
前言 本文將以 C# 語言來實現一個簡單的布隆過濾器,為簡化說明,設計得很簡單,僅供學習使用。 感謝@時總百忙之中的指導。 布隆過濾器簡介 布隆過濾器(Bloom filter)是一種特殊的 Hash Table,能夠以較小的存儲空間較快地判斷出數據是否存在。常用於允許一定誤判率的數據過濾及防止緩存 ...
前言
本文將以 C# 語言來實現一個簡單的布隆過濾器,為簡化說明,設計得很簡單,僅供學習使用。
感謝@時總百忙之中的指導。
布隆過濾器簡介
布隆過濾器(Bloom filter)是一種特殊的 Hash Table,能夠以較小的存儲空間較快地判斷出數據是否存在。常用於允許一定誤判率的數據過濾及防止緩存擊穿及等場景。
相較於 .NET 中的 HashSet 這樣傳統的 Hash Table,存在以下的優劣勢。
優勢:
- 占用的存儲空間較小。不需要像 HashSet 一樣存儲 Key 的原始數據。
劣勢:
- 存在誤判率,過濾器認為不存在的數據一定不存在,但是認為存在的數據不一定真的存在。這個和布隆過濾器的實現方式有關。
- 不支持數據的刪除,下文會講為什麼不支持刪除。
數據的存儲
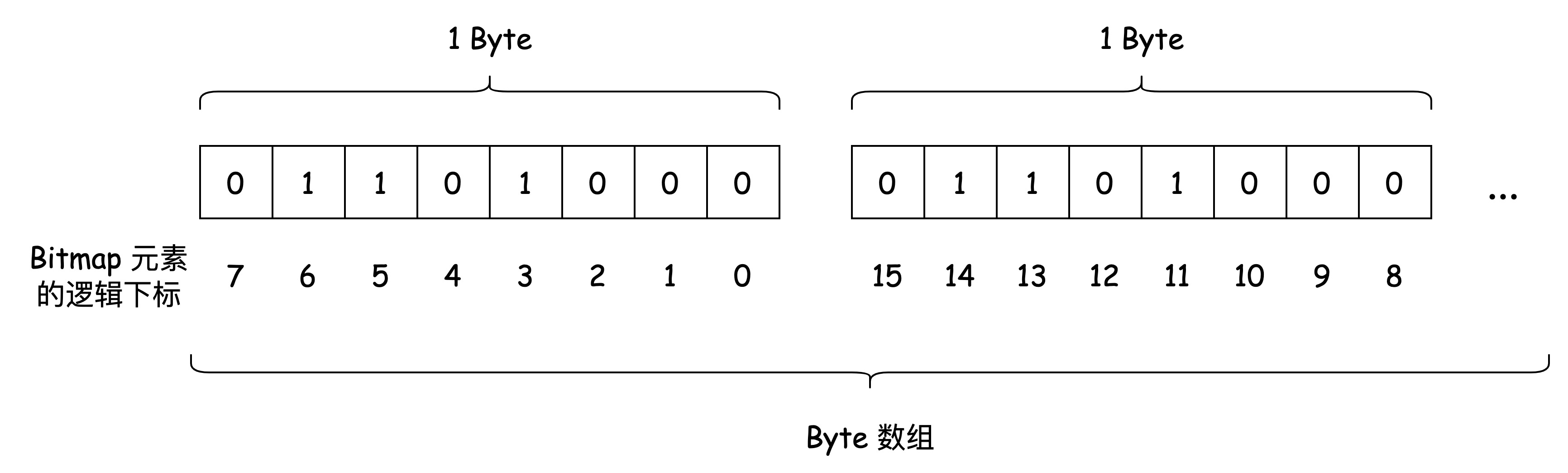
布隆過濾器的數據保存在 點陣圖(Bitmap)上。Bitmap 簡而言之是二進位位(bit)的數組。Hash Table 保存每個元素的位置,我們稱之為 桶(bucket), Bitmap 上的每一位就是布隆過濾器的 bucket。
布隆過濾器的每一個 bucket 只能存儲 0 或 1。數據插入時,布隆過濾器會通過 Hash 函數計算出插入的 key 對應的 bucket,並將該 bucket 設置為 1。
查詢時,再次根據 Hash 函數計算出 key 對應的 bucket,如果 bucket 的值是 1,則認為 key 存在。
Hash 衝突的解決方案
布隆過濾器使用了 Hash 函數,自然也逃不過 Hash 衝突的問題。對布隆過濾器而言,發生 Hash 衝突也就意味著會發生誤判。
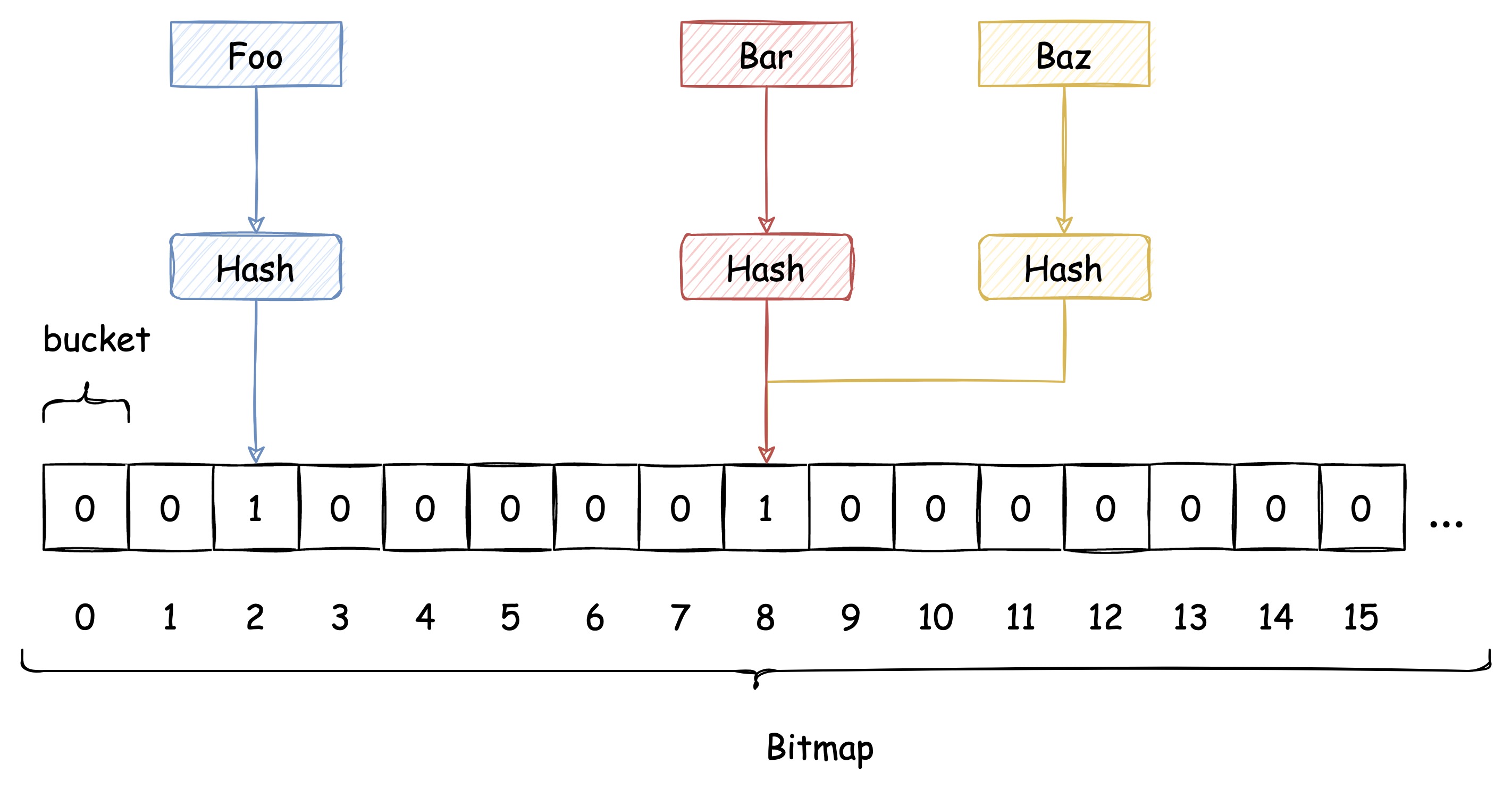
傳統 Hash 演算法解決 Hash 衝突的方式有 開放定址法、鏈表法等。而布隆過濾器解決 Hash 衝突的方式比較特殊,它使用了多個 Hash 函數來解決衝突問題。
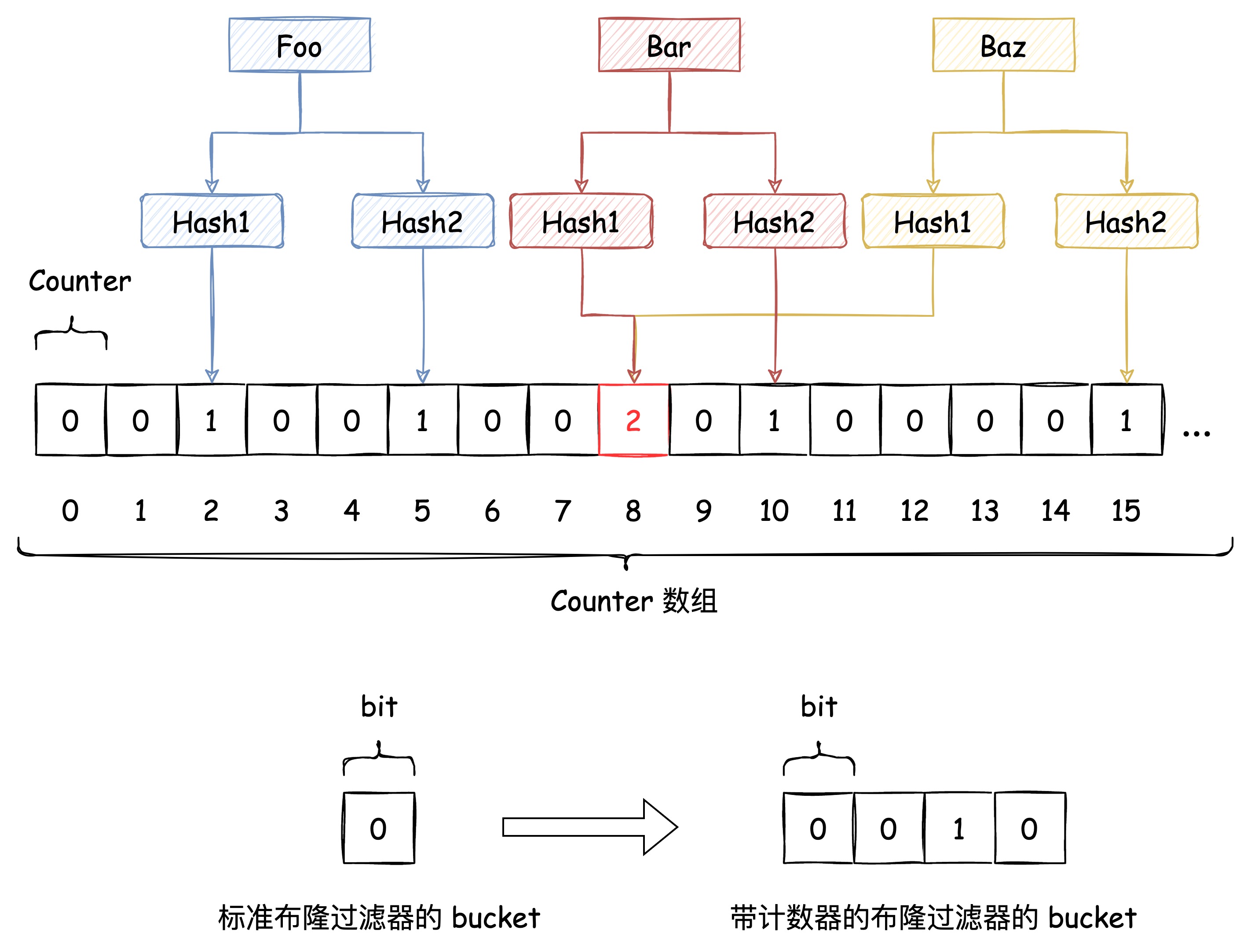
下圖中插入布隆過濾器的 Bar 和 Baz 經過 Hash1 計算出的位置是同一個,但 Hash2 計算出的位置是不一樣的,Bar 和 Baz 得以區分。
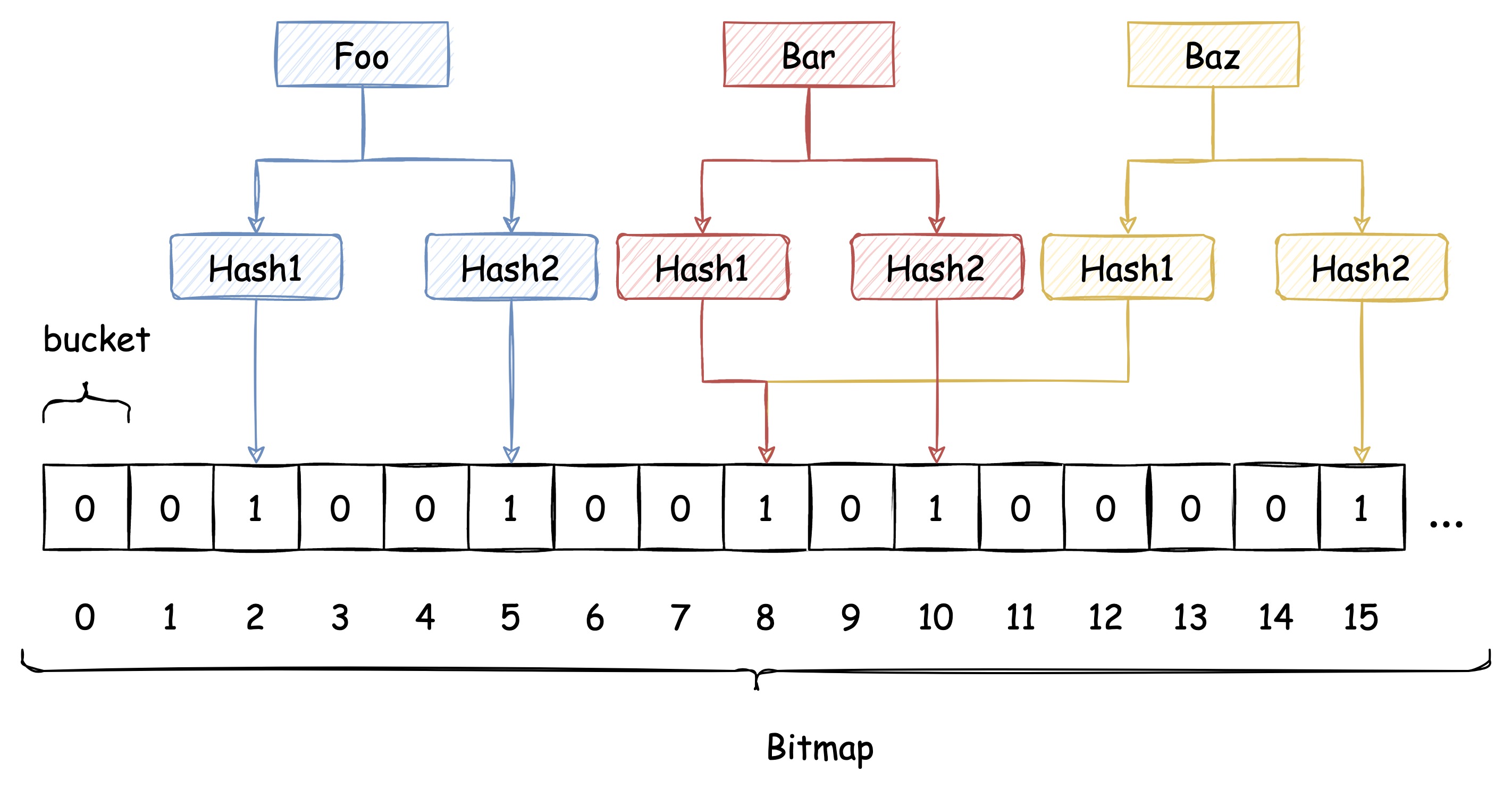
即使布隆過濾器使用了這種方式來解決 Hash衝突,衝突的可能性依舊存在,如下圖所示:
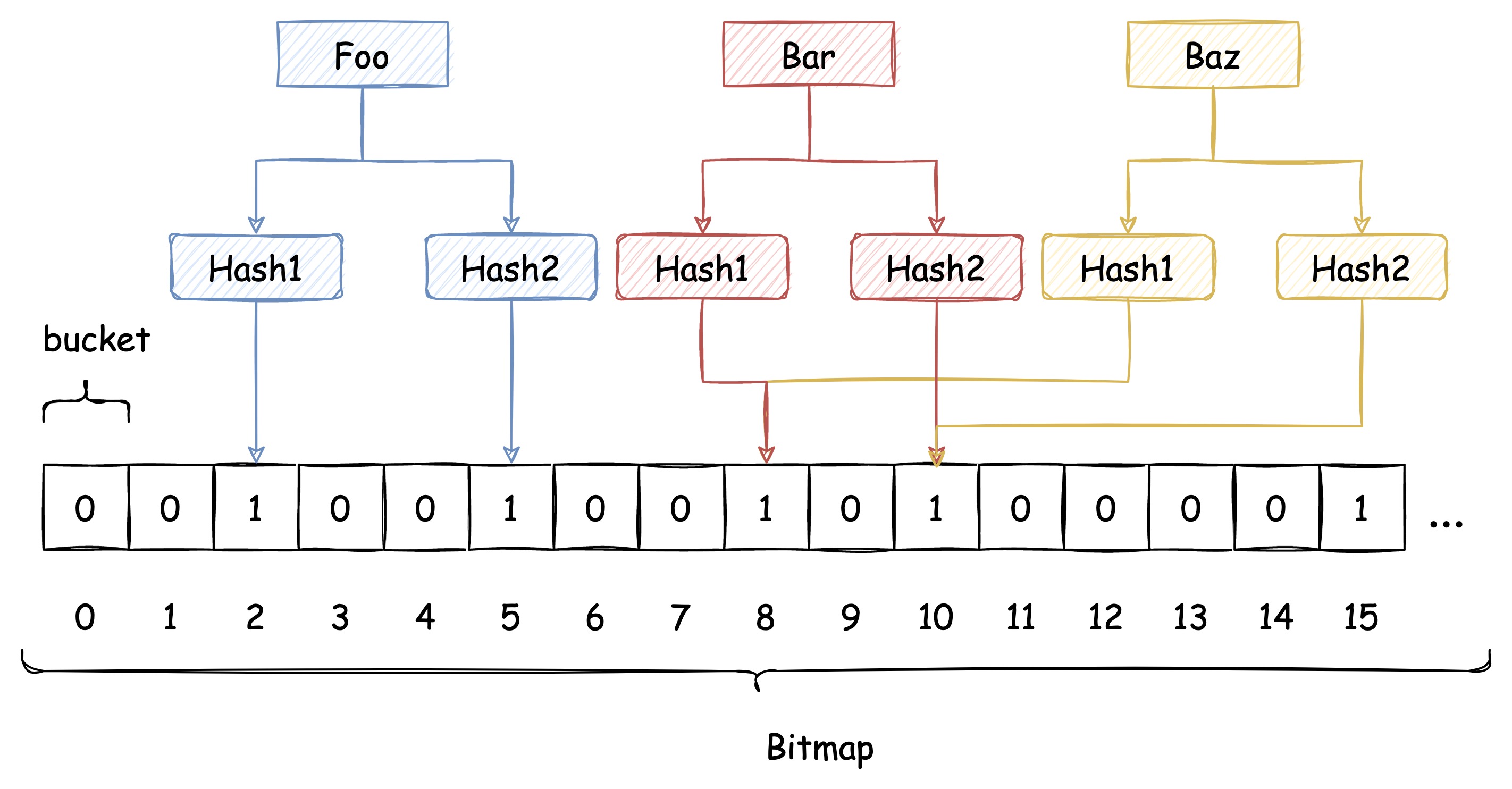
由於布隆過濾器不保留插入的 Key 的原始值,Hash 衝突是無法避免的。我們只能通過增加 Hash 函數的數量來減少衝突的概率,也就是減少誤判率。
假設布隆過濾器有 m 個 bucket,包含 k 個哈希函數,已經插入了 n 個 key。經數學推導可得誤判率 ε 的公式如下:
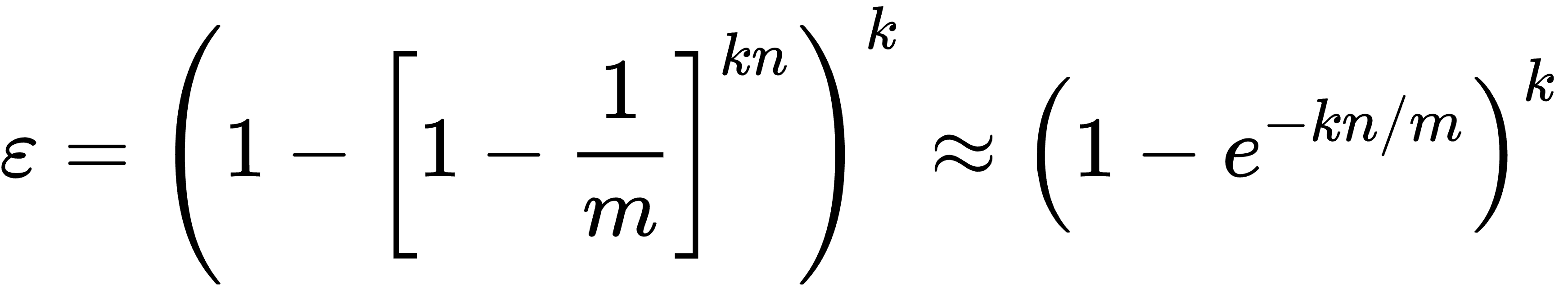
具體推斷過程可參考 https://en.wikipedia.org/wiki/Bloom_filter。
布隆過濾器的誤判概率大致和 已經插入的 key 的數量 n 成正比,和 hash函數數量 k、bucket 數 m 成反比。為了減少誤判率,我們可以增加 m 或 增加 k,增加 m 意味著過濾器占用存儲空間會增加,增加 k 則意味著插入和查詢時的效率會降低。
為什麼布隆過濾器不支持刪除
布隆過濾器通過多個 Hash 函數來解決衝突的設計,也意味著多著插入元素可能會共用同樣的 bucket,刪掉一個元素的同時,也會被其他元素的一部分 bucket 給刪掉。因此基於 Bitmap 實現的布隆過濾器是不支持刪除的。
用 C# 實現 Bitmap
在實現布隆過濾器之前,我們首先要實現一個 Bitmap。
在 C# 中,我們並不能直接用 bit 作為最小的數據存儲單元,但藉助位運算的話,我們就可以基於其他數據類型來表示,比如 byte。下文用 byte 作為例子來描述 Bitmap 的實現,但不僅限於 byte,int、long 等等也是可以的。
位運算
下麵是 C# 中位運算的簡單介紹:
| 符號 | 描述 | 運算規則 |
|---|---|---|
| & | 與 | 兩個位都為1時,結果才為1 |
| | | 或 | 兩個位都為0時,結果才為0 |
| ^ | 異或 | 兩個位相同為0,相異為1 |
| ~ | 取反 | 0變1,1變0 |
| << | 左移 | 各二進位全部左移若幹位,低位補0 |
| >> | 右移 | 各二進位全部右移若幹位,高位補0 |
一般來說,我們要進行位運算計算的數據通常都是由多個二進位組成的。對兩個數字使用 &、|、^ 這三個運算符時,需要對齊兩個數字的右邊,一位位地進行計算。
// 0b 代表值用二進位表示數字
short a = 0b0111111111111001;
byte b = 0b011111111;
short c = (short)(a & b); // 0b0111111111111001
short d = (short)(a | b); // 0b0111111111111111
short e = (short)(a ^ b); // 0b0000000000000110
byte f = (byte)~b; 0b011111111;
short g = (short)(b << 1); // 0b0000000111111111;
short h = (short)(b >> 1); // 0b0000000001111111;
利用位運算創建 Bitmap
藉助 byte 實現 Bitmap,也就是要能夠修改和查看 byte 上的每一個 bit 的值,同時,修改要能夠實現冪等。
- 指定位設置成 1
按前面說的位運算的規則,是不能夠單獨修改 bit 序列中某一位的。位運算需要從右到左一對對計算。
使用|可以實現這個功能。假設我們要改變從右開始下標為 3(初始位置0) 的 bit 的值,則需要準備一個該位置為 1,其他位置都是 0 的 bit 序列,與要改變的 bit 序列進行|運算。
// 為了將 a 的右邊數起第 3 位改成 1,需要準備一個 b
byte a = 0b010100010;
byte b = 1 << 3; // 0b000001000
a |= b; // 0b010101010
- 指定位設置成 0
和設置成 1 正好相反,需要準備一個指定位置為 0,其他位置都是 1 的 bit 序列,與要改變的 bit 序列進行&運算。
byte a = 0b010101010;
byte b = 1 << 3; // 0b000001000
b = ~b; // 0b111110111
a &= b; // 0b010100010
- 查看指定位的值
利用 & 運算符,只要計算結果不為 0,就代表指定位置的值為 1。
byte a = 0b010101010;
byte b = 1 << 3; // 0b000001000;
a &= b; // 0b000001000;
瞭解了基本的操作之後,我們把數據存儲到 byte 數組上。
class Bitmap
{
private readonly byte[] _bytes;
private readonly long _capacity;
public Bitmap(long capacity)
{
_capacity = capacity;
_bytes = new byte[_capacity / 8 + 1];
}
public long Capacity => _capacity;
public void Set(long index)
{
if (index >= _capacity)
{
throw new IndexOutOfRangeException();
}
// 計算出數據存在第幾個 byte 上
long byteIndex = index / 8;
// 計算出數據存在第幾個 bit 上
int bitIndex = (int)(index % 8);
_bytes[byteIndex] |= (byte)(1 << bitIndex);
}
public void Remove(long index)
{
if (index >= _capacity)
{
throw new IndexOutOfRangeException();
}
long byteIndex = index / 8;
int bitIndex = (int)(index % 8);
_bytes[byteIndex] &= (byte)~(1 << bitIndex);
}
public bool Get(long index)
{
if (index >= _capacity)
{
throw new IndexOutOfRangeException();
}
long byteIndex = index / 8;
int bitIndex = (int)(index % 8);
return (_bytes[byteIndex] & (byte)(1 << bitIndex)) != 0;
}
}
用 C# 實現 布隆過濾器
有了 Bitmap,我們再把 Hash 函數的實現準備好,一個簡單的布隆過濾器就可以完成了。這裡,我們參考 guava 這個 java 庫的實現。
https://github.com/google/guava/blob/master/guava/src/com/google/common/hash/BloomFilter.java
MurmurHash3 的使用
我們使用和 guava 一樣的 MurmurHash3 作為 Hash 函數的實現。
下麵是筆者在 github 上找到的一個可用實現。
https://github.com/darrenkopp/murmurhash-net
使用這個庫,我們可以將任意長的 byte 數組轉換成 128 位的二進位位,也就是 16 byte。
byte[] data = Guid.NewGuid().ToByteArray();
// returns a 128-bit algorithm using "unsafe" code with default seed
HashAlgorithm murmur128 = MurmurHash.Create128(managed: false);
byte[] hash = murmur128.ComputeHash(data);
將任意類型的 key 轉換為 byte 數組
Funnel 與 Sink 的定義
我們需要將各種類型 key 轉換成 MurmurHash 能夠直接處理的 byte 數組。為此我們參考 guava 引入下麵兩個概念:
-
Funnel:將各類數據轉換成 byte 數組,包括 int、bool、string 等built-in 類型及自定義的複雜類型。
-
Sink:Funnel 的核心組件,作為數據的緩衝區。Funnel 在將自定義的複雜類型實例轉換成 byte 數組時,就需要將數據拆解分批寫入 sink。
Funnel 可以定義成如下的委托,接受原始值,並將其寫入 sink 中。
delegate void Funnel<in T>(T from, ISink sink);
Sink 將不同類型的數據轉換成 byte 數組並彙總到一起。
interface ISink
{
ISink PutByte(byte b);
ISink PutBytes(byte[] bytes);
ISink PutBool(bool b);
ISink PutShort(short s);
ISink PutInt(int i);
ISink PutString(string s, Encoding encoding);
ISink PutObject<T>(T obj, Funnel<T> funnel);
/// ... 其他 built-in 類型,讀者可自行補充
}
簡單的 Funnel 實現如下所示:
public class Funnels
{
public static Funnel<string> StringFunnel = (from, sink) =>
sink.PutString(from, Encoding.UTF8);
public static Funnel<int> IntFunnel = (from, sink) =>
sink.PutInt(from);
}
自定義複雜類型的 Funnel 實現則可以數據拆解分批寫入 sink。複雜類型的實例成員依舊可能是複雜類型,因此我們要在 Sink 上實現一個 PutObject 來提供套娃式拆解。
Funnel<Foo> funnelFoo = (foo, sink) =>
{
sink.PutString(foo.A, Encoding.UTF8);
sink.PutInt(foo.B);
Funnel<Bar> funnelBar = (bar, barSink) => barSink.PutBool(bar.C);
sink.PutObject(foo.Bar, funnelBar);
};
class Foo
{
public string A { get; set; }
public int B { get; set; }
public Bar Bar { get; set; }
}
class Bar
{
public bool C { get; set; }
}
Sink 的實現
Sink 的核心是 byte 數組緩衝區的實現,利用 ArrayPool 我們可以很方便的實現一個 ByteBuffer。
class ByteBuffer : IDisposable
{
private readonly int _capacity;
private readonly byte[] _buffer;
private int _offset;
private bool _disposed;
public ByteBuffer(int capacity)
{
_capacity = capacity;
_buffer = ArrayPool<byte>.Shared.Rent(capacity);
}
public void Put(byte b)
{
CheckInsertable();
_buffer[_offset] = b;
_offset++;
}
public void Put(byte[] bytes)
{
CheckInsertable();
bytes.CopyTo(_buffer.AsSpan(_offset, bytes.Length));
_offset += bytes.Length;
}
public void PutInt(int i)
{
CheckInsertable();
BinaryPrimitives.WriteInt32BigEndian(GetRemainingAsSpan(), i);
_offset += sizeof(int);
}
public void PutShort(short s)
{
CheckInsertable();
BinaryPrimitives.WriteInt32BigEndian(GetRemainingAsSpan(), s);
_offset += sizeof(short);
}
// ... 其他的 primitive type 的實現
public Span<byte> GetBuffer() =>
_buffer.AsSpan(.._offset);
public bool HasRemaining() => _offset < _capacity;
public void Dispose()
{
_disposed = true;
ArrayPool<byte>.Shared.Return(_buffer);
}
private void CheckInsertable()
{
if (_disposed)
{
throw new ObjectDisposedException(typeof(ByteBuffer).FullName);
}
if (_offset >= _capacity)
{
throw new OverflowException("Byte buffer overflow");
}
}
private Span<byte> GetRemainingAsSpan() => _buffer.AsSpan(_offset..);
}
Sink 則是對 ByteBuffer 的進一步封裝,來適配當前使用場景。
class Sink : ISink, IDisposable
{
private readonly ByteBuffer _byteBuffer;
/// <summary>
/// 創建一個新的 <see cref="Sink"/> 實例
/// </summary>
/// <param name="expectedInputSize">預計輸入的單個元素的最大大小</param>
public Sink(int expectedInputSize)
{
_byteBuffer = new ByteBuffer(expectedInputSize);
}
public ISink PutByte(byte b)
{
_byteBuffer.Put(b);
return this;
}
public ISink PutBytes(byte[] bytes)
{
_byteBuffer.Put(bytes);
return this;
}
public ISink PutBool(bool b)
{
_byteBuffer.Put((byte)(b ? 1 : 0));
return this;
}
public ISink PutShort(short s)
{
_byteBuffer.PutShort(s);
return this;
}
public ISink PutInt(int i)
{
_byteBuffer.PutInt(i);
return this;
}
public ISink PutString(string s, Encoding encoding)
{
_byteBuffer.Put(encoding.GetBytes(s));
return this;
}
public ISink PutObject<T>(T obj, Funnel<T> funnel)
{
funnel(obj, this);
return this;
}
public byte[] GetBytes() => _byteBuffer.GetBuffer().ToArray();
public void Dispose()
{
_byteBuffer.Dispose();
}
}
k 個 Hash 函數與 布隆過濾器 實現
上文提到了 布隆過濾器 通過 k 個 hash 函數來解決 hash 衝突問題。實踐中,我們可以把一次 murmur hash 的計算結果(16 byte)拆分為兩部分並轉換為 long 類型(一個 long 是 8 byte)。
這兩部分結果分別保存到 hash1 和 hash2,第 k 個 hash 函數是對 hash1 和 hash2 的重新組合。
hash(k) = hash1 + (k-1) * hash2
public class BloomFilter<T>
{
private readonly int _hashFunctions;
private readonly Funnel<T> _funnel;
private readonly int _expectedInputSize;
private readonly Bitmap _bitmap;
private readonly HashAlgorithm _murmur128;
/// <summary>
/// 創建一個新的 <see cref="BloomFilter"/> 實例
/// </summary>
/// <param name="funnel">與插入元素類型相關的<see cref="Funnel"/>的實現</param>
/// <param name="buckets">BloomFilter 內部 Bitmap 的 bucket 數量,越大,誤判率越低</param>
/// <param name="hashFunctions">hash 函數的數量,越多,誤判率越低</param>
/// <param name="expectedInputSize">預計插入的單個元素的最大大小</param>
public BloomFilter(Funnel<T> funnel, int buckets, int hashFunctions = 2, int expectedInputSize = 128)
{
_hashFunctions = hashFunctions;
_funnel = funnel;
_expectedInputSize = expectedInputSize;
_bitmap = new Bitmap(buckets);
_murmur128 = MurmurHash.Create128(managed: false);
}
public void Add(T item)
{
long bitSize = _bitmap.Capacity;
var (hash1, hash2) = Hash(item);
long combinedHash = hash1;
for (int i = 0; i < _hashFunctions; i++)
{
_bitmap.Set((combinedHash & long.MaxValue) % bitSize);
combinedHash += hash2;
}
}
public bool MightContains(T item)
{
long bitSize = _bitmap.Capacity;
var (hash1, hash2) = Hash(item);
long combinedHash = hash1;
for (int i = 0; i < _hashFunctions; i++)
{
if (!_bitmap.Get((combinedHash & long.MaxValue) % bitSize))
{
return false;
}
combinedHash += hash2;
}
return true;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private (long Hash1, long Hash2) Hash(T item)
{
byte[] inputBytes;
using (var sink = new Sink(_expectedInputSize))
{
sink.PutObject(item, _funnel);
inputBytes = sink.GetBytes();
}
var hashSpan = _murmur128.ComputeHash(inputBytes).AsSpan();
long lowerEight = BinaryPrimitives.ReadInt64LittleEndian(hashSpan.Slice(0,8));
long upperEight = BinaryPrimitives.ReadInt64LittleEndian(hashSpan.Slice(8,8));
return (lowerEight, upperEight);
}
}
擴展
帶計數器的布隆過濾器
上文講到基於 Bitmap 實現的布隆過濾器不支持刪除,但如果把 Bitmap 這個 bit 數組換成 n 個 bit 作為一個bucket的數組,那單個 bucket 就具備了計數能力。這樣刪掉一個元素的時候,就是在這個計數器上減一,藉此能夠在有限的範圍內實現帶刪除功能的布隆過濾器,代價是,存儲空間會變成原來的 n 倍。
分散式布隆過濾器實現方案
如果你有布隆過濾器的實際使用需求,並且是在分散式環境,筆者推薦下麵這個庫,它是作為 redis 的插件提供的,詳情點擊下方鏈接。
https://github.com/RedisBloom/RedisBloom
代碼地址
為方便學習,本文所有的代碼均已整理在 github:https://github.com/eventhorizon-cli/EventHorizon.BloomFilter


