
從內核角度介紹了經常容易混淆的阻塞與非阻塞,同步與非同步的概念。以這個作為鋪墊,我們通過一個C10K的問題,引出了五種IO模型,隨後在IO多路復用中以技術演進的形式介紹了select,poll,epoll的原理和它們綜合的對比。最後我們介紹了兩種IO線程模型以及netty中的Reactor模型。 ...
從今天開始我們來聊聊Netty的那些事兒,我們都知道Netty是一個高性能非同步事件驅動的網路框架。
它的設計異常優雅簡潔,擴展性高,穩定性強。擁有非常詳細完整的用戶文檔。
同時內置了很多非常有用的模塊基本上做到了開箱即用,用戶只需要編寫短短幾行代碼,就可以快速構建出一個具有高吞吐,低延時,更少的資源消耗,高性能(非必要的記憶體拷貝最小化)等特征的高併發網路應用程式。
本文我們來探討下支持Netty具有高吞吐,低延時特征的基石----netty的網路IO模型。
由Netty的網路IO模型開始,我們來正式揭開本系列Netty源碼解析的序幕:
網路包接收流程
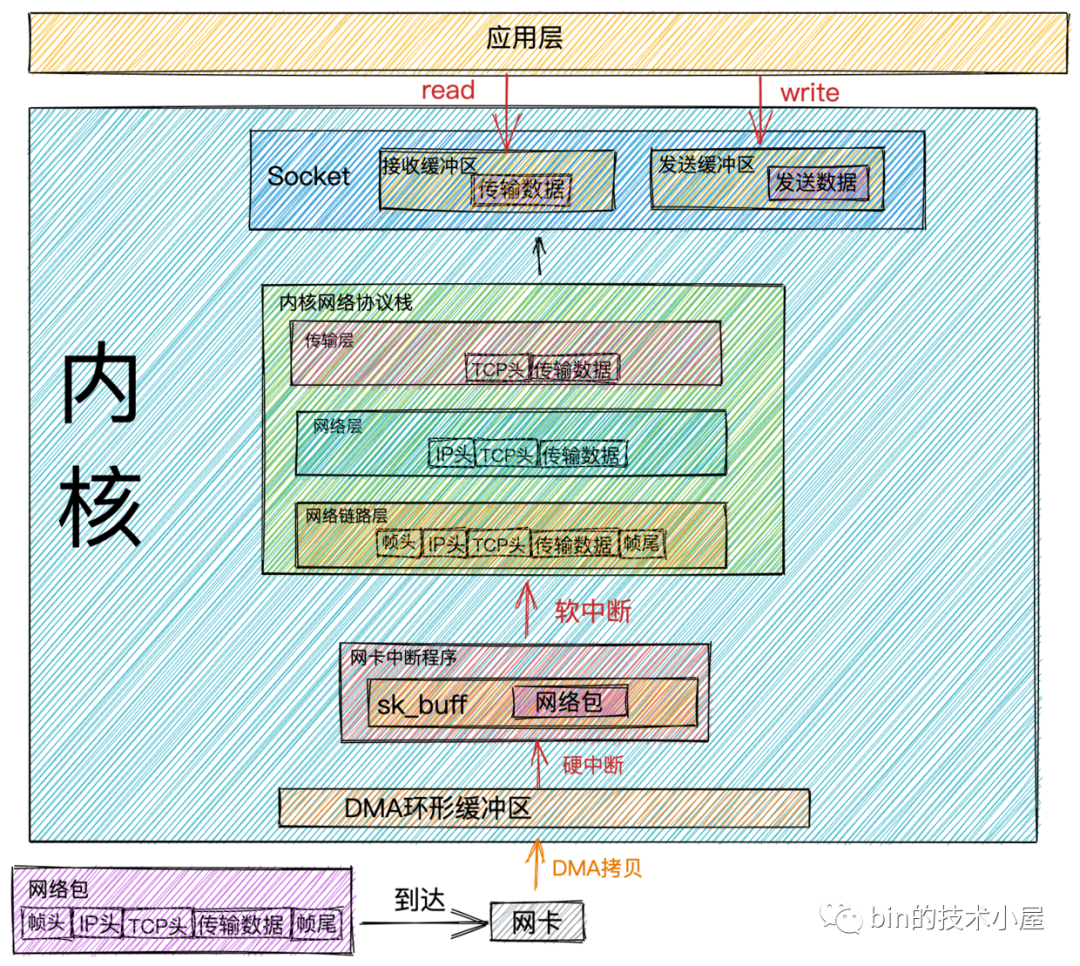
- 當
網路數據幀通過網路傳輸到達網卡時,網卡會將網路數據幀通過DMA的方式放到環形緩衝區RingBuffer中。
RingBuffer是網卡在啟動的時候分配和初始化的環形緩衝隊列。當RingBuffer滿的時候,新來的數據包就會被丟棄。我們可以通過ifconfig命令查看網卡收發數據包的情況。其中overruns數據項表示當RingBuffer滿時,被丟棄的數據包。如果發現出現丟包情況,可以通過ethtool命令來增大RingBuffer長度。
- 當
DMA操作完成時,網卡會向CPU發起一個硬中斷,告訴CPU有網路數據到達。CPU調用網卡驅動註冊的硬中斷響應程式。網卡硬中斷響應程式會為網路數據幀創建內核數據結構sk_buffer,並將網路數據幀拷貝到sk_buffer中。然後發起軟中斷請求,通知內核有新的網路數據幀到達。
sk_buff緩衝區,是一個維護網路幀結構的雙向鏈表,鏈表中的每一個元素都是一個網路幀。雖然 TCP/IP 協議棧分了好幾層,但上下不同層之間的傳遞,實際上只需要操作這個數據結構中的指針,而無需進行數據複製。
- 內核線程
ksoftirqd發現有軟中斷請求到來,隨後調用網卡驅動註冊的poll函數,poll函數將sk_buffer中的網路數據包送到內核協議棧中註冊的ip_rcv函數中。
每個CPU會綁定一個ksoftirqd內核線程專門用來處理軟中斷響應。2個 CPU 時,就會有ksoftirqd/0和ksoftirqd/1這兩個內核線程。
這裡有個事情需要註意下: 網卡接收到數據後,當
DMA拷貝完成時,向CPU發出硬中斷,這時哪個CPU上響應了這個硬中斷,那麼在網卡硬中斷響應程式中發出的軟中斷請求也會在這個CPU綁定的ksoftirqd線程中響應。所以如果發現Linux軟中斷,CPU消耗都集中在一個核上的話,那麼就需要調整硬中斷的CPU親和性,來將硬中斷打散到不通的CPU核上去。
- 在
ip_rcv函數中也就是上圖中的網路層,取出數據包的IP頭,判斷該數據包下一跳的走向,如果數據包是發送給本機的,則取出傳輸層的協議類型(TCP或者UDP),並去掉數據包的IP頭,將數據包交給上圖中得傳輸層處理。
傳輸層的處理函數:
TCP協議對應內核協議棧中註冊的tcp_rcv函數,UDP協議對應內核協議棧中註冊的udp_rcv函數。
-
當我們採用的是
TCP協議時,數據包到達傳輸層時,會在內核協議棧中的tcp_rcv函數處理,在tcp_rcv函數中去掉TCP頭,根據四元組(源IP,源埠,目的IP,目的埠)查找對應的Socket,如果找到對應的Socket則將網路數據包中的傳輸數據拷貝到Socket中的接收緩衝區中。如果沒有找到,則發送一個目標不可達的icmp包。 -
內核在接收網路數據包時所做的工作我們就介紹完了,現在我們把視角放到應用層,當我們程式通過系統調用
read讀取Socket接收緩衝區中的數據時,如果接收緩衝區中沒有數據,那麼應用程式就會在系統調用上阻塞,直到Socket接收緩衝區有數據,然後CPU將內核空間(Socket接收緩衝區)的數據拷貝到用戶空間,最後系統調用read返回,應用程式讀取數據。
性能開銷
從內核處理網路數據包接收的整個過程來看,內核幫我們做了非常之多的工作,最終我們的應用程式才能讀取到網路數據。
隨著而來的也帶來了很多的性能開銷,結合前面介紹的網路數據包接收過程我們來看下網路數據包接收的過程中都有哪些性能開銷:
- 應用程式通過
系統調用從用戶態轉為內核態的開銷以及系統調用返回時從內核態轉為用戶態的開銷。 - 網路數據從
內核空間通過CPU拷貝到用戶空間的開銷。 - 內核線程
ksoftirqd響應軟中斷的開銷。 CPU響應硬中斷的開銷。DMA拷貝網路數據包到記憶體中的開銷。
網路包發送流程
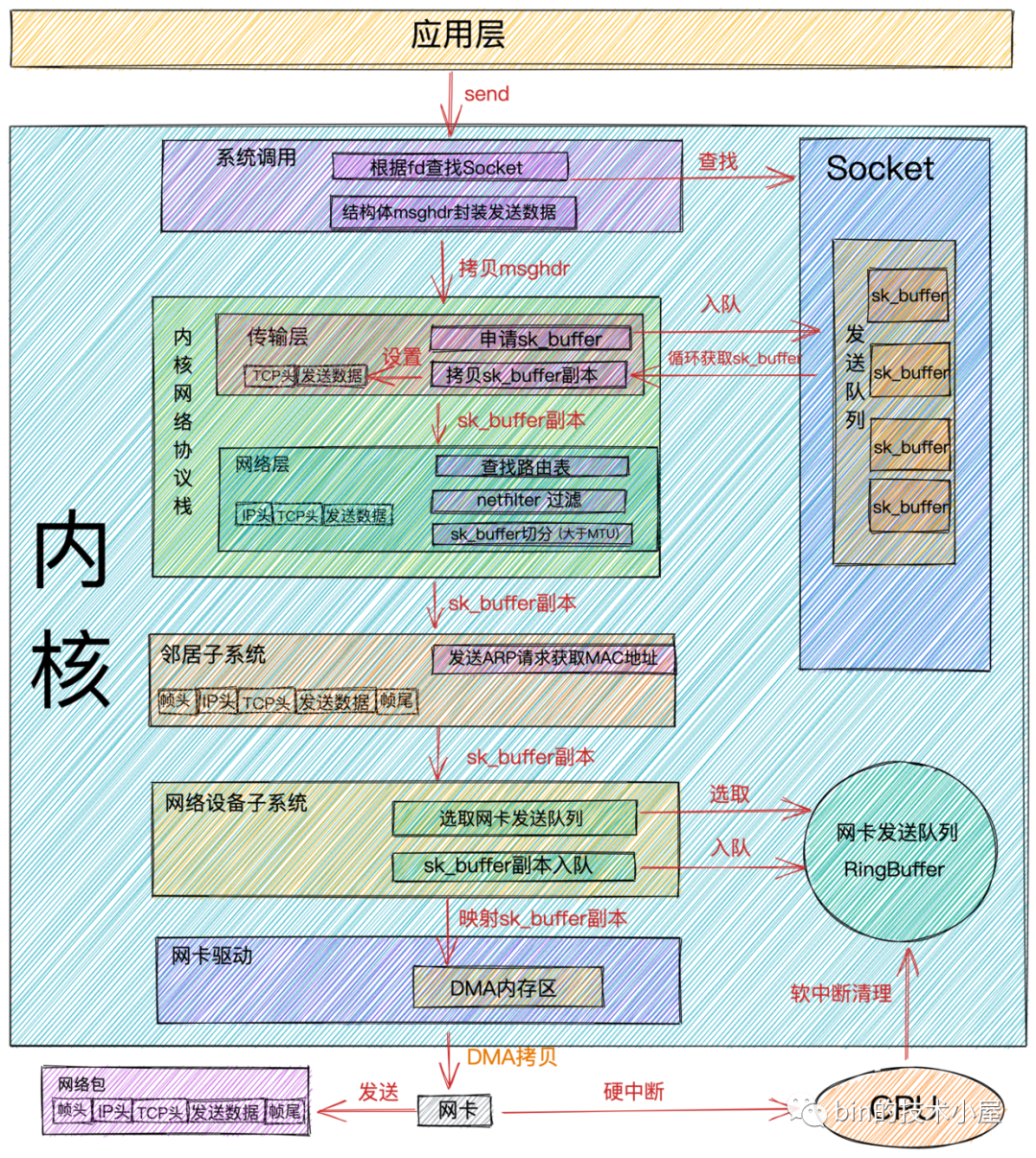
-
當我們在應用程式中調用
send系統調用發送數據時,由於是系統調用所以線程會發生一次用戶態到內核態的轉換,在內核中首先根據fd將真正的Socket找出,這個Socket對象中記錄著各種協議棧的函數地址,然後構造struct msghdr對象,將用戶需要發送的數據全部封裝在這個struct msghdr結構體中。 -
調用內核協議棧函數
inet_sendmsg,發送流程進入內核協議棧處理。在進入到內核協議棧之後,內核會找到Socket上的具體協議的發送函數。
比如:我們使用的是
TCP協議,對應的TCP協議發送函數是tcp_sendmsg,如果是UDP協議的話,對應的發送函數為udp_sendmsg。
- 在
TCP協議的發送函數tcp_sendmsg中,創建內核數據結構sk_buffer,將
struct msghdr結構體中的發送數據拷貝到sk_buffer中。調用tcp_write_queue_tail函數獲取Socket發送隊列中的隊尾元素,將新創建的sk_buffer添加到Socket發送隊列的尾部。
Socket的發送隊列是由sk_buffer組成的一個雙向鏈表。
發送流程走到這裡,用戶要發送的數據總算是從
用戶空間拷貝到了內核中,這時雖然發送數據已經拷貝到了內核Socket中的發送隊列中,但並不代表內核會開始發送,因為TCP協議的流量控制和擁塞控制,用戶要發送的數據包並不一定會立馬被髮送出去,需要符合TCP協議的發送條件。如果沒有達到發送條件,那麼本次send系統調用就會直接返回。
-
如果符合發送條件,則開始調用
tcp_write_xmit內核函數。在這個函數中,會迴圈獲取Socket發送隊列中待發送的sk_buffer,然後進行擁塞控制以及滑動視窗的管理。 -
將從
Socket發送隊列中獲取到的sk_buffer重新拷貝一份,設置sk_buffer副本中的TCP HEADER。
sk_buffer內部其實包含了網路協議中所有的header。在設置TCP HEADER的時候,只是把指針指向sk_buffer的合適位置。後面再設置IP HEADER的時候,在把指針移動一下就行,避免頻繁的記憶體申請和拷貝,效率很高。
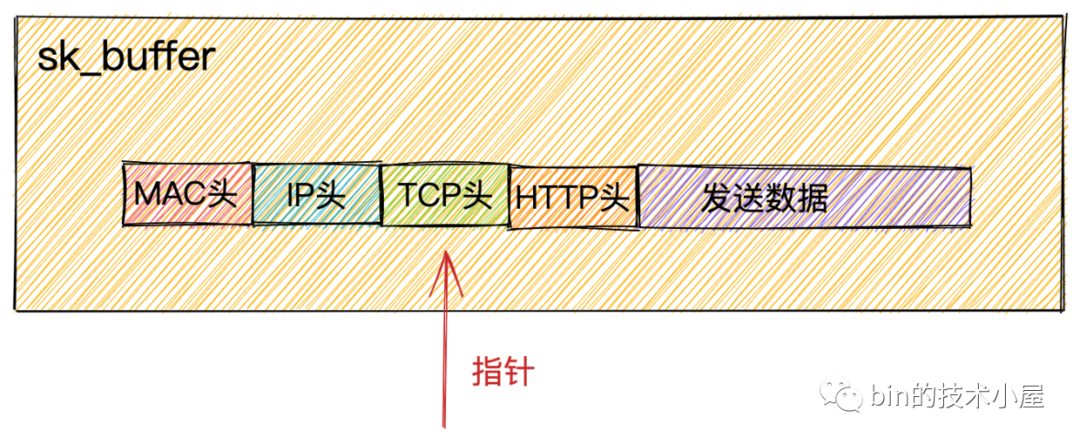
為什麼不直接使用
Socket發送隊列中的sk_buffer而是需要拷貝一份呢?
因為TCP協議是支持丟包重傳的,在沒有收到對端的ACK之前,這個sk_buffer是不能刪除的。內核每次調用網卡發送數據的時候,實際上傳遞的是sk_buffer的拷貝副本,當網卡把數據發送出去後,sk_buffer拷貝副本會被釋放。當收到對端的ACK之後,Socket發送隊列中的sk_buffer才會被真正刪除。
-
當設置完
TCP頭後,內核協議棧傳輸層的事情就做完了,下麵通過調用ip_queue_xmit內核函數,正式來到內核協議棧網路層的處理。- 檢查
Socket中是否有緩存路由表,如果沒有的話,則查找路由項,並緩存到Socket中。接著在把路由表設置到sk_buffer中。
通過
route命令可以查看本機路由配置。-
將
sk_buffer中的指針移動到IP頭位置上,設置IP頭。 -
執行
netfilters過濾。過濾通過之後,如果數據大於MTU的話,則執行分片。
如果你使用
iptables配置了一些規則,那麼這裡將檢測是否命中規則。 如果你設置了非常複雜的 netfilter 規則,在這個函數里將會導致你的線程CPU 開銷會極大增加。 - 檢查
-
內核協議棧
網路層的事情處理完後,現在發送流程進入了到了鄰居子系統,鄰居子系統位於內核協議棧中的網路層和網路介面層之間,用於發送ARP請求獲取MAC地址,然後將sk_buffer中的指針移動到MAC頭位置,填充MAC頭。 -
經過
鄰居子系統的處理,現在sk_buffer中已經封裝了一個完整的數據幀,隨後內核將sk_buffer交給網路設備子系統進行處理。網路設備子系統主要做以下幾項事情:- 選擇發送隊列(
RingBuffer)。因為網卡擁有多個發送隊列,所以在發送前需要選擇一個發送隊列。 - 將
sk_buffer添加到發送隊列中。 - 迴圈從發送隊列(
RingBuffer)中取出sk_buffer,調用內核函數sch_direct_xmit發送數據,其中會調用網卡驅動程式來發送數據。
- 選擇發送隊列(
以上過程全部是用戶線程的內核態在執行,占用的CPU時間是系統態時間(
sy),當分配給用戶線程的CPU quota用完的時候,會觸發NET_TX_SOFTIRQ類型的軟中斷,內核線程ksoftirqd會響應這個軟中斷,並執行NET_TX_SOFTIRQ類型的軟中斷註冊的回調函數net_tx_action,在回調函數中會執行到驅動程式函數dev_hard_start_xmit來發送數據。
註意:當觸發
NET_TX_SOFTIRQ軟中斷來發送數據時,後邊消耗的 CPU 就都顯示在si這裡了,不會消耗用戶進程的系統態時間(sy)了。
從這裡可以看到網路包的發送過程和接受過程是不同的,在介紹網路包的接受過程時,我們提到是通過觸發
NET_RX_SOFTIRQ類型的軟中斷在內核線程ksoftirqd中執行內核網路協議棧接受數據。而在網路數據包的發送過程中是用戶線程的內核態在執行內核網路協議棧,只有當線程的CPU quota用盡時,才觸發NET_TX_SOFTIRQ軟中斷來發送數據。
在整個網路包的發送和接受過程中,
NET_TX_SOFTIRQ類型的軟中斷只會在發送網路包時並且當用戶線程的CPU quota用盡時,才會觸發。剩下的接受過程中觸發的軟中斷類型以及發送完數據觸發的軟中斷類型均為NET_RX_SOFTIRQ。
所以這就是你在伺服器上查看/proc/softirqs,一般NET_RX都要比NET_TX大很多的的原因。
-
現在發送流程終於到了網卡真實發送數據的階段,前邊我們講到無論是用戶線程的內核態還是觸發
NET_TX_SOFTIRQ類型的軟中斷在發送數據的時候最終會調用到網卡的驅動程式函數dev_hard_start_xmit來發送數據。在網卡驅動程式函數dev_hard_start_xmit中會將sk_buffer映射到網卡可訪問的記憶體 DMA 區域,最終網卡驅動程式通過DMA的方式將數據幀通過物理網卡發送出去。 -
當數據發送完畢後,還有最後一項重要的工作,就是清理工作。數據發送完畢後,網卡設備會向
CPU發送一個硬中斷,CPU調用網卡驅動程式註冊的硬中斷響應程式,在硬中斷響應中觸發NET_RX_SOFTIRQ類型的軟中斷,在軟中斷的回調函數igb_poll中清理釋放sk_buffer,清理網卡發送隊列(RingBuffer),解除 DMA 映射。
無論
硬中斷是因為有數據要接收,還是說發送完成通知,從硬中斷觸發的軟中斷都是NET_RX_SOFTIRQ。
這裡釋放清理的只是
sk_buffer的副本,真正的sk_buffer現在還是存放在Socket的發送隊列中。前面在傳輸層處理的時候我們提到過,因為傳輸層需要保證可靠性,所以sk_buffer其實還沒有刪除。它得等收到對方的 ACK 之後才會真正刪除。
性能開銷
前邊我們提到了在網路包接收過程中涉及到的性能開銷,現在介紹完了網路包的發送過程,我們來看下在數據包發送過程中的性能開銷:
-
和接收數據一樣,應用程式在調用
系統調用send的時候會從用戶態轉為內核態以及發送完數據後,系統調用返回時從內核態轉為用戶態的開銷。 -
用戶線程內核態
CPU quota用盡時觸發NET_TX_SOFTIRQ類型軟中斷,內核響應軟中斷的開銷。 -
網卡發送完數據,向
CPU發送硬中斷,CPU響應硬中斷的開銷。以及在硬中斷中發送NET_RX_SOFTIRQ軟中斷執行具體的記憶體清理動作。內核響應軟中斷的開銷。 -
記憶體拷貝的開銷。我們來回顧下在數據包發送的過程中都發生了哪些記憶體拷貝:
- 在內核協議棧的傳輸層中,
TCP協議對應的發送函數tcp_sendmsg會申請sk_buffer,將用戶要發送的數據拷貝到sk_buffer中。 - 在發送流程從傳輸層到網路層的時候,會
拷貝一個sk_buffer副本出來,將這個sk_buffer副本向下傳遞。原始sk_buffer保留在Socket發送隊列中,等待網路對端ACK,對端ACK後刪除Socket發送隊列中的sk_buffer。對端沒有發送ACK,則重新從Socket發送隊列中發送,實現TCP協議的可靠傳輸。 - 在網路層,如果發現要發送的數據大於
MTU,則會進行分片操作,申請額外的sk_buffer,並將原來的sk_buffer拷貝到多個小的sk_buffer中。
- 在內核協議棧的傳輸層中,
再談(阻塞,非阻塞)與(同步,非同步)
在我們聊完網路數據的接收和發送過程後,我們來談下IO中特別容易混淆的概念:阻塞與同步,非阻塞與非同步。
網上各種博文還有各種書籍中有大量的關於這兩個概念的解釋,但是筆者覺得還是不夠形象化,只是對概念的生硬解釋,如果硬套概念的話,其實感覺阻塞與同步,非阻塞與非同步還是沒啥區別,時間長了,還是比較模糊容易混淆。
所以筆者在這裡嘗試換一種更加形象化,更加容易理解記憶的方式來清晰地解釋下什麼是阻塞與非阻塞,什麼是同步與非同步。
經過前邊對網路數據包接收流程的介紹,在這裡我們可以將整個流程總結為兩個階段:
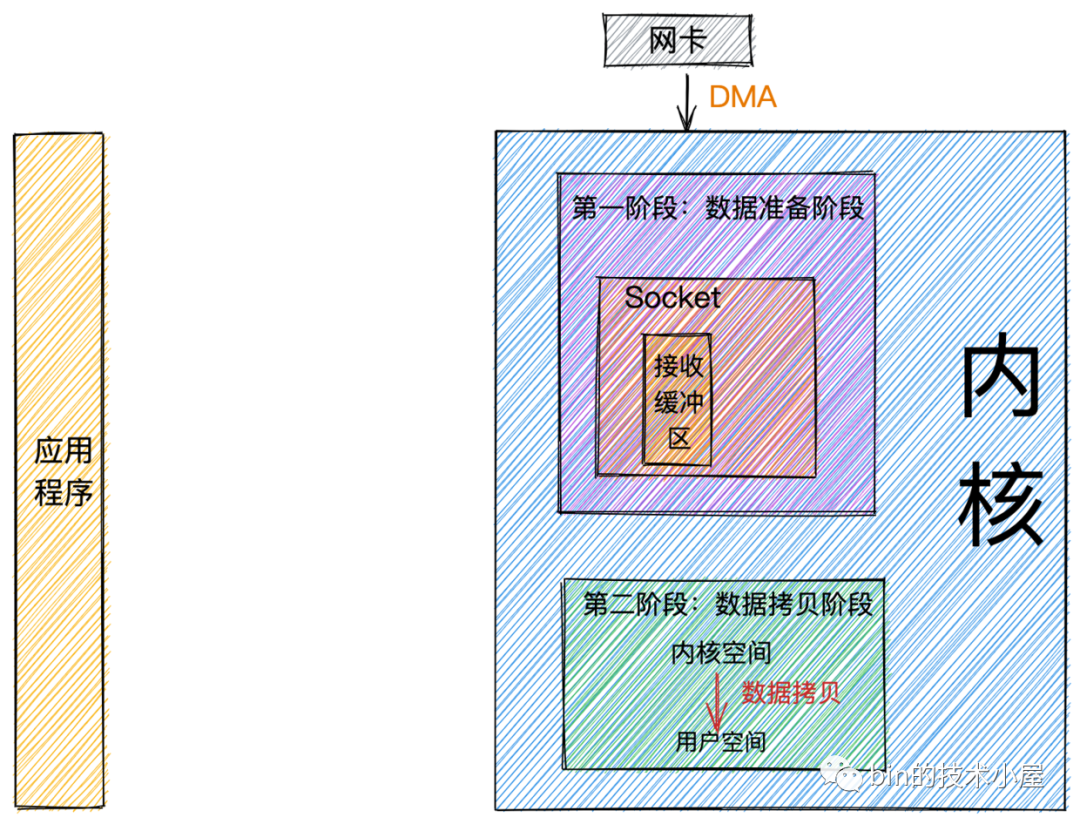
-
數據準備階段: 在這個階段,網路數據包到達網卡,通過
DMA
的方式將數據包拷貝到記憶體中,然後經過硬中斷,軟中斷,接著通過內核線程ksoftirqd經過內核協議棧的處理,最終將數據發送到內核Socket的接收緩衝區中。 -
數據拷貝階段: 當數據到達
內核Socket的接收緩衝區中時,此時數據存在於內核空間中,需要將數據拷貝到用戶空間中,才能夠被應用程式讀取。
阻塞與非阻塞
阻塞與非阻塞的區別主要發生在第一階段:數據準備階段。
當應用程式發起系統調用read時,線程從用戶態轉為內核態,讀取內核Socket的接收緩衝區中的網路數據。
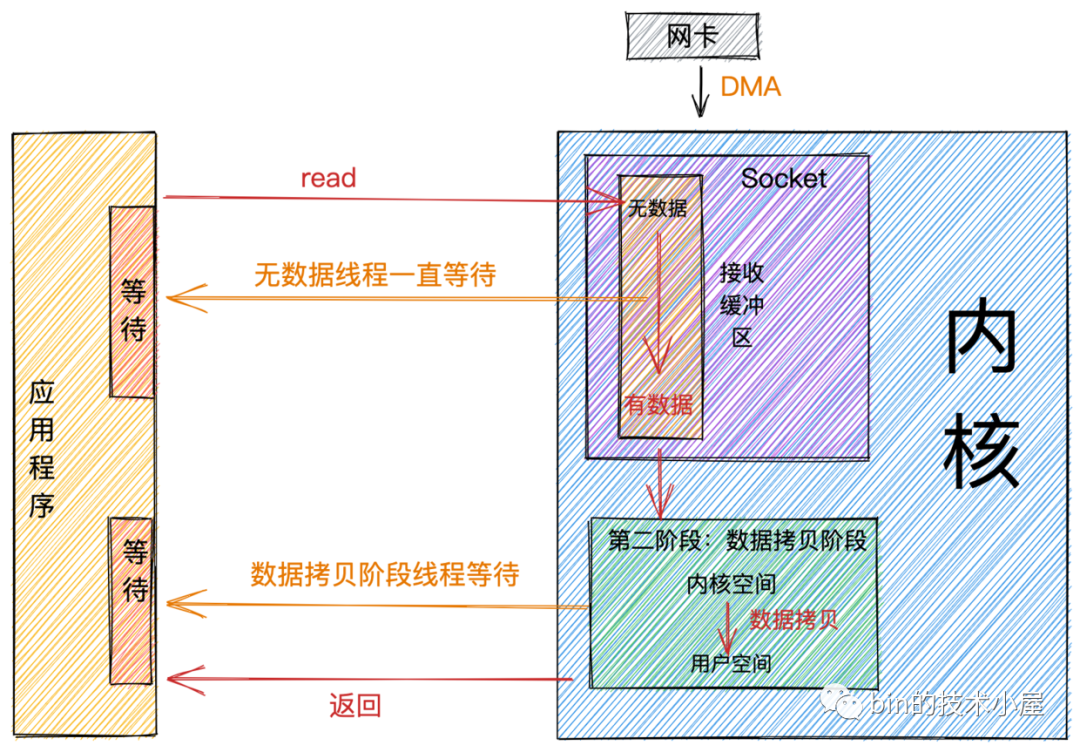
阻塞
如果這時內核Socket的接收緩衝區沒有數據,那麼線程就會一直等待,直到Socket接收緩衝區有數據為止。隨後將數據從內核空間拷貝到用戶空間,系統調用read返回。

從圖中我們可以看出:阻塞的特點是在第一階段和第二階段都會等待。
非阻塞
阻塞和非阻塞主要的區分是在第一階段:數據準備階段。
-
在第一階段,當
Socket的接收緩衝區中沒有數據的時候,阻塞模式下應用線程會一直等待。非阻塞模式下應用線程不會等待,系統調用直接返回錯誤標誌EWOULDBLOCK。 -
當
Socket的接收緩衝區中有數據的時候,阻塞和非阻塞的表現是一樣的,都會進入第二階段等待數據從內核空間拷貝到用戶空間,然後系統調用返回。
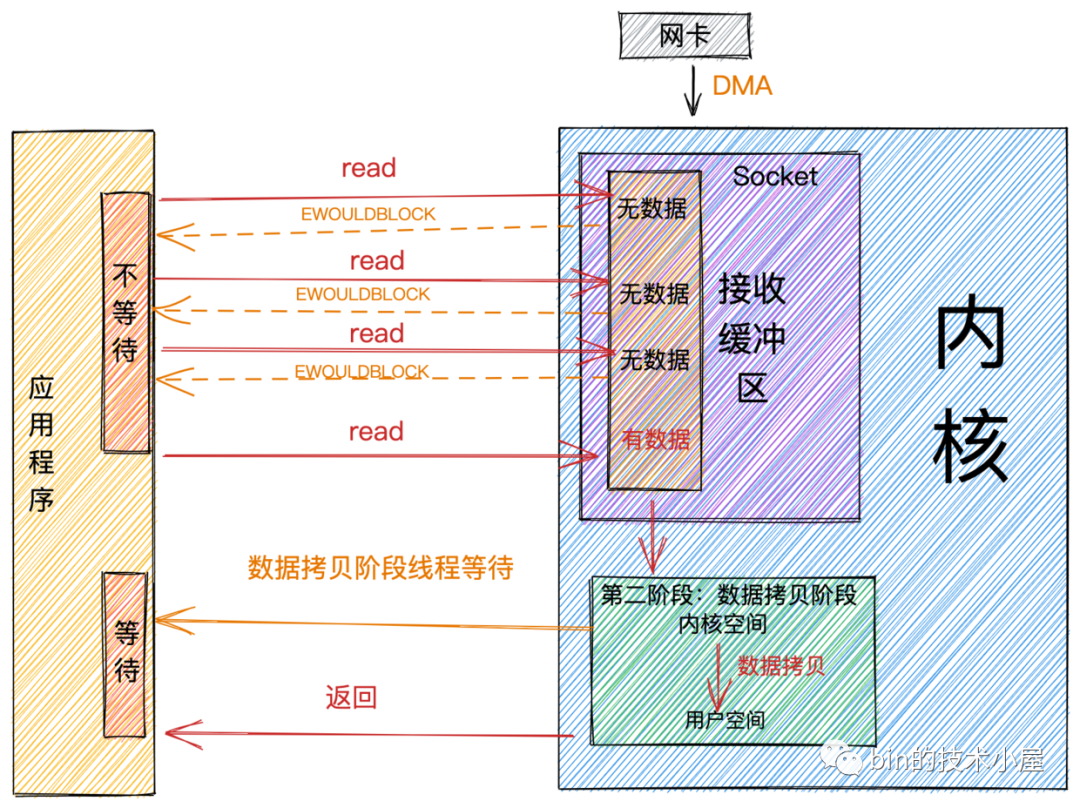
從上圖中,我們可以看出:非阻塞的特點是第一階段不會等待,但是在第二階段還是會等待。
同步與非同步
同步與非同步主要的區別發生在第二階段:數據拷貝階段。
前邊我們提到在數據拷貝階段主要是將數據從內核空間拷貝到用戶空間。然後應用程式才可以讀取數據。
當內核Socket的接收緩衝區有數據到達時,進入第二階段。
同步
同步模式在數據準備好後,是由用戶線程的內核態來執行第二階段。所以應用程式會在第二階段發生阻塞,直到數據從內核空間拷貝到用戶空間,系統調用才會返回。
Linux下的 epoll和Mac 下的 kqueue 都屬於同步 IO。
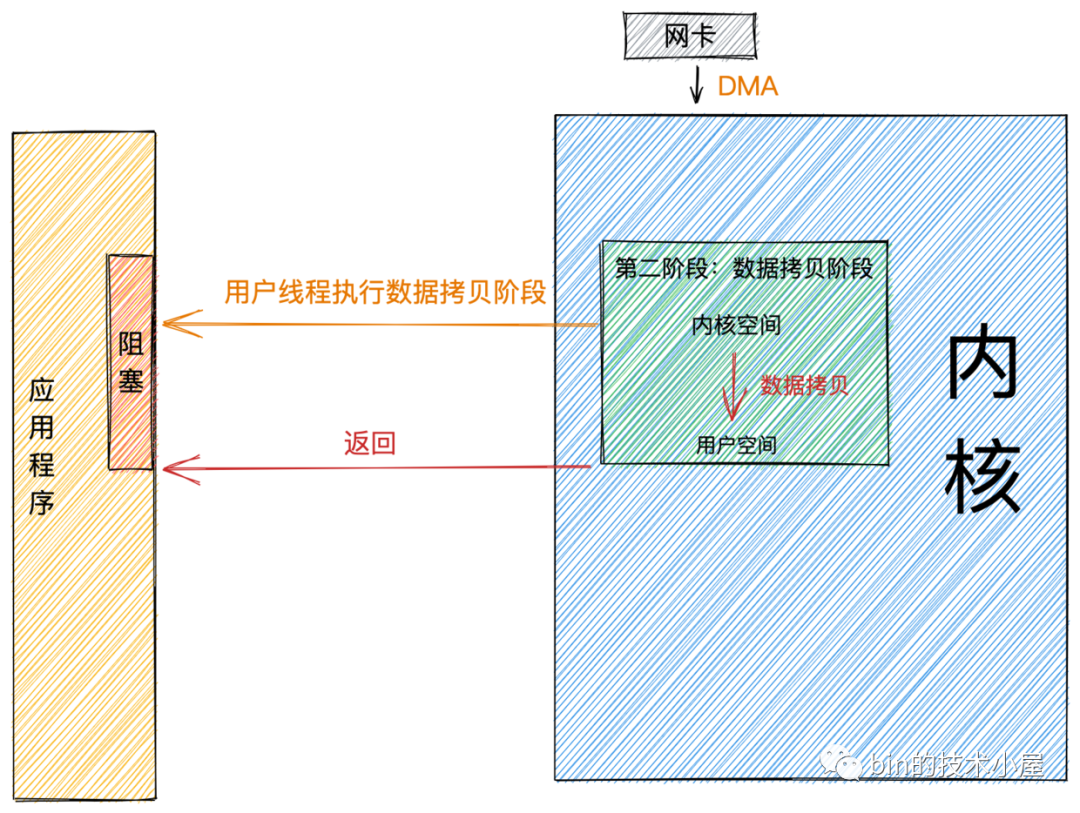
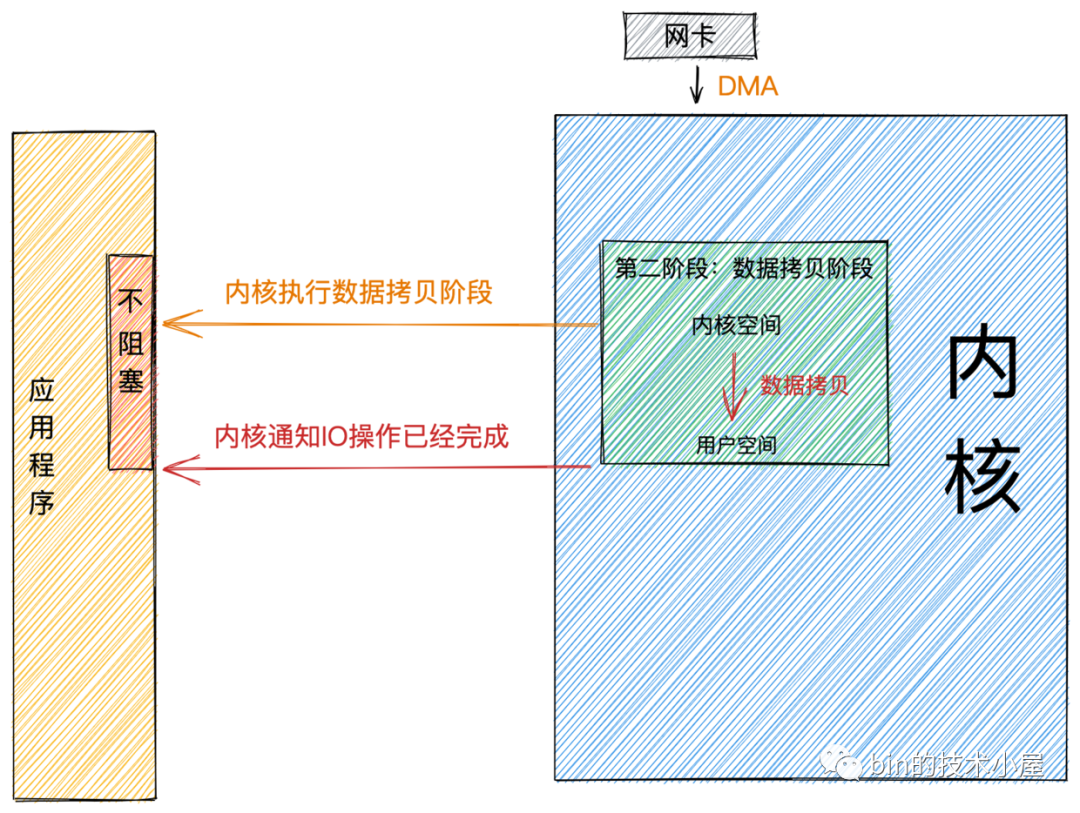
非同步
非同步模式下是由內核來執行第二階段的數據拷貝操作,當內核執行完第二階段,會通知用戶線程IO操作已經完成,並將數據回調給用戶線程。所以在非同步模式下 數據準備階段和數據拷貝階段均是由內核來完成,不會對應用程式造成任何阻塞。
基於以上特征,我們可以看到非同步模式需要內核的支持,比較依賴操作系統底層的支持。
在目前流行的操作系統中,只有Windows 中的 IOCP 才真正屬於非同步 IO,實現的也非常成熟。但Windows很少用來作為伺服器使用。
而常用來作為伺服器使用的Linux,非同步IO機制實現的不夠成熟,與NIO相比性能提升的也不夠明顯。
但Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的非同步IO庫io_uring 改善了原來Linux native AIO的一些性能問題。性能相比Epoll以及之前原生的AIO提高了不少,值得關註。
IO模型
在進行網路IO操作時,用什麼樣的IO模型來讀寫數據將在很大程度上決定了網路框架的IO性能。所以IO模型的選擇是構建一個高性能網路框架的基礎。
在《UNIX 網路編程》一書中介紹了五種IO模型:阻塞IO,非阻塞IO,IO多路復用,信號驅動IO,非同步IO,每一種IO模型的出現都是對前一種的升級優化。
下麵我們就來分別介紹下這五種IO模型各自都解決了什麼問題,適用於哪些場景,各自的優缺點是什麼?
阻塞IO(BIO)
經過前一小節對阻塞這個概念的介紹,相信大家可以很容易理解阻塞IO的概念和過程。
既然這小節我們談的是IO,那麼下邊我們來看下在阻塞IO模型下,網路數據的讀寫過程。
阻塞讀
當用戶線程發起read系統調用,用戶線程從用戶態切換到內核態,在內核中去查看Socket接收緩衝區是否有數據到來。
-
Socket接收緩衝區中有數據,則用戶線程在內核態將內核空間中的數據拷貝到用戶空間,系統IO調用返回。 -
Socket接收緩衝區中無數據,則用戶線程讓出CPU,進入阻塞狀態。當數據到達Socket接收緩衝區後,內核喚醒阻塞狀態中的用戶線程進入就緒狀態,隨後經過CPU的調度獲取到CPU quota進入運行狀態,將內核空間的數據拷貝到用戶空間,隨後系統調用返回。
阻塞寫
當用戶線程發起send系統調用時,用戶線程從用戶態切換到內核態,將發送數據從用戶空間拷貝到內核空間中的Socket發送緩衝區中。
-
當
Socket發送緩衝區能夠容納下發送數據時,用戶線程會將全部的發送數據寫入Socket緩衝區,然後執行在《網路包發送流程》這小節介紹的後續流程,然後返回。 -
當
Socket發送緩衝區空間不夠,無法容納下全部發送數據時,用戶線程讓出CPU,進入阻塞狀態,直到Socket發送緩衝區能夠容納下全部發送數據時,內核喚醒用戶線程,執行後續發送流程。
阻塞IO模型下的寫操作做事風格比較硬剛,非得要把全部的發送數據寫入發送緩衝區才肯善罷甘休。
阻塞IO模型
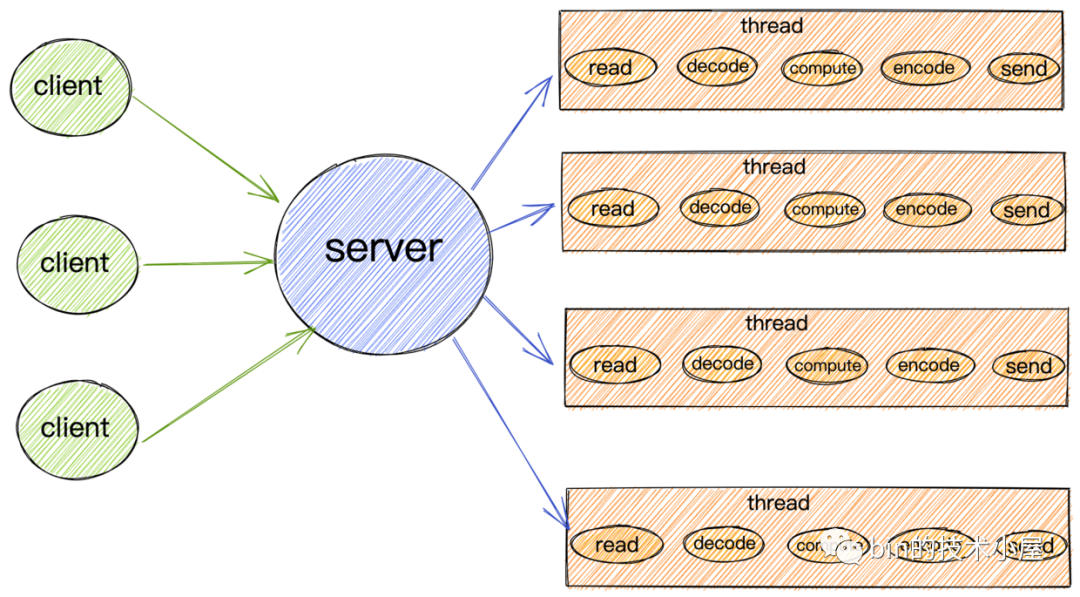
由於阻塞IO的讀寫特點,所以導致在阻塞IO模型下,每個請求都需要被一個獨立的線程處理。一個線程在同一時刻只能與一個連接綁定。來一個請求,服務端就需要創建一個線程用來處理請求。
當客戶端請求的併發量突然增大時,服務端在一瞬間就會創建出大量的線程,而創建線程是需要系統資源開銷的,這樣一來就會一瞬間占用大量的系統資源。
如果客戶端創建好連接後,但是一直不發數據,通常大部分情況下,網路連接也並不總是有數據可讀,那麼在空閑的這段時間內,服務端線程就會一直處於阻塞狀態,無法乾其他的事情。CPU也無法得到充分的發揮,同時還會導致大量線程切換的開銷。
適用場景
基於以上阻塞IO模型的特點,該模型只適用於連接數少,併發度低的業務場景。
比如公司內部的一些管理系統,通常請求數在100個左右,使用阻塞IO模型還是非常適合的。而且性能還不輸NIO。
該模型在C10K之前,是普遍被採用的一種IO模型。
非阻塞IO(NIO)
阻塞IO模型最大的問題就是一個線程只能處理一個連接,如果這個連接上沒有數據的話,那麼這個線程就只能阻塞在系統IO調用上,不能幹其他的事情。這對系統資源來說,是一種極大的浪費。同時大量的線程上下文切換,也是一個巨大的系統開銷。
所以為瞭解決這個問題,我們就需要用儘可能少的線程去處理更多的連接。,網路IO模型的演變也是根據這個需求來一步一步演進的。
基於這個需求,第一種解決方案非阻塞IO就出現了。我們在上一小節中介紹了非阻塞的概念,現在我們來看下網路讀寫操作在非阻塞IO下的特點:
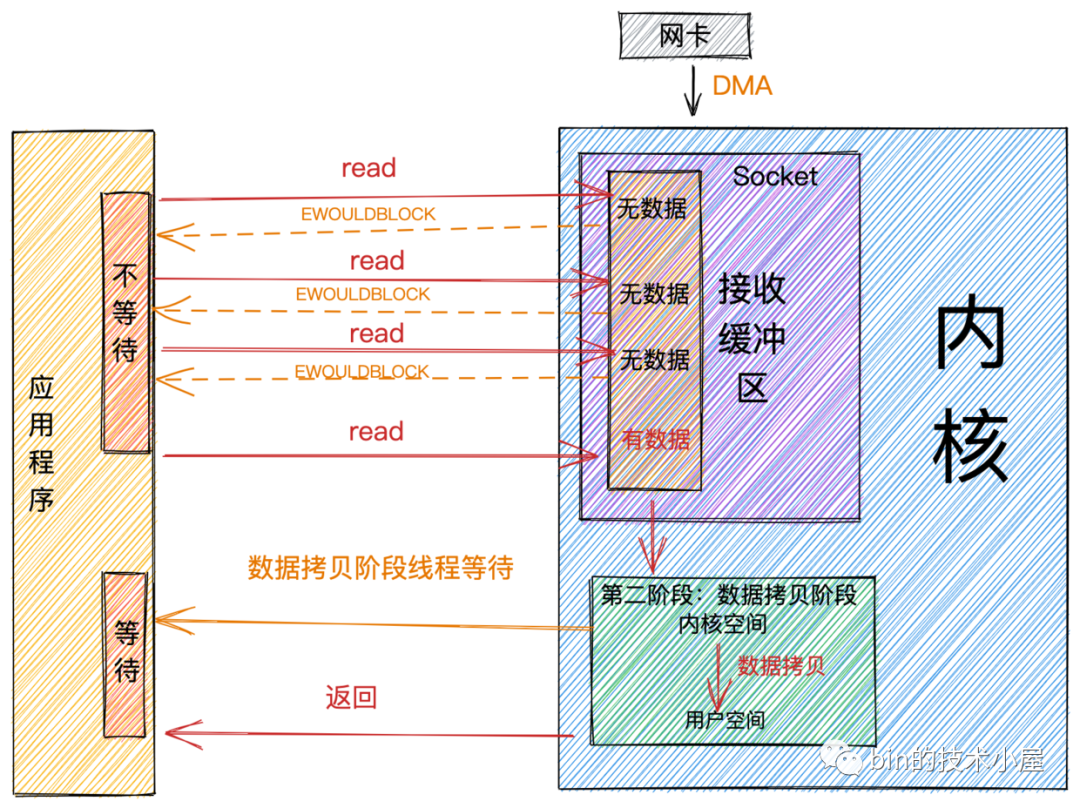
非阻塞讀
當用戶線程發起非阻塞read系統調用時,用戶線程從用戶態轉為內核態,在內核中去查看Socket接收緩衝區是否有數據到來。
-
Socket接收緩衝區中無數據,系統調用立馬返回,並帶有一個EWOULDBLOCK或EAGAIN錯誤,這個階段用戶線程不會阻塞,也不會讓出CPU,而是會繼續輪訓直到Socket接收緩衝區中有數據為止。 -
Socket接收緩衝區中有數據,用戶線程在內核態會將內核空間中的數據拷貝到用戶空間,註意這個數據拷貝階段,應用程式是阻塞的,當數據拷貝完成,系統調用返回。
非阻塞寫
前邊我們在介紹阻塞寫的時候提到阻塞寫的風格特別的硬朗,頭比較鐵非要把全部發送數據一次性都寫到Socket的發送緩衝區中才返回,如果發送緩衝區中沒有足夠的空間容納,那麼就一直阻塞死等,特別的剛。
相比較而言非阻塞寫的特點就比較佛系,當發送緩衝區中沒有足夠的空間容納全部發送數據時,非阻塞寫的特點是能寫多少寫多少,寫不下了,就立即返回。並將寫入到發送緩衝區的位元組數返回給應用程式,方便用戶線程不斷的輪訓嘗試將剩下的數據寫入發送緩衝區中。
非阻塞IO模型
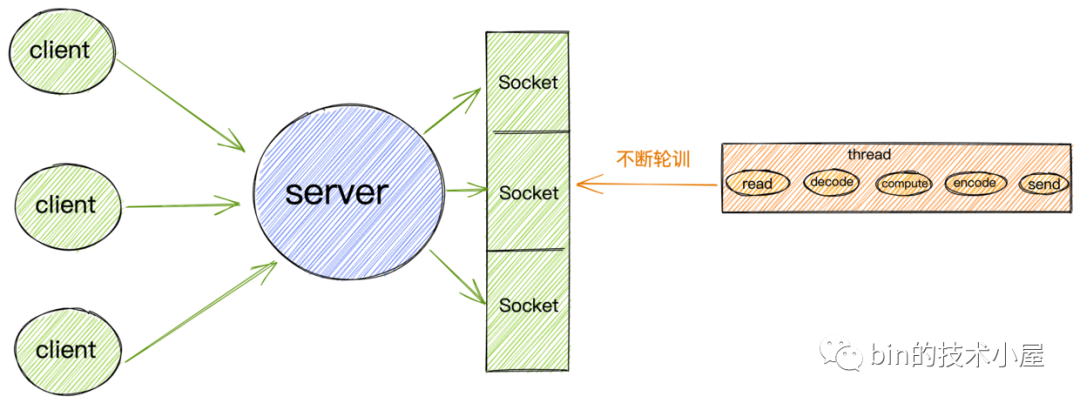
基於以上非阻塞IO的特點,我們就不必像阻塞IO那樣為每個請求分配一個線程去處理連接上的讀寫了。
我們可以利用一個線程或者很少的線程,去不斷地輪詢每個Socket的接收緩衝區是否有數據到達,如果沒有數據,不必阻塞線程,而是接著去輪詢下一個Socket接收緩衝區,直到輪詢到數據後,處理連接上的讀寫,或者交給業務線程池去處理,輪詢線程則繼續輪詢其他的Socket接收緩衝區。
這樣一個非阻塞IO模型就實現了我們在本小節開始提出的需求:我們需要用儘可能少的線程去處理更多的連接
適用場景
雖然非阻塞IO模型與阻塞IO模型相比,減少了很大一部分的資源消耗和系統開銷。
但是它仍然有很大的性能問題,因為在非阻塞IO模型下,需要用戶線程去不斷地發起系統調用去輪訓Socket接收緩衝區,這就需要用戶線程不斷地從用戶態切換到內核態,內核態切換到用戶態。隨著併發量的增大,這個上下文切換的開銷也是巨大的。
所以單純的非阻塞IO模型還是無法適用於高併發的場景。只能適用於C10K以下的場景。
IO多路復用
在非阻塞IO這一小節的開頭,我們提到網路IO模型的演變都是圍繞著---如何用儘可能少的線程去處理更多的連接這個核心需求開始展開的。
本小節我們來談談IO多路復用模型,那麼什麼是多路?,什麼又是復用呢?
我們還是以這個核心需求來對這兩個概念展開闡述:
-
多路:我們的核心需求是要用儘可能少的線程來處理儘可能多的連接,這裡的
多路指的就是我們需要處理的眾多連接。 -
復用:核心需求要求我們使用
儘可能少的線程,儘可能少的系統開銷去處理儘可能多的連接(多路),那麼這裡的復用指的就是用有限的資源,比如用一個線程或者固定數量的線程去處理眾多連接上的讀寫事件。換句話說,在阻塞IO模型中一個連接就需要分配一個獨立的線程去專門處理這個連接上的讀寫,到了IO多路復用模型中,多個連接可以復用這一個獨立的線程去處理這多個連接上的讀寫。
好了,IO多路復用模型的概念解釋清楚了,那麼問題的關鍵是我們如何去實現這個復用,也就是如何讓一個獨立的線程去處理眾多連接上的讀寫事件呢?
這個問題其實在非阻塞IO模型中已經給出了它的答案,在非阻塞IO模型中,利用非阻塞的系統IO調用去不斷的輪詢眾多連接的Socket接收緩衝區看是否有數據到來,如果有則處理,如果沒有則繼續輪詢下一個Socket。這樣就達到了用一個線程去處理眾多連接上的讀寫事件了。
但是非阻塞IO模型最大的問題就是需要不斷的發起系統調用去輪詢各個Socket中的接收緩衝區是否有數據到來,頻繁的系統調用隨之帶來了大量的上下文切換開銷。隨著併發量的提升,這樣也會導致非常嚴重的性能問題。
那麼如何避免頻繁的系統調用同時又可以實現我們的核心需求呢?
這就需要操作系統的內核來支持這樣的操作,我們可以把頻繁的輪詢操作交給操作系統內核來替我們完成,這樣就避免了在用戶空間頻繁的去使用系統調用來輪詢所帶來的性能開銷。
正如我們所想,操作系統內核也確實為我們提供了這樣的功能實現,下麵我們來一起看下操作系統對IO多路復用模型的實現。
select
select是操作系統內核提供給我們使用的一個系統調用,它解決了在非阻塞IO模型中需要不斷的發起系統IO調用去輪詢各個連接上的Socket接收緩衝區所帶來的用戶空間與內核空間不斷切換的系統開銷。
select系統調用將輪詢的操作交給了內核來幫助我們完成,從而避免了在用戶空間不斷的發起輪詢所帶來的的系統性能開銷。
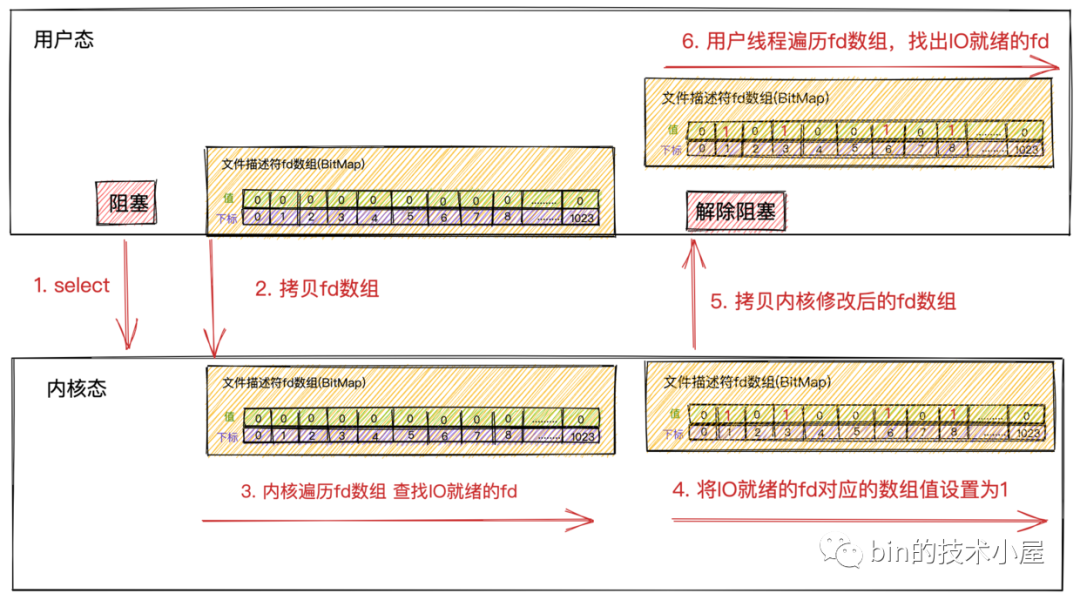
-
首先用戶線程在發起
select系統調用的時候會阻塞在select系統調用上。此時,用戶線程從用戶態切換到了內核態完成了一次上下文切換 -
用戶線程將需要監聽的
Socket對應的文件描述符fd數組通過select系統調用傳遞給內核。此時,用戶線程將用戶空間中的文件描述符fd數組拷貝到內核空間。
這裡的文件描述符數組其實是一個BitMap,BitMap下標為文件描述符fd,下標對應的值為:1表示該fd上有讀寫事件,0表示該fd上沒有讀寫事件。

文件描述符fd其實就是一個整數值,在Linux中一切皆文件,Socket也是一個文件。描述進程所有信息的數據結構task_struct 中有一個屬性struct files_struct *files,它最終指向了一個數組,數組裡存放了進程打開的所有文件列表,文件信息封裝在struct file結構體中,這個數組存放的類型就是
struct file結構體,數組的下標則是我們常說的文件描述符fd。
- 當用戶線程調用完
select後開始進入阻塞狀態,內核開始輪詢遍歷fd數組,查看fd對應的Socket接收緩衝區中是否有數據到來。如果有數據到來,則將fd對應BitMap的值設置為1。如果沒有數據到來,則保持值為0。
註意這裡內核會修改原始的
fd數組!!
-
內核遍歷一遍
fd數組後,如果發現有些fd上有IO數據到來,則將修改後的fd數組返回給用戶線程。此時,會將fd數組從內核空間拷貝到用戶空間。 -
當內核將修改後的
fd數組返回給用戶線程後,用戶線程解除阻塞,由用戶線程開始遍歷fd數組然後找出fd數組中值為1的Socket文件描述符。最後對這些Socket發起系統調用讀取數據。
select不會告訴用戶線程具體哪些fd上有IO數據到來,只是在IO活躍的fd上打上標記,將打好標記的完整fd數組返回給用戶線程,所以用戶線程還需要遍歷fd數組找出具體哪些fd上有IO數據到來。
- 由於內核在遍歷的過程中已經修改了
fd數組,所以在用戶線程遍歷完fd數組後獲取到IO就緒的Socket後,就需要重置fd數組,並重新調用select傳入重置後的fd數組,讓內核發起新的一輪遍歷輪詢。
API介紹
當我們熟悉了select的原理後,就很容易理解內核給我們提供的select API了。
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout)
從select API中我們可以看到,select系統調用是在規定的超時時間內,監聽(輪詢)用戶感興趣的文件描述符集合上的可讀,可寫,異常三類事件。
-
maxfdp1 :select傳遞給內核監聽的文件描述符集合中數值最大的文件描述符+1,目的是用於限定內核遍歷範圍。比如:select監聽的文件描述符集合為{0,1,2,3,4},那麼maxfdp1的值為5。 -
fd_set *readset:對可讀事件感興趣的文件描述符集合。 -
fd_set *writeset:對可寫事件感興趣的文件描述符集合。 -
fd_set *exceptset:對可寫事件感興趣的文件描述符集合。
這裡的
fd_set就是我們前邊提到的文件描述符數組,是一個BitMap結構。
const struct timeval *timeout:select系統調用超時時間,在這段時間內,內核如果沒有發現有IO就緒的文件描述符,就直接返回。
上小節提到,在內核遍歷完fd數組後,發現有IO就緒的fd,則會將該fd對應的BitMap中的值設置為1,並將修改後的fd數組,返回給用戶線程。
在用戶線程中需要重新遍歷fd數組,找出IO就緒的fd出來,然後發起真正的讀寫調用。
下麵介紹下在用戶線程中重新遍歷fd數組的過程中,我們需要用到的API:
-
void FD_ZERO(fd_set *fdset):清空指定的文件描述符集合,即讓fd_set中不在包含任何文件描述符。 -
void FD_SET(int fd, fd_set *fdset):將一個給定的文件描述符加入集合之中。
每次調用
select之前都要通過FD_ZERO和FD_SET重新設置文件描述符,因為文件描述符集合會在內核中被修改。
-
int FD_ISSET(int fd, fd_set *fdset):檢查集合中指定的文件描述符是否可以讀寫。用戶線程遍歷文件描述符集合,調用該方法檢查相應的文件描述符是否IO就緒。 -
void FD_CLR(int fd, fd_set *fdset):將一個給定的文件描述符從集合中刪除
性能開銷
雖然select解決了非阻塞IO模型中頻繁發起系統調用的問題,但是在整個select工作過程中,我們還是看出了select有些不足的地方。
-
在發起
select系統調用以及返回時,用戶線程各發生了一次用戶態到內核態以及內核態到用戶態的上下文切換開銷。發生2次上下文切換 -
在發起
select系統調用以及返回時,用戶線程在內核態需要將文件描述符集合從用戶空間拷貝到內核空間。以及在內核修改完文件描述符集合後,又要將它從內核空間拷貝到用戶空間。發生2次文件描述符集合的拷貝 -
雖然由原來在
用戶空間發起輪詢優化成了在內核空間發起輪詢但select不會告訴用戶線程到底是哪些Socket上發生了IO就緒事件,只是對IO就緒的Socket作了標記,用戶線程依然要遍歷文件描述符集合去查找具體IO就緒的Socket。時間複雜度依然為O(n)。
大部分情況下,網路連接並不總是活躍的,如果
select監聽了大量的客戶端連接,只有少數的連接活躍,然而使用輪詢的這種方式會隨著連接數的增大,效率會越來越低。
-
內核會對原始的文件描述符集合進行修改。導致每次在用戶空間重新發起select調用時,都需要對文件描述符集合進行重置。 -
BitMap結構的文件描述符集合,長度為固定的1024,所以只能監聽0~1023的文件描述符。 -
select系統調用 不是線程安全的。
以上select的不足所產生的性能開銷都會隨著併發量的增大而線性增長。
很明顯select也不能解決C10K問題,只適用於1000個左右的併發連接場景。
poll
poll相當於是改進版的select,但是工作原理基本和select沒有本質的區別。
int poll(struct pollfd *fds, unsigned int nfds, int timeout)
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要監聽的事件 */
short revents; /* 實際發生的事件 由內核修改設置 */
};
select中使用的文件描述符集合是採用的固定長度為1024的BitMap結構的fd_set,而poll換成了一個pollfd 結構沒有固定長度的數組,這樣就沒有了最大描述符數量的限制(當然還會受到系統文件描述符限制)
poll只是改進了select只能監聽1024個文件描述符的數量限制,但是並沒有在性能方面做出改進。和select上本質並沒有多大差別。
-
同樣需要在
內核空間和用戶空間中對文件描述符集合進行輪詢,查找出IO就緒的Socket的時間複雜度依然為O(n)。 -
同樣需要將
包含大量文件描述符的集合整體在用戶空間和內核空間之間來回覆制,無論這些文件描述符是否就緒。他們的開銷都會隨著文件描述符數量的增加而線性增大。 -
select,poll在每次新增,刪除需要監聽的socket時,都需要將整個新的socket集合全量傳至內核。
poll同樣不適用高併發的場景。依然無法解決C10K問題。
epoll
通過上邊對select,poll核心原理的介紹,我們看到select,poll的性能瓶頸主要體現在下麵三個地方:
-
因為內核不會保存我們要監聽的
socket集合,所以在每次調用select,poll的時候都需要傳入,傳出全量的socket文件描述符集合。這導致了大量的文件描述符在用戶空間和內核空間頻繁的來回覆制。 -
由於內核不會通知具體
IO就緒的socket,只是在這些IO就緒的socket上打好標記,所以當select系統調用返回時,在用戶空間還是需要完整遍歷一遍socket文件描述符集合來獲取具體IO就緒的socket。 -
在
內核空間中也是通過遍歷的方式來得到IO就緒的socket。
下麵我們來看下epoll是如何解決這些問題的。在介紹epoll的核心原理之前,我們需要介紹下理解epoll工作過程所需要的一些核心基礎知識。
Socket的創建
服務端線程調用accept系統調用後開始阻塞,當有客戶端連接上來並完成TCP三次握手後,內核會創建一個對應的Socket作為服務端與客戶端通信的內核介面。
在Linux內核的角度看來,一切皆是文件,Socket也不例外,當內核創建出Socket之後,會將這個Socket放到當前進程所打開的文件列表中管理起來。
下麵我們來看下進程管理這些打開的文件列表相關的內核數據結構是什麼樣的?在瞭解完這些數據結構後,我們會更加清晰的理解Socket在內核中所發揮的作用。並且對後面我們理解epoll的創建過程有很大的幫助。
進程中管理文件列表結構
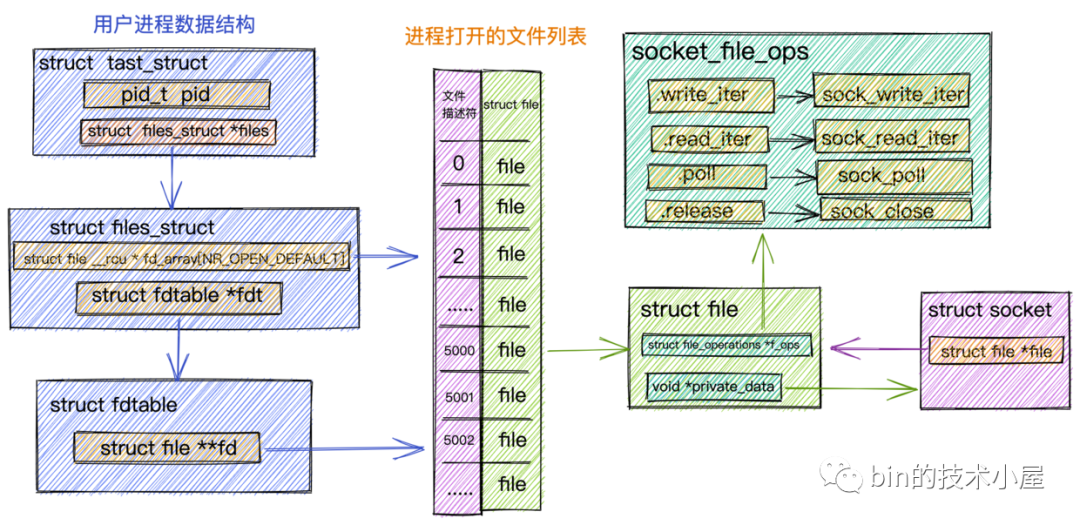
struct tast_struct是內核中用來表示進程的一個數據結構,它包含了進程的所有信息。本小節我們只列出和文件管理相關的屬性。
其中進程內打開的所有文件是通過一個數組fd_array來進行組織管理,數組的下標即為我們常提到的文件描述符,數組中存放的是對應的文件數據結構struct file。每打開一個文件,內核都會創建一個struct file與之對應,併在fd_array中找到一個空閑位置分配給它,數組中對應的下標,就是我們在用戶空間用到的文件描述符。
對於任何一個進程,預設情況下,文件描述符
0表示stdin 標準輸入,文件描述符1表示stdout 標準輸出,文件描述符2表示stderr 標準錯誤輸出。
進程中打開的文件列表fd_array定義在內核數據結構struct files_struct中,在struct fdtable結構中有一個指針struct fd **fd指向fd_array。
由於本小節討論的是內核網路系統部分的數據結構,所以這裡拿Socket文件類型來舉例說明:
用於封裝文件元信息的內核數據結構struct file中的private_data指針指向具體的Socket結構。
struct file中的file_operations屬性定義了文件的操作函數,不同的文件類型,對應的file_operations是不同的,針對Socket文件類型,這裡的file_operations指向socket_file_ops。
我們在
用戶空間對Socket發起的讀寫等系統調用,進入內核首先會調用的是Socket對應的struct file中指向的socket_file_ops。
比如:對Socket發起write寫操作,在內核中首先被調用的就是socket_file_ops中定義的sock_write_iter。Socket發起read讀操作內核中對應的則是sock_read_iter。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
Socket內核結構
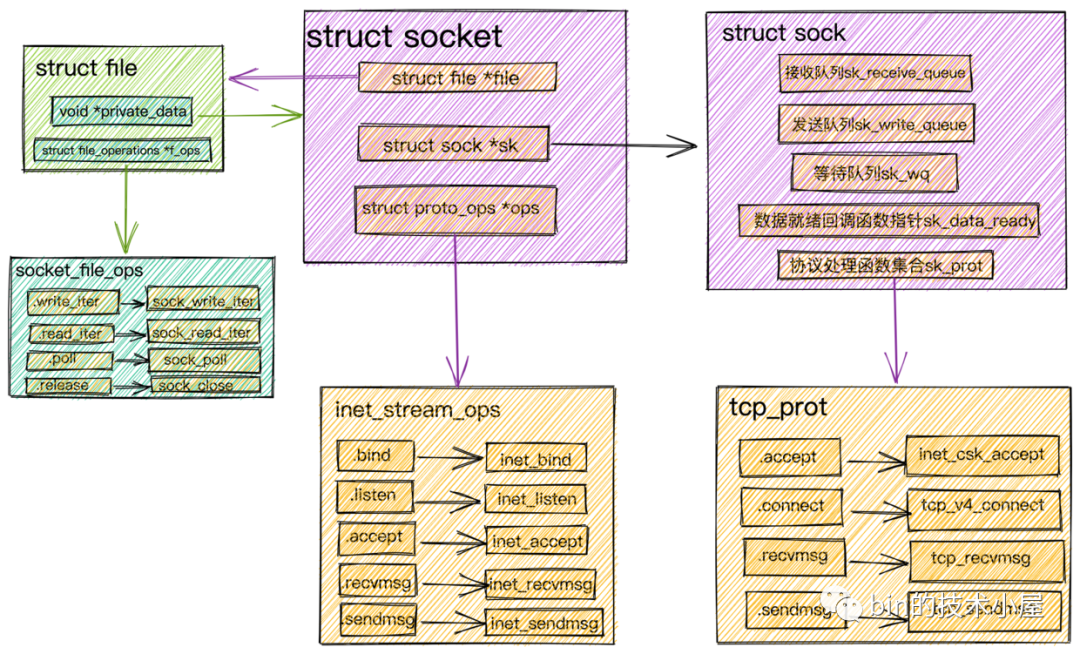
在我們進行網路程式的編寫時會首先創建一個Socket,然後基於這個Socket進行bind,listen,我們先將這個Socket稱作為監聽Socket。
- 當我們調用
accept後,內核會基於監聽Socket創建出來一個新的Socket專門用於與客戶端之間的網路通信。並將監聽Socket中的Socket操作函數集合(inet_stream_ops)ops賦值到新的Socket的ops屬性中。
const struct proto_ops inet_stream_ops = {
.bind = inet_bind,
.connect = inet_stream_connect,
.accept = inet_accept,
.poll = tcp_poll,
.listen = inet_listen,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
......
}
這裡需要註意的是,
監聽的 socket和真正用來網路通信的Socket,是兩個 Socket,一個叫作監聽 Socket,一個叫作已連接的Socket。
- 接著內核會為
已連接的Socket創建struct file並初始化,並把Socket文件操作函數集合(socket_file_ops)賦值給struct file中的f_ops指針。然後將struct socket中的file指針指向這個新分配申請的struct file結構體。
內核會維護兩個隊列:
- 一個是已經完成
TCP三次握手,連接狀態處於established的連接隊列。內核中為icsk_accept_queue。- 一個是還沒有完成
TCP三次握手,連接狀態處於syn_rcvd的半連接隊列。
- 然後調用
socket->ops->accept,從Socket內核結構圖中我們可以看到其實調用的是inet_accept,該函數會在icsk_accept_queue中查找是否有已經建立好的連接,如果有的話,直接從icsk_accept_queue中獲取已經創建好的struct sock。並將這個struct sock對象賦值給struct socket中的sock指針。
struct sock在struct socket中是一個非常核心的內核對象,正是在這裡定義了我們在介紹網路包的接收發送流程中提到的接收隊列,發送隊列,等待隊列,數據就緒回調函數指針,內核協議棧操作函數集合
- 根據創建
Socket時發起的系統調用sock_create中的protocol參數(對於TCP協議這裡的參數值為SOCK_STREAM)查找到對於 tcp 定義的操作方法實現集合inet_stream_ops和tcp_prot。並把它們分別設置到socket->ops和sock->sk_prot上。
這裡可以回看下本小節開頭的《Socket內核結構圖》捋一下他們之間的關係。
socket相關的操作介面定義在inet_stream_ops函數集合中,負責對上給用戶提供介面。而socket與內核協議棧之間的操作介面定義在struct sock中的sk_prot指針上,這裡指向tcp_prot協議操作函數集合。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.backlog_rcv = tcp_v4_do_rcv,
......
}
之前提到的對
Socket發起的系統IO調用,在內核中首先會調用Socket的文件結構struct file中的file_operations文件操作集合,然後調用struct socket中的ops指向的inet_stream_opssocket操作函數,最終調用到struct sock中sk_prot指針指向的tcp_prot內核協議棧操作函數介面集合。
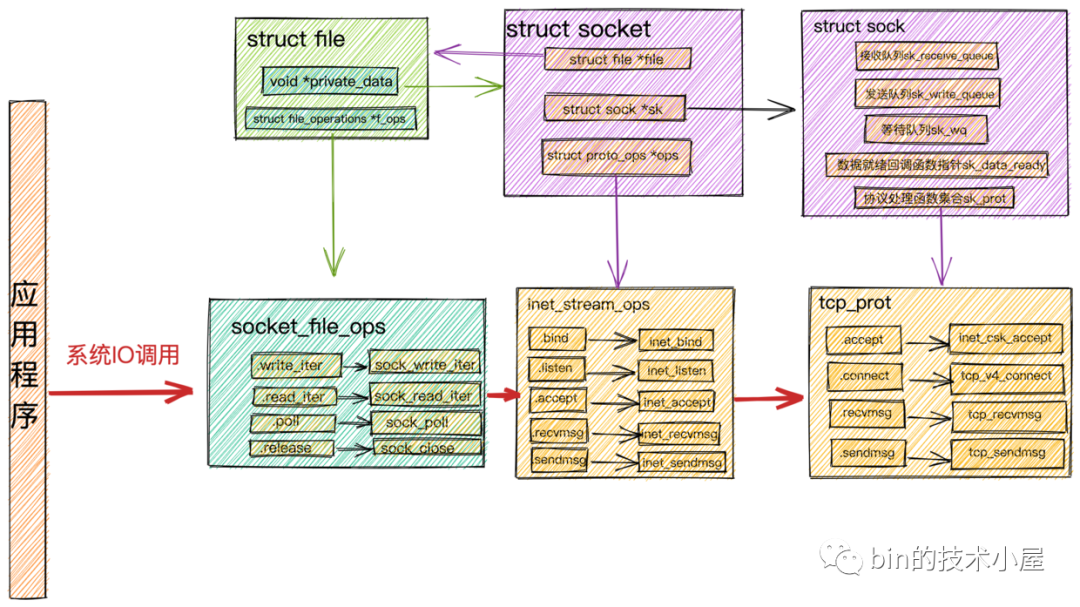
-
將
struct sock對象中的sk_data_ready函數指針設置為sock_def_readable,在Socket數據就緒的時候內核會回調該函數。 -
struct sock中的等待隊列中存放的是系統IO調用發生阻塞的進程fd,以及相應的回調函數。記住這個地方,後邊介紹epoll的時候我們還會提到!
- 當
struct file,struct socket,struct sock這些核心的內核對象創建好之後,最後就是把socket對象對應的struct file放到進程打開的文件列表fd_array中。隨後系統調用accept返回socket的文件描述符fd給用戶程式。
阻塞IO中用戶進程阻塞以及喚醒原理
在前邊小節我們介紹阻塞IO的時候提到,當用戶進程發起系統IO調用時,這裡我們拿read舉例,用戶進程會在內核態查看對應Socket接收緩衝區是否有數據到來。
Socket接收緩衝區有數據,則拷貝數據到用戶空間,系統調用返回。Socket接收緩衝區沒有數據,則用戶進程讓出CPU進入阻塞狀態,當數據到達接收緩衝區時,用戶進程會被喚醒,從阻塞狀態進入就緒狀態,等待CPU調度。
本小節我們就來看下用戶進程是如何阻塞在Socket上,又是如何在Socket上被喚醒的。理解這個過程很重要,對我們理解epoll的事件通知過程很有幫助
- 首先我們在用戶進程中對
Socket進行read系統調用時,用戶進程會從用戶態轉為內核態。 - 在進程的
struct task_struct結構找到fd_array,並根據Socket的文件描述符fd找到對應的struct file,調用struct file中的文件操作函數結合file_operations,read系統調用對應的是sock_read_iter。 - 在
sock_read_iter函數中找到struct file指向的struct socket,並調用socket->ops->recvmsg,這裡我們知道調用的是inet_stream_ops集合中定義的inet_recvmsg。 - 在
inet_recvmsg中會找到struct sock,並調用sock->skprot->recvmsg,這裡調用的是tcp_prot集合中定義的tcp_recvmsg函數。
整個調用過程可以參考上邊的《系統IO調用結構圖》
熟悉了內核函數調用棧後,我們來看下系統IO調用在tcp_recvmsg內核函數中是如何將用戶進程給阻塞掉的
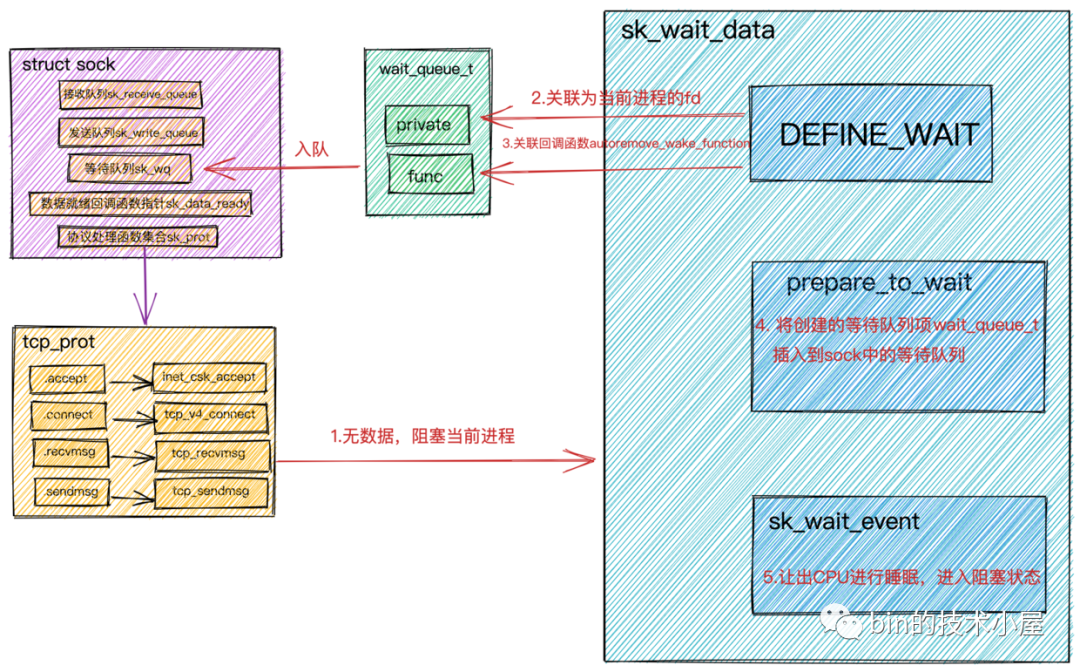
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
.................省略非核心代碼...............
//訪問sock對象中定義的接收隊列
skb_queue_walk(&sk->sk_receive_queue, skb) {
.................省略非核心代碼...............
//沒有收到足夠數據,調用sk_wait_data 阻塞當前進程
sk_wait_data(sk, &timeo);
}
int sk_wait_data(struct sock *sk, long *timeo)
{
//創建struct sock中等待隊列上的元素wait_queue_t
//將進程描述符和回調函數autoremove_wake_function關聯到wait_queue_t中
DEFINE_WAIT(wait);
// 調用 sk_sleep 獲取 sock 對象下的等待隊列的頭指針wait_queue_head_t
// 調用prepare_to_wait將新創建的等待項wait_queue_t插入到等待隊列中,並將進程狀態設置為可打斷 INTERRUPTIBLE
prepare_to_wait(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA, &sk->sk_socket->flags);
// 通過調用schedule_timeout讓出CPU,然後進行睡眠,導致一次上下文切換
rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue));
...
- 首先會在
DEFINE_WAIT中創建struct sock中等待隊列上的等待類型wait_queue_t。
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function) \
wait_queue_t name = { \
.private = current, \
.func = function, \
.task_list = LIST_HEAD_INIT((name).task_list), \
}
等待類型wait_queue_t中的private用來關聯阻塞在當前socket上的用戶進程fd。func用來關聯等待項上註冊的回調函數。這裡註冊的是autoremove_wake_function。
-
調用
sk_sleep(sk)獲取struct sock對象中的等待隊列頭指針wait_queue_head_t。 -
調用
prepare_to_wait將新創建的等待項wait_queue_t插入到等待隊列中,並將進程設置為可打斷INTERRUPTIBL。 -
調用
sk_wait_event讓出CPU,進程進入睡眠狀態。
用戶進程的阻塞過程我們就介紹完了,關鍵是要理解記住struct sock中定義的等待隊列上的等待類型wait_queue_t的結構。後面epoll的介紹中我們還會用到它。
下麵我們接著介紹當數據就緒後,用戶進程是如何被喚醒的
在本文開始介紹《網路包接收過程》這一小節中我們提到:
- 當網路數據包到達網卡時,網卡通過
DMA的方式將數據放到RingBuffer中。 - 然後向CPU發起硬中斷,在硬中斷響應程式中創建
sk_buffer,並將網路數據拷貝至sk_buffer中。 - 隨後發起軟中斷,內核線程
ksoftirqd響應軟中斷,調用poll函數將sk_buffer送往內核協議棧做層層協議處理。 - 在傳輸層
tcp_rcv 函數中


