
概述 beanstalkd 是一個簡單快速的分散式工作隊列系統,協議基於 ASCII 編碼運行在 TCP 上。其最初設計的目的是通過後臺非同步執行耗時任務的方式降低高容量 Web 應用的頁面延時。其具有簡單、輕量、易用等特點,也支持對任務優先順序、延時/超時重發等控制,同時還有眾多語言版本的客戶端支持, ...
概述
beanstalkd 是一個簡單快速的分散式工作隊列系統,協議基於 ASCII 編碼運行在 TCP 上。其最初設計的目的是通過後臺非同步執行耗時任務的方式降低高容量 Web 應用的頁面延時。其具有簡單、輕量、易用等特點,也支持對任務優先順序、延時/超時重發等控制,同時還有眾多語言版本的客戶端支持,這些優點使得它成為各種需要隊列系統場景的一種常見選擇。
beanstalkd 優點
- 如他官網的介紹,simple&fast,使用非常簡單,適合需要引入消息隊列又不想引入 kafka 這類重型的 mq,維護成本低;同時,它的性能非常高,大部分場景下都可以 cover 住。
- 支持持久化
- 支持消息優先順序,topic,延時消息,消息重試等
- 主流語言客戶端都支持,還可以根據 beanstalkd 協議自行實現。
beanstalkd 不足
- 無最大記憶體控制,當業務消息極多時,服務可能會不穩定。
- 官方沒有提供集群故障切換方案(主從或哨兵等),需要自己解決。
beanstalkd 重點概念
- job
任務,隊列中的基本單元,每個 job 都會有 id 和優先順序。有點類似其他消息隊列中的 message 的概念。但 job 有各種狀態,下文介紹生命周期部分會重點介紹。job 存放在 tube 中。
- tube
管道,用來存儲同一類型的 job。有點類似其他消息隊列中的 topic 的概念。beanstalkd 通過 tube 來實現多任務隊列,beanstalkd 中可以有多個管道,每個管道有自己的 producer 和 consumer,管道之間互相不影響。
- producer
job 生產者。通過 put 命令將一個 job 放入到一個 tube 中。
- consumer
job 消費者。通過 reserve 來獲取 job,通過 delete、release、bury 來改變 job 的狀態。
beanstalkd 生命周期
上文介紹到,beanstalkd 中 job 有狀態區分,在整個生命周期中,job 可能有四種狀態:READY, RESERVED, DELAYED, BURIED。只有處於READY狀態的 job 才能被消費。下圖介紹了各狀態之間的流轉情況。
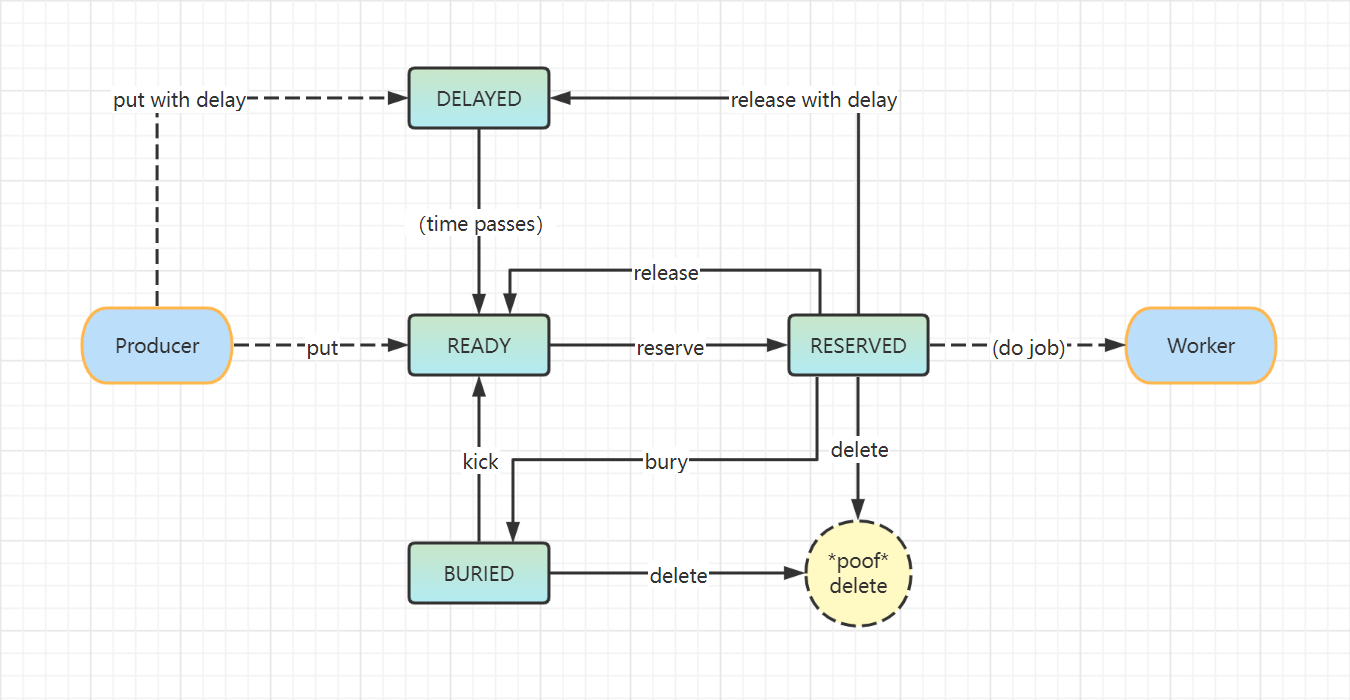
producer 在創建 job 的時候有兩種方式,put 和 put with delay(延時任務)。
如果 producer 使用 put 直接創建一個 job 時,該 job 就處於 READY 狀態,等待 consumer 處理。
如果 producer 使用 put with delay 方式創建 job,該 job 的初始狀態為 DELAYED 狀態,等待延遲時間過後才變更為 READY 狀態。
以上兩種方式創建的 job 都會傳入一個 TTR(超時機制),當 job 處於 RESERVED 狀態時,TTR 開始倒計時,當 TTR 倒計時完,job 狀態還沒有改變,則會認為該 job 處理失敗,會被重新放回到隊列中。
consumer 獲取到(reserve)一個 READY 狀態的 job 之後,該 job 的狀態就會變更為 RESERVED。此時,其他的 consumer 就不能再操作該 job 了。當 consumer 完成該 job 之後,可以選擇 delete,release,或 bury 操作。
- delete ,job 被刪除,從 beanstalkd 中清除,以後也無法再獲取到,生命周期結束。
- release ,可以把該 job 重新變更為 READY 狀態,使得其他的 consumer 可以繼續獲取和執行該 job,也可以使用 release with delay 延時操作,這樣會先進入 DELAYED 狀態,延遲時間到達後再變為 READY。
- bury,可以將 job 休眠,等需要的時候,在將休眠的 job 通過 kick 命令變更回 READY 狀態,也可以通過 delete 直接刪除 BURIED 狀態的 job 。
處於 BURIED 狀態的 job,可以通過 kick 重回 READY 狀態,也可以通過 delete 刪除 job。
為什麼設計這個 BURIED 狀態呢?
一般我們可以用這個狀態來做異常捕獲,例如執行超時或者異常的 job,我們可以將其置為 BURIED 狀態,這樣做有幾個好處:
1.可以便面這些異常的 job 直接被放回隊列重試,影響正常的隊列消費(這些失敗一次的 job,很有可能再次失敗)。如果沒有這個 BURIED 狀態,如果我們要單獨隔離,一般我們會使用一個新的 tube 單獨存放這些異常的 job,使用單獨的 consumer 消費。這樣就不會影響正常的新消息消費。特別是失敗率比較高的時候,會占用很多的正常資源。
2.便於人工排查,上面已經講到,可以將異常的 job 置為 BURIED 狀態,這樣人工排查時重點關註這個狀態就可以了。
beanstalkd 特性
持久化
通過 binlog 將 job 及其狀態記錄到本地文件,當 beanstalkd 重啟時,可以通過讀取 binlog 來恢復之前的 job 狀態。
分散式
在 beanstalkd 的文檔中,其實是支持分散式的,其設計思想和 Memcached 類似,beanstalkd 各個 server 之間並不知道彼此的存在,是通過 client 實現分散式以及根據 tube 名稱去特定的 server 上獲取 job。貼一篇專門討論 beanstalkd 分散式的文章,Beanstalkd的一種分散式方案
任務延時
天然支持延時任務,可以在創建 job 時指定延時時間,也可以當 job 被處理完後才能後,消費者使用 release with delay 將 job 再次放入隊列延時執行。
任務優先順序
producer 生成的 job 可以給他分配優先順序,支持 0 到 2^32 的優先順序,值越小,優先順序越高,預設優先順序為 1024。優先順序高的 job 會被 consumer 優先執行。
超時機制
為了防止某個 consumer 長時間占用 job 但無法處理完成的情況,beanstalkd 的 reserve 操作支持設置 timeout 時間(TTR)。如果 consumer 不能在 TTR 內發送 delete、release 或 bury 命令改變 job 狀態,那麼 beanstalkd 會認為任務處理失敗,會將 job 重新置為 READY 狀態供其他 consumer 消費。
如果消費者已經預知可能無法在 TTR 內完成該 job,則可以發送 touch 命令,使得 beanstalkd 重新計算 TTR。
任務預留
有一個 BURIED 狀態可以作為緩衝,具體特點見上文生命周期中關於 BURIED 狀態的介紹。
安裝及配置
以下以 ubuntu 為例,安轉 beanstalkd:
sudo apt-get update
sudo apt-get install beanstalkd
vi /etc/sysconfig/beanstalkd
# 添加如下內容
BEANSTALKD_BINLOG_DIR=/data/beanstalkd/binlog
可以通過 beanstalkd 命令來運行服務,並且可以添加多種參數。命令的格式如下:
beanstalkd [OPTIONS]
-b DIR wal directory
-f MS fsync at most once every MS milliseconds (use -f0 for "always fsync")
-F never fsync (default)
-l ADDR listen on address (default is 0.0.0.0)
-p PORT listen on port (default is 11300)
-u USER become user and group
-z BYTES set the maximum job size in bytes (default is 65535)
-s BYTES set the size of each wal file (default is 10485760)
(will be rounded up to a multiple of 512 bytes)
-c compact the binlog (default)
-n do not compact the binlog
-v show version information
-V increase verbosity
-h show this help
如下我們啟動一個 beanstalkd 服務,並開啟 binlog:
nohup beanstalkd -l 0.0.0.0 -p 11300 -b /data/beanstalkd/binlog/ &
beanstalkd管理工具
官方推薦的一些管理工具:Tools
筆者常用的管理工具:https://github.com/ptrofimov/beanstalk_console
如果只是簡單的操作和查看 beanstalkd,可以使用 telnet 工具,然後執行 stats,use,put,watch 等:
$ telnet 127.0.0.1 11300
stats
實際應用
beansralkd 有很多語言版本的客戶端實現,官方提供了一些客戶端列表beanstalkd客戶端列表。
如果現有的這些庫不滿足需求,也可以自行實現,參考 beanstalkd協議。
以下以 go 為例,簡單演示下 beanstalkd 常用處理操作。
go get github.com/beanstalkd/go-beanstalk
生產者
向預設的 tube 中投入 job:
id, err := conn.Put([]byte("myjob"), 1, 0, time.Minute)
if err != nil {
panic(err)
}
fmt.Println("job", id)
向指定的 tube 中投入 job:
tube := &beanstalk.Tube{Conn: conn, Name: "mytube"}
id, err := tube.Put([]byte("myjob"), 1, 0, time.Minute)
if err != nil {
panic(err)
}
fmt.Println("job", id)
消費者
消費預設的 tube 中的 job:
id, body, err := conn.Reserve(5 * time.Second)
if err != nil {
panic(err)
}
fmt.Println("job", id)
fmt.Println(string(body))
消費指定的 tube (此處指定多個) 中的 job:
tubeSet := beanstalk.NewTubeSet(conn, "mytube1", "mytube2")
id, body, err := tubeSet.Reserve(10 * time.Hour)
if err != nil {
panic(err)
}
fmt.Println("job", id)
fmt.Println(string(body))
beanstalkd 使用小 tips
- 可以通過指定 tube ,在 put 的時候將 job 放入指定的 tube 中,否則會放入 default 的 tube 中。
- beanstalkd 支持持久化,在啟動時使用
-b參數來開啟binlog,通過binog可以將 job 及其狀態記錄到文件里。當重新使用-b參數重啟 beanstalkd,將讀取binlog來恢復之前的 job 及狀態。

