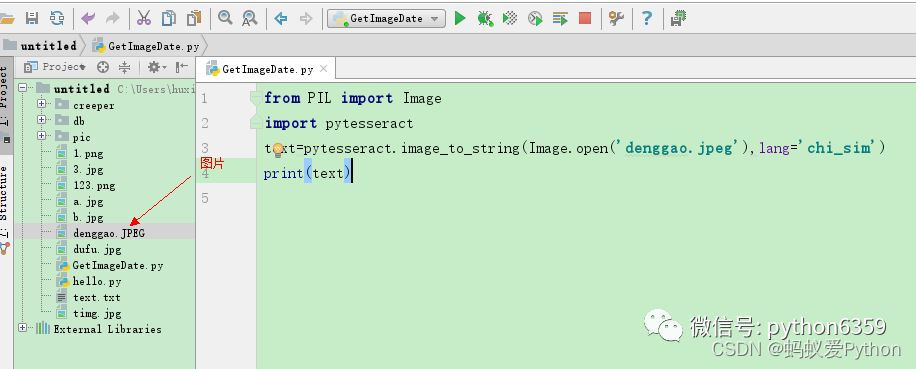
我們以識別詩詞為例下麵是我們要識別的圖片 先看下效果圖 我們運行代碼後識別的結果,有幾個字沒有正確識別,但是大多數字都能識別出來。 一行代碼就能識別圖片,我們背後要做些準備工作的 •這裡我們需要用到兩個庫:pytesseract和PIL •同時我們還需要安裝識別引擎tesseract-ocr 下麵就 ...
 我們以識別詩詞為例
我們以識別詩詞為例
下麵是我們要識別的圖片

先看下效果圖
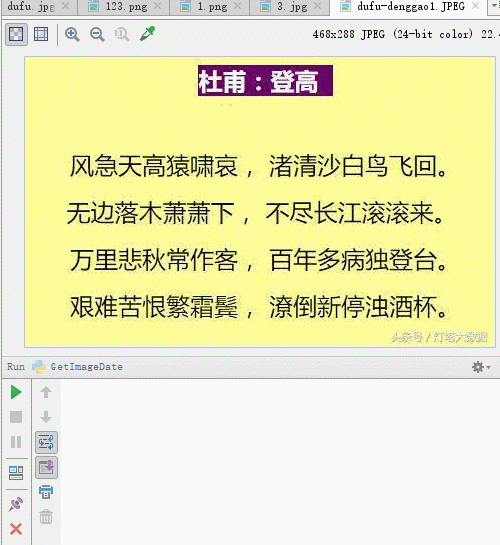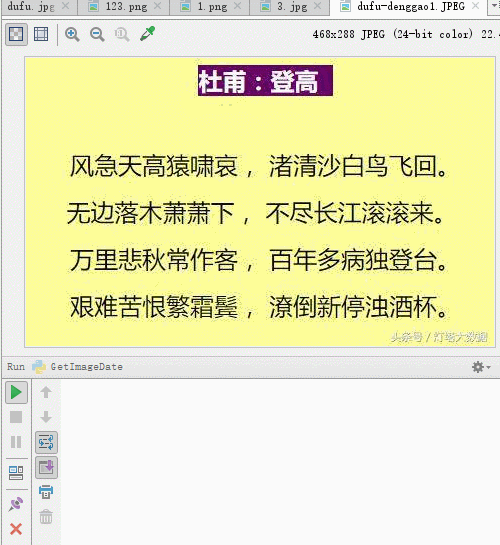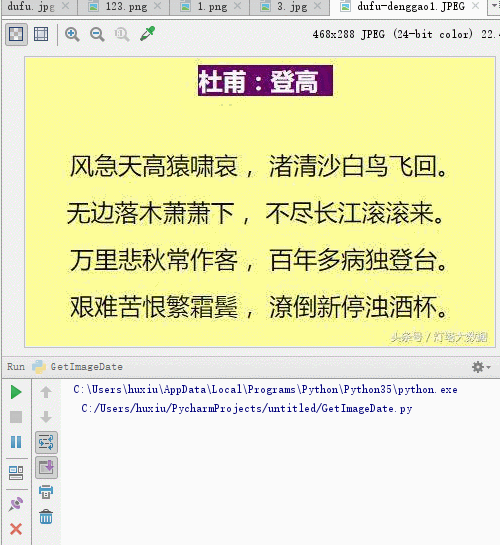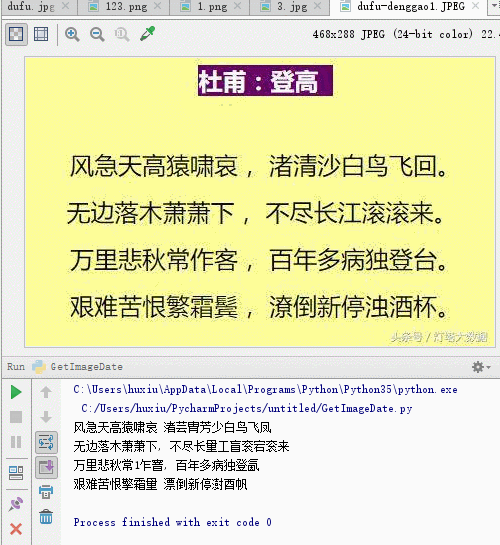
我們運行代碼後識別的結果,有幾個字沒有正確識別,但是大多數字都能識別出來。

一行代碼就能識別圖片,我們背後要做些準備工作的
•這裡我們需要用到兩個庫:pytesseract和PIL
•同時我們還需要安裝識別引擎tesseract-ocr
下麵就來講講這幾個庫的安裝,因為只有這幾個庫安裝好以後Python才能實現一行代碼實現圖片文字識別
一,pytesseract和PIL的安裝
Python學習交流Q群:906715085### 安裝這兩個包可以藉助pip - 1,命令行安裝 pip install PIL pip install pytesseract - 2,如果你用的pycharm編輯器,就可以直接藉助pycharm實現快速安裝。 在pycharm的Settings設置頁按照下麵步驟操作
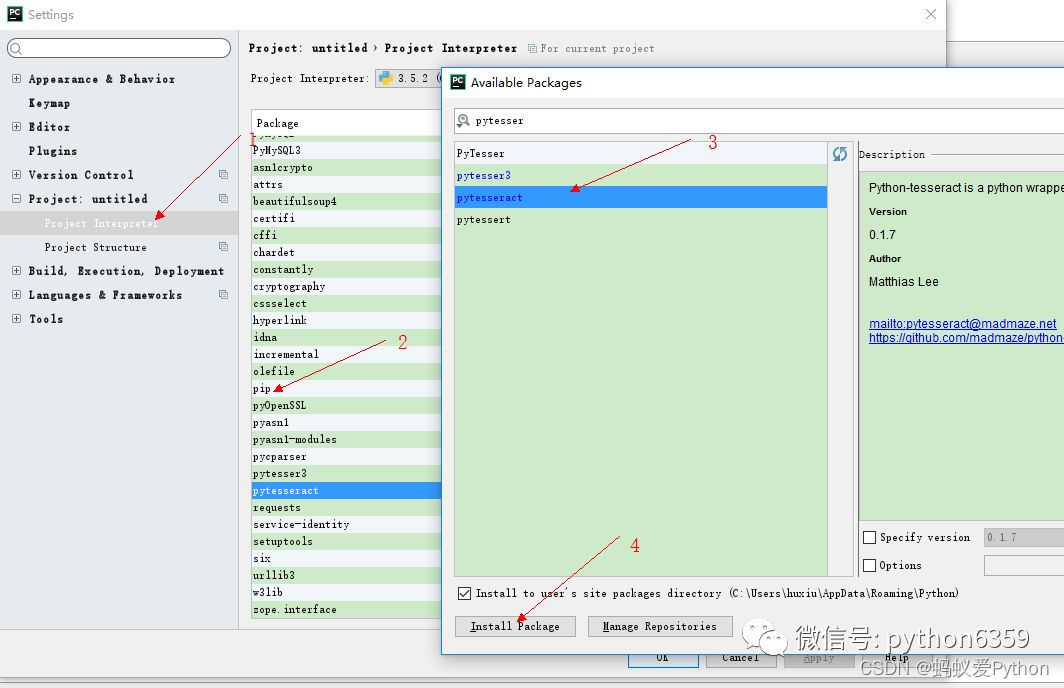
這樣就能成功安裝pytesseract,安裝PIL只需要在上面第三步里搜索PIL並點擊安裝即可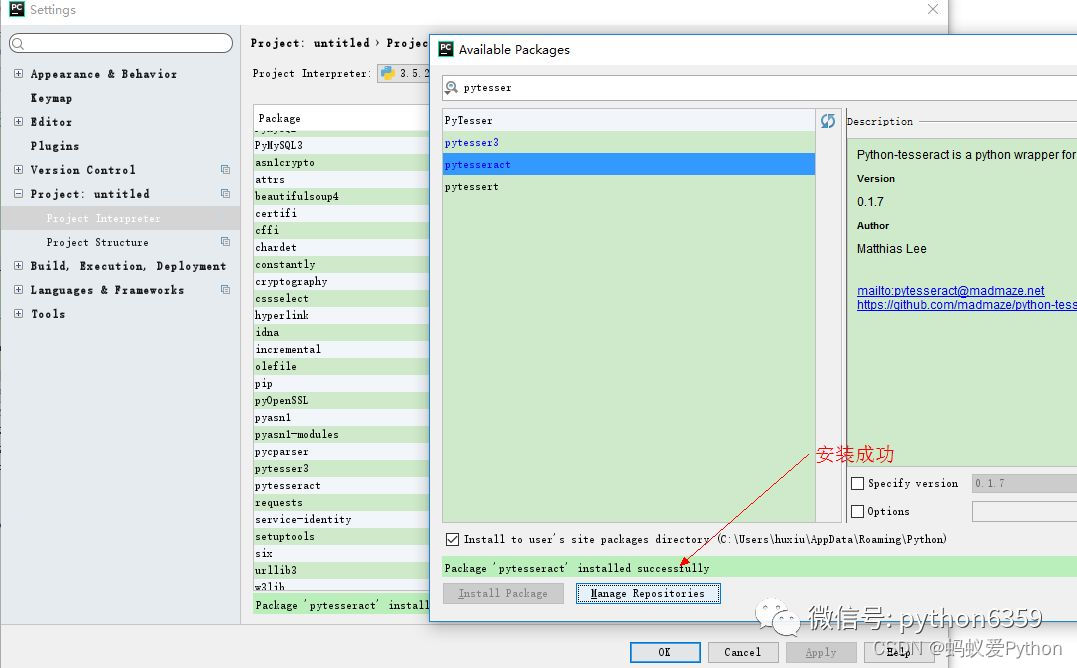
這時我們安轉好了庫,運行下麵代碼

會報下麵錯誤,錯誤原因是:沒有安裝識別引擎tesseract-ocr

二,安裝識別引擎tesseract-ocr
•1.下載下麵的安裝包,然後直接點擊安裝即可
http://download.csdn.net/download/qiushi_1990/9987023
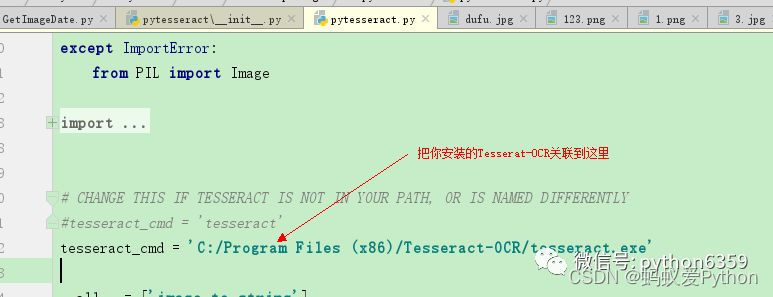
解壓安裝tesseract-ocr後做如下操作,就可以支持中文識別了。因為tesseract-ocr預設不支持中文識別。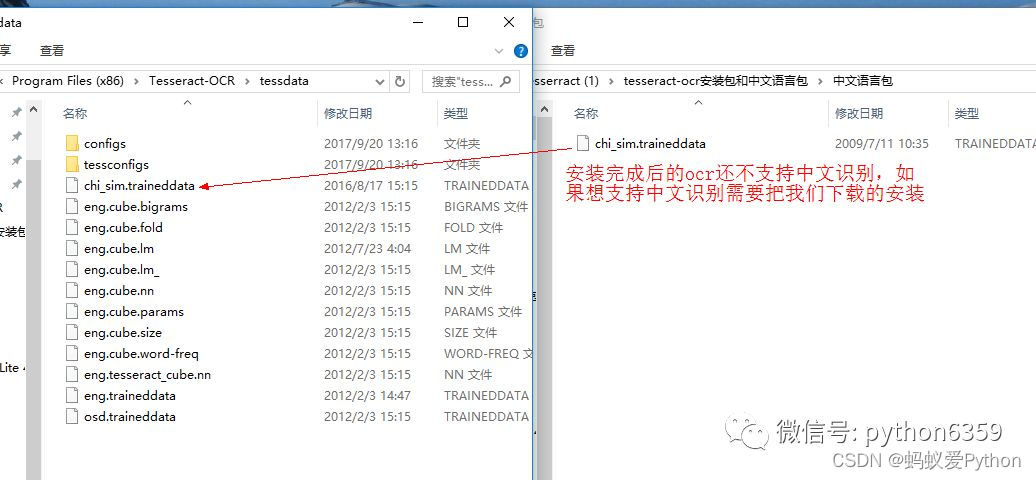
•2,安裝完成tesseract-ocr後,我們還需要做一下配置
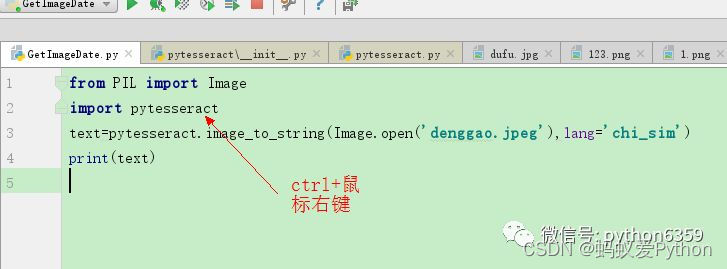
在C:\Users\huxiu\AppData\Local\Programs\Python\Python35\Lib\site-packages\pytesseract找到pytesseract.py打開後做如下操作

也可以通過pycharm快速打開pytesseract.py

至此我們所有的配置就完成了,運行下麵代碼就可以把杜甫的登高這首圖片詩解析成文字了