
《紅樓夢》作為我國四大名著之一,古典小說的巔峰之作,粉絲量極其龐大,而紅學也經久不衰。所以我們今天通過 Python 來探索下紅樓夢裡那千絲萬縷的人物關係,話不多說,開始整活! 一、準備工作 紅樓夢txt格式電子書一份 金陵十二釵+賈寶玉人物名稱列表 寶玉 nr 黛玉 nr 寶釵 nr 湘雲 nr ...

《紅樓夢》作為我國四大名著之一,古典小說的巔峰之作,粉絲量極其龐大,而紅學也經久不衰。所以我們今天通過 Python 來探索下紅樓夢裡那千絲萬縷的人物關係,話不多說,開始整活!
一、準備工作
- 紅樓夢txt格式電子書一份
- 金陵十二釵+賈寶玉人物名稱列表
寶玉 nr
黛玉 nr
寶釵 nr
湘雲 nr
鳳姐 nr
李紈 nr
元春 nr
迎春 nr
探春 nr
惜春 nr
妙玉 nr
巧姐 nr
秦氏 nr
該分列表是為了做分詞時使用,後面的 nr 就是人名的意思。
二、人物出鏡次數
首先讀取小說
with open("紅樓夢.txt", encoding="gb18030") as f: honglou = f.read() # 更多視頻教程、電子書、源碼加君羊:279199867
接下來進行出場次數數據整理
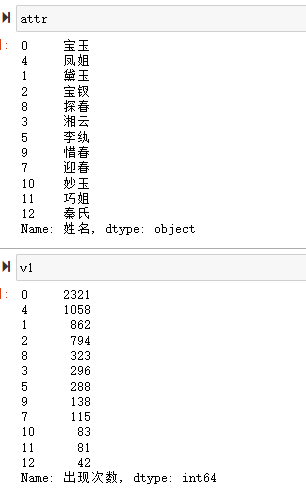
honglou = honglou.replace("\n", " ") honglou_new = honglou.split(" ") renwu_list = ['寶玉', '黛玉', '寶釵', '湘雲', '鳳姐', '李紈', '元春', '迎春', '探春', '惜春', '妙玉', '巧姐', '秦氏'] renwu = pd.DataFrame(data=renwu_list, columns=['姓名']) renwu['出現次數'] = renwu.apply(lambda x: len([k for k in honglou_new if x[u'姓名'] in k]), axis=1) renwu.to_csv('renwu.csv', index=False, sep=',') renwu.sort_values('出現次數', ascending=False, inplace=True) attr = renwu['姓名'][0:12] v1 = renwu['出現次數'][0:12]
這樣我們就得到了 attr 和 v1 兩個數據,內容如下
下麵就可以通過 pyecharts 來繪製柱狀圖了
bar = ( Bar() .add_xaxis(attr.tolist()) .add_yaxis("上鏡次數", v1.tolist()) .set_global_opts(title_opts=opts.TitleOpts(title="紅樓夢上鏡13人")) ) bar.render_notebook()

三、人物關係
1、數據處理
我們先將讀取到記憶體中的小說內容進行 jieba 分詞處理
import jieba jieba.load_userdict("renwu_forcut") renwu_data = pd.read_csv("renwu_forcut", header=-1) mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]
通過 load_userdict 將我們上面自定義的詞典載入到了 jieba 庫中
分詞處理
tmpNames = [] names = {} relationships = {} for h in honglou: h.replace("賈妃", "元春") h.replace("李宮裁", "李紈") poss = pseg.cut(h) tmpNames.append([]) for w in poss: if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist: continue tmpNames[-1].append(w.word) if names.get(w.word) is None: names[w.word] = 0 relationships[w.word] = {} names[w.word] += 1
因為文中"賈妃", “元春”,“李宮裁”, “李紈” 等人物名字混用嚴重,所以這裡做替換處理。
然後使用 jieba 庫提供的 pseg 工具來做分詞處理,會返回每個分詞的詞性。
之後做判斷,只有符合要求且在我們提供的字典列表裡的分詞,才會保留。
一個人每出現一次,就會增加一,方便後面畫關係圖時,人物 node 大小的確定。
對於存在於我們自定義詞典的人名,保存到一個臨時變數當中 tmpNames
處理每個段落中的人物關係
for name in tmpNames: for name1 in name: for name2 in name: if name1 == name2: continue if relationships[name1].get(name2) is None: relationships[name1][name2] = 1 else: relationships[name1][name2] += 1
對於出現在同一個段落中的人物,我們認為他們是關係緊密的,同時每出現一次,關係增加1 。
可以把相關信息保存到文件當中
with open("relationship.csv", "w", encoding='utf-8') as f: f.write("Source,Target,Weight\n") for name, edges in relationships.items(): for v, w in edges.items(): f.write(name + "," + v + "," + str(w) + "\n") with open("NameNode.csv", "w", encoding='utf-8') as f: f.write("ID,Label,Weight\n") for name, times in names.items(): f.write(name + "," + name + "," + str(times) + "\n")
文件1:人物關係表,包含首先出現的人物、之後出現的人物和一同出現次數。
文件2:人物比重表,包含該人物總體出現次數,出現次數越多,認為所占比重越大。
2、數據分析
下麵我們可以做一些簡單的人物關係分析
這裡我們還是使用 pyecharts 繪製圖表
def deal_graph(): relationship_data = pd.read_csv('relationship.csv') namenode_data = pd.read_csv('NameNode.csv') relationship_data_list = relationship_data.values.tolist() namenode_data_list = namenode_data.values.tolist() nodes = [] for node in namenode_data_list: if node[0] == "寶玉": node[2] = node[2]/3 nodes.append({"name": node[0], "symbolSize": node[2]/30}) links = [] for link in relationship_data_list: links.append({"source": link[0], "target": link[1], "value": link[2]}) g = ( Graph() .add("", nodes, links, repulsion=8000) .set_global_opts(title_opts=opts.TitleOpts(title="紅樓人物關係")) ) return g
首先把兩個文件通過 pandas 讀取到記憶體當中
對於“寶玉”,由於其占比過大,如果統一進行縮放,會導致其他人物的 node 過小,展示不美觀,所以這裡先做了一次縮放
最後我們得到的人物關係圖如下

鐵子們,今天的分享就到這, 如果感覺文章內容不錯的話,記得關註+收藏讓更多的人看到!
給大家分享一套視頻,非常全面!
Python爬蟲:代碼總是學完就忘記?100個爬蟲實戰項目!讓你沉迷學習丨學以致用丨下一個Python大神就是你!


