
前幾篇我們一起學習了 SQL 如何對錶進行創建、更新和刪除操作、SQL SELECT WHERE 語句如何指定一個或多個查詢條件 和 SQL 如何插入、刪除和更新數據 等資料庫的基本操作方法。 從本文開始,我們將會在這些基本方法的基礎上,學習一些實際應用中的方法。 本文將以此前學過的 SELECT ...
目錄
前幾篇我們一起學習了 SQL 如何對錶進行創建、更新和刪除操作、SQL SELECT WHERE 語句如何指定一個或多個查詢條件 和 SQL 如何插入、刪除和更新數據 等資料庫的基本操作方法。
從本文開始,我們將會在這些基本方法的基礎上,學習一些實際應用中的方法。
本文將以此前學過的 SELECT 語句,以及嵌套在 SELECT 語句中的視圖和子查詢等技術為中心進行學習。由於視圖和子查詢可以像表一樣進行使用,因此如果能恰當地使用這些技術,就可以寫出更加靈活的 SQL 了。
一、視圖
本節重點
從 SQL 的角度來看,視圖和表是相同的,兩者的區別在於表中保存的是實際的數據,而視圖中保存的是
SELECT語句(視圖本身並不存儲數據)。使用視圖,可以輕鬆完成跨多表查詢數據等複雜操作。
可以將常用的
SELECT語句做成視圖來使用。創建視圖需要使用
CREATE VIEW語句。視圖包含“不能使用
ORDER BY”和“可對其進行有限制的更新”兩項限制。刪除視圖需要使用
DROP VIEW語句。
1.1 視圖和表
我們首先要學習的是一個新的工具——視圖。
視圖究竟是什麼呢?如果用一句話概述的話,就是“從 SQL 的角度來看視圖就是一張表”。
實際上,在 SQL 語句中並不需要區分哪些是表,哪些是視圖,只需要知道在更新時它們之間存在一些不同就可以了,這一點之後會為大家進行介紹。
至少在編寫 SELECT 語句時並不需要特別在意表和視圖有什麼不同。
那麼視圖和表到底有什麼不同呢?區別隻有一個,那就是“是否保存了實際的數據”。
通常,我們在創建表時,會通過 INSERT 語句將數據保存到資料庫之中,而資料庫中的數據實際上會被保存到電腦的存儲設備(通常是硬碟)中。
因此,我們通過 SELECT 語句查詢數據時,實際上就是從存儲設備(硬碟)中讀取數據,進行各種計算之後,再將結果返回給用戶這樣一個過程。
但是使用視圖時並不會將數據保存到存儲設備之中,而且也不會將數據保存到其他任何地方。
實際上視圖保存的是 SELECT 語句(圖 1)。我們從視圖中讀取數據時,視圖會在內部執行該 SELECT 語句並創建出一張臨時表。
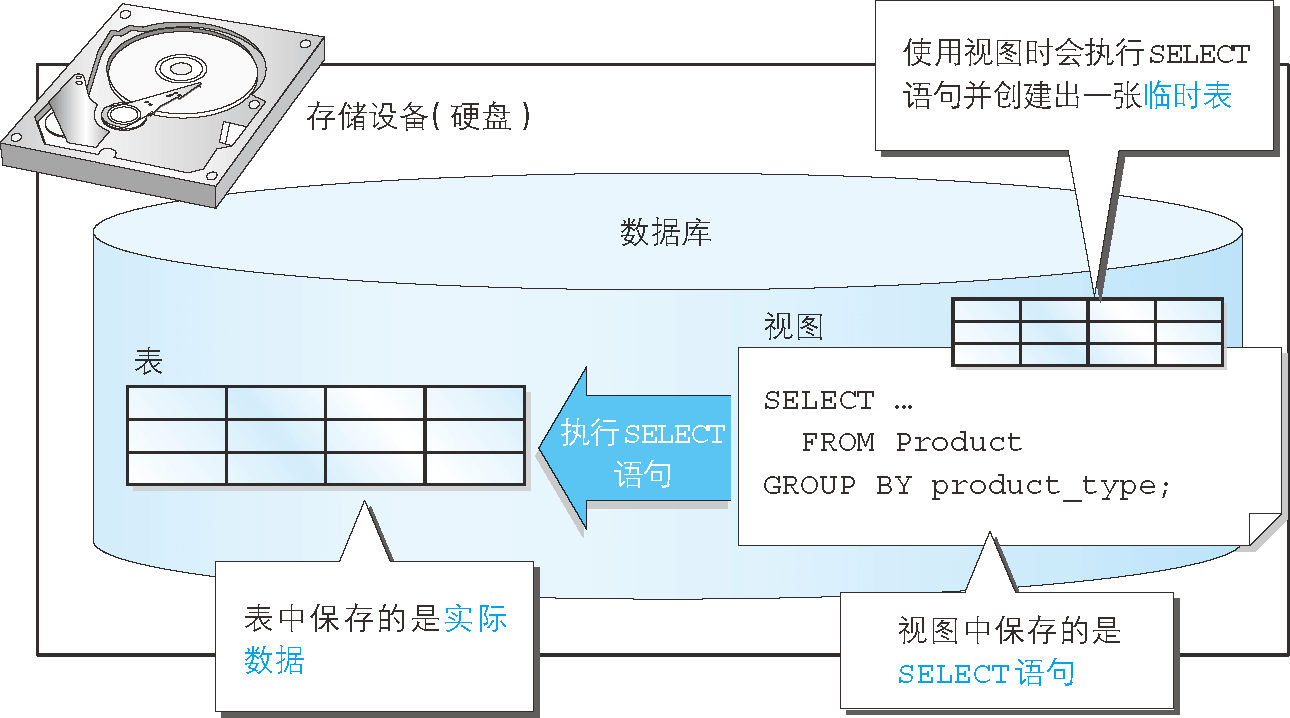
圖 1 視圖和表
-
視圖的優點
視圖的優點大體有兩點。
第一點是由於視圖無需保存數據,因此可以節省存儲設備的容量。
例如,我們在 SQL 如何插入、刪除和更新數據 中創建了用來彙總商品種類(
product_type)的表。由於該表中的數據最終都會保存到存儲設備之中,因此會占用存儲設備的數據空間。
但是,如果把同樣的數據作為視圖保存起來的話,就只需要代碼清單 1 那樣的
SELECT語句就可以了,這樣就節省了存儲設備的數據空間。代碼清單 1 通過視圖等 SELECT 語句保存數據
SELECT product_type, SUM(sale_price), SUM(purchase_price) FROM Product GROUP BY product_type;由於本示例中表的數據量充其量只有幾行,所以使用視圖並不會大幅縮小數據的大小。但是在實際的業務中數據量往往非常大,這時使用視圖所節省的容量就會非常可觀了。
法則 1
表中存儲的是實際數據,而視圖中保存的是從表中取出數據所使用的
SELECT語句。第二個優點就是可以將頻繁使用的
SELECT語句保存成視圖,這樣就不用每次都重新書寫了。創建好視圖之後,只需在
SELECT語句中進行調用,就可以方便地得到想要的結果了。特別是在進行彙總以及複雜的查詢條件導致SELECT語句非常龐大時,使用視圖可以大大提高效率。而且,視圖中的數據會隨著原表的變化自動更新。視圖歸根到底就是
SELECT語句,所謂“參照視圖”也就是“執行SELECT語句”的意思,因此可以保證數據的最新狀態。這也是將數據保存在表中所不具備的優勢 [1]。
法則 2
應該將經常使用的
SELECT語句做成視圖。
1.2 創建視圖的方法
創建視圖需要使用 CREATE VIEW 語句,其語法如下所示。
語法 1 創建視圖的 CREATE VIEW 語句
CREATE VIEW 視圖名稱(<視圖列名1>, <視圖列名2>, ……)
AS
<SELECT語句>
SELECT 語句需要書寫在 AS 關鍵字之後。
SELECT 語句中列的排列順序和視圖中列的排列順序相同,SELECT 語句中的第 1 列就是視圖中的第 1 列,SELECT 語句中的第 2 列就是視圖中的第 2 列,以此類推。
視圖的列名在視圖名稱之後的列表中定義。
備忘
接下來,我們將會以此前使用的
Product(商品)表為基礎來創建視圖。如果大家已經根據之前章節的內容更新了
Product表中的數據,請在創建視圖之前將數據恢復到初始狀態。操作步驟如下所示。① 刪除
Product表中的數據,將表清空DELETE FROM Product;② 執行代碼清單 6(向 Product 表中插入數據)中的 SQL 語句,將數據插入到空表
Product中
下麵就讓我們試著來創建視圖吧。和此前一樣,這次我們還是將 Product 表(代碼清單 2)作為基本表。
代碼清單 2 ProductSum 視圖

這樣我們就在資料庫中創建出了一幅名為 ProductSum(商品合計)的視圖。
請大家一定不要省略第 2 行的關鍵字 AS。這裡的 AS 與定義別名時使用的 AS 並不相同,如果省略就會發生錯誤。雖然很容易混淆,但是語法就是這麼規定的,所以還是請大家牢記。
接下來,我們來學習視圖的使用方法。視圖和表一樣,可以書寫在 SELECT 語句的 FROM 子句之中(代碼清單 3)。
代碼清單 3 使用視圖

執行結果:
product_type | cnt_product
--------------+------------
衣服 | 2
辦公用品 | 2
廚房用具 | 4
通過上述視圖 ProductSum 定義的主體(SELECT 語句)我們可以看出,該視圖將根據商品種類(product_type)彙總的商品數量(cnt_product)作為結果保存了起來。
這樣如果大家在工作中需要頻繁進行彙總時,就不用每次都使用 GROUP BY 和 COUNT 函數寫 SELECT 語句來從 Product 表中取得數據了。
創建出視圖之後,就可以通過非常簡單的 SELECT 語句,隨時得到想要的彙總結果。並且如前所述,Product 表中的數據更新之後,視圖也會自動更新,非常靈活方便。
之所以能夠實現上述功能,是因為視圖就是保存好的 SELECT 語句。
定義視圖時可以使用任何 SELECT 語句,既可以使用 WHERE、GROUP BY、HAVING,也可以通過 SELECT * 來指定全部列。
-
使用視圖的查詢
在
FROM子句中使用視圖的查詢,通常有如下兩個步驟:① 首先執行定義視圖的
SELECT語句② 根據得到的結果,再執行在
FROM子句中使用視圖的SELECT語句也就是說,使用視圖的查詢通常需要執行 2 條以上的
SELECT語句 [2]。這裡沒有使用“2 條”而使用了“2 條以上”,是因為還可能出現以視圖為基礎創建視圖的多重視圖(圖 2)。
例如,我們可以像代碼清單 4 那樣以
ProductSum為基礎創建出視圖ProductSumJim。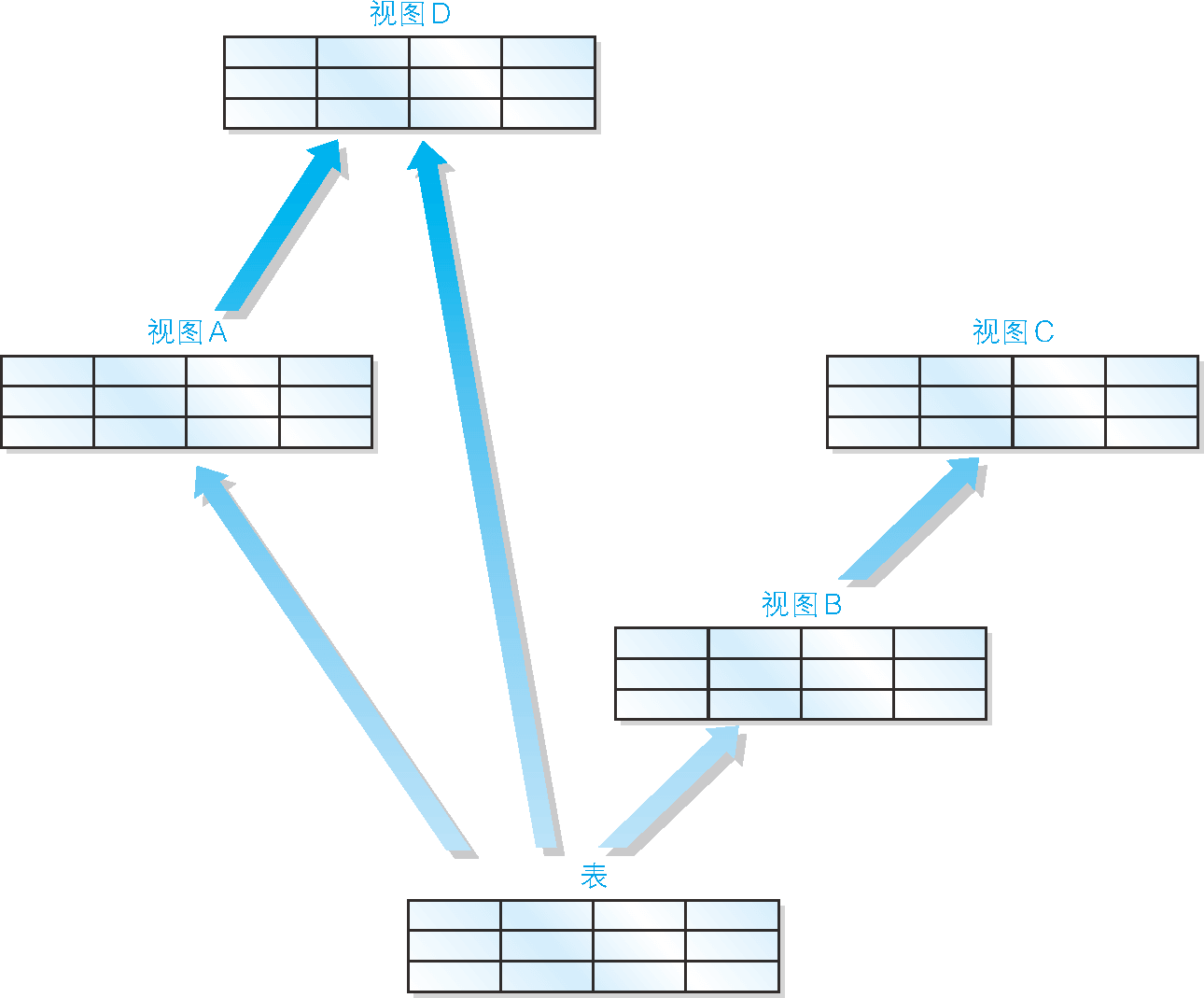
圖 2 可以在視圖的基礎上創建視圖
代碼清單 4 視圖 ProductSumJim

-- 確認創建好的視圖 SELECT product_type, cnt_product FROM ProductSumJim;執行結果:
product_type | cnt_product --------------+------------ 辦公用品 | 2雖然語法上沒有錯誤,但是我們還是應該儘量避免在視圖的基礎上創建視圖。這是因為對多數 DBMS 來說,多重視圖會降低 SQL 的性能。因此,希望大家(特別是剛剛接觸視圖的讀者)能夠使用單一視圖。
法則 3
應該避免在視圖的基礎上創建視圖。
除此之外,在使用時還要註意視圖有兩個限制,接下來會給大家詳細介紹。
1.3 視圖的限制 ①——定義視圖時不能使用 ORDER BY 子句
雖然之前我們說過在定義視圖時可以使用任何 SELECT 語句,但其實有一種情況例外,那就是不能使用 ORDER BY 子句,因此下述視圖定義語句是錯誤的。

為什麼不能使用 ORDER BY 子句呢?這是因為視圖和表一樣,數據行都是沒有順序的。
實際上,有些 DBMS 在定義視圖的語句中是可以使用 ORDER BY 子句的 [3],但是這並不是通用的語法。因此,在定義視圖時請不要使用 ORDER BY 子句。
法則 4
定義視圖時不要使用
ORDER BY子句。
1.4 視圖的限制 ② ——對視圖進行更新
之前我們說過,在 SELECT 語句中視圖可以和表一樣使用。那麼,對於 INSERT、DELETE、UPDATE 這類更新語句(更新數據的 SQL)來說,會怎麼樣呢?
實際上,雖然這其中有很嚴格的限制,但是某些時候也可以對視圖進行更新。標準 SQL 中有這樣的規定:如果定義視圖的 SELECT 語句能夠滿足某些條件,那麼這個視圖就可以被更新。
下麵就給大家列舉一些比較具有代表性的條件。
① SELECT 子句中未使用 DISTINCT
② FROM 子句中只有一張表
③ 未使用 GROUP BY 子句
④ 未使用 HAVING 子句
在前幾章的例子中,FROM 子句里通常只有一張表。因此,大家可能會覺得 ② 中的條件有些奇怪,但其實 FROM 子句中也可以併列使用多張表。大家在學習完 SQL 如何使用內聯結、外聯結和交叉聯結 的操作之後就明白了。
其他的條件大多數都與聚合有關。簡單來說,像這次的例子中使用的 ProductSum 那樣,使用視圖來保存原表的彙總結果時,是無法判斷如何將視圖的更改反映到原表中的。
例如,對 ProductSum 視圖執行如下 INSERT 語句。
INSERT INTO ProductSum VALUES ('電器製品', 5);
但是,上述 INSERT 語句會發生錯誤。這是因為視圖 ProductSum 是通過 GROUP BY 子句對原表進行彙總而得到的。為什麼通過彙總得到的視圖不能進行更新呢?
視圖歸根結底還是從表派生出來的,因此,如果原表可以更新,那麼視圖中的數據也可以更新。反之亦然,如果視圖發生了改變,而原表沒有進行相應更新的話,就無法保證數據的一致性了。
使用前述 INSERT 語句,向視圖 ProductSum 中添加數據 ('電器製品',5) 時,原表 Product 應該如何更新才好呢?按理說應該向表中添加商品種類為“電器製品”的 5 行數據,但是這些商品對應的商品編號、商品名稱和銷售單價等我們都不清楚(圖 3)。資料庫在這裡就遇到了麻煩。
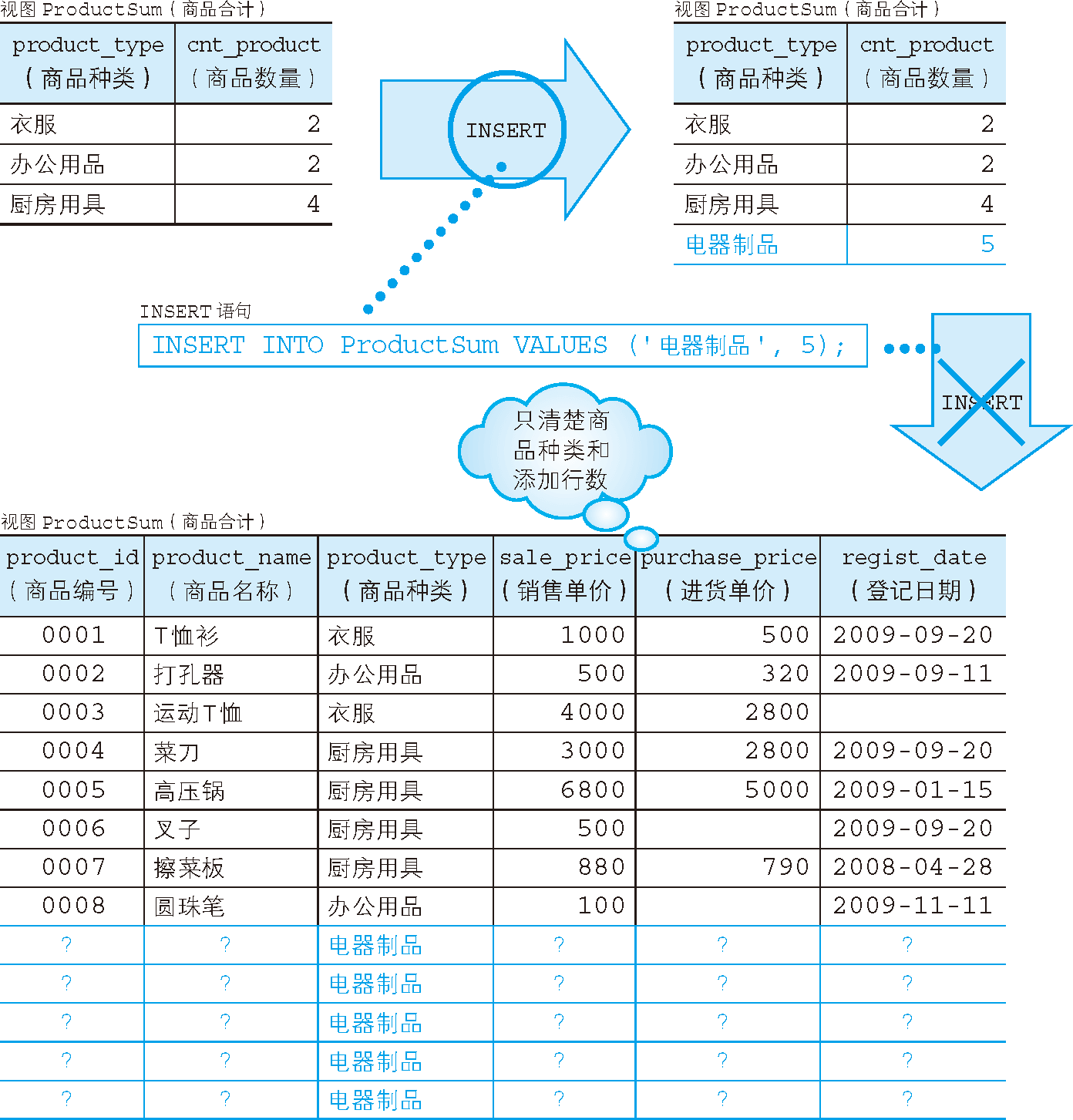
圖 3 通過彙總得到的視圖無法更新
法則 5
視圖和表需要同時進行更新,因此通過彙總得到的視圖無法進行更新。
-
能夠更新視圖的情況
像代碼清單 5 這樣,不是通過彙總得到的視圖就可以進行更新。
代碼清單 5 可以更新的視圖
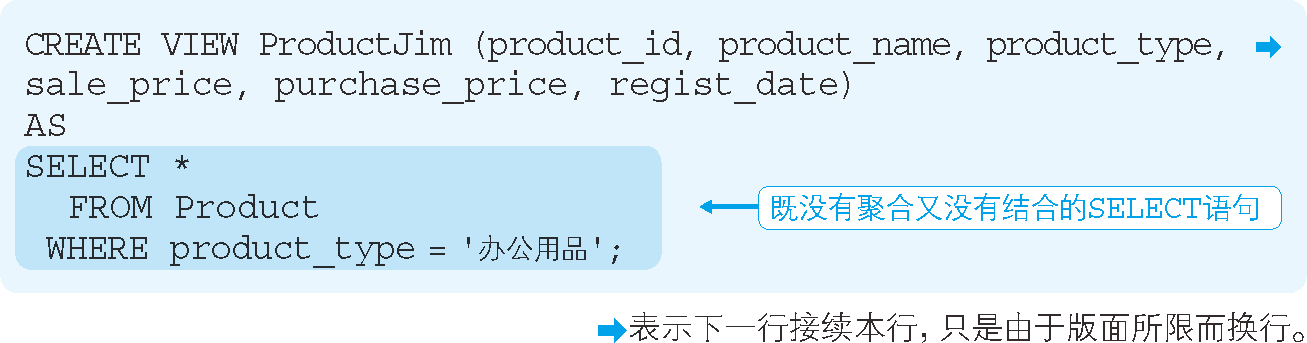
對於上述只包含辦公用品類商品的視圖
ProductJim來說,就可以執行類似代碼清單 6 這樣的INSERT語句。代碼清單 6 向視圖中添加數據行

註意事項
由於 PostgreSQL 中的視圖會被初始設定為只讀,所以執行代碼清單 6 中的
INSERT語句時,會發生下麵這樣的錯誤:ERROR: 不能向視圖中插入數據 HINT: 需要一個無條件的ON INSERT DO INSTEAD規則這種情況下,在
INSERT語句執行之前,需要使用代碼清單 A 中的指令來允許更新操作。在 DB2 和 MySQL 等其他 DBMS 中,並不需要執行這樣的指令。代碼清單 A 允許 PostgreSQL 對視圖進行更新
PostgreSQL
CREATE OR REPLACE RULE insert_rule AS ON INSERT TO ProductJim DO INSTEAD INSERT INTO Product VALUES ( new.product_id, new.product_name, new.product_type, new.sale_price, new.purchase_price, new.regist_date);
下麵讓我們使用 SELECT 語句來確認數據行是否添加成功吧。
-
視圖
-- 確認數據是否已經添加到視圖中 SELECT * FROM ProductJim;執行結果:

-
原表
-- 確認數據是否已經添加到原表中 SELECT * FROM Product;執行結果:
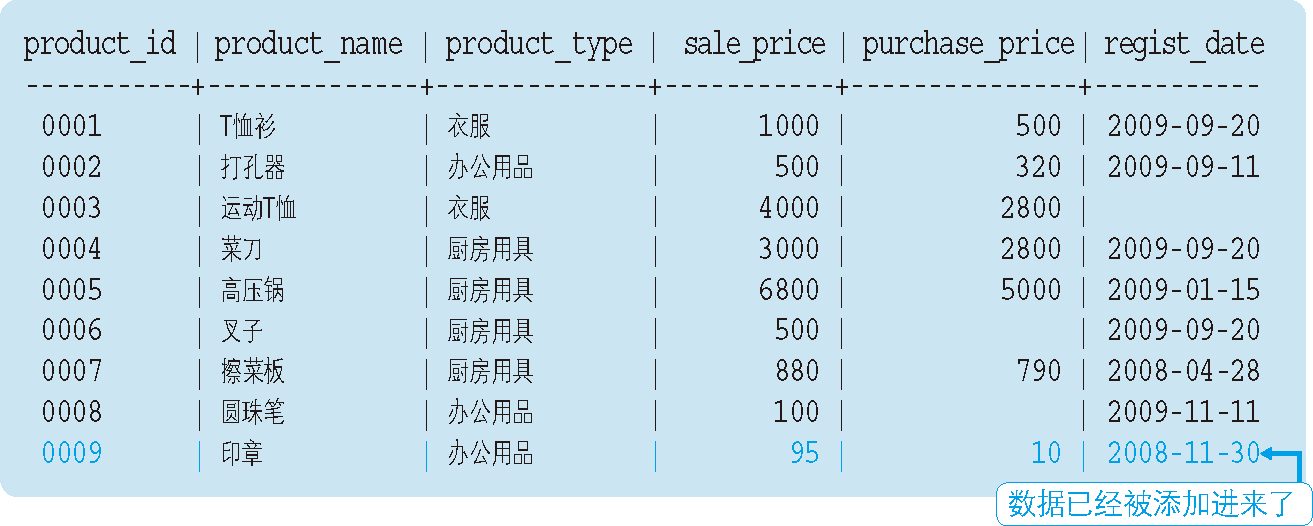
UPDATE 語句和 DELETE 語句當然也可以像操作表時那樣正常執行,但是對於原表來說卻需要設置各種各樣的約束(主鍵和 NOT NULL 等),需要特別註意。
1.5 刪除視圖
刪除視圖需要使用 DROP VIEW 語句,其語法如下所示。
語法 2 刪除視圖的 DROP VIEW 語句
DROP VIEW 視圖名稱(<視圖列名1>, <視圖列名2>, ……)
例如,想要刪除視圖 ProductSum 時,就可以使用代碼清單 7 中的 SQL 語句。
代碼清單 7 刪除視圖
DROP VIEW ProductSum;
特定的 SQL
在 PostgreSQL 中,如果刪除以視圖為基礎創建出來的多重視圖,由於存在關聯的視圖,因此會發生如下錯誤:
ERROR: 由於存在關聯視圖,因此無法刪除視圖productsum DETAIL: 視圖productsumjim與視圖productsum相關聯 HINT: 刪除關聯對象請使用DROP…CASCADE這時可以像下麵這樣,使用
CASCADE選項來刪除關聯視圖:DROP VIEW ProductSum CASCADE;
備忘
下麵我們再次將
Product表恢復到初始狀態(8 行)。請執行如下DELETE語句,刪除之前添加的 1 行數據。-- 刪除商品編號為0009(印章)的數據 DELETE FROM Product WHERE product_id = '0009';
二、子查詢
本節重點
一言以蔽之,子查詢就是一次性視圖(
SELECT語句)。與視圖不同,子查詢在SELECT語句執行完畢之後就會消失。由於子查詢需要命名,因此需要根據處理內容來指定恰當的名稱。
標量子查詢就是只能返回一行一列的子查詢。
2.1 子查詢和視圖
前一節我們學習了視圖這個非常方便的工具,本節將學習以視圖為基礎的子查詢。子查詢的特點概括起來就是一張一次性視圖。
我們先來複習一下視圖的概念,視圖並不是用來保存數據的,而是通過保存讀取數據的 SELECT 語句的方法來為用戶提供便利。
反之,子查詢就是將用來定義視圖的 SELECT 語句直接用於 FROM 子句當中。
接下來,就讓我們拿前一節使用的視圖 ProductSum(商品合計)來與子查詢進行一番比較吧。
首先,我們再來看一下視圖 ProductSum 的定義和視圖所對應的 SELECT 語句(代碼清單 8)。
代碼清單 8 視圖 ProductSum 和確認用的 SELECT 語句
-- 根據商品種類統計商品數量的視圖
CREATE VIEW ProductSum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
-- 確認創建好的視圖
SELECT product_type, cnt_product
FROM ProductSum;
能夠實現同樣功能的子查詢如代碼清單 9 所示。
代碼清單 9 子查詢

特定的 SQL
在 Oracle 的
FROM子句中,不能使用AS(會發生錯誤),因此,在 Oracle 中執行代碼清單 9 時,需要將 ① 中的“) AS ProductSum;”變為“) ProductSum;”
兩種方法得到的結果完全相同。
執行結果:
product_type | cnt_product
--------------+------------
衣服 | 2
辦公用品 | 2
廚房用具 | 4
如上所示,子查詢就是將用來定義視圖的 SELECT 語句直接用於 FROM 子句當中。
雖然“AS ProductSum”就是子查詢的名稱,但由於該名稱是一次性的,因此不會像視圖那樣保存在存儲介質(硬碟)之中,而是在 SELECT 語句執行之後就消失了。
實際上,該 SELECT 語句包含嵌套的結構,首先會執行 FROM 子句中的 SELECT 語句,然後才會執行外層的 SELECT 語句(圖 4)。

圖 4 SELECT 語句的執行順序
① 首先執行 FROM 子句中的 SELECT 語句(子查詢)
SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type;
② 根據 ① 的結果執行外層的 SELECT 語句
SELECT product_type, cnt_product
FROM ProductSum;
法則 6
子查詢作為內層查詢會首先執行。
-
增加子查詢的層數
由於子查詢的層數原則上沒有限制,因此可以像“子查詢的
FROM子句中還可以繼續使用子查詢,該子查詢的FROM子句中還可以再使用子查詢……”這樣無限嵌套下去(代碼清單 10)。代碼清單 10 嘗試增加子查詢的嵌套層數
SQL Server DB2 PostgreSQL MySQL
SELECT product_type, cnt_product FROM (SELECT * FROM (SELECT product_type, COUNT(*) AS cnt_product FROM Product GROUP BY product_type) AS ProductSum -----① WHERE cnt_product = 4) AS ProductSum2; -----------②特定的 SQL
在 Oracle 的
FROM子句中不能使用AS(會發生錯誤),因此,在 Oracle 中執行代碼清單 10 時,需要將 ① 中的“) AS ProductSum”變為“) ProductSum”,將 ② 中的“) AS ProductSum2;”變為“) ProductSum2;”。執行結果:
product_type | cnt_product --------------+------------ 廚房用具 | 4最內層的子查詢(
ProductSum)與之前一樣,根據商品種類(product_type)對數據進行彙總,其外層的子查詢將商品數量(cnt_product)限定為 4,結果就得到了 1 行廚房用具的數據。但是,隨著子查詢嵌套層數的增加,SQL 語句會變得越來越難讀懂,性能也會越來越差。因此,請大家儘量避免使用多層嵌套的子查詢。
2.2 子查詢的名稱
之前的例子中我們給子查詢設定了 ProductSum 等名稱。原則上子查詢必須設定名稱,因此請大家儘量從處理內容的角度出發為子查詢設定恰當的名稱。
在上述例子中,子查詢用來對 Product 表的數據進行彙總,因此我們使用了尾碼 Sum 作為其名稱。
為子查詢設定名稱時需要使用 AS 關鍵字,該關鍵字有時也可以省略 [4]。
2.3 標量子查詢
接下來我們學習子查詢中的標量子查詢(scalar subquery)。
2.3.1 什麼是標量
標量就是單一的意思,在資料庫之外的領域也經常使用。
上一節我們學習的子查詢基本上都會返回多行結果(雖然偶爾也會只返回 1 行數據)。由於結構和表相同,因此也會有查詢不到結果的情況。
而標量子查詢則有一個特殊的限制,那就是必須而且只能返回 1 行 1 列的結果,也就是返回表中某一行的某一列的值,例如“10”或者“東京都”這樣的值。
法則 7
標量子查詢就是返回單一值的子查詢。
細心的讀者可能會發現,由於返回的是單一的值,因此標量子查詢的返回值可以用在 = 或者 <> 這樣需要單一值的比較運算符之中。這也正是標量子查詢的優勢所在。下麵就讓我們趕快來試試看吧。
2.3.2 在 WHERE 子句中使用標量子查詢
在 SQL 如何插入、刪除和更新數據 中,我們練習了通過各種各樣的條件從 Product(商品)表中讀取數據。大家有沒有想過通過下麵這樣的條件查詢數據呢?
“查詢出銷售單價高於平均銷售單價的商品。”
或者說想知道價格處於上游的商品時,也可以通過上述條件進行查詢。
然而這並不是用普通方法就能解決的。如果我們像下麵這樣使用 AVG 函數的話,就會發生錯誤。

雖然這樣的 SELECT 語句看上去能夠滿足我們的要求,但是由於在 WHERE 子句中不能使用聚合函數,因此這樣的 SELECT 語句是錯誤的。
那麼究竟什麼樣的 SELECT 語句才能滿足上述條件呢?
這時標量子查詢就可以發揮它的功效了。首先,如果想要求出 Product 表中商品的平均銷售單價(sale_price),可以使用代碼清單 11 中的 SELECT 語句。
代碼清單 11 計算平均銷售單價的標量子查詢
SELECT AVG(sale_price)
FROM Product;
執行結果:
avg
----------------------
2097.5000000000000000
AVG 函數的使用方法和 COUNT 函數相同,其計算式如下所示。
(1000+500+4000+3000+6800+500+880+100) / 8 = 2097.5
這樣計算出的平均單價大約就是 2100 元。不難發現,代碼清單 11 中的 SELECT 語句的查詢結果是單一的值(2097.5)。
因此,我們可以直接將這個結果用到之前失敗的查詢之中。正確的 SQL 如代碼清單 12 所示。
代碼清單 12 選取出銷售單價(sale_price)高於全部商品的平均單價的商品

執行結果:
product_id | product_name | sale_price
------------+--------------+-----------
0003 | 運動T恤 | 4000
0004 | 菜刀 | 3000
0005 | 高壓鍋 | 6800
前一節我們已經介紹過,使用子查詢的 SQL 會從子查詢開始執行。因此,這種情況下也會先執行下述計算平均單價的子查詢(圖 5)。
-- ① 內層的子查詢
SELECT AVG(sale_price)
FROM Product ;
子查詢的結果是 2097.5,因此會用該值替換子查詢的部分,生成如下 SELECT 語句。
-- ② 外層的查詢
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > 2097.5
大家都能看出該 SQL 沒有任何問題可以正常執行,結果如上所述。
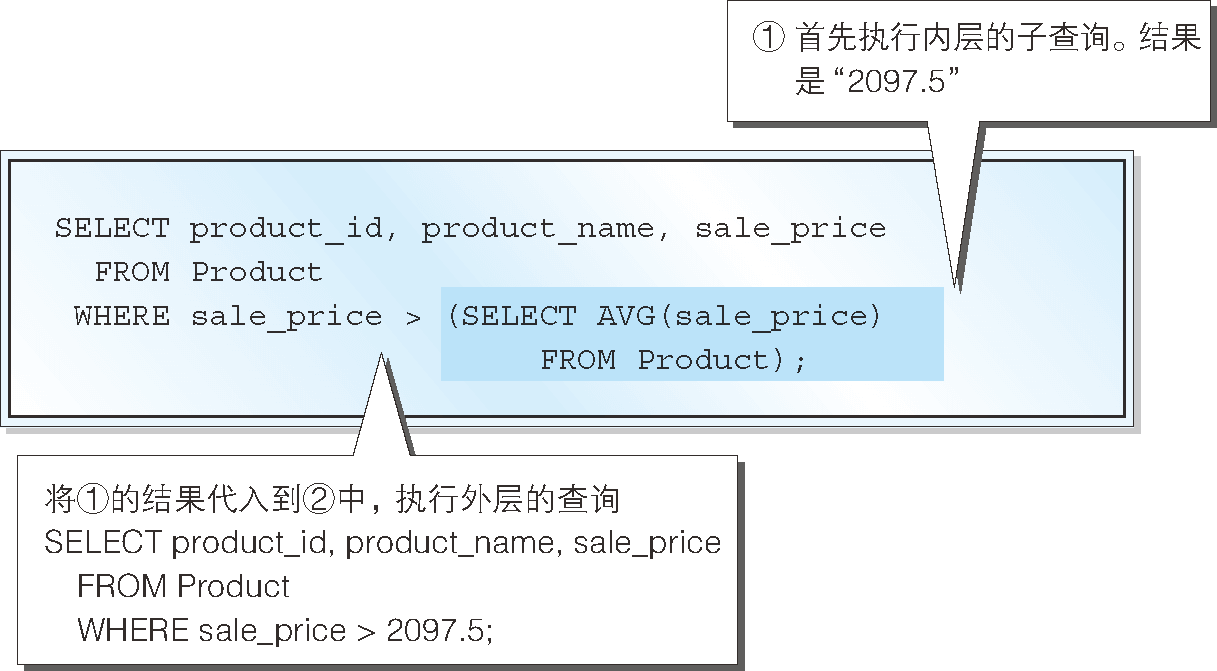
圖 5 SELECT 語句的執行順序(標量子查詢)
2.4 標量子查詢的書寫位置
標量子查詢的書寫位置並不僅僅局限於 WHERE 子句中,通常任何可以使用單一值的位置都可以使用。也就是說,能夠使用常數或者列名的地 方,無論是 SELECT 子句、GROUP BY 子句、HAVING 子句,還是 ORDER BY 子句,幾乎所有的地方都可以使用。
例如,在 SELECT 子句當中使用之前計算平均值的標量子查詢的 SQL 語句,如代碼清單 13 所示。
代碼清單 13 在 SELECT 子句中使用標量子查詢
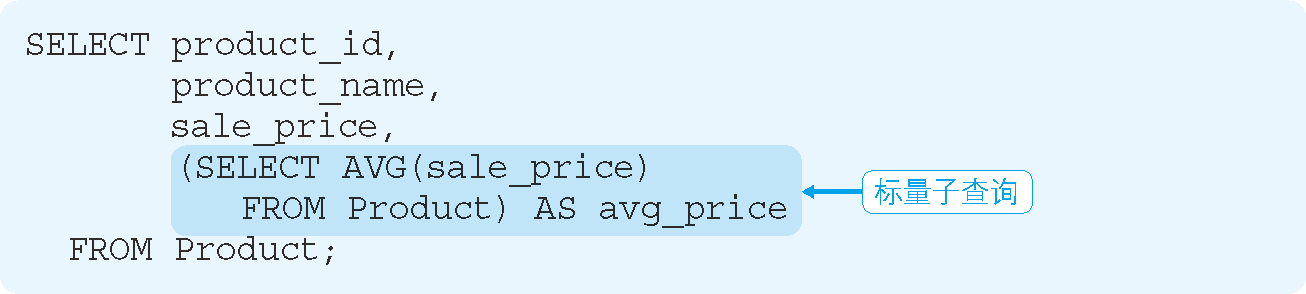
執行結果:
product_id | product_name | sale_price | avg_price
------------+---------------+------------+----------------------
0001 | T恤衫 | 1000 | 2097.5000000000000000
0002 | 打孔器 | 500 | 2097.5000000000000000
0003 | 運動T恤 | 4000 | 2097.5000000000000000
0004 | 菜刀 | 3000 | 2097.5000000000000000
0005 | 高壓鍋 | 6800 | 2097.5000000000000000
0006 | 叉子 | 500 | 2097.5000000000000000
0007 | 擦菜板 | 880 | 2097.5000000000000000
0008 | 圓珠筆 | 100 | 2097.5000000000000000
從上述結果可以看出,在商品一覽表中加入了全部商品的平均單價。有時我們會需要這樣的單據。
此外,我們還可以像代碼清單 14 中的 SELECT 語句那樣,在 HAVING 子句中使用標量子查詢。
代碼清單 14 在 HAVING 子句中使用標量子查詢

執行結果:
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
廚房用具 | 2795.0000000000000000
該查詢的含義是想要選取出按照商品種類計算出的銷售單價高於全部商品的平均銷售單價的商品種類。
如果在 SELECT 語句中不使用 HAVING 子句的話,那麼平均銷售單價為 300 元的辦公用品也會被選取出來。
但是,由於全部商品的平均銷售單價是 2097.5 元,因此低於該平均值的辦公用品會被 HAVING 子句中的條件排除在外。
2.5 使用標量子查詢時的註意事項
最後我們來介紹一下使用標量子查詢時的註意事項,那就是該子查詢絕對不能返回多行結果。
也就是說,如果子查詢返回了多行結果,那麼它就不再是標量子查詢,而僅僅是一個普通的子查詢了,因此不能被用在 = 或者 <> 等需要單一輸入值的運算符當中,也不能用在 SELECT 等子句當中。
例如,如下的 SELECT 子查詢會發生錯誤。

發生錯誤的原因很簡單,就是因為會返回如下多行結果:
avg
----------------------
2500.0000000000000000
300.0000000000000000
2795.0000000000000000
在 1 行 SELECT 子句之中當然不可能使用 3 行數據。因此,上述 SELECT 語句會返回“因為子查詢返回了多行數據所以不能執行”這樣的錯誤信息 [5]。
三、關聯子查詢
本節重點
關聯子查詢會在細分的組內進行比較時使用。
關聯子查詢和
GROUP BY子句一樣,也可以對錶中的數據進行切分。關聯子查詢的結合條件如果未出現在子查詢之中就會發生錯誤。
3.1 普通的子查詢和關聯子查詢的區別
按此前所學,使用子查詢就能選取出銷售單價(sale_price)高於全部商品平均銷售單價的商品。
這次我們稍稍改變一下條件,選取出各商品種類中高於該商品種類的平均銷售單價的商品。
3.1.1 按照商品種類與平均銷售單價進行比較
只通過語言描述可能難以理解,還是讓我們來看看具體示例吧。我們以廚房用具中的商品為例,該分組中包含了表 1 所示的 4 種商品。
表 1 廚房用具中的商品
| 商品名稱 | 銷售單價 |
|---|---|
| 菜刀 | 3000 |
| 高壓鍋 | 6800 |
| 叉子 | 500 |
| 擦菜板 | 880 |
因此,計算上述 4 種商品的平均價格的算術式如下所示。
(3000 + 6800 + 500 + 880) / 4 = 2795 (元)
這樣我們就能得知該分組內高於平均價格的商品是菜刀和高壓鍋了,這兩種商品就是我們要選取的對象。
我們可以對餘下的分組繼續使用同樣的方法。衣服分組的平均銷售單價是:
(1000 + 4000) / 2 = 2500 (元)
因此運動T恤就是要選取的對象。辦公用品分組的平均銷售單價是:
(500 + 100) / 2 = 300 (元)
因此打孔器就是我們要選取的對象。
這樣大家就能明白該進行什麼樣的操作了吧。我們並不是要以全部商品為基礎,而是要以細分的組為基礎,對組內商品的平均價格和各商品的銷售單價進行比較。
按照商品種類計算平均價格並不是什麼難事,我們已經學習過了,只需按照代碼清單 15 那樣,使用 GROUP BY 子句就可以了。
代碼清單 15 按照商品種類計算平均價格
SELECT AVG(sale_price)
FROM Product
GROUP BY product_type;
但是,如果我們使用前一節(標量子查詢)的方法,直接把上述 SELECT 語句使用到 WHERE 子句當中的話,就會發生錯誤。
-- 發生錯誤的子查詢
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product
GROUP BY product_type);
出錯原因前一節已經講過了,該子查詢會返回 3 行結果(2795、2500、300),並不是標量子查詢。在 WHERE 子句中使用子查詢時,該子查詢的結果必須是單一的。
但是,如果以商品種類分組為單位,對銷售單價和平均單價進行比較,除此之外似乎也沒有其他什麼辦法了。到底應該怎麼辦才好呢?
3.1.2 使用關聯子查詢的解決方案
這時就輪到我們的好幫手——關聯子查詢登場了。
只需要在剛纔的 SELECT 語句中追加一行,就能得到我們想要的結果了 [6]。事實勝於雄辯,還是讓我們先來看看修改之後的 SELECT 語句吧(代碼清單 16)。
代碼清單 16 通過關聯子查詢按照商品種類對平均銷售單價進行比較

特定的 SQL
Oracle 中不能使用
AS(會發生錯誤)。因此,在 Oracle 中執行代碼清單 16 時,請大家把 ① 中的FROM Product AS P1變為FROM Product P1,把 ② 中的FROM Product AS P2變為FROM Product P2。
執行結果:
product_type | product_name | sale_price
---------------+---------------+------------
辦公用品 | 打孔器 | 500
衣服 | 運動T恤 | 4000
廚房用具 | 菜刀 | 3000
廚房用具 | 高壓鍋 | 6800
這樣我們就能選取出辦公用品、衣服和廚房用具三類商品中高於該類商品的平均銷售單價的商品了。
這裡起到關鍵作用的就是在子查詢中添加的 WHERE 子句的條件。該條件的意思就是,在同一商品種類中對各商品的銷售單價和平均單價進行比較。
這次由於作為比較對象的都是同一張 Product 表,因此為了進行區別,分別使用了 P1 和 P2 兩個別名。
在使用關聯子查詢時,需要在表所對應的列名之前加上表的別名,以“<表名>.<列名>”的形式記述。
在對錶中某一部分記錄的集合進行比較時,就可以使用關聯子查詢。
因此,使用關聯子查詢時,通常會使用“限定(綁定)”或者“限制”這樣的語言,例如本次示例就是限定“商品種類”對平均單價進行比較。
法則 8
在細分的組內進行比較時,需要使用關聯子查詢。
3.2 關聯子查詢也是用來對集合進行切分的
換個角度來看,其實關聯子查詢也和 GROUP BY 子句一樣,可以對集合進行切分。
大家還記得我們用來說明 GROUP BY 子句 的圖(圖 6)嗎?
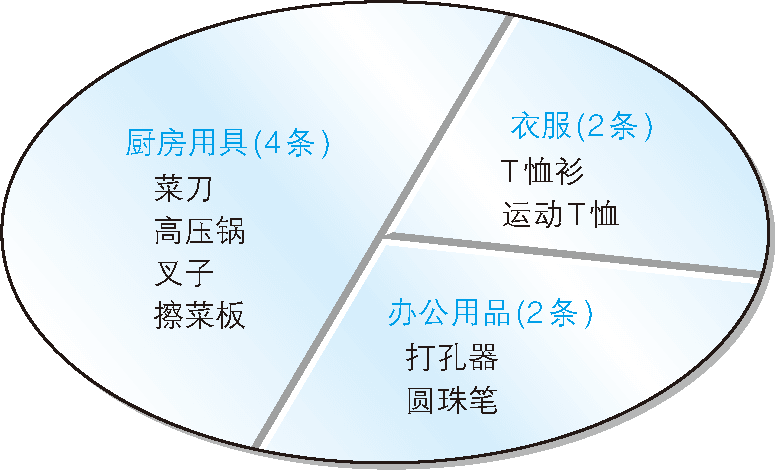
圖 6 根據商品種類對錶進行切分的圖示
上圖顯示了作為記錄集合的表是如何按照商品種類被切分的。使用關聯子查詢進行切分的圖示也基本相同(圖 7)。
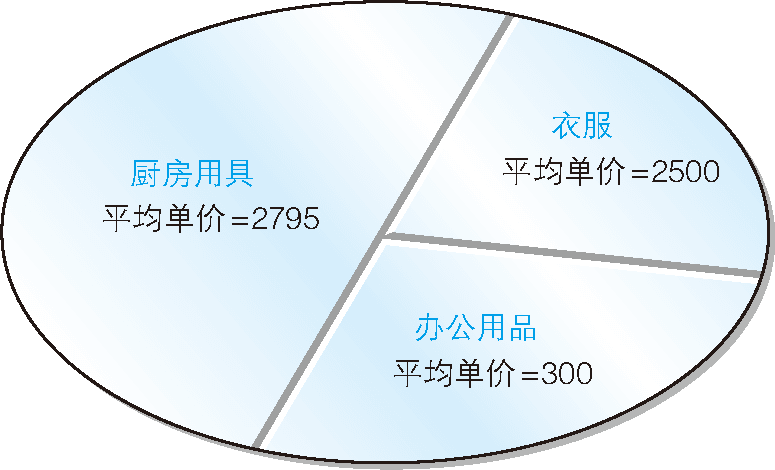
圖 7 根據關聯子查詢進行切分的圖示
我們首先需要計算各個商品種類中商品的平均銷售單價,由於該單價會用來和商品表中的各條記錄進行比較,因此關聯子查詢實際只能返回 1 行結果。
這也是關聯子查詢不出錯的關鍵。關聯子查詢執行時,DBMS 內部的執行情況如圖 8 所示。
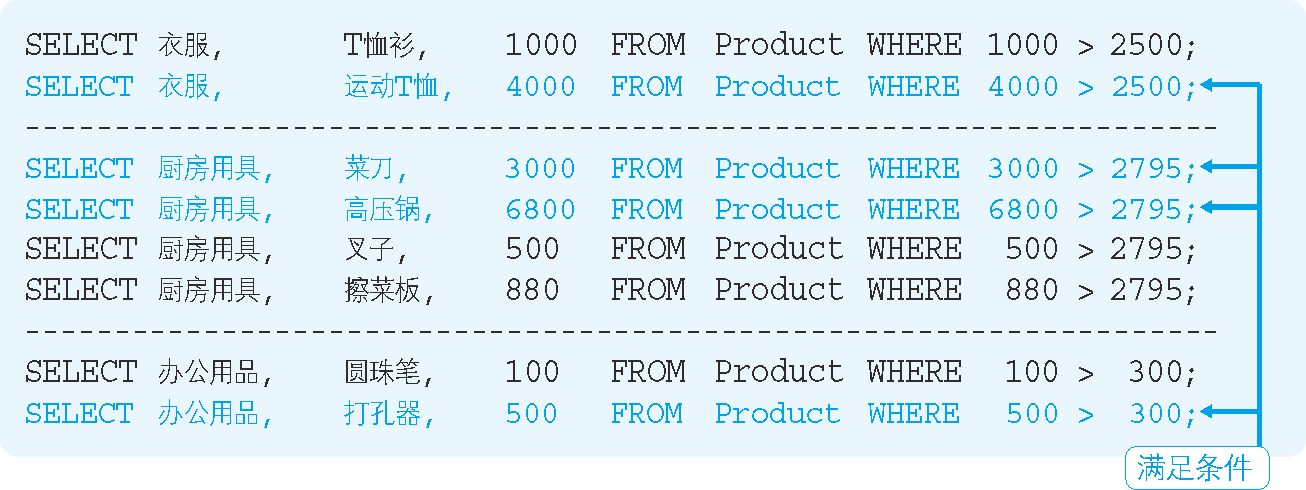
圖 8 關聯子查詢執行時 DBMS 內部的執行情況
如果商品種類發生了變化,那麼用來進行比較的平均單價也會發生變化,這樣就可以將各種商品的銷售單價和平均單價進行比較了。
關聯子查詢的內部執行結果對於初學者來說是比較難以理解的,但是像上圖這樣將其內部執行情況可視化之後,理解起來就變得非常容易了吧。
3.3 結合條件一定要寫在子查詢中
下麵給大家介紹一下 SQL 初學者在使用關聯子查詢時經常犯的一個錯誤,那就是將關聯條件寫在子查詢之外的外層查詢之中。請大家看一下下麵這條 SELECT 語句。

上述 SELECT 語句只是將子查詢中的關聯條件移到了外層查詢之中,其他並沒有任何更改。但是,該 SELECT 語句會發生錯誤,不能正確執行。
允許存在這樣的書寫方法可能並不奇怪,但是 SQL 的規則禁止這樣的書寫方法。
該書寫方法究竟違反了什麼規則呢?那就是關聯名稱的作用域。雖然這一術語看起來有些晦澀難懂,但是一解釋大家就明白了。
關聯名稱就是像 P1、P2 這樣作為表別名的名稱,作用域(scope)就是生存範圍(有效範圍)。也就是說,關聯名稱存在一個有效範圍的限制。
具體來講,子查詢內部設定的關聯名稱,只能在該子查詢內部使用(圖 9)。換句話說,就是“內部可以看到外部,而外部看不到內部”。
請大家一定不要忘記關聯名稱具有一定的有效範圍。
如前所述,SQL 是按照先內層子查詢後外層查詢的順序來執行的。這樣,子查詢執行結束時只會留下執行結果,作為抽出源的 P2 表其實已經不存在了 [7]。
因此,在執行外層查詢時,由於 P2 表已經不存在了,因此就會返回“不存在使用該名稱的表”這樣的錯誤。

圖 9 子查詢內的關聯名稱的有效範圍
原文鏈接:https://www.developerastrid.com/sql/sql-view-subqueries/
(完)
數據保存在表中時,必須要顯式地執行 SQL 更新語句才能對數據進行更新。 ↩︎
但是根據實現方式的不同,也存在內部使用視圖的
SELECT語句本身進行重組的 DBMS。 ↩︎例如,在 PostgreSQL 中上述 SQL 語句就沒有問題,可以執行。 ↩︎
其中也有像 Oracle 這樣,在名稱之前使用
AS關鍵字就會發生錯誤的資料庫,大家可以將其視為例外的情況。 ↩︎例如,使用 PostgreSQL 時會返回如下錯誤。“ERROR :副查詢中使用了返回多行結果的表達式” ↩︎
事實上,對於代碼清單 16 中的
SELECT語句,即使在子查詢中不使用GROUP BY子句,也能得到正確的結果。這是因為在WHERE子句中追加了“P1.product_type=P2.product_type”這個條件,使得AVG函數按照商品種類進行了平均值計算。但是為了跟前面出錯的查詢進行對比,這裡還是加上了GROUP BY子句。 ↩︎當然,消失的其實只是
P2這個名稱而已,Product表以及其中的數據還是存在的。 ↩︎


