
本章是系列文章的第八章,用著色演算法進行寄存器的分配過程。 本文中的所有內容來自學習DCC888的學習筆記或者自己理解的整理,如需轉載請註明出處。周榮華@燧原科技 寄存器分配 寄存器分配是為程式處理的值找到存儲位置的問題 這些值可以存放到寄存器,也可以存放在記憶體中 寄存器更快,但數量有限 記憶體很多,但 ...
本章是系列文章的第八章,用著色演算法進行寄存器的分配過程。
本文中的所有內容來自學習DCC888的學習筆記或者自己理解的整理,如需轉載請註明出處。周榮華@燧原科技
寄存器分配
- 寄存器分配是為程式處理的值找到存儲位置的問題
- 這些值可以存放到寄存器,也可以存放在記憶體中
- 寄存器更快,但數量有限
- 記憶體很多,但訪問速度慢
- 好的寄存器分配演算法儘量將使用更頻繁的變數保存的寄存器中
8.1.1 寄存器分配的主要工作
- 寄存器指派
- 寄存器溢出處理
- 寄存器使用合併
8.1.2 寄存器的約束
硬碟硬體或者編譯器的限制,某些值只能保存在特定的寄存器中
虛擬寄存器(程式中的變數)和物理寄存器(實際的寄存器)
calling convention(調用約定)
同一個程式點alive的多個變數必須指派不同的寄存器
8.1.3 寄存器分配與生命周期管理
最小寄存器數量 ≥ 最大生命周期變數集合
不過DCC888課程膠片裡面給的這個例子,我不太認同:
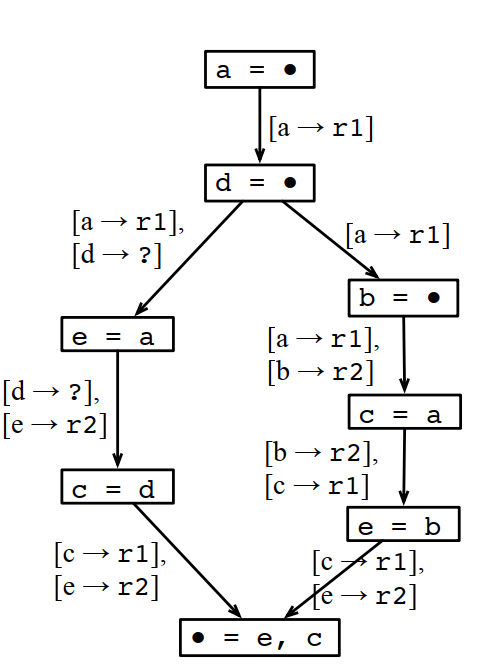
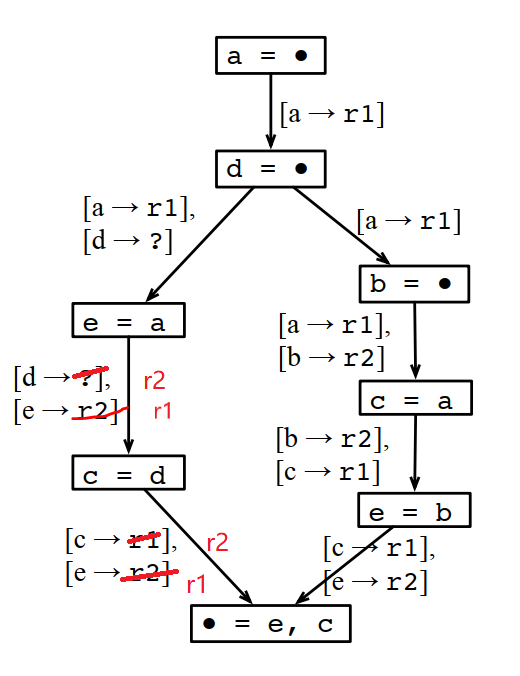
這樣分配下來雖然MaxLive是2個,但MinReg需要3個。
為什麼不能這樣分配?因為最後輸出是e和c,如果多個分支使用的e和c的寄存器不一樣,那到匯聚點的時候,就沒法直接用,還要做一次轉移,這個轉移也是需要額外的寄存器的,或者至少需要額外的計算。如果不做轉移,就要插入一條store和一條load指令,這個成本更高。
8.1.4 寄存器分配是個NP完成問題
它的複雜度和邏輯等同於圖的著色問題。
同樣的,對於這樣的CFG,同樣匯聚點上輸出的變數往上的多個分支中,同一個變數需要使用同樣的寄存器:
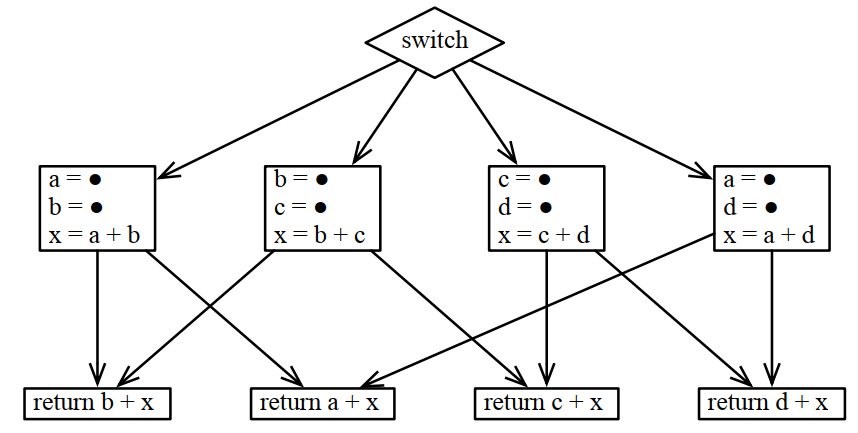
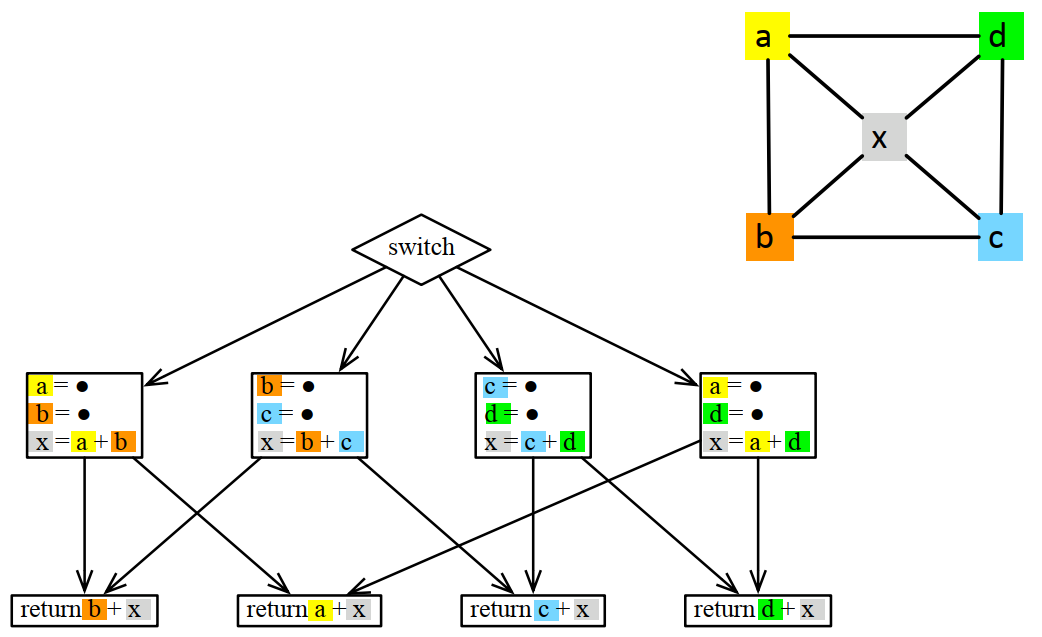
轉換成著色問題的邏輯變成這樣,對下麵的k種顏色,需要k+1個寄存器:
8.2 線性掃描
線性掃描基於區間圖的貪婪著色演算法:
- 給定一個區間序列,重疊的區間必須給定不同的顏色,求最小顏色數。
- 貪婪著色有最優演算法
- 但線性掃描不是貪婪著色的最優演算法,而是最優演算法的一個近似解。
8.2.1 基本塊的線性化
通常用逆後根排序對CFG做排序生成線性化的BB塊序列(前面worklist演算法也用了逆後根排序,看來這個排序和程式執行之間的關係非常密切)。
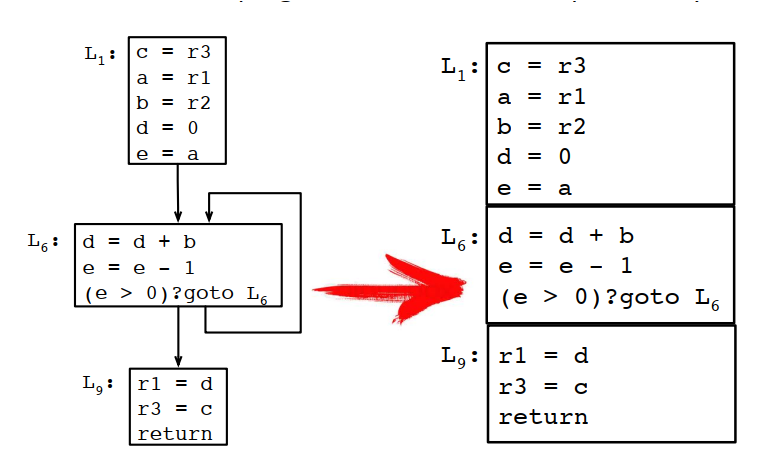
8.2.2 生成區間線
變數v的區間線Iv從v的生命期開始的程式點開始,到v的生命期結束的程式點結束。
為什麼b和e的區間線要到第二個BB塊最後,而不是在最後一次使用後就結束?因為後面還有分支,根據條件不同,第二個BB塊還有可能從L6繼續執行。
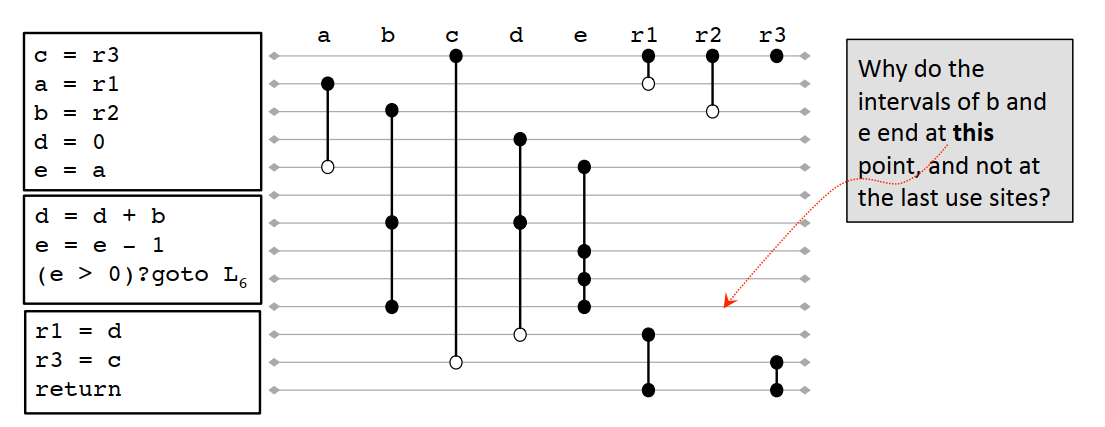
8.2.3 區間線的線性掃描演算法
演算法描述如下
1 LINEARSCANREGISTERALLOCATION♧ 2 active = {} 3 foreach interval i, in order of increasing start point 4 EXPIREOLDINTERVALS(i) 5 if length(active) = R then 6 SPILLATINTERVAL(i) 7 else 8 register[i] = a register removed from the pool of free registers. 9 Add i to active, sorted by increasing end point 10 11 EXPIREOLDINTERVALS(i) 12 foreach interval j in active, in order of increasing end point 13 if endpoint[j] ≥ startpoint[i] then 14 return 15 remove j from active 16 add register[j] to pool of free registers 17 18 SPILLATINTERVAL(i) 19 spill = last interval in active 20 register[i] = register[spill] 21 location[spill] = new stack location 22 remove spill from active 23 add i to active, sorted by increasing end point
上面的常式經過演算法處理之後的寄存器分配結果如下:
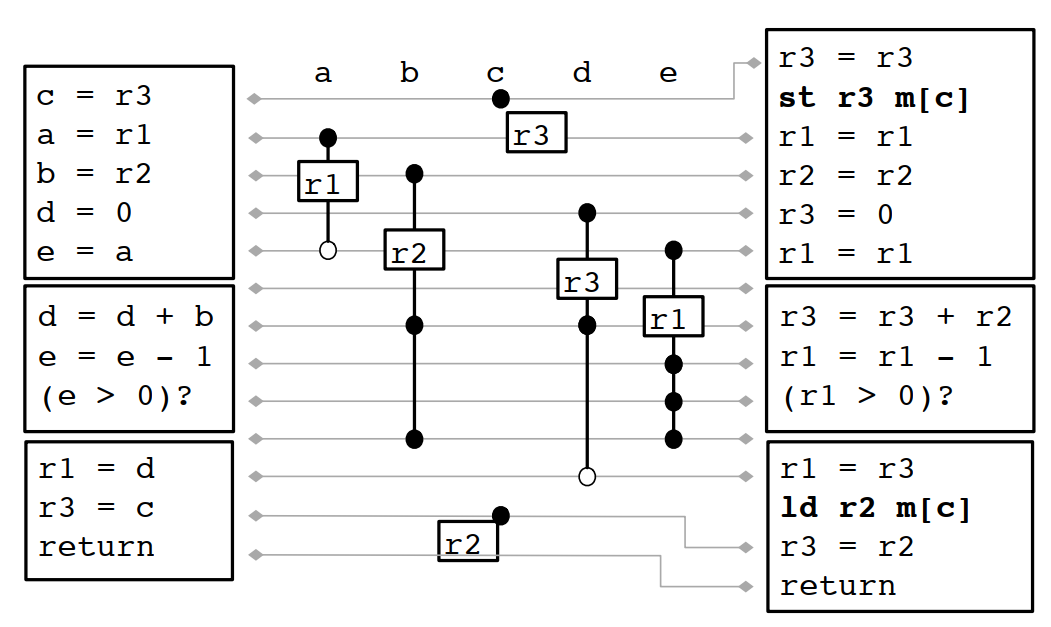
8.2.4 合併
上面的結果還不是最優解,需要經過合併
帶合併過程的線性掃描演算法如下:
1 LINEARSCANREGISTERALLOCATIONWITHCOALESCING 2 active = {} 3 foreach interval i, in order of increasing start point 4 EXPIREOLDINTERVALS(i) 5 if length(active) = R then 6 SPILLATINTERVAL(i) 7 else 8 if definition of i is "a = b" and register[b] ∈ free registers 9 register[i] = register[i(b)] 10 remove register[i(b)] from the list of free registers 11 else 12 register[i] = a register removed from the list of free registers 13 add i to active, sorted by increasing end point
合併之後的結果如下:

8.2.5 生命周期黑洞
線性掃描不是最優解,在一些場景下,和最優解相差還非差大,例如多個分支之間存在生命周期黑洞的情況。
例如對下麵的CFG:
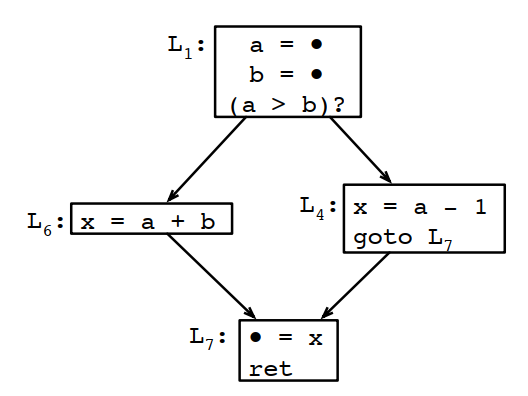
線性掃描處理的結果如下:
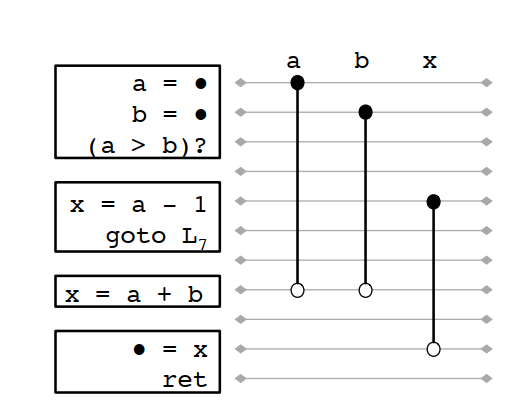
按線性掃描的結果x和a是不能共寄存器的。但如果看生命周期分析結果:
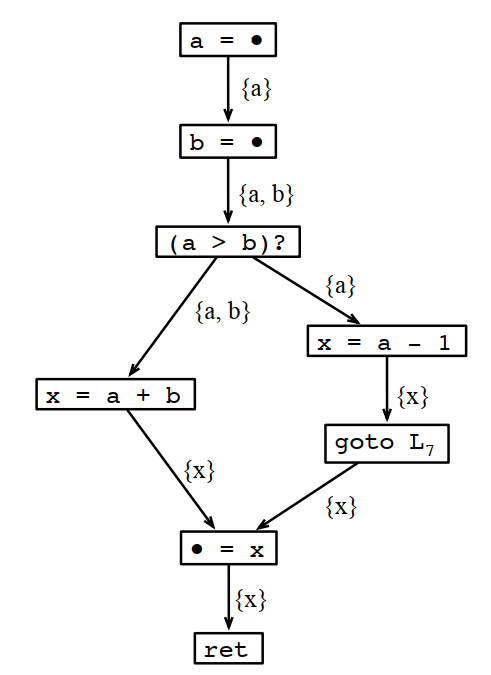
x出現後,a和b都不會再使用,也就是說x肯定是可以和a或者b共用一個寄存器的。
8.3 基於圖著色的寄存器分配
8.3.1 干涉圖(The Interference Graph)
最常見的寄存器分配演算法家族是基於干涉圖的理念推演出來的。
干涉圖是基於控制流圖中變數的生命周期範圍的網路圖:
- 每個變數是圖的一個結點;
- 如果兩個變數的生命周期存在重疊,則這2個節點在圖上鄰接,也就是存在一條邊將2個節點連接起來,這樣的邊也稱為干涉邊(interference edges)。
- 除了干涉邊,如果2個變數存在且僅存在一條move指令將2個變數關聯起來,則在2個變數之間畫一條虛線,稱為合併邊(coalescing edges)
8.3.2 肯普簡化演算法(Kempe's Simplification)
如果圖中存在一個節點m,它的鄰接節點小於k,設G' = G \ {m},如果G'能被k種顏色著色,那麼G也能被k種顏色著色。
通過肯普簡化演算法,可以將圖簡化到只有一個節點,或者簡化到只剩下一些高階節點,這樣方便求出圖的最小可著色的顏色數。
下麵是簡化過程:
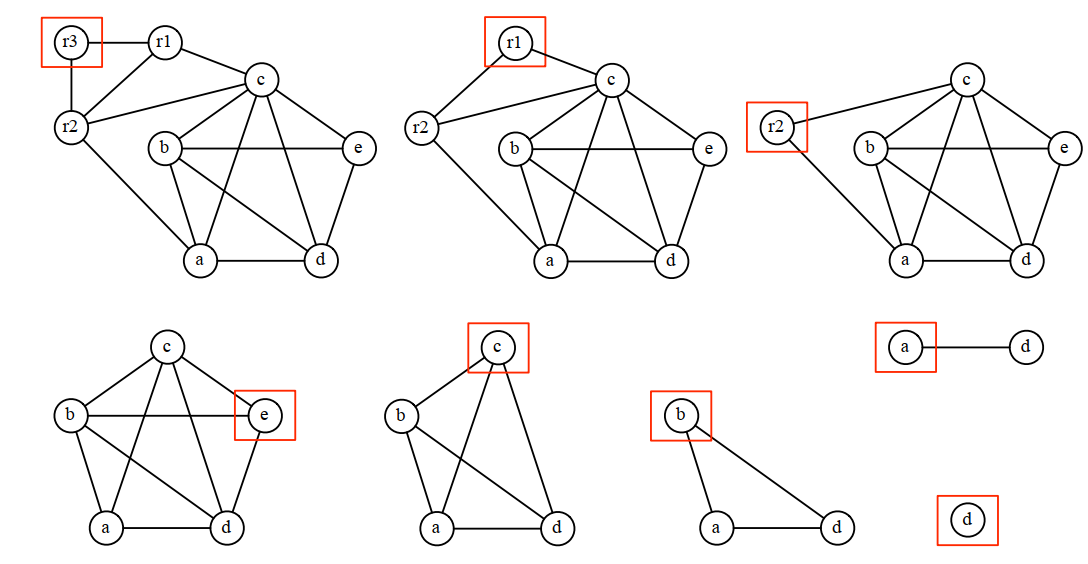
8.3.3 貪婪著色演算法(Greedy Coloring)
貪婪著色的順序是肯普簡化演算法刪除節點的順序的逆序,每次著色都要找一個鄰接節點中不存在的顏色進行著色。
針對上面的簡化過程,著色過程是這樣的:

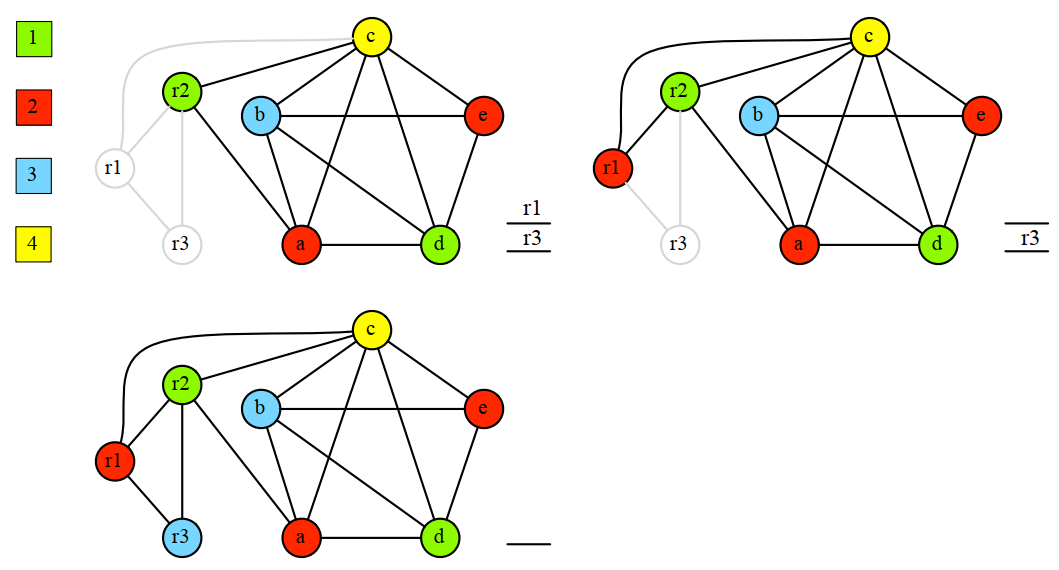
註意,上面的演算法只是為了證明一個圖是否能被K種顏色進行著色,但不關心是否可以用更少的顏色來著色。
8.4 迴圈進行寄存器合併
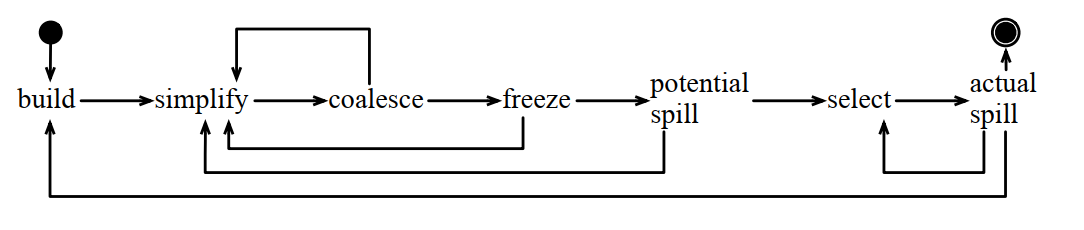
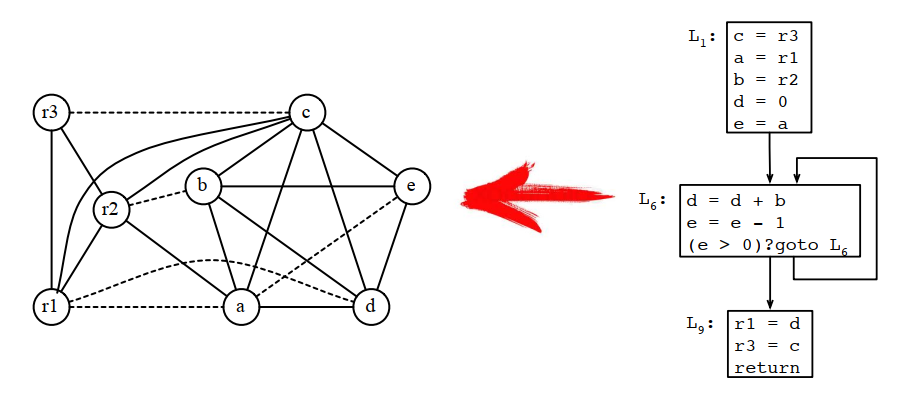
8.4.1 build
就是基於生命周期生成干涉圖的過程:
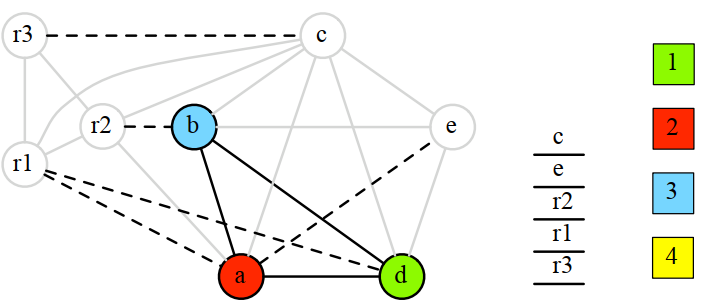
8.4.2 simplify
使用肯普演算法刪除非move相關節點:
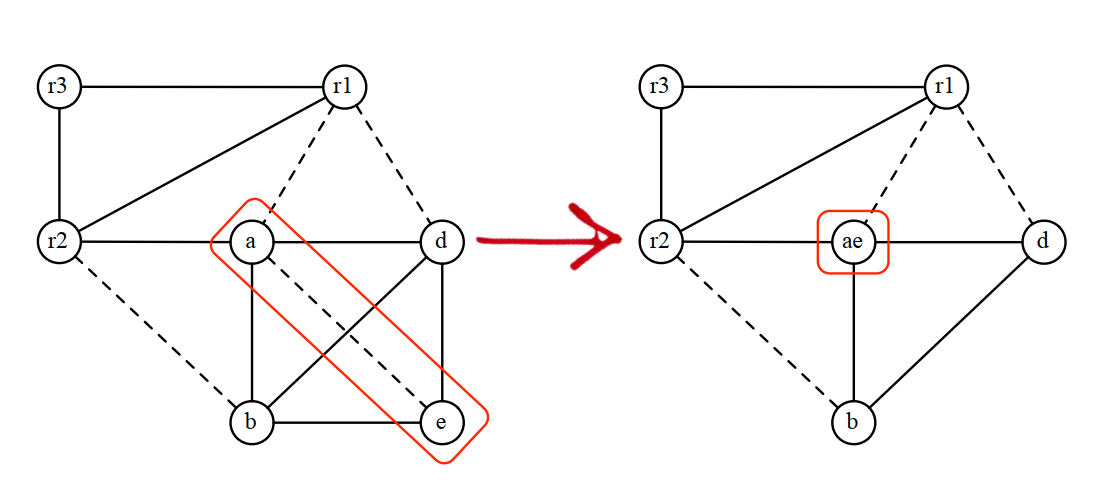
8.4.3 Coalesce
合併過程是將move關聯節點合併成一個:
保守合併演算法:
Briggs:節點a和b能合併當且僅當ab有更少的高階(≥k)鄰接節點
George:節點a和b能合併,當且僅當,所有a的鄰接節點要麼和b相互干涉,要麼是一個低階節點
8.4.4 freeze
如果前面的的簡化和合併都沒有影響干涉圖,嘗試刪除一條move干涉關係。
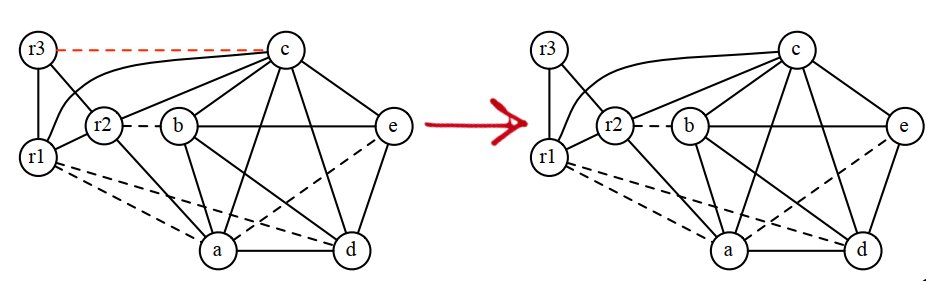
8.4.5 潛在溢出
如果找不到低階節點,就要選擇一個節點作為潛在的溢出節點,並將它加入到簡化節點棧中。
現在還沒有確定會溢出,有可能著色時,發現很多標記了溢出的節點,能夠有效著色。
8.4.6 溢出演算法(Spilling Heuristics)
溢出演算法的核心是找到一個溢出代價最小的節點,我們給迴圈內的節點一個更高的代價因數:
1 SPILLCOST(v) 2 cost = 0 3 foreach definition at block B, or use at block B 4 cost += 10^N/D, where 5 N is B's loop nesting factor 6 D is v's degree in the interference graph
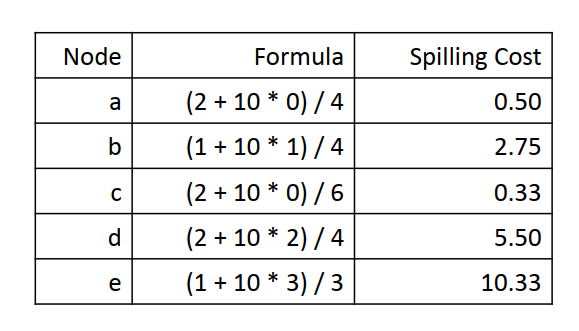
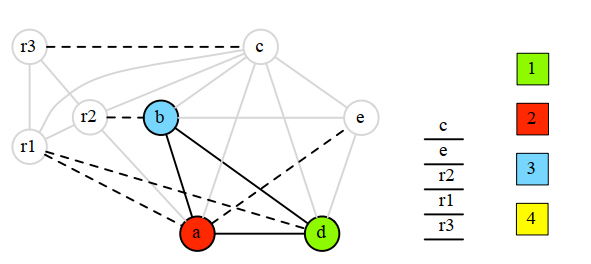
8.4.7 select
將棧中的節點出棧,並嘗試用貪婪著色演算法進行著色
8.4.8 溢出
如果確定需要溢出,在變數前後增加load和store指令,並重新走一遍從build開始的整個迭代過程。
在只有3個寄存器的情況下,通過上面的計算,應該溢出c,將兩次c的使用改成c0和c1,重新進行計算:
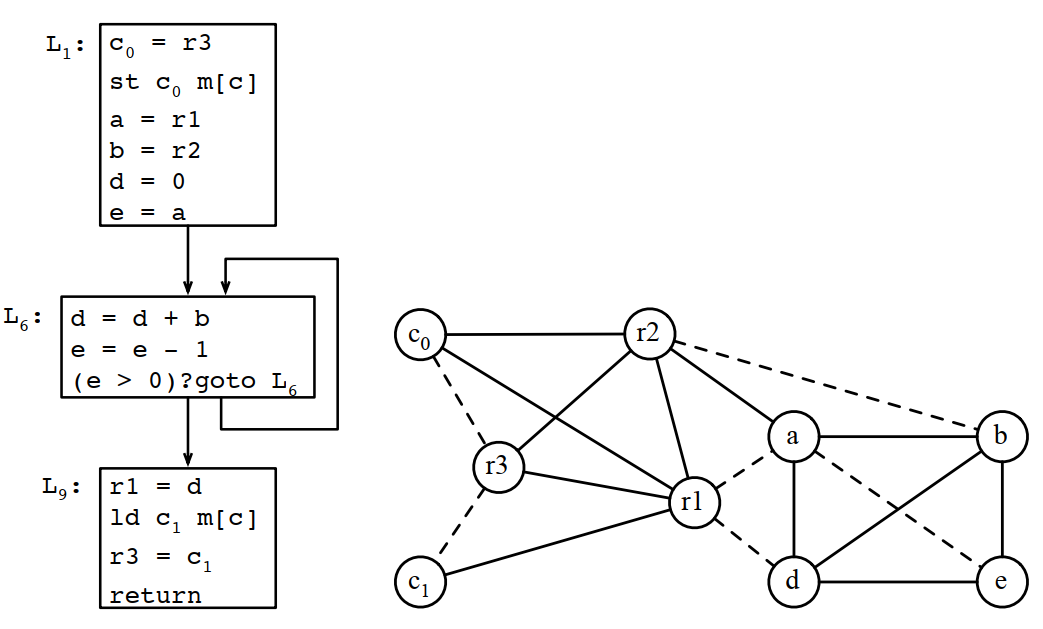
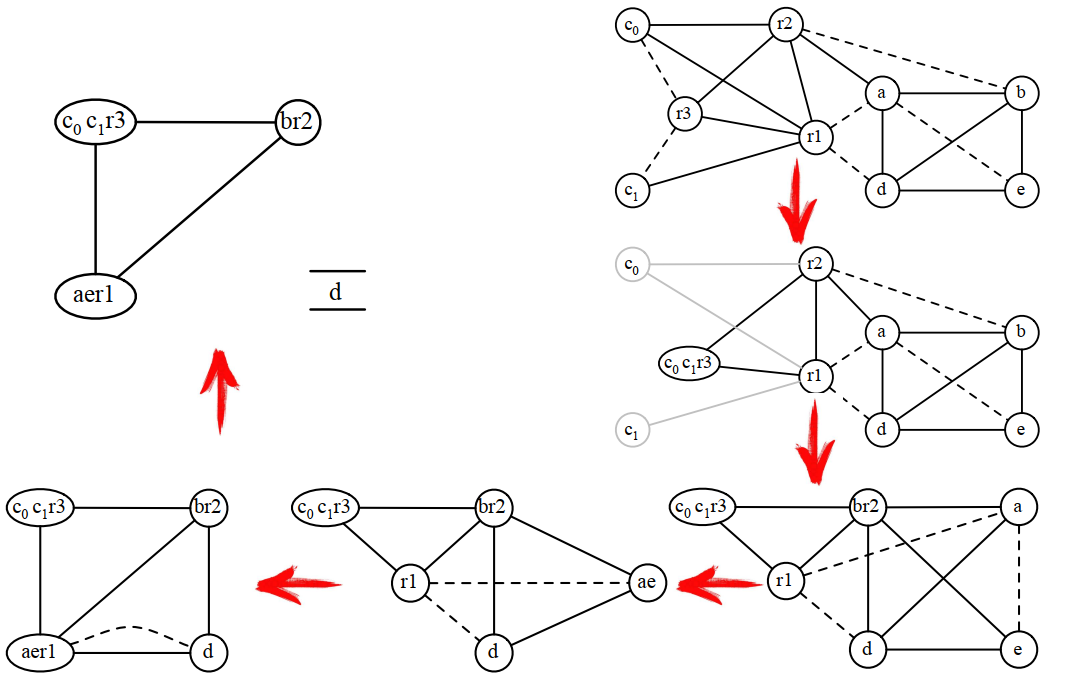
8.4.9 根據最終寄存器分配結果重寫程式
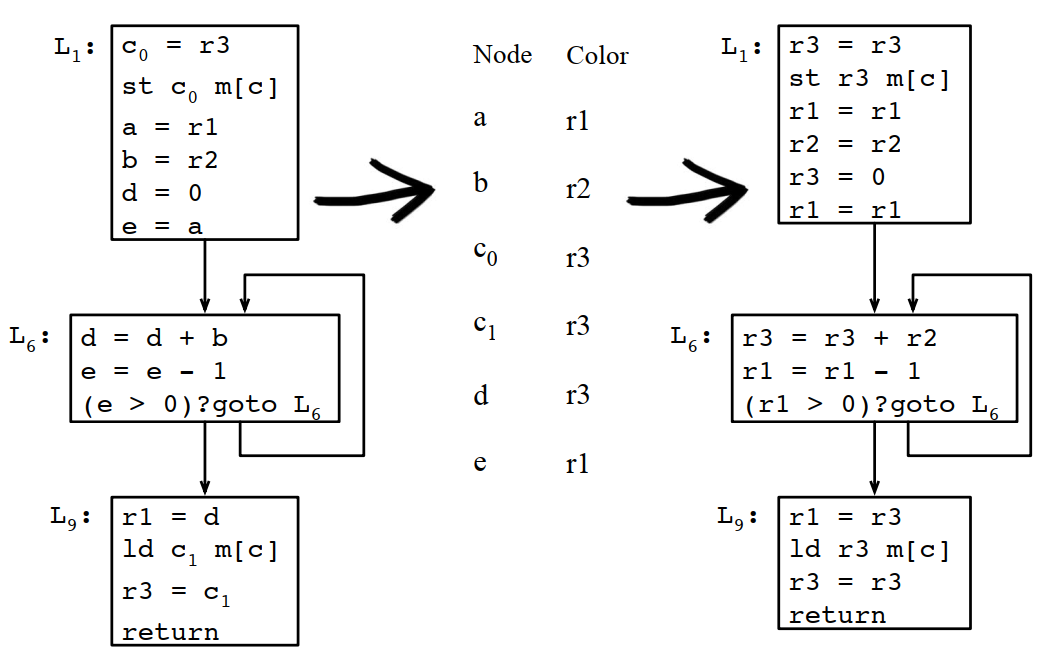
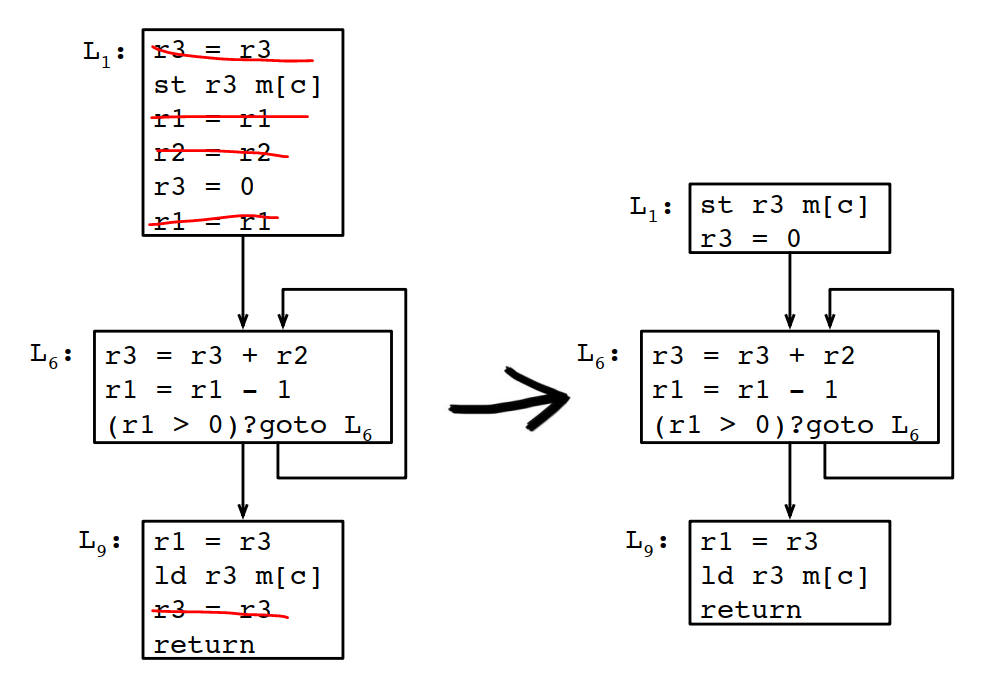
8.4.10 刪除冗餘的copy操作
8.5 寄存器分配簡史
- Chaitin, G., Auslander, M., Chandra, A., Cocke, J., Hopkins, M., and Markstein, P. "Register allocation via coloring", Computer Languages, p 47-57 (1981),首次將圖著色引入寄存器分配
- George, L., and Appel, A., "Iterated Register Coalescing", North Holland, TOPLAS, p 300-324 (1996),引入寄存器合併的迭代過程
- Poletto, M., and Sarkar, V., "Linear Scan Register Allocation", TOPLAS, p895-913 (1999),將線性掃描引入寄存器分配


