
基礎數據準備 基礎數據是通過爬蟲獲取到。 以下是從第一期03年雙色球開獎號到今天的所有數據整理,截止目前一共2549期,balls.txt 文件內容如下 Python 代碼實現 分析數據特征和數據處理方式選擇 python學習交流Q群:906715085### #導入Counter from col ...
基礎數據準備
基礎數據是通過爬蟲獲取到。
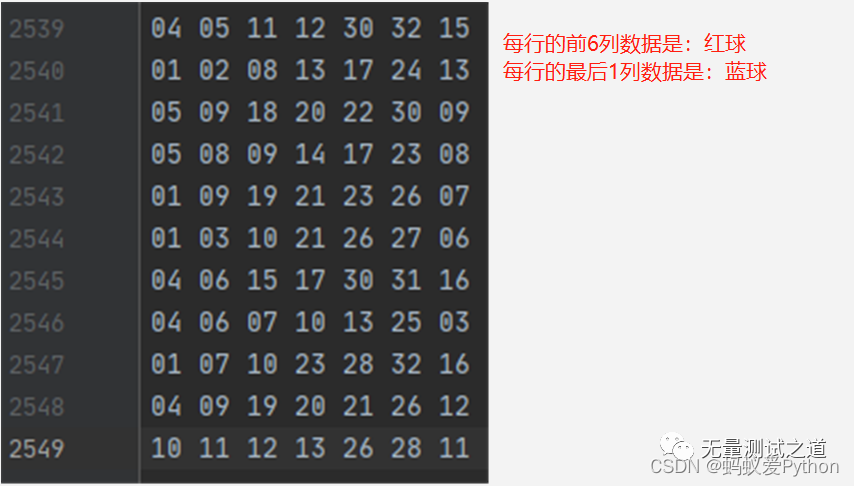
以下是從第一期03年雙色球開獎號到今天的所有數據整理,截止目前一共2549期,balls.txt 文件內容如下
Python 代碼實現
分析數據特征和數據處理方式選擇
python學習交流Q群:906715085### #導入Counter from collections import Counter def readfile(): red_lists=[] blue_lists=[] #打開文件並獲取文件句柄 with open("./balls.txt", "r",encoding='utf-8') as fp: #開始讀取文件並返回一個list list1=fp.readlines() #遍歷整個文件內容 for i in range(len(list1)): #替換掉\n的字元再按空格分隔 list2=str(list1[i]).replace("\n","").split(" ") for j in range(len(list2)): if j==6: #藍球放入到blue_lists 列表中 blue_lists.append(list2[j]) else: #紅球放入到red_lists 列表中 red_lists.append(list2[j]) #Counter可以快速便捷的對某些對象做一些統計操作,這裡是對列表裡面的數據進行出現次數統計,返回一個tuple red_count=Counter(red_lists) blue_count=Counter(blue_lists) #most_common可以用來統計列表或字元串中最常出現的元素並做排序,並返回一個list k = red_count.most_common(len(red_count)) #輸出出現頻率最高的六個紅球 print("the red ball:",k[:6]) l = blue_count.most_common(len(blue_count)) #輸出出現頻率最高的六個藍球 print("the blue ball:",l[:6]) if __name__=="__main__": readfile()
執行結果執行結果對比驗證
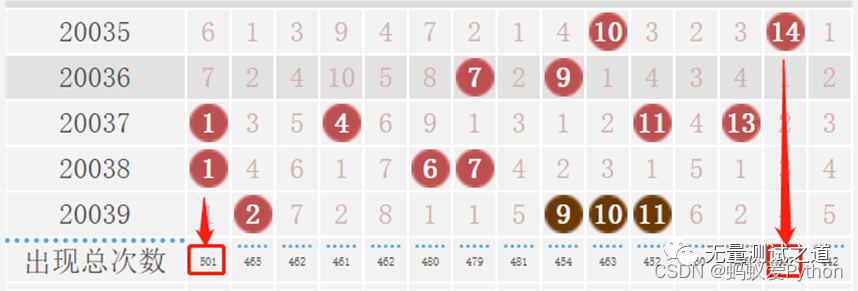
從官網獲取的數據進行對比,一致性校驗通過。
總結:
Python 在數據處理方面有著非常強大的優勢,Python 的 Panda 庫也可以非常出色的完成雙色球的數據統計,大家有興趣的可以實驗一下。
最後
如果今天的分享對你有幫助的話,請毫不猶豫:關註、分享、點贊、在看、收藏呀~
你的鼓勵將會是我創作的最大動力。


