
背景: 一般我們可以用HashMap做本地緩存,但是HashMap功能比較弱,不支持Key過期,不支持數據範圍查找等。故在此實現了一個簡易的本地緩存,取名叫fastmap。 功能: 1.支持數據過期 2.支持等值查找 3.支持範圍查找 4.支持key排序 實現思路: 1.等值查找採用HashMap2 ...
在平常的一些的小規模的數據的過濾、清洗過程中使用最多的就是正則表達式,但是隨著數據規模的增大,正則表達式就顯得有些心有餘力不足了。
正則表達式在一個 10k 的詞庫中查找 15k 個關鍵詞的時間差不多是 0.165 秒。但是對於 Flashtext 而言只需要 0.002 秒。因此,在這個問題上 Flashtext的速度大約比正則表達式快 82 倍。
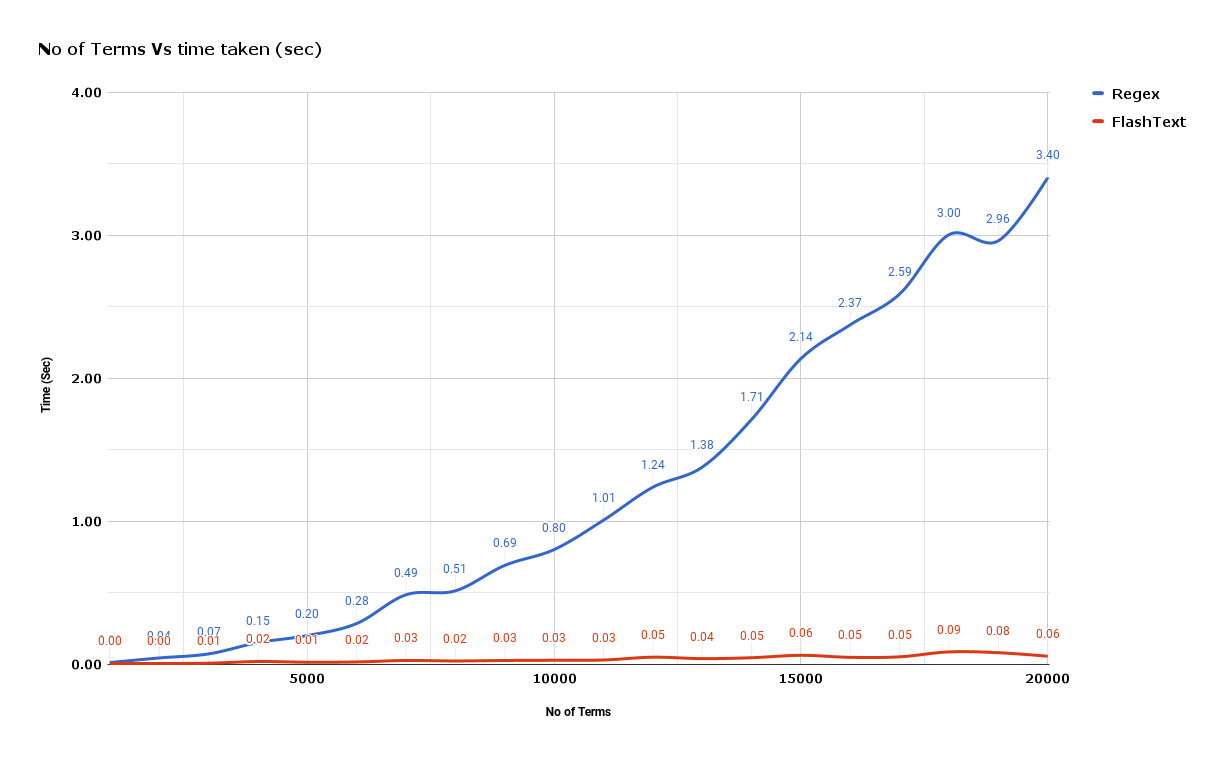
從上面的示例圖的性能對比中,可以發現隨著我們需要處理的字元越來越多,正則表達式的處理速度幾乎都是線性增加的。然而,Flashtext 幾乎是一個常量。
1、準備flashtext環境
通過pip的方式來安裝flashtext,或是其他的方式也是可以的,這裡預設使用的是清華大學的鏡像站。
pip install flashtext -i https://pypi.tuna.tsinghua.edu.cn/simple
在準備好flashtext環境以後,來看一下flashtext重要的使用過程,幫助我們能更好的完成數據清洗操作。
2、添加關鍵詞
這裡添加關鍵詞時是通過單個關鍵詞的來添加到關鍵詞詞庫中,使用add_keyword函數來添加。第一次參數表示需要添加的關鍵詞,第二個參數則表示為第一個關鍵詞的別名,如果關鍵詞被找到了則顯示為別名的形式,若是沒有使用第二個參數作為別名則還是顯示原有的名稱。
from flashtext import KeywordProcessor
# 初始化關鍵詞庫處理器
processor = KeywordProcessor()
# 常規方式添加關鍵詞
processor.add_keyword('Python')
# 別名方式添加關鍵詞
processor.add_keyword('Scala', 'Java')
這樣分別使用兩種方式已經將需要的關鍵詞添加到詞庫處理器中了。
3、提取關鍵詞
通過上一步添加關鍵詞,現在詞庫處理器中已經存在有關鍵詞的信息了,再使用extract_keywords將關鍵詞提取出來即可。
# 在一個字元串中提取出關鍵詞信息
found = processor.extract_keywords('I like Python and Scala.')
# 結果
print(found)
# ['Python', 'Java']
結果出來了,跟我們預想的是一樣的,並Scala也顯示為了Java。
4、替換關鍵詞
替換關鍵詞使用的是replace_keywords函數,前提是詞庫中擁有別名的詞才能被替換,就像上面的Scala被顯示成了的Java一樣。
替換一個字元串中的Scala關鍵詞,由於Scala對應的別名是Java,所以一個字元串中的Scala應該被替換為Java。
replaced = processor.replace_keywords('I like Scala.')
# 結果
print(replaced)
# I like Java.
# Scala 果真就被替換為了Java。
5、獲取所有關鍵詞
有些時候,在KeywordProcessor詞庫處理器中添加了哪些關鍵詞可能自己都記不清楚了,這個時候可以使用get_all_keywords函數來獲取當前的所有關鍵詞。
all_keywords = processor.get_all_keywords()
# 結果
print(all_keywords)
# {'python': 'Python', 'scala': 'Java'}
6、批量的添加關鍵詞
當關鍵詞庫需要更多的關鍵詞的時候,可以通過列表或是字典的方式來進行批量的添加。對應的函數分別是add_keywords_from_list、add_keywords_from_dict函數。
# 初始化一個字典通過用來做批量添加
dict_ = {
'java': ['java_ee', 'java_se', 'java_me'],
'python': ['pandas', 'all']
}
# 通過字典的方式來批量添加關鍵詞
processor.add_keywords_from_dict(dict_)
# 從批量添加的關鍵詞中匹配關鍵詞
result = processor.extract_keywords('looking for java_ee and pandas.')
# 結果
print(result)
# ['java', 'python']
# 通過列表的方式批量添加關鍵詞
processor.add_keywords_from_list(['scala', 'python', 'scala', 'go'])
# 通過get_all_keywords查看一下所有關鍵詞
all_keywords = processor.get_all_keywords()
# 結果
print(all_keywords)
# {'python': 'python', 'pandas': 'python', 'scala': 'scala', 'java_ee': 'java', 'java_se': 'java', 'java_me': 'java', 'all': 'python', 'go': 'go'}
發現所有的關鍵詞已經添加到詞庫處理器中,並且重覆的不會再次添加。
7、批量刪除關鍵詞
批量刪除詞庫處理器中的關鍵詞同樣是有兩種方式,一個是列表、另一個是字典。對應的函數分別是remove_keywords_from_list、remove_keywords_from_dict函數。
# 批量移除列表中的關鍵詞
processor.remove_keywords_from_list(['python','java_ee','java_me'])
# 批量移除字典中的關鍵詞
processor.remove_keywords_from_dict({'python': ['pandas','all']})
# 通過get_all_keywords查看一下所有關鍵詞
all_keywords = processor.get_all_keywords()
# 結果
print(all_keywords)
# {'scala': 'scala', 'java_se': 'java', 'go': 'go'}
發現需要移除的關鍵詞已經被全部移除了。
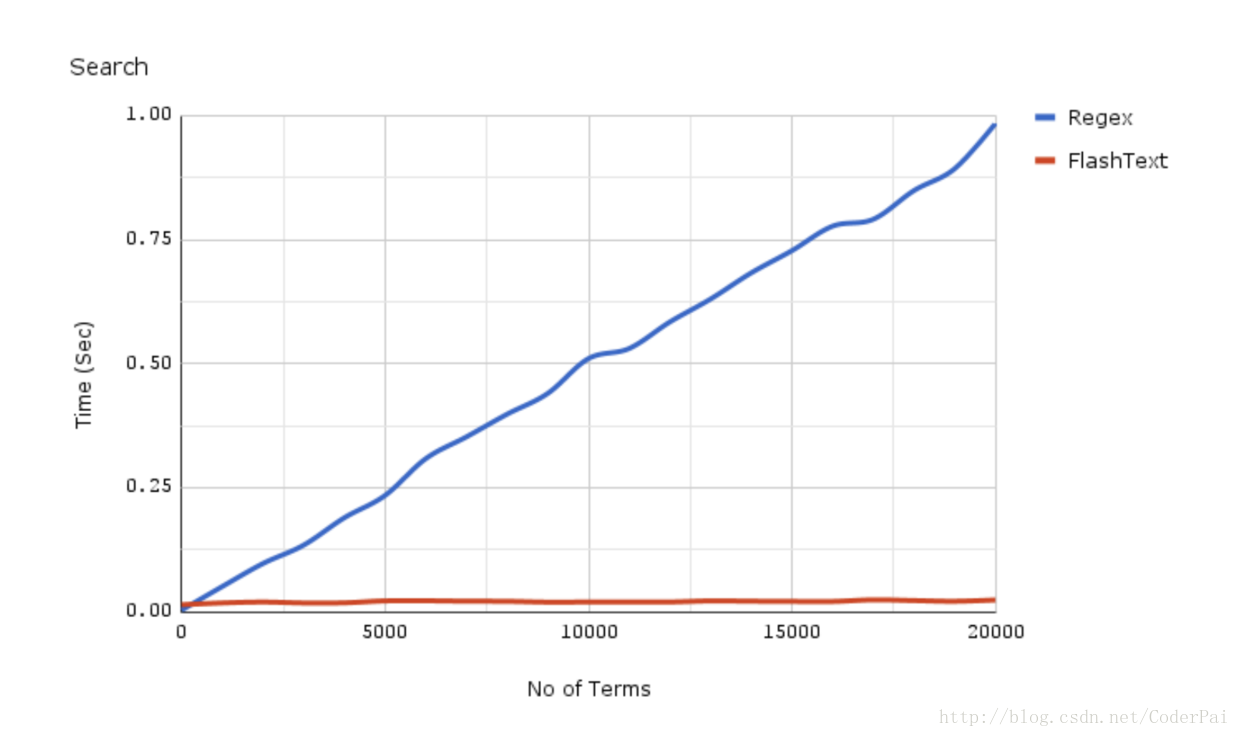
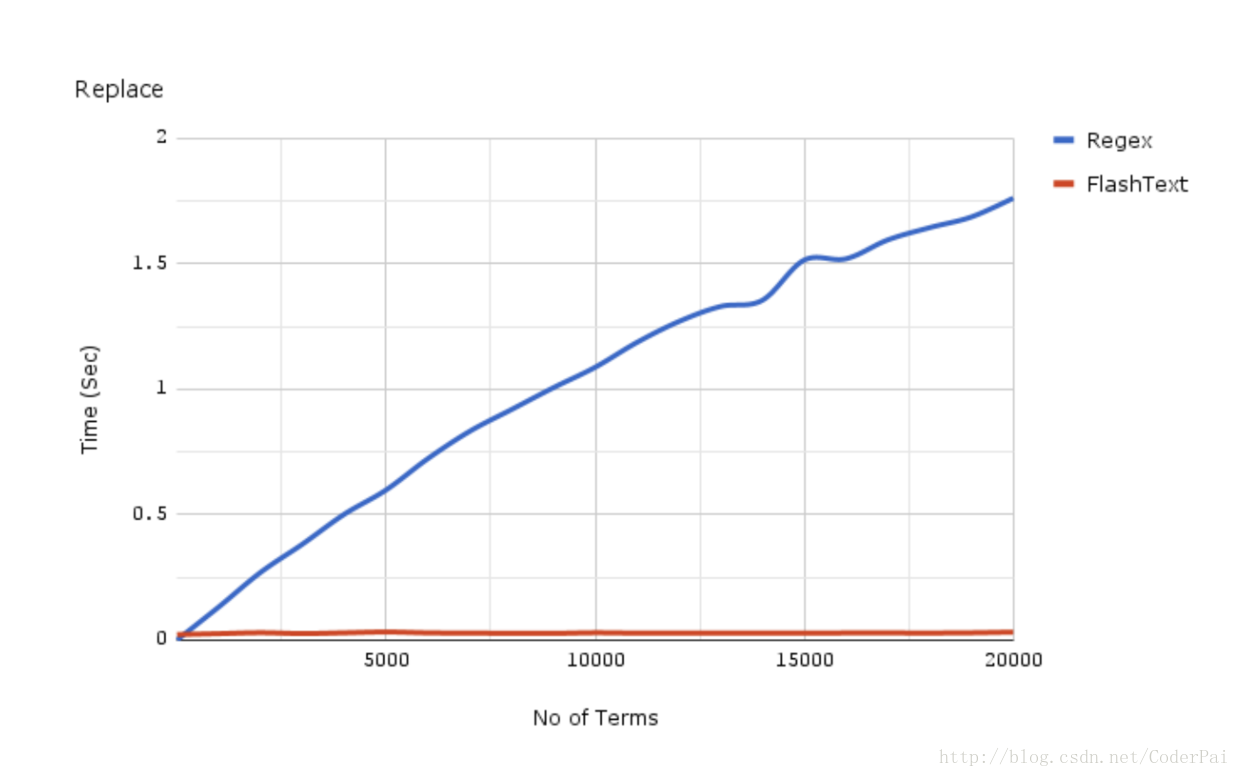
8、執行效率對比
為了更可觀的展示效果,找了兩個flashtext在搜索和替換關鍵詞過程中的效率對比圖可以一目瞭然。
flashtext、正則表達式搜索效率對比
flashtext、正則表達式搜索替換對比
【往期精彩】

一個help函數解決了python的所有文檔信息查看...
python 自定義異常/raise關鍵字拋出異常
python 本地音樂播放器製作過程(附完整源碼)
自動化工具:PyAutoGUI的滑鼠與鍵盤控制,解放雙手的利器!
來自程式猿的生日蛋糕你見過嗎?
歡迎關註作者公眾號【Python 集中營】,專註於後端編程,每天更新技術乾貨,不定時分享各類資料!

