
導讀: 首先簡單介紹一下網易杭州研究院情況簡介,如下圖所示: 我們公司主要從事平臺技術開發和建設方面,工作的重點方向主要在解決用戶在數據治理中的各種問題,讓用戶能更高效地管理自己的數據,進而產生更大的價值,比如如何整合現有功能流程,節省用戶使用成本;增加新平臺不斷調研,豐富平臺功能;新平臺功能、性能 ...

導讀: 首先簡單介紹一下網易杭州研究院情況簡介,如下圖所示:

我們公司主要從事平臺技術開發和建設方面,工作的重點方向主要在解決用戶在數據治理中的各種問題,讓用戶能更高效地管理自己的數據,進而產生更大的價值,比如如何整合現有功能流程,節省用戶使用成本;增加新平臺不斷調研,豐富平臺功能;新平臺功能、性能改造,從而滿足用戶大規模使用需求;根據業務實際需求,輸出相應的解決方案等。今天分享的內容主要是從資料庫內核到大數據平臺底層技術開發,分享網易數據科學中心多年的大數據建設經驗。
--
01 資料庫技術
數據技術主要有InnoSQL和NTSDB,NTSDB是最近研發的新產品,預計明年將向外推薦此產品,InnoSQL屬於MySQL分支方面的研究大概從2011年開始的,InnoSQL的主要目標是提供更好的性能以及高可用性,同時便於DBA的運維以及監控管理。

RocksDB是以樹的形式組織數據的產品,MySQL有一個MyRocks產品,我們內部將其集成到InnoSQL分支上。這樣做的原因是公司有很多業務,很多都是利用緩存保持其延遲,其規模會越來越大,這樣就導致緩存、記憶體成本很高;其業務對延遲要求不是特別高,但要保持延遲穩定(小於50毫秒)。
RocksDB能夠很好地將緩存控制的很好,隨著緩存越來越大,有的公司會將其放到HBase上,但是其延遲有時波動會很大,如小米HBase很強,但還是做了一個基於K-V模式的緩存處理,主要解決延遲波動問題。我們主要是基於開源產品來解決,如將RocksDB集成起來解決公司業務對延遲穩定的一些需求。
InnoRocks由於是基於LSM,因此對寫入支持非常好,後續有內部測試數據可以展示。還有就是LSM壓縮比很高,網易一種是替換緩存,一種是普通資料庫存儲,目前還是用InnoDB存儲,如果用InnoRocks存儲會節省很多存儲空間;還有一個就是結合DB做擴展,將其集成到公司內部。

上圖是寫入對比,是一個普通的寫入測試,其主介質是遞增型的,對於兩個都是一個順序讀寫過程;如果要完全對比還要測試RFID寫入測試,這樣能夠明顯反應RocksDB和InnoDB的差距。圖中RocksDB寫入性能比InnoDB要好,讀取性能InnoDB性能比RocksDB。300GB原始數據,分別導入到Inno DB(未壓縮)和Inno Rocks後的存儲容量對比,Inno DB為315GB左右,Inno Rocks為50 ~ 60GB,存儲容量是Inno DB的20%到30%。
InnoRock一般場景是替換InnoDB寫入,因為其寫入性能、壓縮性能更好、成本也更低。另一方面能夠解決InnoDB延遲不穩定,替換大量的緩存應用,只要其對相應時間沒有特殊要求。
- (1)大量數據寫入場景,比如日誌、訂單等;
- (2)需要高壓縮以便存儲更多的數據,Inno DB --> Inno Rocks;
- (3)對寫入延遲波動比較敏感,HBase --> Inno Rocks;
- (4)相對較低的延遲要求(10 ~ 50ms)下替換緩存場景(延遲<5ms),節省記憶體成本, Redis --> Inno Rocks。
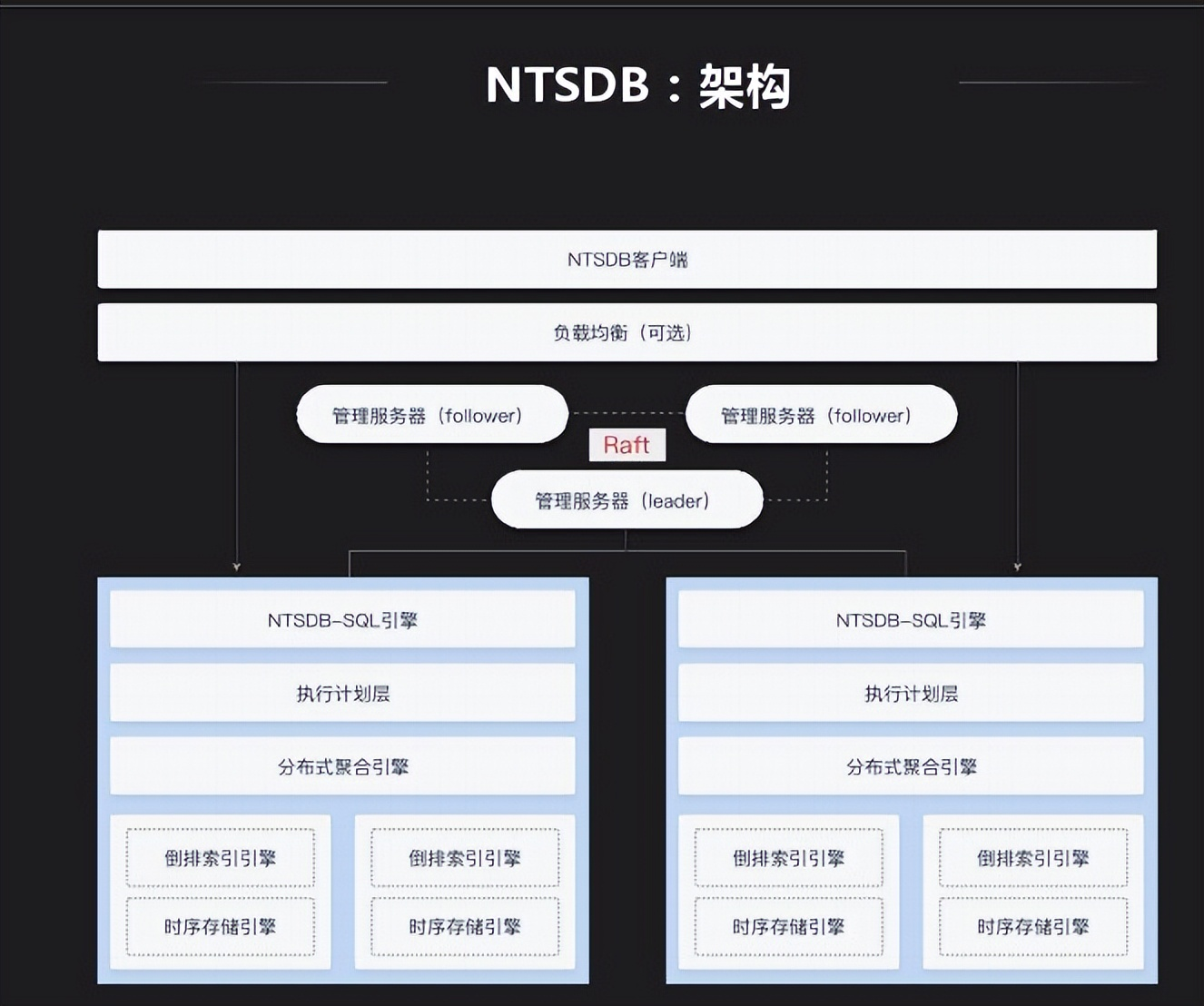
InnoSQL是MySQL一個分支,同時還做了一個時序資料庫。其不依賴第三方存儲,重新做了一套。其架構也是列式存儲,支持倒排索引等不同索引組織形式。對大型數據公司時序資料庫集中在訪問時通過什麼去訪問,我們提供SQL層給外部應用去訪問,應用簡單。
NTSDB特點有聚合運算相關演算法,時序資料庫相對於關係型資料庫沒有特別複雜的查詢,最常見的使用類型是寬表使用,在此基礎上做一些聚合演算法、插值查詢。

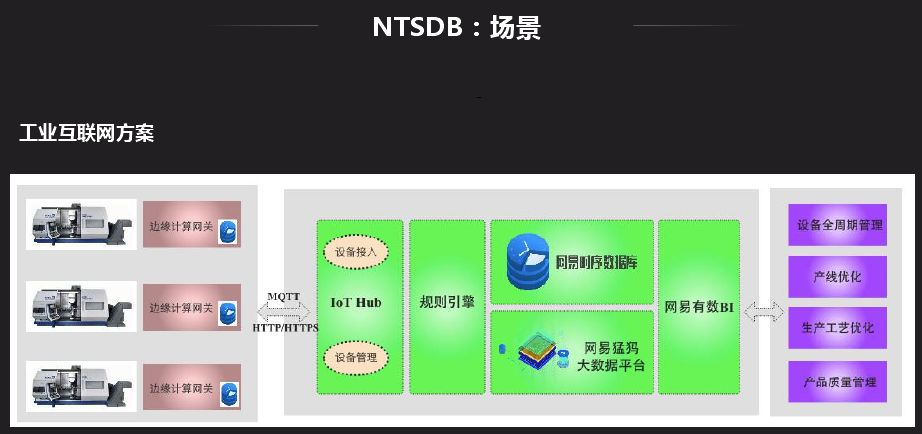
NTSDB應用場景很多,很多應用都可以基於時序資料庫來做,最常見的就是監控系統,有一些外部應用也會對接監控系統。外部應用中,現在RIT比較火,時序是其中比較重要的一環,很多設備目前都需要聯網,數據的產生都是以時間的形式產生,有的通過規則引擎處理存儲在時序資料庫中。
--
02 大數據技術
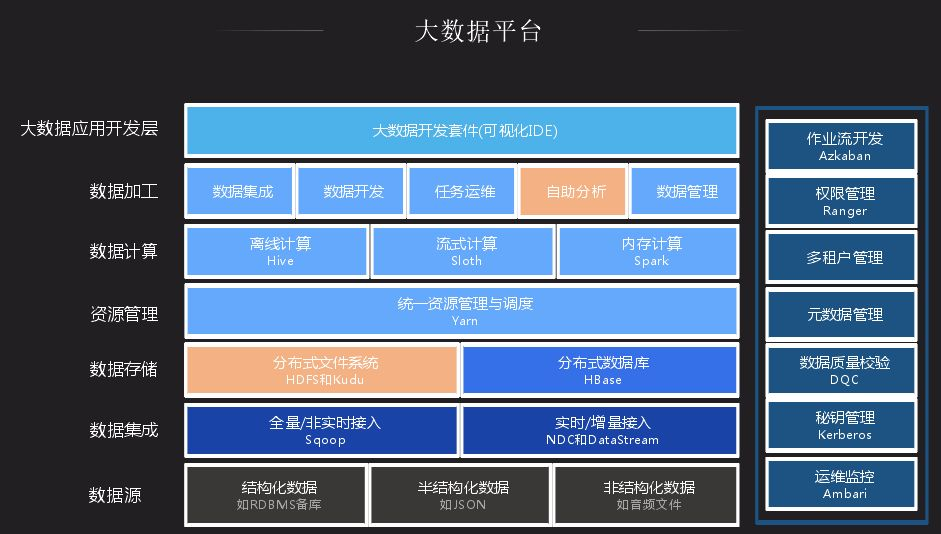
我們大數據平臺整合了一些開源社區的一些組件,內部進行一些產品化的改造和bug修複。最頂層是大數據接入層,作為大數據平臺,業務平臺很多數據來源於資料庫,也有很大一部分來源於日誌。通過NDC做全量數據導入,如有些數據在Oracle中,通過NDC導入,後續可以通過數據變更來進行同步,還有一個通過dataStream將日誌數據錄入大數據平臺。數據存儲層大都差不多,都用HDFS 存儲,搭載一些HBase分散式存儲;數據計算大都是離線計算平臺,記憶體計算是基於Spark;數據加工和一般大數據平臺都差不多,我們加入了自助分析、任務運維,後續會詳細介紹。接下來介紹自助分析裡面應用的一個插件Impala,以及分散式存儲系統中的Kudu平臺。
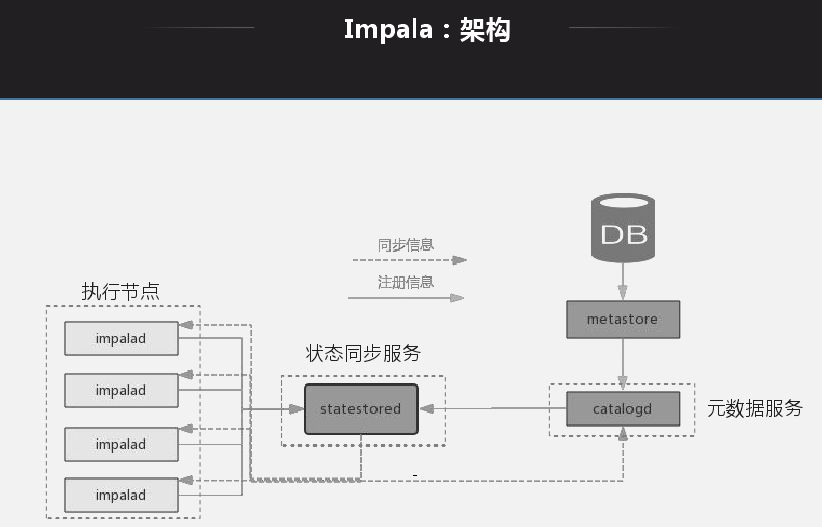
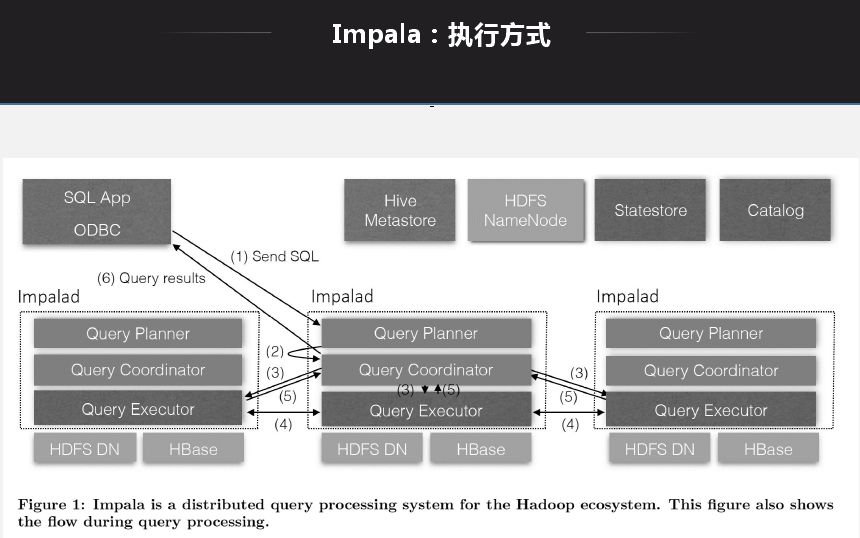
應用Impala目標是解決大數據量下的ad-hoc查詢問題,ad-hoc是介於OITP和OIAP中間的一層,OITP是響應層很快,毫秒級;OIAP查詢有時會耗時很久。ad-hoc定位與1分鐘到幾分鐘,現在很多業務需要ad-hoc提供,如公司報表,有時需要實時計算,響應在5秒-1分鐘延遲。
Impala架構特點就是每一個節點都是無狀態節點,節點查詢地位一樣,查詢無論發送到哪一個節點都可以生成查詢計劃、產生結果。查詢打到哪一個節點就能生成執行計劃,將對應的節點分配給對應的處理節點,將所有節點返回後做一個規則,然後做一個返回。基本所有的MPP架構都是類似。

選擇Impala而不選擇其他工具的原因:首先它有元數據緩存,好處是節點緩存元數據做查詢時不用再去獲取元數據,缺點就是元數據爆炸問題;再者就是Impala相容Hive,元數據可以和Hive共用;同時還支持很多運算元下推。Impala最好使用方式是通過Impala自己insert然後通過其自己去查,實際過程是通過Hive和Spark寫入大數據平臺,通過Impala來做查詢。這種方式有些限制就是寫入時Impala無法感知寫入,還有在Hive更改元數據,Impala能讀取數據但是無法動態感知,為瞭解決這個問題官方提供手動刷新操作。

Impala缺陷就是所有節點都是MPP結構,沒有統一的Master入口,負載均衡不易控制。底層數據許可權粒度控制不夠,HDFS轉HBase是以同級HBase身份訪問,Impala訪問底層需要以Impala身份訪問。這種問題尤其在同一平臺下分有很多業務時,用Hive寫數據時,訪問許可權就會有問題,因此我們在內部許可權訪問方面做了改造。每個coordinator節點都能接收SQL,沒有集中統一的SQL管理,如果掛掉所有歷史信息都無法追蹤。

我們基於Impala問題做了相應整改:
- (1)首先是基於Zookeeper的Load Balance機制;
- (2)管理服務解決SQL無法持續化問題,管理伺服器保存最近幾天的SQL和執行過程,便於後續SQL審計,超時SQL自動kill;
- (3)管理許可權將底層許可權分得很細;
- (4)元數據緩存問題,增加與Hive的元數據同步功能,Hive記錄元數據變更,Impala拉取變更自動同步,這種只能緩解元數據爆炸問題。
遺留的問題就是元數據容量,過濾智能解決部分問題;還有一個就是底層IO問題,因為離線寫入和Impala查詢是同一份數據,如果寫入吃掉很多IO,查詢就會出現問題。離線本身對IO敏感很低。除此之外我們還引入了ES技術,公司ES業務也有很多,碰到問題就是ES在SQL支持方面不是很好,目前我們的Impala支持一些ES的查詢。
Kudu用於解決離線數據實時性問題,HDFS存K-v數據,類似IOAP訪問,Hive是來做離線分析的,Kudu就是想同時做這兩件事情的背景下產生的。行為數據是在離線平臺上,用戶數據是實時在資料庫中,如快遞行業經常需要追蹤快遞的位置,離線平臺就要經常做自助分析,需要將資料庫中的狀態實時同步到離線平臺上去。目前做法就是資料庫批量寫入Hive表中,同時你的批量不能太小,容易產生很多小文件,這樣可能造成數據實時性很差,一般是半小時到一小時的延遲。大部分業務可接受,但是對於對延遲敏感的業務可能不支持,Kudu就是解決半小時到一小時的數據實時性。
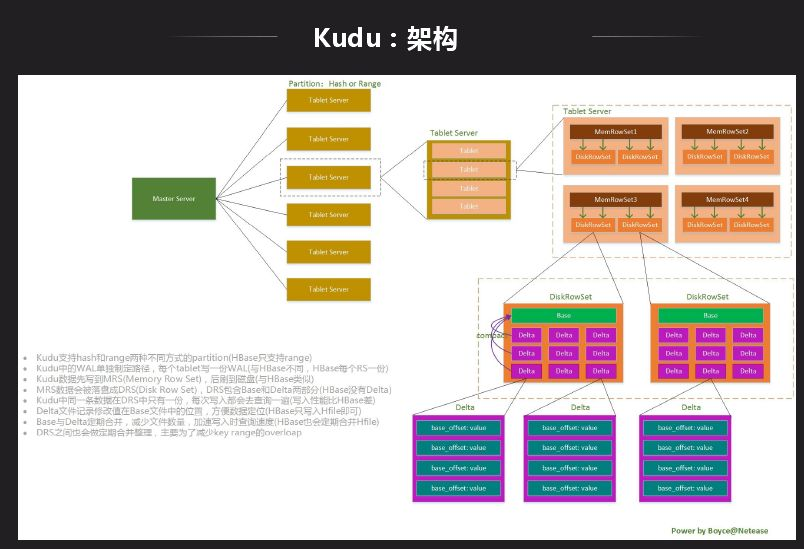
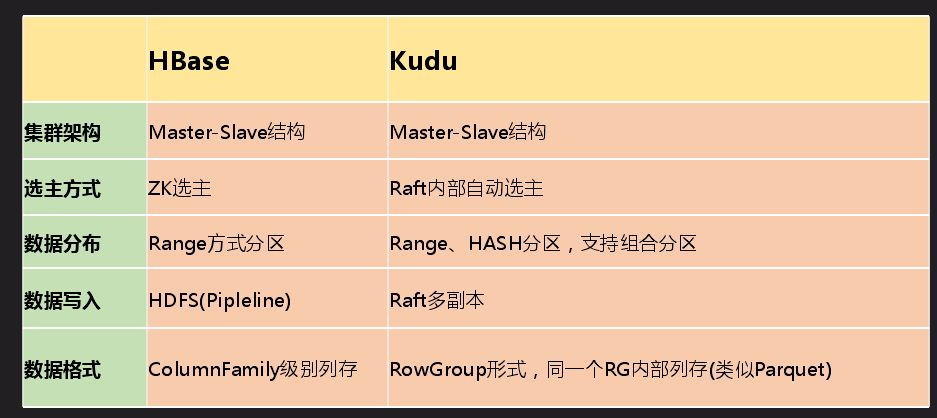
Kudu是一個存儲平臺,不依賴於任何第三方存儲系統,目前更類似於資料庫形式,Impala既能訪問Hive中的數據,也能訪問Kudu中的數據,這樣的好處是兩邊的數據可以進行聯合查詢。Kudu現在也支持Spark,也可以直接通過API訪問。上圖是Kudu的結構劃分到內部數據組織形式,Kudu支持Tablelet操作而HDFS不支持。前面的結構和HBase挺像,不同的是數據組織形式是不一樣的,Kudu可以做一些分析性的業務查詢。最主要的區別是數據存儲格式不一樣,Kudu是Column Family級別列存,先整個切一塊然後再做列組形式。
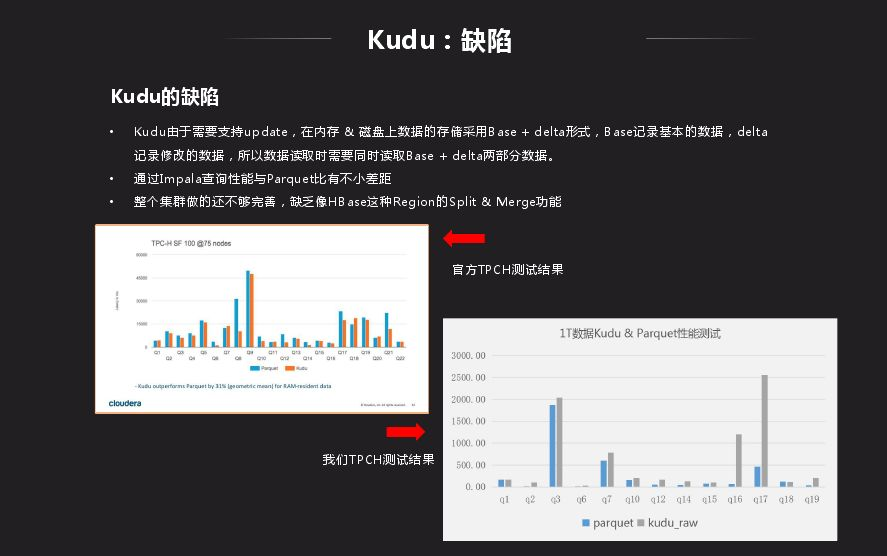
Kudu跟HDFS相比性能還是有差距,Kudu由於需要支持update,在記憶體 & 磁碟上數據的存儲採用Base + delta形式,Base記錄基本的數據,delta記錄修改的數據,所以數據讀取時需要同時讀取Base + delta兩部分數據。
Kudu優化主要是:
- (1)支持Kudu tablet的split;
- (2)支持指定列的TTL功能;
- (3)支持Kudu數據Runtime Filter功能;
- (4)支持Kudu創建Bitmap索引。
我們主要是按照HBase進行優化,在有需要情況下優化,HBase有而Kudu沒有就對照的做。
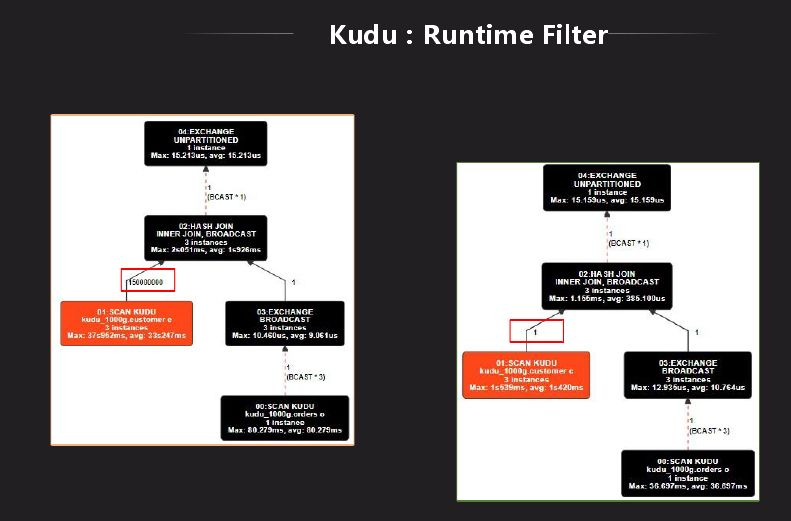
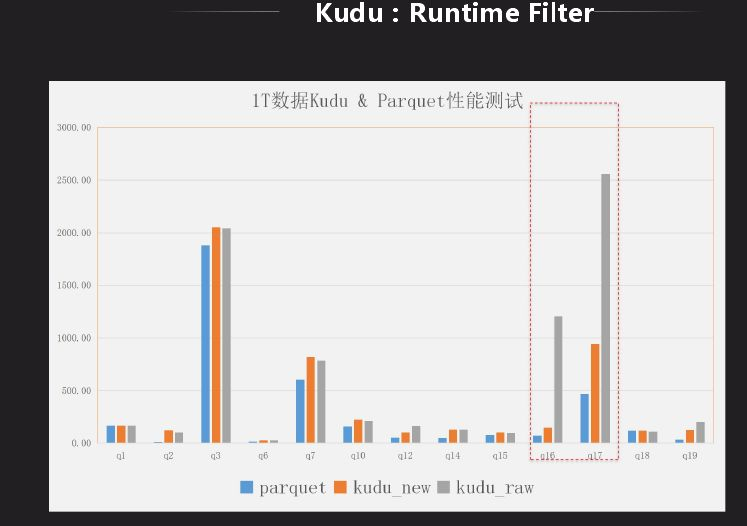
Impala裡面對HDFS有一個Runtime Filter功能,Kudu表上沒有,我們先分析下它到底有什麼作用,是不是有性能上的改進,將其移植過來。Runtime Filter主要是用在大表和小表做關聯時使用,在關聯時做成hash表,綁定到所有大表節點上去,在大表掃數據時利用hash表做過濾,因此在底層掃描就已經過濾掉很多數據,就可以省略很多不必要的計算。上圖是Kudu的是否有Runtime Filter的結果對比,可以看出減少了很多計算量,原先需要幾秒,現在只需秒級顯示結果。結果對比有了很大的改進,雖然還是有差距,目前也在改進,目標是和Impala相差不是很大。

還有一個場景就是在Kudu上做Bitmap索引,主要面向的業務是寬表的多維過濾,有些表的查詢會依據後面的實例去確定查詢,這種用Bitmap做比一個個找出來查詢性能要優越很多。另一個好處就是group by,因為其要將相同類型合併到一列,主要是做hash或者排序,這種查詢會很快,而不用做全局排序。Bitmap應用的限制就是數據離散性不能太好,dinstct count的值不能太多,向資料庫中主鍵不適合做Bitmap,像省份等值比較少的適合做Bitmap。
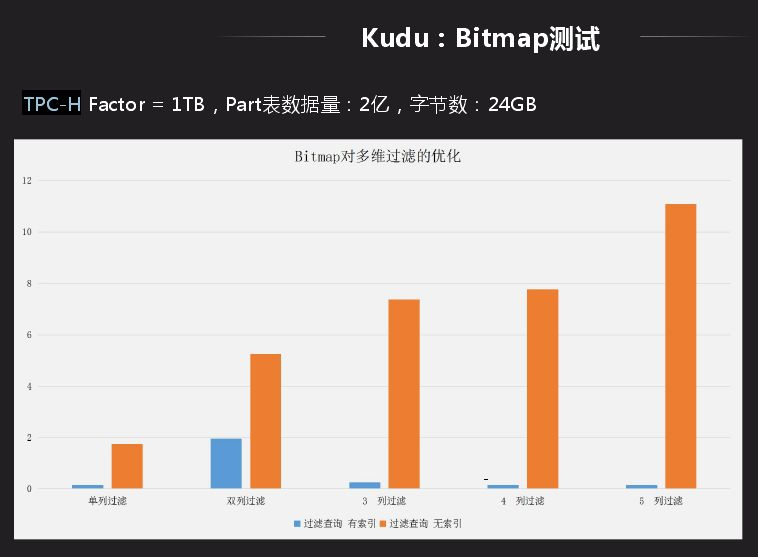
應用後用TPC-H中的一張表測試,Bitmap主要應用多維場景過濾,從一列過濾、兩列過濾、到五維過濾整個表現很好,性能提升有十幾倍提升。如果數據從資料庫導入大數據平臺離線分析其實時性比較慢,主要局限小文件以及導入批量大小問題,利用Kudu就不用考慮,可以直接通過Kudu實現數據變更導入大數據支持實時聯查。而且可以實時同步Oracle和MySQL數據到Kudu中,進行聯查就可以了,如果沒有就需要同步查詢可能需要半小時才能返回結果。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”。


