
導讀: 大家好,今天主要分享數據分析平臺的平臺演進以及我們在上面沉澱的一些數據分析方法是如何應用的。 具體分以下四部分: Part1:主要介紹下我所在的部門,數據平臺部主要是做什麼的,大概涉及到哪些業務,在整個數據流程當中數據平臺部負責哪些東西; Part2:既然我們講數據分析平臺,那麼數據分析是什 ...

導讀: 大家好,今天主要分享數據分析平臺的平臺演進以及我們在上面沉澱的一些數據分析方法是如何應用的。
具體分以下四部分:
- Part1:主要介紹下我所在的部門,數據平臺部主要是做什麼的,大概涉及到哪些業務,在整個數據流程當中數據平臺部負責哪些東西;
- Part2:既然我們講數據分析平臺,那麼數據分析是什麼樣的,數據分析領域是什麼樣的;
- Part3:螞蟻現在的數據分析平臺是怎麼來的,是怎麼演進到最新版本,在最新版本3.0裡面有一些技術詳解;
- Part4:既然有了數據分析平臺,那麼數據分析能幫我們乾什麼,講了一個具體在工程上應用的case。
--
01 數據平臺部介紹
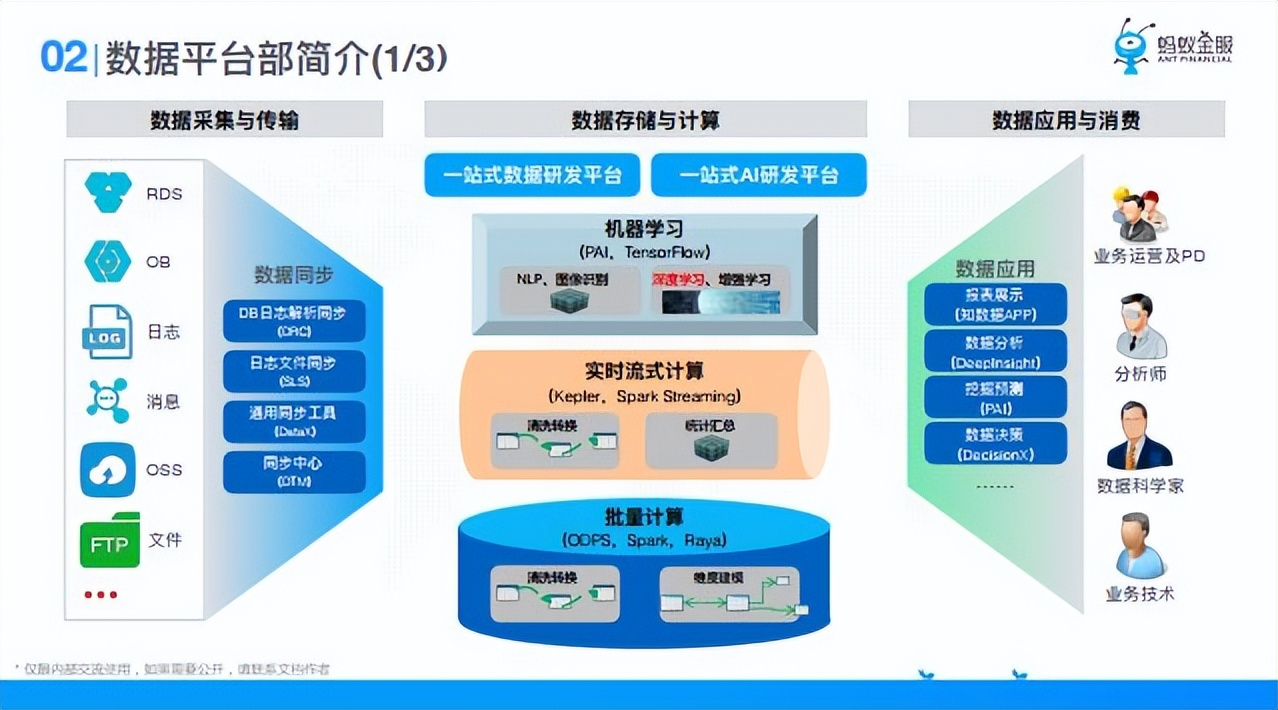
第一,數據平臺部的介紹,首先從整個數據流程開始講解,數據流程的開始從數據採集與傳輸,這裡面涉及到比如說線上的RDS,OB這些是線上業務資料庫;日誌,比如是線上應用,機器上打的那些文件日誌;還有一些消息,線上應用寫的一些消息;還有一些文件,外面的文件。經過數據採集,數據同步,進入到我們的數倉體系裡面,這裡面數據同步可能有很多,比如DB的日誌解析同步DRC、日誌文件的解析、採集SRS,然後有一些通用的同步工具DataX。
第二,在數據存儲與計算裡面,從下往上看上圖,第一是比較多的、傳統的批量計算,就像ODPS,Spark,還有最新的一些框架,比如Ray,Ray在螞蟻變種就是Raya。第二塊就是實時流計算,業界有比如storm,JStorm,螞蟻有Kepler,Spark Streaming這些東西。第三在這之上是垂直的,有一些機器學習的場景,有PAI,有TersonFlow這樣的東西在裡面。第四,在這個體系裡用戶接觸最多的是一站式數據研發平臺和一站式AI研發平臺,分別是面向數倉、AI兩個體系去做的。
最後,在存儲與計算完成以後就要面嚮應用場景,面向最後的消費者,這中間的應用,比如說有報表展示,數據分析(今天我們著重講數據分析這一塊),還有一些挖掘預測,就是做演算法,做模型,還有一些數據決策,就是把數據作為線上決策,這就是整個數據流。
數據平臺部在這裡面著重的是偏後面,就是數據存儲與計算以及數據應用與消費這兩個東西。下麵著重介紹兩個環節,數據平臺部有哪些業務。
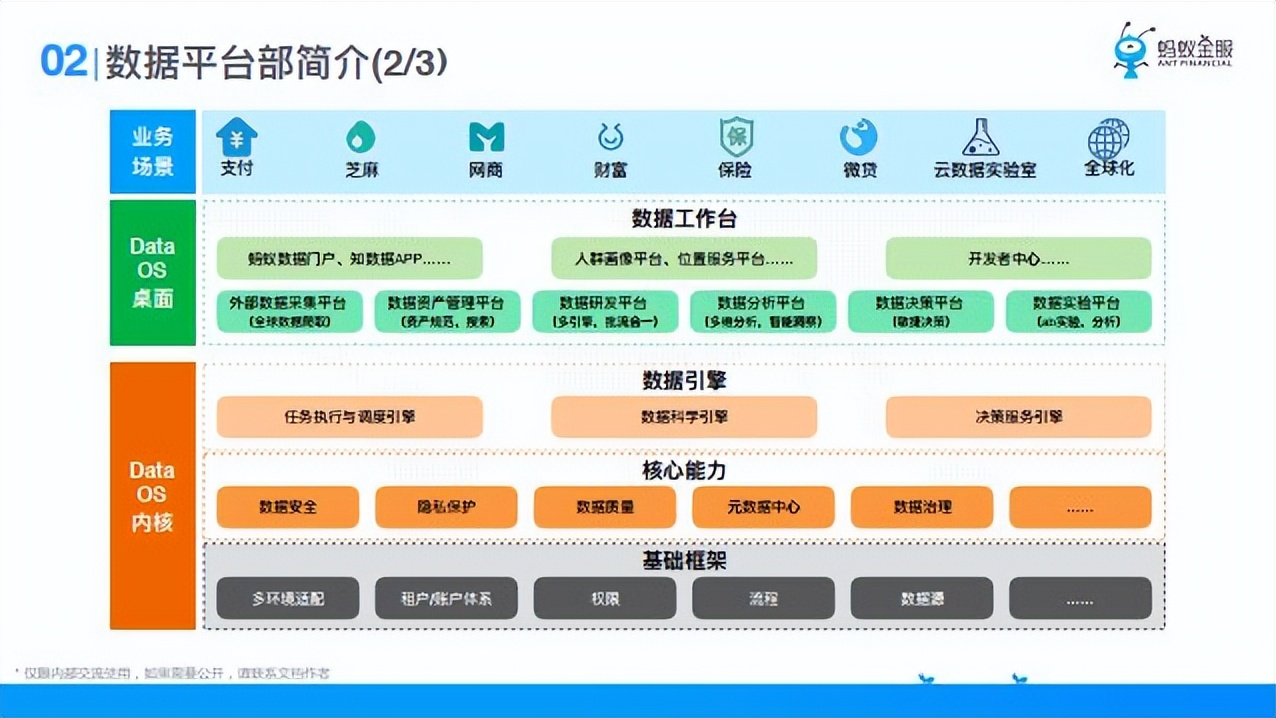
這張圖可是一個業務架構,就是數據平臺部涉及到哪些業務,總共我們分為3層,我們把我們數據平臺部在做的一個東西叫做數據操作系統,我們有兩塊,一個是數據操作系統內核,一個是用戶接觸到的軟體。還有是外面有哪些場景。
1. 數據操作系統的內核
- 基礎框架
基礎框架裡面有什麼東西,為什麼有他,比如說多環境適配,因為我們整套數據平臺的解決方案是對外輸出的,有公有雲環境,有專有雲環境,這些環境底下的基礎設施都不一樣,比如說包括租戶和賬戶體系,許可權體系,流程體系,審批流這類東西,所以正是通過基礎框架搭我們底層的環境。最主要目的其實是提供一些我們上層數據應用的通用能力以及把底層的數據環境的差異給屏蔽掉。
- 核心能力
① 數據安全:數據安全就會涉及到數據資產的分類、分級。不同類別的資產,他的安全等級是不一樣的,他在安全裡面需要有許可權的話,他的審批策略是不一樣的,這是數據安全這一塊,可能還涉及一些比如脫敏,我們消費端接觸到這些數據怎麼脫敏;
② 隱私保護:隱私保護更偏重,比如說隱私保護還有一個叫法是數據安全、數據合規,我們想要做什麼事情,就是我們要去透明化的看到各個公司數據流通,比如有哪些數據,這些數據的安全等級是什麼樣的,涉及到用戶哪些數據;
③ 數據質量:主要是在我們數據研發過程當中,數據周期從發佈到線上調度,調度完了怎麼去做數據質量的監測,檢測完了以後,比如說我們做離線調度的時候最重要的一個就是數據產出時效,所以有一個基線。這都是怎麼去保障我們任務的基線;
④ 元數據中心:元數據中心大家都知道,因為我們下麵有各種各樣不同的引擎,有Spark,有ODPS,有MySQL這些東西,怎麼去把它當中的數據統一的元數據中心;
⑤ 數據治理:數據治理的邏輯就是配合數據質量把我們現有的數據給盤清楚。
- 數據引擎
① 任務執行與調度引擎:我們在做ETL的時候大多數都是這種任務執行與調度;
② 數據科學引擎:數據科學引擎主要是做分析,做業務洞察這一類,今天的數據業務平臺可能更多的就是依賴於數據科學引擎,後面會詳細介紹;
③ 決策服務引擎:決策引擎比如說給大家舉一個場景,芝麻分大家都知道,那首先假如我有一個業務線上上,線上上做策略的時候,或者給大家看不同的頁面的時候,不同的芝麻分的等級看到的頁面或者等級是不一樣的,這種東西是需要數據決策的,或者直白的來說,是需要這個人的芝麻分,這個通過統計數據服務會去配一個決策規則,相當於這裡的決策引擎裡面支持一種決策的DSL配置,簡單來講就是if……else……,if…else……,能夠配置這樣一套規則後,給線上業務場景提供服務,這是決策服務引擎。整個數據內核就這麼多東西。
2. 數據操作系統的桌面
在這之上我們建了面向用戶的數據工作台主要包括:
① 外部數據採集平臺:因為我們有很多數,比如口碑,口碑的交易量的漲跌有一個很關鍵的因素,天氣,所以我需要外部天氣數據,所以這是外部數據採集平臺;
② 資產管理平臺:和這裡面元數據中心是對等的,我們需要把我們體系內所有的數據規範化管理起來,在我們的研發流程裡面他就必須到這個數據資產管理平臺裡面去把他這一次要建的表規範化下來;
③ 數據研發平臺:數據研發平臺就要支持多引擎、批流合一,我們寫一個統一的SQL,它可以切換到批ODPS調動,也可以切換到實時,切換到比如我們體系內的Kepler,切換到Spark Streaming上去做調度,這是數據研發平臺要做的事情。他就可能依賴於任務執行調度引擎;
④ 數據分析平臺:它主要做一些多維分析和自助的多維分析,還做一些智能的業務洞察;
⑤ 數據決策平臺:為線上業務提供數據能力。然後就是數據實驗平臺,實驗概念就是A/B實驗,我今天切一個演算法,可以在這上面切1%的流量到這個演算法,另外1%的流量到這個老演算法對比。對比他們的效果、顯著度。做一些置信區間的分析,來看看這個演算法的效果,因為這裡面實驗涉及到的概念就是,同樣這一個演算法切1%,如果一個效果是98%,一個是95%,如果沒經過科學檢驗的話,沒辦法說明98%的三個點到底是樣本誤差導致的,還是說就是我這個演算法,所以說實驗平臺解決這個問題。
在這之上有一些垂直場景的服務,比如說螞蟻的數據產品對外透出的一些端的能力,能夠在移動端去看我們的數據。
第二塊有一些垂直的解決方案,比如說人群畫像平臺、位置服務。
第三塊是開發者中心,主要是應對一個場景叫開放。
這就是從數據操作系統內核到數據系統桌面,再到數據業務場景。數據平臺部業務大概的範疇是這樣的。
--
02 數據分析領域簡介
數據分析這個詞大家都講了很多,那數據分析到底怎麼樣呢,其實我們身邊有很多數據分析的例子,給大家舉一個例子,然後再來看看數據分析體系化結構怎麼樣。
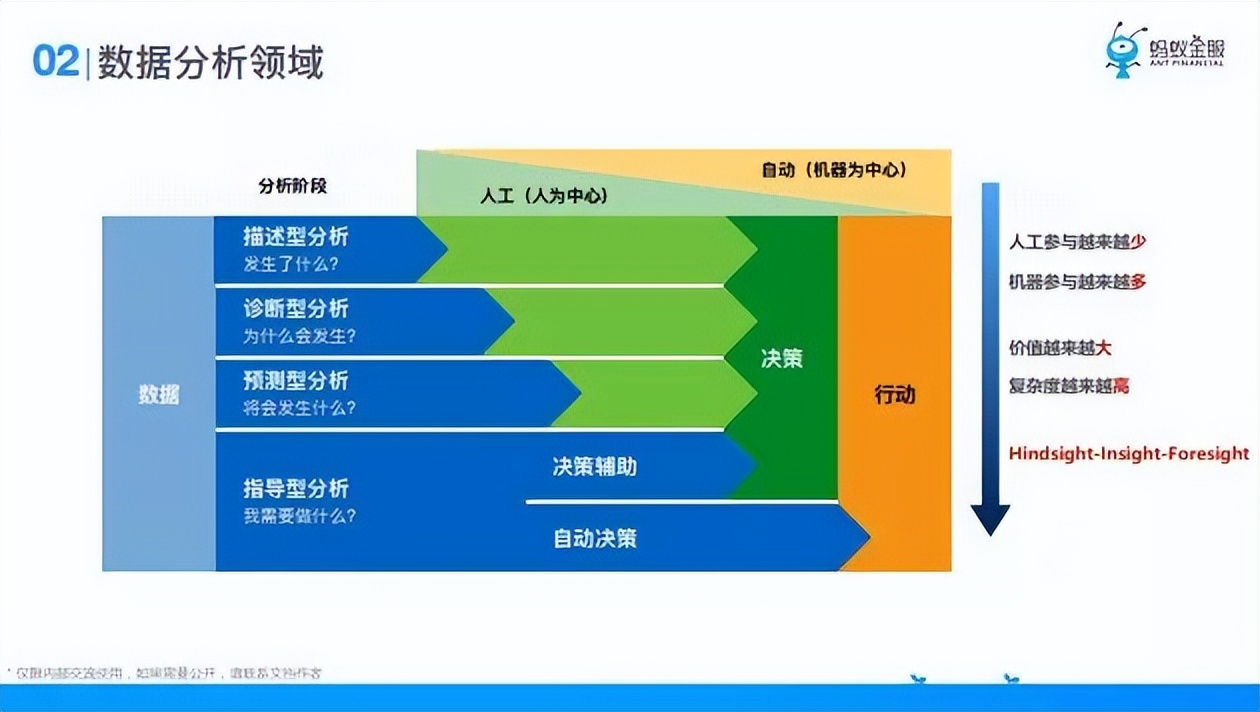
數據分析階段包括:
- ① 描述型分析階段;
- ② 診斷型分析階段;
- ③ 預測型分析階段;
- ④ 指導型分析階段。
指導性分析的話,他可能會有兩條路徑,第一條他是決策輔助,它告訴你要來做什麼,具體要不要做你來做決策,最後再去產生行動,還有一種比如線上的機器學習,我可以讓機器自動切換參數,做一些效果的提升,下麵這一步就是機器自動了。所以說數據分析的不同階段不同層次,人工參與的會越來越少,機器參與的會越來越多,但是它的價值越來越大,複雜度越來越高,就是從馬後炮到構建再到穩健。就是這麼一個過程,這就是我們理解的數據分析。這個領域是這樣的,所以說數據分析不是簡單的四個字。
--
03 數據分析平臺
說完數據分析以後,給大家介紹一下螞蟻的數據分析平臺,它的演進歷史以及最新3.0版本的裡面有哪些東西。
螞蟻金服楊軍:螞蟻數據分析平臺的演進及數據分析方法的應用
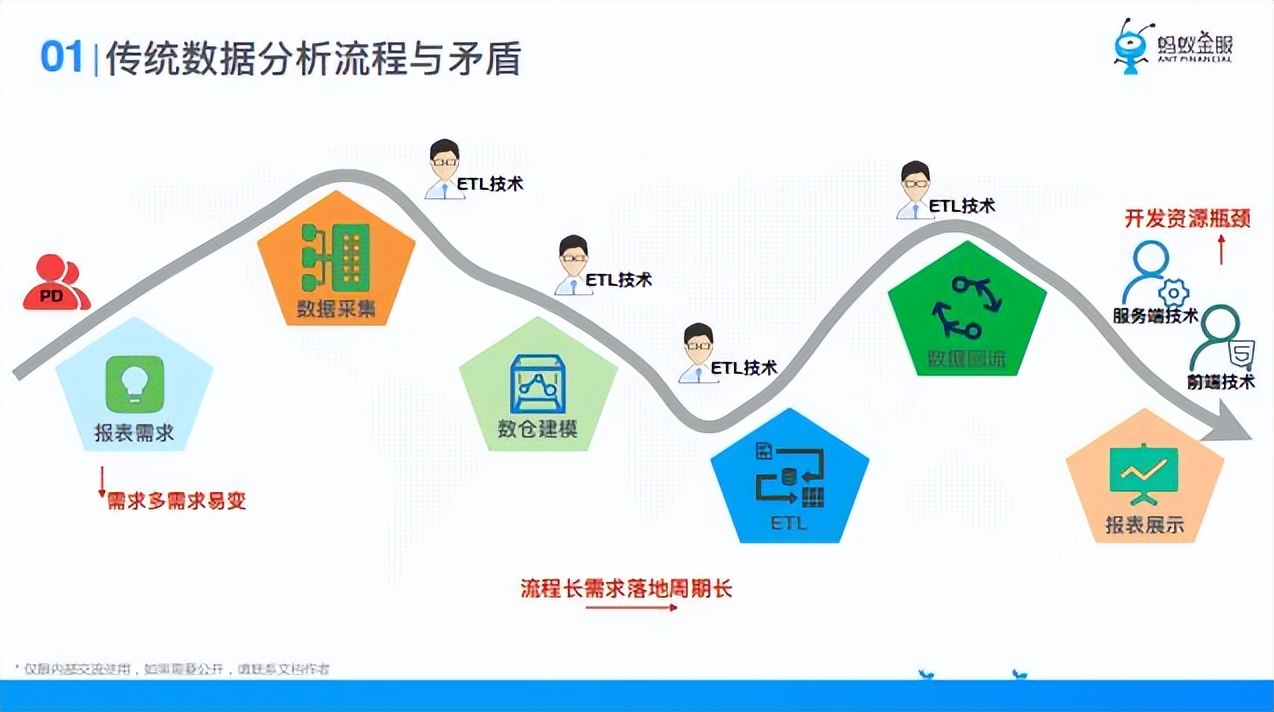
說到數據平臺的誕生,就要說到傳統數據分析,它存在的矛盾有:
- ① 報表需求易變;
- ② 流程需求落地周期會長;
- ③ 開發資源瓶頸(技術排期長)。
有了這個矛盾以後,數據分析平臺13年的時候出了一個1.0版本,可以認為是一個報表工具,展現層可以自助拖拽,比如說封裝維度和度量這兩個概念,把什麼欄位拖到維度,把什麼欄位拖到度量,然後把數據查出來,就是通過展現層去生成一個查詢,最後把查詢轉換成SQL到下麵數據源里去查。但是那時候大部分數據在一個比較慢的ODPS,性能用戶接受不了,還有一個就是許可權模塊。1.0版本大家可以理解成一個簡單的報表工具,他的查詢能力這些都不是很完備。
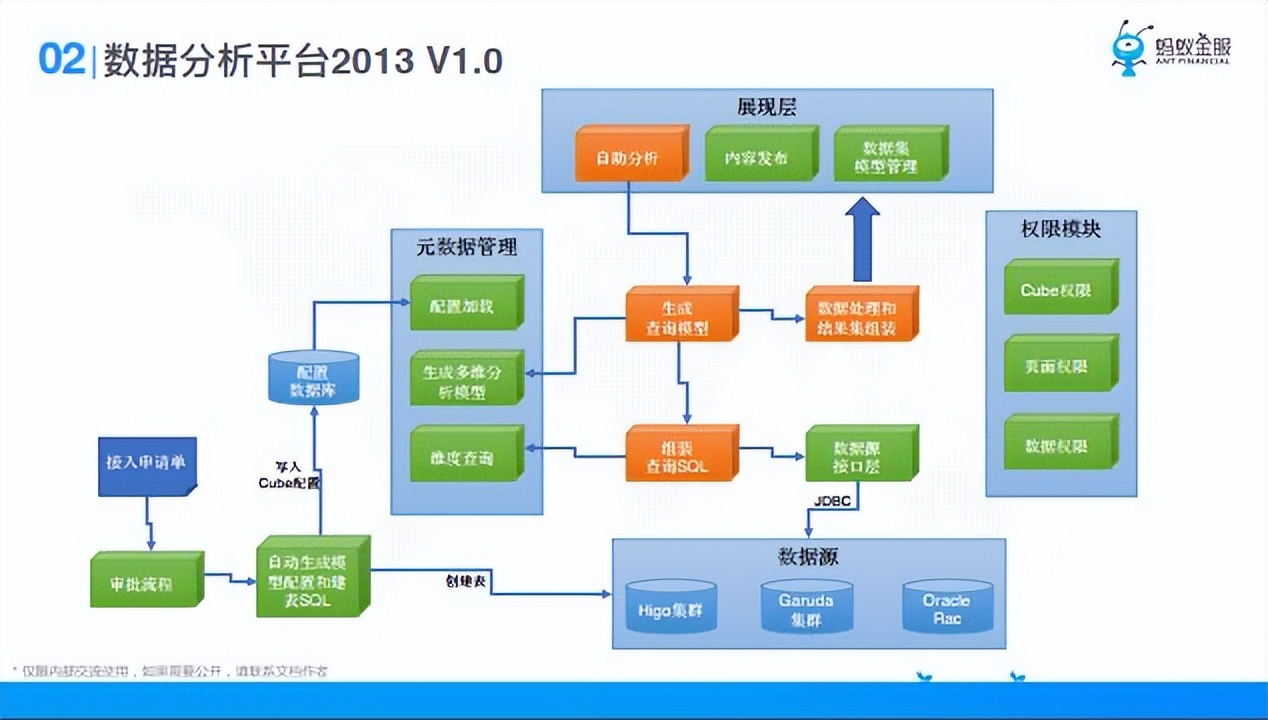
1.0版本以後,存在的矛盾有:
- ① 分析功能不足;
- ② 分析性能不足;
- ③ 數據能力與業務工作台是分裂。

這個情況下,我們做了2.0,2.0版本黃色的部分是新加的一些東西:
- ① 數據集:我是為了支撐一些更複雜的分析模型。可以做一些星型模型,雪花模型,做關聯數據集;
- ** ② 多維分析**:這一塊專門做了Mondrian,用MDX這種語言做多維分析;
- ③ 系統的自動加速:其實就是把它從以前的數據RDS,只要它引入到數據集裡面。只要它數據集一變,我就把它同步到ODPS,這一步是加速,所以說在查詢的時候,如果他已經加速了,我就把它路由到上一個數據源裡面去;
- ④ 開放:最早的開放比較簡單,就比如說iframe嵌入,或者說數據查詢介面,就這兩種能力,iframe嵌入就可以把他做的報表嵌入到自己的業務工作台裡面去,不用離開他的平臺。還有查詢,查詢開放給他,就可以更容易組裝他的流程。因為iframe嵌入只能整頁嵌入。
這就是數據分析平臺14年到16年的2.0,14年到16年我們其實都是在這張圖上去做的迭代,去豐富了很多能力,包括郵件訂閱的能力應對周報月報的一些場景。
在這之後,結合前面我們對數據分析的理解,其實我們想去重新定義一下分析洞察。
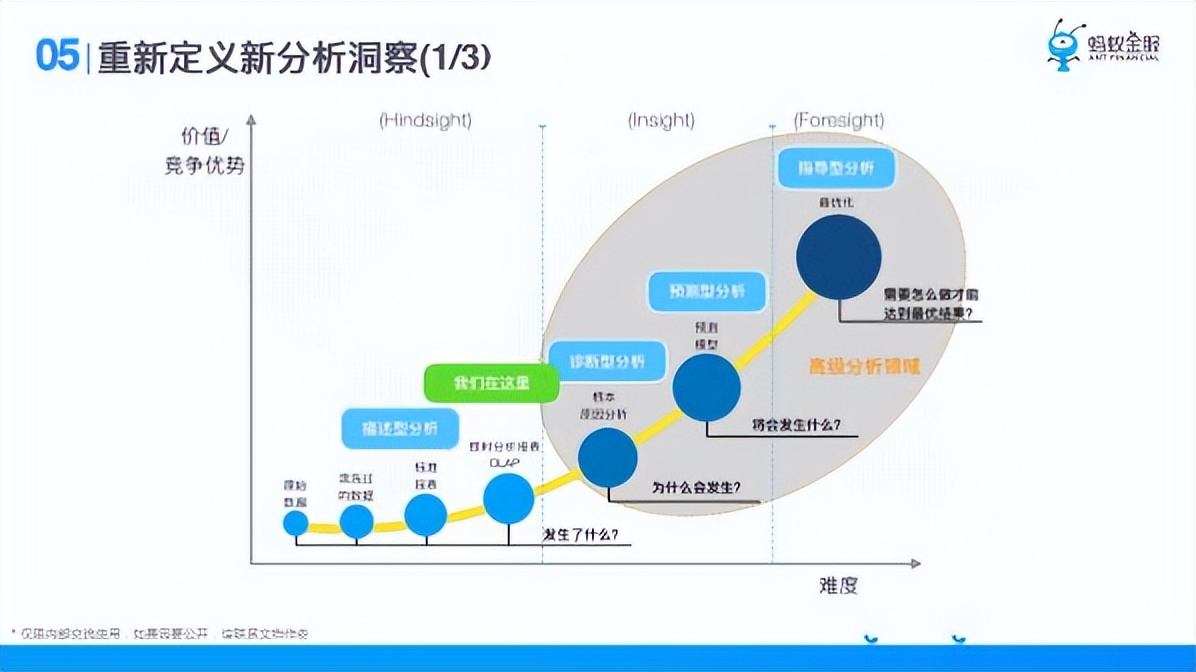
在17年的時候,我們去做這件事情。從描述型分析到診斷型分析到預測再到指導。這張圖裡我們還處在描述型分析這一塊使用,我們就分析下我們的用戶到底是怎麼樣的。
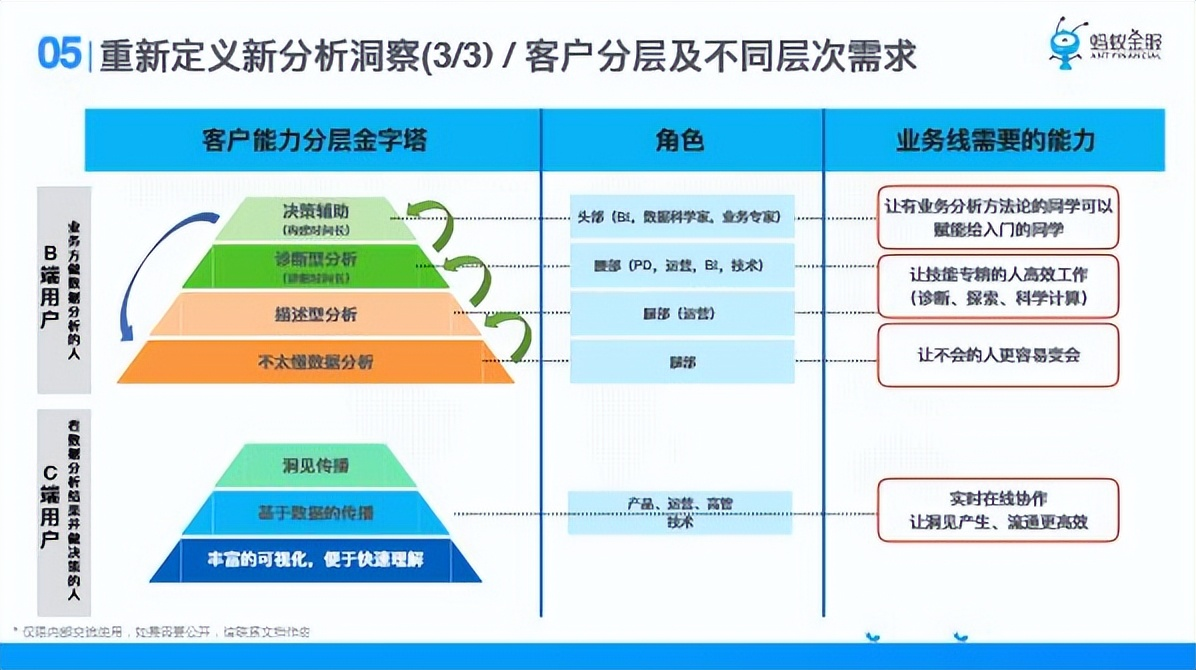
橫向分成三段,客戶能力分層,到他是什麼角色,到他的能力。我們把數據分析平臺用戶分成兩類,一類是B端業務方做數據分析的人,一類是C端看數據分析結果並做決策的人。
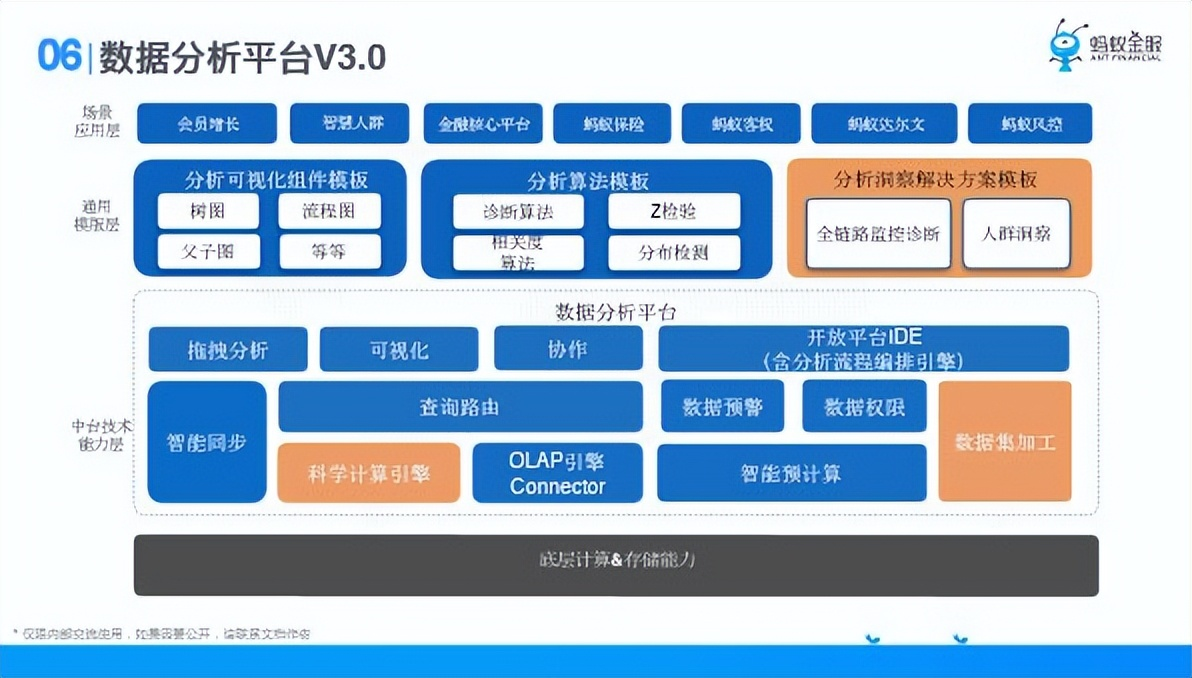
1、 場景應用層
2、 通用層
① 可視化:用戶自己定義自己的可視化組件;
② 分析演算法:自定義分析演算法的運算元;
③ 分析洞察解決方案:更大範圍的把這些分析原始的演算法包裝成一個分析流程。
3、中台核心能力
① 協作;
② 查詢路由;
③ 科學計算引擎;
④ 不同引擎的連接器;
⑤ 智能預計算;
⑥ 智能同步。
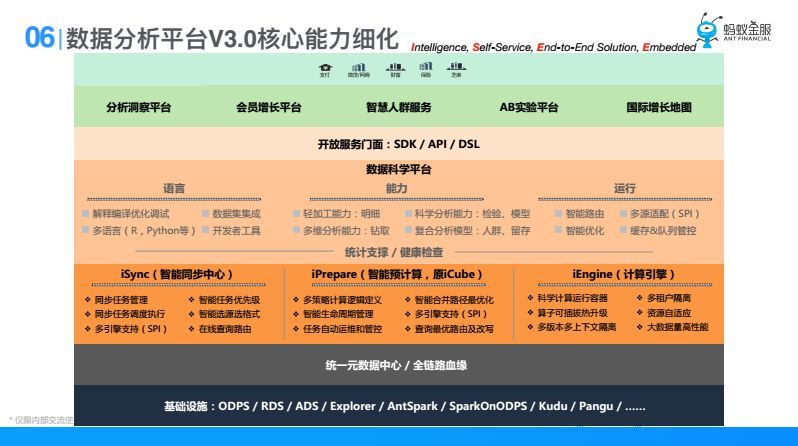
下麵可能會把數據分析平臺中間偏技術的會詳細細化一部分。他的核心能力有哪些,主要看下麵這一塊。
1、開放服務門面,無論是SDK,API還是DSL,在這裡面數據科學平臺裡面最主要的是有一門最主要的數據分析語言,這門數據分析語言包涵數據分析能力,包含演算法能力,他可以調一個演算法的運算元,把一個SQL結果去調一個演算法的運算元,調完演算法的運算元再去做多維分析。有了數據分析語言之後,我們會在數據科學平臺裡面提供一些能力,比如說輕加工能力,多維分析能力,科學分析能力,還有複合分析能力,在之後是運行,運行後我要去把他用語言表達出來的分析過程路由到下麵引擎去執行,把執行過程做優化,然後能適配到多維引擎。
2、核心能力
在這之下有三塊核心能力:
① 智能同步中心:智能同步中心最大的目的或者說解決的最大的問題,就是儘可能的在用戶訪問數據之前把他加速到快的數據源裡面去,如果慢的話,他看到的是老數據,他來我平臺訪問,他看到的是我昨天加速過去的數據,所以智能同步中心是解決這個問題;
② 智能預計算:我們發現我們有許多報表,因為報表拖出來的東西是固化的,昨天來看和今天來看只是日期不一樣,所以說我們會提前幫他做一些預計算,預先幫他算好存到那裡;
③ 執行引擎:執行引擎是需要把上面語言適配,一些高級分析能夠在這裡執行,然後多個源數據引擎往上面去適配,後面數據分析平臺的核心能力是基於這幾個關鍵字。第一個是智能的,這裡面一個是我們對象提供的數據分析方法論是智能,另一個就是我們在這裡面有一些工程能力;第二個是自服務,我們希望用戶在平臺上是自己服務自己的;第三個是端到端,我希望用戶無論做什麼事情,他需要數據能力,不用跳到其他地方去,他能夠一站式解決問題;第四個是嵌入式,就是能夠賦能到各個業務平臺,這是數據分析核心能力裡面的四個關鍵字,接下來就是一些基礎細節,主要講這一層的東西。
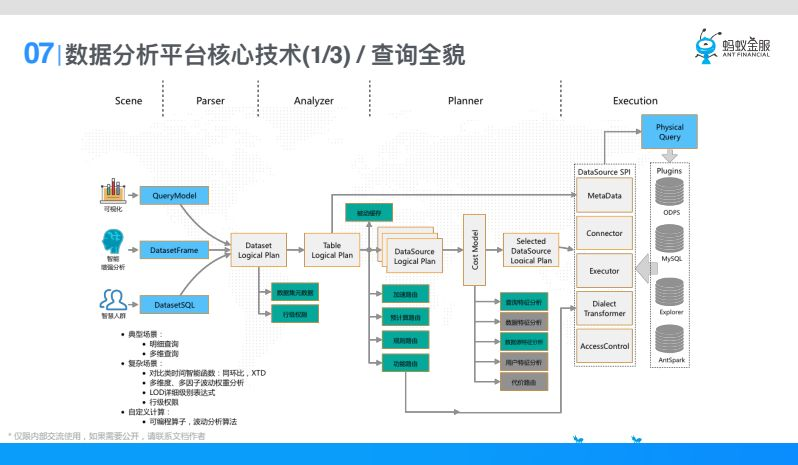
第一個是查詢,就是在數據分析平臺裡面一個查詢怎麼執行下去的呢,首先我們查詢的場景有很多,比如說可視化、智能增強分析、智慧人群,這些查詢模型統一翻譯成數據分析平臺的一個叫基於Dataset的Logical Plan。在這個Logical Plan裡面依賴數據集元數據、行級許可權(同樣一個數據集,不同的人來看只能看到不同的行,這是行級許可權)。
在這之後基於數據集的元數據翻譯成基於表的邏輯執行計劃Table Logical Plan, 基於表的Logical Plan,我們拿到表的元數據,再往後翻譯,因為一份數據大家可以看到,加速的過程可能會把一份數據加速到不同的引擎。原因是因為他應對的分析場景不一樣,有的引擎可以很快的支持多維分析的可視化,有的引擎可以支持智能增強分析,所以一份數據用到多個引擎,在這裡Table Logical Plan翻譯成DataSource Logical Plan,就是具體某一個元選定了,這裡可能有一些緩存、加速路由、預計算路由,還有規則和功能。
選出來多個數據源以後,經過一個代價模型,選出最優的數據源把它執行下去。代價模型裡面考慮的因素比較多,比如查詢特征,這一次group by了多少欄位,這些欄位的維度計數是怎麼樣的,有多少個count,distinct。第二數據特征,就是數據分佈是什麼樣的,第三還有一些用戶特征,比如螞蟻的高管優先順序更高一些,會給他一些執行比較快的引擎。
這樣選擇一個最優的數據源以後,會有一層抽象,我們會對DataSource進行SPI抽象,這裡面具備MetaData元數據、連接能力、執行能力、方言轉換能力、具備許可權控制能力,這個方言就是說同樣一個查詢,MySQL語法,ODPS語法或者說是hive語法是完全不一樣的,所以方言轉換就是同一個語言到各種語言的適配。
有了這一層SPI抽象以後,我們會去適配很多Plugins,Plugins可以動態載入進來,只要Plugins載入進來,我們就支持這個數據源的查詢,最終把這個查詢執行掉,這就是數據分新平臺整個查詢的過程。
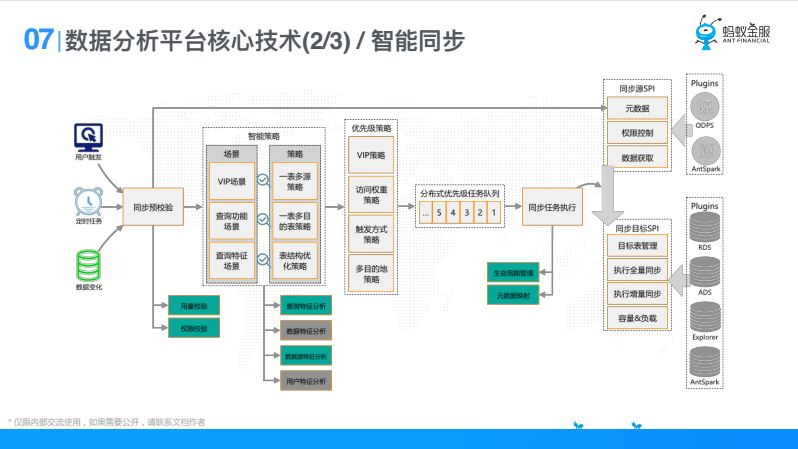
剛纔提到了加速,就是同步,在3.0裡面我們叫智能同步,剛纔給大家說了智能同步能解決什麼問題。我儘可能快的在用戶訪問之前把數據加速到正確的引擎,為什麼要加速到正確的引擎,因為這張表上有不同的分析訴求,比如說他有多維分析,有高級分析,或者要做一些演算法模型,那不同的引擎才能支持不同的場景,什麼時候觸發呢,可能用戶自己觸發,也可能定時任務觸發,還有數據變化,不管是元數據還是數據變化了。
之後要做同步校驗,可能有一些用量控制,有一些用戶許可權控制,校驗過以後會經過一個智能策略,智能策略就一件事情,把場景和策略做匹配,比如說VIP場景(剛纔說的高管);還有查詢特征功能場景,看看這張表上都有哪些查詢特征,比如他做多維分析查詢還是做演算法;還有查詢特征,查詢特征什麼意思呢,比如說他經常用某一個欄位做where條件,經常group by一個欄位,那應對的一些策略有VIP報表,我為了保證高管用戶,我會把一張表加速到多個元數據,可能把一張表加速到多個目的地表,在同一個元里給它建不同的深度格式,舉個例子比如說用戶表,第一用戶表經常做多維分析,第二它經常被用來join,這是個很常見的用uid跟交易表去做join,那用戶表我同步過去的時候就會有一表多目的地,首先同步一份基礎的能夠做多維分析的,同步一份按照uid散列的,提前按照uid散列後我的join效率更高,同樣交易這張表也會提前按照uid散列,所以這就是一表多目的地。還有表結構優化,比如同步到MySQL,發現他經常小數據量,比如說20萬、100萬以下這種數據量,我會把他同步到MySQL裡面去,我發現他的查詢特征經常用某一個欄位做where,我在這個欄位上建上索引,這就是表結構優化,這裡面可能和查詢路由差不多,有查詢特征,數據分佈,這個數據源支持什麼樣的特征,有了這些以後,會設置一些同步優先順序。
同步優先順序在一個分散式隊列裡面去排隊被執行掉,最後一步就是同步任務執行,就是兩層東西,一個是同步源,就是同步哪裡,還有就是同步到哪裡,同步目標,在SPI抽象以後跟前面查詢思路是類似的,回去實現很多Plugins,就可以從這裡同步到那裡,這是智能同步的技術詳解。
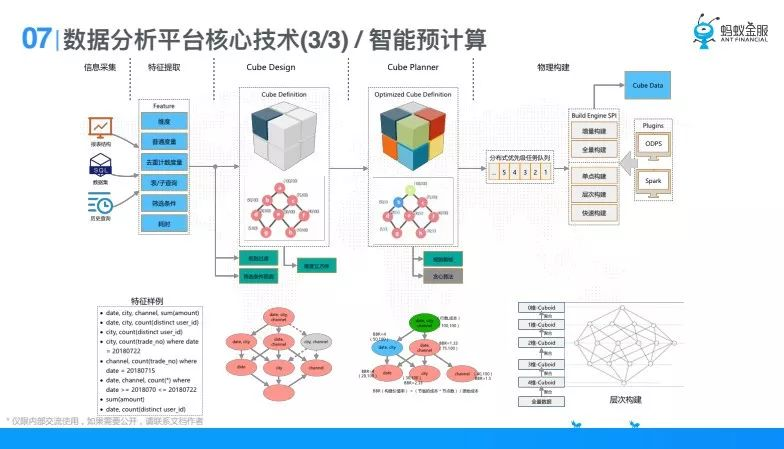
最後一塊就是之前提到的智能預計算, Kylin大家都聽說過,最早我們借鑒了麒麟的思想,第一數據分析平臺裡面做了很多報表,這些報表是明顯可固化的;第二數據分析平臺裡面有很多表被大家公共用到,一個業務部門都有很多人,這些表會被大家公用,在做拖拽的過程中有很多分析也是重合的,所以引用了預計算。
預計算整個過程是怎樣的,比如第一步我會去做信息採集,信息採集來自於幾個部分,比如說報表結構,定義的數據集結構,比如定義表和表做join分析,第三是歷史查詢,歷史的拖拽。有了這些以後我去提取特征,提取特征就有維度,就有普通度量,distinct度量,還有表/子查詢,是哪張表,是哪個子查詢,他的篩選條件是什麼,他的耗時是什麼。有了這些特征以後,我會去做一個叫立方體的概念,就是Cube Design,這個過程我們去設計立方體,設計立方體邏輯很簡單,就是把同表同子查詢的這些維度度量建成一棵樹,這是最細維度的,細粒度比如說group by 4個欄位,我可以彙總到group by三個欄位、兩個欄位,或者說我可以彙總成group by兩個欄位,一個欄位的結果,這樣建成一個Cube。建成一棵樹以後並不是說這一個樹的所有節點都幫他算,因為維度組合是算不過來的,所以去做一些Cube Planner,去做一些剪枝,哪些規則我不要,比如說基於規則,比如說耗時已經小於三秒或者已經小於一秒了,我就不幫你建了,因為你的引擎已經能滿足你了,還有做一些貪心演算法,做一些優化怎麼做才能讓這樹的收益達到最高。之後就要做物理構建了,物理構建是一樣的,在螞蟻下麵引擎設都涉及到多引擎,我們都是要做這一層,在我們三個核心技術細節都會看到SPI抽象,但在這個SPI框裡面是不一樣的。這裡構建引擎的SPI有增量構建,全量構建,有單點構建,也有城市構建,還有快速構建,這些不同的能力。有這些能力以後,比如說ODPS,Spark這兩個,去做最終構建,這樣構建以後去查詢路由的時候,就會路由到已經經過智能預計算中心的元數據去做路由,路由到一個最優的,已經計算好的。最優的一般都是group by 最少的那個,智能預計算就是這個。
下麵這一排是針對上面的最近的例子,前面講的數據平臺的核心能力以及幾個點的技術細節,有了這些以後我們數據平臺有一些結果。

--
04 數據分析應用
數據分析平臺有了這些技術以後,他到底能幫助我們做什麼,或者說如果用數據分析平臺來幫助我他的套路是什麼樣的,舉個例子就是數據分析驅動數據分析平臺技能優化,這是一個用數據分析來驅動工程上優化的例子,首先第一步看看問題是什麼。

不同的人都期望提升到秒級,還有個別報表查詢要90秒,這就是走的0DPS這種查詢,很慢達到了分鐘級,所以說大家抱怨就是RT的問題,用戶的期望是達到秒級,但我們知道就像穩定性一樣,實際情況是不可能100%達到秒級的,總有一些異常情況和考慮不到的地方,這是問題,我們要解決這個RT。
接下來我們要解決一個問題,要讓這個問題可衡量,我要能夠度量它這也便於優化他,也知道解決到什麼程度了,第二塊就要定義指標。

指標就如剛纔說的,我們沒辦法做到100%,所以我們定義指標有一兩個,一個是體驗指標,一個是底線指標,體驗指標就是查詢RT在一秒內要達到占比98%,底線指標就是RT在10秒內占比100%,因為10秒這種界限我們還是有信心的。為什麼叫體驗指標,這其實和大部分用戶相關的,他能感受到,為什麼要有底線指標,那少部分人隨著平臺用戶量的增長也會把平臺拖死,他每天都來麻煩你,隨著用戶量的增長找你的人也會越來越多,所以說有一個底線指標。那這裡涉及到定義一個指標,一個好的指標應該簡單易懂,一個好的指標應該是個比率,好的指標可以指導行為改變。
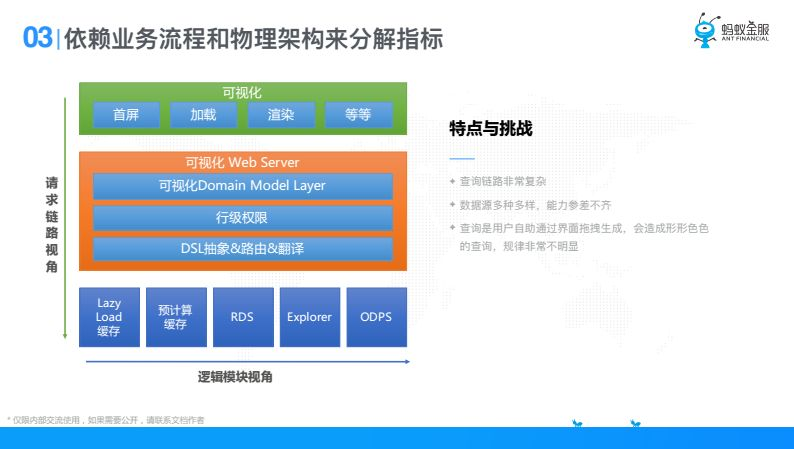
我們要依賴業務流程和物理架構來進行分解,這是我對數據分析平臺做了一個簡化,從可視化到服務端再到數據查詢語言,這部分是請求鏈路視角,橫向是邏輯模塊視角,比如有哪些可能的數據源,查詢一列要經過那些過程,有了這個認知以後我們對它進行數據抽象。
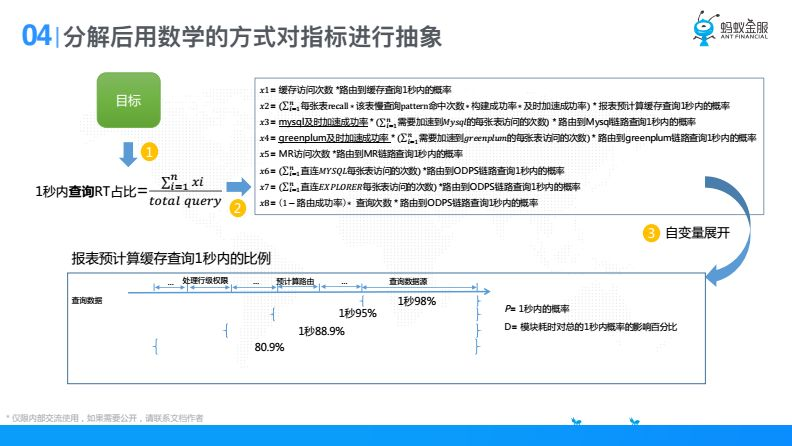
分解後要用數學的方式進行抽象,其實剛纔上面那一張圖可以看到,有緩存,有預計算,有RDS,有不同引擎,有了這些引擎以後我把我一秒內占比的RT拆解為這個公式,分母就是總的查詢量,分子就是一秒內的查詢量,一秒內的查詢量我可以按照引擎去拆,拆完以後每一個引擎都代表他一秒內的引擎次數,X1一直到X8,都是不同元的一秒內查詢次數,當某一個元確定以後,我又可以按照鏈路去拆,比如說預計算我經過了什麼鏈路,比如說先進來處理行級許可權,接下來處理預計算路由,然後是查詢數據源,就是這個邏輯,有了這個抽象以後,我們就可以去做數據分析。
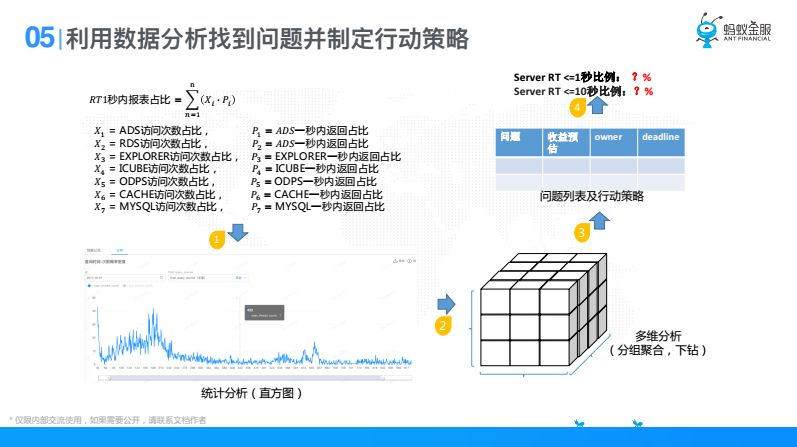
這是我們的抽象,抽象以後我們把我們的數據拿出來。比如說選定某一個元,我去看他的統計直方圖,橫軸是耗時,就是找問題的耗時,縱軸是他的次數,他一秒內有多少次,兩秒內有多少次,很明顯有了這個圖以後我們很容易看出一些東西,圖中有間次的地方先圈出來,比如我現在就想解決這一段(波峰),解決這撥人,我就先把這裡圈出來,去做多維分析,然後去找到原因,找到原因以後,如果我把這個地方優化掉,對我的總指標能提升多少,比如一秒內占比,十秒內占比,我是能預估出來這個地方優化對我總指標能提升多少,這個過程大家可以發現為什麼看總指標的提升,因為我們人力總是有限的,我要去評估ROI產出比,肯定是投入小對這個指標先做。
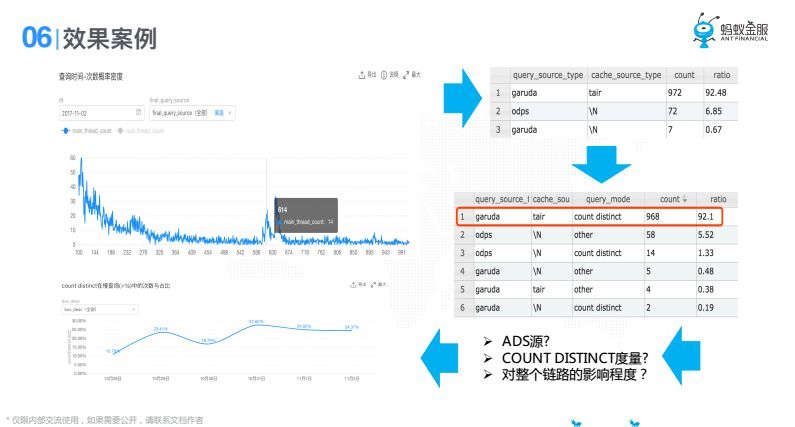
舉個例子,就這個過程當中,這個間次我們先把他圈出來以後,發現有一個數據源(我們內部叫ADS),發現這個ADS這個次數最多,在這區間ADS達到了900多次,我們把這個圈出來看他其他的漏洞,我發現在下鑽一個維度,下鑽query_mode查詢類型是怎樣的,我發現count_distinct占比92%,也就是導致這一段的原因是ADS這個源的count_distinct不行。這其實最終找到了這個原因,之後我們判斷一下這一個點對我們整個慢查詢的性能有多少,整體慢查詢能占到20%30%的樣子,也就是說我只要把這個優化,對我整體指標能夠提升20%30%,這可能就是經過剛纔這個思路找到的具體優化,這隻是其中一個。
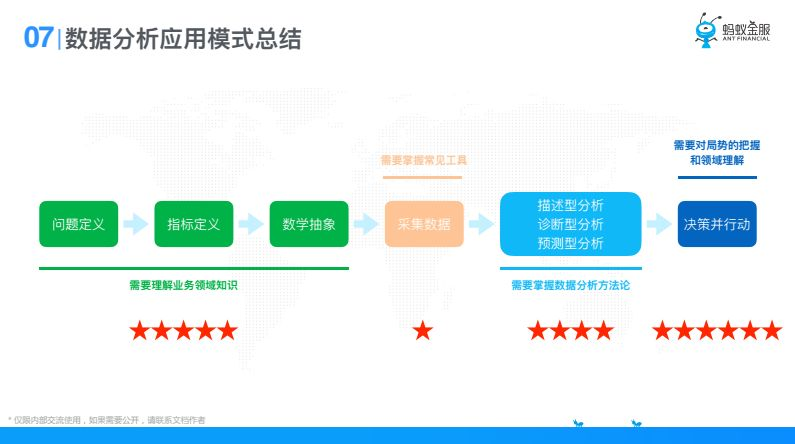
總結一下就是數據分析要做出一些東西的話,他的套路就是這樣的,先要問題定義,你要解決什麼問題,然後你要衡量這個問題(指標定義),彼得德魯克曾說過,沒有很好的度量,就沒有辦法增長,所以說我們得先定義出來,定義出來如果你只有這個指標,你什麼也不能幹,只能做個監控,只能用它來印證你的想法,所以說我們要去進行數學抽象,從一些業務鏈路上,從一些系統模塊上去做一些抽象,抽象好了以後去看有沒有相應的數據(採集數據),有了數據以後去做分析,無論是描述型分析、診斷型分析還是預測型分析,運用分析方法去找到原因,然後去決策並行動。這個過程裡面比較難的,當然做決定是比較難的,一是你要對這個業務領域有很強的理解,第二你要判斷數據分析的結果到底符不符合業務理解。第二難就是數據抽象這一塊,這一塊要你對業務有很深的認知,無論從鏈路上還是從模塊上,如果你解決工程問題,你就要對系統有認知,如果你解決業務問題,要對鏈路有很強的認知,這就是數據分析應用模式,總結下來就是這樣的套路。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”。


