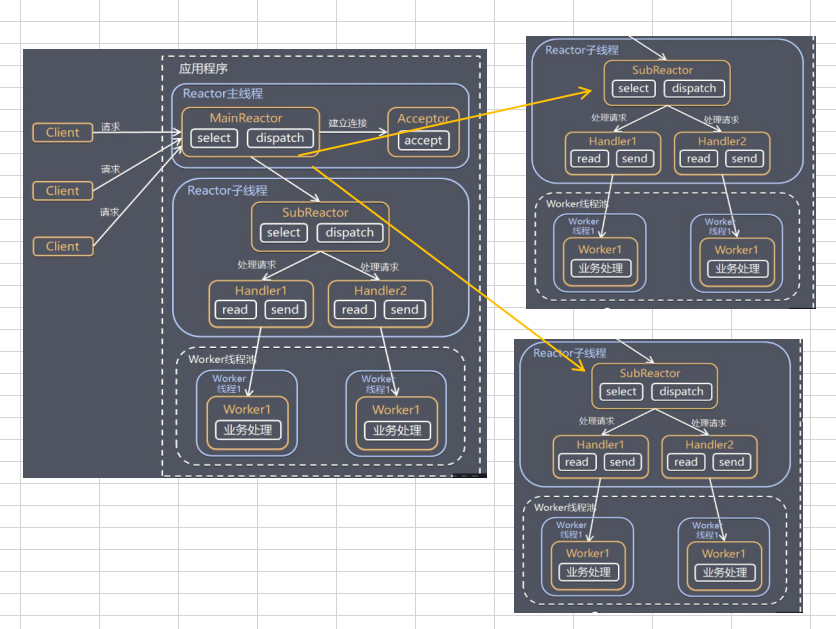
2.2. 主從Reactor多線程模型
主從Reactor多線程模型採用多個Reactor 的機制,將服務端的整個處理事件分為若幹個事件,Reactor 通過事件檢測機制把若幹個事件Handler分發給不同的處理器去處理。每一個Reactor對應著一個線程。
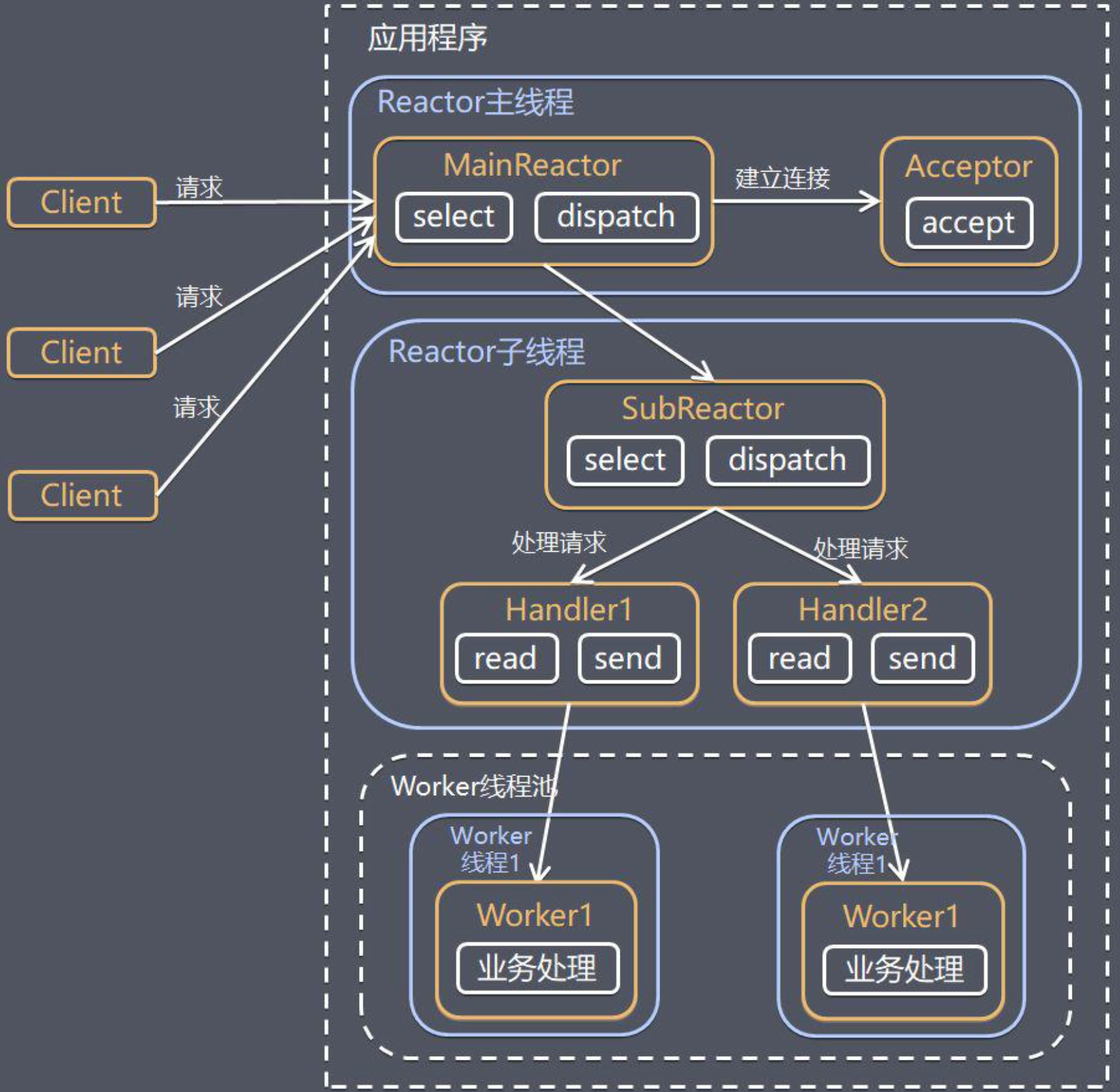
採用多個Reactor實例的機制:
-主Reactor:負責建立連接,建立連接後的句柄丟給從Reactor。
-從Reactor: 負責監聽所有事件進行處理。
相當於,Reactor對於接收事件(Accept Event),讀事件(Read Event),寫事件(Write Event),以及執行事件(Process Event)等分發到各自的處理器時:
- 由於接收事件是針對於伺服器端而言的,連接接收的工作統一由連接處理器完成,則連接處理器把接收到的客戶端連接均勻分配到所有的實例中去。
- 每一個Reactor 實例負責處理分配到該Reactor 實例的客戶端連接,完成連接時的讀寫操作和其他邏輯操作。
由此可見,主從Reactor多線程模型中Reactor實例職責分工明確,具有一定分攤壓力的效能,我們常見Nginx/Netty/Memcached等就是採用這中模型。
從一定意義上來說,主從Reactor多線程模型是基於多實例的Reactor模式。
2. 基於Proactor模式的Proactor模型
Proactor 模型是指在事件驅動的思想上,基於Proactor 的工作模式而設計的非同步I/O模型(AIO 模型),一定程度上來說,可以說是被動模式I/O模型。
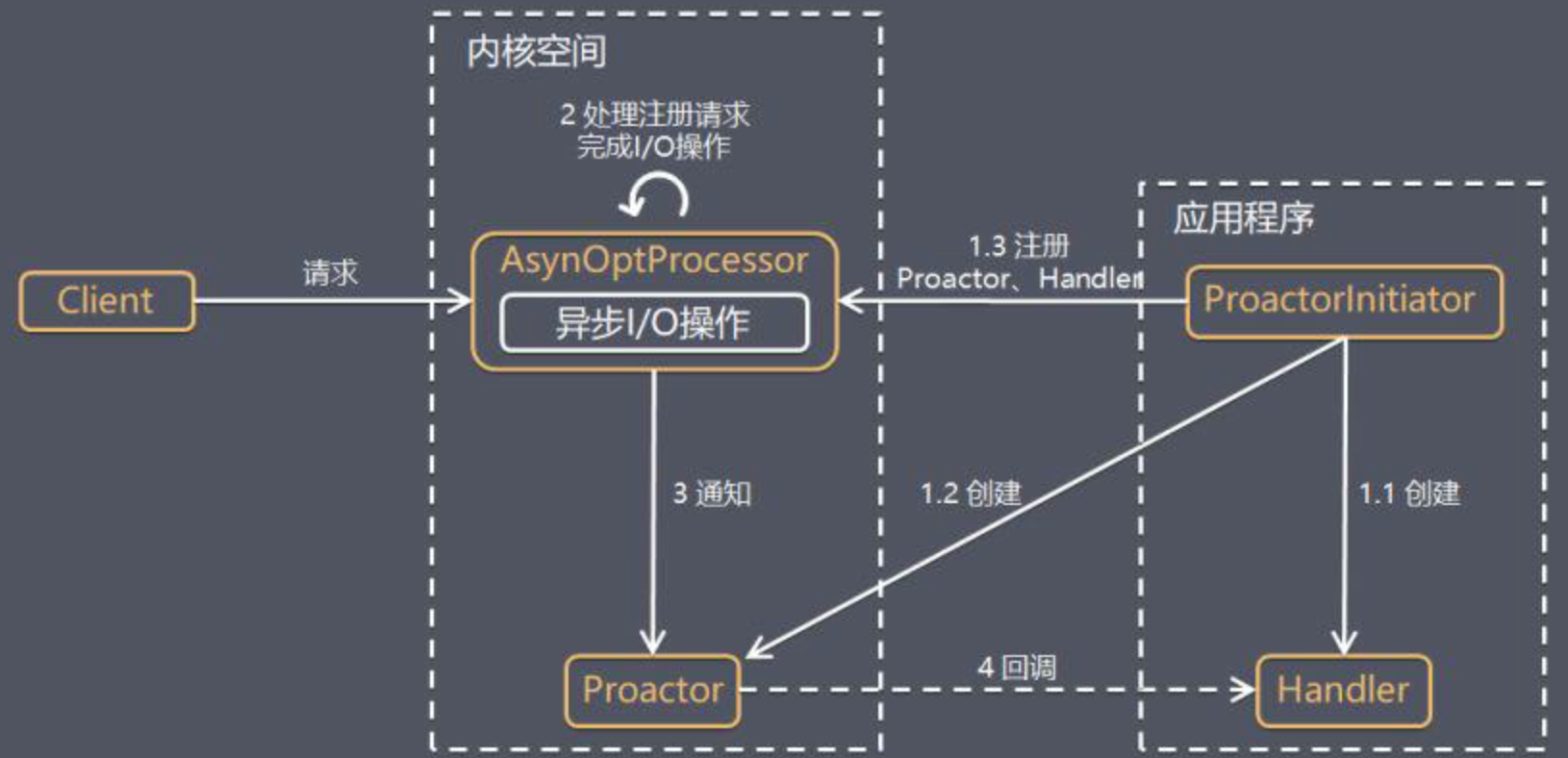
無論是 Reactor,還是 Proactor,都是一種基於事件分發的網路編程模式,區別在於 Reactor 模式是基於「待完成」的 I/O 事件,而 Proactor 模式則是基於「已完成」的 I/O 事件。
相對於Reactor來說,Proactor 模型處理讀取操作的主要流程:
- 應用程式初始化一個非同步讀取操作,然後註冊相應的事件處理器,此時事件處理器不關註讀取就緒事件,而是關註讀取完成事件。
- 事件分離器等待讀取操作完成事件。
- 在事件分離器等待讀取操作完成的時候,操作系統調用內核線程完成讀取操作,並將讀取的內容放入用戶傳遞過來的緩存區中。
- 事件分離器捕獲到讀取完成事件後,激活應用程式註冊的事件處理器,事件處理器直接從緩存區讀取數據,而不需要進行實際的讀取操作。
由此可見,Proactor中寫入操作和讀取操作基本一致,只不過監聽的事件是寫入完成事件而已。
在Java領域中,非同步IO(AIO)是在Java JDK 7 之後引入的,都是操作系統負責將數據讀寫到應用傳遞進來的緩衝區供應用程式操作。
其中,從對於Proactor模式的設計來看,Proactor 模式的工作流程:
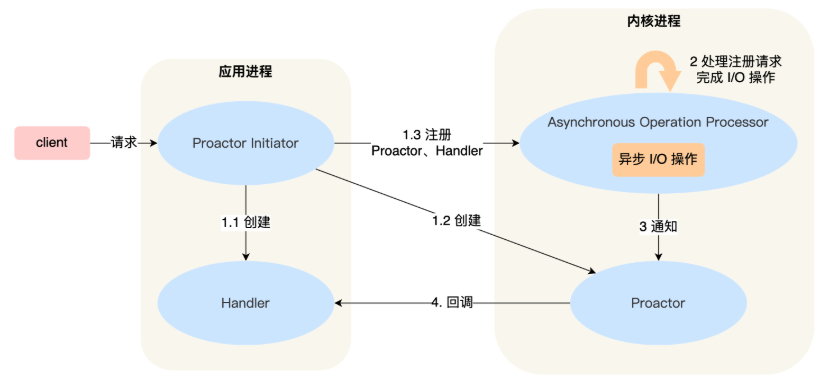
- Proactor Initiator: 負責創建 Proactor 和 Handler 對象,並將 Proactor 和 Handler 都通過 Asynchronous Operation Processor 註冊到內核。
- Asynchronous Operation Processor :負責處理註冊請求,並處理 I/O 操作。
- Asynchronous Operation Processor :完成 I/O 操作後通知 Proactor。
- Proactor :根據不同的事件類型回調不同的 Handler 進行業務處理。
- Handler: 完成業務處理,其中是通過CompletionHandler表示完成後處理器。
從一定意義上來說, 基於Proactor模式的Proactor模型是非同步IO。
3. 基於Promise模式的Promise模型
Promise模型是基於Promise非同步編程模式,客戶端代碼調用某個非同步方法所得到的返回值僅是一個憑據對象,憑藉該對象,客戶端代碼可以獲取非同步方法相應的真正任務的執行結果的一種模型。
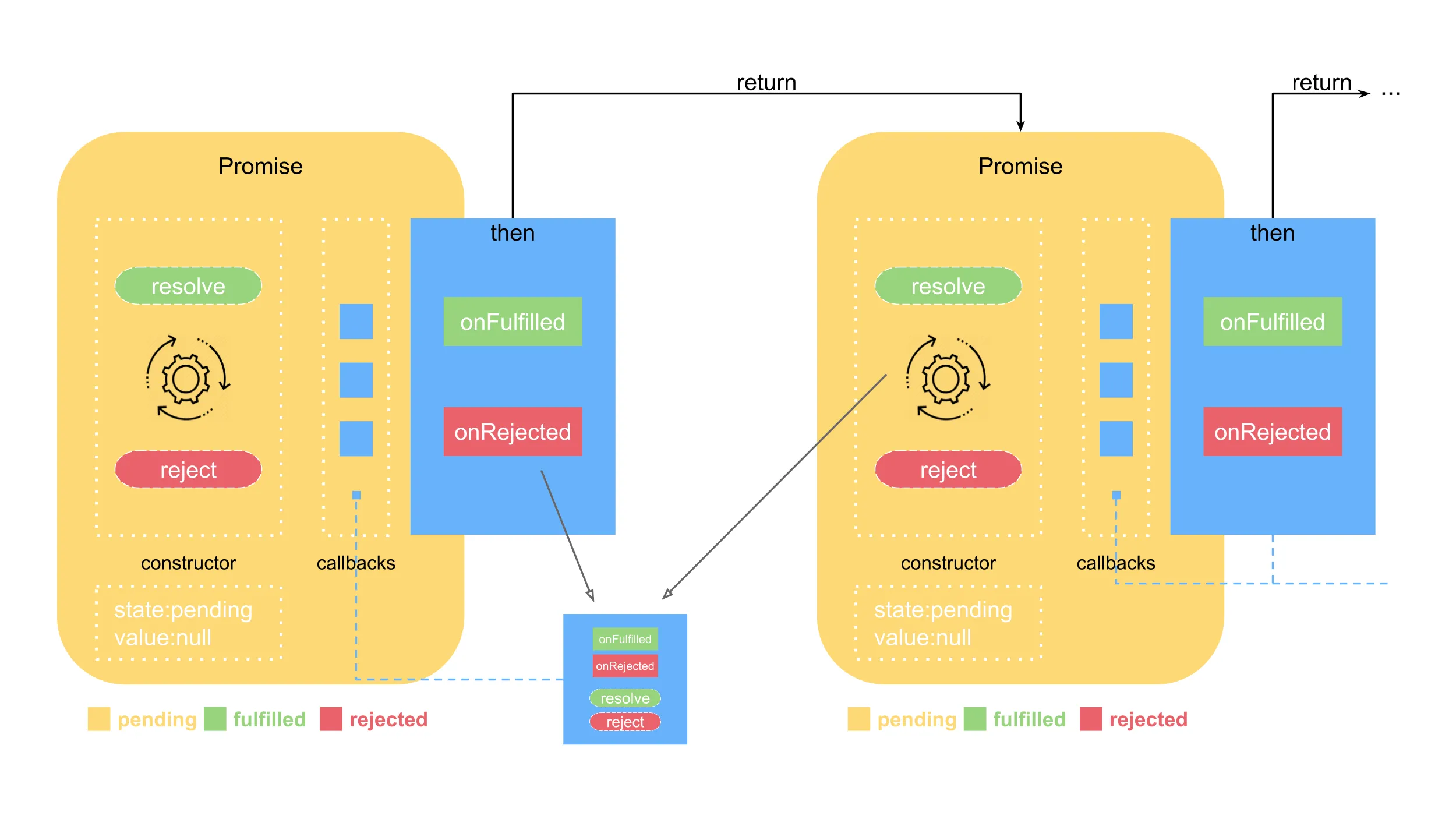
Promise 模式是開始一個任務的執行,並得到一個用於獲取該任務執行結果的憑據對象,而不必等待該任務執行完畢就可以繼續執行其他操作。
從Promise 模式的工作機制來看,主要如下:
- 當我們開始一個任務的執行,並得到一個用於獲取該任務執行結果的憑據對象,而不必等待該任務執行完畢就可以繼續執行其他操作。
- 等到我們需要該任務的執行結果時,再調用憑據對象的相關方法來獲取。
由此可以確定的是,Promise 模式既發揮了非同步編程的優勢——增加系統的併發性,減少不必要的等待,又保持了同步編程的簡單性。
從Promise 模式技術實現來說,主要職責角色如下:
- Promisor:負責對外暴露可以返回 Promise 對象的非同步方法,並啟動非同步任務的執行,主要利用compute方法啟動非同步任務的執行,並返回用於獲取非同步任務執行結果的憑據對象。
- Promise :負責包裝非同步任務處理結果的憑據對象。負責檢測非同步任務是否處理完畢、返回和存儲非同步任務處理結果。
- Result :負責表示非同步任務處理結果。具體類型由應用決定。
- TaskExecutor:負責真正執行非同步任務所代表的計算,並將其計算結果設置到相應的 Promise 實例對象。
在Java領域中,最典型的就是基於Future模型實現的Executor和FutureTask。
由於Future模型存在一定的局限性,在JDK 1.8 之後,對Future的擴展和增強實現又新增了一個CompletableFuture。
當然,Promise模式在前端技術JavaScript中Promise有具體的體現,而且隨著前端技術的發展日趨成熟,對於這種模式的運用早已日臻化境。
寫在最後

在Java領域中,Java領域中的線程主要分為Java層線程(Java Thread) ,JVM層線程(JVM Thread),操作系統層線程(Kernel Thread)。
從Java線程映射類型來看,主要有線程一對一(1:1)映射,線程多對多(M:1)映射,線程多對多(M:N)映射等關係。
因此,Java 領域中的線程映射模型主要有內核級線程模型(Kernel-Level Thread ,KLT)、應用級線程模型(Application-Level Thread ,ALT)、混合兩級線程模型(Mixture-Level Thread ,MLT)等3種模型。
在Java領域中,我們對照線程概念(單線程和多線程)來說,可以分為Java 線程-阻塞I/O模型和Java 線程-非阻塞I/O模型兩種。其中,
- Java 線程-阻塞I/O模型: 主要可以分為單線程阻塞I/O模型和多線程阻塞I/O模型。
- Java 線程-非阻塞I/O模型:主要可以分為應用層I/O多路復用模型和內核層I/O多路復用模型,以及內核回調事件驅動I/O模型。
特別指出,在Java領域中,非阻塞I/O的實現完全是基於操作系統內核的非阻塞I/O,JDK會依據操作系統內核支持的非阻塞I/O方式來幫助我們選擇實現方式。
綜上所述,在Java領域中,併發編程中的線程機制以及多線程的控制,在實際開發過程中,需要依據實際業務場景來考慮和衡量,這需要我們對其有更深的研究,才可以得心應手。
在討論編程模型的時候,我們提到了像基於Promise模式和基於Thread Pool 模式的這樣的設計模式的概念,這也是一個我們比較容易忽略的概念,如果有興趣的話,可以自行進行查詢相關資料進行瞭解。
最後,祝福大家在Java併發編程的“看山是山,看山不是山,看山還是山”的修行之路上,“撥開雲霧見天日,守得雲開見月明”,早日達到有跡可循到有跡可尋的目標!
版權聲明:本文為博主原創文章,遵循相關版權協議,如若轉載或者分享請附上原文出處鏈接和鏈接來源。


