#RDD(2) ##RDD轉換運算元 RDD根據數據處理方式的不同將運算元整體上分為Value類型、雙Value類型、Key-Value類型 ###value類型 ####map 函數簽名 def map[U:ClassTag](f:T=>U):RDD[U] 函數說明 將處理的數據逐條進行映射轉換,這裡 ...
RDD(2)
RDD轉換運算元
RDD根據數據處理方式的不同將運算元整體上分為Value類型、雙Value類型、Key-Value類型
value類型
map
函數簽名
def map[U:ClassTag](f:T=>U):RDD[U]
函數說明
將處理的數據逐條進行映射轉換,這裡的轉換可以是類型的轉換,也可以是值的轉換
e.g.1
val source = sparkContext.parallelize(Seq(1, 2, 3, 4, 5, 6))
val map = source.map(item => item*10)
val result = map.collect()
result.foreach(println)
e.g.2
val data1: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4), 2)
// val data2: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4), 1)
val rdd1: RDD[Int] = data1.map(
num => {
println(">>>" + num)
num
}
)
val rdd2: RDD[Int] = rdd1.map(
num => {
println("<<<" + num)
num
}
)
rdd2.collect()
note:
RDD計算同一分區內數據有序,不同分區數據無序
(func)從伺服器日誌數據apache.log中獲取用戶請求URL資源路徑(例):
apache.log
83.149.9.216 - - 17/05/2015:10:05:12 +0000 GET /presentations/logstash-monitorama-2013/plugin/zoom-js/zoom.js
83.149.9.216 - - 17/05/2015:10:05:07 +0000 GET /presentations/logstash-monitorama-2013/plugin/notes/notes.js
83.149.9.216 - - 17/05/2015:10:05:34 +0000 GET /presentations/logstash-monitorama-2013/images/sad-medic.png
code:
val data = sparkContext.textFile("input/apache.log")
val clean = data.map{
item => {
item.split(" ")(6)
}
}
clean.foreach(println(_))
mapPartitions
函數簽名
def mapPartitions[U:ClassTag](
f:Iterator[T] =>Iterator[U],
preservesPartitioning:Boolean = false):RDD[U]
函數說明
將待處理的數據以分區為單位發送到計算節點進行任意的處理(過濾數據亦可)
note: 函數會將整個分區的數據載入到記憶體中進行引用。記憶體較小、數據量較大的情況下,容易出現記憶體溢出。
val dataRDD1: RDD[Int]= dataRDD.mapPartitions(
datas =>{ //遍歷每個分區進行操作
datas.filter(_==2) //過濾每個分區中值為2的數據
}
)
(func)獲取每個數據分區的最大值
code:
object getMaxFromArea {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Max")
val sparkContext: SparkContext = new SparkContext(sparkConf)
val source: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4, 5, 6), 2)
val mapPartition: RDD[Int] = source.mapPartitions(p => List(p.max).iterator)
//多個分區獲取最大值,使用迭代器
val result: Array[Int] = mapPartition.collect()
result.foreach(println)
sparkContext.stop()
}
}
comparison:
map和mapPartitions的區別
數據處理角度
Map 運算元是分區內一個數據一個數據的執行,類似於串列操作。而 mapPartitions 運算元
是以分區為單位進行批處理操作。
功能的角度
Map 運算元主要目的將數據源中的數據進行轉換和改變。但是不會減少或增多數據。
MapPartitions 運算元需要傳遞一個迭代器,返回一個迭代器,沒有要求的元素的個數保持不變,
所以可以增加或減少數據
性能的角度
Map 運算元因為類似於串列操作,所以性能比較低,而是 mapPartitions 運算元類似於批處
理,所以性能較高。但是 mapPartitions 運算元會長時間占用記憶體,那麼這樣會導致記憶體可能
不夠用,出現記憶體溢出的錯誤。所以在記憶體有限的情況下,不推薦使用。使用 map 操作
mapPartitionsWithIndex
函數簽名
def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]
函數說明
將待處理的數據以分區為單位發送到計算節點進行處理,這裡的處理是指可以進行任意的處理,哪怕是過濾數據,在處理時同時可以獲取當前分區索引。
val dataRDD1 = dataRDD.mapPartitionsWithIndex(
(index, datas) => {
datas.map(index, _)
}
)
(func)獲取第二個數據分區的數據
code:
object getSecondArea {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Sec")
val sparkContext: SparkContext = new SparkContext(sparkConf)
val source: RDD[Int] = sparkContext.parallelize(List(1, 2, 3, 4, 5, 6), 2)
val mapPartitionsWithIndex: RDD[Int] = source.mapPartitionsWithIndex(
(index, data) => {
if (index == 1) {
data
} else {
Nil.iterator
}
}
)
val result: Array[Int] = mapPartitionsWithIndex.collect()
result.foreach(println(_))
sparkContext.stop()
}
}
(func)獲取每個數據及其對應分區索引
code:
object getDataAndIndexOfArea {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Data")
val sparkContext: SparkContext = new SparkContext(conf)
val data: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4, 5, 6))
val dataAndIndex: RDD[(Int, Int)] = data.mapPartitionsWithIndex(
(index, iter) => {
iter.map(data => (data, index))
}
)
val result: Array[(Int, Int)] = dataAndIndex.collect()
result.foreach(println)
}
}
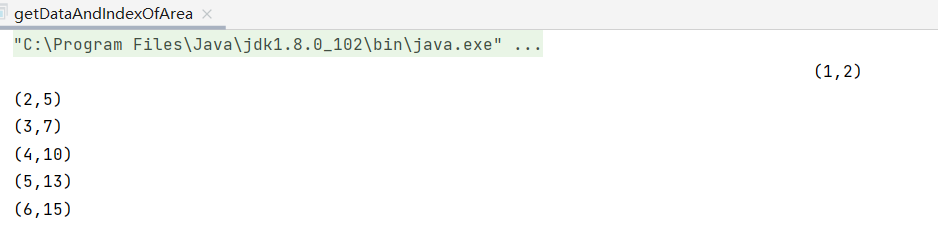
note:這裡沒有自定義分區數量,故預設最多分區數(與機器邏輯處理器數量相關),數據隨機存儲在這些分區中
flatMap
函數簽名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
函數說明
將處理的數據進行扁平化後再進行映射處理,所以運算元也稱作扁平映射
val dataRDD = sparkContext.makeRDD(
List(List(1,2),List(3,4)),1)
val dataRDD1 = dataRDD.flatMap(list => list)
1
2
3
4
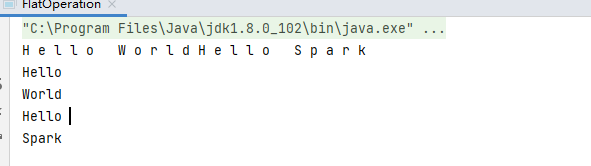
(func)將List("Hello World","Hello Spark")進行扁平化操作
1)字元扁平化
val data = sparkContext.makeRDD(List("Hello World","Hello Spark"),1)
val rdd: RDD[Char] = data.flatMap(list => list)
val result1: Array[Char] = rdd.collect()
result1.foreach(item => print(item+" "))
2)字元串扁平化
val data1: RDD[String] = sparkContext.parallelize(List("Hello World", "Hello Spark"), 1)
val rdd1: RDD[String] = data1.flatMap(list => {
list.split(" ")
})
val result2: Array[String] = rdd1.collect()
result2.foreach(item => println(item + " "))
(func)將List(List(1,2),3,List(4,5))進行扁平化操作
thinking:List(List(1,2),3,List(4,5)) => List(list,int,list) => RDD[Any]
當數據的格式不能夠滿足時我們可以使用match進行格式的匹配(類似java中的switch,case)
code:
val data2: RDD[Any] = sparkContext.parallelize(List(List(1, 2), 3, List(4, 5)))
val rdd2: RDD[Any] = data2.flatMap {
// 完整代碼:
// dat =>{
// dat match {
// case list: List[_] => list
// case int => List(int)
// }
// }
case list: List[_] => list
case int => List(int)
}
val result3: Array[Any] = rdd2.collect()
result3.foreach(item => print(item + " "))