
MyDisruptor V6版本介紹 在v5版本的MyDisruptor實現DSL風格的API後。按照計劃,v6版本的MyDisruptor作為最後一個版本,需要對MyDisruptor進行最終的一些細節優化。 v6版本一共做了三處優化: 解決偽共用問題 支持消費者線程優雅停止 生產者序列器中維護消 ...
MyDisruptor V6版本介紹
在v5版本的MyDisruptor實現DSL風格的API後。按照計劃,v6版本的MyDisruptor作為最後一個版本,需要對MyDisruptor進行最終的一些細節優化。
v6版本一共做了三處優化:
- 解決偽共用問題
- 支持消費者線程優雅停止
- 生產者序列器中維護消費者序列集合的數據結構由ArrayList優化為數組Array類型(減少ArrayList在get操作時額外的rangeCheck檢查)
由於該文屬於系列博客的一部分,需要先對之前的博客內容有所瞭解才能更好地理解本篇博客
- v1版本博客:從零開始實現lmax-Disruptor隊列(一)RingBuffer與單生產者、單消費者工作原理解析
- v2版本博客:從零開始實現lmax-Disruptor隊列(二)多消費者、消費者組間消費依賴原理解析
- v3版本博客:從零開始實現lmax-Disruptor隊列(三)多線程消費者WorkerPool原理解析
- v4版本博客:從零開始實現lmax-Disruptor隊列(四)多線程生產者MultiProducerSequencer原理解析
- v5版本博客:從零開始實現lmax-Disruptor隊列(五)Disruptor DSL風格API原理解析
偽共用問題(FalseSharing)原理詳解
在第一篇博客中我們就已經介紹過偽共用問題了,這裡複製原博客內容如下:
現代的CPU都是多核的,每個核心都擁有獨立的高速緩存。高速緩存由固定大小的緩存行組成(通常為32個位元組或64個位元組)。CPU以緩存行作為最小單位讀寫,且一個緩存行通常會被多個變數占據(例如32位的引用指針占4位元組,64位的引用指針占8個位元組)。
這樣的設計導致了一個問題:即使緩存行上的變數是無關聯的(比如不屬於同一個對象),但只要緩存行上的某一個共用變數發生了變化,則整個緩存行都會進行緩存一致性的同步。
而CPU間緩存一致性的同步是有一定性能損耗的,能避免則儘量避免。這就是所謂的“偽共用”問題。
disruptor通過對隊列中一些關鍵變數進行了緩存行的填充,避免其因為不相干的變數讀寫而無謂的刷新緩存,解決了偽共用的問題。
舉例展示偽共用問題對性能的影響
- 假設存在一個Point對象,其中有兩個volatile修飾的long類型欄位,x和y。
有兩個線程併發的訪問一個Point對象,但其中一個線程1只讀寫x欄位,而另一個線程2只讀寫y欄位。
存在偽共用問題的demo
public class Point {
public volatile int x;
public volatile int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class FalseSharingDemo {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new SynchronousQueue<>());
CountDownLatch countDownLatch = new CountDownLatch(2);
Point point = new Point(1,2);
long start = System.currentTimeMillis();
executor.execute(()->{
// 線程1 x自增1億次
for(int i=0; i<100000000; i++){
point.x++;
}
countDownLatch.countDown();
});
executor.execute(()->{
// 線程2 y自增1億次
for(int i=0; i<100000000; i++){
point.y++;
}
countDownLatch.countDown();
});
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("testNormal 耗時=" + (end-start));
executor.shutdown();
}
}
- 兩個線程各自獨立訪問兩個不同的數據,但x和y是一個對象的兩個相鄰屬性因此在記憶體中是連續分佈的,大概率讀寫時會被放到同一個高速緩存行中,
由於volatile變數修飾的原因,線程1對x線程的修改會對當前緩存行進行觸發高速緩存間同步進行強一致地寫,使得線程2中x、y欄位所在CPU的高速緩存行失效,被迫重新讀取主存中最新的數據。
但實際上線程1讀寫x和線程2讀寫y是完全不相關的,線程1與線程2在實際業務中並不需要共用同一片記憶體空間,因此強一致的高速緩存行同步完全是畫蛇添足,只會降低性能。
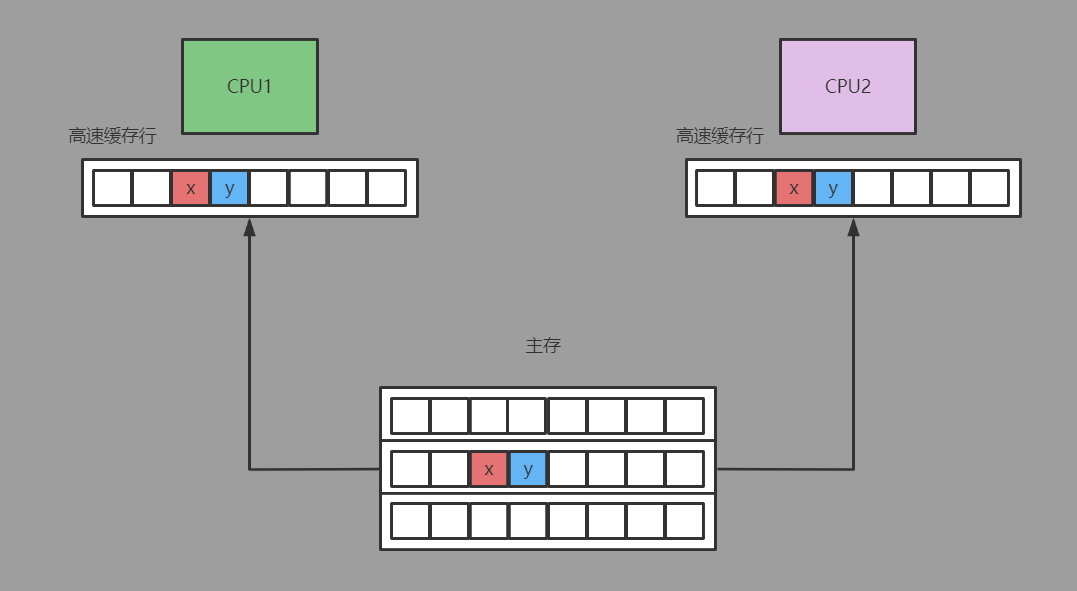
- 需要註意的是,偽共用問題絕大多數情況下是出現在不同對象之間的,例如線程1會訪問對象A中的volatile變數aaa,而線程2會訪問另一個對象B中的volatile變數bbb。
但恰好對象A的aaa屬性和對象B的bbb屬性被載入到同一個緩存行中,這便是實際上最常見的偽共用場景。
因此上述同一個Point對象中x、y兩個屬性互相干擾的例子其實並不是很恰當,只是為了方便演示效果才拿同一個對象里的不同欄位的偽共用場景舉例。 - 解決偽共用問題的方法是做緩存行的填充,簡單來說就是通過在需要避免偽共用的volatile欄位集合前後填充無用的padding欄位,讓編譯器在編排變數地址時保證其不會被其它線程在訪問不相關的變數時所影響。
無論怎樣分配變數地記憶體地址,被填充欄位包裹的volatile變數都不會被其它無關的變數訪問而被迫進行強一致地高速緩存同步。

通過填充無用欄位解決偽共用問題demo
public class PointNoFalseSharing {
private long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
public volatile long x;
private long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
public volatile long y;
public PointNoFalseSharing(int x, int y) {
this.x = x;
this.y = y;
}
}
public class NoFalseSharingDemo {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new SynchronousQueue<>());
CountDownLatch countDownLatch = new CountDownLatch(2);
PointNoFalseSharing point = new PointNoFalseSharing(1,2);
long start = System.currentTimeMillis();
executor.execute(()->{
// 線程1 x自增1億次
for(int i=0; i<100000000; i++){
point.x++;
}
countDownLatch.countDown();
});
executor.execute(()->{
// 線程2 y自增1億次
for(int i=0; i<100000000; i++){
point.y++;
}
countDownLatch.countDown();
});
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("testNoFalseSharing 耗時=" + (end-start));
executor.shutdown();
}
}
- 感興趣的讀者可以把上述存在偽共用問題和解決了偽共用問題的demo分別執行下看看。
在我的機器上,兩個線程在對x、y分別自增1億次的場景下,存在偽共用問題的示例代碼FalseSharingDemo比解決了偽共用問題示例代碼NoFalseSharingDemo要慢3到5倍。
disruptor中偽共用問題的解決方式
- disruptor中對三個關鍵組件的全部或部分屬性進行了緩存行的填充,分別是Sequence、RingBuffer和SingleProducerSequencer。
這三個組件有兩大特征:只會被單個線程寫、會被大量其它線程頻繁的讀,令它們避免出現偽共用問題在高併發場景下對性能有很大提升。 - MySingleProducerSequencer中很多屬性,但只有nextValue和cachedConsumerSequenceValue被填充欄位包裹起來,其主要原因是只有這兩個欄位會被生產者頻繁的讀寫。
MySequence解決偽共用實現
/**
* 序列號對象(仿Disruptor.Sequence)
*
* 由於需要被生產者、消費者線程同時訪問,因此內部是一個volatile修飾的long值
* */
public class MySequence {
/**
* 解決偽共用 左半部分填充
* */
private long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
/**
* 序列起始值預設為-1,保證下一個序列恰好是0(即第一個合法的序列號)
* */
private volatile long value = -1;
/**
* 解決偽共用 右半部分填充
* */
private long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
try {
UNSAFE = UnsafeUtil.getUnsafe();
VALUE_OFFSET = UNSAFE.objectFieldOffset(MySequence.class.getDeclaredField("value"));
}
catch (final Exception e) {
throw new RuntimeException(e);
}
}
// 註意:省略了方法代碼
}
MyRingBuffer解決偽共用實現
/**
* 環形隊列(仿Disruptor.RingBuffer)
* */
public class MyRingBuffer<T> {
/**
* 解決偽共用 左半部分填充
* */
protected long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
private final T[] elementList;
private final MyProducerSequencer myProducerSequencer;
private final int ringBufferSize;
private final int mask;
/**
* 解決偽共用 右半部分填充
* */
protected long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
// 註意:省略了方法代碼
}
MySingleProducerSequencer解決偽共用實現
/**
* 單線程生產者序列器(仿Disruptor.SingleProducerSequencer)
* 只支持單消費者的簡易版本(只有一個consumerSequence)
*
* 因為是單線程式列器,因此在設計上就是線程不安全的
* */
public class MySingleProducerSequencer implements MyProducerSequencer {
/**
* 生產者序列器所屬ringBuffer的大小
* */
private final int ringBufferSize;
/**
* 當前已發佈的生產者序列號
* (區別於nextValue)
* */
private final MySequence currentProducerSequence = new MySequence();
/**
* 生產者序列器所屬ringBuffer的消費者序列集合
* */
private volatile MySequence[] gatingConsumerSequences = new MySequence[0];
private final MyWaitStrategy myWaitStrategy;
/**
* 解決偽共用 左半部分填充
* */
private long lp1, lp2, lp3, lp4, lp5, lp6, lp7;
/**
* 當前已申請的序列(但是是否發佈了,要看currentProducerSequence)
*
* 單線程生產者內部使用,所以就是普通的long,不考慮併發
* */
private long nextValue = -1;
/**
* 當前已緩存的消費者序列
*
* 單線程生產者內部使用,所以就是普通的long,不考慮併發
* */
private long cachedConsumerSequenceValue = -1;
/**
* 解決偽共用 右半部分填充
* */
private long rp1, rp2, rp3, rp4, rp5, rp6, rp7;
// 註意:省略了方法代碼
}
- 對象填充多餘欄位避免偽共用問題,提高了性能的同時,也需要註意其可能大幅增加了對象所占用的記憶體空間。
在disruptor中因為Sequence,RingBuffer,SingleProducerSequencer這三個數據結構都是被線程頻繁訪問的,但實際的數量卻十分有限(正比於生產者、消費者的總數),所以這個問題並不嚴重。 - 填充緩存行的方法既可以像disruptor一樣,手動的設置填充欄位,也可以使用jdk提供的Contended註解來告訴編譯器進行緩衝行的填充,限於篇幅就不再繼續展開了。
為什麼和SingleProducerSequencer類似的MultiProducerSequencer不需要解決偽共用問題?
- 因為多線程生產者序列器中和nextValue、cachedConsumerSequenceValue等價的屬性就是需要在多個生產者線程間共用的,因此確實需要頻繁的在多個CPU核心的高速緩存行間進行同步。
這種場景是實實在在的共用場景,而不是偽共用場景,因此也就不存在偽共用問題了。
支持消費者線程優雅停止詳解
截止MyDisruptor的v5版本,消費者線程都是通過一個永不停止的while迴圈進行工作的,除非強制殺死線程,否則無法令消費者線程關閉,而這無疑是不優雅的。
實現外部通知消費者線程自行終止
為此,disruptor實現了令消費者線程主動停止的機制。
- 具體思路是在消費者線程內部維護一個用於標識是否需要繼續運行的標識running,預設是運行中,但外部可以去修改標識的狀態(halt方法),將其標識為停止。
- 消費者主迴圈時每次都檢查一下該狀態,如果標識是停止,則拋出AlertException異常。主迴圈中捕獲該異常,然後通過一個break跳出主迴圈,主動地關閉。
實現了優雅停止功能的單線程消費者
/**
* 單線程消費者(仿Disruptor.BatchEventProcessor)
* */
public class MyBatchEventProcessor<T> implements MyEventProcessor{
private final MySequence currentConsumeSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final MyEventHandler<T> myEventConsumer;
private final MySequenceBarrier mySequenceBarrier;
private final AtomicBoolean running = new AtomicBoolean();
public MyBatchEventProcessor(MyRingBuffer<T> myRingBuffer,
MyEventHandler<T> myEventConsumer,
MySequenceBarrier mySequenceBarrier) {
this.myRingBuffer = myRingBuffer;
this.myEventConsumer = myEventConsumer;
this.mySequenceBarrier = mySequenceBarrier;
}
@Override
public void run() {
if (!running.compareAndSet(false, true)) {
throw new IllegalStateException("Thread is already running");
}
this.mySequenceBarrier.clearAlert();
// 下一個需要消費的下標
long nextConsumerIndex = currentConsumeSequence.get() + 1;
// 消費者線程主迴圈邏輯,不斷的嘗試獲取事件併進行消費(為了讓代碼更簡單,暫不考慮優雅停止消費者線程的功能)
while(true) {
try {
long availableConsumeIndex = this.mySequenceBarrier.getAvailableConsumeSequence(nextConsumerIndex);
while (nextConsumerIndex <= availableConsumeIndex) {
// 取出可以消費的下標對應的事件,交給eventConsumer消費
T event = myRingBuffer.get(nextConsumerIndex);
this.myEventConsumer.consume(event, nextConsumerIndex, nextConsumerIndex == availableConsumeIndex);
// 批處理,一次主迴圈消費N個事件(下標加1,獲取下一個)
nextConsumerIndex++;
}
// 更新當前消費者的消費的序列(lazySet,不需要生產者實時的強感知刷緩存性能更好,因為生產者自己也不是實時的讀消費者序列的)
this.currentConsumeSequence.lazySet(availableConsumeIndex);
LogUtil.logWithThreadName("更新當前消費者的消費的序列:" + availableConsumeIndex);
} catch (final MyAlertException ex) {
LogUtil.logWithThreadName("消費者MyAlertException" + ex);
// 被外部alert打斷,檢查running標記
if (!running.get()) {
// running == false, break跳出主迴圈,運行結束
break;
}
} catch (final Throwable ex) {
// 發生異常,消費進度依然推進(跳過這一批拉取的數據)(lazySet 原理同上)
this.currentConsumeSequence.lazySet(nextConsumerIndex);
nextConsumerIndex++;
}
}
}
@Override
public MySequence getCurrentConsumeSequence() {
return this.currentConsumeSequence;
}
@Override
public void halt() {
// 當前消費者狀態設置為停止
running.set(false);
// 喚醒消費者線程(令其能立即檢查到狀態為停止)
this.mySequenceBarrier.alert();
}
@Override
public boolean isRunning() {
return this.running.get();
}
}
實現了優雅停止功能多線程消費者
/**
* 多線程消費者工作線程 (仿Disruptor.WorkProcessor)
* */
public class MyWorkProcessor<T> implements MyEventProcessor{
private final MySequence currentConsumeSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final MyWorkHandler<T> myWorkHandler;
private final MySequenceBarrier sequenceBarrier;
private final MySequence workGroupSequence;
private final AtomicBoolean running = new AtomicBoolean(false);
public MyWorkProcessor(MyRingBuffer<T> myRingBuffer,
MyWorkHandler<T> myWorkHandler,
MySequenceBarrier sequenceBarrier,
MySequence workGroupSequence) {
this.myRingBuffer = myRingBuffer;
this.myWorkHandler = myWorkHandler;
this.sequenceBarrier = sequenceBarrier;
this.workGroupSequence = workGroupSequence;
}
@Override
public MySequence getCurrentConsumeSequence() {
return currentConsumeSequence;
}
@Override
public void halt() {
// 當前消費者狀態設置為停止
running.set(false);
// 喚醒消費者線程(令其能立即檢查到狀態為停止)
this.sequenceBarrier.alert();
}
@Override
public boolean isRunning() {
return this.running.get();
}
@Override
public void run() {
if (!running.compareAndSet(false, true)) {
throw new IllegalStateException("Thread is already running");
}
this.sequenceBarrier.clearAlert();
long nextConsumerIndex = this.currentConsumeSequence.get();
// 設置哨兵值,保證第一次迴圈時nextConsumerIndex <= cachedAvailableSequence一定為false,走else分支通過序列屏障獲得最大的可用序列號
long cachedAvailableSequence = Long.MIN_VALUE;
// 最近是否處理過了序列
boolean processedSequence = true;
while (true) {
try {
if(processedSequence) {
// 爭搶到了一個新的待消費序列,但還未實際進行消費(標記為false)
processedSequence = false;
// 如果已經處理過序列,則重新cas的爭搶一個新的待消費序列
do {
nextConsumerIndex = this.workGroupSequence.get() + 1L;
// 由於currentConsumeSequence會被註冊到生產者側,因此需要始終和workGroupSequence worker組的實際sequence保持協調
// 即當前worker的消費序列currentConsumeSequence = 當前消費者組的序列workGroupSequence
this.currentConsumeSequence.lazySet(nextConsumerIndex - 1L);
// 問題:只使用workGroupSequence,每個worker不維護currentConsumeSequence行不行?
// 回答:這是不行的。因為和單線程消費者的行為一樣,都是具體的消費者eventHandler/workHandler執行過之後才更新消費者的序列號,令其對外部可見(生產者、下游消費者)
// 因為消費依賴關係中約定,對於序列i事件只有在上游的消費者消費過後(eventHandler/workHandler執行過),下游才能消費序列i的事件
// workGroupSequence主要是用於通過cas協調同一workerPool內消費者線程式列爭搶的,對外的約束依然需要workProcessor本地的消費者序列currentConsumeSequence來控制
// cas更新,保證每個worker線程都會獲取到唯一的一個sequence
} while (!workGroupSequence.compareAndSet(nextConsumerIndex - 1L, nextConsumerIndex));
}else{
// processedSequence == false(手頭上存在一個還未消費的序列)
// 走到這裡說明之前拿到了一個新的消費序列,但是由於nextConsumerIndex > cachedAvailableSequence,沒有實際執行消費邏輯
// 而是被阻塞後返回獲得了最新的cachedAvailableSequence,重新執行一次迴圈走到了這裡
// 需要先把手頭上的這個序列給消費掉,才能繼續拿下一個消費序列
}
// cachedAvailableSequence只會存在兩種情況
// 1 第一次迴圈,初始化為Long.MIN_VALUE,則必定會走到下麵的else分支中
// 2 非第一次迴圈,則cachedAvailableSequence為序列屏障所允許的最大可消費序列
if (cachedAvailableSequence >= nextConsumerIndex) {
// 爭搶到的消費序列是滿足要求的(小於序列屏障值,被序列屏障允許的),則調用消費者進行實際的消費
// 取出可以消費的下標對應的事件,交給eventConsumer消費
T event = myRingBuffer.get(nextConsumerIndex);
this.myWorkHandler.consume(event);
// 實際調用消費者進行消費了,標記為true.這樣一來就可以在下次迴圈中cas爭搶下一個新的消費序列了
processedSequence = true;
} else {
// 1 第一次迴圈會獲取當前序列屏障的最大可消費序列
// 2 非第一次迴圈,說明爭搶到的序列超過了屏障序列的最大值,等待生產者推進到爭搶到的sequence
cachedAvailableSequence = sequenceBarrier.getAvailableConsumeSequence(nextConsumerIndex);
}
} catch (final MyAlertException ex) {
// 被外部alert打斷,檢查running標記
if (!running.get()) {
// running == false, break跳出主迴圈,運行結束
break;
}
} catch (final Throwable ex) {
// 消費者消費時發生了異常,也認為是成功消費了,避免阻塞消費序列
// 下次迴圈會cas爭搶一個新的消費序列
processedSequence = true;
}
}
}
}
/**
* 多線程消費者(仿Disruptor.WorkerPool)
* */
public class MyWorkerPool<T> {
private final AtomicBoolean started = new AtomicBoolean(false);
private final MySequence workSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final List<MyWorkProcessor<T>> workEventProcessorList;
public void halt() {
for (MyWorkProcessor<?> processor : this.workEventProcessorList) {
// 挨個停止所有工作線程
processor.halt();
}
started.set(false);
}
public boolean isRunning(){
return this.started.get();
}
// 註意:省略了無關代碼
}
實現了優雅停止功能的序列屏障
- 在修改標識狀態為停止的halt方法中,消費者線程可能由於等待生產者繼續生產而處於阻塞狀態(例如BlockingWaitStrategy),
所以還需要通過消費者維護的序列屏障SequenceBarrier的alert方法來嘗試著喚醒消費者。
/**
* 序列柵欄(仿Disruptor.SequenceBarrier)
* */
public class MySequenceBarrier {
private final MyProducerSequencer myProducerSequencer;
private final MySequence currentProducerSequence;
private volatile boolean alerted = false;
private final MyWaitStrategy myWaitStrategy;
private final MySequence[] dependentSequencesList;
public MySequenceBarrier(MyProducerSequencer myProducerSequencer, MySequence currentProducerSequence,
MyWaitStrategy myWaitStrategy, MySequence[] dependentSequencesList) {
this.myProducerSequencer = myProducerSequencer;
this.currentProducerSequence = currentProducerSequence;
this.myWaitStrategy = myWaitStrategy;
if(dependentSequencesList.length != 0) {
this.dependentSequencesList = dependentSequencesList;
}else{
// 如果傳入的上游依賴序列為空,則生產者序列號作為兜底的依賴
this.dependentSequencesList = new MySequence[]{currentProducerSequence};
}
}
/**
* 獲得可用的消費者下標(disruptor中的waitFor)
* */
public long getAvailableConsumeSequence(long currentConsumeSequence) throws InterruptedException, MyAlertException {
// 每次都檢查下是否有被喚醒,被喚醒則會拋出MyAlertException代表當前消費者要終止運行了
checkAlert();
long availableSequence = this.myWaitStrategy.waitFor(currentConsumeSequence,currentProducerSequence,dependentSequencesList,this);
if (availableSequence < currentConsumeSequence) {
return availableSequence;
}
// 多線程生產者中,需要進一步約束(於v4版本新增)
return myProducerSequencer.getHighestPublishedSequence(currentConsumeSequence,availableSequence);
}
/**
* 喚醒可能處於阻塞態的消費者
* */
public void alert() {
this.alerted = true;
this.myWaitStrategy.signalWhenBlocking();
}
/**
* 重新啟動時,清除標記
*/
public void clearAlert() {
this.alerted = false;
}
/**
* 檢查當前消費者的被喚醒狀態
* */
public void checkAlert() throws MyAlertException {
if (alerted) {
throw MyAlertException.INSTANCE;
}
}
}
由disruptor對外暴露的halt方法,停止當前所有消費者線程
- disruptor類提供了一個halt方法,其基於組件提供的halt機制將所有註冊的消費者線程全部關閉。
- consumerInfo抽象了單線程/多線程消費者,其子類的halt方法內部會調用對應消費者的halt方法將對應消費者終止。
/**
* disruptor dsl(仿Disruptor.Disruptor)
* */
public class MyDisruptor<T> {
private final MyRingBuffer<T> ringBuffer;
private final Executor executor;
private final MyConsumerRepository<T> consumerRepository = new MyConsumerRepository<>();
private final AtomicBoolean started = new AtomicBoolean(false);
/**
* 啟動所有已註冊的消費者
* */
public void start(){
// cas設置啟動標識,避免重覆啟動
if (!started.compareAndSet(false, true)) {
throw new IllegalStateException("Disruptor只能啟動一次");
}
// 遍歷所有的消費者,挨個start啟動
this.consumerRepository.getConsumerInfos().forEach(
item->item.start(this.executor)
);
}
/**
* 停止註冊的所有消費者
* */
public void halt() {
// 遍歷消費者信息列表,挨個調用halt方法終止
for (final MyConsumerInfo consumerInfo : this.consumerRepository.getConsumerInfos()) {
consumerInfo.halt();
}
}
// 註意:省略了無關代碼
}
優雅停止消費者線程
- 目前為止,已經實現了disruptor的halt方法,可以從外部控制消費者線程的啟動和終止了。但還存在一個關鍵問題沒有解決:如何保證消費者線程halt停止時,不會存在還未消費完成的事件?
- disruptor是一個記憶體隊列,關閉時如果消費者沒有把已經在ringBuffer中的事件消費掉,則相當於丟消息了。這個問題在某些場景下是致命的,無法接受的。
- disruptor為此提供了一個shutdown方法,用於真正優雅的停止所有消費者,shutdown方法可以檢查所有消費者的消費狀態,直到所有消費者都把生產的事件消費完後才調用halt方法終止消費者線程。
可以令用戶在不丟事件的情況下,實現真正的優雅停止。
disruptor的shutdown方法實現
- 在disruptor提供的dsl風格api中,通過updateGatingSequencesForNextInChain方法將不處於消費鏈尾部的消費者序列從生產者中剔除出去進行了優化。
同時也對這些消費者(ConsumeInfo)進行了是否處於消費者隊尾的進行了標記(endOfChain) - shutdown方法內通過忙迴圈不斷的通過hasBacklog方法檢查是否有消費鏈尾部的(最慢的)消費者其進度慢於生產者。
/**
* disruptor dsl(仿Disruptor.Disruptor)
* */
public class MyDisruptor<T> {
private final MyRingBuffer<T> ringBuffer;
private final Executor executor;
private final MyConsumerRepository<T> consumerRepository = new MyConsumerRepository<>();
private final AtomicBoolean started = new AtomicBoolean(false);
public MyDisruptor(
final MyEventFactory<T> eventProducer,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final MyWaitStrategy myWaitStrategy) {
this.ringBuffer = MyRingBuffer.create(producerType,eventProducer,ringBufferSize,myWaitStrategy);
this.executor = executor;
}
/**
* 註冊單線程消費者 (無上游依賴消費者,僅依賴生產者序列)
* */
@SafeVarargs
public final MyEventHandlerGroup<T> handleEventsWith(final MyEventHandler<T>... myEventHandlers){
return createEventProcessors(new MySequence[0], myEventHandlers);
}
/**
* 註冊單線程消費者 (有上游依賴消費者,僅依賴生產者序列)
* @param barrierSequences 依賴的序列屏障
* @param myEventHandlers 用戶自定義的事件消費者集合
* */
public MyEventHandlerGroup<T> createEventProcessors(
final MySequence[] barrierSequences,
final MyEventHandler<T>[] myEventHandlers) {
final MySequence[] processorSequences = new MySequence[myEventHandlers.length];
final MySequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
int i=0;
for(MyEventHandler<T> myEventConsumer : myEventHandlers){
final MyBatchEventProcessor<T> batchEventProcessor =
new MyBatchEventProcessor<>(ringBuffer, myEventConsumer, barrier);
processorSequences[i] = batchEventProcessor.getCurrentConsumeSequence();
i++;
// consumer對象都維護起來,便於後續start時啟動
consumerRepository.add(batchEventProcessor);
}
// 更新當前生產者註冊的消費者序列
updateGatingSequencesForNextInChain(barrierSequences,processorSequences);
return new MyEventHandlerGroup<>(this,this.consumerRepository,processorSequences);
}
/**
* 註冊多線程消費者 (無上游依賴消費者,僅依賴生產者序列)
* */
@SafeVarargs
public final MyEventHandlerGroup<T> handleEventsWithWorkerPool(final MyWorkHandler<T>... myWorkHandlers) {
return createWorkerPool(new MySequence[0], myWorkHandlers);
}
/**
* 註冊多線程消費者 (有上游依賴消費者,僅依賴生產者序列)
* @param barrierSequences 依賴的序列屏障
* @param myWorkHandlers 用戶自定義的事件消費者集合
* */
public MyEventHandlerGroup<T> createWorkerPool(
final MySequence[] barrierSequences, final MyWorkHandler<T>[] myWorkHandlers) {
final MySequenceBarrier sequenceBarrier = ringBuffer.newBarrier(barrierSequences);
final MyWorkerPool<T> workerPool = new MyWorkerPool<>(ringBuffer, sequenceBarrier, myWorkHandlers);
// consumer都保存起來,便於start統一的啟動或者halt、shutdown統一的停止
consumerRepository.add(workerPool);
final MySequence[] workerSequences = workerPool.getCurrentWorkerSequences();
updateGatingSequencesForNextInChain(barrierSequences, workerSequences);
return new MyEventHandlerGroup<>(this, consumerRepository,workerSequences);
}
private void updateGatingSequencesForNextInChain(final MySequence[] barrierSequences, final MySequence[] processorSequences) {
if (processorSequences.length != 0) {
// 這是一個優化操作:
// 由於新的消費者通過ringBuffer.newBarrier(barrierSequences),已經是依賴於之前ringBuffer中已有的消費者序列
// 消費者即EventProcessor內部已經設置好了老的barrierSequences為依賴,因此可以將ringBuffer中已有的消費者序列去掉
// 只需要保存,依賴當前消費者鏈條最末端的序列即可(也就是最慢的序列),這樣生產者可以更快的遍歷註冊的消費者序列
for(MySequence sequence : barrierSequences){
ringBuffer.removeConsumerSequence(sequence);
}
for(MySequence sequence : processorSequences){
// 新設置的就是當前消費者鏈條最末端的序列
ringBuffer.addConsumerSequence(sequence);
}
// 將被剔除的序列的狀態標記為其不屬於消費者依賴鏈尾部(用於shutdown優雅停止)
consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences);
}
}
/**
* 啟動所有已註冊的消費者
* */
public void start(){
// cas設置啟動標識,避免重覆啟動
if (!started.compareAndSet(false, true)) {
throw new IllegalStateException("Disruptor只能啟動一次");
}
// 遍歷所有的消費者,挨個start啟動
this.consumerRepository.getConsumerInfos().forEach(
item->item.start(this.executor)
);
}
/**
* 停止註冊的所有消費者
* */
public void halt() {
// 遍歷消費者信息列表,挨個調用halt方法終止
for (final MyConsumerInfo consumerInfo : this.consumerRepository.getConsumerInfos()) {
consumerInfo.halt();
}
}
/**
* 等到所有的消費者把已生產的事件全部消費完成後,再halt停止所有消費者線程
* */
public void shutdown(long timeout, TimeUnit timeUnit){
final long timeOutAt = System.currentTimeMillis() + timeUnit.toMillis(timeout);
// 無限迴圈,直到所有已生產的事件全部消費完成
while (hasBacklog()) {
if (timeout >= 0 && System.currentTimeMillis() > timeOutAt) {
throw new RuntimeException("disruptor shutdown操作,等待超時");
}
// 忙等待
}
// hasBacklog為false,跳出了迴圈
// 說明已生產的事件全部消費完成了,此時可以安全的優雅停止所有消費者線程了,
halt();
}
/**
* 判斷當前消費者是否還有未消費完的事件
*/
private boolean hasBacklog() {
final long cursor = ringBuffer.getCurrentProducerSequence().get();
// 獲得所有的處於最尾端的消費者序列(最尾端的是最慢的,所以是準確的)
for (final MySequence consumer : consumerRepository.getLastSequenceInChain()) {
if (cursor > consumer.get()) {
// 如果任意一個消費者序列號小於當前生產者序列,說明存在未消費完的事件,返回true
return true;
}
}
// 所有最尾端的消費者的序列號都和生產者的序列號相等
// 說明所有的消費者截止當前都已經消費完了全部的已生產的事件,返回false
return false;
}
/**
* 獲得當親Disruptor的ringBuffer
* */
public MyRingBuffer<T> getRingBuffer() {
return ringBuffer;
}
}
/**
* 維護當前disruptor的所有消費者對象信息的倉庫(仿Disruptor.ConsumerRepository)
*/
public class MyConsumerRepository<T> {
private final ArrayList<MyConsumerInfo> consumerInfos = new ArrayList<>();
/**
* 不重寫Sequence的hashCode,equals,因為比對的就是原始對象是否相等
* */
private final Map<MySequence, MyConsumerInfo> eventProcessorInfoBySequence = new IdentityHashMap<>();
public ArrayList<MyConsumerInfo> getConsumerInfos() {
return consumerInfos;
}
public void add(final MyEventProcessor processor) {
final MyEventProcessorInfo<T> consumerInfo = new MyEventProcessorInfo<>(processor);
eventProcessorInfoBySequence.put(processor.getCurrentConsumeSequence(),consumerInfo);
consumerInfos.add(consumerInfo);
}
public void add(final MyWorkerPool<T> workerPool) {
final MyWorkerPoolInfo<T> workerPoolInfo = new MyWorkerPoolInfo<>(workerPool);
for (MySequence sequence : workerPool.getCurrentWorkerSequences()) {
eventProcessorInfoBySequence.put(sequence, workerPoolInfo);
}
consumerInfos.add(workerPoolInfo);
}
/**
* 找到所有還在運行的、處於尾端的消費者
* */
public List<MySequence> getLastSequenceInChain() {
List<MySequence> lastSequenceList = new ArrayList<>();
for (MyConsumerInfo consumerInfo : consumerInfos) {
// 找到所有還在運行的、處於尾端的消費者
if (consumerInfo.isRunning() && consumerInfo.isEndOfChain()) {
final MySequence[] sequences = consumerInfo.getSequences();
// 將其消費者序列號全部放進lastSequenceList
Collections.addAll(lastSequenceList, sequences);
}
}
return lastSequenceList;
}
public void unMarkEventProcessorsAsEndOfChain(final MySequence... barrierEventProcessors) {
for (MySequence barrierEventProcessor : barrierEventProcessors) {
eventProcessorInfoBySequence.get(barrierEventProcessor).markAsUsedInBarrier();
}
}
}
ConsumerInfo及其子類實現
/**
* 消費者信息 (仿Disruptor.ConsumerInfo)
* */
public interface MyConsumerInfo {
/**
* 通過executor啟動當前消費者
* @param executor 啟動器
* */
void start(Executor executor);
/**
* 停止當前消費者
* */
void halt();
/**
* 是否是最尾端的消費者
* */
boolean isEndOfChain();
/**
* 將當前消費者標記為不是最尾端消費者
* */
void markAsUsedInBarrier();
/**
* 當前消費者是否還在運行
* */
boolean isRunning();
/**
* 獲得消費者的序列號(多線程消費者由多個序列號對象)
* */
MySequence[] getSequences();
}
/**
* 單線程事件處理器信息(仿Disruptor.EventProcessorInfo)
* */
public class MyEventProcessorInfo<T> implements MyConsumerInfo {
private final MyEventProcessor myEventProcessor;
/**
* 預設是最尾端的消費者
* */
private boolean endOfChain = true;
public MyEventProcessorInfo(MyEventProcessor myEventProcessor) {
this.myEventProcessor = myEventProcessor;
}
@Override
public void start(Executor executor) {
executor.execute(myEventProcessor);
}
@Override
public void halt() {
this.myEventProcessor.halt();
}
@Override
public boolean isEndOfChain() {
return endOfChain;
}
@Override
public void markAsUsedInBarrier() {
this.endOfChain = false;
}
@Override
public boolean isRunning() {
return this.myEventProcessor.isRunning();
}
@Override
public MySequence[] getSequences() {
return new MySequence[]{this.myEventProcessor.getCurrentConsumeSequence()};
}
}
/**
* 多線程消費者信息(仿Disruptor.WorkerPoolInfo)
* */
public class MyWorkerPoolInfo<T> implements MyConsumerInfo {
private final MyWorkerPool<T> workerPool;
/**
* 預設是最尾端的消費者
* */
private boolean endOfChain = true;
public MyWorkerPoolInfo(MyWorkerPool<T> workerPool) {
this.workerPool = workerPool;
}
@Override
public void start(Executor executor) {
workerPool.start(executor);
}
@Override
public void halt() {
this.workerPool.halt();
}
@Override
public boolean isEndOfChain() {
return endOfChain;
}
@Override
public void markAsUsedInBarrier() {
this.endOfChain = true;
}
@Override
public boolean isRunning() {
return this.workerPool.isRunning();
}
@Override
public MySequence[] getSequences() {
return this.workerPool.getCurrentWorkerSequences();
}
}
- 至此,v6版本的MyDisruptor就完整的實現了消費者的優雅停止功能。生產者線程不再生產後便可以通過Disruptor提供的shutdown方法安全的、優雅的關閉所有的消費者。
- 對比上個版本,可以看到disruptor為了實現優雅停止這一功能新增了很多的方法和邏輯,使得整體代碼變得複雜起來而不易理解,所以MyDisruptor才將這一功能推遲到最後才實現。
生產者中的消費者序列集合由ArrayList優化為數組
截止v5版本的MyDisruptor,是通過ArrayList線性表來存儲生產者序列器(ProducerSequencer)中所註冊的消費者序列集合的。而disruptor中卻是直接使用數組來保存的,這是為什麼呢?
- disruptor中生產者序列器維護的消費者序列集合是會動態添加和刪除的,早期版本的MyDisruptor直接使用ArrayList,目的是避免編寫額外的代碼對數組進行擴容,令代碼更加的簡單易懂。
- 雖然ArrayList是線性表結構,基於數組做了一個簡單的封裝,但是在訪問數組中元素時依然不如"array[index]"直接訪問的方式效率高。
原因在於ArrayList的get方法中,多了一個rangeCheck判斷;而ArrayList的迭代器中則更是包括了對併發版本號驗證等額外邏輯。
存在額外邏輯的ArrayList訪問內部元素的性能肯定是不如裸數組的。 - 在絕大多數的場景下,裸數組和ArrayList這一點微小的性能差異是完全可以忽略的。但disruptor中的生產者會不斷的通過getMinimumSequence方法遍歷維護的消費者序列。因此略微捨棄一些可讀性,換來性能上的小提升是值得的。
生產者由ArrayList改為數組實現(多線程生產者中實現原理也是一樣的)
/**
* 單線程生產者序列器(仿Disruptor.SingleProducerSequencer)
*
* 因為是單線程式列器,因此在設計上就是線程不安全的
* */
public class MySingleProducerSequencer implements MyProducerSequencer{
private static final AtomicReferenceFieldUpdater<MySingleProducerSequencer, MySequence[]> SEQUENCE_UPDATER =
AtomicReferenceFieldUpdater.newUpdater(MySingleProducerSequencer.class, MySequence[].class, "gatingConsumerSequences");
@Override
public void addGatingConsumerSequence(MySequence newGatingConsumerSequence){
MySequenceGroups.addSequences(this,SEQUENCE_UPDATER,this.currentProducerSequence,newGatingConsumerSequence);
}
@Override
public void addGatingConsumerSequenceList(MySequence... newGatingConsumerSequences){
MySequenceGroups.addSequences(this,SEQUENCE_UPDATER,this.currentProducerSequence,newGatingConsumerSequences);
}
@Override
public void removeConsumerSequence(MySequence sequenceNeedRemove) {
MySequenceGroups.removeSequence(this,SEQUENCE_UPDATER,sequenceNeedRemove);
}
// 註意:省略了無關的代碼
}
/**
* 更改Sequence數組工具類(仿Disruptor.SequenceGroups)
* 註意:實現中cas的插入/刪除機制在MyDisruptor中是不必要的,因為MyDisruptor不支持在運行時動態的註冊新消費者(disruptor支持,但是有一些額外的複雜度)
* 只是為了和Disruptor的實現保持一致,可以更好的說明實現原理才這樣做的,本質上只需要支持sequence數組擴容/縮容即可
* */
public class MySequenceGroups {
/**
* 將新的需要註冊的序列集合加入到holder對象的對應sequence數組中(sequencesToAdd集合)
* */
public static <T> void addSequences(
final T holder,
final AtomicReferenceFieldUpdater<T, MySequence[]> updater,
final MySequence currentProducerSequence,
final MySequence... sequencesToAdd) {
long cursorSequence;
MySequence[] updatedSequences;
MySequence[] currentSequences;
do {
// 獲得數據持有者當前的數組引用
currentSequences = updater.get(holder);
// 將原數組中的數據複製到新的數組中
updatedSequences = Arrays.copyOf(currentSequences, currentSequences.length + sequencesToAdd.length);
cursorSequence = currentProducerSequence.get();
int index = currentSequences.length;
// 每個新添加的sequence值都以當前生產者的序列為準
for (MySequence sequence : sequencesToAdd) {
sequence.set(cursorSequence);
// 新註冊sequence放入數組中
updatedSequences[index++] = sequence;
}
// cas的將新數組賦值給對象,允許disruptor在運行時併發的註冊新的消費者sequence集合
// 只有cas賦值成功才會返回,失敗的話會重新獲取最新的currentSequences,重新構建、合併新的updatedSequences數組
} while (!updater.compareAndSet(holder, currentSequences, updatedSequences));
// 新註冊的消費者序列,再以當前生產者序列為準做一次最終修正
cursorSequence = currentProducerSequence.get();
for (MySequence sequence : sequencesToAdd) {
sequence.set(cursorSequence);
}
}
/**
* 從holder的sequence數組中刪除掉一個sequence
* */
public static <T> void removeSequence(
final T holder,
final AtomicReferenceFieldUpdater<T, MySequence[]> sequenceUpdater,
final MySequence sequenceNeedRemove) {
int numToRemove;
MySequence[] oldSequences;
MySequence[] newSequences;
do {
// 獲得數據持有者當前的數組引用
oldSequences = sequenceUpdater.get(holder);
// 獲得需要從數組中刪除的sequence個數
numToRemove = countMatching(oldSequences, sequenceNeedRemove);
if (0 == numToRemove) {
// 沒找到需要刪除的Sequence,直接返回
return;
}
final int oldSize = oldSequences.length;
// 構造新的sequence數組
newSequences = new MySequence[oldSize - numToRemove];
for (int i = 0, pos = 0; i < oldSize; i++) {
// 將原數組中的sequence複製到新數組中
final MySequence testSequence = oldSequences[i];
if (sequenceNeedRemove != testSequence) {
// 只複製不需要刪除的數據
newSequences[pos++] = testSequence;
}
}
} while (!sequenceUpdater.compareAndSet(holder, oldSequences, newSequences));
}
private static int countMatching(MySequence[] values, final MySequence toMatch) {
int numToRemove = 0;
for (MySequence value : values) {
if (value == toMatch) {
// 比對Sequence引用,如果和toMatch相同,則需要刪除
numToRemove++;
}
}
return numToRemove;
}
}
總結
- 作為disruptor學習系列的最後一篇博客,v6版本對MyDisruptor存在的一些關鍵的性能問題做了最後的優化。最終的v6版本MyDisruptor除了少部分不常用的功能沒實現外,整體已經和Disruptor相差無幾了。
- 縱觀v1到v6版本迭代的全過程,MyDisruptor從最初簡單的只支持單線程/單消費者開始,不斷的豐富功能、優化性能,代碼也逐漸膨脹,變得越來越複雜。
但只要按照每個版本都是為了實現一至多個完整功能模塊的角度出發,有機的切分這些代碼,也不會覺得難以理解。 - 站在設計者的角度去實現MyDisruptor的過程中,我學到了很多東西,也逐漸地理解了disruptor在一些地方為什麼那樣實現的原因。
這種臨摹、自己動手實現的方式,可以大幅降低對disruptor這樣一個實現巧妙、細節頗多的項目的學習曲線,幫助我們更好的理解disruptor的工作原理以及背後的設計思想。
disruptor無論在整體設計還是最終代碼實現上都有很多值得反覆琢磨和學習的細節,希望這個系列博客能幫助到對disruptor感興趣的小伙伴。
本篇博客的完整代碼在我的github上:https://github.com/1399852153/MyDisruptor 分支:feature/lab6


