
分享嘉賓:劉冰冰 亞馬遜雲科技 編輯整理:張了了 聚水潭 出品平臺:DataFunTalk **導讀:**資料庫經過了幾十年的發展,目前已經是一項非常成熟的技術,然而隨著當今互聯網的極速增長,我們進入到雲時代,企業亟需構建現代化的應用,因此資料庫有了更大的挑戰。今天結合當前時代的發展和趨勢,分享未來 ...
分享嘉賓:劉冰冰 亞馬遜雲科技
編輯整理:張了了 聚水潭
出品平臺:DataFunTalk
導讀:資料庫經過了幾十年的發展,目前已經是一項非常成熟的技術,然而隨著當今互聯網的極速增長,我們進入到雲時代,企業亟需構建現代化的應用,因此資料庫有了更大的挑戰。今天結合當前時代的發展和趨勢,分享未來資料庫需要關註的硬核創新。
今天的介紹圍繞以下幾部分展開:
- 趨勢——資料庫自由和創新
- 資料庫硬核創新——雲原生資料庫
- 資料庫硬核創新——雲原生資料庫遷移利器
- 演示——雲原生資料庫遷移利器
- 問答
--
01 趨勢——資料庫自由和創新
1. 數據需求快速擴張

當今社會IT的快速發展,對誕生於20世紀70年代初的資料庫技術提出了更高的要求。
- 在互聯網和IOT設備的推動下,各企業所管理的數據量每5年就會有10倍的增長,數據急劇增長已經成為發展的一個必然結果。
- 同時,隨著微服務技術的產生,在減少“通用型”資料庫需求的同時,增加了實時監控和分析需求,這種方式促進了現代化的應用開發,也增加了數據的產生。
- 從傳統的IT到開發運維的過渡加快了變革速度,使得整體開發周期更短,也推動了數據增長的速度。
2. 數據飛輪
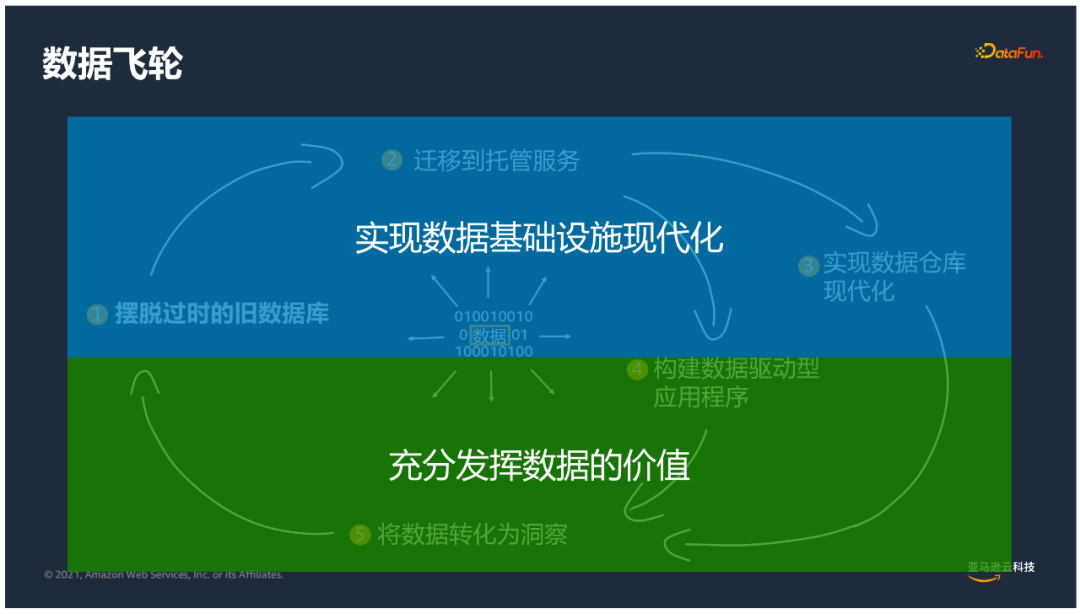
不可否認的是當今時代數據已經成為企業最寶貴的資產,資料庫作為存儲和管理數據的載體,合理利用可以使企業的數據飛輪轉起來,充分發揮數據的價值,使數據轉化為業務洞察來指導企業發展。
資料庫在企業存儲和分析、現代化支撐方面起到了非常重要的作用,因此資料庫需要做出更多創新;擺脫傳統資料庫的使用方式,通過遷移上雲的方式來實現托管服務,然後基於資料庫構建現代化雲資料庫,基於數據驅動的應用,把數據轉化為洞察。
資料庫的現代化過程,對企業也非常重要。數據基礎設施的建設,資料庫的支撐以及數倉的構建可以使企業中的數據充分流轉,發揮出應有的價值。
3. 本地管理資料庫挑戰

很多企業目前還是在自己的IDC數據中心去管理資料庫,會有很多挑戰,主要有以下幾種:
- 安裝資料庫,硬體和軟體安裝;
- 資料庫配置、補丁修複和備份;這些資料庫的工作繁瑣,使得大多數資料庫管理人員無法抽出精力去實踐現代化的方式;
- 集群配置和數據複製保證高可用性;
- 計算和存儲的容量規劃和擴展集群。
很多用戶在使用傳統關係型資料庫,面臨著成本高、license懲罰性許可導致的不方便、管理複雜等問題。
4. 傳統資料庫的缺陷

很多用戶使用傳統的關係型資料庫都會遇到這些挑戰:成本高昂、技術專有化、管理資料庫的學習成本高、管理工作複雜,還會遇到License的限定等問題。
5. 趨勢-利用雲創新掙脫束縛
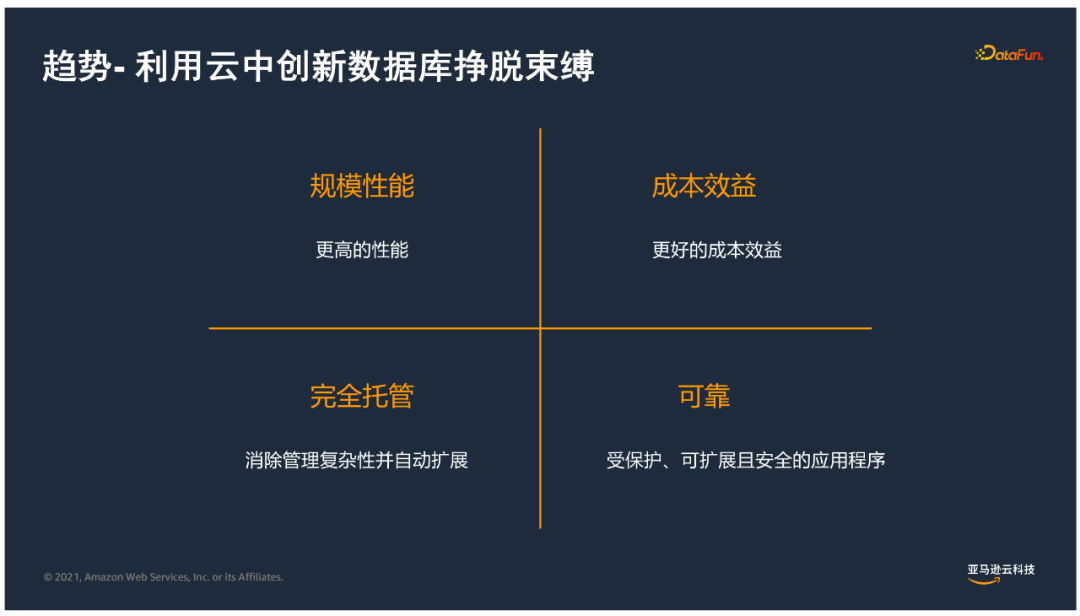
基於以上挑戰,目前越來越多用戶希望利用雲的資源來實現資料庫的創新,包括:
- 規模性能:基於業務擴展實現自由擴展。
- 成本效益:通過按需使用、按需支付來實現成本的節約。
- 完全托管:消除管理複雜性並自動拓展。
- 可靠:擁有受保護、可拓展且安全的應用程式,實現同城、異地災備無縫恢復。
--
02 資料庫硬核創新——雲原生資料庫
1. 對雲原生的理解
雲原生資料庫是一種構建和運行都充分利用雲計算模型優勢的構建資料庫的方法。亞馬遜雲科技VP Adrian Cockcroft提出,雲原生架構充分利用按需交付、全球部署、彈性和更高級別的服務,它們大大提高了開發人員的開發效率、業務敏捷性、可拓展性、可用性,資源利用率和成本節約。
我們把客戶對雲的接受分為了雲好奇、雲親近和雲原生三個階段。
和資料庫相結合,再去理解雲原生,就是利用雲上的創新的技術和架構賦能資料庫,讓資料庫有更好的敏捷性、擴展性、高性能,從而實現全球部署、按需交付和彈性,以及高可用性。
2. 雲原生資料庫 Amazon Aurora
基於以上理解,亞馬遜發佈了業界第一個雲原生資料庫Amazon Aurora,這也是亞馬遜雲科技歷史上用戶數量增速最快的雲服務。它具有如下優勢:
- 媲美高端商業資料庫的速度與可用性
- 媲美開源資料庫的簡單性和成本效益
- 與MySQL及postgreSql全面相容
- 按使用量計費的簡單定價模式
- 適用於所有傳統關係型資料庫應用的場景
- 以完全托管服務形式交付
① Amazon Aurora的特點
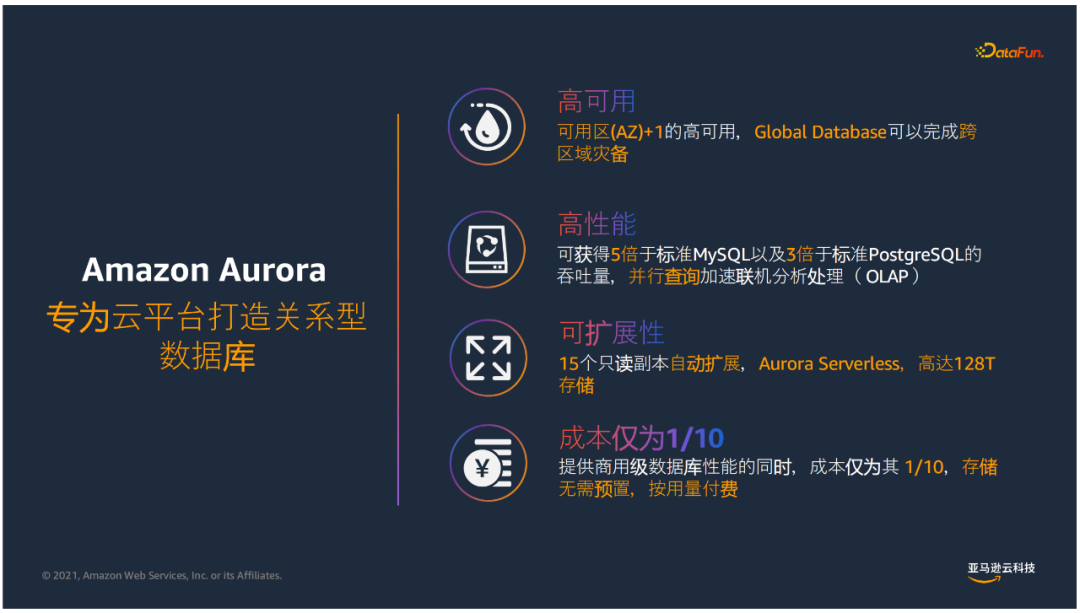
- 高可用
可以實現最多可容忍AZ+1失效的高可用性,設計面向金融級跨3個AZ的資料庫,同時提供了Global Database完成跨區域災備。
- 高性能
可獲得5倍於標準MySQL以及3倍於標準postgreSql的吞吐量,並行查詢加速聯機分析處理。
- 可拓展性
15個只讀副本實現擴展性,Aurora Serverless來實現無伺服器架構按需、自動拓展的資料庫服務,可以實現無業務時自動關閉、按需啟動資料庫;同時擁有128T的存儲。
- 成本低廉
提供商用級資料庫性能的同時,成本僅為傳統商業版資料庫1/10,存儲無需預置,按量付費。
② 設計原則及架構
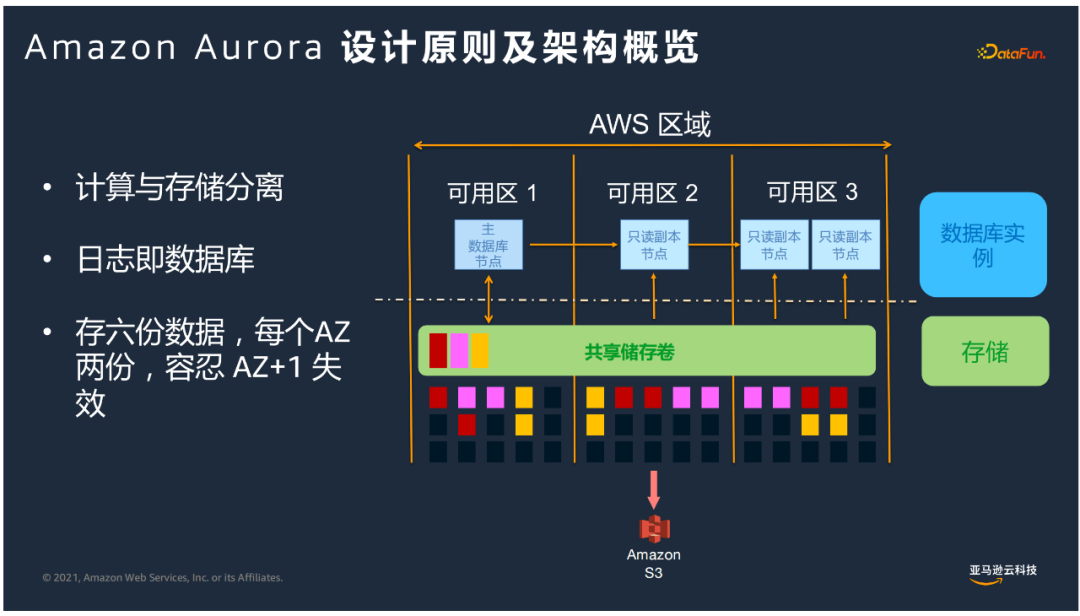
- 計算和存儲分離
基於計算層和存儲層分別進行拓展,計算拓展8-10分鐘。
- 日誌即資料庫
消除了資料庫這端很多臟頁回寫到存儲的動作,變化的日誌流存儲到共用儲存捲來處理。
- 保證了數據的高持久性
每個AZ存兩份數據,即跨三個AZ存儲6個數據副本,做到了保障開箱即用金融級別的高可用性,如果有一個AZ故障,依然可以保證4/6副本,保持可寫的狀態;如果有AZ+1故障,依然有3份副本,不會有數據丟失,可以通過幸存的3副本恢復損壞的副本來恢覆寫能力;如果面臨整個區域故障,Global Database提供了跨區域的災備能力。
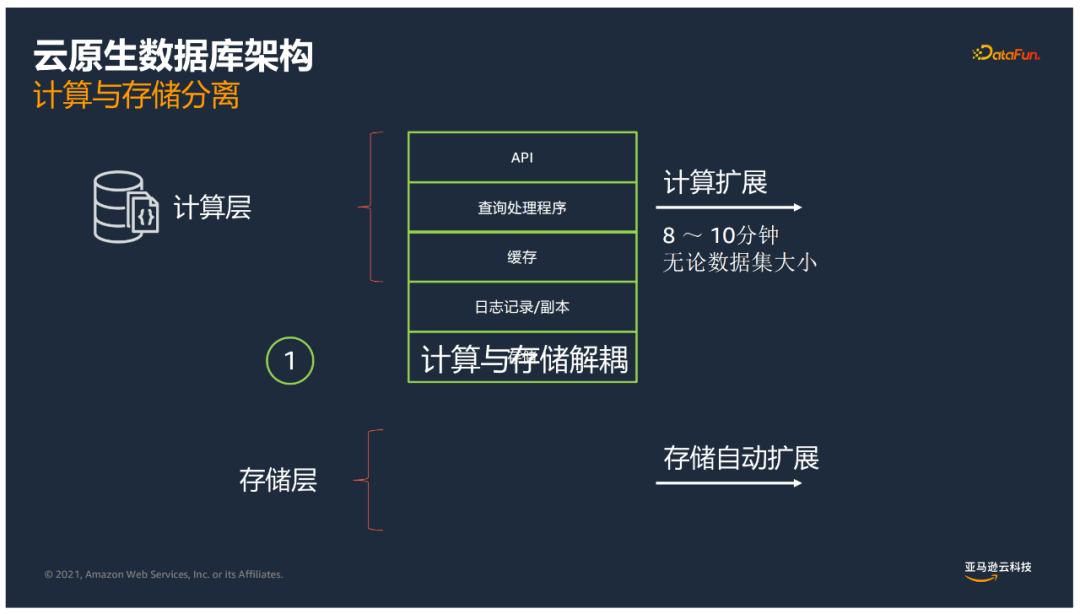
我們把很多資料庫計算的動作下推到智能的存儲引擎。計算與存儲解耦,計算層和存儲層可根據各自需求進行擴展。無論數據量多大,計算擴展速度可以很快。
③ Amazon Aurora 提供極致可用性

Aurora實現了開箱即用金融級的高可用性。如果一個數據中心宕掉了,再加上另一個AZ里的一份數據宕掉了,資料庫仍然可以訪問。因為在數據層面,是把數據打散,10GB為一個單元,每個數據有6份拷貝,每個AZ是兩份,這樣可以保證面臨AZ+1故障時,仍然有3份拷貝可讀。同時,我們還通過Global Database提供了跨區域的災備。
④ 客戶案例

九州通B2B系統的業務特點是讀多寫少,之前遇到過以下挑戰:
- 受業務影響經常會出現波峰波谷落差較大的情況
- 自建MySQL主從庫數據複製延遲超過1秒,讀寫分離效果不好,主庫壓力大
- 資料庫管理員需要預先配置資源來應對高峰,高峰過後又會產生成本和資源浪費的情況
使用了Aurora之後明顯有了提升,主要體現在以下幾方面:
- 整體資料庫性能提升了5倍,TCO降低了50%,實現了跨可用區部署、負載均衡、自動故障轉移、精細監控、按需自動伸縮等。
- 輕鬆實現了資料庫的讀寫分離及按需拓展,Auto Scaling功能實現只讀副本按需拓展,滿足業務需求的同時節省伺服器成本。
- 主從節點間的延遲保持在20毫秒左右,可以把更多查詢操作放在從庫執行。
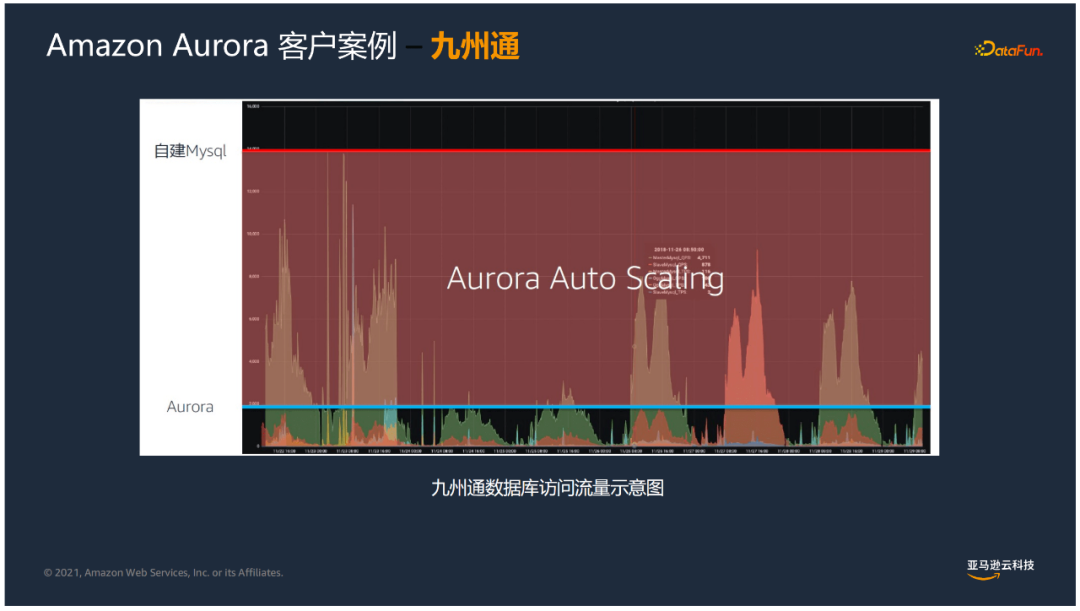
上圖中可以看到,原來的自建Mysql需要把資源開的很高,來應付業務高峰時的負載。而Aurora按需而動,在高峰來臨時擴展讀副本,負載下降後再回縮讀副本,有非常好的伸縮性。
⑤ Aurora Serverless

Aurora Serverless是Aurora提供的無服務架構,擴展性有了更高提升,可以實現以下功能:
- 按需啟動資料庫,無業務時自動關閉
- 自動拓展、無需管理資料庫實例
- 按使用的資料庫資源以秒計費
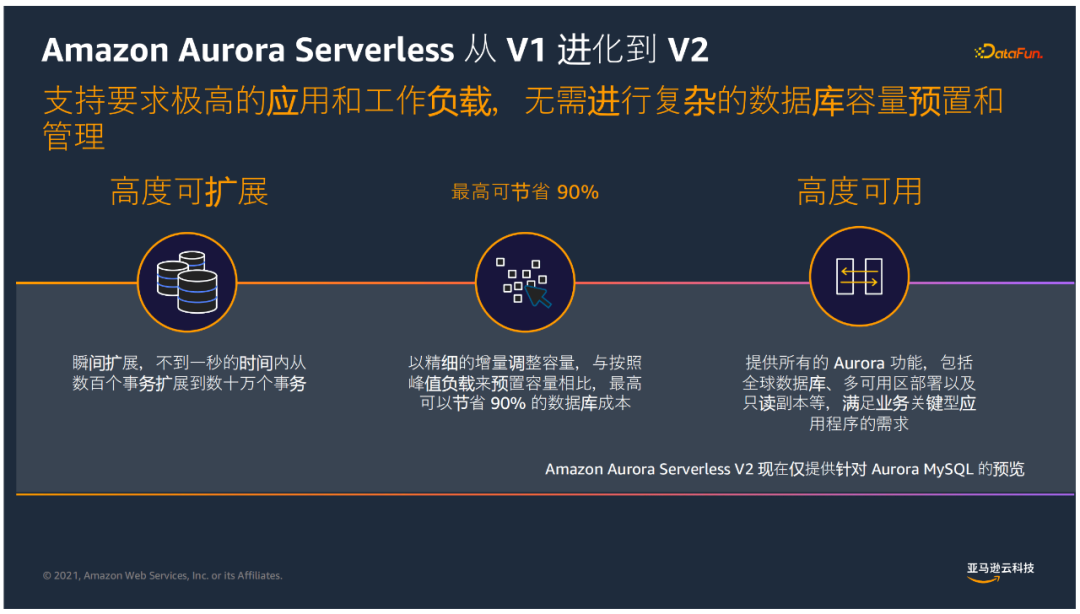
- 目前Serverless 已經升級到了V2,提供了預覽版本,相比V1,有更好的拓展性,不到1秒的時間內可以從數百個事務拓展到數十萬個事務,同時基於ACU的拓展,方式更精細化,比傳統的預置引擎的方式有更高成本的節省;同時提供所有的Aurora功能,滿足業務關鍵型應用程式的需求。
⑥ Aurora Global Database
現代化應用的全球部署,需要通過構建資料庫:
- 在發生地區級的中斷時提供災難恢復能力,提升全球業務連續性
- 讓數據更靠近各個地區的用戶,提升用戶訪問體驗
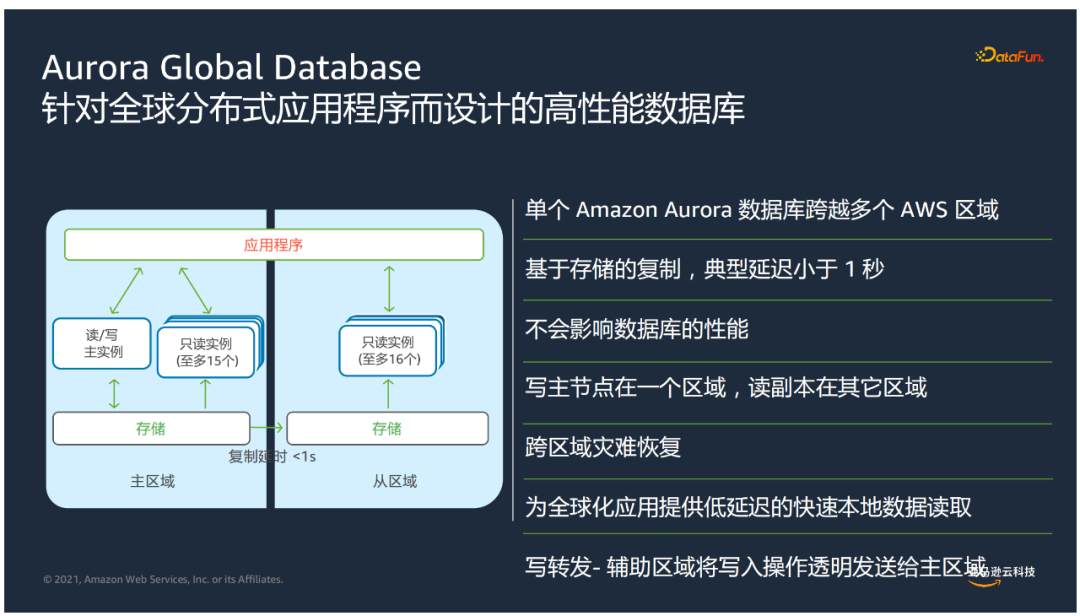
- 在現代化應用中,需要通過構建資料庫實現跨區域的容災,提升全球業務連續性及用戶訪問體驗。Aurora
Global Database是針對全球分散式應用程式而設計的高性能資料庫,有以下特點:
- 單個Aurora資料庫跨越多個AWS區域
- 採用物理複製的方式,典型延遲遠小於1秒,並且不會影響資料庫性能
- 主從節點分佈在不同區域
- 寫轉發+輔助區域將寫入操作透明發送給主區域
- 為全球化應用提供低延遲的快速本地數據讀取

- 虎牙直播資料庫後臺動態信息由Amozon DynamoDB存儲,相對靜態的信息則存儲在Aurora上。
使用了Aurora之後明顯有了提升,主要體現在以下幾方面:
- 性能提升:Aurora能自動擴容,且計算和存儲分離,數據量較大時單獨升級計算實例來確保性能,與MySQL相比,有5倍以上的性能提升。
- 支持故障轉移:異常情況下,只需要10秒左右就能夠自動實現自動故障轉移,終端用戶無感知。
- 本地用戶體驗提升:利用Global Database功能,在AWS亞太區域部署資料庫,併在其他區域建立副本,大大提升了用戶體驗。
--
03 雲原生資料庫遷移利器
遷移對於企業來說是面臨的一個較大挑戰,怎麼無縫實現從傳統的資料庫遷移到雲上?下麵來介紹另一個硬核創新,雲原生資料庫遷移利器。
① 挑戰
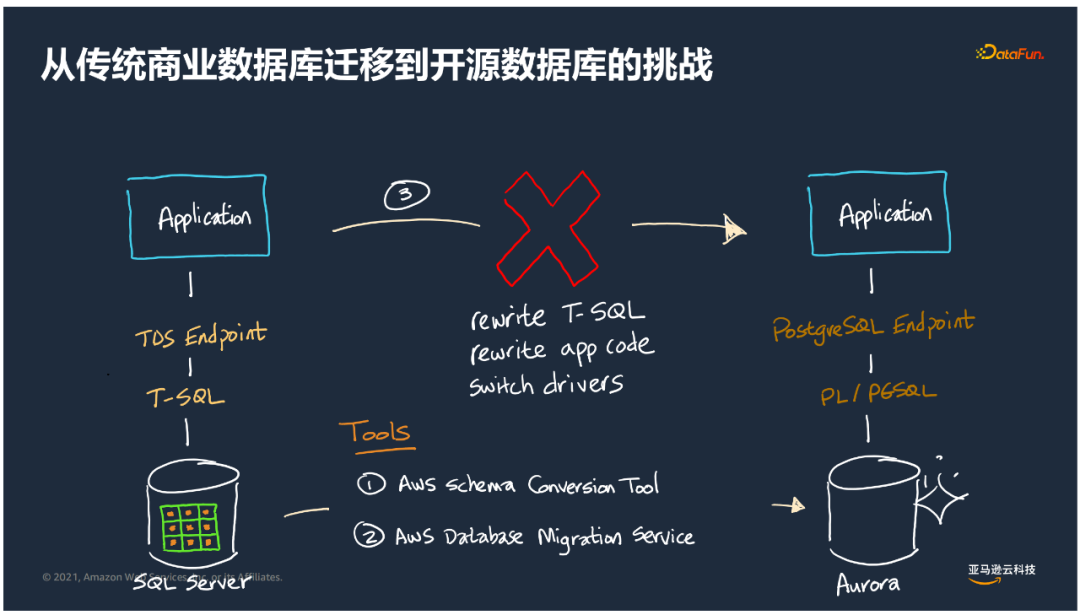
以微軟SQL Server遷移到Aurora PGSQL為例:
- 數據模型的實現可以通過AWS Schema Conversion Tool來實現。
- 數據的遷移可以通過AWS Database Migration Service。
- 而SQL Server應用邏輯、存儲過程、以及前端應用的T-SQL的實現需要花費更多的時間。
② Babelfish for Aurora PostgreSQL
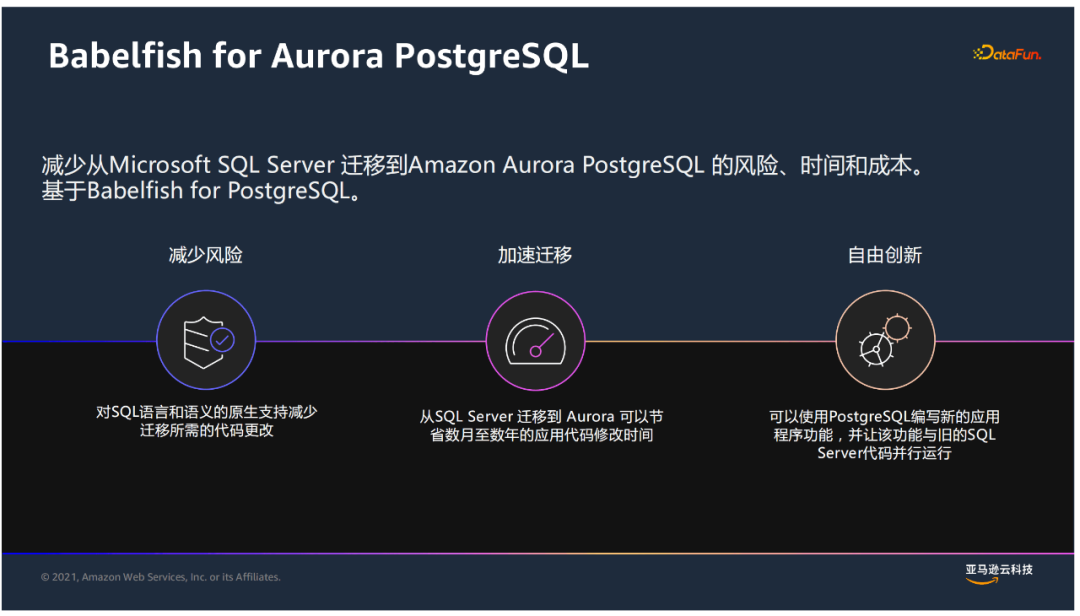
它能夠原生地支持對T-SQL語言的理解,同時支持SQL Server協議訪問,這樣使得遷移時間大大縮短。遷移後,既可以訪問原有的SQLServer代碼,又可以利用PostgreSQL編寫新的功能,並且兩者之間可以進行調用。
我們也已將Babelfish for PostagreSQL項目開源。
③ Babelfish部署模型
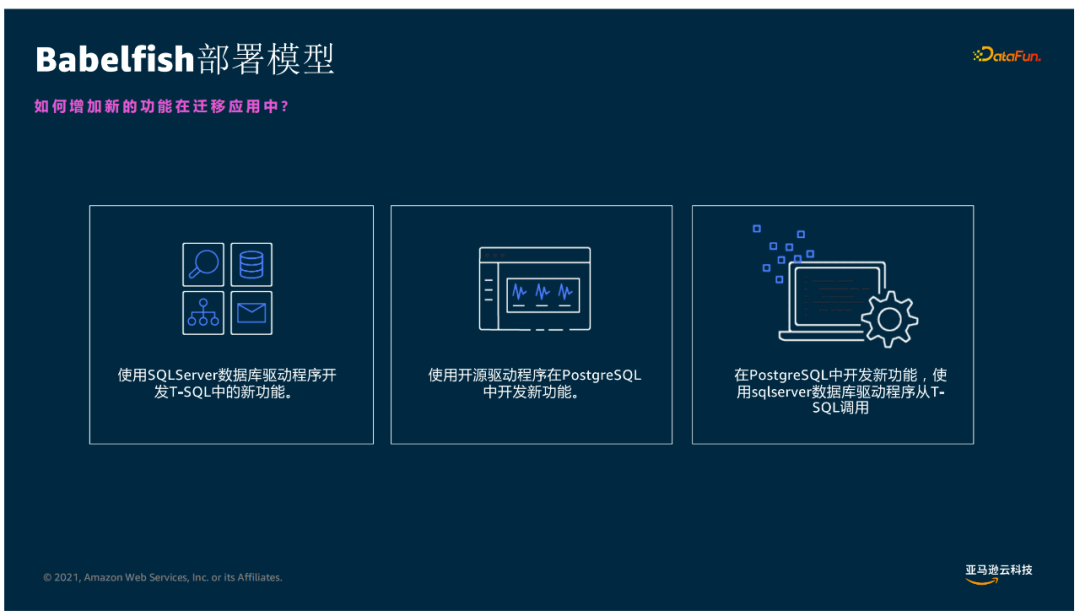
- 可以使用SQLserver資料庫驅動程式開發T-SQL中的功能
- 使用開源驅動程式在Postgresql中開發新功能
- Postgresql和T-SQL兩個引擎的存儲過程和函數可相互無縫調用

- Bebelfish是SQL server遷移加速器,在Aurora Postgresql內置引擎中增加了三個拓展包來實現TDS協議和T-SQL的支持,同時在Aurora PG引擎中增加兩個EndPoint監聽,以達到提供正確的T-SQL執行的目的,底層通過實現1433埠的監聽來支持傳統的SQL server的T-SQL調用和TDS協議,5432埠的監聽來支持傳統的Postgresql的調用。

④ 遷移流程
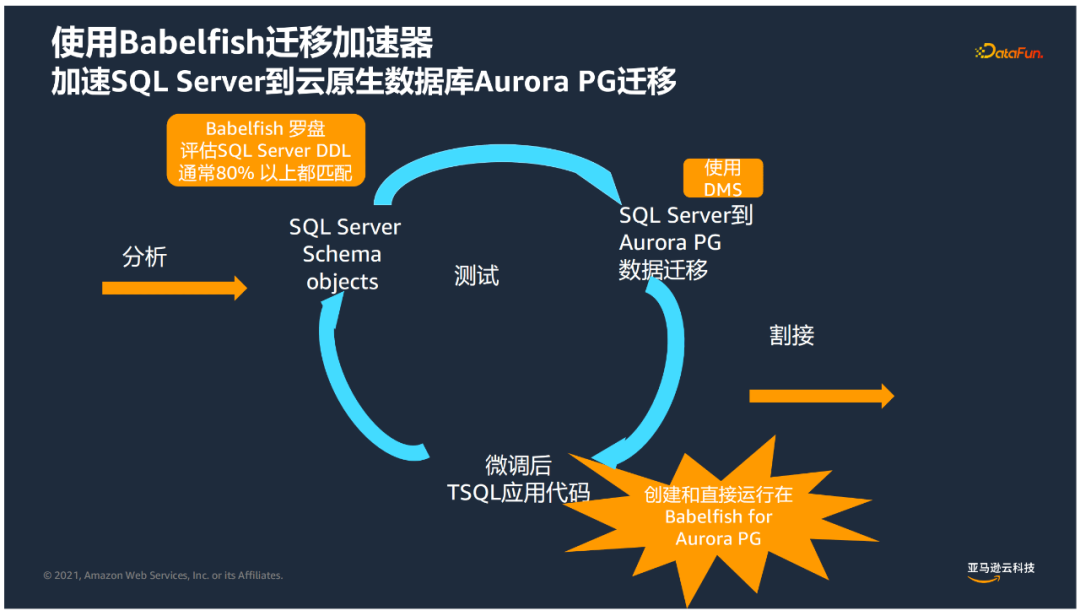
- 首先通過SQL server Management Studio取出對應的DDL;
- 然後使用Babelfish羅盤評估匹配度,目前測試通常SQL Server DDL與Babelfish匹配度高達80%及以上;
- 對於不匹配的部分進行微調,然後直接創建在Bebelfish for Aurora Postgresql進行執行;
- 數據方面通過DMS進行遷移;
- 經過充分測試後,就可以實現將SQL server的應用由SQL server引擎指向Bebelfish for Aurora Postgresql完成最終的遷移。
--
05 問答環節
Q:Aurora後續有開源的計劃嗎?
A:我們目前已經把一些Aurora相關的項目在開源,例如Babelfish for Aurora PostgreSQL , 希望能將亞馬遜雲科技更多技術賦能客戶和開源社區,助力客戶和開源社區持續的技術創新。
Q:Aurora底層的存儲複製使用的技術?
A:Aurora存儲層複製使用Quorum協議實現,把數據塊劃分為10GB為一個單元,每份數據6份副本,將6個副本存儲在3個AZ,為了滿足一致性,需要滿足兩個條件,首先Vr + Vw > V,V=6,Vw=4,Vr=3,Aurora可以實現開箱即用的金融級高可用性 (跨3個AZ,最多可容忍AZ+1故障):Aurora可以容忍任何一個AZ出現故障,不會影響寫服務;任何一個AZ出現故障,以及另外一個AZ中的一個節點出現故障,不會影響讀服務且不會丟失數據。
今天的分享就到這裡,謝謝大家。
分享嘉賓:

本文首發於微信公眾號“DataFunTalk”。


