
Zookeeper3.7源碼剖析 能力目標 掌握Zookeeper中Session的管理機制 能基於Client進行Debug測試Session創建/刷新操作 能搭建Zookeeper集群源碼配置 掌握集群環境下Leader選舉啟動過程 能說出Zookeeper選舉過程中的概念 能說出Zookeep ...
Zookeeper3.7源碼剖析
能力目標
- 掌握Zookeeper中Session的管理機制
- 能基於Client進行Debug測試Session創建/刷新操作
- 能搭建Zookeeper集群源碼配置
- 掌握集群環境下Leader選舉啟動過程
- 能說出Zookeeper選舉過程中的概念
- 能說出Zookeeper選舉投票規則
- 能畫出Zookeeper集群數據同步流程
1 Session源碼分析
客戶端創建Socket連接後,會嘗試連接,如果連接成功成功會調用到primeConnection方法用來發送ConnectRequest連接請求,這裡便是設置session會話 ,關於客戶端創建會話我們就不在這裡做講解了,我們直接講解服務端Session會話處理流程。
1.1 服務端Session屬性分析
Zookeeper服務端會話操作如下圖:
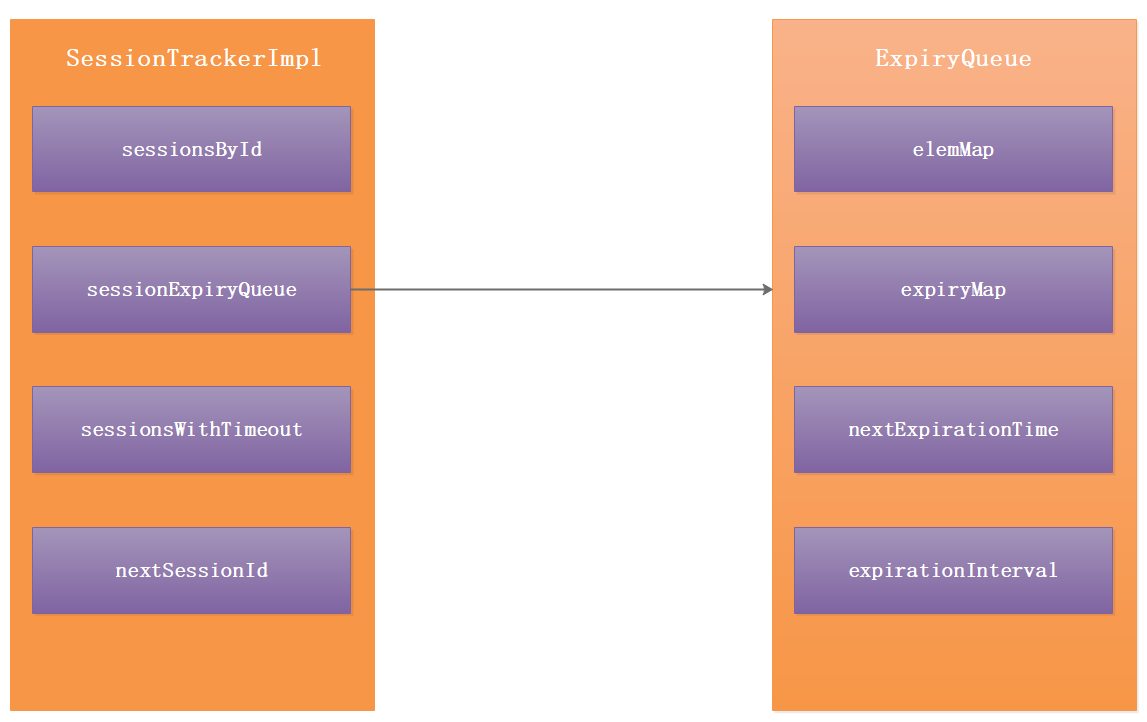
在服務端通過SessionTrackerImpl和ExpiryQueue來保存Session會話信息。
SessionTrackerImpl有以下屬性:
1:sessionsById 用來存儲ConcurrentHashMap<Long, SessionImpl> {sessionId:SessionImpl} 2:sessionExpiryQueue ExpiryQueue<SessionImpl>失效隊列
3:sessionsWithTimeout ConcurrentMap<Long, Integer>存儲的是{sessionId: sessionTimeout}
4:nextSessionId 下一個sessionId
ExpiryQueue失效隊列有以下屬性:
1:elemMap ConcurrentHashMap<E, Long> 存儲的是{SessionImpl: newExpiryTime} Session實例對象,失效時間。
2:expiryMap ConcurrentHashMap<Long, Set<E>>存儲的是{time: set<SessionImp>} 失效時間,當前失效時間的Session對象集合。
3:nextExpirationTime 下一次失效時間 {(System.nanoTime() / 1000000)/expirationInterval+1}*expirationInterval 當前系統時間毫秒值ms=System.nanoTime() / 1000000。 nextExpirationTime=當前系統時間毫秒值+expirationInterval(失效間隔)。
4:expirationInterval 失效間隔,預設是10s,可以通過sessionlessCnxnTimeout修改。即是通過配置文件的tickTime修改。
1.2 Session創建
我們接著上一章的案例繼續分析,假如客戶端發起請求後,後端如何識別是第一次創建請求?在之前的案例源碼NIOServerCnxn.readPayload()中有所體現,NIOServerCnxn.readPayload()部分關鍵源碼如下:
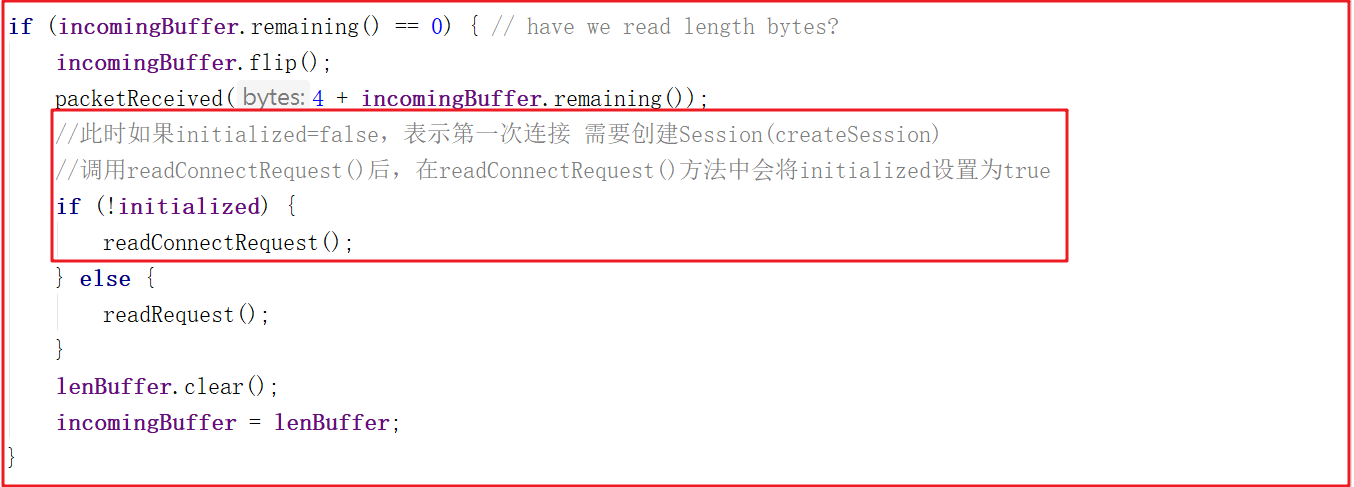
此時如果initialized=false,表示第一次連接 需要創建Session(createSession),此處調用readConnectRequest()後,在readConnectRequest()方法中會將initialized設置為true,只有在處理完連接請求之後才會把initialized設置為true,才可以處理客戶端其他命令。

上面方法還調用了processConnectRequest處理連接請求, processConnectRequest 第一次從請求中獲取的sessionId=0,此時會把創建Session作為一個業務,會調用createSession()方法,processConnectRequest 方法部分關鍵代碼如下:
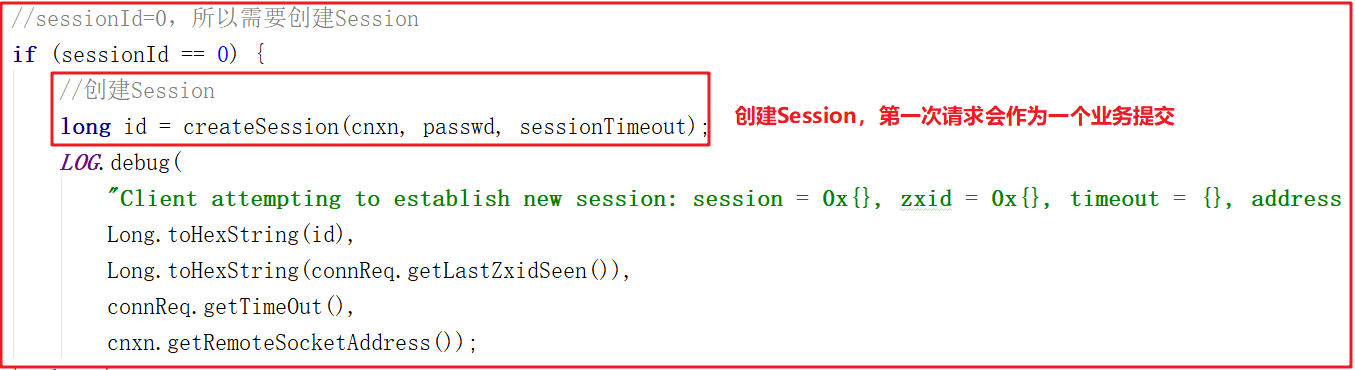
創建會話調用createSession(),該方法會首先創建一個sessionId,並把該sessionId作為會話ID創建一個創建session會話的請求,並將該請求交給業務鏈作為一個業務處理,createSession()源碼如下:
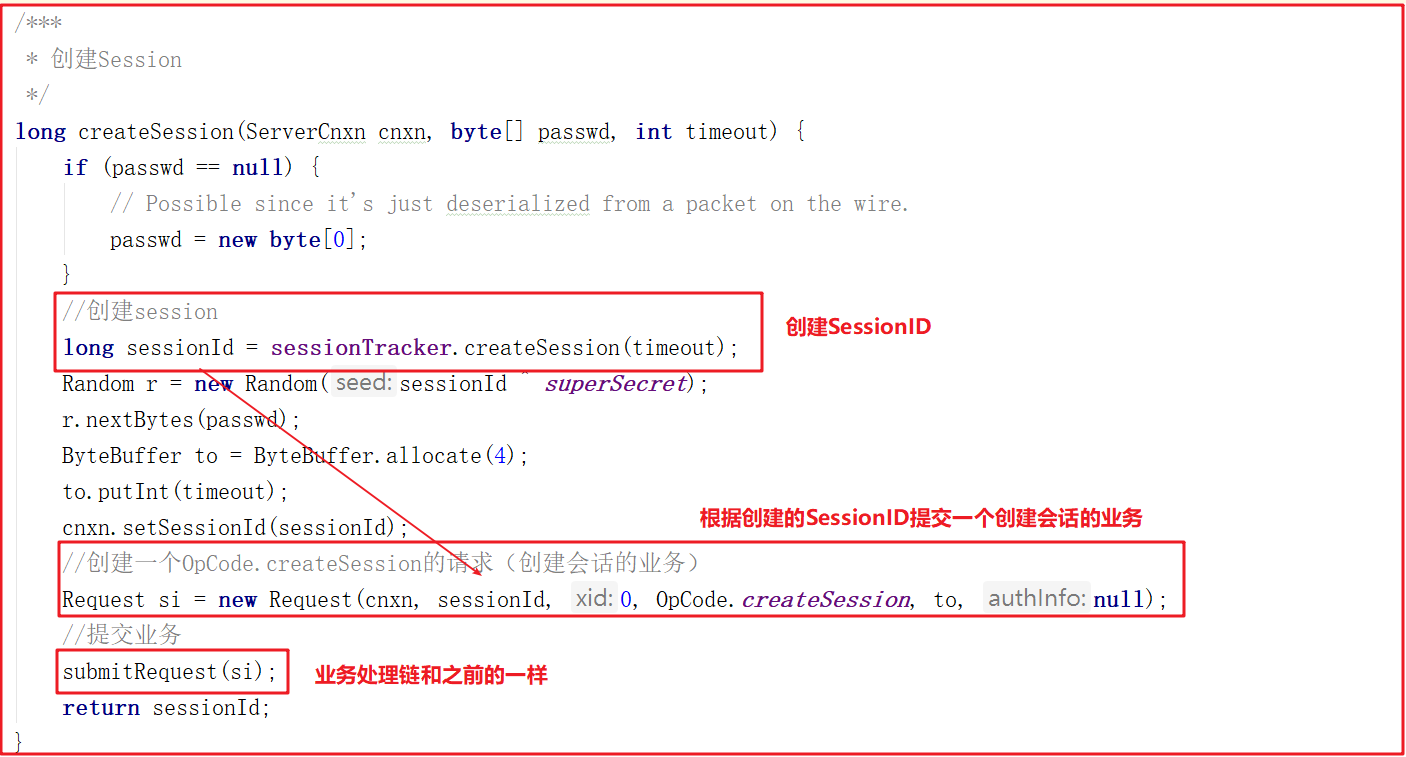
上面方法用到的sessionTracker.createSession(timeout)做了2個操作分別是創建sessionId和配置sessionId的跟蹤信息,方法源碼如下:

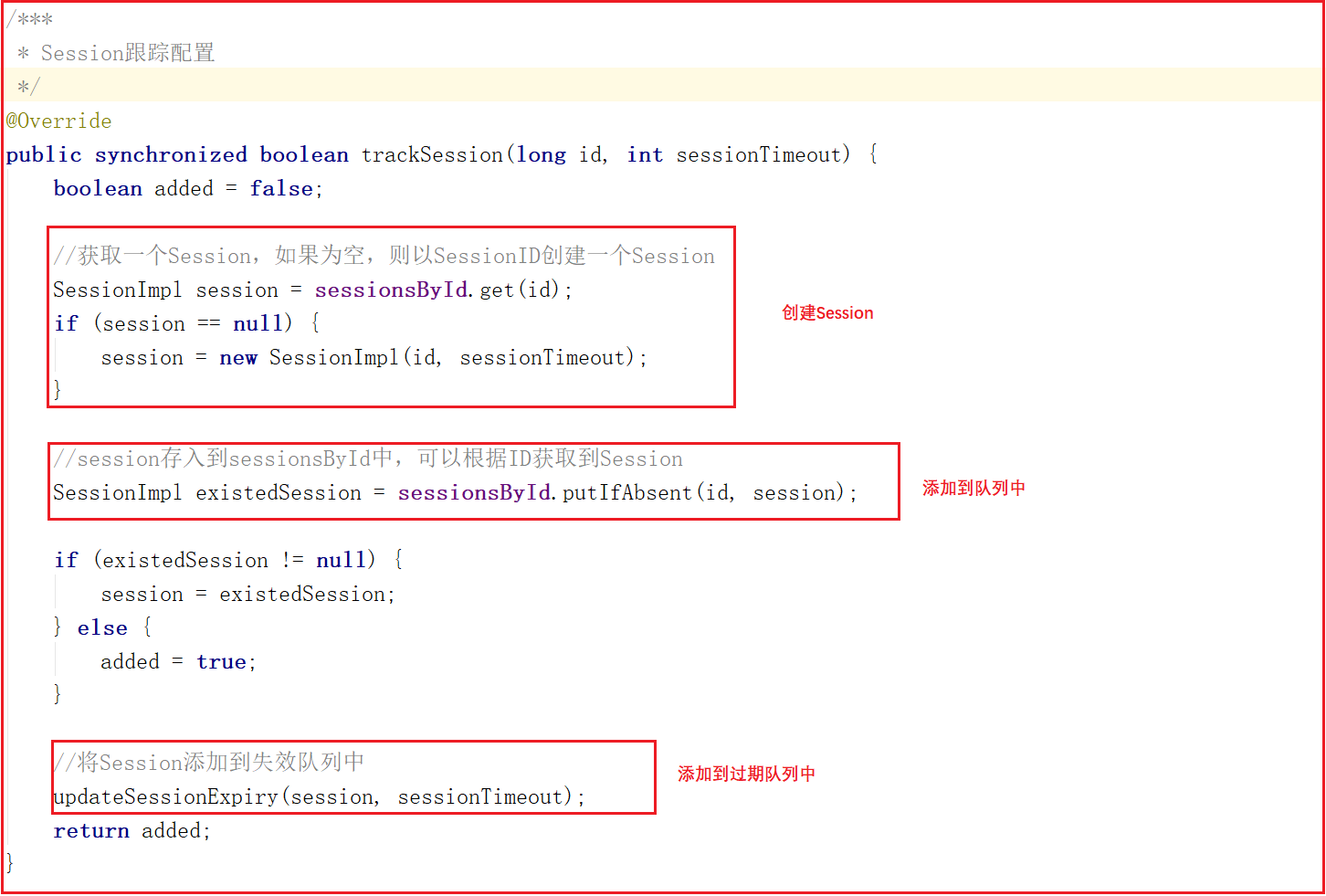
會話信息的跟蹤其實就是將會話信息添加到隊列中,任何地方可以根據會話ID找到會話信息,trackSession方法實現了Session創建、Session隊列存儲、Session過期隊列存儲,trackSession方法源碼如下:
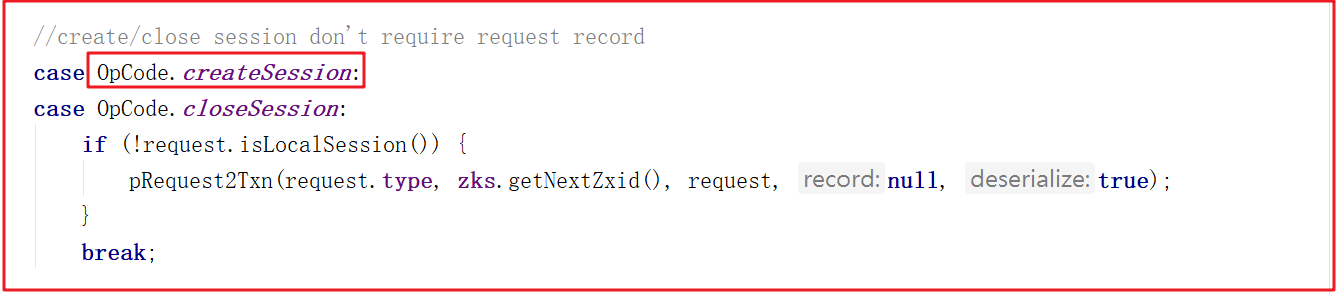
在PrepRequestProcessor的run方法中調用pRequest2Txn,關鍵代碼如下:

在SyncRequestProcessor對txn(創建session的操作)進行持久化,在FinalRequestProcessor會對Session進行提交,其實就是把Session的ID和Timeout存到sessionsWithTimeout中去。
由於FinalRequestProcessor中調用鏈路太複雜,我們把調用鏈路寫出來,大家可以按照這個順序跟蹤:
1:FinalRequestProcessor.applyRequest()
方法代碼:ProcessTxnResult rc = zks.processTxn(request);
2:ZooKeeperServer.processTxn(org.apache.zookeeper.server.Request)
方法代碼:processTxnForSessionEvents(request, hdr, request.getTxn());
上面調用鏈路中processTxnForSessionEvents(request, hdr, request.getTxn());方法代碼如下:
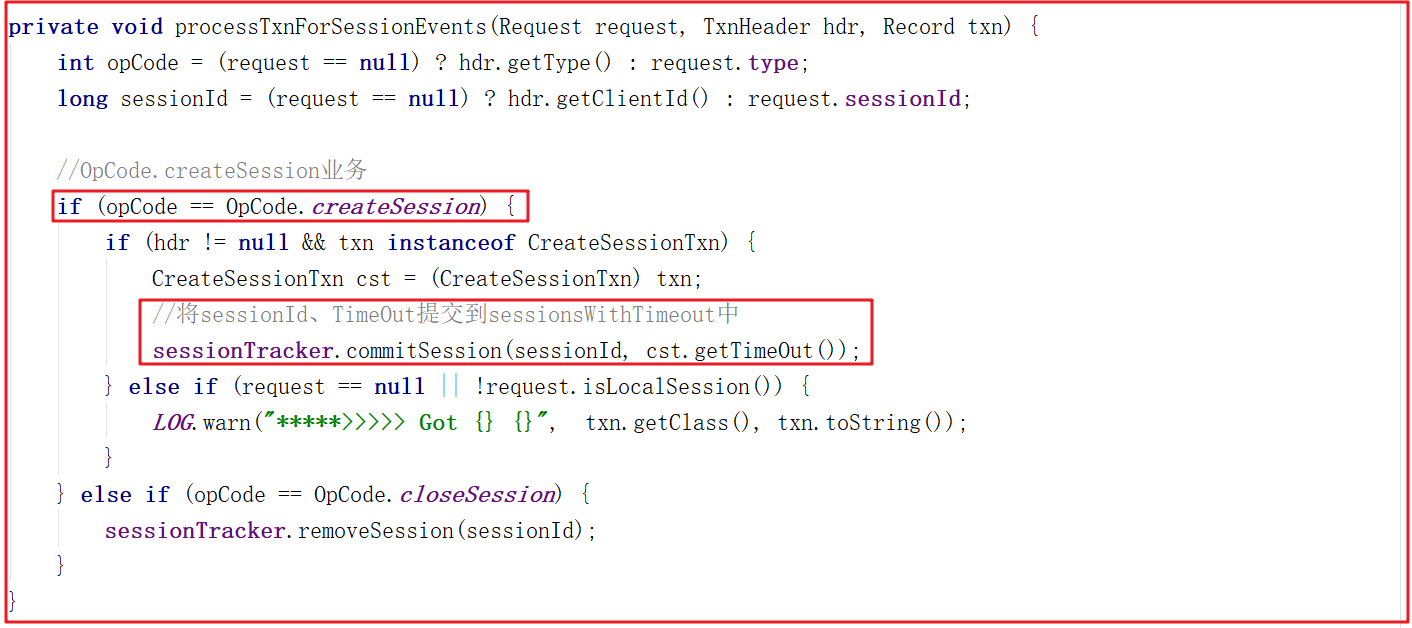
上面方法主要處理了OpCode.createSession並且將sessionId、TimeOut提交到sessionsWithTimeout中,而提交到sessionsWithTimeout的方法SessionTrackerImpl.commitSession()代碼如下:

1.3 Session刷新
服務端無論接受什麼請求命令(增刪或ping等請求)都會更新Session的過期時間 。我們做增刪或者ping命令的時候,都會經過RequestThrottler,RequestThrottler的run方法中調用zks.submitRequestNow(),而zks.submitRequestNow(request)中調用了touch(si.cnxn);,該方法源碼如下:
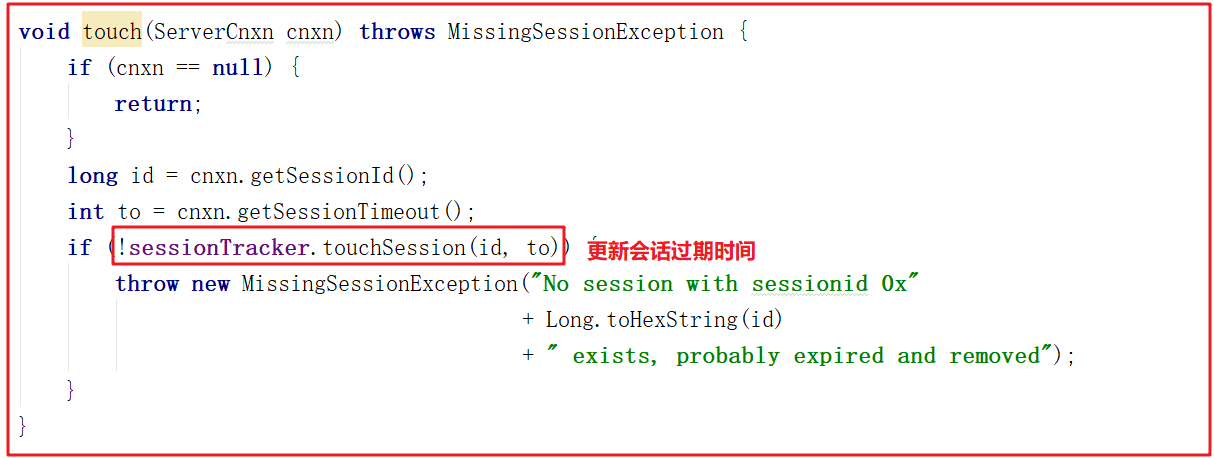
touchSession()方法更新sessionExpiryQueue失效隊列中的失效時間,源碼如下:
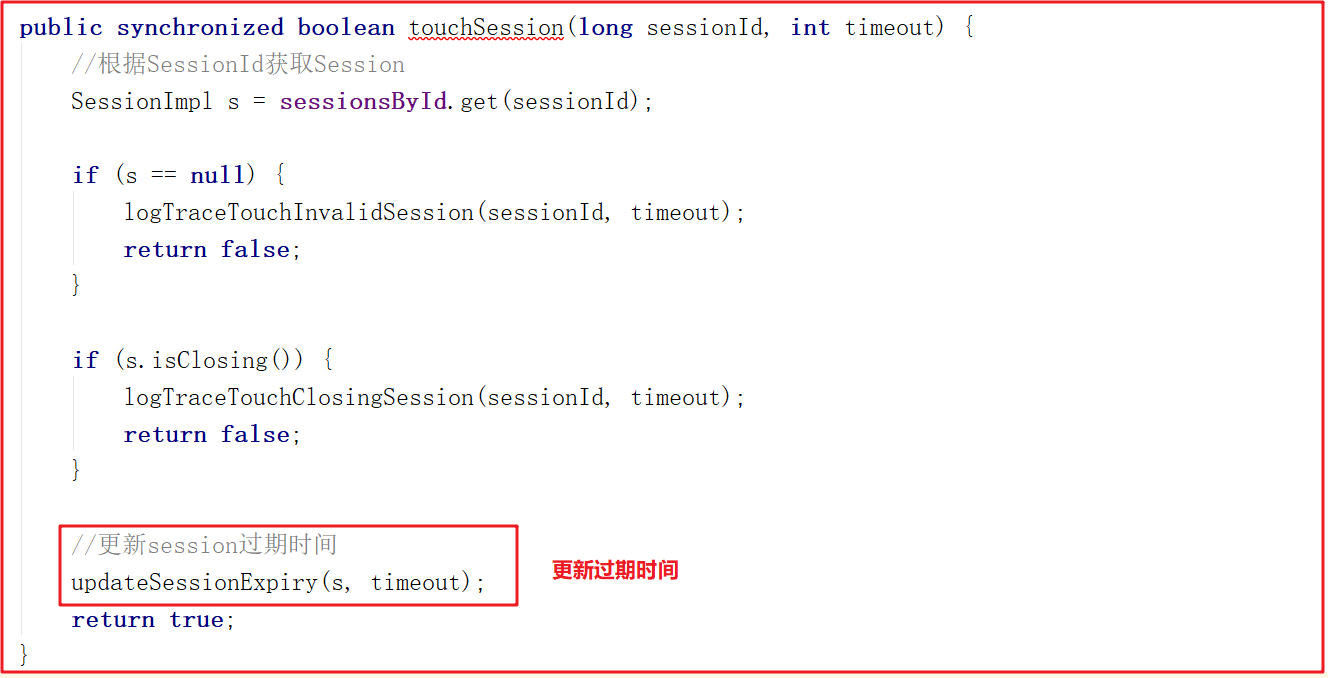
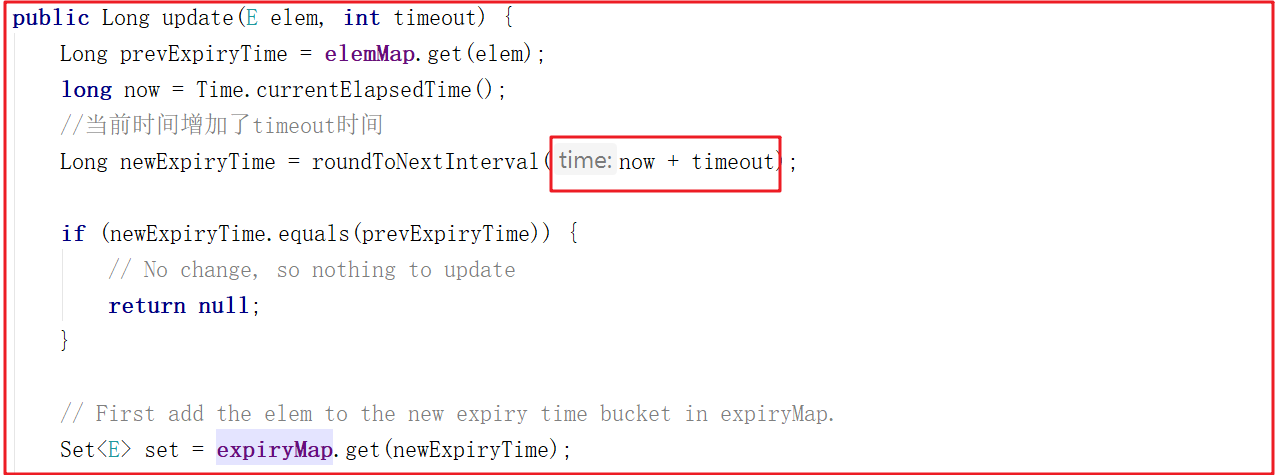
update()方法會在當前時間的基礎上增加timeout,並更新失效時間為newExpiryTime,關鍵源碼如下:
1.4 Session過期
SessionTrackerImpl是一個線程類,繼承了ZooKeeperCriticalThread,我們可以看它的run方法,它首先獲取了下一個會話過期時間,並休眠等待會話過期時間到期,然後獲取過期的客戶端會話集合併迴圈關閉,源碼如下:

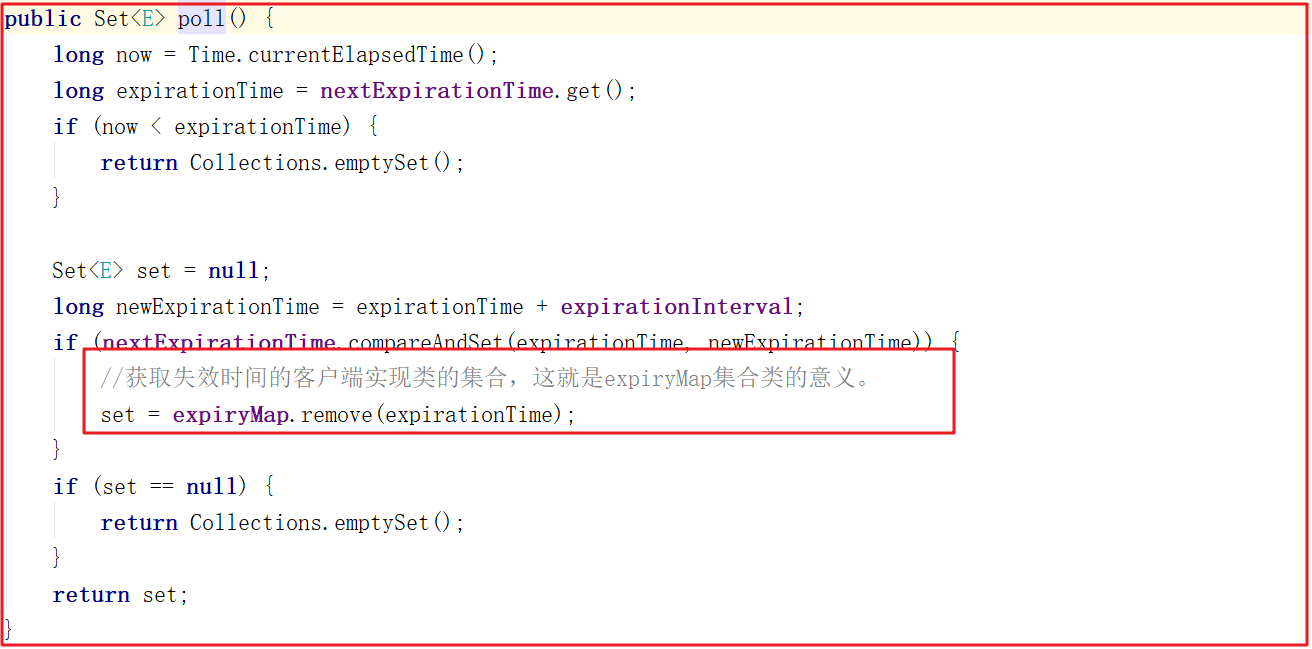
上面方法中調用了sessionExpiryQueue.poll(),該方法代碼主要是獲取過期時間對應的客戶端會話集合,源碼如下:
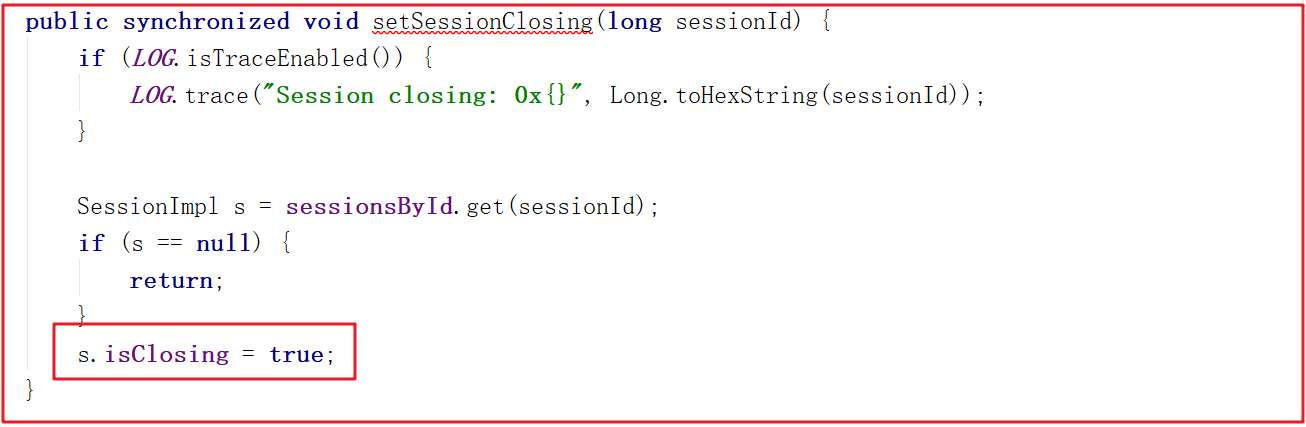
上面的setSessionClosing()方法其實是把Session會話的isClosing狀態設置為了true,方法源碼如下:
而讓客戶端失效的方法expirer.expire(s);其實也是一個業務操作,主要調用了ZooKeeperServer.expire()方法,而該方法獲取SessionId後,又創建了一個OpCode.closeSession的請求,並交給業務鏈處理,我們查看ZooKeeperServer.expire()方法源碼如下:
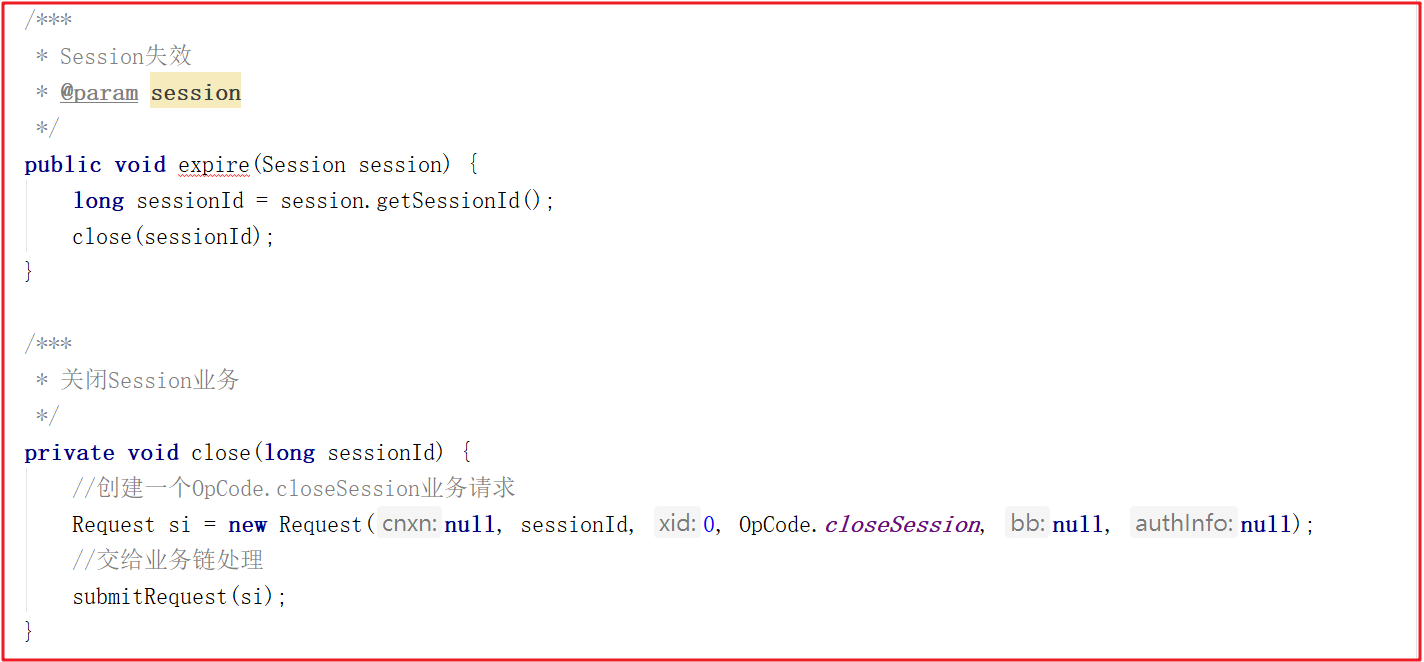
在PrepRequestProcessor.pRequest2Txn()方法中OpCode.closeSession操作里最後部分代理明確將會話Session的isClosing設置為了true,源碼如下:
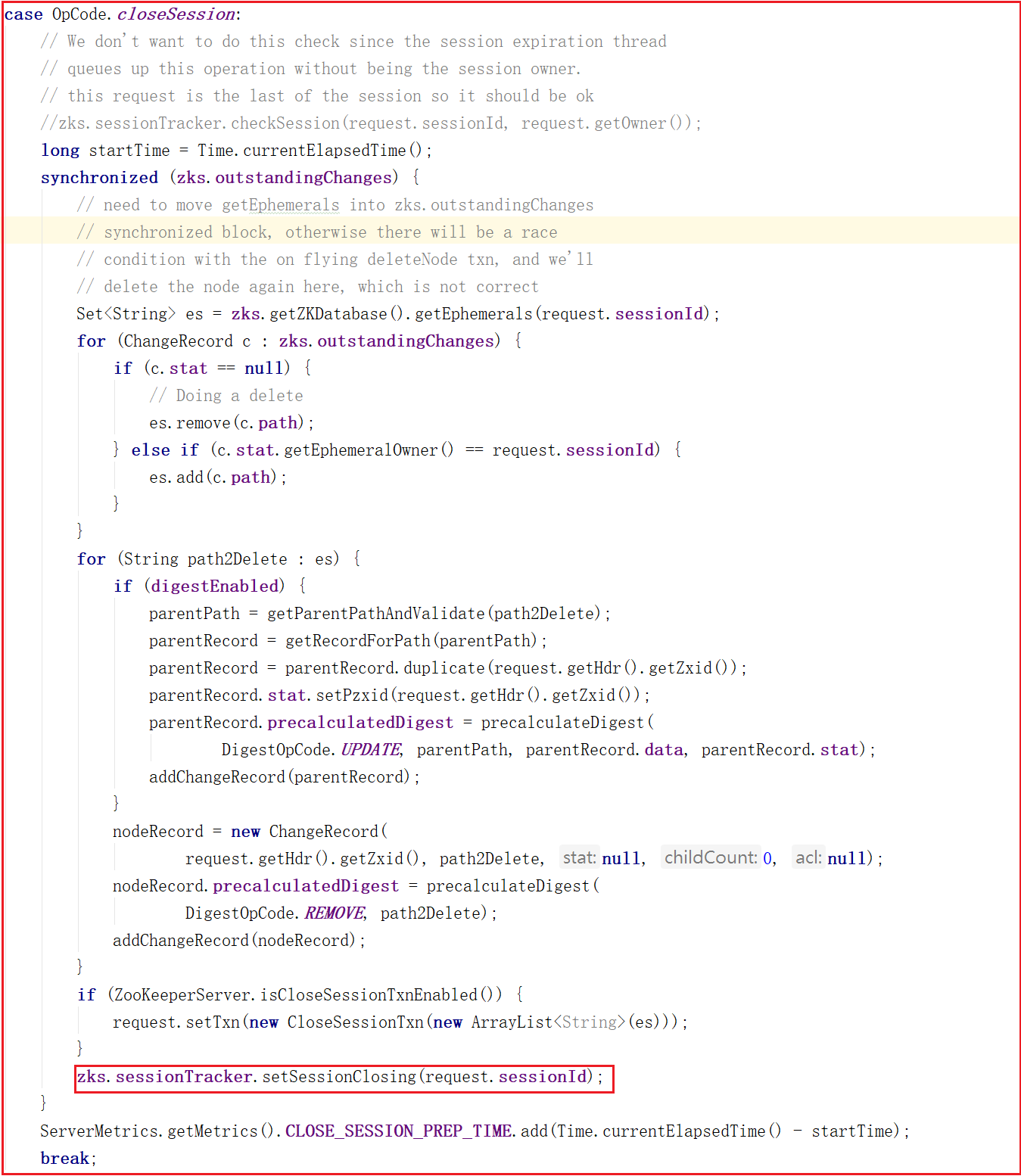
業務鏈處理對象FinalRequestProcessor.processRequest()方法調用了ZooKeeperServer.processTxn(),並且在processTxn()方法中執行了processTxnForSessionEvents,而processTxnForSessionEvents()方法正好移除了會話信息,方法源碼如下:
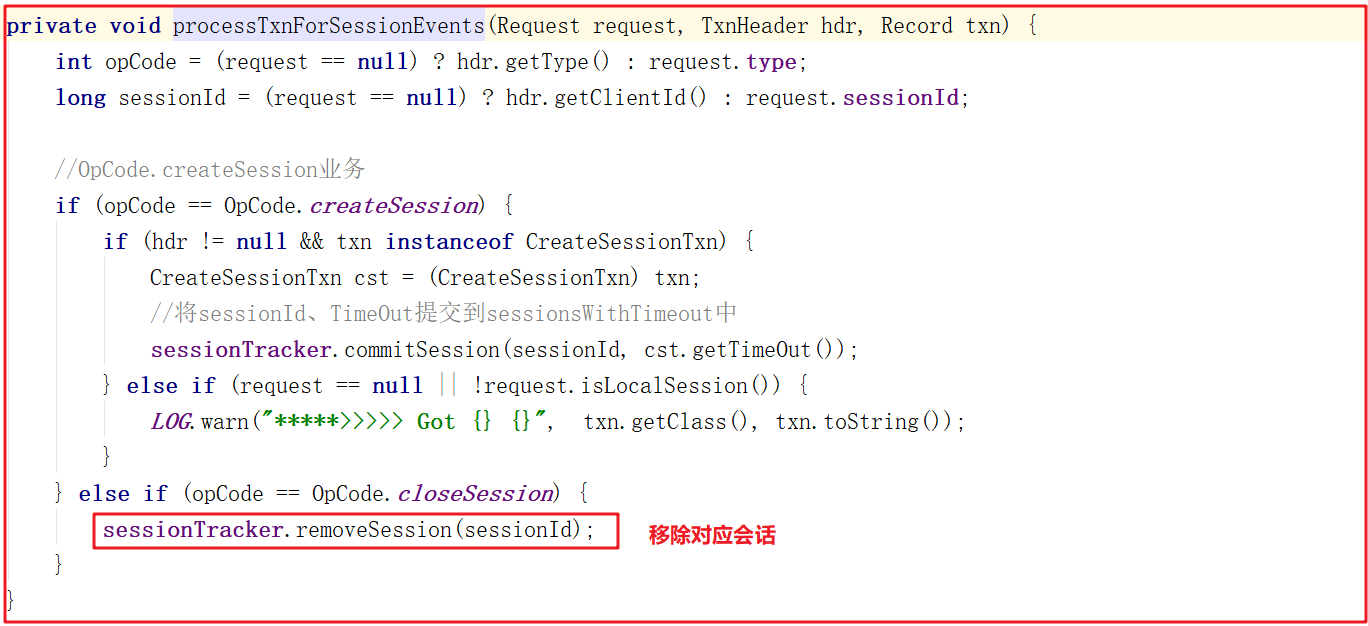
移除會話的方法SessionTrackerImpl.removeSession()會移除會話ID以及過期會話對象,源碼如下:
1.5 Zookeeper會話測試
為了讓Zookeeper的會話理解更深刻,我們對會話流程做一個測試,首先測試會話創建,再測試會話刷新。
1)會話創建測試
我們打開NIOServerCnxn.readPayload()方法,跟蹤首次創建會話,調試情況如下:
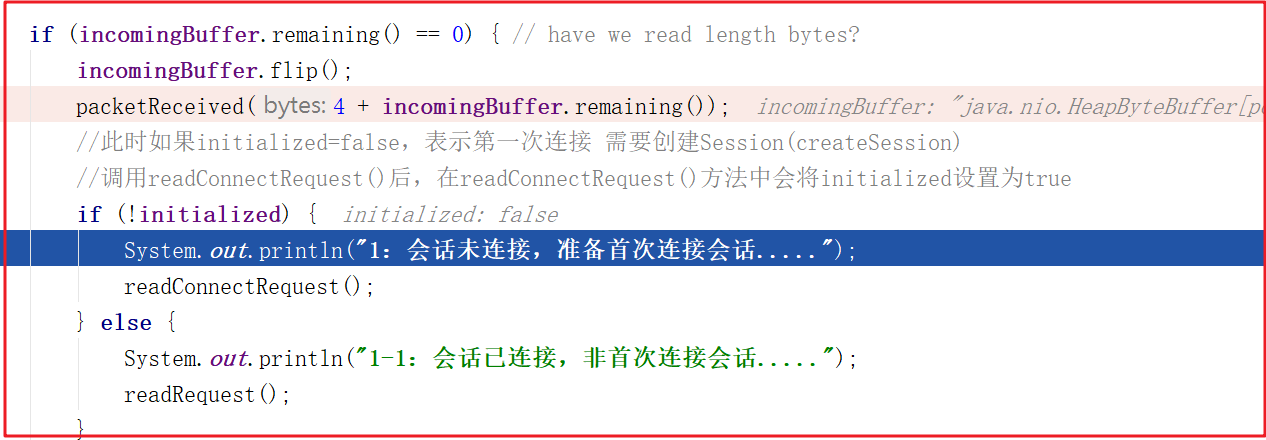
此時會建立遠程連接並創建SessionID,我們調試到NIOServerCnxn.readConnectRequest()方法,此時建立鏈接,並且得到的sessionId=0。
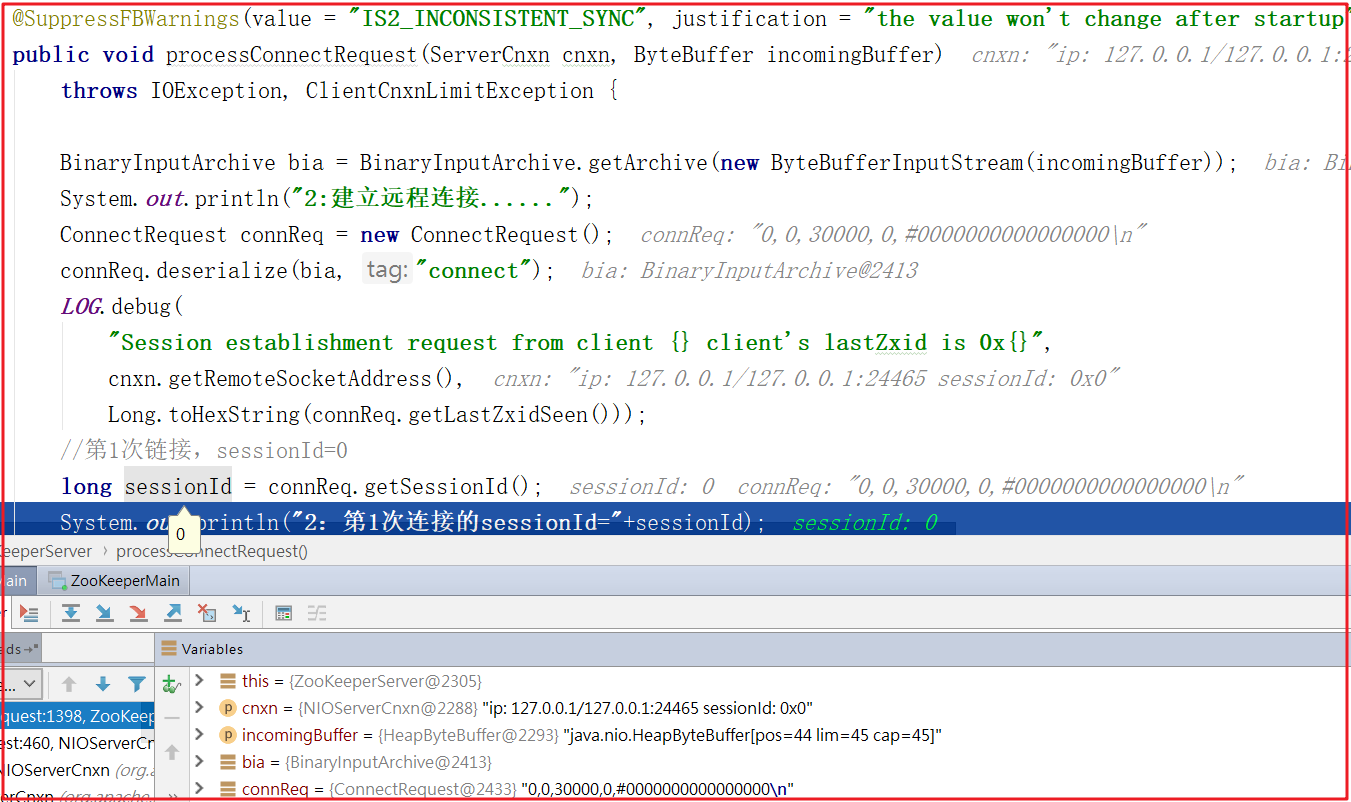
當sessionId=0時,會執行Session創建,Session創建會調用SessionTrackerImpl.createSession()方法實現會話創建,並將會話存入跟蹤隊列,DEBUG測試如下:
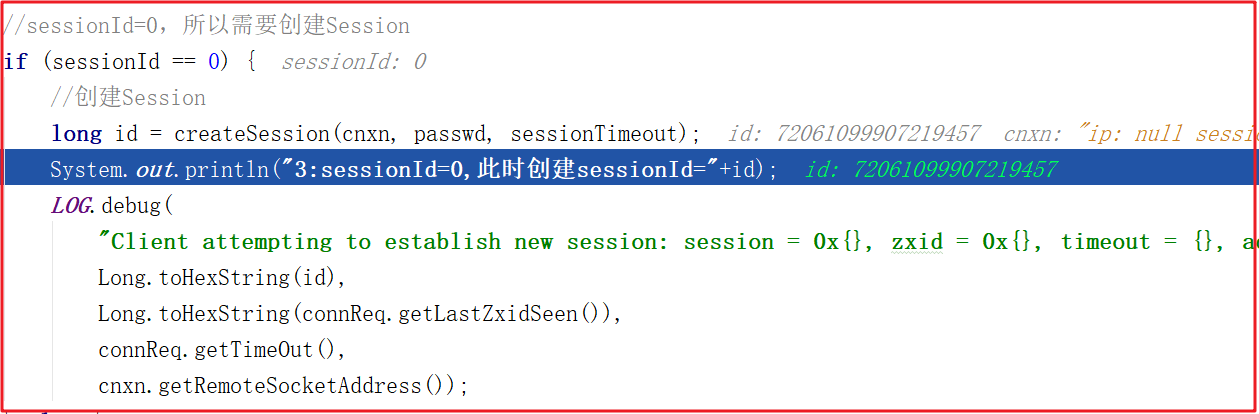
會話創建代碼如下:
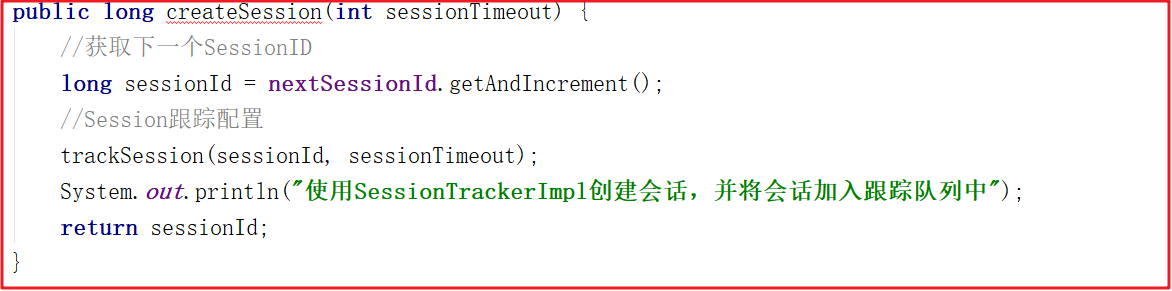
跟蹤測試後,控制台輸出如下信息:
AcceptThread----------鏈接服務的IP:127.0.0.1
1:會話未連接,準備首次連接會話.....
2:建立遠程連接......
2:第1次連接的sessionId=0
使用SessionTrackerImpl創建會話,並將會話加入跟蹤隊列中
3:sessionId=0,此時創建sessionId=72061099907219458
2)會話刷新測試
我們執行get /zookeeper指令,然後首先跟蹤到RequestThrottler.run()方法,執行如下:

執行程式到達ZooKeeperServer.touch(),即將開始準備刷新會話了,我們測試效果如下:
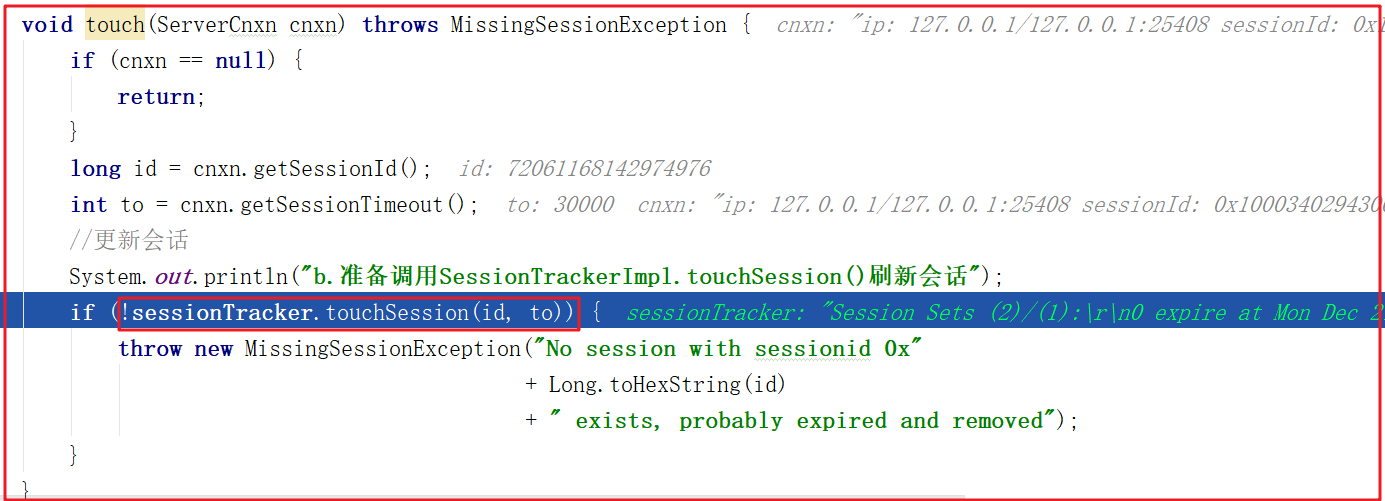
調用SessionTrackerImpl.touchSession()的時候會先判斷會話是否為空、會話是否已經關閉,如果都沒有,才執行刷新會話操作,DEBUG跟蹤如下:
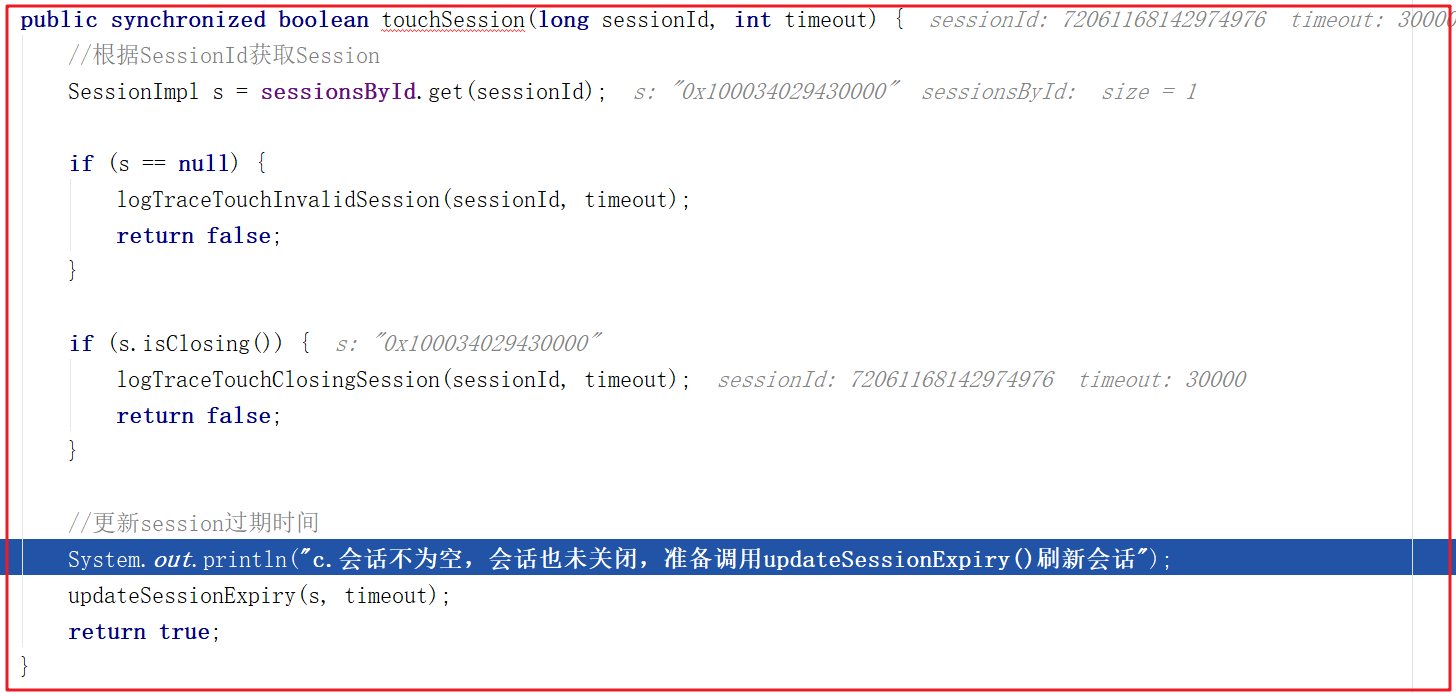
刷新會話其實就是會話時間增加,增加會話時間DEBUG跟蹤如下:
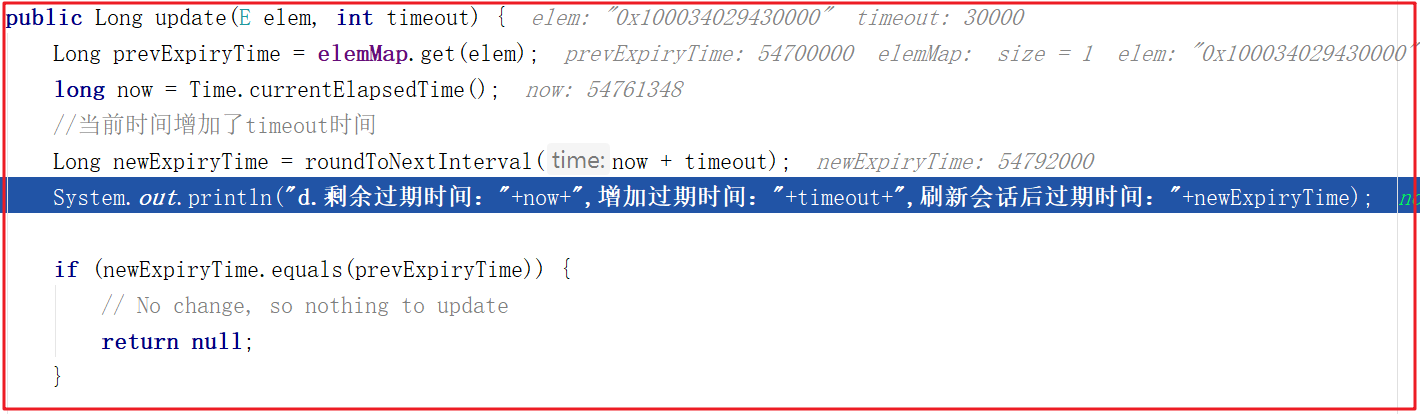
測試後效果如下:
a.當前請求並未過期,不需要刪除,準備刷新會話
b.準備調用SessionTrackerImpl.touchSession()刷新會話
c.會話不為空,會話也未關閉,準備調用updateSessionExpiry()刷新會話
d.剩餘過期時間:54572178,增加過期時間:30000,刷新會話後過期時間:54604000
2 Zookeeper集群啟動流程
我們先搭建Zookeeper集群,再來分析選舉演算法。
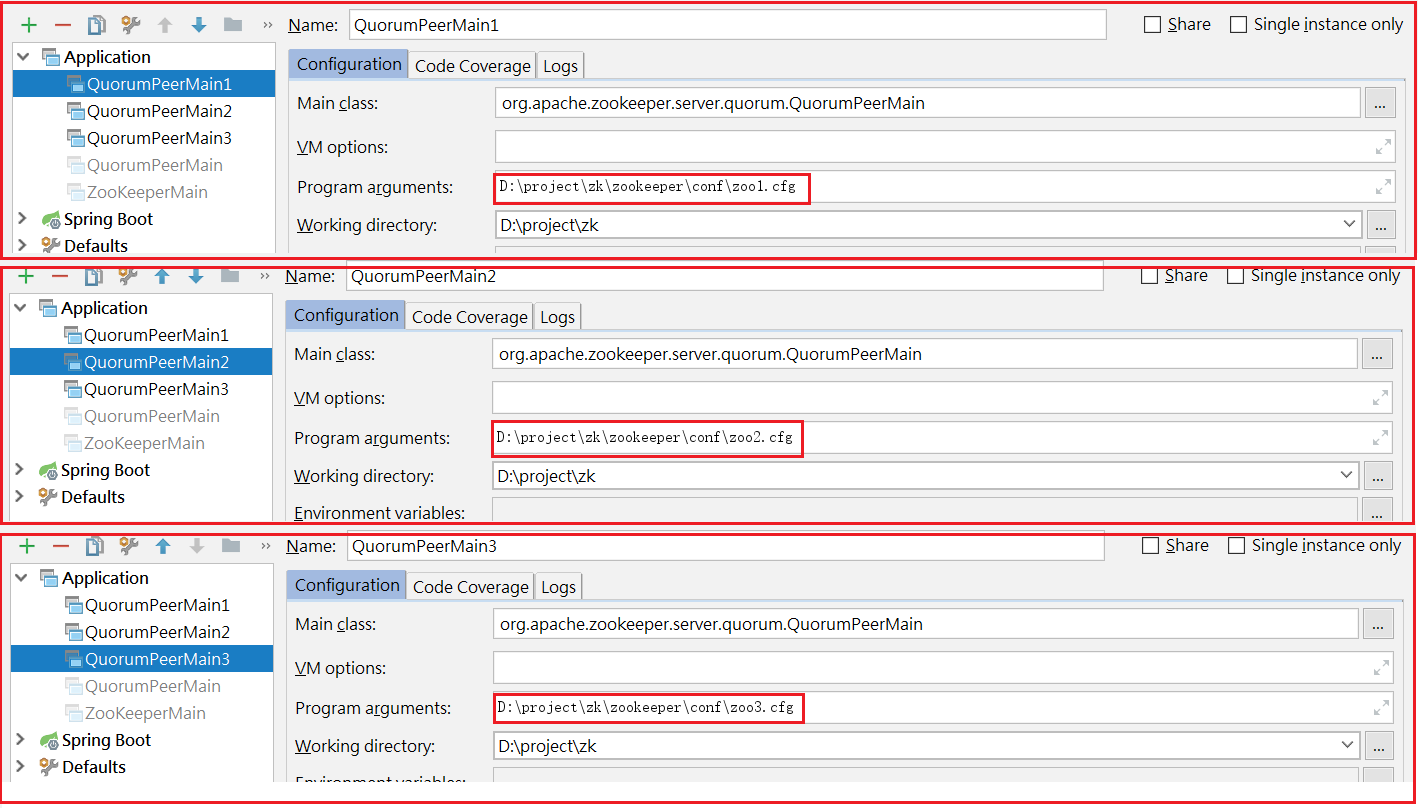
2.1 Zookeeper集群配置

如上圖:
1:創建zoo1.cfg、zoo2.cfg、zoo3.cfg
2:創建zkdata1、zkdata2、zkdata3
3:創建3個myid,值分別為1、2、3
配置3個啟動類,如下圖:
2.2 集群啟動流程分析
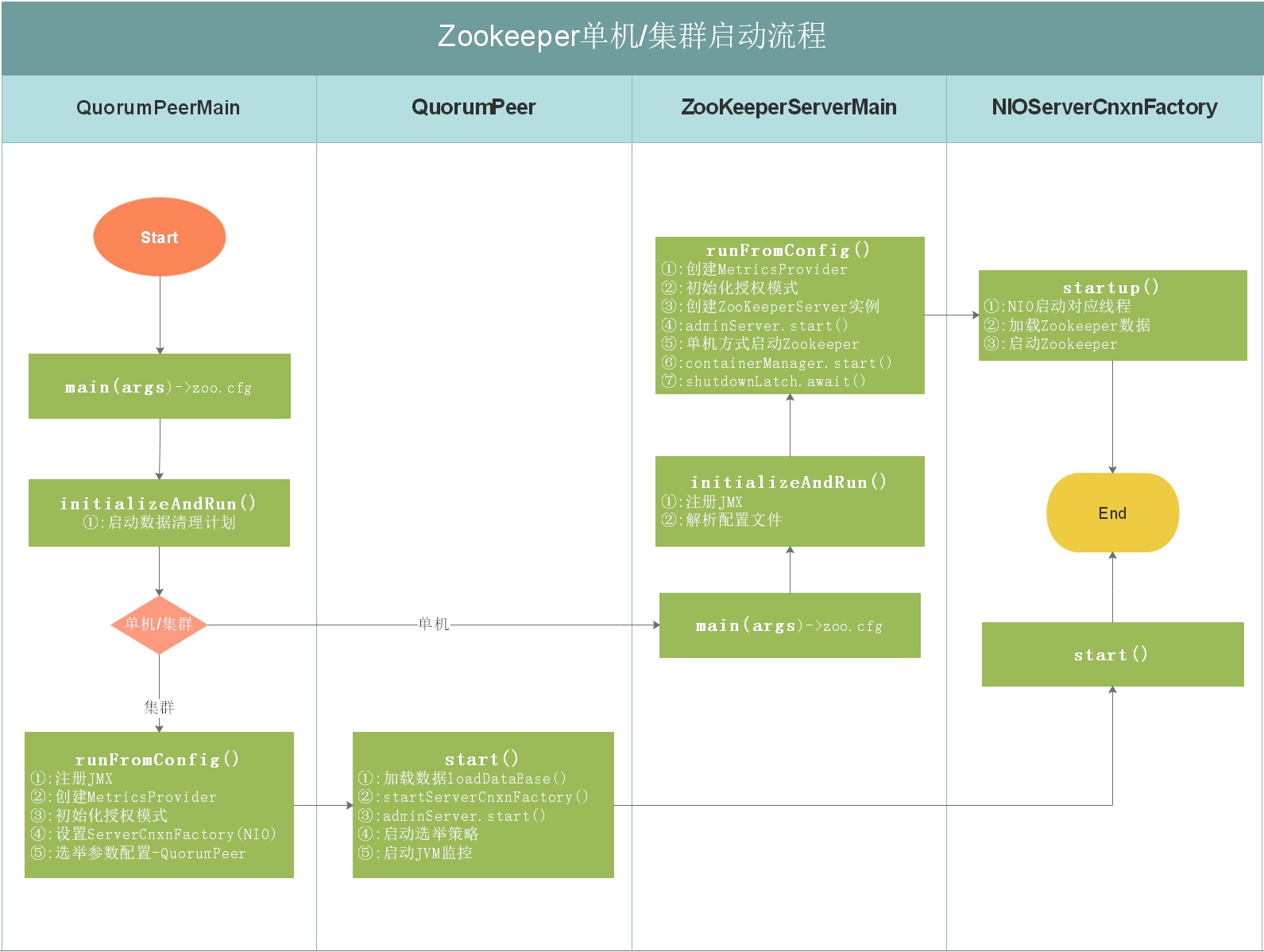
如上圖,上圖是Zookeeper單機/集群啟動流程,每個細節所做的事情都在上圖有說明,我們接下來按照流程圖對源碼進行分析。
程式啟動,運行流程啟動集群模式,如下圖:

quorumPeer.start()啟動服務,如下代碼:

quorumPeer.start()方法代碼如下:
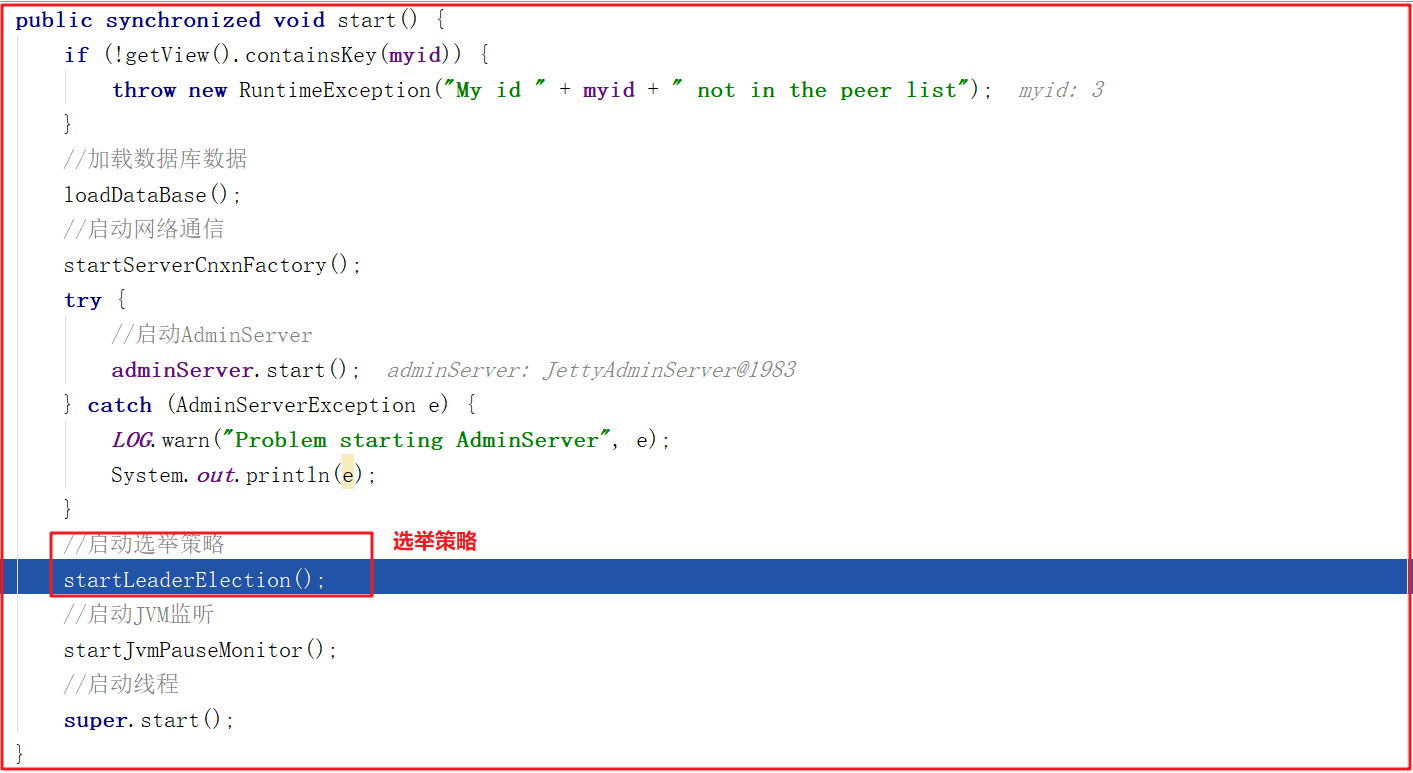
quorumPeer.start()方法啟動的主要步驟:
1:loadDataBase()載入數據。
2:startServerCnxnFactory 用來開啟acceptThread、SelectorThread和workerPool線程池。
3:開啟Leader選舉startLeaderElection。
4:開啟JVM監控線程startJvmPauseMonitor。
5:調用父類super.start();進行Leader選舉。
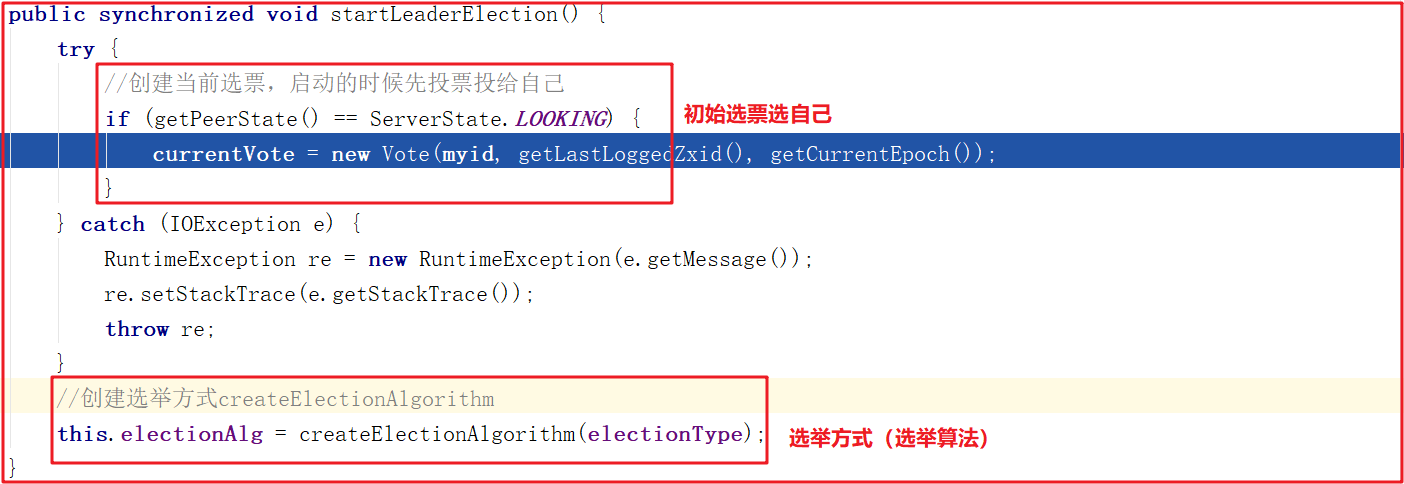
startLeaderElection()開啟Leader選舉方法做了2件事,首先創建初始化選票選自己,接著創建選舉投票方式,源碼如下:
createElectionAlgorithm()創建選舉演算法只有第3種,其他2種均已廢棄,方法源碼如下:
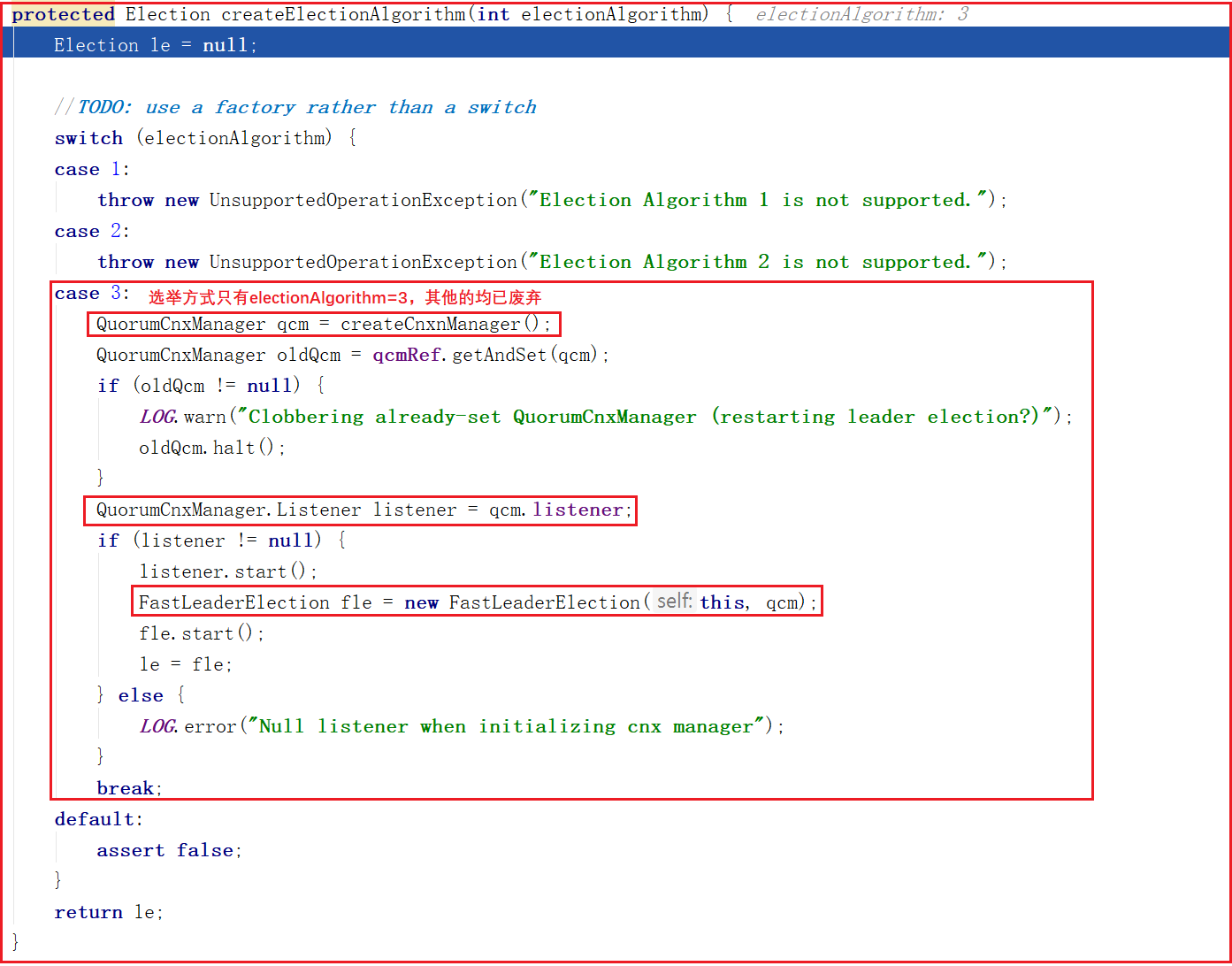
這個方法創建了以下三個對象:
①、創建QuorumCnxManager對象
②、QuorumCnxManager.Listener
③、FastLeaderElection
3 Zookeeper集群Leader選舉
3.1 Paxos演算法介紹
Zookeeper選舉主要依賴於FastLeaderElection演算法,其他演算法均已淘汰,但FastLeaderElection演算法又是典型的Paxos演算法,所以我們要先學習下Paxos演算法,這樣更有助於掌握FastLeaderElection演算法。
1)Paxos介紹
分散式事務中常見的事務模型有2PC和3PC,無論是2PC提交還是3PC提交都無法徹底解決分散式的一致性問題以及無法解決太過保守及容錯性不好。Google Chubby的作者Mike Burrows說過,世上只有一種一致性演算法,那就是Paxos,所有其他一致性演算法都是Paxos演算法的不完整版。Paxos演算法是公認的晦澀,很難講清楚,但是工程上也很難實現,所以有很多Paxos演算法的工程實現,如Chubby, Raft,ZAB,微信的PhxPaxos等。這一篇會介紹這個公認為難於理解但是行之有效的Paxos演算法。Paxos演算法是萊斯利·蘭伯特(Leslie Lamport)1990年提出的一種基於消息傳遞的一致性演算法,它曾就此發表了《The Part-Time Parliament》,《Paxos Made Simple》,由於採用故事的方式來解釋此演算法,感覺還是很難理解。
2)Paxos演算法背景
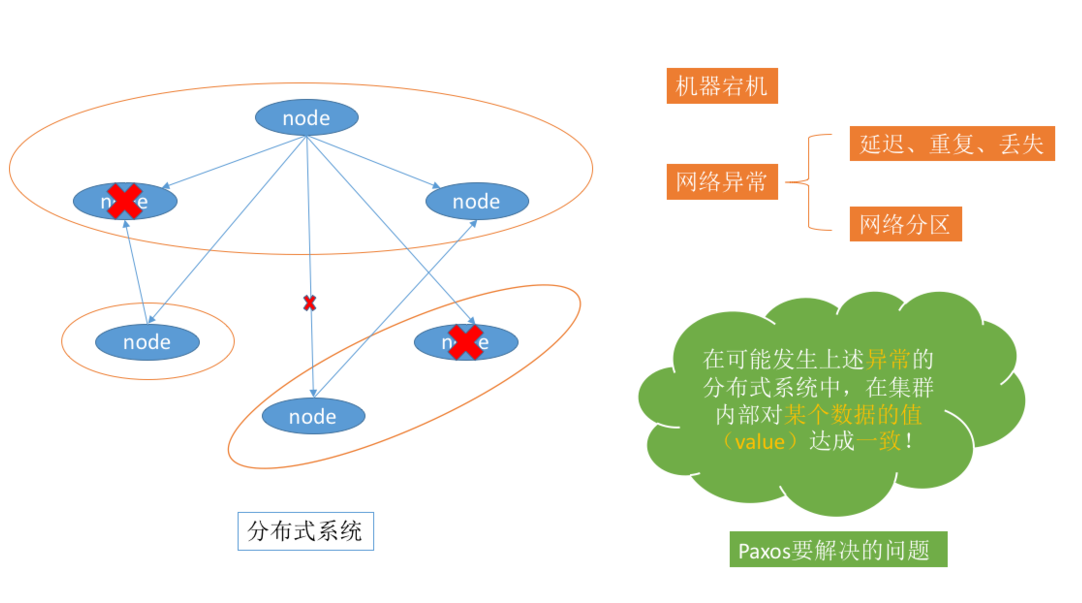
Paxos演算法是基於消息傳遞且具有高度容錯特性的一致性演算法,是目前公認的解決分散式一致性問題最有效的演算法之一,其解決的問題就是在分散式系統中如何就某個值(決議)達成一致。
面試的時候:不要把這個Paxos演算法達到的目的和分散式事務聯繫起來,而是針對Zookeeper這樣的master-slave集群對某個決議達成一致,也就是副本之間寫或者leader選舉達成一致。我覺得這個演算法和狹義的分散式事務不是一樣的。
在常見的分散式系統中,總會發生諸如機器宕機或網路異常(包括消息的延遲、丟失、重覆、亂序,還有網路分區)(也就是會發生異常的分散式系統)等情況。Paxos演算法需要解決的問題就是如何在一個可能發生上述異常的分散式系統中,快速且正確地在集群內部對某個數據的值達成一致。也可以理解成分散式系統中達成狀態的一致性。
3)Paxos演算法理解
Paxos 演算法是分散式一致性演算法用來解決一個分散式系統如何就某個值(決議)達成一致的問題。一個典型的場景是,在一個分散式資料庫系統中,如果各節點的初始狀態一致,每個節點都執行相同的操作序列,那麼他們最後能得到一個一致的狀態。為保證每個節點執行相同的命令序列,需要在每一條指令上執行一個”一致性演算法”以保證每個節點看到的指令一致。
分散式系統中一般是通過多副本來保證可靠性,而多個副本之間會存在數據不一致的情況。所以必須有一個一致性演算法來保證數據的一致,描述如下:
假如在分散式系統中初始是各個節點的數據是一致的,每個節點都順序執行系列操作,然後每個節點最終的數據還是一致的。
Paxos演算法就是解決這種分散式場景中的一致性問題。對於一般的開發人員來說,只需要知道paxos是一個分散式選舉演算法即可。多個節點之間存在兩種通訊模型:共用記憶體(Shared memory)、消息傳遞(Messages passing),Paxos是基於消息傳遞的通訊模型的。
4)Paxos相關概念
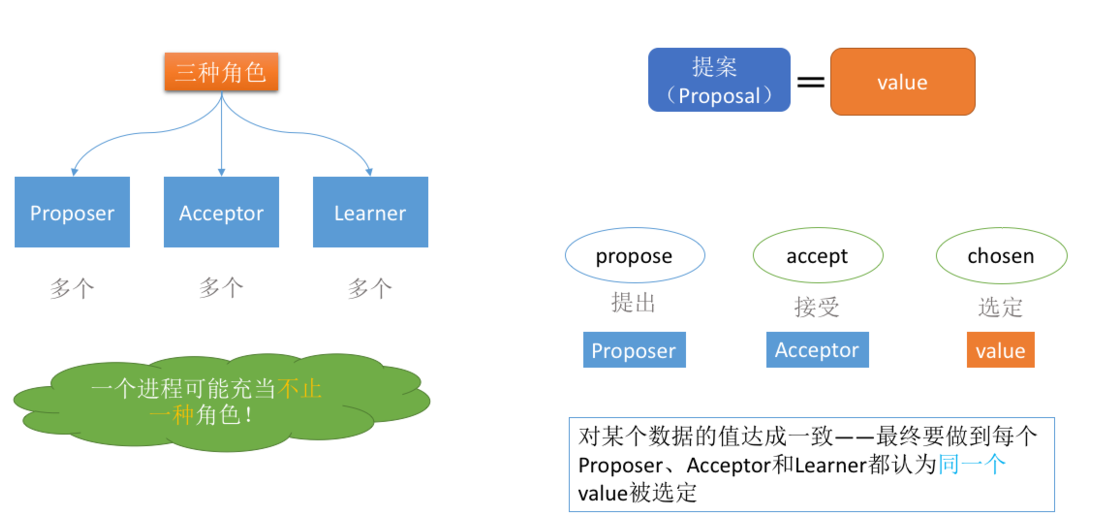
在Paxos演算法中,有三種角色:
- Proposer
- Acceptor
- Learners
在具體的實現中,一個進程可能同時充當多種角色。比如一個進程可能既是Proposer又是Acceptor又是Learner。Proposer負責提出提案,Acceptor負責對提案作出裁決(accept與否),learner負責學習提案結果。
還有一個很重要的概念叫提案(Proposal)。最終要達成一致的value就在提案里。只要Proposer發的提案被Acceptor接受(半數以上的Acceptor同意才行),Proposer就認為該提案里的value被選定了。Acceptor告訴Learner哪個value被選定,Learner就認為那個value被選定。只要Acceptor接受了某個提案,Acceptor就認為該提案里的value被選定了。
為了避免單點故障,會有一個Acceptor集合,Proposer向Acceptor集合發送提案,Acceptor集合中的每個成員都有可能同意該提案且每個Acceptor只能批准一個提案,只有當一半以上的成員同意了一個提案,就認為該提案被選定了。
3.2 QuorumPeer工作流程
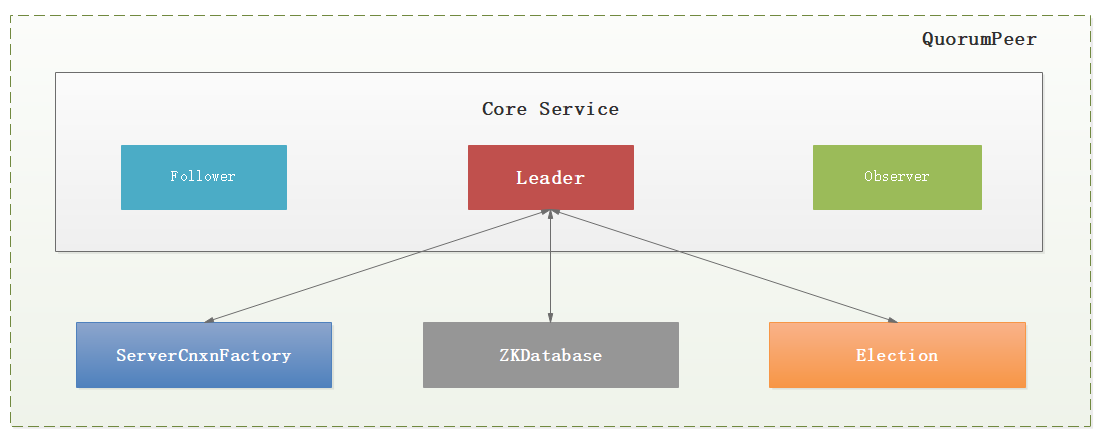
QuorumCnxManager:每台伺服器在啟動的過程中,會啟動一個QuorumPeer,負責各台伺服器之間的底層Leader選舉過程中的網路通信對應的類就是QuorumCnxManager。
Zookeeper對於每個節點QuorumPeer的設計相當的靈活,QuorumPeer主要包括四個組件:客戶端請求接收器(ServerCnxnFactory)、數據引擎(ZKDatabase)、選舉器(Election)、核心功能組件(Leader/Follower/Observer)。
1:ServerCnxnFactory負責維護與客戶端的連接(接收客戶端的請求併發送相應的響應);(1001行)
2:ZKDatabase負責存儲/載入/查找數據(基於目錄樹結構的KV+操作日誌+客戶端Session);(129行)
3:Election負責選舉集群的一個Leader節點;(998行)
4:Leader/Follower/Observer確認是QuorumPeer節點應該完成的核心職責;(1270行)
QuorumPeer工作流程比較複雜,如下圖:
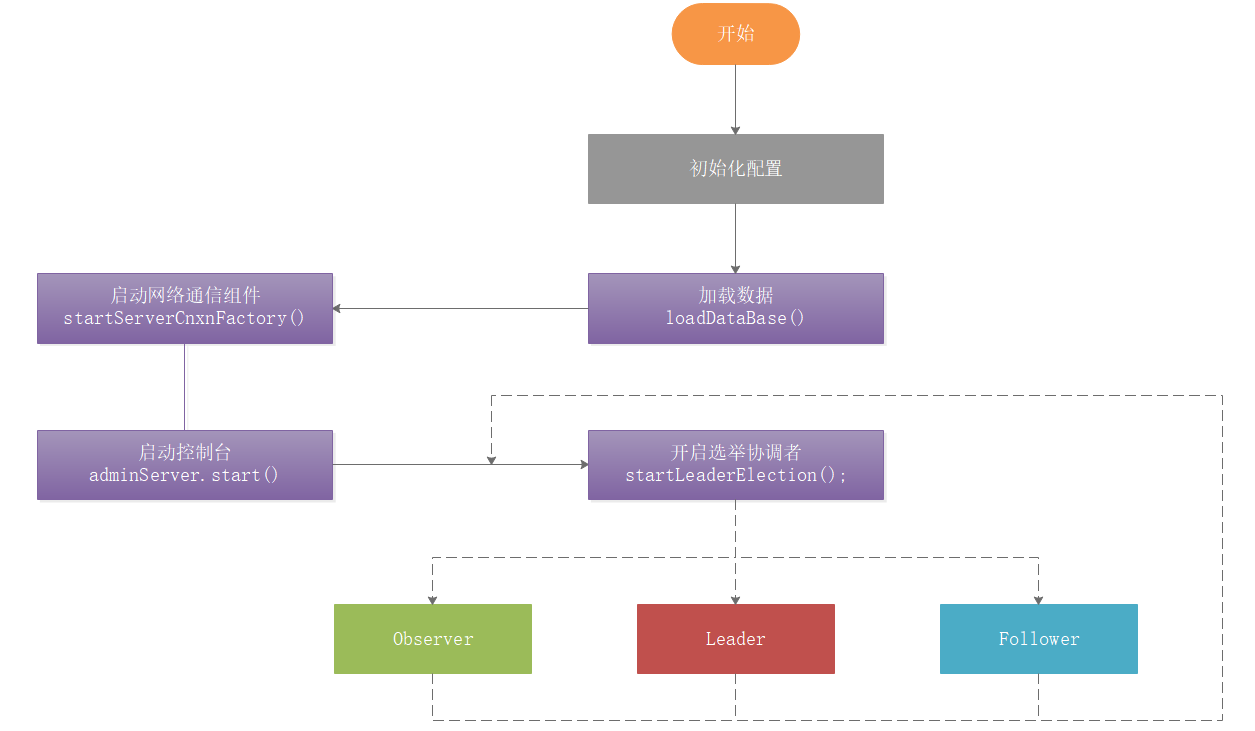
QuorumPeer工作流程:
1:初始化配置
2:載入當前存在的數據
3:啟動網路通信組件
4:啟動控制台
5:開啟選舉協調者,並執行選舉(這個過程是會持續,並不是一次操作就結束了)
3.3 QuorumCnxManager源碼分析
QuorumCnxManager內部維護了一系列的隊列,用來保存接收到的、待發送的消息以及消息的發送器,除接收隊列以外,其他隊列都按照SID分組形成隊列集合,如一個集群中除了自身還有3台機器,那麼就會為這3台機器分別創建一個發送隊列,互不幹擾。
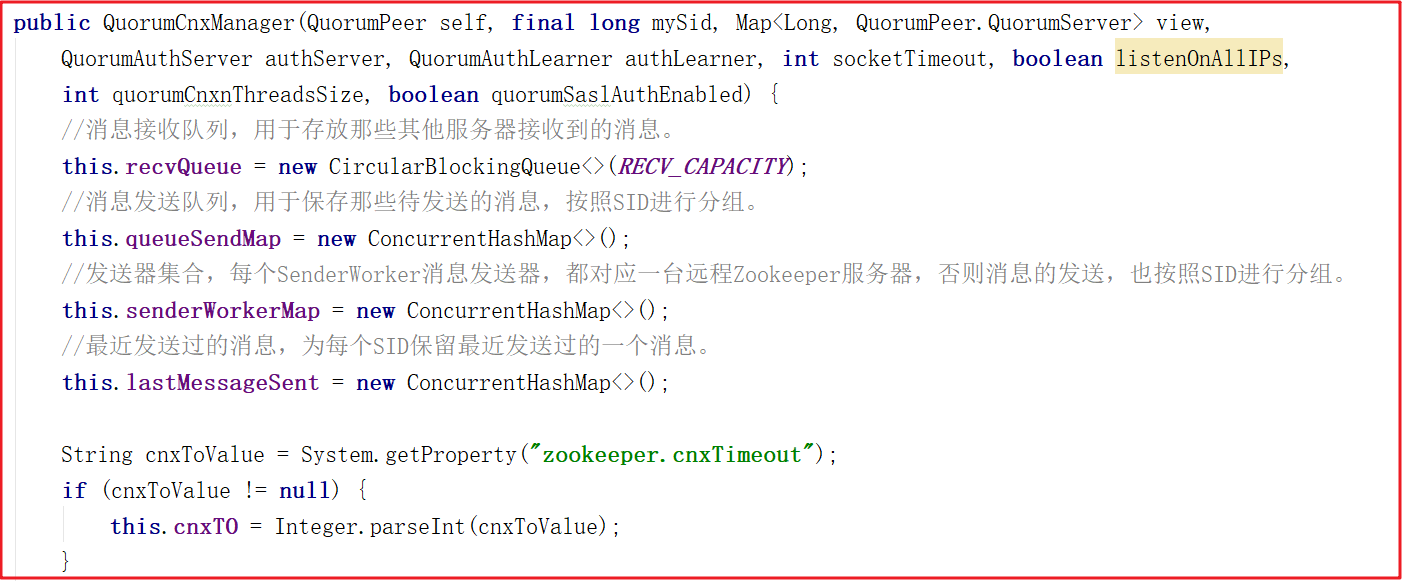
QuorumCnxManager.Listener :為了能夠相互投票,Zookeeper集群中的所有機器都需要建立起網路連接。QuorumCnxManager在啟動時會創建一個ServerSocket來監聽Leader選舉的通信埠。開啟監聽後,Zookeeper能夠不斷地接收到來自其他伺服器地創建連接請求,在接收到其他伺服器地TCP連接請求時,會進行處理。為了避免兩台機器之間重覆地創建TCP連接,Zookeeper只允許SID大的伺服器主動和其他機器建立連接,否則斷開連接。在接收到創建連接請求後,伺服器通過對比自己和遠程伺服器的SID值來判斷是否接收連接請求,如果當前伺服器發現自己的SID更大,那麼會斷開當前連接,然後自己主動和遠程伺服器將連接(自己作為“客戶端”)。一旦連接建立,就會根據遠程伺服器的SID來創建相應的消息發送器SendWorker和消息發送器RecvWorker,並啟動。
QuorumCnxManager.Listener監聽啟動可以查看QuorumCnxManager.Listener的run方法,源代碼如下,可以斷點調試看到此時監聽的正是我們所說的投票埠:
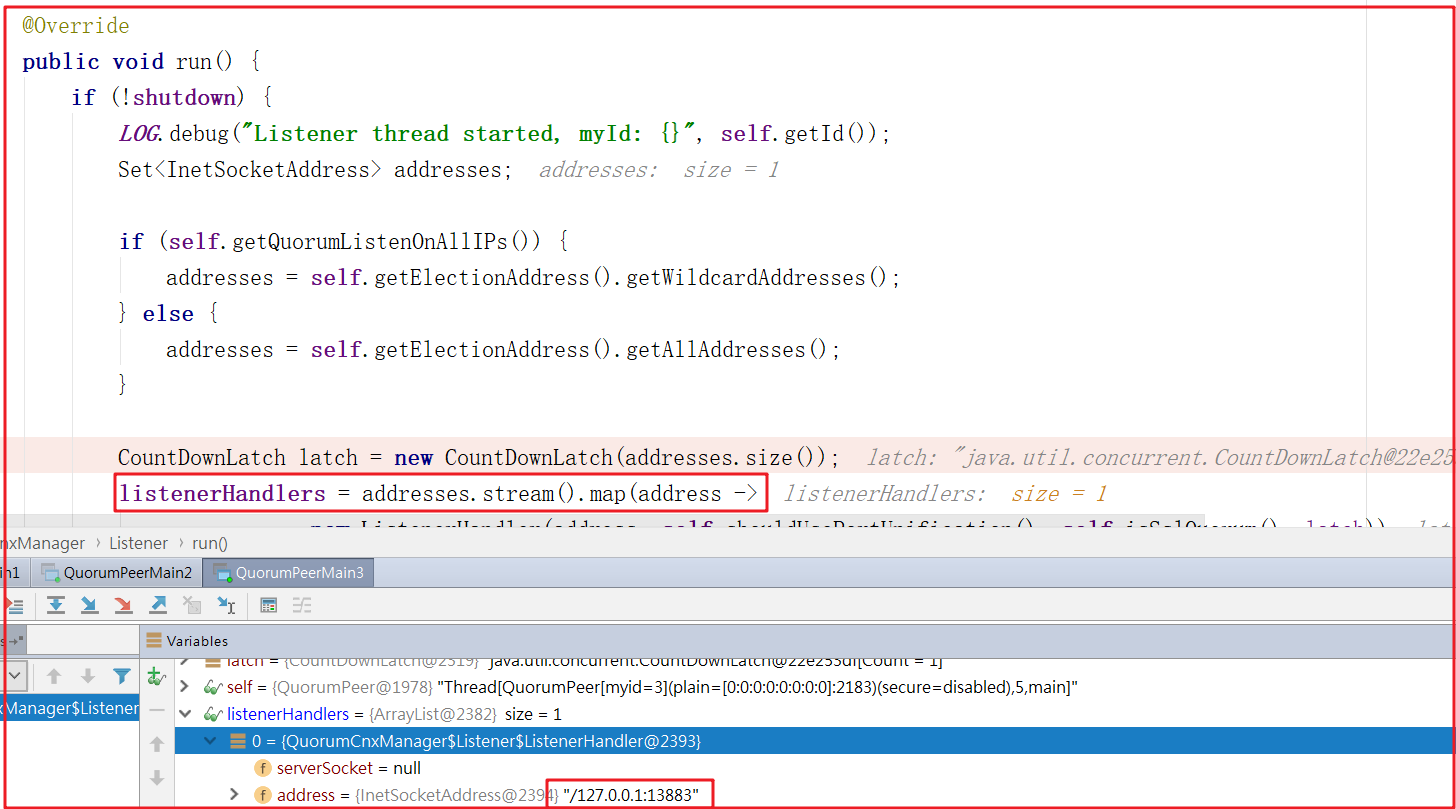
上面是監聽器,各個服務之間進行通信我們需要開啟ListenerHandler線程,在QuorumCnxManager.Listener.ListenerHandler的run方法中有一個方法acceptConnections() 調用,該方法就是用於接受每次選舉投票的信息,如果只有一個節點或者沒有投票信息的時候,此時方法會阻塞,一旦執行選舉,程式會往下執行,我們可以先啟動1台服務,再啟動第2台、第3台,此時會收到有客戶端參與投票鏈接,程式會往下執行,源碼如下:

我們啟動2台服務,效果如下:

上面雖然能證明投票訪問了當前監聽的埠,但怎麼知道是哪台服務呢?我們可以沿著receiveConnection()源碼繼續研究,源碼如下:
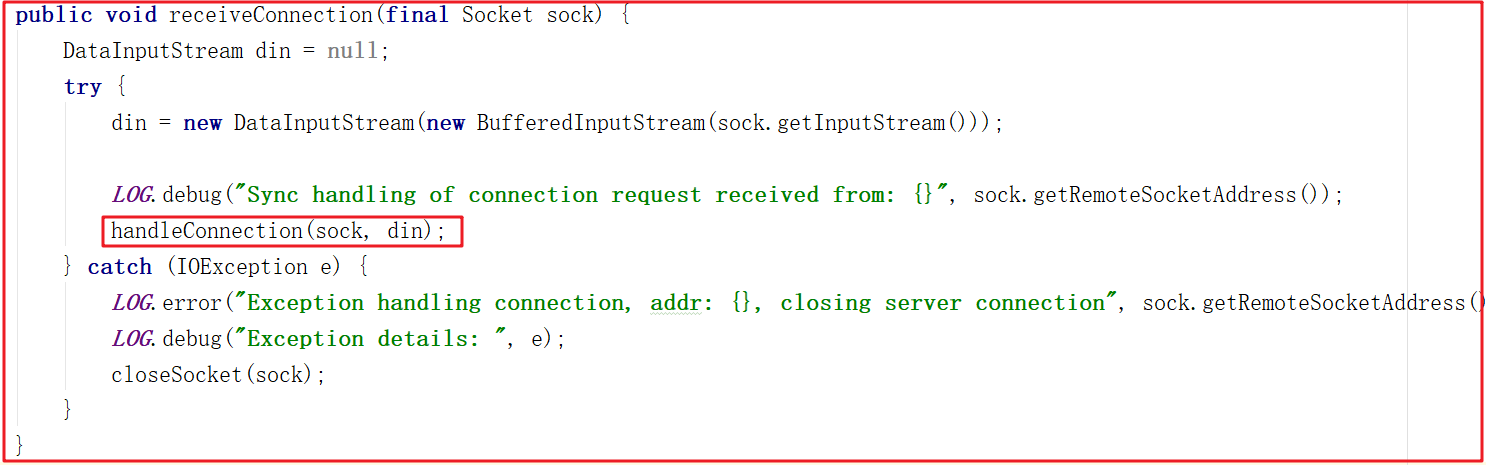
receiveConnection()方法只是獲取了數據流,並沒做特殊處理,並且調用了handleConnection()方法,該方法源碼如下:
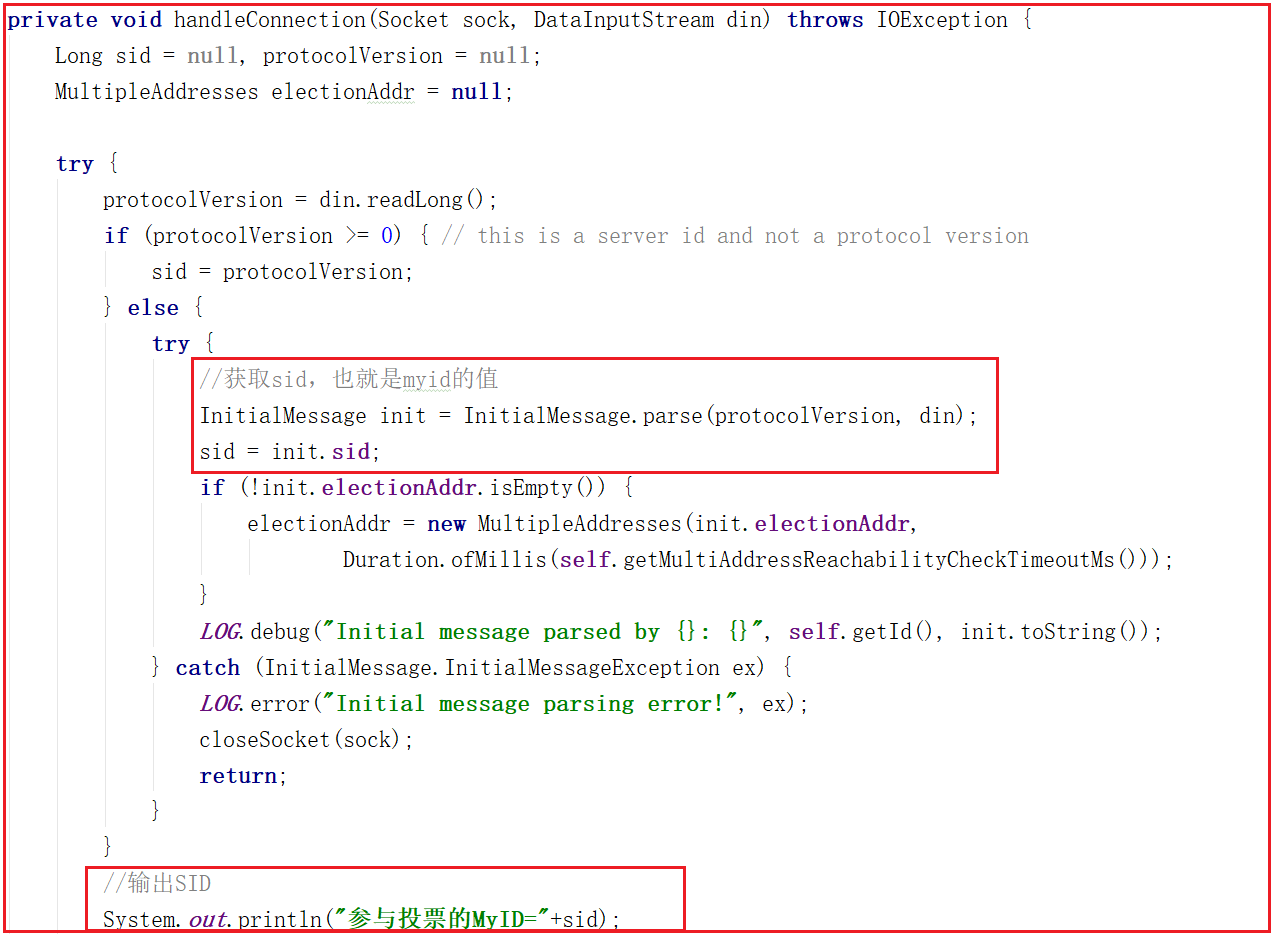
通過網路連接獲取數據sid,獲取sid表示是哪一臺連過來的,我們可以列印輸出sid,測試輸出如下數據:
參與投票的MyID=2
參與投票的MyID=3
3.4 FastLeaderElection演算法源碼分析
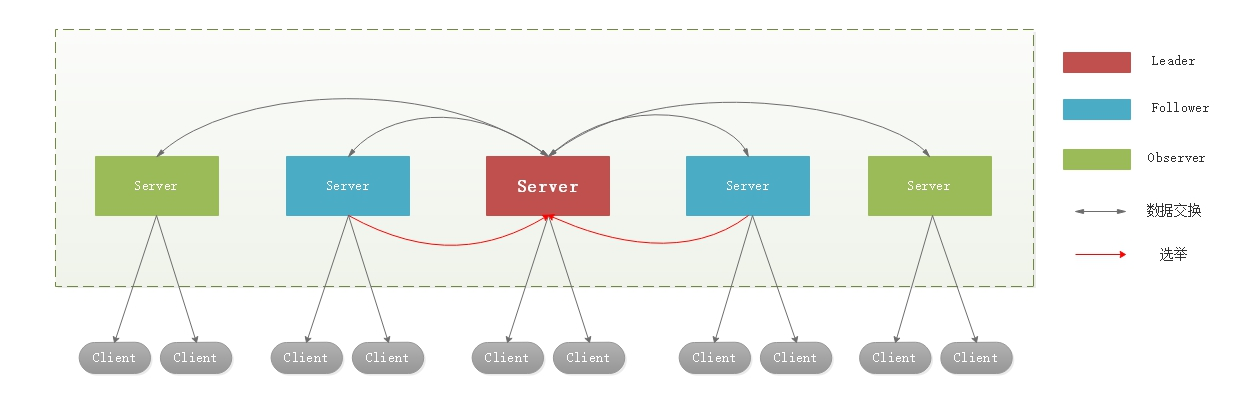
在Zookeeper集群中,主要分為三者角色,而每一個節點同時只能扮演一種角色,這三種角色分別是:
(1)Leader 接受所有Follower的提案請求並統一協調發起提案的投票,負責與所有的Follower進行內部的數據交換(同步);
(2)Follower 直接為客戶端提供服務並參與提案的投票,同時與Leader進行數據交換(同步);
(3)Observer 直接為客戶端服務但並不參與提案的投票,同時也與Leader進行數據交換(同步);
FastLeaderElection 選舉演算法是標準的 Fast Paxos 演算法實現,可解決 LeaderElection 選舉演算法收斂速度慢的問題。
創建FastLeaderElection 只需要new FastLeaderElection()即可,如下代碼:

創建FastLeaderElection會調用starter()方法,該方法會創建sendqueue、recvqueue隊列、Messenger對象,其中Messenger對象的作用非常關鍵,方法源碼如下:

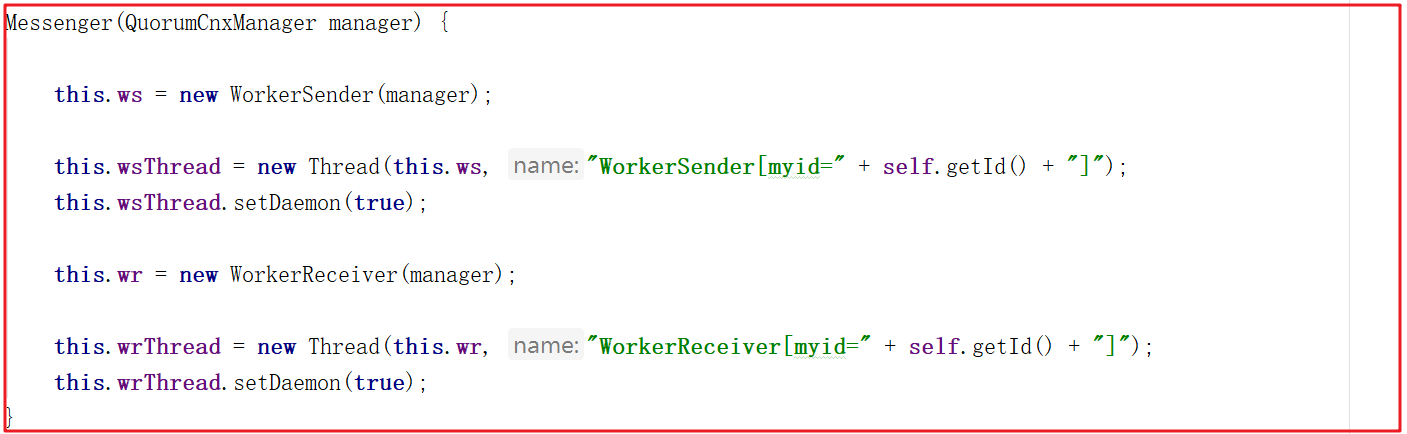
創建Messenger的時候,會創建WorkerSender並封裝成wsThread線程,創建WorkerReceiver並封裝成wrThread線程,看名字就很容易理解,wsThread用於發送數據,wrThread用於接收數據,Messenger創建源碼如下:
創建完FastLeaderElection後接著會調用它的start()方法啟動選舉演算法,代碼如下:
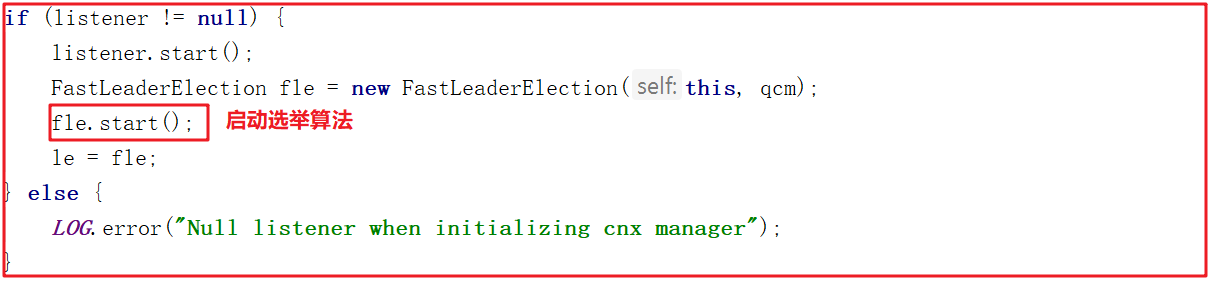
啟動選舉演算法會調用start()方法,start()方法如下:
public void start() {
this.messenger.start();
}
上面會執行messager.start(),也就是如下方法,也就意味著wsThread和wrThread線程都將啟動,源碼如下:
void start() {
this.wsThread.start();
this.wrThread.start();
}
wsThread由WorkerSender封裝而來,此時會調用WorkerSender的run方法,run方法會調用process()方法,源碼如下:
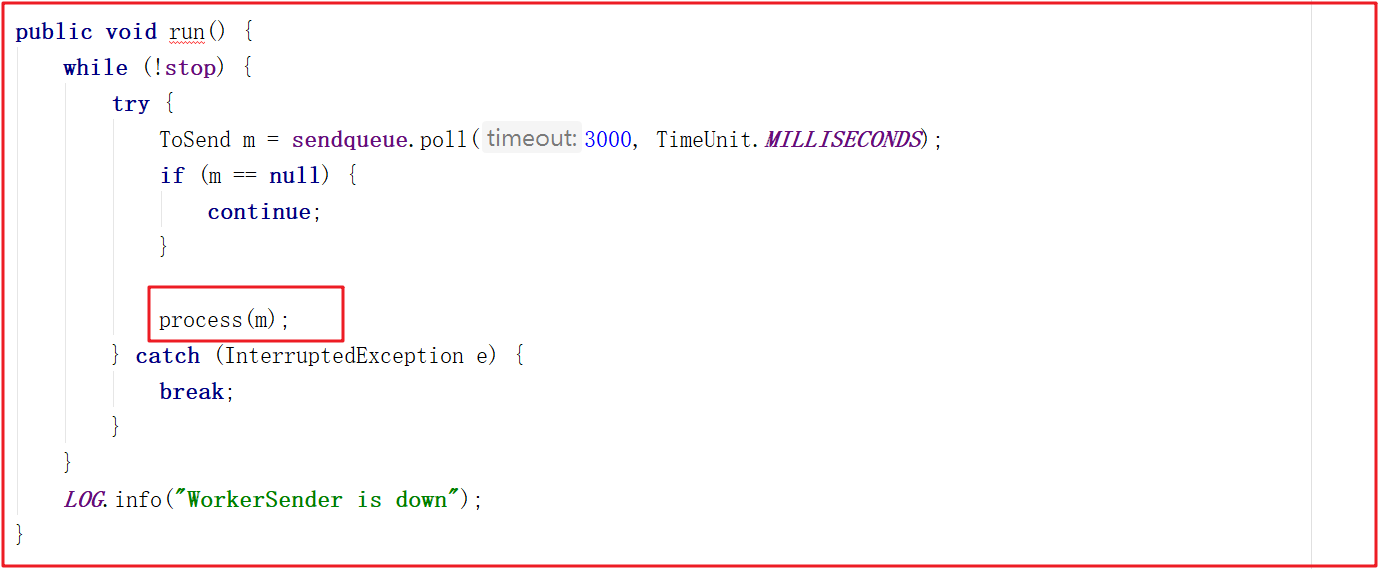
process方法調用了manager的toSend方法,此時是把對應的sid作為了消息發送出去,這裡其實是發送投票信息,源碼如下:
void process(ToSend m) {
ByteBuffer requestBuffer = buildMsg(m.state.ordinal(), m.leader, m.zxid, m.electionEpoch, m.peerEpoch, m.configData);
manager.toSend(m.sid, requestBuffer);
}
投票可以投自己,也可以投別人,如果是選票選自己,只需要把投票信息添加到recvQueue中即可,源碼如下:
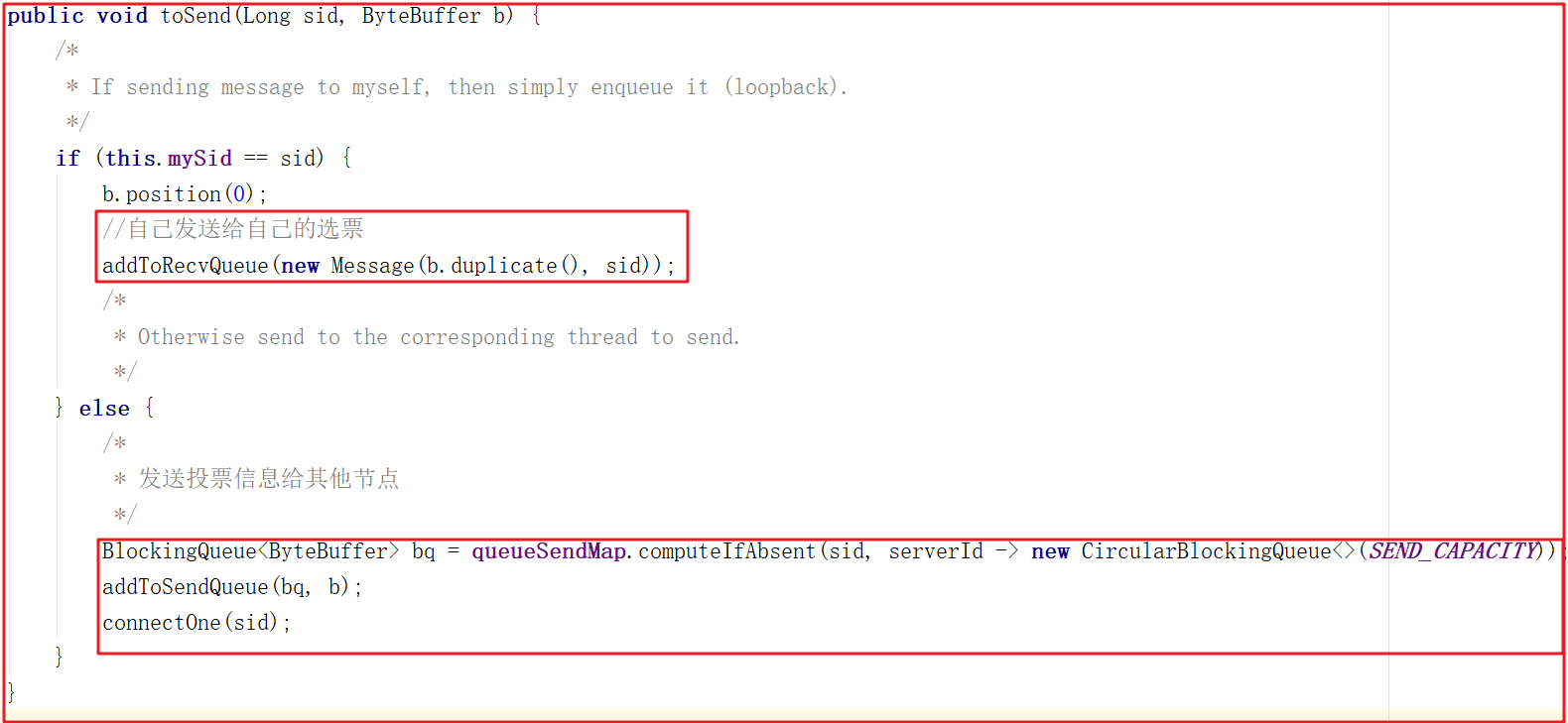
在WorkerReceiver.run方法中會從recvQueue中獲取Message,並把發送給其他服務的投票封裝到sendqueue隊列中,交給WorkerSender發送處理,源碼如下:

3.5 Zookeeper選舉投票剖析
選舉是個很複雜的過程,要考慮很多場景,而且選舉過程中有很多概念需要理解。
3.5.1 選舉概念
1)ZK服務狀態:
public enum ServerState {
//代表沒有當前集群中沒有Leader,此時是投票選舉狀態
LOOKING,
//代表已經是伴隨者狀態
FOLLOWING,
//代表已經是領導者狀態
LEADING,
//代表已經是觀察者狀態(觀察者不參與投票過程)
OBSERVING
}
2)服務角色:
//Learner 是隨從服務和觀察者的統稱
public enum LearnerType {
//隨從者角色
PARTICIPANT,
//觀察者角色
OBSERVER
}
3)投票消息廣播:
public static class Notification {
int version;
//被推薦leader的ID
long leader;
//被推薦leader的zxid
long zxid;
//投票輪次
long electionEpoch;
//當前投票者的服務狀態 (LOOKING)
QuorumPeer.ServerState state;
//當前投票者的ID
long sid;
//QuorumVerifier作為集群驗證器,主要完成判斷一組server在
//已給定的配置的server列表中,是否能夠構成集群
QuorumVerifier qv;
//被推薦leader的投票輪次
long peerEpoch;
}
4)選票模型:
public class Vote {
//投票版本號,作為一個標識
private final int version;
//當前服務的ID
private final long id;
//當前服務事務ID
private final long zxid;
//當前服務投票的輪次
private final long electionEpoch;
//被推舉伺服器的投票輪次
private final long peerEpoch;
//當前伺服器所處的狀態
private final ServerState state;
}
5)消息發送對象:
public static class ToSend {
//支持的消息類型
enum mType {
crequest, //請求
challenge, //確認
notification,//通知
ack //確認回執
}
ToSend(mType type, long leader, long zxid, long electionEpoch, ServerState state, long sid, long peerEpoch, byte[] configData) {
this.leader = leader;
this.zxid = zxid;
this.electionEpoch = electionEpoch;
this.state = state;
this.sid = sid;
this.peerEpoch = peerEpoch;
this.configData = configData;
}
/*
* Proposed leader in the case of notification
* 被投票推舉為leader的服務ID
*/ long leader;
/*
* id contains the tag for acks, and zxid for notifications
*
*/ long zxid;
/*
* Epoch
* 投票輪次
*/ long electionEpoch;
/*
* Current state;
* 服務狀態
*/ QuorumPeer.ServerState state;
/*
* Address of recipient
* 消息接收方服務ID
*/ long sid;
/*
* Used to send a QuorumVerifier (configuration info)
*/ byte[] configData = dummyData;
/*
* Leader epoch
*/ long peerEpoch;
}
3.5.2 選舉過程
QuorumPeer本身是個線程,在集群啟動的時候會執行quorumPeer.start();,此時會調用它重寫的start()方法,最後會調用父類的start()方法,所以該線程會啟動執行,因此會執行它的run方法,而run方法正是選舉流程的入口,我們看run方法關鍵源碼如下:

所有節點初始狀態都為LOOKING,會進入到選舉流程,選舉流程首先要獲取演算法,獲取演算法的方法是makeLEStrategy(),該方法返回的是FastLeaderElection實例,核心選舉流程是FastLeaderElection中的lookForLeader()方法。
/****
* 獲取選舉演算法
*/
@SuppressWarnings("deprecation")
protected Election makeLEStrategy() {
return electionAlg;
}
lookForLeader()是選舉過程的關鍵流程,源碼分析如下:
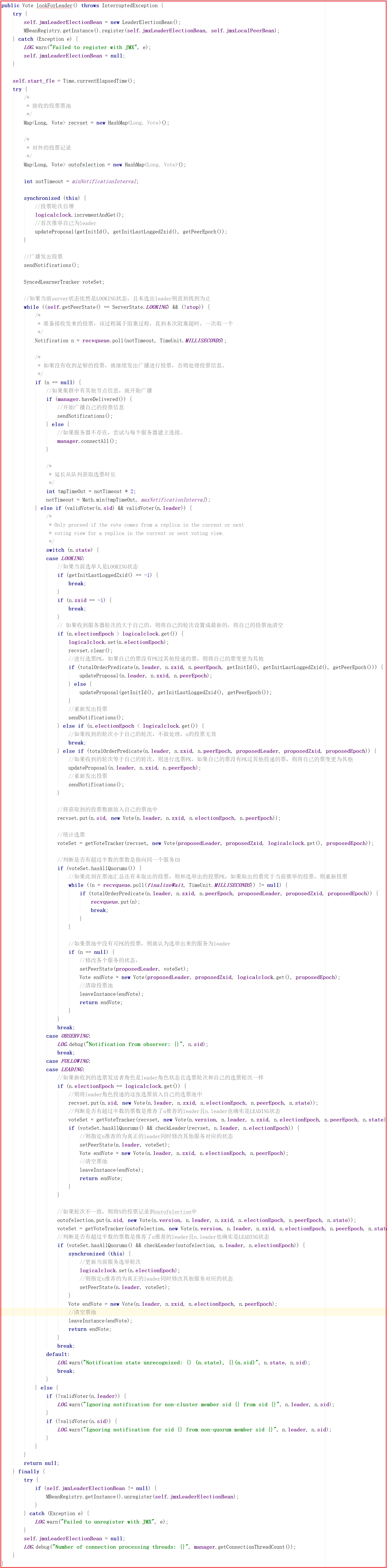
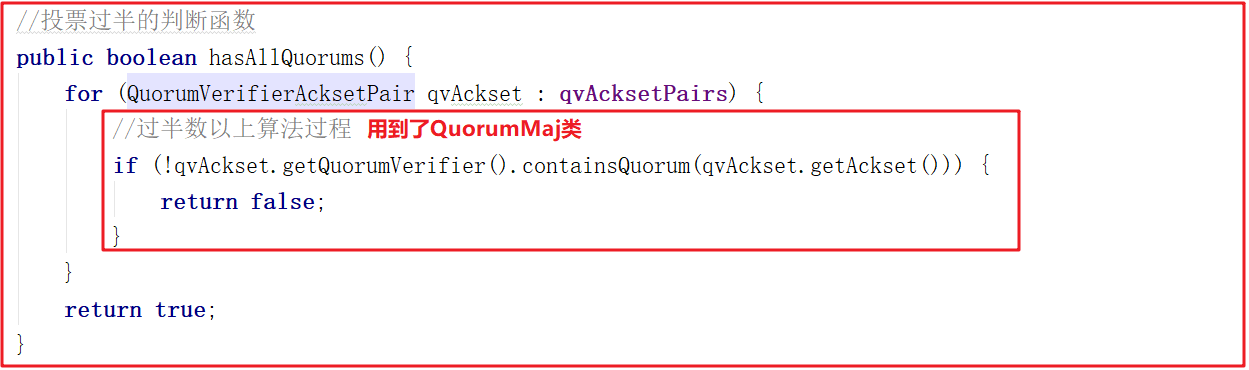
上面多個地方都用到了過半數以上的方法hasAllQuorums()該方法用到了QuorumMaj類,代碼如下:
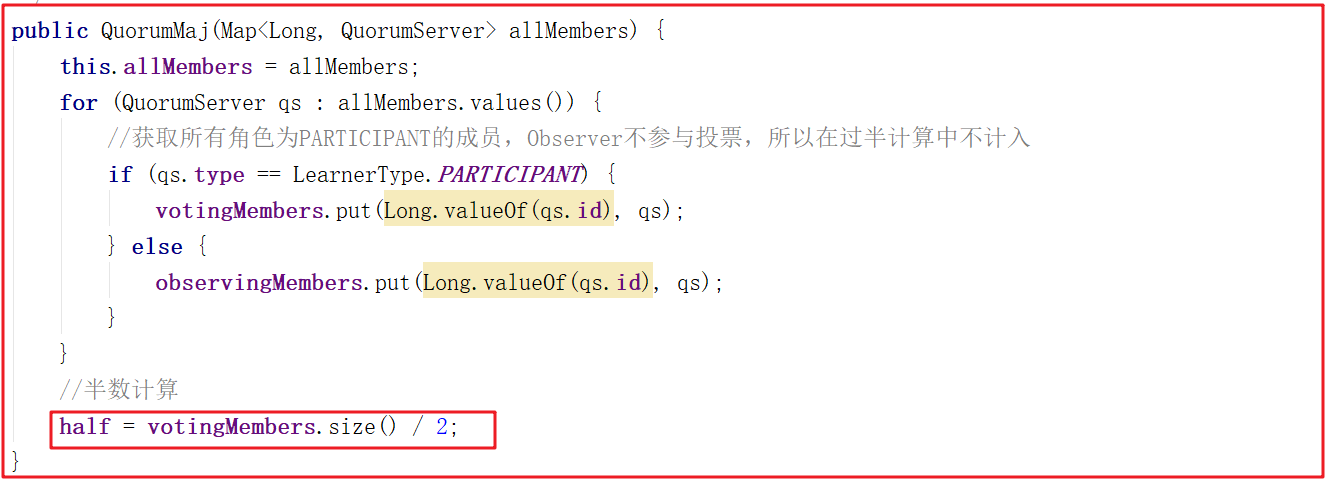
QuorumMaj構造函數中體現了過半數以上的操作,代碼如下:
3.5.3 投票規則
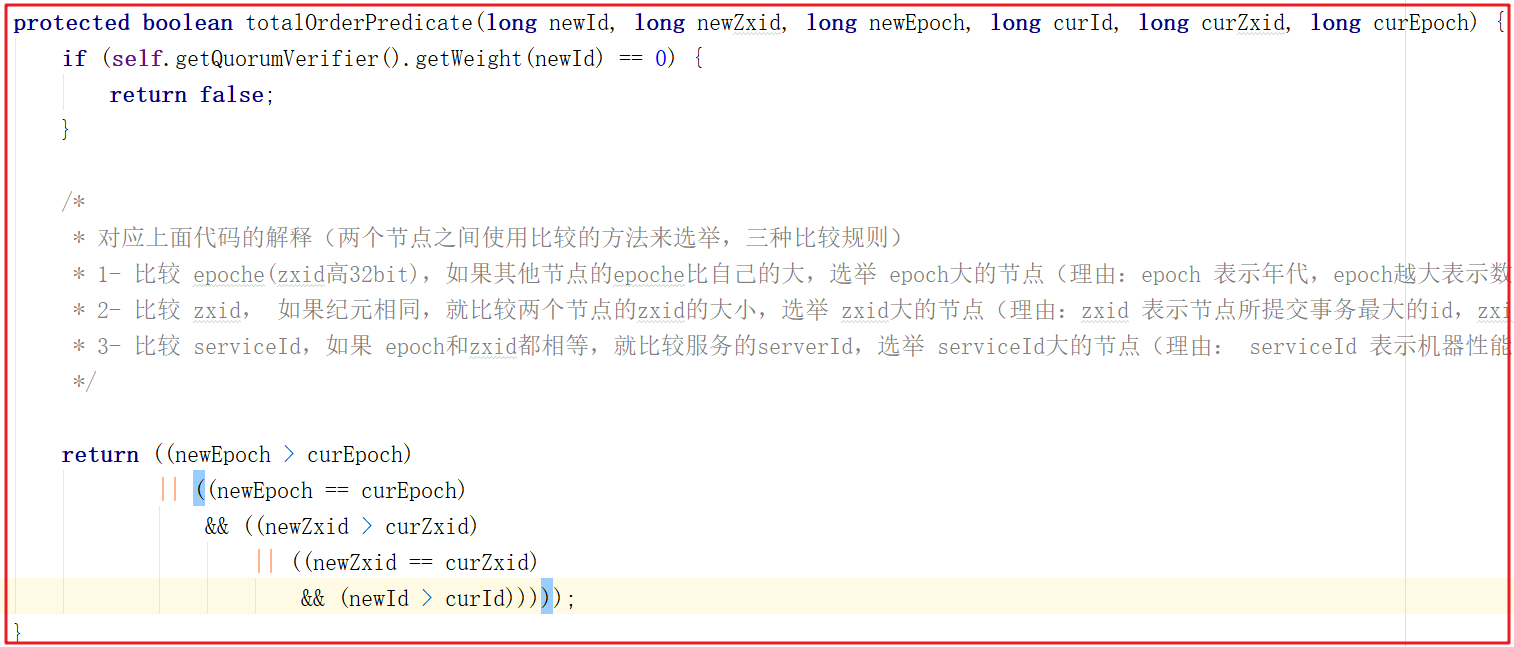
我們來看一下選票PK的方法totalOrderPredicate(),該方法其實就是Leader選舉規則,規則有如下三個:
1:比較 epoche(zxid高32bit),如果其他節點的epoche比自己的大,選舉 epoch大的節點(理由:epoch 表示年代,epoch越大表示數據越新)代碼:(newEpoch > curEpoch);
2:比較 zxid, 如果epoche相同,就比較兩個節點的zxid的大小,選舉 zxid大的節點(理由:zxid 表示節點所提交事務最大的id,zxid越大代表該節點的數據越完整)代碼:(newEpoch == curEpoch) && (newZxid > curZxid);
3:比較 serviceId,如果 epoch和zxid都相等,就比較服務的serverId,選舉 serviceId大的節點(理由: serviceId 表示機器性能,他是在配置zookeeper集群時確定的,所以我們配置zookeeper集群的時候可以把服務性能更高的集群的serverId設置大些,讓性能好的機器擔任leader角色)代碼 :(newEpoch == curEpoch) && ((newZxid == curZxid) && (newId > curId))。
源碼如下:
4 Zookeeper集群數據同步
所有事務操作都將由leader執行,並且會把數據同步到其他節點,比如follower、observer,我們可以分析leader和follower的操作行為即可分析出數據同步流程。
4.1 Zookeeper同步流程說明
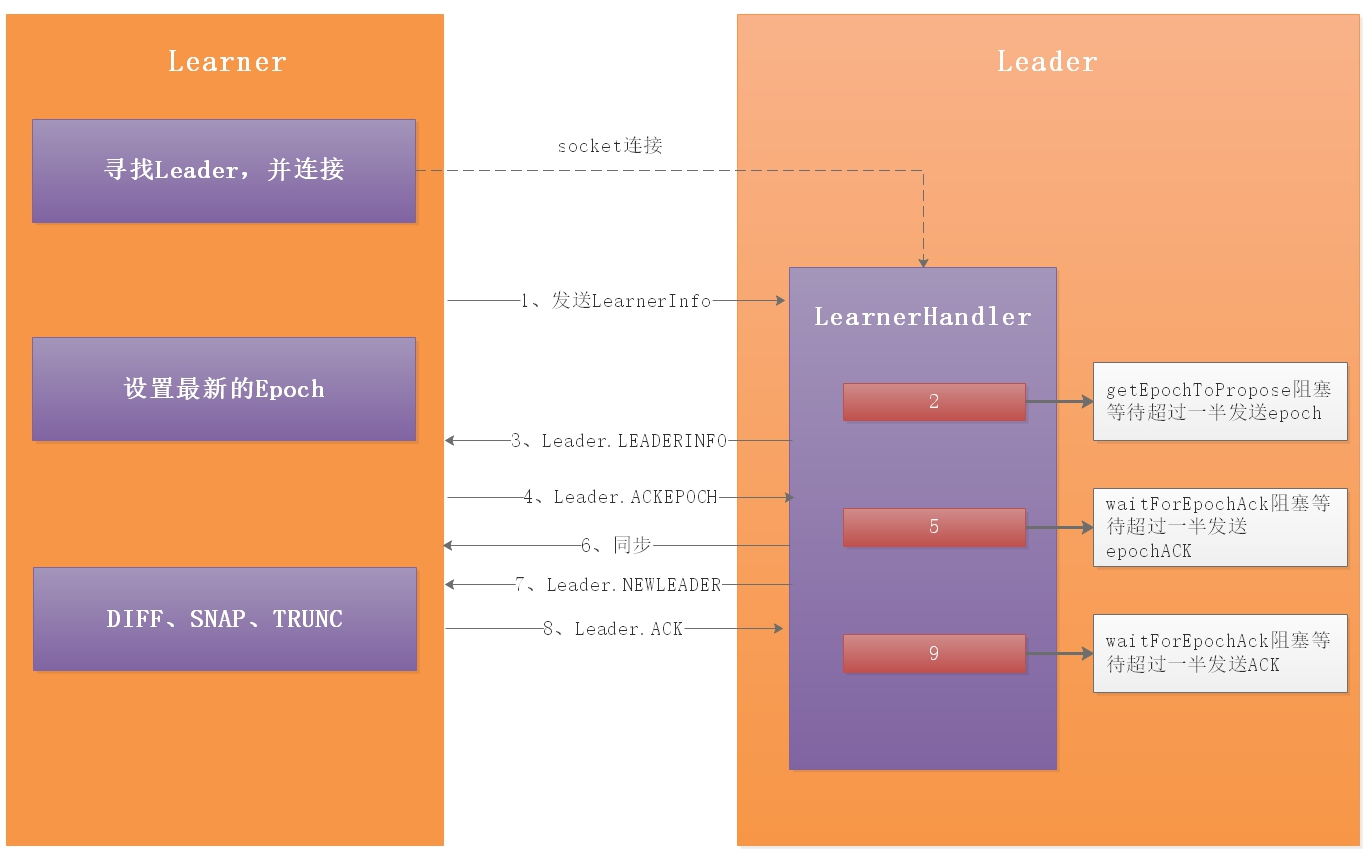
整體流程:
1:當角色確立之後,leader調用leader.lead();方法運行,創建一個接收連接的LearnerCnxAcceptor線程,在LearnerCnxAcceptor線程內部又建立一個阻塞的LearnerCnxAcceptorHandler線程等待Learner端的連接。Learner端以follower為例,follower調用follower.followLeader();方法首先查找leader的Socket服務端,然後建立連接。當follower建立連接後,leader端會建立一個LearnerHandler線程相對應,用來處理follower與leader的數據包傳輸。
2:follower端封裝當前zk伺服器的Zxid和Leader.FOLLOWERINFO的LearnerInfo數據包發送給leader
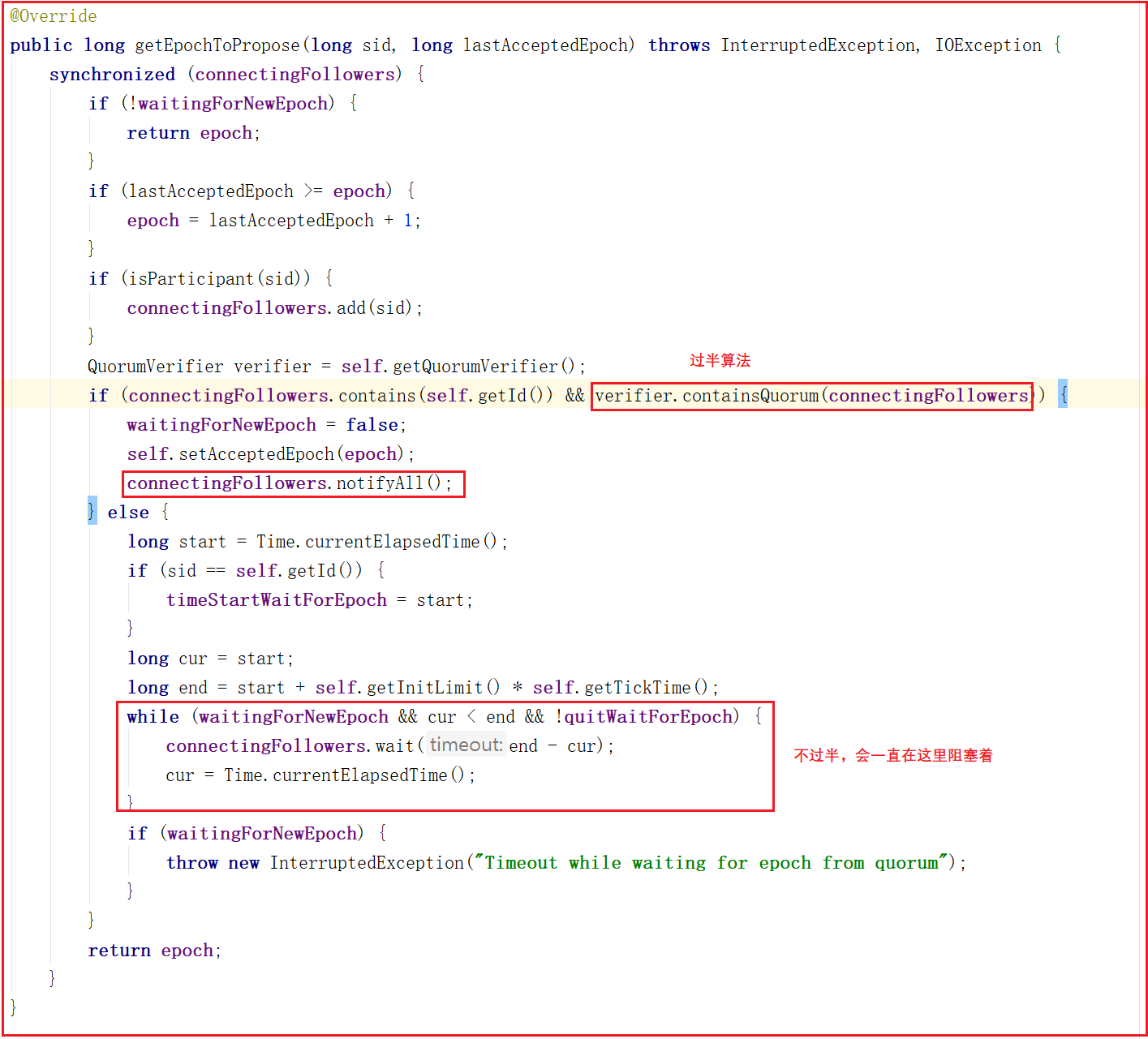
3:leader端這時處於getEpochToPropose方法的阻塞時期,需要得到Learner端超過一半的伺服器發送Epoch
4:getEpochToPropose解阻塞之後,LearnerHandler線程會把超過一半的Epoch與leader比較得到最新的newLeaderZxid,並封裝成Leader.LEADERINFO包發送給Learner端
5:Learner端得到最新的Epoch,會更新當前伺服器的Epoch。並把當前伺服器所處的lastLoggedZxid位置封裝成Leader.ACKEPOCH發送給leader
6:此時leader端處於waitForEpochAck方法的阻塞時期,需要得到Learner端超過一半的伺服器發送EpochACK
7:當waitForEpochAck阻塞之後便可以在LearnerHandler線程內決定用那種方式進行同步。如果Learner端的lastLoggedZxid>leader端的,Learner端將會被刪除多餘的部分。如果小於leader端的,將會以不同方式進行同步
8:leader端發送Leader.NEWLEADER數據包給Learner端(6、7步驟都是另開一個線程來發送這些數據包)
9:Learner端同步之後,會在一個while迴圈內處理各種leader端發送數據包,包括兩階段提交的Leader.PROPOSAL、Leader.COMMIT、Leader.INFORM等。在同步數據後會處理Leader.NEWLEADER數據包,然後發送Leader.ACK給leader端
10:此時leader端處於waitForNewLeaderAck阻塞等待超過一半節點發送ACK。
我們回到QuorumPeer.run()方法,根據確認的不同角色執行不同操作展開分析。
4.2 Zookeeper Follower同步流程
Follower主要連接Leader實現數據同步,我們看看Follower做的事,我們仍然沿著QuorumPeer.run()展開學習,關鍵代碼如下:
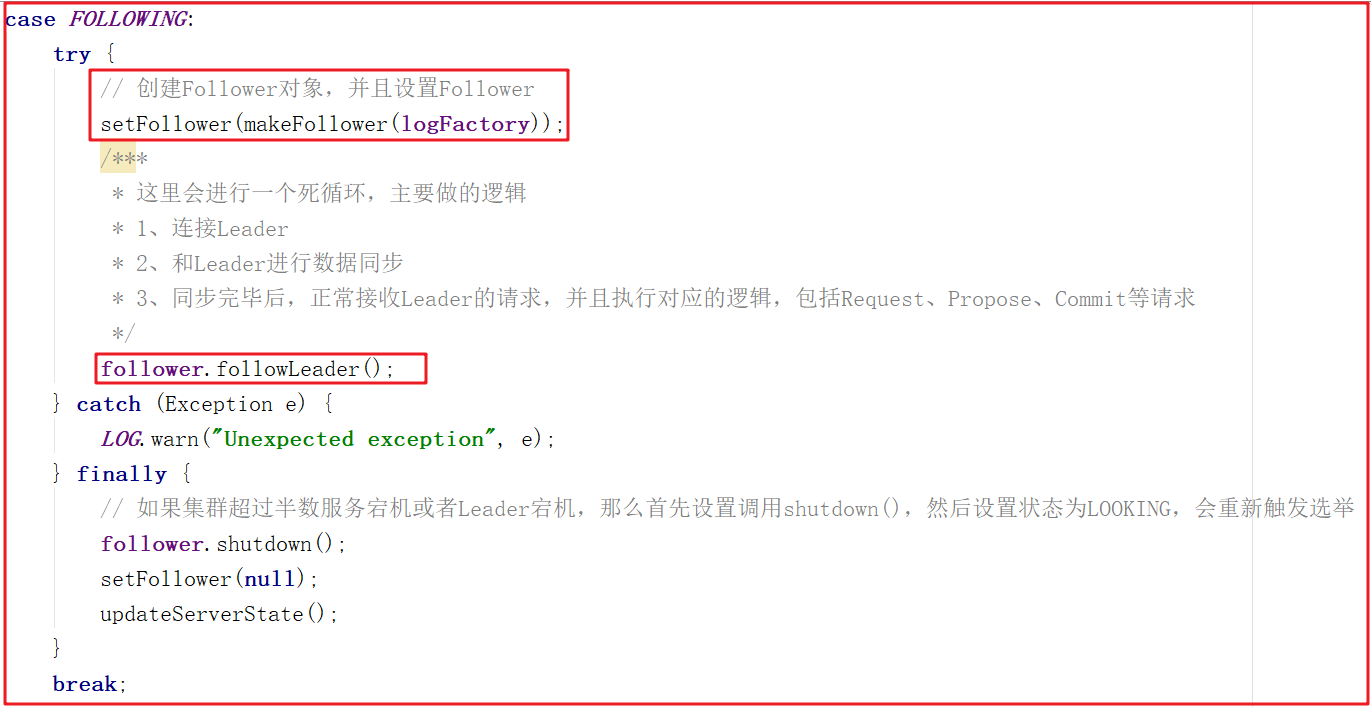
創建Follower的方法比較簡單,代碼如下:

我們看一下整個Follower在數據同步中做的所有操作follower.followLeader();,源碼如下圖:
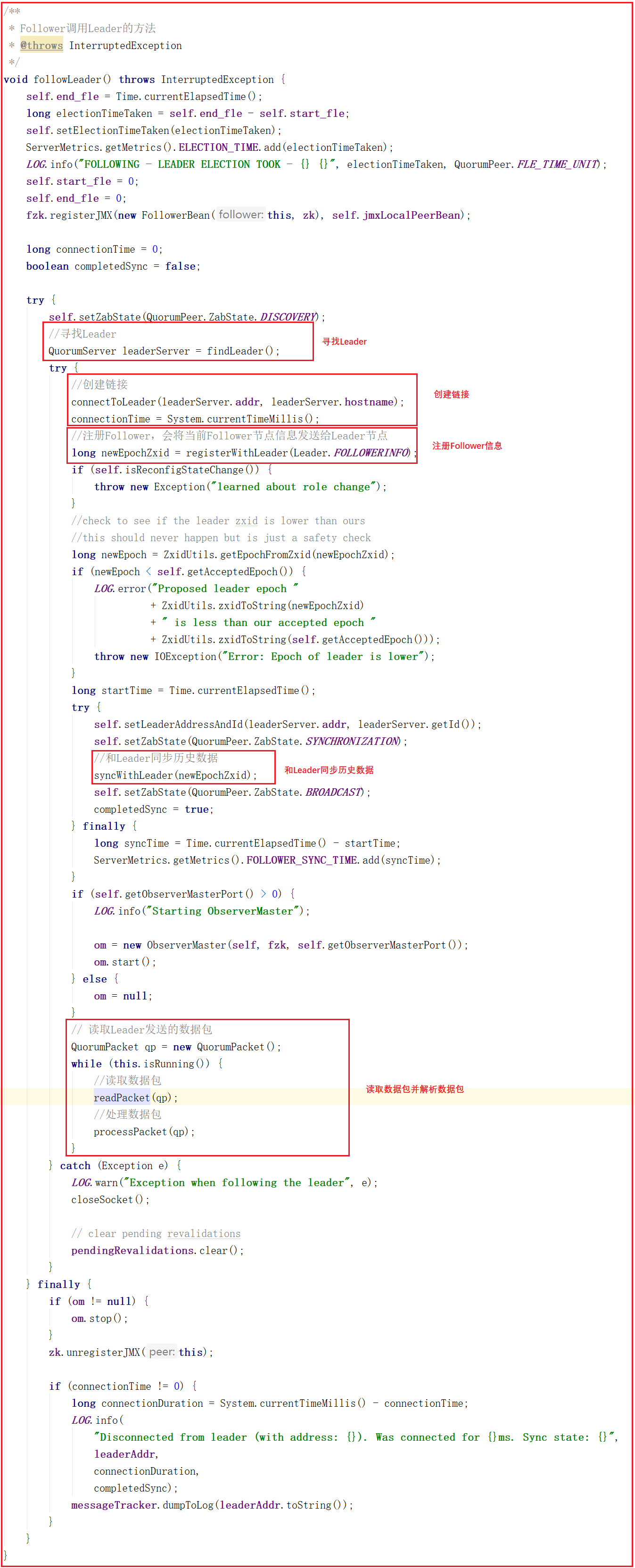
上面源碼中的follower.followLeader()方法主要做瞭如下幾件事:
1:尋找Leader
2:和Leader創建鏈接
3:向Leader註冊Follower,會將當前Follower節點信息發送給Leader節點
4:和Leader同步歷史數據
5:讀取Leader發送的數據包
6:同步Leader數據包
我們對follower.followLeader()調用的其他方法進行剖析,其中findLeader()是尋找當前Leader節點的,源代碼如下:
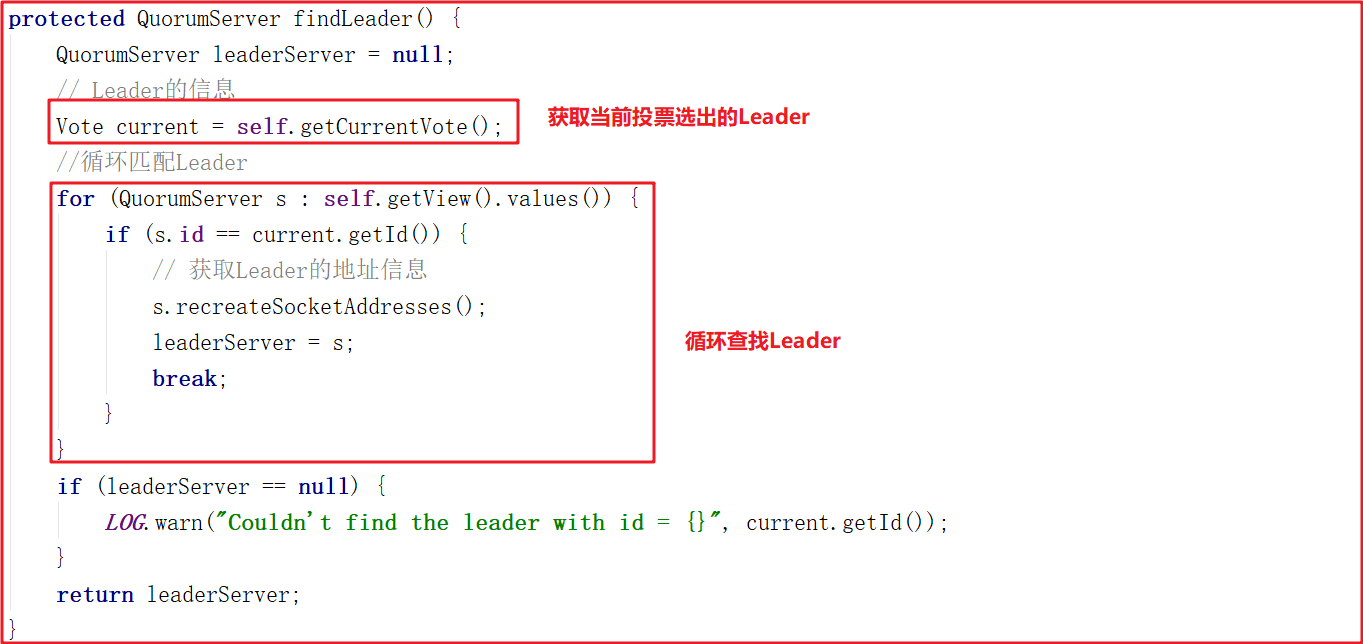
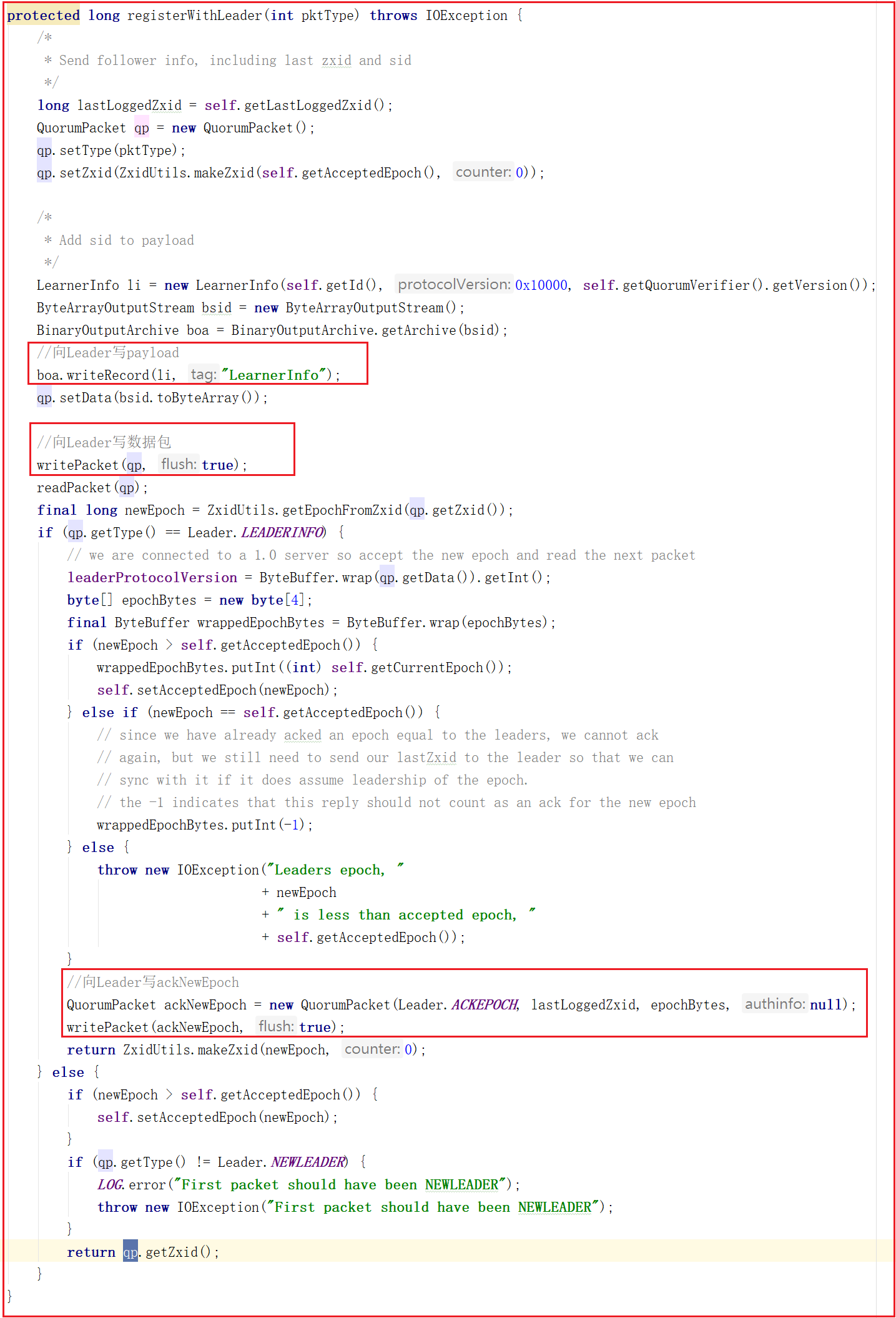
followLeader()中調用了registerWithLeader(Leader.FOLLOWERINFO);該方法是向Leader註冊Follower,會將當前Follower節點信息發送給Leader節點,Follower節點信息發給Leader是必須的,是Leader同步數據個基礎,源碼如下:
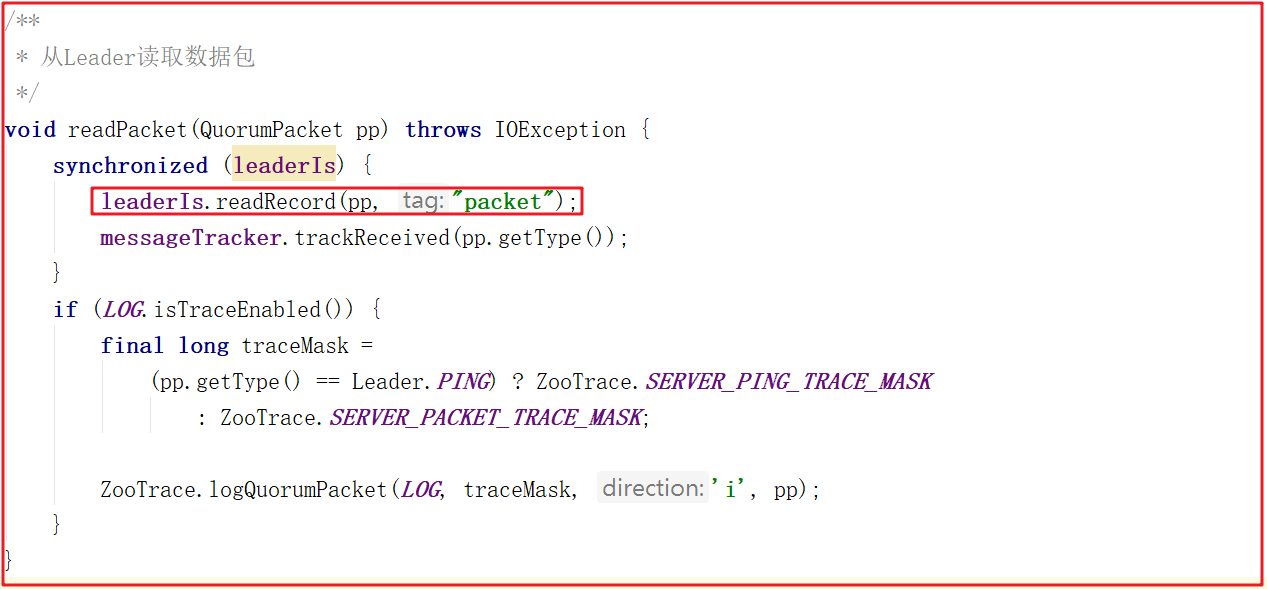
followLeader()中最後讀取數據包執行同步的方法中調用了readPacket(qp);,這個方法就是讀取Leader的數據包的封裝,源碼如下:
4.3 Zookeeper Leader同步流程
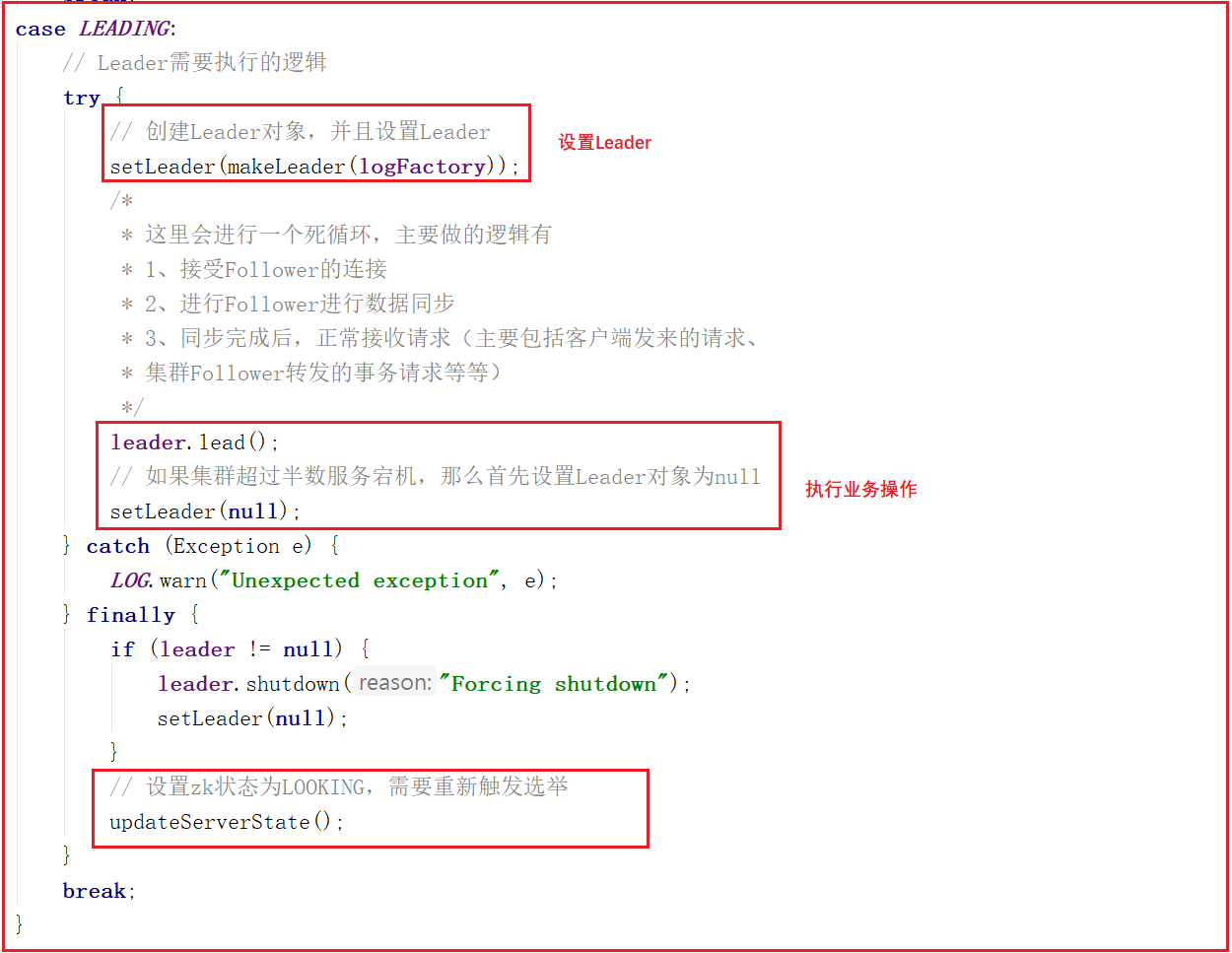
我們查看QuorumPeer.run()方法的LEADING部分,可以看到先創建了Leader對象,並設置了Leader,然後調用了leader.lead(),leader.lead()是執行的核心業務流程,源碼如下:
leader.lead()方法是Leader執行的核心業務流程,源碼如下:

leader.lead()方法會執行如下幾個操作:
1:從快照和事務日誌中載入數據
2:創建一個線程,接收Follower/Observer的連接
3:等待超過一半的(Follower和Observer)連接,再繼續往下執行程式
4:等待超過一半的(Follower和Observer)獲取了新的epoch,並且返回了Leader.ACKEPOCH,再繼續往下執行程式
5:等待超過一半的(Follower和Observer)進行數據同步成功,並且返回了Leader.ACK,再繼續往下執行程式
6:數據同步完成,開啟zkServer,並且同時開啟請求調用鏈接收請求執行
7:進行一個死迴圈,每次休眠self.tickTime / 2,和對所有的(Observer/Follower)發起心跳檢測
8:集群中沒有過半Follower在集群中,調用shutdown關閉一些對象,重新選舉
lead()方法中會創建LearnerCnxAcceptor,該對象是一個線程,主要用於接收followers的連接,這裡加了CountDownLatch根據配置的同步的地址的數量(例如:server.2=127.0.0.1:12881:13881 配置同步的埠是12881只有一個),LearnerCnxAcceptor的run方法源碼如下:
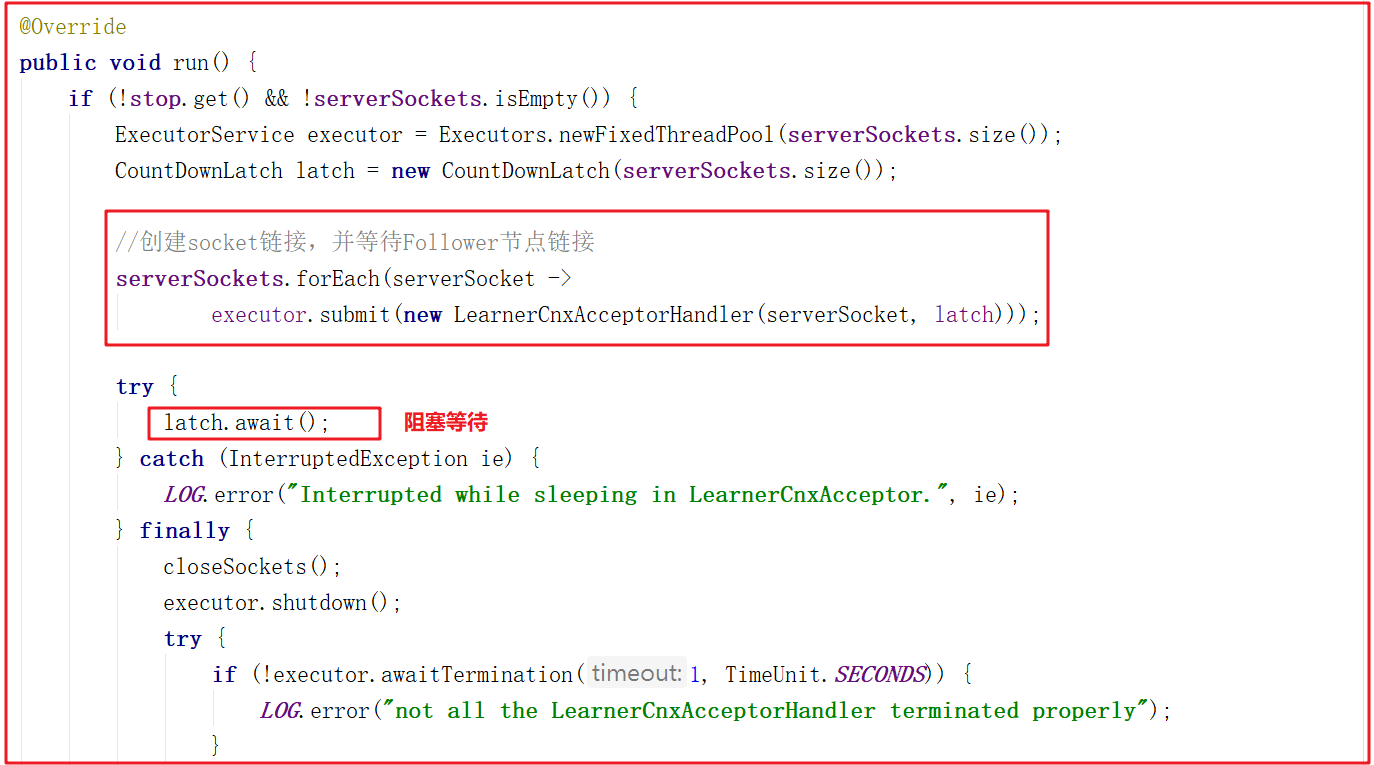
LearnerCnxAcceptor的run方法中創建了LearnerCnxAcceptorHandler對象,在接收到鏈接後,就會調用LearnerCnxAcceptorHandler,而LearnerCnxAcceptorHandler是一個線程,它的run方法中調用了acceptConnections()方法,源碼如下:

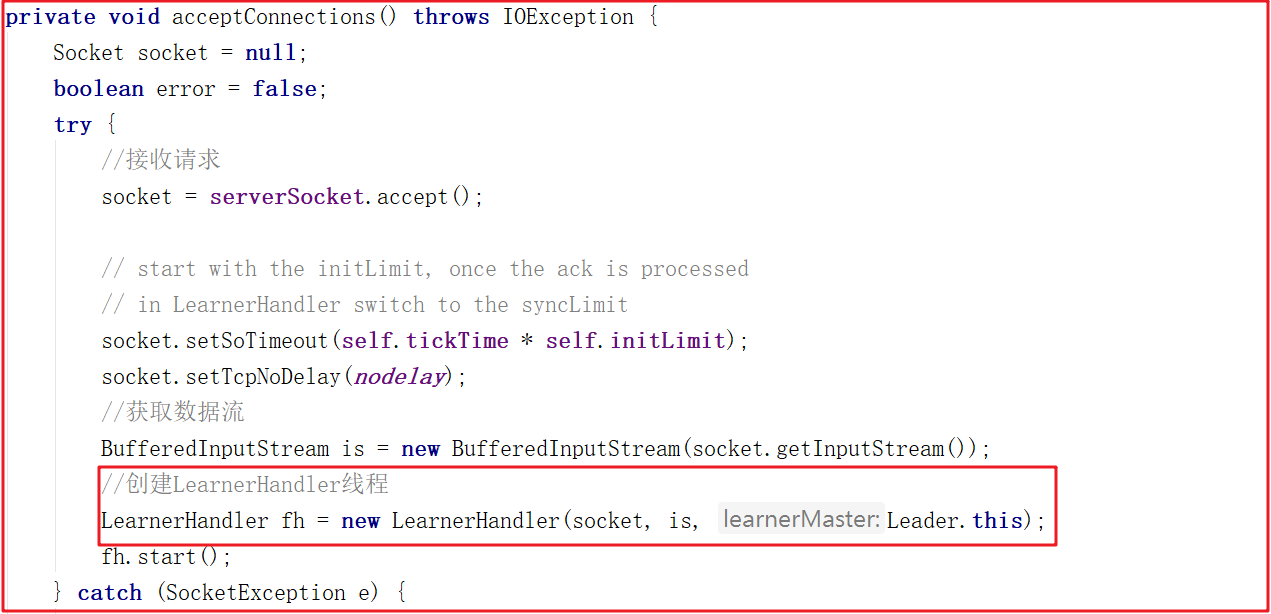
acceptConnections()方法會在這裡阻塞接收followers的連接,當有連接過來會生成一個socket對象。然後根據當前socket生成一個LearnerHandler線程 ,每個Learner者都會開啟一個LearnerHandler線程,方法源碼如下:
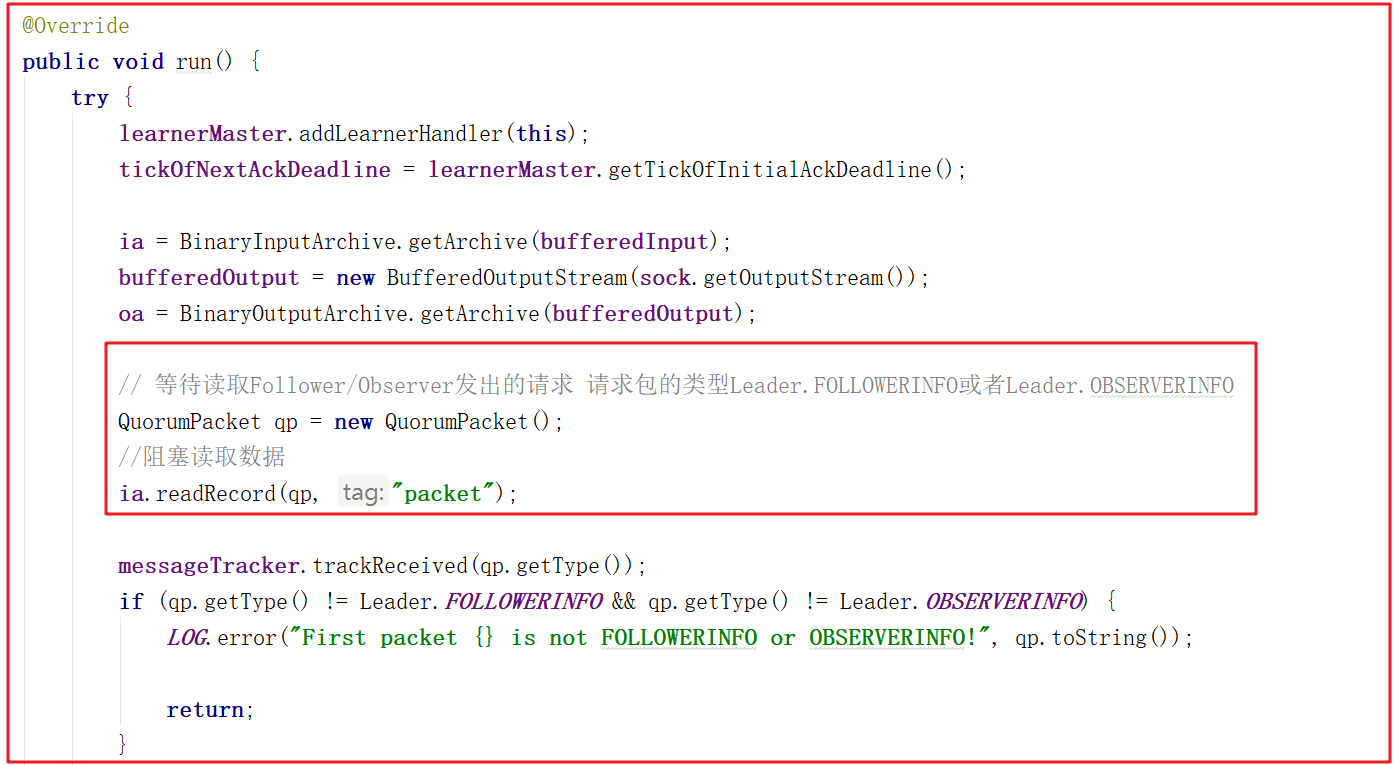
LearnerHandler.run 這裡就是讀取或寫數據包與Learner交換數據包。如果沒有數據包讀取,則會阻塞當前方法ia.readRecord(qp, "packet");,源碼如下:
我們再回到leader.lead()方法,其中調用了getEpochToPropose()方法,該方法是判斷connectingFollowers發給leader端的Epoch是否過半,如果過半則會解阻塞,不過半會一直阻塞著,直到Follower把自己的Epoch數據包發送過來並符合過半機制,源碼如下:
在lead()方法中,當發送的Epoch過半之後,把當前zxid設置到zk,並等待EpochAck,關鍵源碼如下:

waitForEpochAck()方法也會等待超過一半的(Follower和Observer)獲取了新的epoch,並且返回了Leader.ACKEPOCH,才會解除阻塞,否則會一直阻塞。等待EpochAck解阻塞後,把得到最新的epoch更新到當前服務,設置當前leader節點的zab狀態是SYNCHRONIZATION,方法源碼如下:
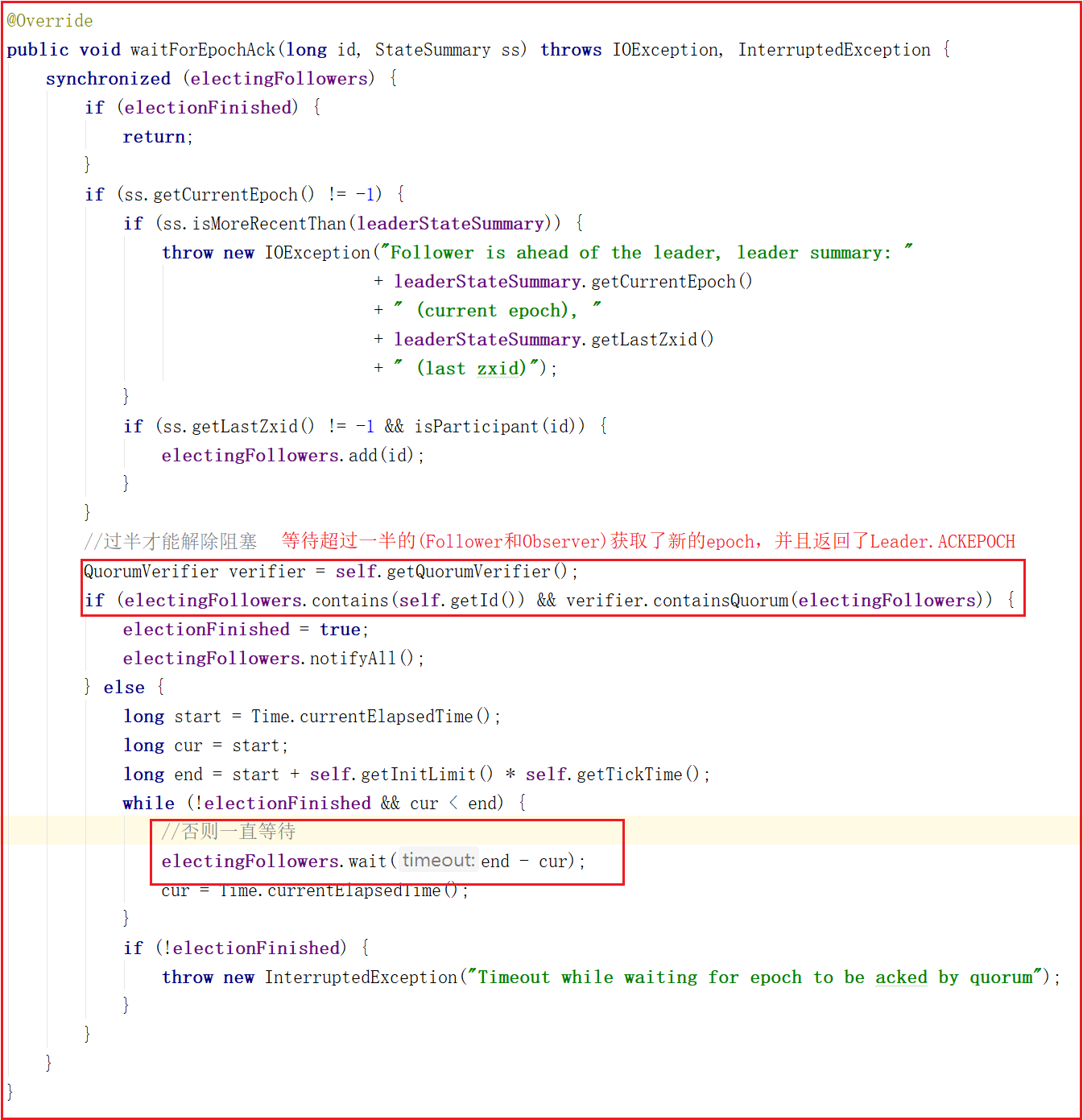
lead()方法中還需要等待超過一半的(Follower和Observer)進行數據同步成功,並且返回了Leader.ACK,程式才會解除阻塞,如下代碼:

上面所有流程都走完之後,就證明數據已經同步成功了,會執行startZkServer();
4.4 LearnerHandler數據同步操作
LearnerHandler線程是對應於Learner連接Leader端後,建立的一個與Learner端交換數據的線程。每一個Learner端都會創建一個 LearnerHandler線程。
我們詳細講解LearnerHandler.run()方法。

readRecord讀取數據包 不斷從learner節點讀數據,如果沒讀到將會阻塞readRecord。

如果數據包類型不是Leader.FOLLOWERINFO或Leader.OBSERVERINFO將會返回,因為咱們這裡本身就是Leader節點,讀數據肯定是讀非Leader節點數據。

獲取learnerInfoData來獲取sid和版本信息。
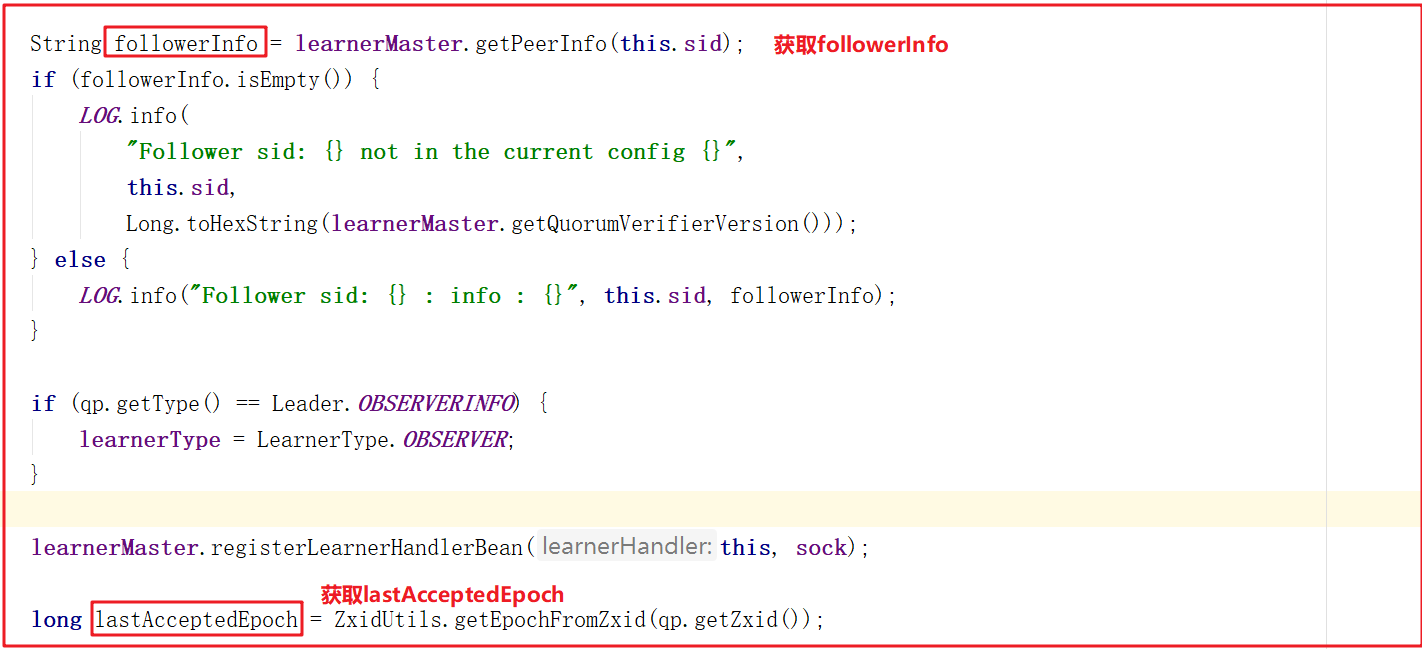
獲取followerInfo和lastAcceptedEpoch,信息如下:

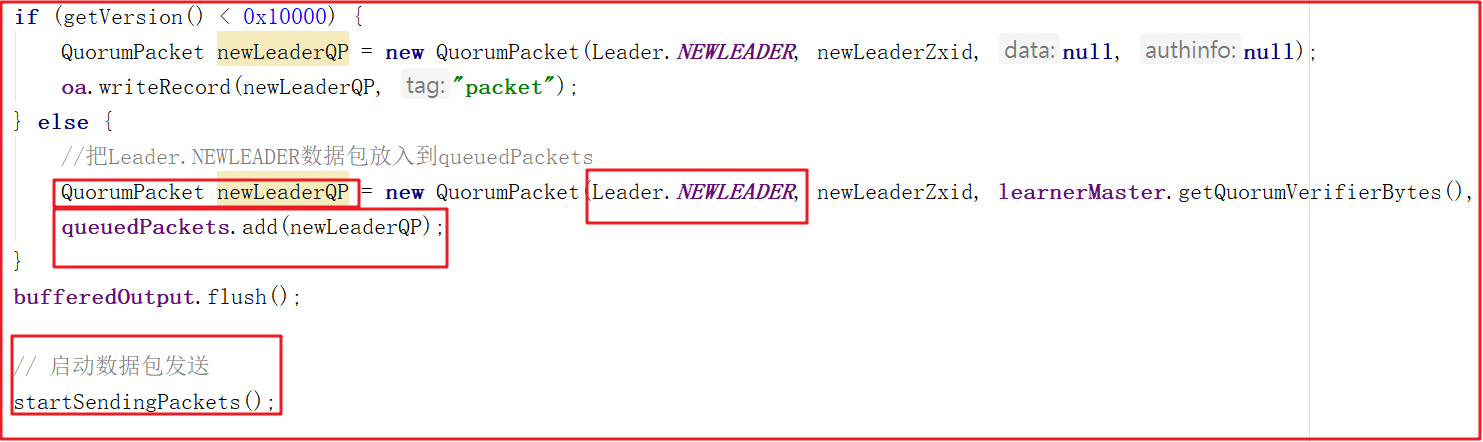
把Leader.NEWLEADER數據包放入到queuedPackets,並向其他節點發送,源碼如下:
本文由傳智教育博學谷 - 狂野架構師教研團隊發佈
如果本文對您有幫助,歡迎關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請註明出處!


