
精華筆記: 1. 變數:存數的 - 聲明: 在銀行開了個帳戶 - 初始化: 給帳戶存錢 - 使用: 使用的是帳戶裡面的錢 - 對變數的使用就是對它所存的那個數的使用 - 變數在使用之前必須聲明並初始化 - 命名: - 只能包含字母、數字、_和$符,並且不能以數字開頭 - 嚴格區分大小寫 - 不能使用 ...
索引生命周期管理 (Index cycle management: ILM) 是在 Elasticsearch 6.7 版正式推出的一項功能,它是 Elasticsearch 的一部分,主要用來幫助管理索引。
1、簡介
如果你要處理時間序列數據,則不想將所有內容連續轉儲到單個索引中。 取而代之的是,你可以定期將數據滾動到新索引,以防止數據過大而又緩慢又昂貴。 隨著索引的老化和查詢頻率的降低,你可能會將其轉移到價格較低的硬體上,並減少分片和副本的數量。
要在索引的生命周期內自動移動索引,可以創建策略來定義隨著索引的老化對索引執行的操作,這樣可以確保所有索引具有相似的大小。
ILM 由一些策略(policies)組成,而這些策略可以觸發一些 actions。這些 actions 可以為:
| Action | Description |
| rollover | 創建一個新的索引,基於數據的時間跨度,大小及文檔的多少 |
| shrink | 減少 primary shards 的數目 |
| force merge | 合併 shard 的 segments |
| freeze | 針對鮮少使用的索引進行凍結以節省記憶體 |
| delete | 永久地刪除一個索引 |
索引生命周期由五個階段(phases)組成:hot,warm,cold,frozen 及 delete。每個階段有一組可用的 actions。這些 actions 由上面的 actions 中的一些組成。把這些階段和相應的 actions 一起組合起來就形成了一個策略(policy)。我們可以通過 API 的形式或者直接在 Kibana 中使用 UI 的形式來創建這些 policies。
ILM 策略實例:
在 hot 階段,你可能 rollover 一個 alias 從而每兩個星期就生成一個新的索引,避免太大的索引數據。在這個階段你可以做導入數據,並允許繁重的搜索。
在 warm 階段,你可能把索引變成 read-only,並把索引保留於這個階段一個星期。在這個階段,不可以導入數據,但是可以進行適度的搜索。
在 cold 階段,你可能 freeze 索引,並減少 replica 的數量,並保留於這個階段三個星期。在這個階段,不可以導入數據,但是可以進行極其少量的搜索,
在 delete 階段,只有一個動作可以選擇。比如你可以刪除超過 6 個星期的索引數據以節省成本。
索引在 Elasticsearch 中的生命周期:
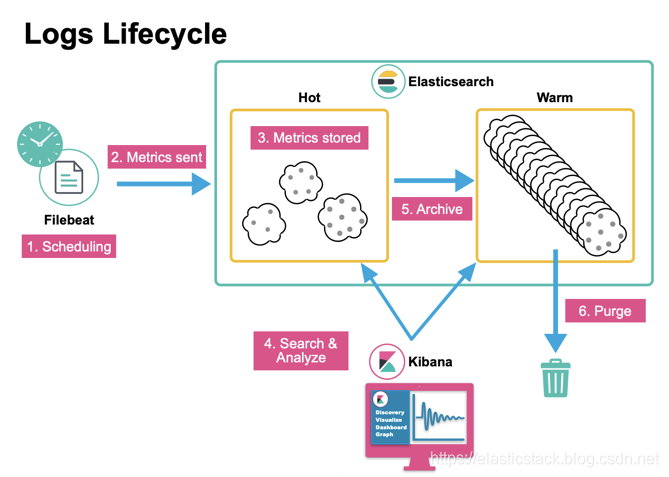
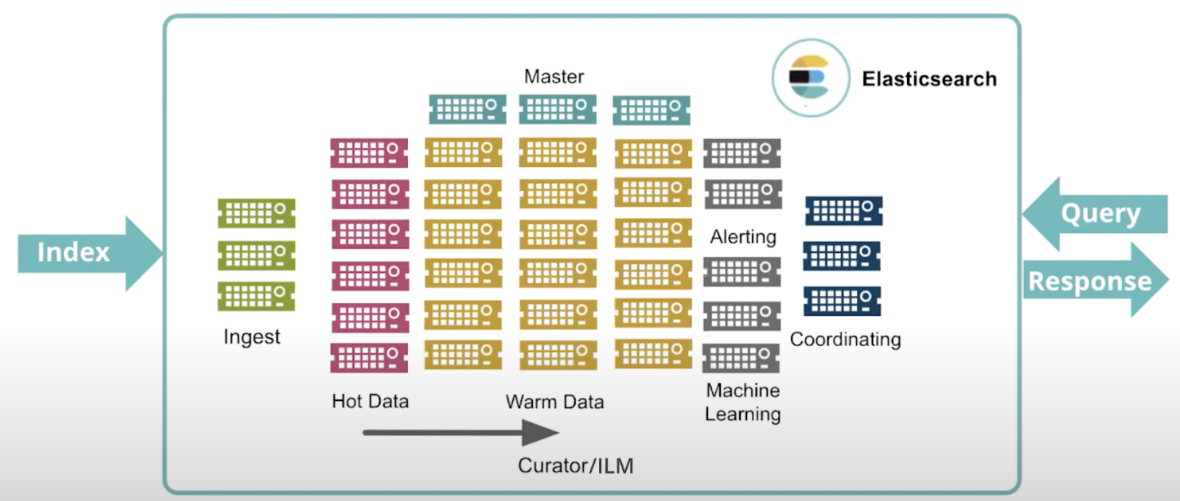
針對一個超大規模的集群:
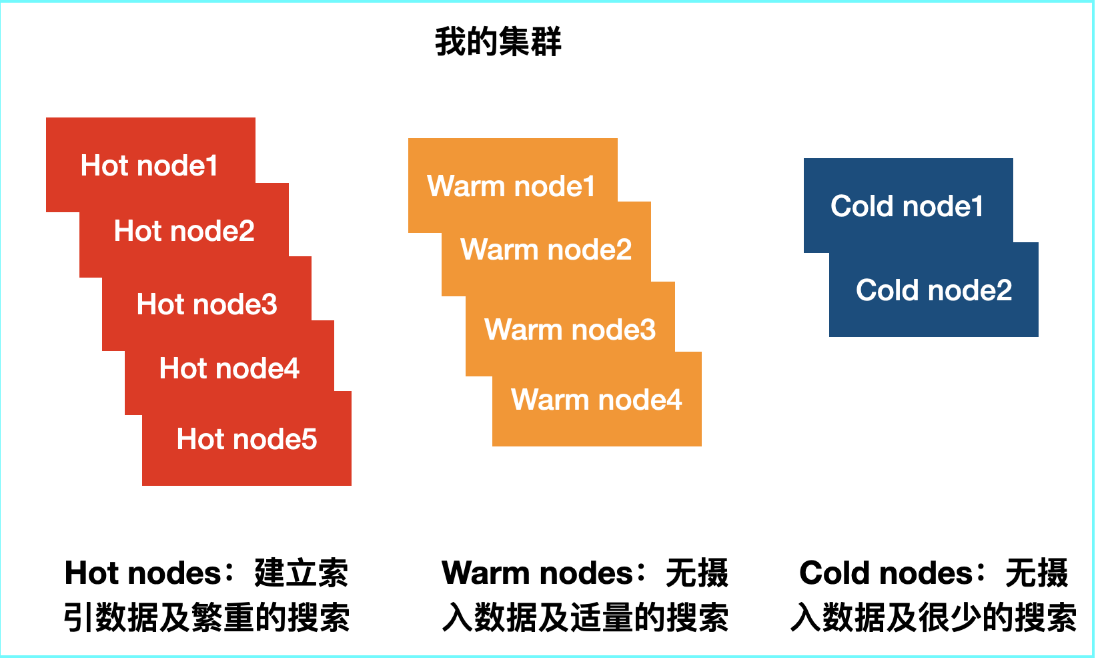
各節點職責:
2、生命周期管理演示
2.1、啟動 Elasticsearch 集群
啟動三個節點(10.49.196.10、10.49.196.11、10.49.196.12)的集群,其中兩個為 hot 節點(存放 hot 階段的數據),一個為 warm 節點(存放 warm 階段的數據)。
在 10.49.196.10、10.49.196.11 上運行:
bin/elasticsearch -d -E node.attr.data=hot
在 10.49.196.12 上運行:
bin/elasticsearch -d -E node.attr.data=warm
查看 node 屬性信息:
GET _cat/nodeattrs?v

2.2、創建 ILM policy
PUT _ilm/policy/my_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "10mb", "max_age": "1d", "max_docs": 5 } } }, "warm": { "min_age": "5m", "actions": { "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 0, "require": { "data": "warm" } } } }, "delete": { "min_age": "10m", "actions": { "delete": {} } } } } }
這裡定義的 policy 意思為:
熱階段
索引創建 1 天後、索引大小達到 10MB 或 索引文檔數達到 5(符合任何一個即可),該索引將滾動更新,系統將創建一個新索引。該新索引將重新啟動策略,而當前的索引(剛剛滾動更新的索引)將在滾動更新後等待 5 分鐘進入溫階段。
溫階段
索引進入溫階段後,ILM 會將索引收縮到 1 個分片 0 個副本,通過分配操作將索引移動到溫節點。完成該操作後,索引將再等待 5 分鐘 (時間都是從滾動跟新算起,10 - 5 = 5)後進入刪除階段。
刪除階段
刪除階段具有用於刪除索引的刪除操作。在刪除階段,您將始終需要有一個 min_age 條件,以允許索引在給定時段內待在熱、溫或冷階段。
2.3、創建 Index template
PUT _template/my_template { "index_patterns": ["test-*"], "settings": { "index.lifecycle.name": "my_policy", "index.lifecycle.rollover_alias": "test-alias", "index.routing.allocation.require.data": "hot", "index": { "number_of_shards": 2, "number_of_replicas": 1 } }, "mappings": { "properties": { "age": { "type": "integer" }, "name": { "type": "keyword" }, "poems": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "about": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "success": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } }
所有以 test- 開頭的 index 都需要遵循這個規律。這裡定義了 rollover 的 alias 為 “test-alias”。需要註意的是 "index.routing.allocation.require.data": "hot",這定義了我們需要 indexing 的 node 的 data 屬性是 hot。
2.4、定義 Index alias
PUT test-000001 { "aliases": { "test-alias": { "is_write_index": true } } }
這裡定義了一個叫做 test-alias 的 alias,它指向 test-00001 索引。註意這裡的 is_write_index 為 true。如果有 rollover 發生時,這個alias會自動指向最新 rollover 的 index。
使用 elasticsearch-head 查看該索引:

2.5、新增數據
POST test-alias/_bulk {"index":{"_id":"1"}} {"age": 30,"name": "李白1","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"} {"index":{"_id":"2"}} {"age": 30,"name": "李白2","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"} {"index":{"_id":"3"}} {"age": 30,"name": "李白3","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"} {"index":{"_id":"4"}} {"age": 30,"name": "李白4","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"} {"index":{"_id":"5"}} {"age": 30,"name": "李白5","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"} {"index":{"_id":"6"}} {"age": 30,"name": "李白6","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到後人難及的高度"}
2.5、rollover
已經有超過 5 個文檔了,將會 rollover;rollover 掃描間隔預設時 10 分鐘,可以通過修改 indices.lifecycle.poll_interval 參數來改變預設的間隔時間。
PUT _cluster/settings { "transient": { "indices.lifecycle.poll_interval": "30s" } }
rollover 後會生成新的索引:

2.6、進入 warm 階段
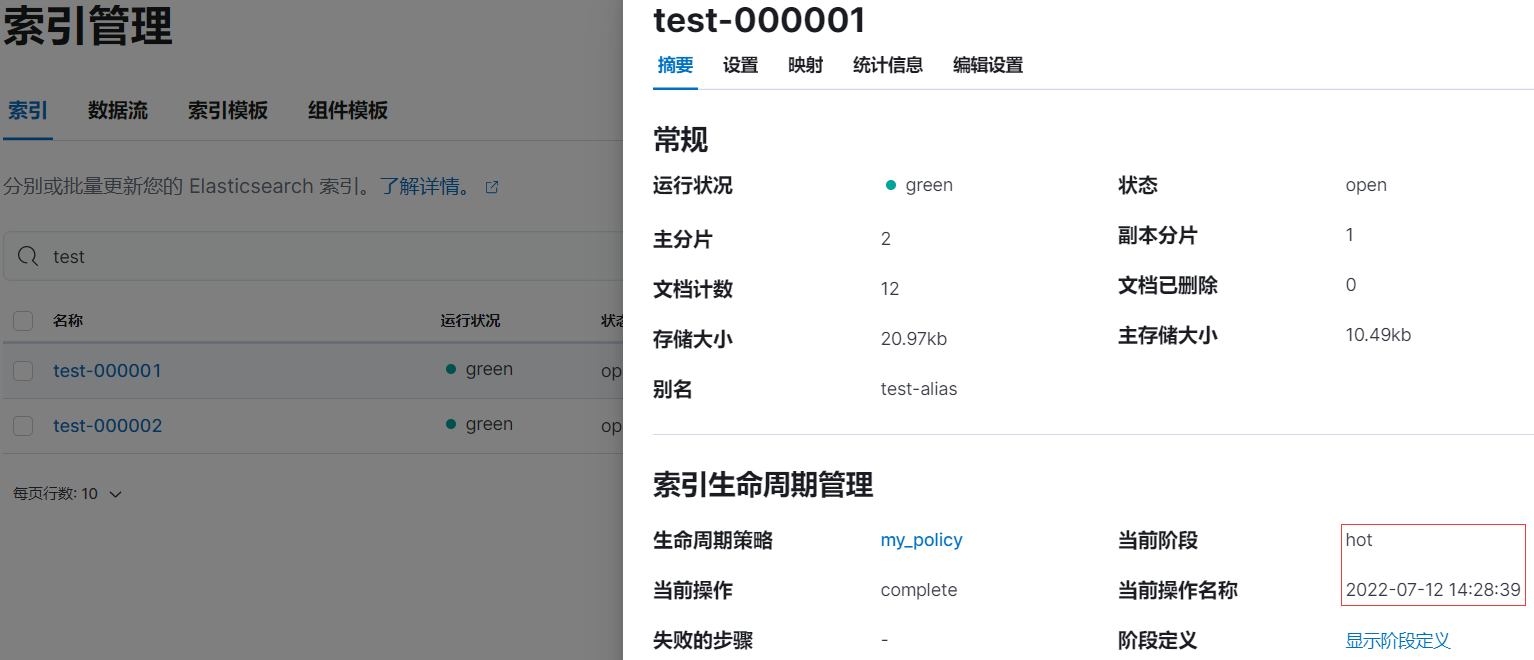
rollover 後,索引 test-000001 等待 5 分鐘左右後將會進入 warm 階段。
rollover 後的情況:
rollover 後等待 5 分鐘左右後,索引 test-000001 已被重命名為 shrink-so7u-test-000001:
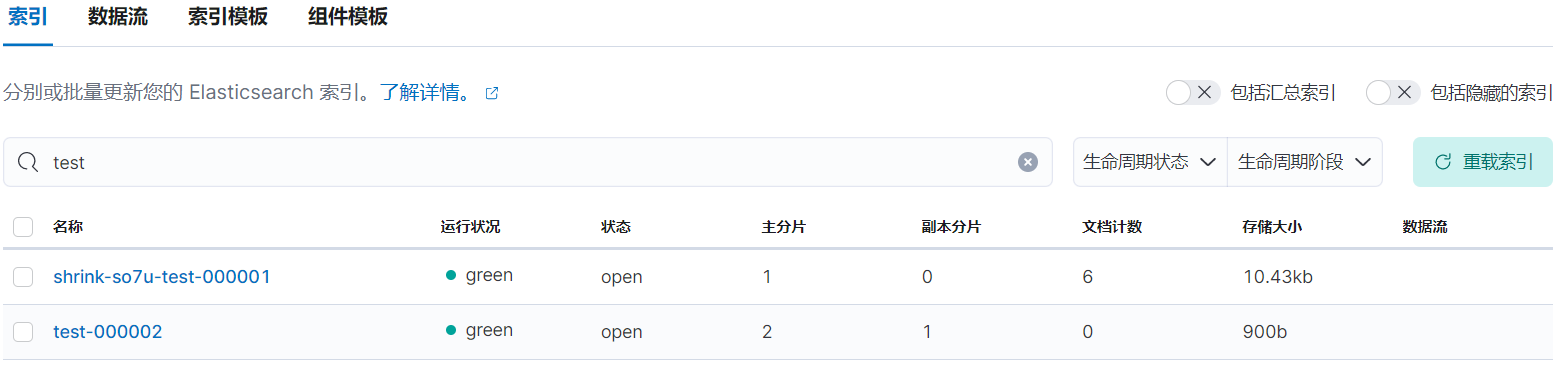
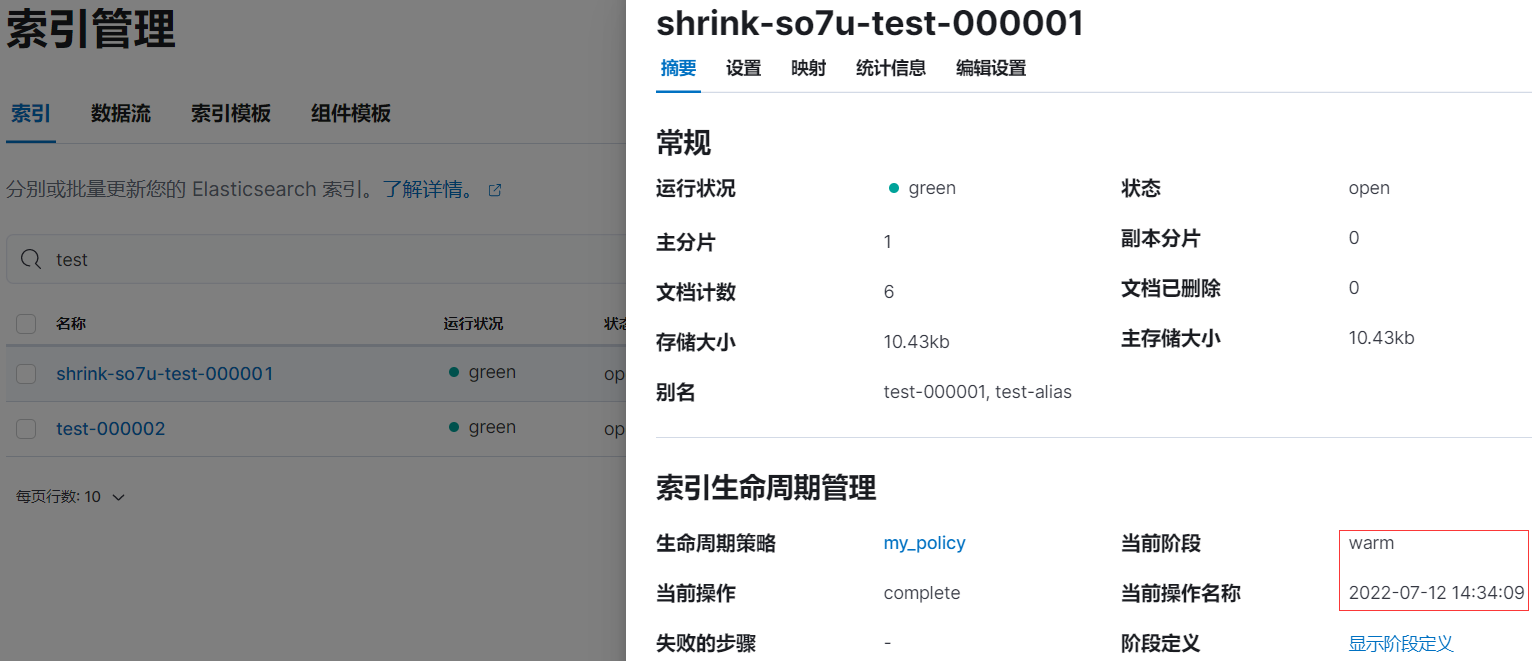
2.7、進入 delete 階段
在 warm 階段再等待 5 分鐘(10m - 5m)左右後, shrink-so7u-test-000001 進入 delete 階段,索引將被刪除。
參考:
1、https://elasticstack.blog.csdn.net/article/details/102728987
2、https://elasticstack.blog.csdn.net/article/details/102856967


